
Predicting Higher Heating Value of Sewage Sludges via Artificial Neural Network Based on Proximate and Ultimate Analyses


Abstract
:1. Introduction
2. Materials and Methods
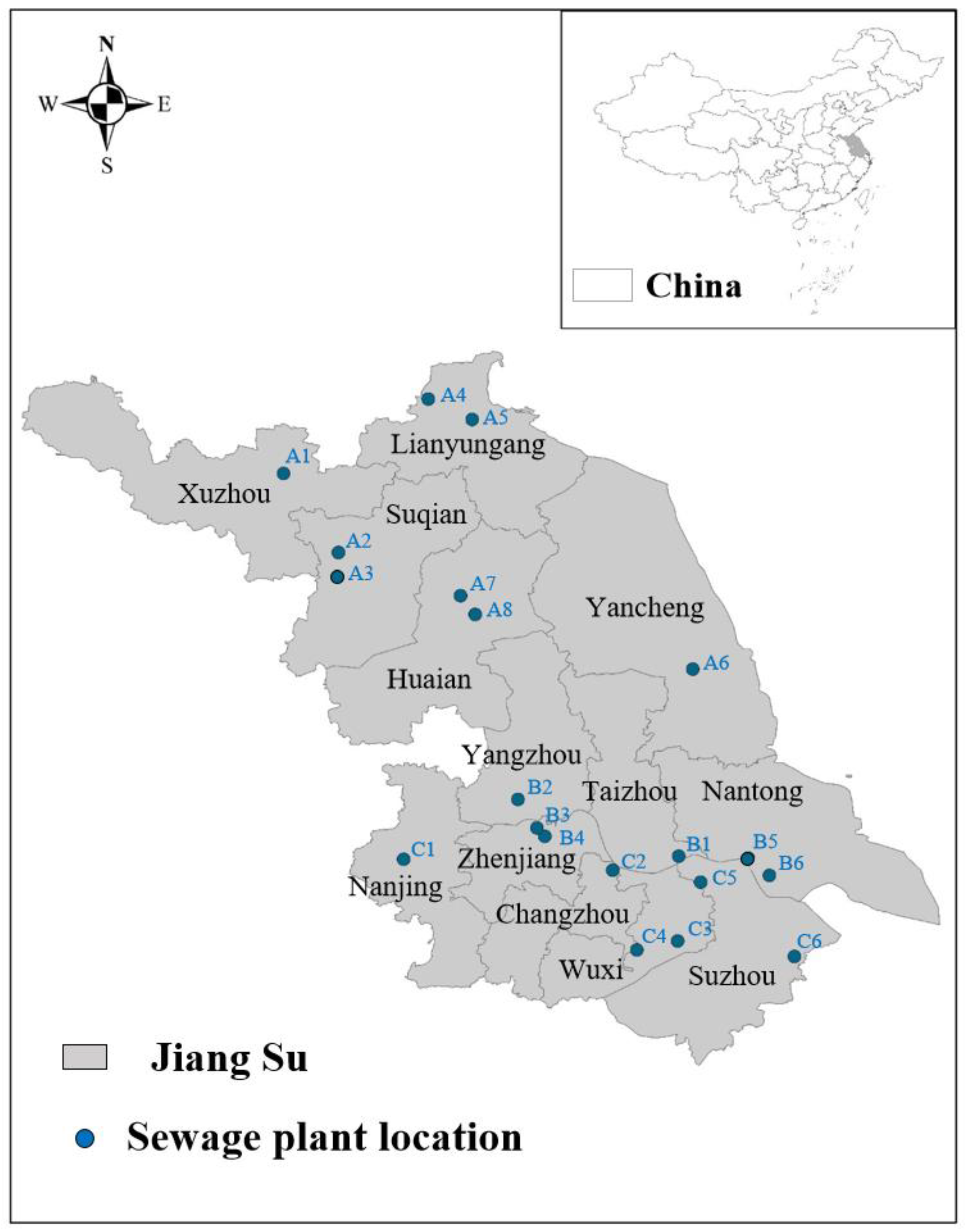
2.1. Source of Sample
2.2. Sample Preparation
2.3. Sample Characterization
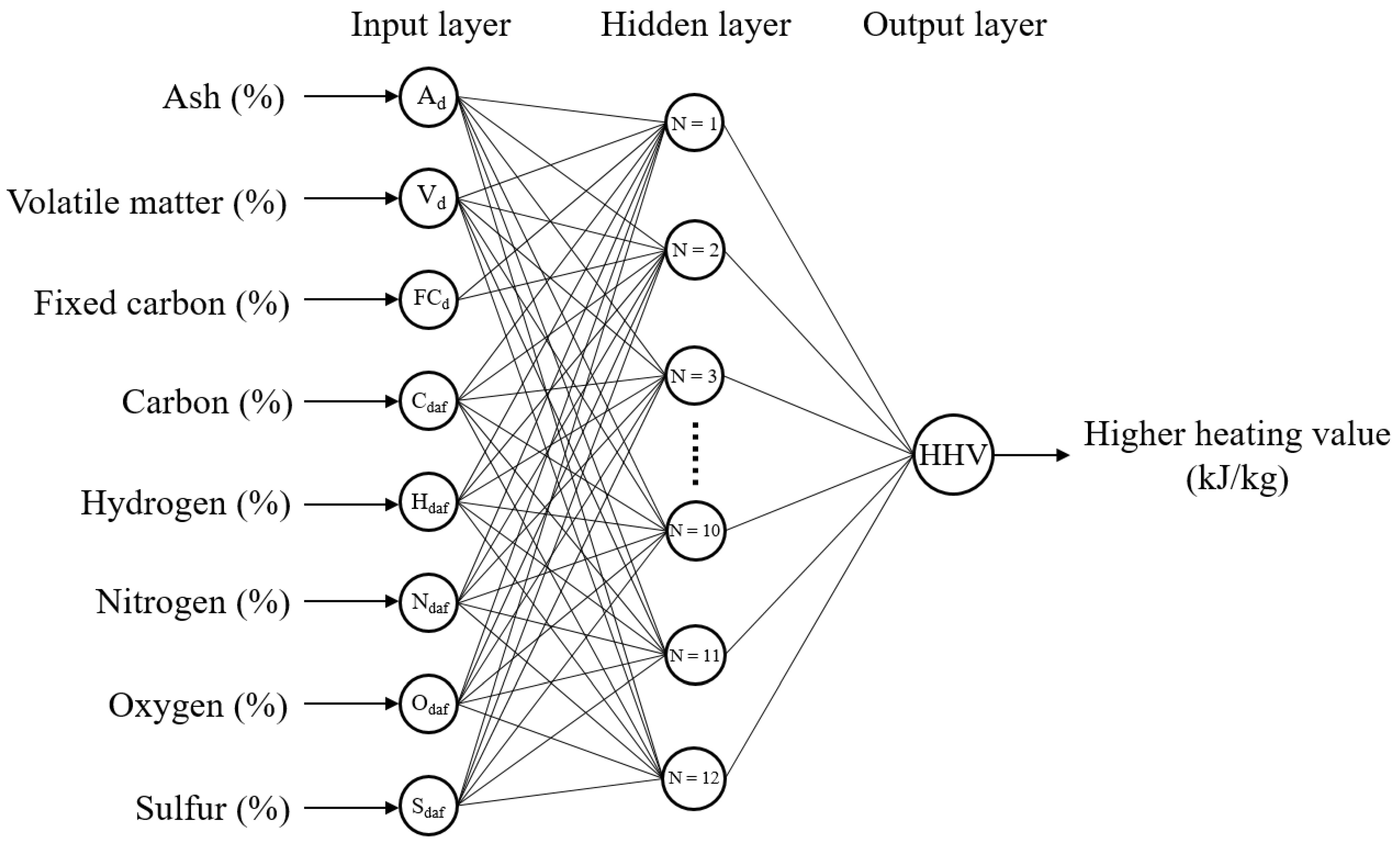
2.4. Back Propagation Neural Network
2.5. Statistical Analysis
3. Results
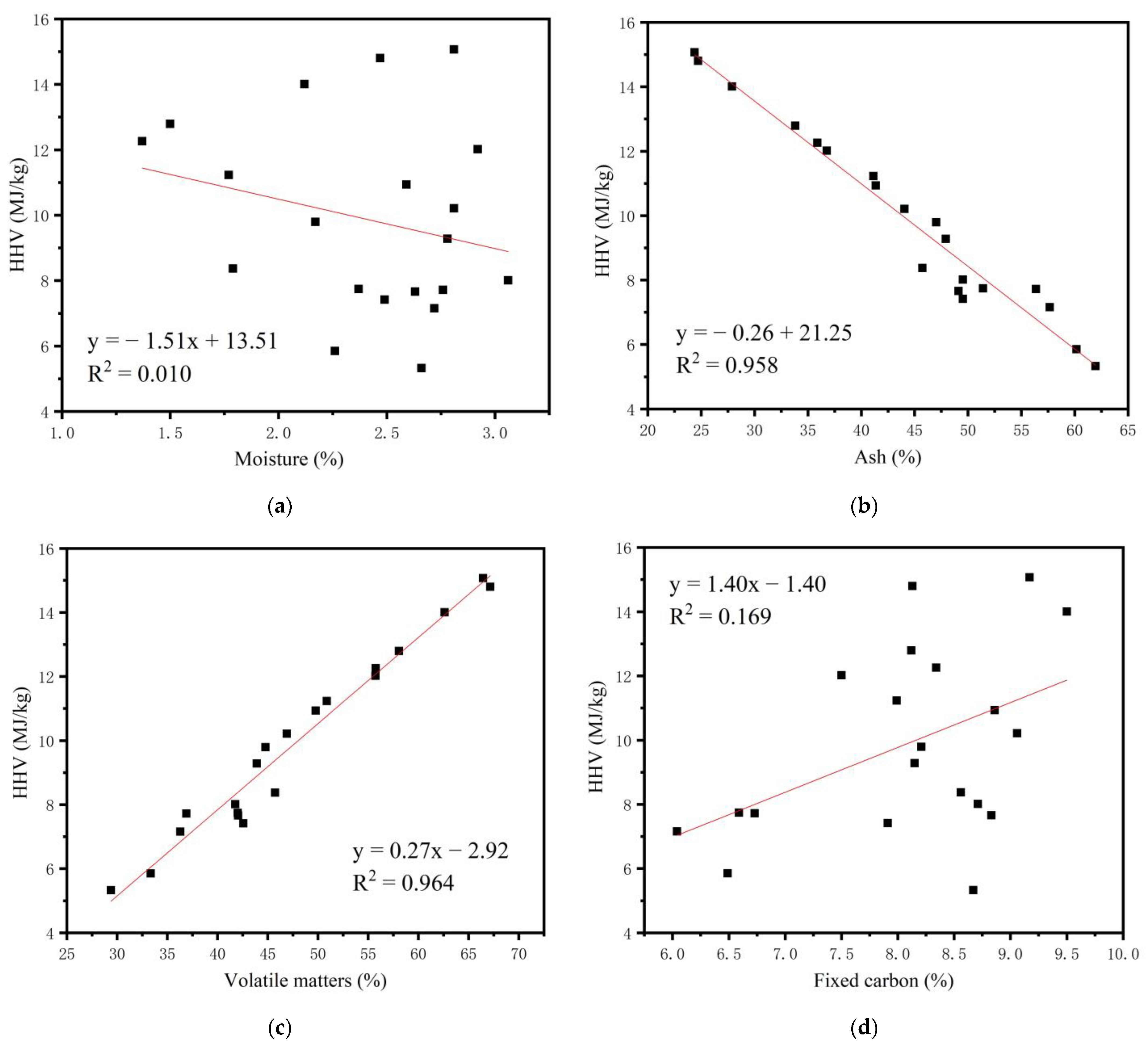
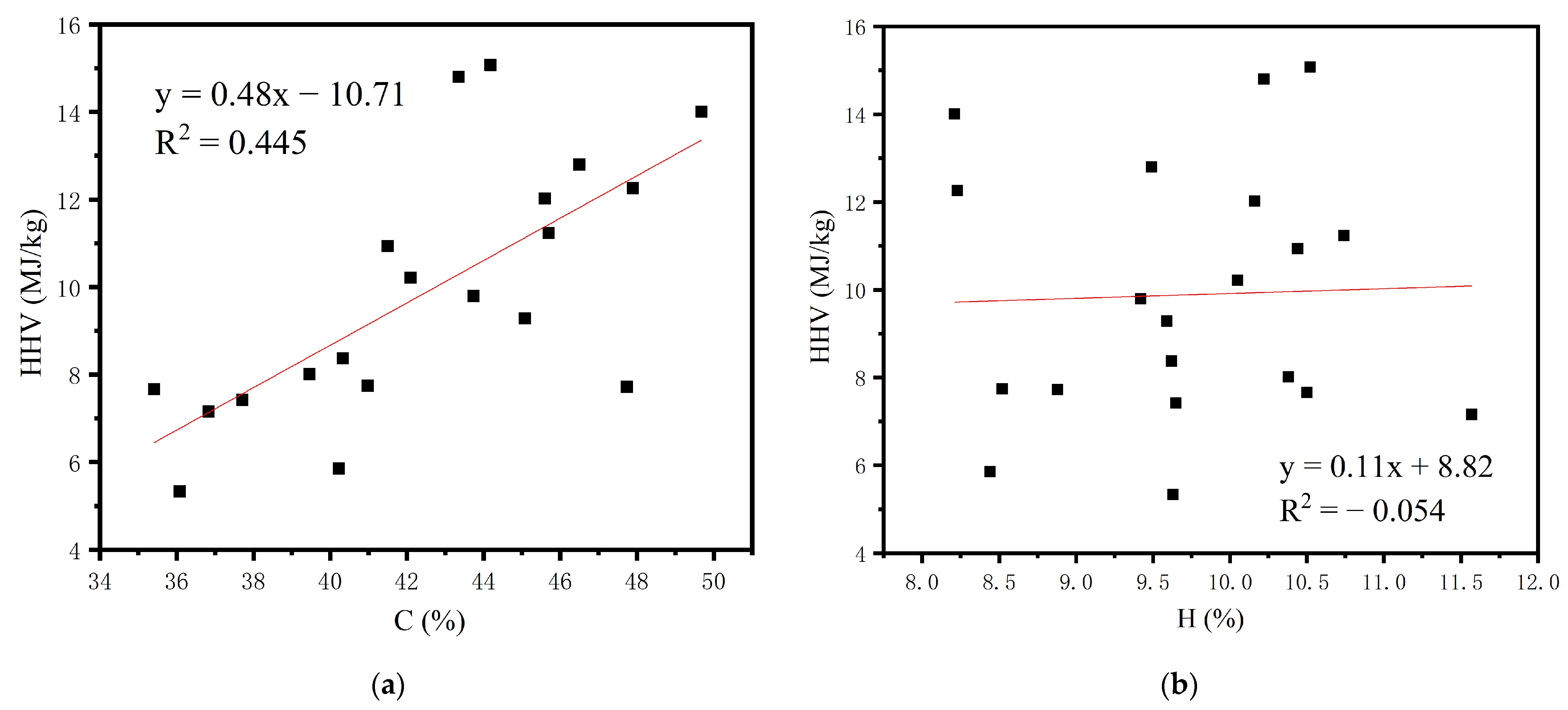
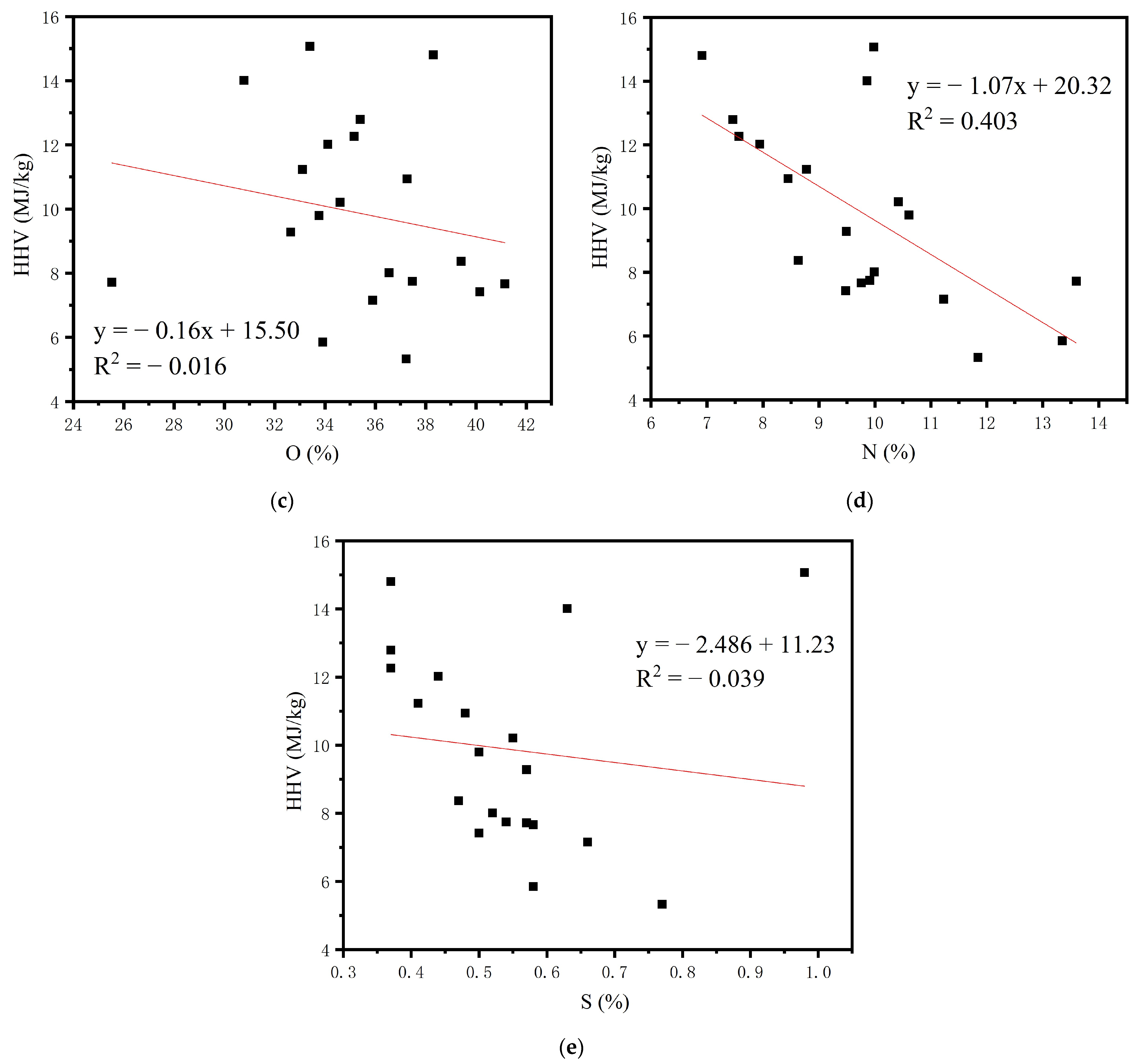
3.1. Proximate and Ultimate Analyses of Sewage Sludge
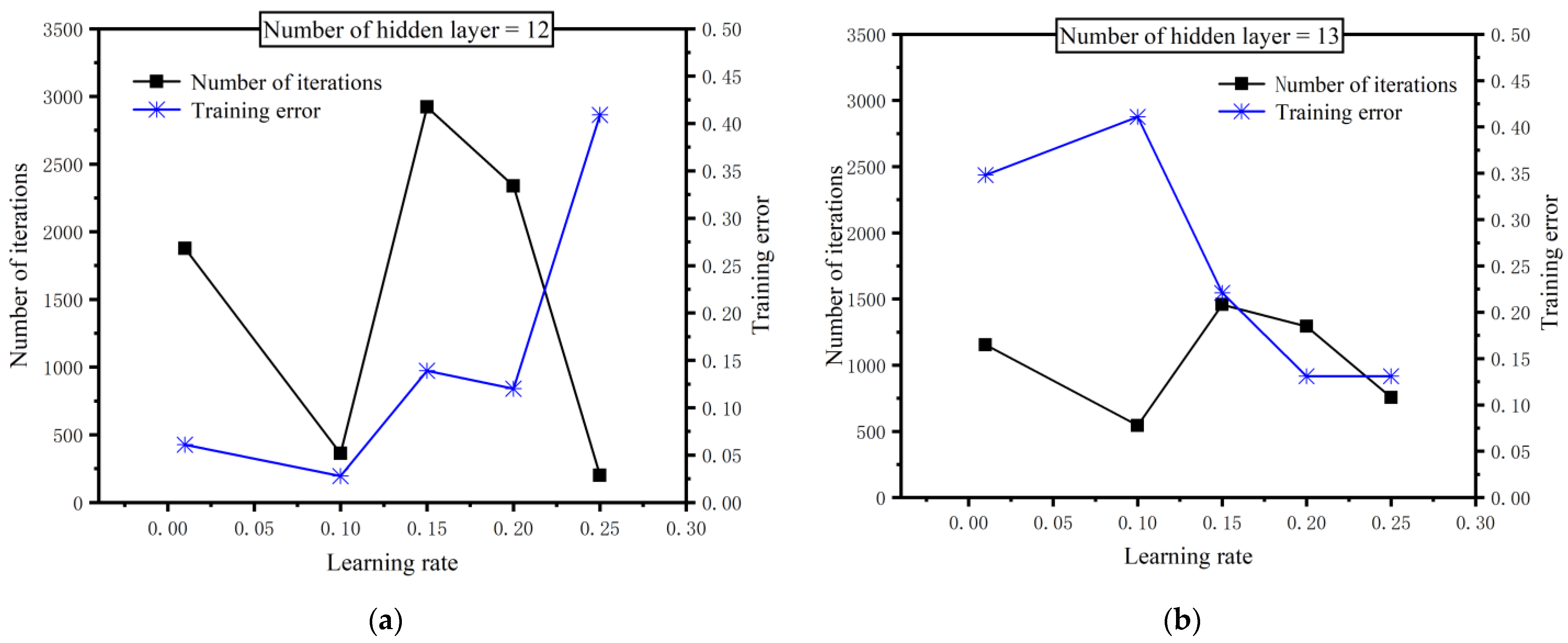
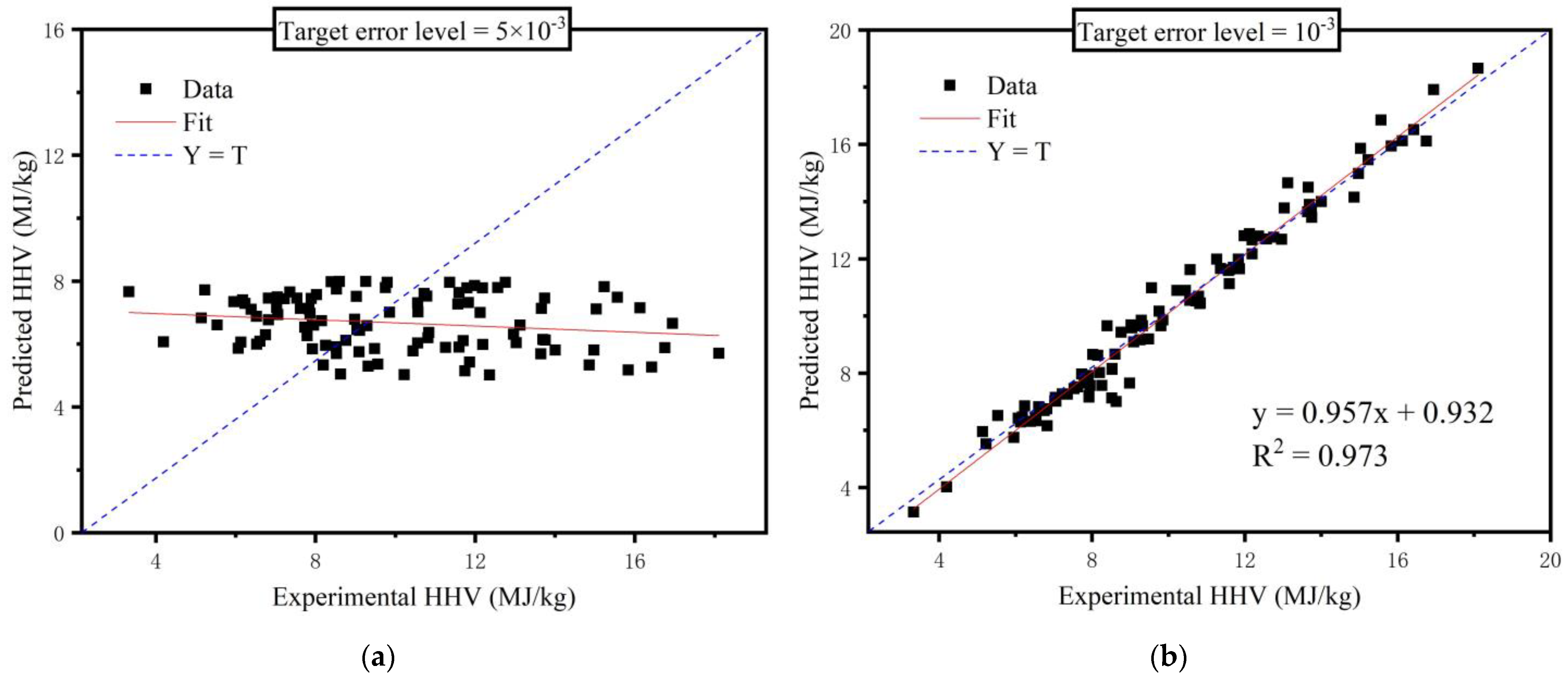
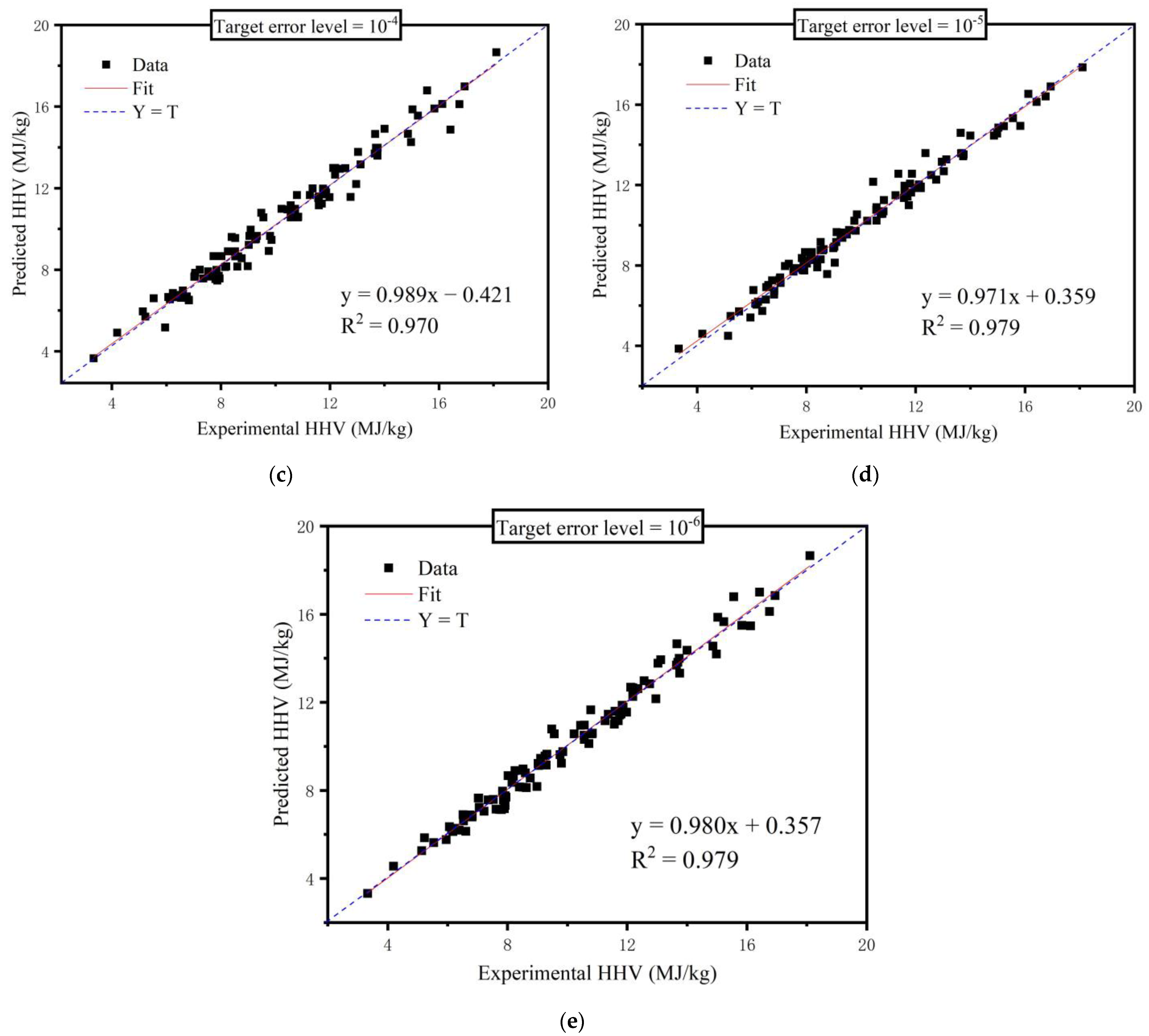
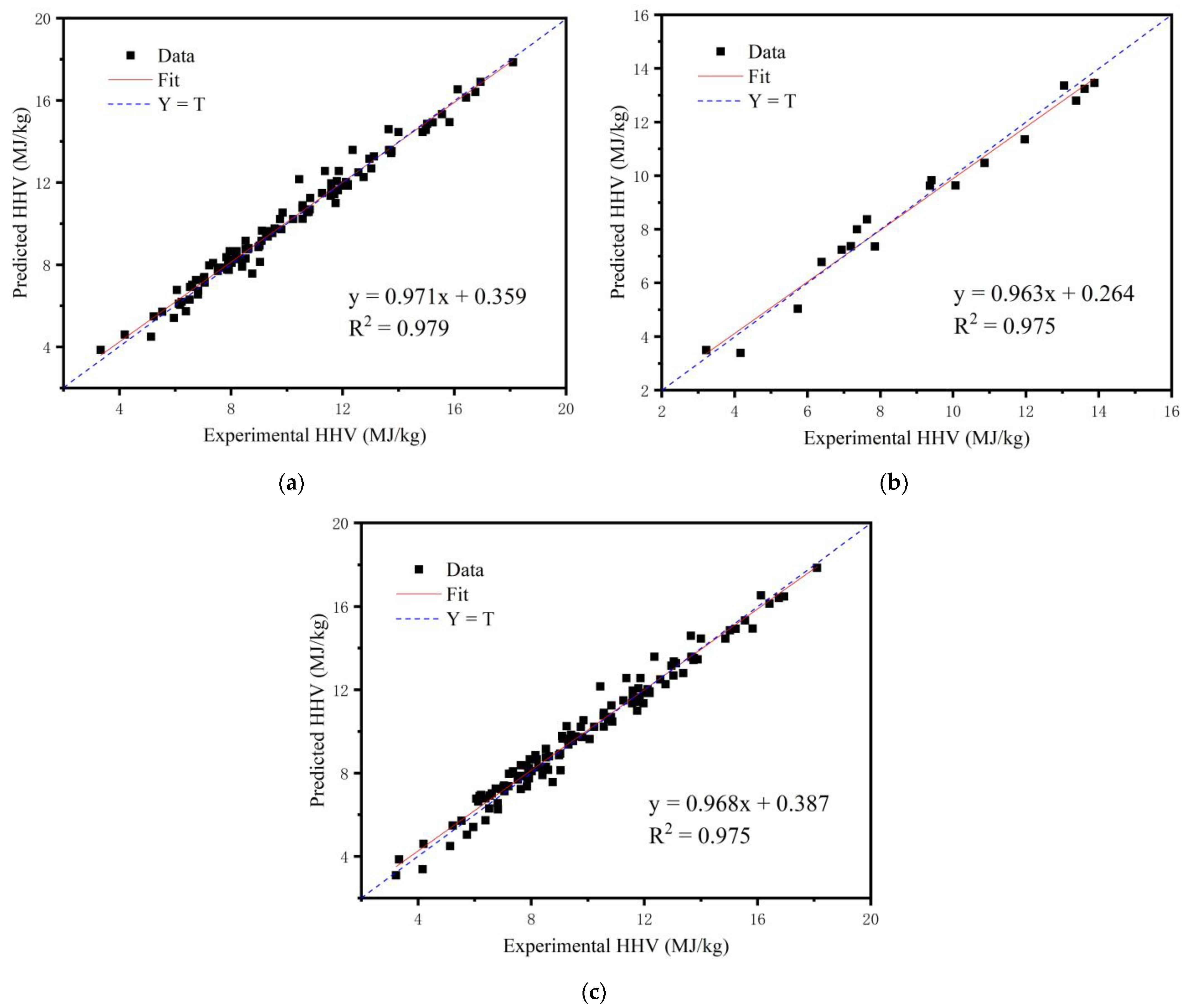
3.2. Modeling Back Propagation Neural Network Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wei, L.; Xia, X.; Zhu, F.; Li, Q.; Xue, M.; Li, J.; Sun, B.; Jiang, J.; Zhao, Q. Dewatering efficiency of sewage sludge during Fe(2+)-activated persulfate oxidation: Effect of hydrophobic/hydrophilic properties of sludge EPS. Water Res. 2020, 181, 115903. [Google Scholar] [CrossRef] [PubMed]
- Bai, B.; Rao, D.; Chang, T.; Guo, Z. A nonlinear attachment-detachment model with adsorption hysteresis for suspension-colloidal transport in porous media. J. Hydrol. 2019, 578, 124080. [Google Scholar] [CrossRef]
- Bai, B.; Wang, Y.; Rao, D.; Bai, F. The Effective Thermal Conductivity of Unsaturated Porous Media Deduced by Pore-Scale SPH Simulation. Front. Earth Sci. 2022, 10, 943853. [Google Scholar] [CrossRef]
- Hoang, S.A.; Bolan, N.; Madhubashani, A.M.P.; Vithanage, M.; Perera, V.; Wijesekara, H.; Wang, H.; Srivastava, P.; Kirkham, M.B.; Mickan, B.S.; et al. Treatment processes to eliminate potential environmental hazards and restore agronomic value of sewage sludge: A review. Environ. Pollut. 2022, 293, 118564. [Google Scholar] [CrossRef] [PubMed]
- Ge, D.; Yuan, H.; Xiao, J.; Zhu, N. Insight into the enhanced sludge dewaterability by tannic acid conditioning and pH regulation. Sci. Total Environ. 2019, 679, 298–306. [Google Scholar] [CrossRef]
- Wang, C.; Fan, Y.; Hornung, U.; Zhu, W.; Dahmen, N. Char and tar formation during hydrothermal treatment of sewage sludge in subcritical and supercritical water: Effect of organic matter composition and experiments with model compounds. J. Clean. Prod. 2020, 242, 118586. [Google Scholar] [CrossRef]
- Fang, X.; Wang, Q.; Wang, J.; Xiang, Y.; Wu, Y.; Zhang, Y. Employing extreme value theory to establish nutrient criteria in bay waters: A case study of Xiangshan Bay. J. Hydrol. 2021, 603, 127146. [Google Scholar] [CrossRef]
- Li, T.; Su, T.; Wang, J.; Zhu, S.; Zhang, Y.; Geng, Z.; Wang, X.; Gao, Y. Simultaneous removal of sulfate and nitrate from real high-salt flue gas wastewater concentrate via a waste heat crystallization route. J. Clean. Prod. 2023, 382, 135262. [Google Scholar] [CrossRef]
- Gaur, R.Z.; Khoury, O.; Zohar, M.; Poverenov, E.; Darzi, R.; Laor, Y.; Posmanik, R. Hydrothermal carbonization of sewage sludge coupled with anaerobic digestion: Integrated approach for sludge management and energy recycling. Energy Convers. Manag. 2020, 224, 113353. [Google Scholar] [CrossRef]
- Oliveira, A.S.; Sarrion, A.; Baeza, J.A.; Diaz, E.; Calvo, L.; Mohedano, A.F.; Gilarranz, M.A. Integration of hydrothermal carbonization and aqueous phase reforming for energy recovery from sewage sludge. Chem. Eng. J. 2022, 442, 136301. [Google Scholar] [CrossRef]
- Liu, W.; Zheng, J.; Ou, X.; Liu, X.; Song, Y.; Tian, C.; Rong, W.; Shi, Z.; Dang, Z.; Lin, Z. Effective Extraction of Cr(VI) from Hazardous Gypsum Sludge via Controlling the Phase Transformation and Chromium Species. Environ. Sci. Technol. 2018, 52, 13336–13342. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Liu, X.; Ni, S.-Q.; Zhuang, X.; Lee, T. Nano zero-valent iron improves anammox activity by promoting the activity of quorum sensing system. Water Res. 2021, 202, 117491. [Google Scholar] [CrossRef] [PubMed]
- Xu, D.; Li, J.; Liu, J.; Qu, X.; Ma, H. Advances in continuous flow aerobic granular sludge: A review. Process Saf. Environ. Prot. 2022, 163, 27–35. [Google Scholar] [CrossRef]
- Xu, Y.; Dai, X. Integrating multi-state and multi-phase treatment for anaerobic sludge digestion to enhance recovery of bio-energy. Sci. Total Environ. 2020, 698, 134196. [Google Scholar] [CrossRef] [PubMed]
- Passos, J.; Alves, O.; Brito, P. Management of municipal and construction and demolition wastes in Portugal: Future perspectives through gasification for energetic valorisation. Int. J. Environ. Sci. Technol. 2020, 17, 2907–2926. [Google Scholar] [CrossRef]
- Chen, L.; Liao, Y.; Ma, X. Economic analysis on sewage sludge drying and its co-combustion in municipal solid waste power plant. Waste Manag. 2021, 121, 11–22. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, Q.; Cui, Q.; Ni, S.-Q. Nitrogen recovery through fermentative dissimilatory nitrate reduction to ammonium (DNRA): Carbon source comparison and metabolic pathway. Chem. Eng. J. 2022, 441, 135938. [Google Scholar] [CrossRef]
- Mosko, J.; Pohorely, M.; Skoblia, S.; Beno, Z.; Jeremias, M. Detailed Analysis of Sewage Sludge Pyrolysis Gas: Effect of Pyrolysis Temperature. Energies 2020, 13, 4087. [Google Scholar] [CrossRef]
- Zhang, X.; Ma, F.; Yin, S.; Wallace, C.; Soltanian, M.R.; Dai, Z.; Ritzi, R.W.; Ma, Z.; Zhan, C.; Lu, X. Application of upscaling methods for fluid flow and mass transport in multi-scale heterogeneous media: A critical review. Appl. Energy 2021, 303, 117603. [Google Scholar] [CrossRef]
- Zhao, L.; Du, M.; Du, W.; Guo, J.; Liao, Z.; Kang, X.; Liu, Q. Evaluation of the Carbon Sink Capacity of the Proposed Kunlun Mountain National Park. Int. J. Environ. Res. Public Health 2022, 19, 9887. [Google Scholar] [CrossRef]
- Xu, L.; Yuan, J. Online identification of the lower heating value of the coal entering the furnace based on the boiler-side whole process models. Fuel 2015, 161, 68–77. [Google Scholar] [CrossRef]
- Dashti, A.; Noushabadi, A.S.; Asadi, J.; Raji, M.; Chofreh, A.G.; Klemes, J.J.; Mohammadi, A.H. Review of higher heating value of municipal solid waste based on analysis and smart modelling. Renew. Sustain. Energy Rev. 2021, 151, 111591. [Google Scholar] [CrossRef]
- Ghugare, S.B.; Tiwary, S.; Elangovan, V.; Tambe, S.S. Prediction of Higher Heating Value of Solid Biomass Fuels Using Artificial Intelligence Formalisms. Bioenergy Res. 2014, 7, 681–692. [Google Scholar] [CrossRef]
- Cordero, T.; Marquez, F.; Rodriguez-Mirasol, J.; Rodriguez, J.J. Predicting heating values of lignocellulosics and carbonaceous materials from proximate analysis. Fuel 2001, 80, 1567–1571. [Google Scholar] [CrossRef]
- Kathiravale, S.; Yunus, M.N.M.; Sopian, K.; Samsuddin, A.H.; Rahman, R.A. Modeling the heating value of Municipal Solid Waste. Fuel 2003, 82, 1119–1125. [Google Scholar] [CrossRef]
- Choi, H.L.; Sudiarto, S.I.A.; Renggaman, A. Prediction of livestock manure and mixture higher heating value based on fundamental analysis. Fuel 2014, 116, 772–780. [Google Scholar] [CrossRef]
- Thipkhunthod, P.; Meeyoo, V.; Rangsunvigit, P.; Kitiyanan, B.; Siemanond, K.; Rirksomboon, T. Predicting the heating value of sewage sludges in Thailand from proximate and ultimate analyses. Fuel 2005, 84, 849–857. [Google Scholar] [CrossRef]
- Akkaya, E. ANFIS based prediction model for biomass heating value using proximate analysis components. Fuel 2016, 180, 687–693. [Google Scholar] [CrossRef]
- Petkovic, B.; Petkovic, D.; Kuzman, B. Adaptive neuro fuzzy predictive models of agricultural biomass standard entropy and chemical exergy based on principal component analysis. Biomass Convers. Biorefinery 2022, 12, 2835–2845. [Google Scholar] [CrossRef]
- Xing, J.; Luo, K.; Wang, H.; Gao, Z.; Fan, J. A comprehensive study on estimating higher heating value of biomass from proximate and ultimate analysis with machine learning approaches. Energy 2019, 188, 116077. [Google Scholar] [CrossRef]
- Aladejare, A.E.; Onifade, M.; Lawal, A.I. Application of metaheuristic based artificial neural network and multilinear regression for the prediction of higher heating values of fuels. Int. J. Coal Prep. Util. 2022, 42, 1830–1851. [Google Scholar] [CrossRef]
- Kapetanakis, T.N.; Vardiambasis, I.O.; Nikolopoulos, C.D.; Konstantaras, A.I.; Trang, T.K.; Khuong, D.A.; Tsubota, T.; Keyikoglu, R.; Khataee, A.; Kalderis, D. Towards Engineered Hydrochars: Application of Artificial Neural Networks in the Hydrothermal Carbonization of Sewage Sludge. Energies 2021, 14, 3000. [Google Scholar] [CrossRef]
- Cakman, G.; Gheni, S.; Ceylan, S. Prediction of higher heating value of biochars using proximate analysis by artificial neural network. Biomass Convers. Biorefinery 2021, 1–9. [Google Scholar] [CrossRef]
- Taki, M.; Rohani, A. Machine learning models for prediction the Higher Heating Value (HHV) of Municipal Solid Waste (MSW) for waste-to-energy evaluation. Case Stud. Therm. Eng. 2022, 31, 101823. [Google Scholar] [CrossRef]
- Genuino, D.A.D.; Bataller, B.G.; Capareda, S.C.; de Luna, M.D.G. Application of artificial neural network in the modeling and optimization of humic acid extraction from municipal solid waste biochar. J. Environ. Chem. Eng. 2017, 5, 4101–4107. [Google Scholar] [CrossRef]
- Akkaya, A.V. Predicting Coal Heating Values Using Proximate Analysis via a Neural Network Approach. Energy Sources Part A-Recovery Util. Environ. Eff. 2013, 35, 253–260. [Google Scholar] [CrossRef]
- Chang, Y.F.; Lin, C.J.; Chyan, J.M.; Chen, I.M.; Chang, J.E. Multiple regression models for the lower heating value of municipal solid waste in Taiwan. J. Environ. Manag. 2007, 85, 891–899. [Google Scholar] [CrossRef]
- Chan, W.P.; Wang, J.-Y. Comprehensive characterisation of sewage sludge for thermochemical conversion processes—Based on Singapore survey. Waste Manag. 2016, 54, 131–142. [Google Scholar] [CrossRef]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An efficient k-means clustering algorithm: Analysis and implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- Pattanayak, S.; Loha, C.; Hauchhum, L.; Sailo, L. Application of MLP-ANN models for estimating the higher heating value of bamboo biomass. Biomass Convers. Biorefinery 2021, 11, 2499–2508. [Google Scholar] [CrossRef]
- Gulec, F.; Pekaslan, D.; Williams, O.; Lester, E. Predictability of higher heating value of biomass feedstocks via proximate and ultimate analyses-A comprehensive study of artificial neural network applications. Fuel 2022, 320, 123944. [Google Scholar] [CrossRef]
- Dashti, A.; Noushabadi, A.S.; Raji, M.; Razmi, A.; Ceylan, S.; Mohammadi, A.H. Estimation of biomass higher heating value (HHV) based on the proximate analysis: Smart modeling and correlation. Fuel 2019, 257, 115931. [Google Scholar] [CrossRef]
- Lee, K.M.; Zanil, M.F.; Chan, K.K.; Chin, Z.P.; Liu, Y.C.; Lim, S. Synergistic ultrasound-assisted organosolv pretreatment of oil palm empty fruit bunches for enhanced enzymatic saccharification: An optimization study using artificial neural networks. Biomass Bioenergy 2020, 139, 105621. [Google Scholar] [CrossRef]
- Parikh, J.; Channiwala, S.A.; Ghosal, G.K. A correlation for calculating HHV from proximate analysis of solid fuels. Fuel 2005, 84, 487–494. [Google Scholar] [CrossRef]
- Channiwala, S.A.; Parikh, P.P. A unified correlation for estimating HHV of solid, liquid and gaseous fuels. Fuel 2002, 81, 1051–1063. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample | Source City | HHV (MJ/kg) | Proximate Analysis | Ultimate Analysis | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mad (%) | Ashd (%) | VMd (%) | FCd 1 (%) | Cdaf (%) | Hdaf (%) | Odaf 1 (%) | Ndaf (%) | Sdaf (%) | |||
| A1 | Xuzhou | 12.794 | 1.50 | 33.81 | 58.07 | 8.12 | 46.50 | 9.49 | 35.40 | 7.46 | 0.37 |
| A2 | Suqian | 5.328 | 2.66 | 61.95 | 29.38 | 8.67 | 36.08 | 9.63 | 37.23 | 11.84 | 0.77 |
| A3 | Suqian | 7.743 | 2.37 | 51.42 | 42.00 | 6.59 | 40.98 | 8.52 | 37.48 | 9.91 | 0.54 |
| A4 | Lianyungang | 12.020 | 2.92 | 36.77 | 55.73 | 7.50 | 45.60 | 10.16 | 34.11 | 7.94 | 0.44 |
| A5 | Lianyungang | 12.260 | 1.37 | 35.89 | 55.76 | 8.34 | 47.89 | 8.23 | 35.16 | 7.57 | 0.37 |
| A6 | Yancheng | 7.416 | 2.49 | 49.53 | 42.56 | 7.91 | 37.71 | 9.65 | 40.15 | 9.48 | 0.50 |
| A7 | Huaian | 7.661 | 2.63 | 49.11 | 42.06 | 8.83 | 35.41 | 10.50 | 41.15 | 9.76 | 0.58 |
| A8 | Huaian | 5.852 | 2.26 | 60.16 | 33.35 | 6.49 | 40.23 | 8.44 | 33.91 | 13.35 | 0.58 |
| B1 | Taizhou | 8.011 | 3.06 | 49.52 | 41.78 | 8.71 | 39.46 | 10.38 | 36.55 | 9.99 | 0.52 |
| B2 | Yangzhou | 8.372 | 1.79 | 45.72 | 45.72 | 8.56 | 40.33 | 9.62 | 39.41 | 8.63 | 0.47 |
| B3 | Zhenjiang | 14.800 | 2.47 | 24.71 | 67.16 | 8.13 | 43.35 | 10.22 | 38.31 | 6.91 | 0.37 |
| B4 | Zhenjiang | 7.155 | 2.72 | 57.67 | 36.29 | 6.04 | 36.83 | 11.57 | 35.89 | 11.23 | 0.66 |
| B5 | Nantong | 9.281 | 2.78 | 47.93 | 43.92 | 8.15 | 45.08 | 9.59 | 32.64 | 9.49 | 0.57 |
| B6 | Nantong | 7.718 | 2.76 | 56.37 | 36.90 | 6.73 | 47.74 | 8.88 | 25.53 | 13.60 | 0.57 |
| C1 | Nanjing | 10.213 | 2.81 | 44.04 | 46.90 | 9.06 | 42.10 | 10.05 | 34.60 | 10.42 | 0.55 |
| C2 | Changzhou | 11.230 | 1.77 | 41.13 | 50.89 | 7.99 | 45.70 | 10.74 | 33.11 | 8.78 | 0.41 |
| C3 | Wuxi | 9.794 | 2.17 | 47.02 | 44.77 | 8.21 | 43.74 | 9.42 | 33.76 | 10.61 | 0.50 |
| C4 | Wuxi | 10.935 | 2.59 | 41.37 | 49.77 | 8.86 | 41.50 | 10.44 | 37.26 | 8.45 | 0.48 |
| C5 | Suzhou | 14.005 | 2.12 | 27.89 | 62.61 | 9.50 | 49.68 | 8.21 | 30.78 | 9.86 | 0.63 |
| C6 | Suzhou | 15.069 | 2.81 | 24.39 | 66.44 | 9.17 | 44.18 | 10.52 | 33.40 | 9.98 | 0.98 |
| Sample | Clustering Categories | Distance | Sample | Clustering Categories | Distance |
|---|---|---|---|---|---|
| A1 | 1 | 4.580 | B2 | 3 | 3.385 |
| C5 | 1 | 6.443 | C3 | 3 | 4.079 |
| A5 | 1 | 7.884 | C1 | 3 | 4.240 |
| A4 | 1 | 8.364 | B1 | 3 | 4.841 |
| C6 | 1 | 8.989 | B5 | 3 | 5.813 |
| B3 | 1 | 9.979 | A3 | 3 | 6.256 |
| A8 | 2 | 2.250 | A6 | 3 | 6.473 |
| B4 | 2 | 5.740 | C4 | 3 | 7.512 |
| A2 | 2 | 8.260 | A7 | 3 | 8.462 |
| B6 | 2 | 11.549 | C2 | 3 | 10.181 |
| Different Sizes of Data | MSE | RMSE | MAD | MAPE | R2 |
|---|---|---|---|---|---|
| Train | 0.161 | 0.401 | 0.319 | 3.260 | 0.979 |
| Test | 0.209 | 0.457 | 0.375 | 4.651 | 0.975 |
| All | 0.198 | 0.444 | 0.385 | 4.081 | 0.975 |
| Input Parameters | Equation | Reference |
|---|---|---|
| Proximate analysis (FC, VM, Ash) | HHV = 353.6FC + 155.9VM − 7.8Ash | Jigisha Parikh et al. [44] |
| HHV = 255.75VM + 283.88FC − 2386.38 | Puchong Thipkhunthod et al. [27] | |
| Ultimate analysis (C, H, O, N, S) | HHV = 430.2C − 186.7H−127.4N + 178.6S + 184.2O − 2379.9 | Puchong Thipkhunthod et al. [27] |
| HHV = 349.1C + 1178.3H + 100.5S − 103.4O − 15.1N − 21.1Ash | S. A. Channiwala et al. [45] |
| Models | MSE | RMSE | MAD | MAPE | R2 |
|---|---|---|---|---|---|
| Jigisha Parikh et al. [44] | 2.262 | 1.504 | 1.188 | 15.546 | 0.722 |
| Puchong Thipkhunthod et al. [27] | 5.161 | 2.272 | 2.198 | 24.574 | 0.365 |
| Puchong Thipkhunthod et al. [27] | 1.588 | 1.178 | 1.104 | 11.862 | 0.797 |
| S. A. Channiwala et al. [45] | 2.591 | 1.610 | 1.531 | 15.743 | 0.688 |
| The BPNN model in this study | 0.198 | 0.444 | 0.385 | 4.081 | 0.975 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Li, H.; Wang, Y.; Qu, L. Predicting Higher Heating Value of Sewage Sludges via Artificial Neural Network Based on Proximate and Ultimate Analyses. Water 2023, 15, 674. https://doi.org/10.3390/w15040674
Yang X, Li H, Wang Y, Qu L. Predicting Higher Heating Value of Sewage Sludges via Artificial Neural Network Based on Proximate and Ultimate Analyses. Water. 2023; 15(4):674. https://doi.org/10.3390/w15040674
Chicago/Turabian StyleYang, Xuanyao, He Li, Yizhuo Wang, and Linyan Qu. 2023. "Predicting Higher Heating Value of Sewage Sludges via Artificial Neural Network Based on Proximate and Ultimate Analyses" Water 15, no. 4: 674. https://doi.org/10.3390/w15040674
APA StyleYang, X., Li, H., Wang, Y., & Qu, L. (2023). Predicting Higher Heating Value of Sewage Sludges via Artificial Neural Network Based on Proximate and Ultimate Analyses. Water, 15(4), 674. https://doi.org/10.3390/w15040674