1. Introduction
Streamflow data are necessary for managing water resources for numerous societal and environmental uses as well as to support research and modeling efforts to address climate change impacts on water availability. While the U.S. Geological Survey (USGS) operates the Nation’s largest streamflow monitoring network [
1], there are significant spatial gaps and stream order biases in monitoring locations [
2,
3,
4]. The water resources community has been advocating for more streamflow monitoring to fill these spatial gaps [
5], though the extent to which streamflow monitoring across the Nation has increased is unknown. This gap in monitoring is partially due to the lack of centralized information about existing streamflow monitoring outside of the USGS [
6]. The USGS has an accurate count of streamflow gaging stations (i.e., gages) in its operational network, and in 2021 the number of gages operated by the USGS was 8215 [
7], which is 273 more gages than the previous peak in 1967. Within the United States Pacific Northwest (PNW: Idaho, Oregon, and Washington), the peak number of gages operated in a single year by the USGS was 816 in 1968 and has declined to 639 in 2021. These opposing trends display the variability of current gage numbers across the Nation. In addition to the national USGS monitoring program, there are discrete streamflow measurement locations and continuous streamflow gaging stations operated by non-USGS organizations. The number of discrete and continuous streamflow monitoring locations operated by these organizations has not been quantified, nor is the water resources community aware of how many non-USGS networks currently exist. Thus, an important approach to increasing the availability of streamflow information is to identify streamflow monitoring data that already exist and evaluate the potential of making these data more findable and accessible.
States, tribes, counties, cities, universities, non-profits, private firms, and other federal agencies operate streamflow gaging stations and collect discrete streamflow data [
8]. These data are distributed across organizations’ websites with varying operability and in disparate offices with limited accessibility (e.g., off-line, isolated digital storage, or paper records). For these reasons, it is currently difficult to identify all current and historical streamflow data that may exist for a given geographic area. This challenge is being addressed with efforts to make streamflow data findable, accessible, interoperable, and reusable (FAIR) [
9,
10], including increasing awareness of the importance of adhering to FAIR data standards [
11]. There are a growing number of repositories in which individuals may upload streamflow data (CUASHI HydroClient, HydroShare, Environmental Data Initiative, and ScienceBase) and various efforts to create mechanisms to find these data once their metadata are available online (Network Linked Data Index, [
12], Geoconnex, [
13]). The remaining challenge is one that is unlikely to be automated via these workflows and community standards. That challenge is to initially find, characterize, and populate streamflow locations, location metadata, and streamflow data. For the PNW, it was uncertain how many of the organizations’ operating networks were either unaware of emerging streamflow data repositories and search mechanisms or were aware but did not have the resources to populate data in these repositories or make their data findable.
Here, we present results of a project to catalog non-USGS streamflow monitoring locations and accompanying metadata from across the PNW and qualitatively describe the challenges associated with making metadata findable, accessible, interoperable, and reusable. For this study, metadata was defined as data describing streamflow locations and associated streamflow data [
14]. Additionally, throughout the cataloging process we identified obstacles that water professionals face regarding streamflow data and metadata management. While the goals of accessible streamflow data extend beyond the PNW, the authors focused on the PNW because it is sufficiently large enough to identify challenges with FAIR data practices, the authors had existing knowledge of the streamflow networks, and the catalog could be accomplished with available resources.
2. Methods
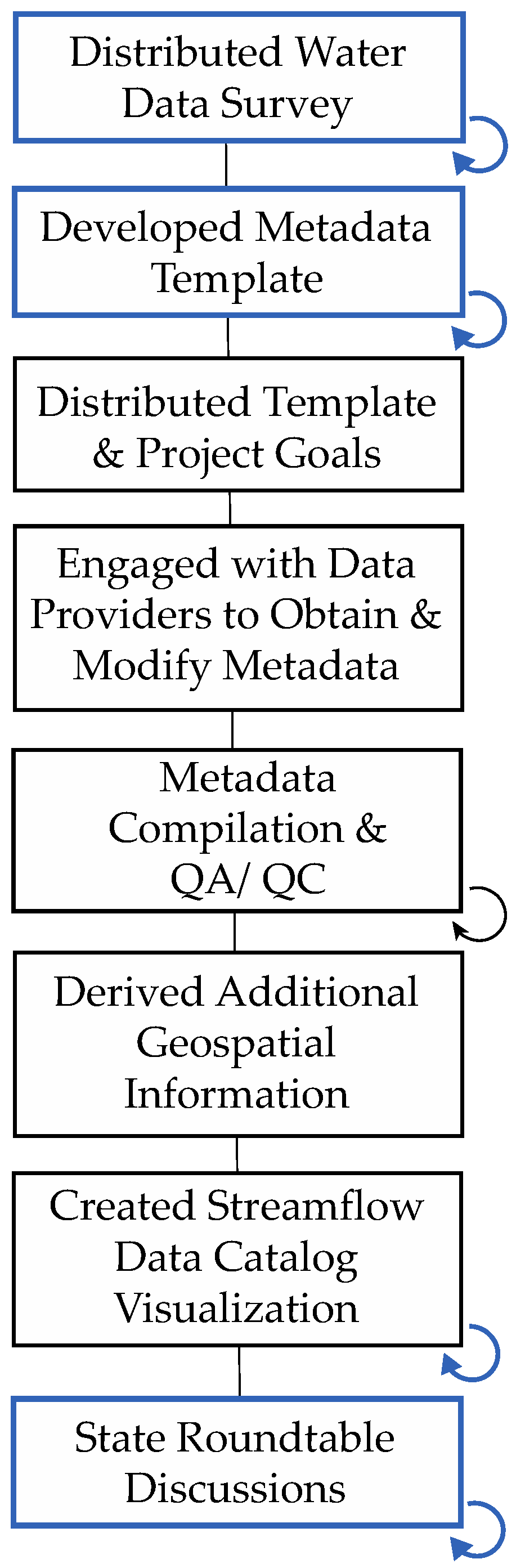
In 2020, a stakeholder advisory board (SAB) was created for this project. It included representatives from 11 organizations across Idaho, Oregon, and Washington that operated streamflow monitoring networks and used streamflow data daily. The SAB initially helped develop a survey to solicit information about organizations’ streamflow monitoring programs and metadata considered necessary to improve FAIR data practices (
Figure 1). The SAB assembled a list of organizations across the PNW that may have collected streamflow information. Authors from Boise State University and the Idaho Policy Institute then distributed the survey along with a description of the Streamflow Data Catalog and its intended purpose. The SAB also developed a set of metadata considered to be the most important information to collect about streamflow monitoring locations (
Table S1).
The metadata template and a description of the goals of the Streamflow Data Catalog were then distributed to the list of organizations via email (
Figure 1). Organizations with small monitoring networks were able to add their data directly to the metadata template, while larger organizations generally sent their metadata in the structure and format that could easily be exported from their data management program. For these datasets, we extracted and reorganized the relevant information to fit into the metadata template. The process of obtaining metadata often required consistent contact with data managers and follow up emails to clarify information. Data were also obtained from various online repositories, such as the Forest Service Research Data Archive (
Table S2).
Data quality assurance and quality control (QA/QC) was an ongoing component of the data compilation effort as new issues were identified. The primary metadata issues were missing or incomplete dates, missing information about status (active/inactive), measurement frequency, and inconsistent naming conventions. Many discrete measurement datasets did not have complete dates, for example, they might have provided month-year or only year. For these measurements, we set the date to either the first of the month or the first of the year and noted this in the notes section of the metadata. Some locations did not have start or end dates, we set these to “unknown” if they were a continuous dataset. While categories were provided for many of the categorical variables, typos and capitalizations resulted in duplicative categories. These duplications were identified, edited, and grouped into appropriate categories. Some organizations provided multiple datasets that they manage. For these datasets an additional label was added in the Streamflow Data Catalog to denote the internal naming convention of the organization’s dataset (e.g., IDWR has a telemetry dataset and daily time series dataset). Given the number of independent irrigation district datasets, the individual district name was set as the “organization dataset” and the “organization” was set as “Irrigation District.” This was done to improve the data visualization.
Once the largest known streamflow monitoring networks had provided information on their streamflow programs, including location data and accompanying metadata, additional geospatial information was derived (county and hydrologic unit codes). The Streamflow Data Catalog visualization was then developed using the provided and derived data. Roundtable discussions were organized for each state to engage with streamflow metadata providers and evaluate the utility of the data visualization and the metadata collected [
15]. Roundtable discussions were modeled after the Aspen Institute Roundtable discussions that were held in California, Texas, the Great Lakes, and the Upper Colorado River Basin from 2017 to 2019 [
16]. Participants (1) described comprehensive and detailed streamflow data uses and requirements for their organizational missions; (2) identified challenges with and opportunities to apply FAIR data practices; (3) shared knowledge of their network operations; and (4) provided feedback on features of the Streamflow Data Catalog.
3. Results
This effort has produced the largest inter-organizational dataset of streamflow monitoring metadata in the PNW and an interactive data visualization to archive and access the metadata (
Table S1,
Figure 2). The metadata represent 33,267 non-USGS streamflow monitoring locations across 32 organizations (
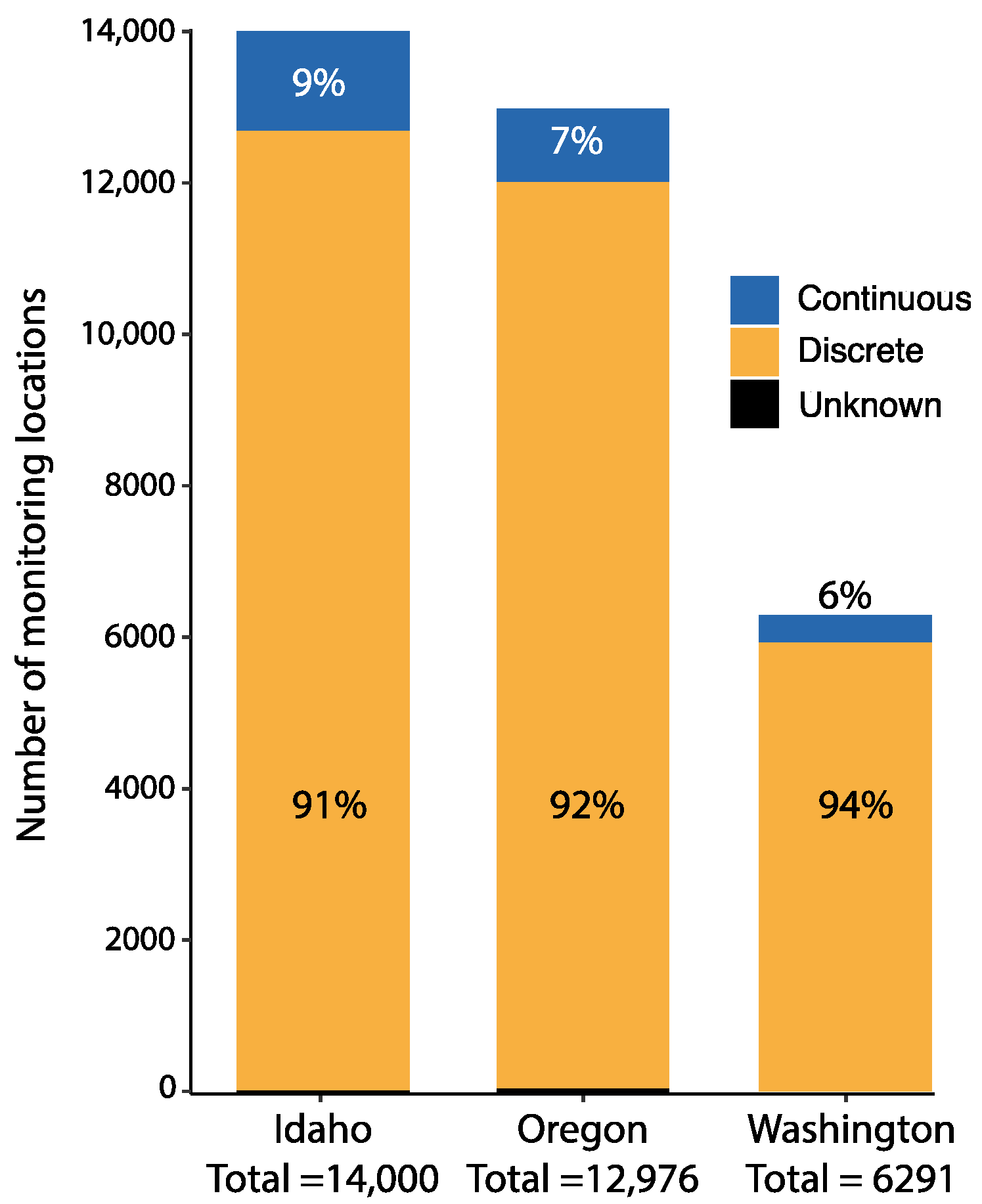
Table S2) with data from 112 of 142 counties (79%) and 206 of 234 HUC8 watersheds (88%). There are 2661 known continuous monitoring locations, 30,557 discrete measurement locations, and 49 locations with an unknown measurement interval (
Figure 3,
Table 1). Of the continuous streamflow monitoring locations, 588 (22%) are currently active and 41% do not have end dates, indicating potentially more sites in the catalog that are active (
Figure 4,
Table 2). Idaho has a significant number of monitoring locations in irrigation canals that are monitored by water managers. These data are self-reported and make up most of the continuous monitoring locations that have unknown monitoring frequency or unknown status (
Figure 3 and
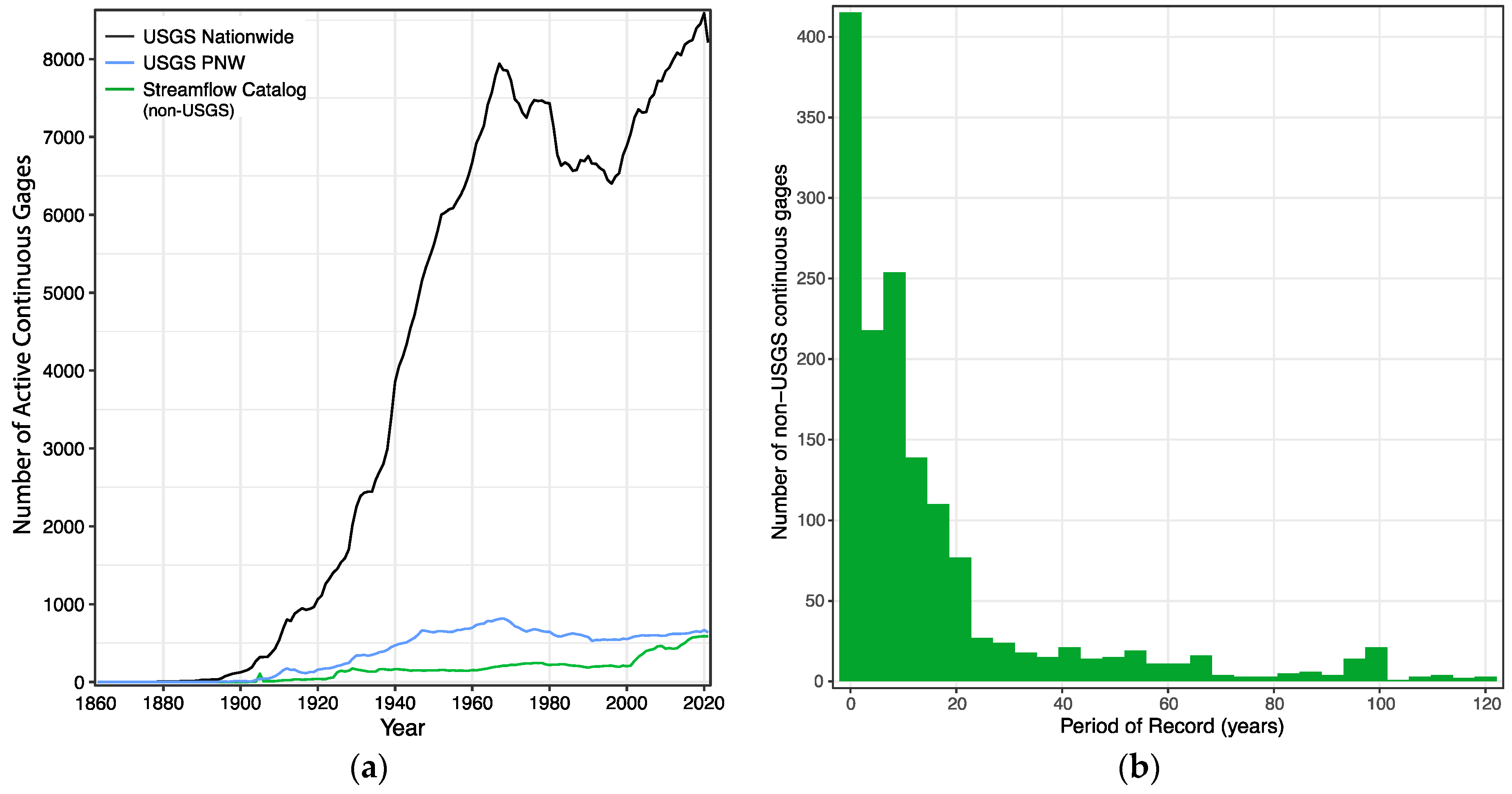
Figure 4). In 2021, there were a nearly equal number of non-USGS continuous streamflow monitoring locations compared to USGS streamflow monitoring locations in the PNW. Most of the non-USGS locations have fewer than 20 years of data and 139 locations with more than 50 years of data (
Figure 5). While this is the largest collection of metadata in the region, critical gaps in the dataset remain. For example, 48% of the continuous monitoring locations do not have information about measurement interval (
Figure 3), and 55% do not denote the stream characterization (
Figure 6). Of the continuous data, only about 50% can be accessed online by way of weblinks for this project. Organizations providing online access included state agencies, private hydro power, and a few cities, counties, research watersheds, and watershed councils/associations (
Table S1).
The streamflow monitoring networks varied in size, with the state organizations providing the largest continuous monitoring networks, and both federal and state organizations provided the largest number of discrete monitoring locations. The U.S. Forest Service (USFS) has by far the largest collection of discrete streamflow measurements (17,787), which at this point still does not include all the USFS streamflow information in the PNW, followed by the Idaho Department of Environmental Quality Beneficial Use Reconnaissance Project (12,671) [
17]. The Oregon and Washington Departments of Fish and Wildlife had the next largest set of discrete measurements (69 and 37 respectively) in the Streamflow Data Catalog.
4. Discussion
The need for additional and standardized streamflow data to support water resources management has been suggested by many organizations [
5,
18], though the authors are unaware of evaluations of the number of non-centralized streamflow monitoring locations prior to this study. Metadata assembled in the Streamflow Data Catalog show an increase in the number of non-USGS streamflow monitoring locations within the PNW in the last twenty years (
Figure 5a). By engaging stakeholders across the PNW, this project compiled streamflow monitoring location metadata for 30,557 locations from 32 organizations (
Table 1 and
Table S1). The resulting interactive metadata visualization allows users to easily identify potential sources of data for a given area of interest (
Figure 2). While this effort captured data from many organizations, including those operating the largest known networks, we know there are additional streamflow data collected by other organizations (e.g., consulting firms and irrigation districts) not represented in this catalog. The Streamflow Data Catalog and feedback generated during the roundtable discussions can inform future data integration efforts and demonstrate the value of aggregating observational data. The Streamflow Data Catalog showcases the significant amount of existing data sources available to integrate into the next generation of advanced databases and web crawlers and be used to provide additional clarity on data gaps and priority locations for new monitoring efforts within the PNW.
A critical component of this work was bringing water resources professionals together to discuss the challenges of operating streamflow monitoring networks, collecting discrete measurements, and managing associated metadata [
15]. While the organizations operating networks differ, there are many commonalities in the challenges they face including finding open-source metadata standards specific to streamflow data, training on how to collect streamflow data to increase interoperability and reusability, and resource capacity to perform multi-step quality assurance. The attendees reported learning about additional educational tools and funding opportunities from the roundtable discussions. Providing forums like these are important for sharing information that can improve FAIR data within the water resources communities because of the gap that remains between understanding the importance of FAIR data and implementing FAIR data practices [
19,
20]. The 2022 National Water Use Data Workshop identified similar challenges across the country as well as structural limitations regarding legislation or laws that impede sharing data, the impacts of centralized state-wide information technology systems, and data privacy issues [
19].
The findability of streamflow data will remain a significant challenge as many organizations do not have the resources to provide data online. The streamflow data survey was used to help identify organizations that had streamflow data, but as with many surveys, the response rate was relatively low [
15]. The most challenging part of this endeavor was finding the right offices and individuals within organizations to solicit streamflow metadata and transferring the metadata from those offices to the catalog. Personal communications and meetings were often the only way to obtain the information needed to add monitoring locations and associated metadata to the catalog. For example, while many of the state agencies operating large networks have online databases, shapefiles of their monitoring locations with pertinent metadata did not exist. This required staff to extract the relevant information from their data management systems (e.g., WISKY, AQUARIUS, and MS Excel; any use of trade, firm, or product names is for descriptive purposes only and does not imply endorsement by the U.S. Government) with subsequent manual and time-intensive formatting and editing.
USGS Water Mission Area and the Internet of Water (IoW) are working toward increasing findability of streamflow data [
21]. They have developed the Network Linked Data Index (NLDI) and Geoconnex, which are mechanisms to facilitate finding streamflow data. The NLDI indexes data to the National Hydrography Dataset (NHDPlus V2) [
12,
22], and Geoconnex is a registry system that creates a unique identifier that is linked to the URL that hosts the original data [
13]. The utility of these tools is that once a measurement location has a permanent landing page, the Geoconnex web crawler can harvest links between hydrologic features and the associated data. Full utility of these tools will require organizations that collect continuous datasets to create webpages measurement locations and will decrease the effort needed to maintain a centralized database. As these groups and others (e.g., Water Data Exchange Program (WADE) [
23] and Consortium of Universities for the Advancement of Hydrological Sciences, [CUASHI]) continue to collaboratively work toward open-source data management tools, the scaffolding for interoperable streamflow data will emerge and build on the successes of similar efforts like the Water Quality Portal and the Community Collaborative Rain, Hail, and Snow Network (CoCoRaHS) [
24].
The ultimate success of these search engines requires data to be online, which is not the case for at least 60% of the network data identified within the catalog. The attendees identified a range of organizational abilities and capacities to consolidate streamflow data and metadata into communicable formats and into accessible platforms. Organizations operating smaller networks or collecting a smaller number of discrete measurements were less likely to prioritize these efforts or have the necessary resources to accomplish these tasks. While these organizations may want to make their data findable and available, external resources will be necessary to achieve this outcome. The attendees identified the need for no/low-cost tools for data formatting and metadata description to assure data are easily transferred to online repositories.
While multiple organizations provided geographic metadata for their continuous and discrete streamflow gaging locations, other important types of metadata were missing. Some of these metadata were accessible on organizational websites or internal databases but were not provided directly, so the authors obtained this information from online or other organizational records. Of the metadata entries in this catalog, 94% included the complete dataset including start and end dates, 100% included latitude and longitude, 53% included measurement intervals, and only 8% of metadata included information about instrumentation. Basic stream characterization (e.g., “natural”, “canal”, etc.) was only included in 45% of the metadata associated with the continuous gages. Knowing measurement instrumentation and intervals (
Figure 5a) are critical to understanding the usability of the data, and while the individual organizations likely recorded this information, it is not regularly integrated into their existing data structures or easily obtained from their data management systems. None of the organizations provided geospatial accuracy metadata for the sites or methods used to determine geolocations. Very few of the data providers included information about their streamflow measurement techniques. Several organizations operating the largest networks provide data collection protocols through their online data portals [
25]. Characterizing which metadata were easily obtained, or lacking, highlights the information that will be readily available and also highlights those metadata which the water resources community may need to provide assistance if it is to be obtainable in the future.
Interoperability and reusability of streamflow data are primary objectives for the data identified within the Streamflow Data Catalog. Creating and implementing controlled vocabularies when sourcing information from many organizations could substantially improve automated interoperability. For example, many stream type categories were provided (e.g., “constructed channel”, “canal”, “diversion”, and “weir”) that later were grouped into a smaller set of stream types (
Figure 5b). These vocabularies are well defined in the CUASHI HydroClient (
http://his.cuahsi.org/mastercvreg/cv11.aspx (accessed on 19 January 2023)) [
26], a subset of which could be included with metadata templates to increase efficiencies and provide some initial standardization. Relational databases, such as CUASHIs HydroClient, can facilitate data interoperability [
27], yet the effort to contribute data to these repositories can be a limiting factor for an organization that is staff and/or resource limited [
15,
19].
Reproducibility of data collection and quality assurance methods, which can improve confidence in reusability, is considered a more challenging task given that streamflow is a calculated value from multiple parameters that can themselves be measured using varying techniques and procedures. Metadata about streamflow measurement methods are important for characterizing uncertainty [
28,
29] and confirming the applicability of data for its intended purpose. Methods for data collection were reported for only 8% of the continuously monitored gage locations. About 35% of responding organizations used a provisional QA/QC method, meaning data were checked when downloaded but not reviewed or analyzed for errors, and only 13% of the organizations audit their data on an annual basis [
8]. Training and education on both streamflow measurement methods and QA/QC processes were identified as important for improving reproducibility within the streamflow monitoring community, especially as they relate to preferred techniques for small versus large order streams. Creation of open-source QA/QC tools could be particularly beneficial for small organizations and could be a mechanism to incentivize data contributions to online platforms.
The challenges we will continue to face as we seek to integrate streamflow data are (1) obtaining additional data from known and unknown networks, (2) addressing incomplete metadata, (3) obtaining sustained resources for data management, and (4) developing streamlined processes and tools for organizations to update their network metadata. The water resources community can help address these challenges in many ways. First, individuals and organizations can ensure that streamflow metadata are complete for each location and supporting organizations can coordinate common metadata templates (see
metadata template, Table S1). The primary weakness of the Streamflow Data Catalog is that it is incomplete, both in total number and location of measurements and associated metadata for each location. Small organizations may be the most challenging groups to gather metadata from as they are limited in their capacity to compile information if it is not already centralized. Support for, and adoption of, available and emerging data management strategies and workflows will improve organizational capacity to maintain complete metadata [
30]. Supporting organizations can support community education and outreach around data management standards (e.g., Internet of Water Coalition). Secondly, matching the funding for data management with funding for additional monitoring efforts would likely improve overall data fidelity for the entire network. Keeping information sourced from many organizations current will be a significant challenge given the time required to gather and QA/QC the data provided. This is not an insurmountable task given the many examples of data compilation efforts, such as the Water Quality Portal [
31], which provides an example of how data providers maintaining ownership can distribute the effort of data maintenance, and the NorWest stream temperature database, which compiled data from over 100 agencies in the western United States [
32]. Identifying mechanisms to continue ongoing efforts to centralize streamflow data and improve associated metadata and data management workflows will have valuable and widespread impacts on water resources research and management.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}