1. Introduction
Runoff simulation and prediction is a fundamental problem in water resource allocation, management and planning. Accurate and reliable runoff simulation and prediction are significant for water management in irrigated paddy areas and agricultural non-point-source pollution prevention and control. However, the runoff formation process is relatively complex and can be influenced by many factors, such as rainfall and topography, which gives the runoff series the characteristics of nonlinearity and nonstationarity [
1]. The runoff yield and concentration of irrigated paddy areas are affected by human activities, especially by agricultural management measures. In addition, there are also few stations and incomplete data in irrigated paddy areas, making runoff simulation and prediction in agricultural irrigated areas more difficult to realize.
At present, process-driven models (conceptual and physically based) and data-driven models (statistical-science-based) have made certain progress in the field of runoff simulation and prediction. Ajmal [
2] conceptualized a CN-based ensembled approach by amending the previously suggested formulation for enhanced watershed runoff prediction. Kim [
3] found rainfall spatial distribution has a significant effect on accurate runoff prediction under midsize real field conditions. Among them, the distributed hydrological model that can describe the temporal and spatial change process of the water cycle has been widely used in the simulation of runoff yield and concentration in worldwide basins since it was proposed. However, most traditional hydrological models are developed based on natural basins, which are unsuitable for irrigated paddy areas with intense human activities [
4]. Moreover, constructing a relative integrity process-driven model requires a large amount of input data, such as climate, topography, land use, etc. The computational complexity and parameters of uncertainty present the hydrological models with a significant challenge in practical applications [
5].
With the improvement of computational power and data availability, the development of data-driven models has become more appealing. Artificial Intelligence algorithms have been extensively used in recent years in the development of hydrological prediction models [
6,
7]. Demirel et al. [
8] found that an Artificial Neural Network (ANN) model could predict peak discharge more efficiently than the soil and water assessment tool (SWAT) model. Additionally, the data-driven model requires only a few time series, which directly excavates the complex relationship between the predicted object and the observed data through the black box model, reducing the difficulty of hydrological simulation and prediction in data-deficient areas [
9]. At present, data-driven models are mainly divided into two categories. One is the traditional single-variation model based on the law of runoff series itself [
10]. The other is multivariations models of regression analysis and machine learning through excavating the potential laws of hydrological and meteorological data and considering hydrological, meteorological and other multivariate variables as predictors. The latter has more knowledge of the physical mechanisms due to consideration of the meteorological factors, and it could fully capture the complex correlation characteristics between time series to obtain relatively high accuracy.
Furthermore, in recent years, in order to improve the prediction accuracy of ML algorithms, research has been directed toward the development of deep learning models (e.g., one-dimensional Convolutional Neural Networks and Long Short-Term Memory networks [
11,
12]) and ensemble or hybrid models [
13,
14]. Fu et al. [
15] proposed a LSTM-based deep learning model to simulate streamflow in the Kelantan River, Malaysia. They found that the LSTM-based model showed high accuracy both in the prediction of smooth streamflow in the dry season and rapidly fluctuant streamflow in the rainy season, outperforming traditional neural networks. Kidoo et al. [
16] created a multivariations input GRU model for the accurate prediction of water level by selecting meteorological data related to water level height at Hangang Bridge Station. Recent research has tried to propose some hybrid models to improve the accuracy and generalization of a model, such as LSTM-ALO [
17], LSTM-GA [
18], LSTM-INFO [
19] and so on.
However, the drawback of data-driven models is overfitting, in which noise within the data negatively impacts the predictive performance of the model due to the lack of understanding of physical hydrological processes when handling new data [
20]. Moreover, the decomposition method has shown that through the decomposition process, each subsequence of the original signal can reveal the signal’s distinct intrinsic features and obtain more features for the predicted signals. The empirical mode decomposition (EMD) technique has widely been used for decomposing original signals into their intrinsic multiscale features [
21]. Tan [
22] and Elias [
23] each proposed a prediction model combining the EEMD method and the ML algorithms. They decomposed the runoff signal or water quality parameter datasets into more regular subseries and used them as input data for the model, which effectively improved the model prediction accuracy. Zhang et al. [
24] proposed a depth prediction method of nonstationary time series based on multivariate decomposition to solve the prediction problem of multivariate, nonlinear complex time series and multiple factors affecting photovoltaic power generation. Ikram et al. [
19] found that optimization algorithms can be utilized to model other hydrological variables. They can also be used with decomposition techniques to capture noise in data to improve the further prediction accuracy of the models.
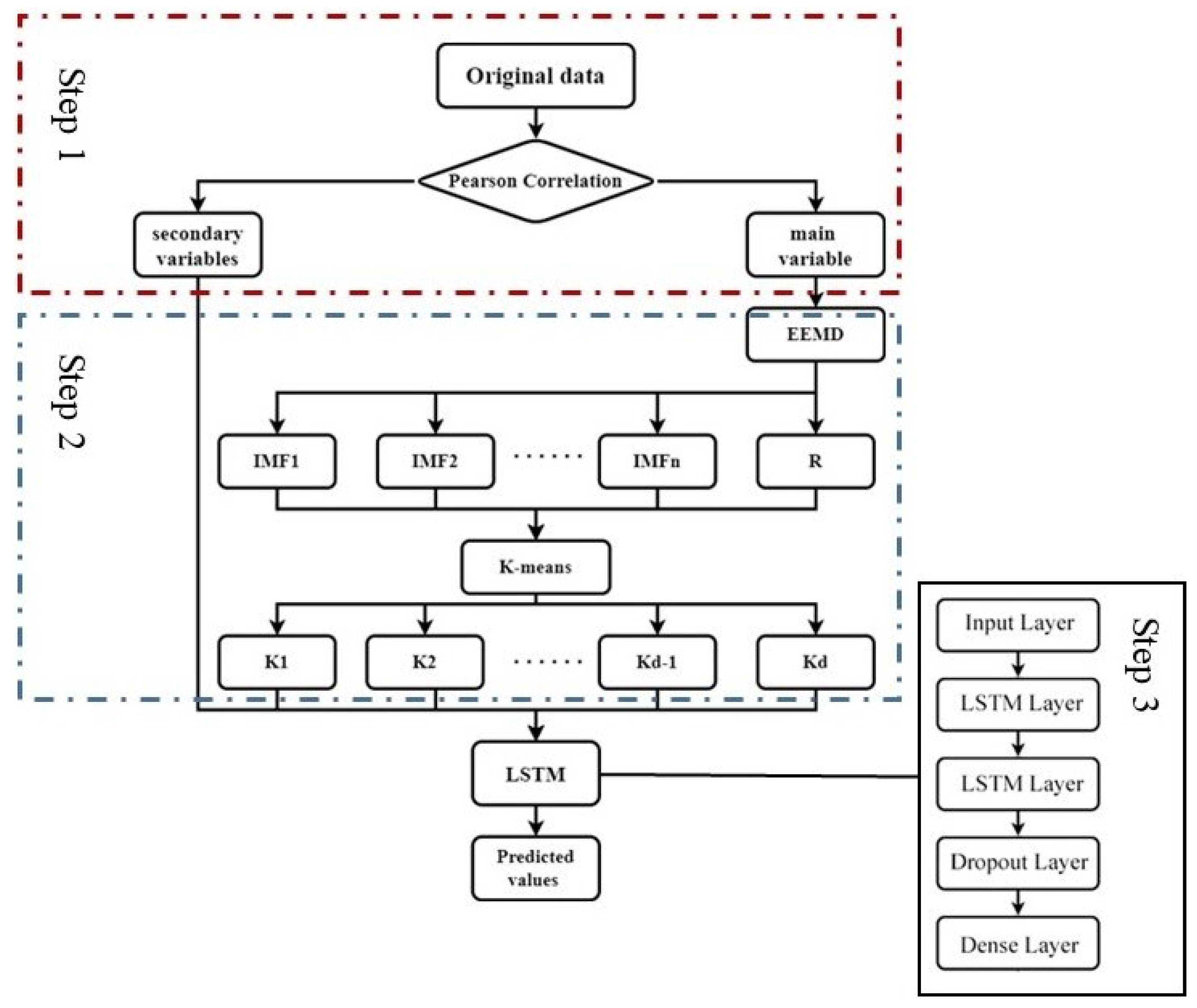
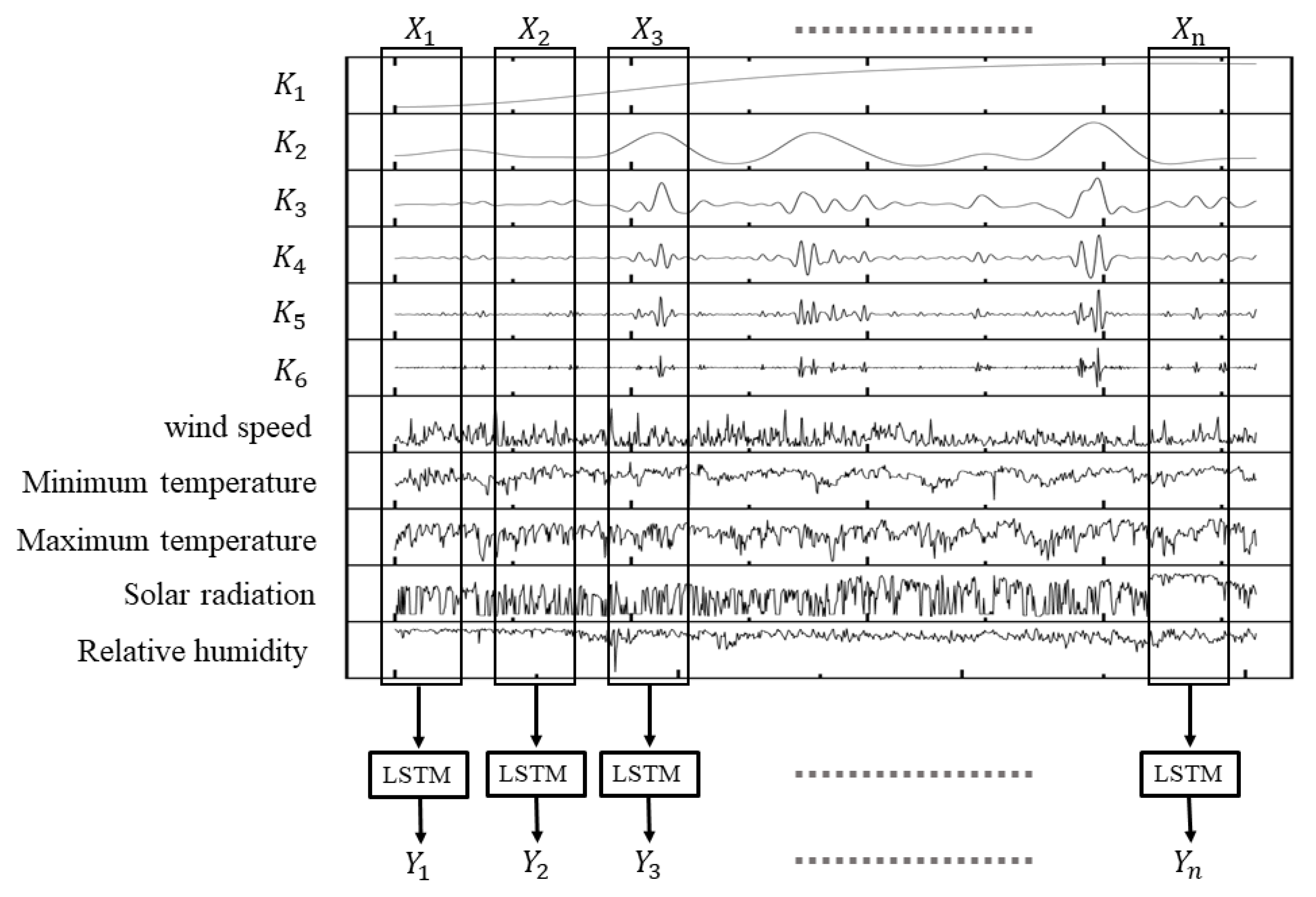
It can be seen that, currently, there are few types of research about the combination of the decomposition method with multivariations models considering meteorological factors. Additionally, the current related research is mainly focused on natural watersheds. Additional study needs to verify whether such models can be applied to the irrigated paddy areas with limited data and that are severely affected by human activities. Therefore, this paper proposes a runoff prediction model based on EEMD and LSTM in an attempt to enhance existing prediction models. Firstly, we attempt to reconstruct the meteorological data by using three methods (Pearson correlation coefficient method, EEMD and K-means). Secondly, we attempt to use the meteorological data as multivariate input to the model to predict runoff in irrigated paddy areas. This study can give a better solution for daily runoff prediction in irrigated paddy areas with limited data and provide decision-making support for the efficient utilization and management of water resources in irrigated paddy areas by a runoff simulation and prediction method with higher accuracy.
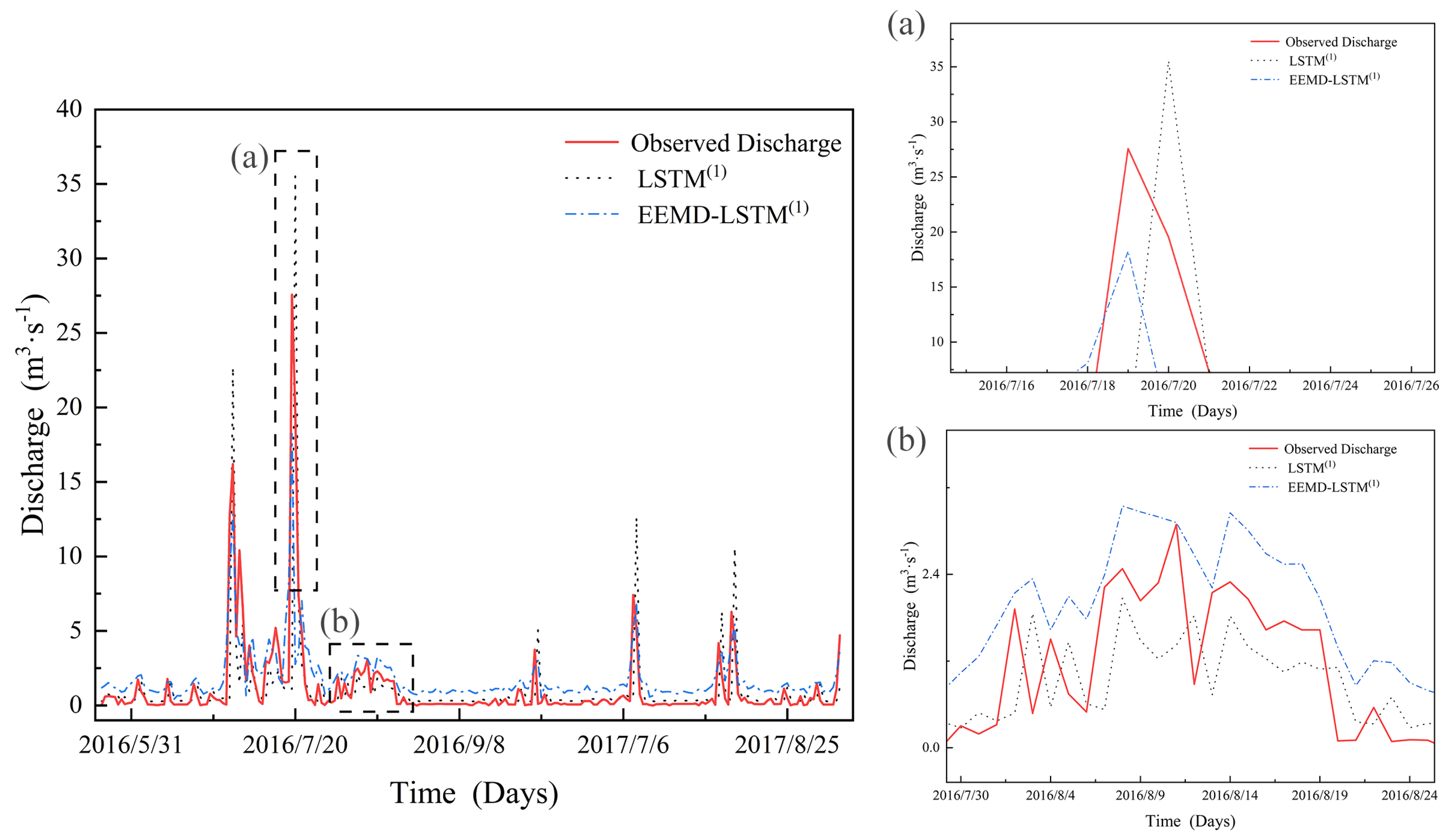
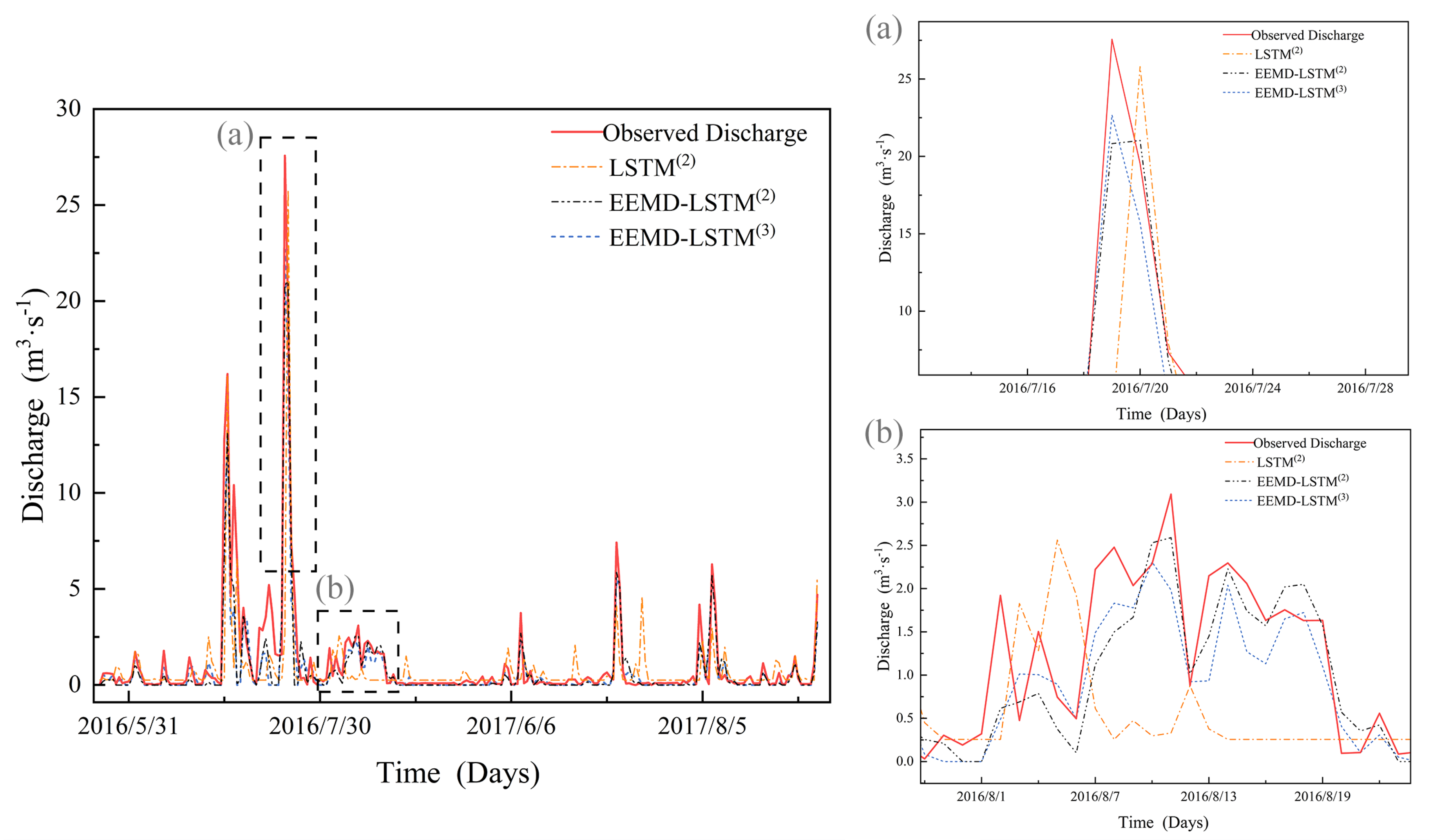
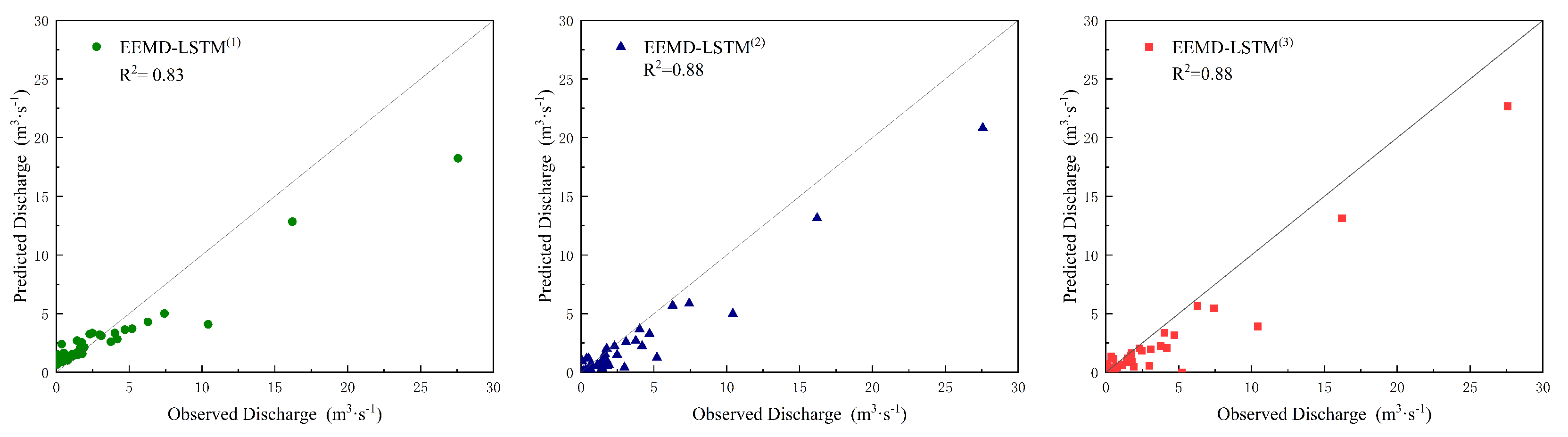
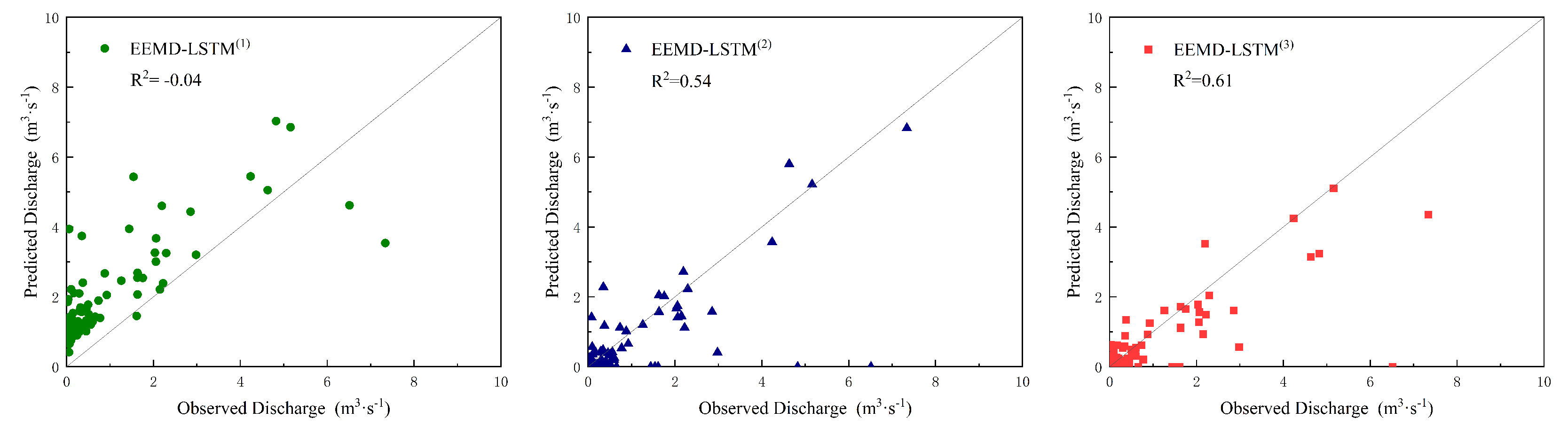
5. Discussion
A clear understanding of the future state of any runoff, through accurate predictive modeling, is critical to the efficient utilization and management of water resources in irrigated paddy areas, which is also a critical element for sustainable water use and improved agricultural practices, or making a risk assessment [
34] to reduce the potential risk of flooding [
35]. These tasks have largely been accomplished through significant research aiming to develop statistical, physical, and more recently, dependable deep learning predictive methods to help policymakers in their day-to-day decision making. The current research integrates a predictive method (i.e., LSTM and GRU models) with a data analysis algorithm (i.e., EEMD and Variational Mode Decomposition, VMD) for improved performance accuracy. A comparison of the efficiency of the new hybrid EEMD-LSTM prediction model was performed against other similar hybrid models, such as the conventional LSTM model and EEMD-LSTM single-variation models. The result indicates a higher prediction accuracy of our proposed model. The performance gain is due to the application of the EEMD algorithm by our proposed novel hybrid EEMD-LSTM prediction model to effectively perform the decomposition of the original signals to obtain its constituent separate essential subsequences. The study was capable of predicting runoff to an acceptable degree of testing accuracy. The results achieved demonstrate that the EEMD algorithm is a strong data analysis tool that can identify the significant features within predictor variables, which is required to model the hydrological state of a river system. This notion is consistent with the quality of the hydrological datasets that could potentially influence the predictive merits of any hydrological model [
35].
In this study, it was noted that the incorporation of meteorological data derived improved hybrid deep learning approaches developed for runoff prediction, and this performance was better than the conventional machine learning models. The performance of the models in this study also concurs with that of previous research. Madonia [
15] proposed a multivariate and multistage medium- and long-term streamflow prediction model that achieved good application (the
= 19.249 and
= 0.985) in the Swat River Watershed, Pakistan. Ahmed [
36] aggregates the significant antecedent lag memory of climate mode indices, rainfall and the monthly factor based on the periodicity as the predictor variables to attain significantly accurate stream water level forecasts with relatively low relative errors (
= 0.882%).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}