

Deep Learning Approaches for Numerical Modeling and Historical Reconstruction of Water Quality Parameters in Lower Seine


Abstract
:1. Introduction
2. Material and Methods
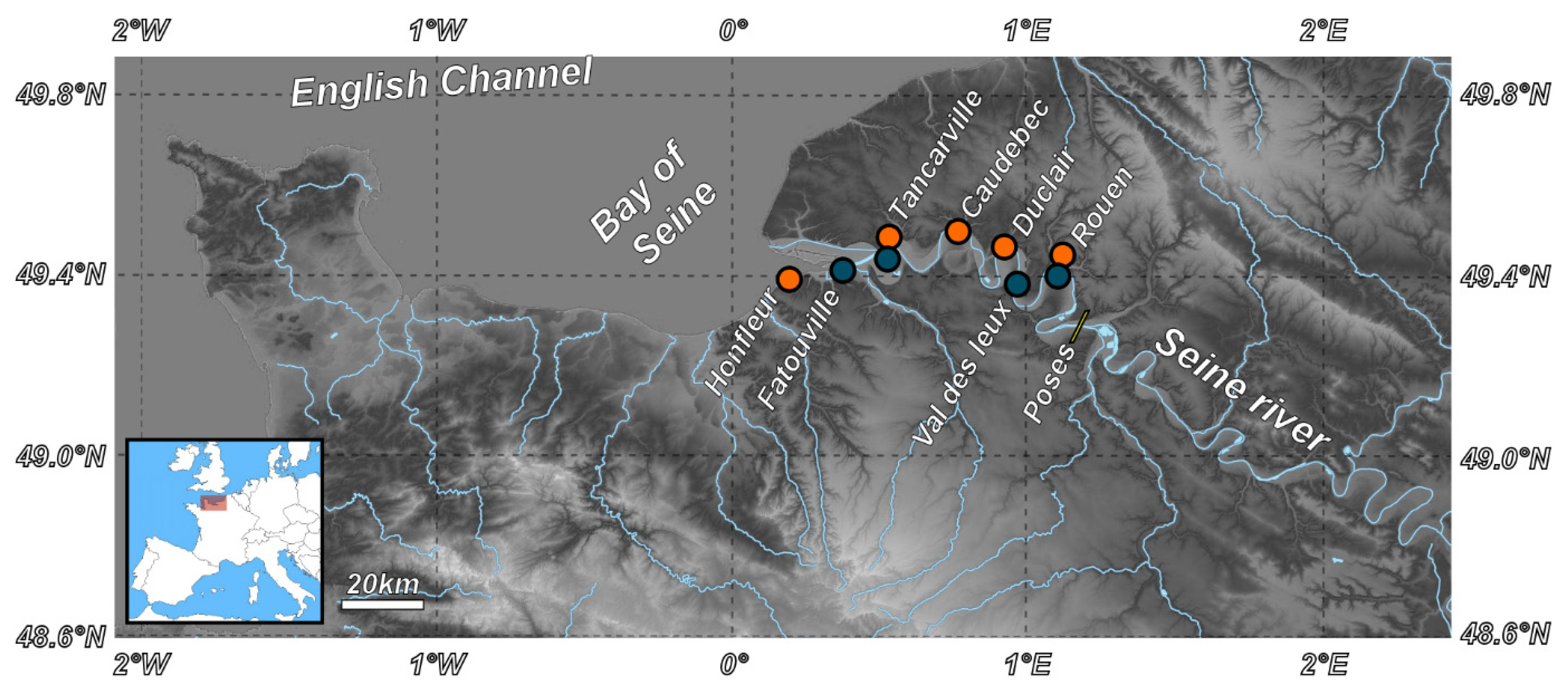
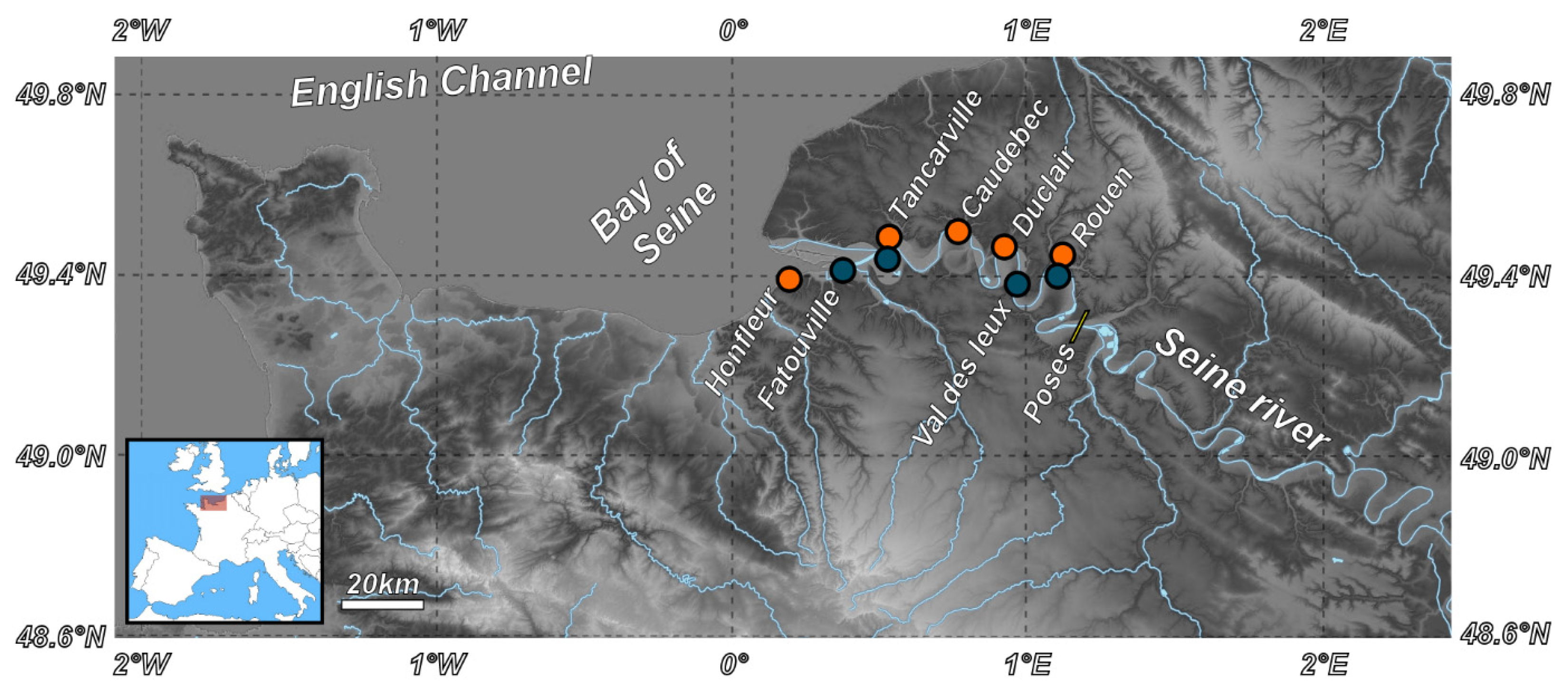
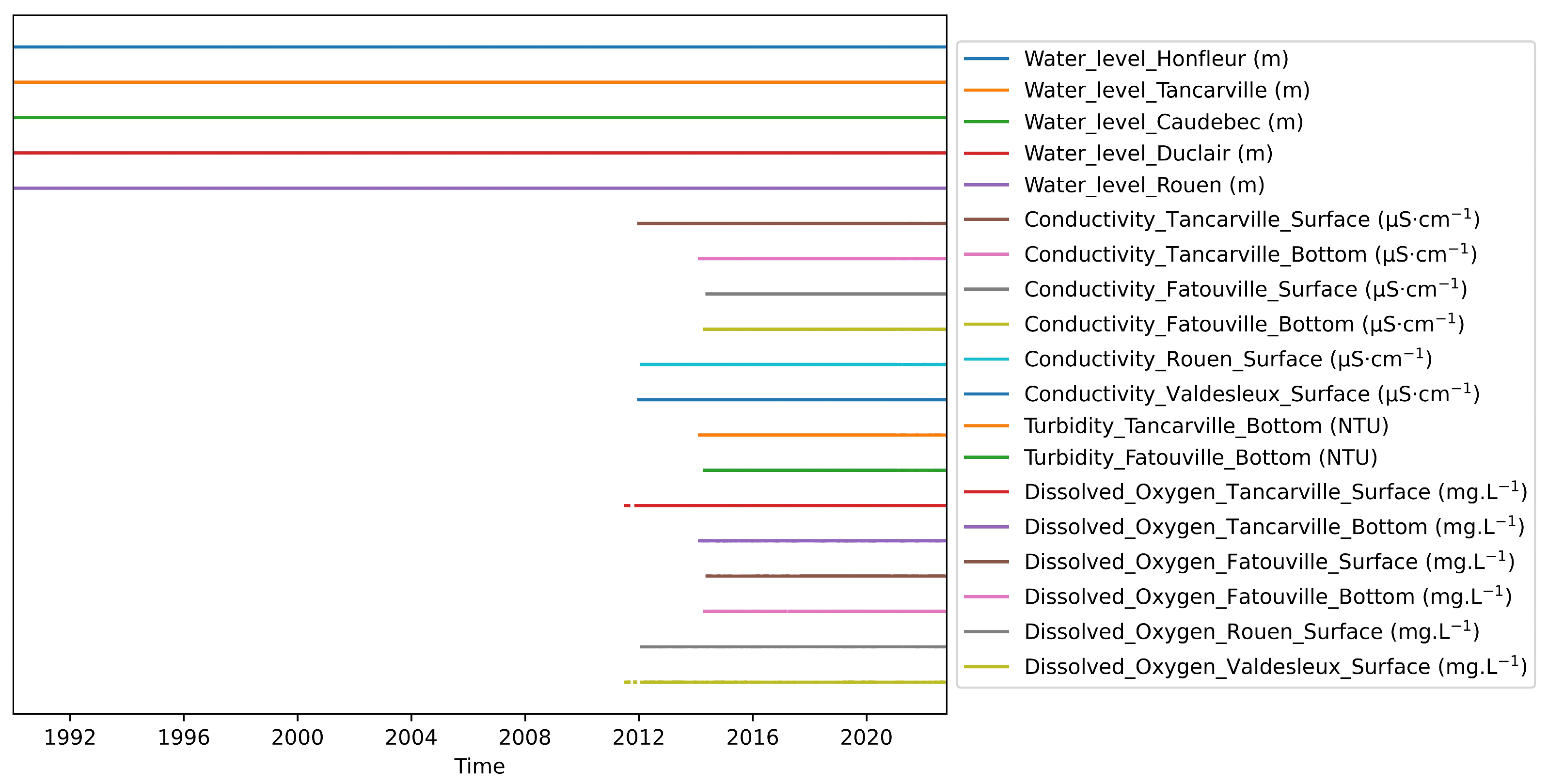
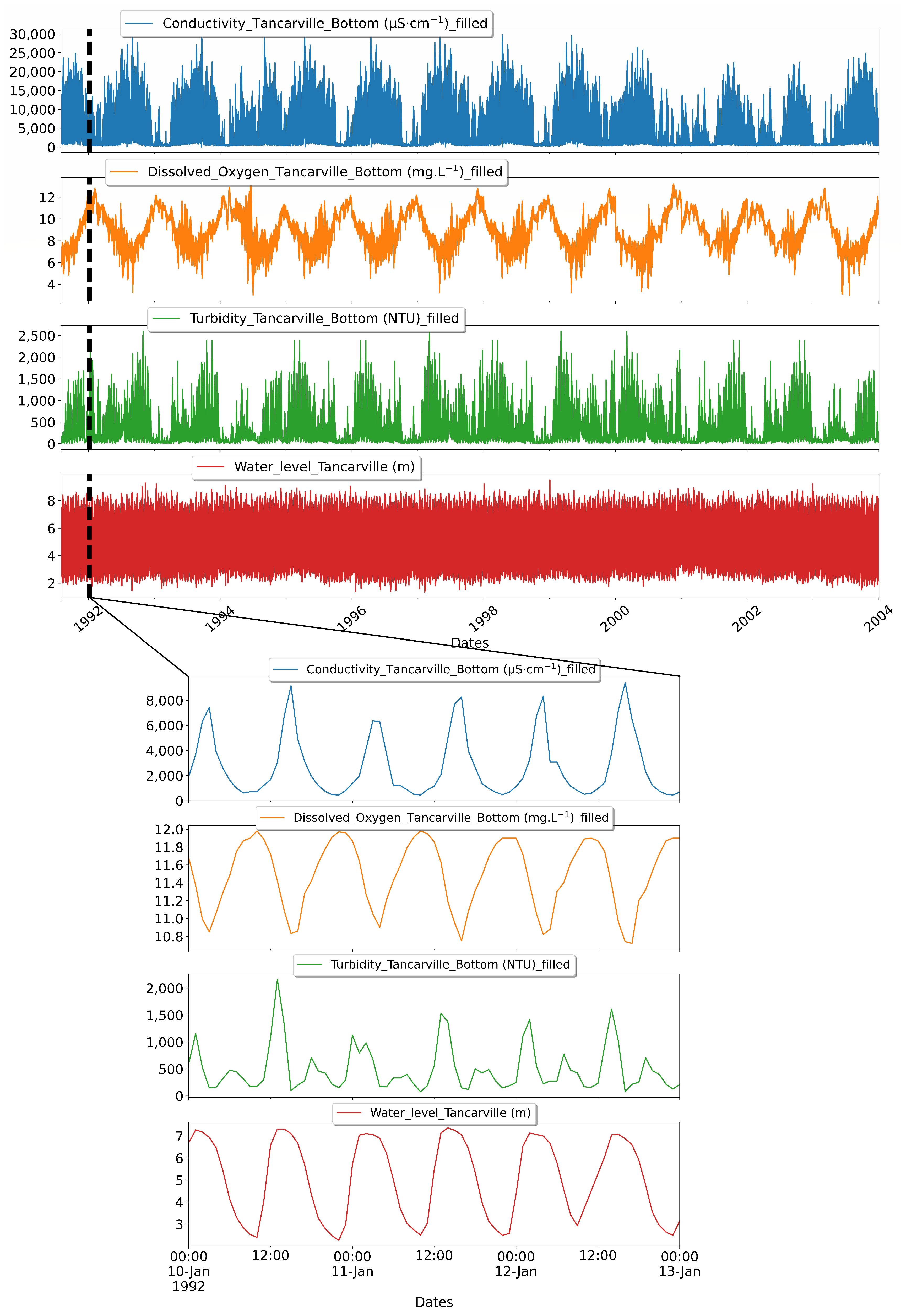
2.1. Study Area and Data Acquisition
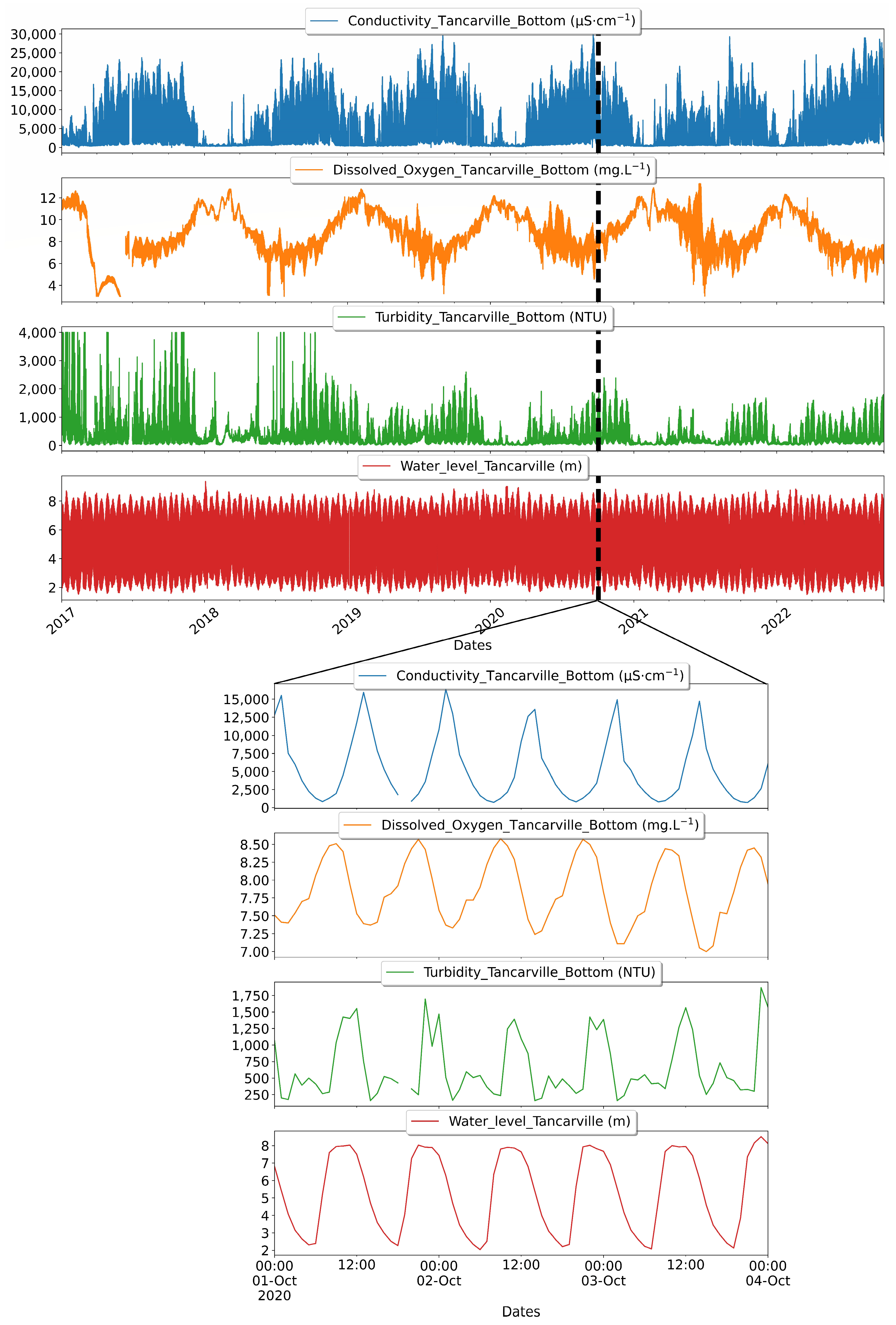
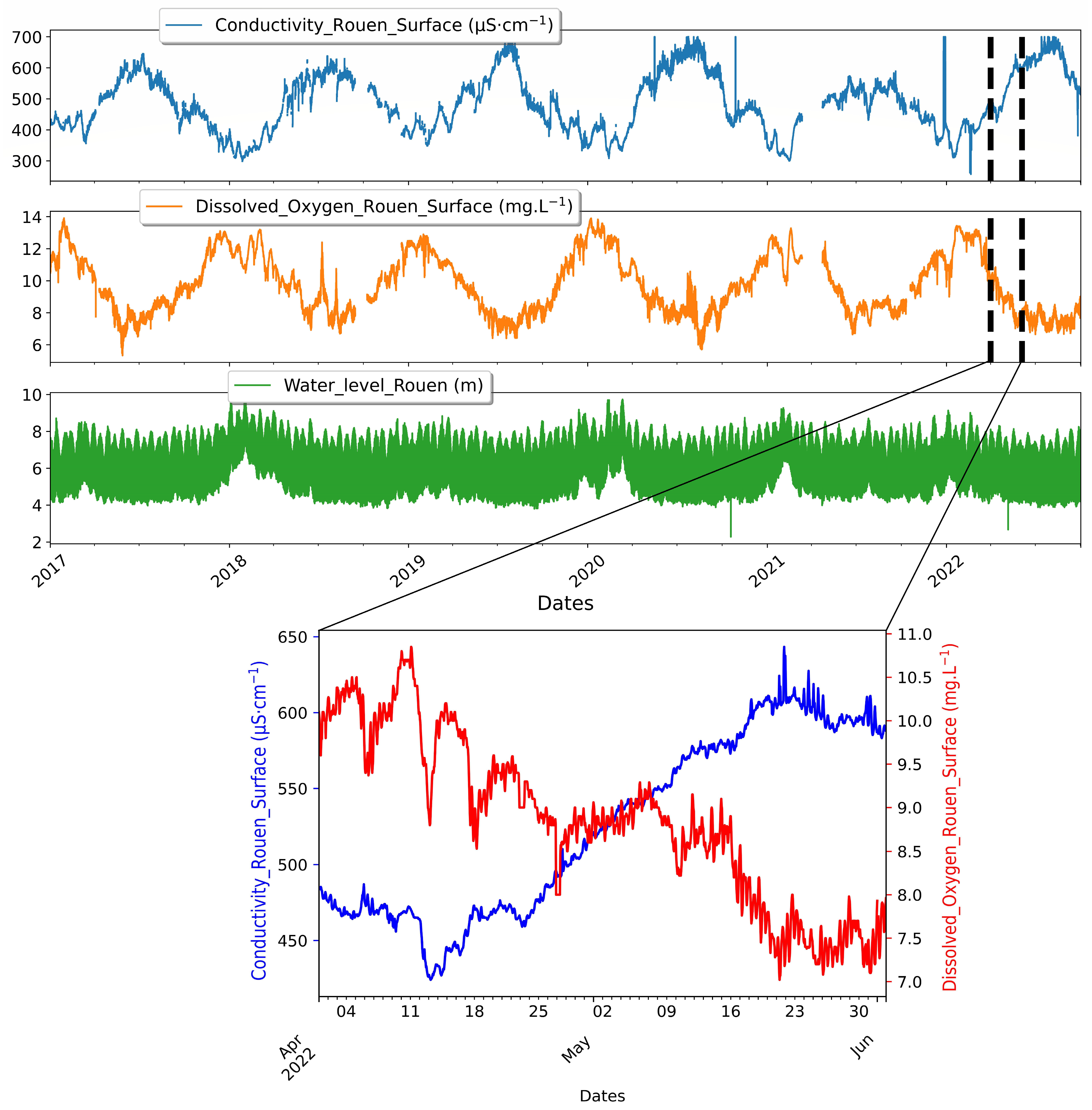
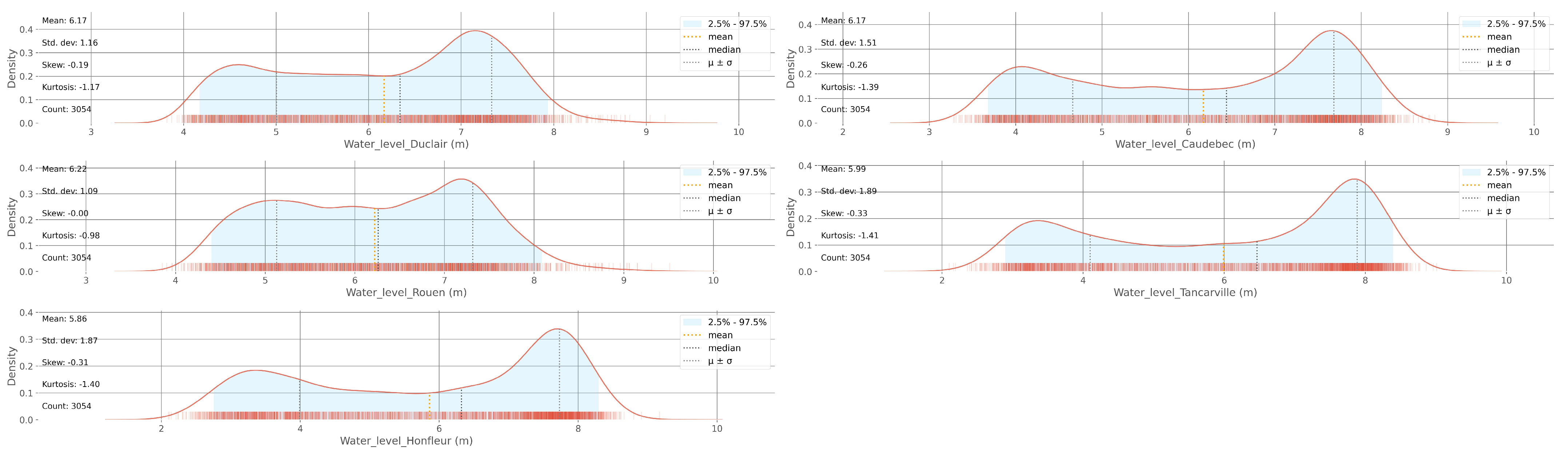
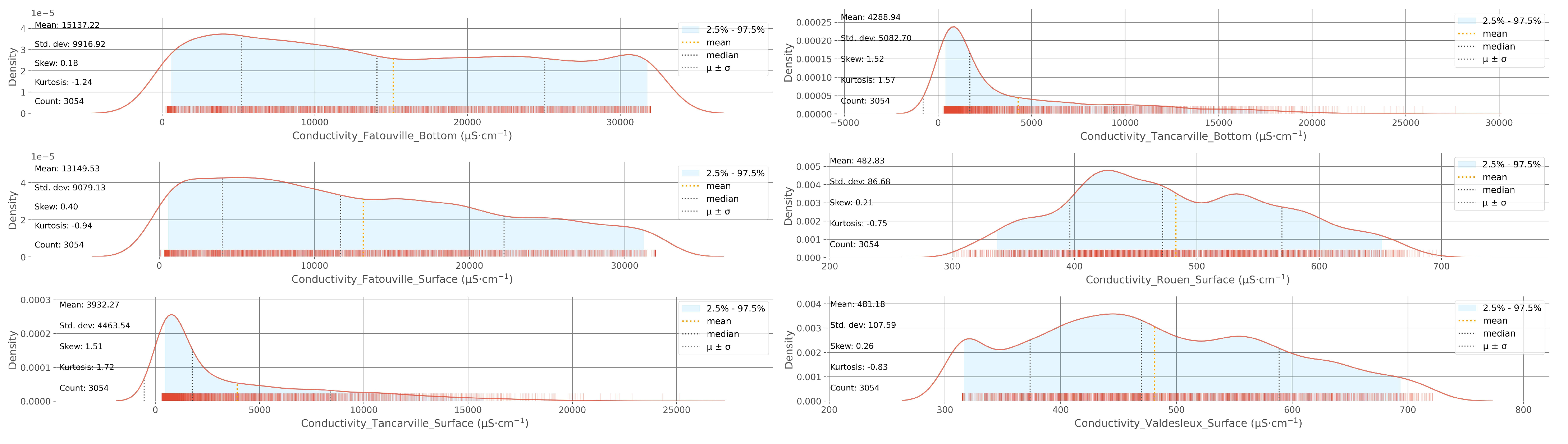
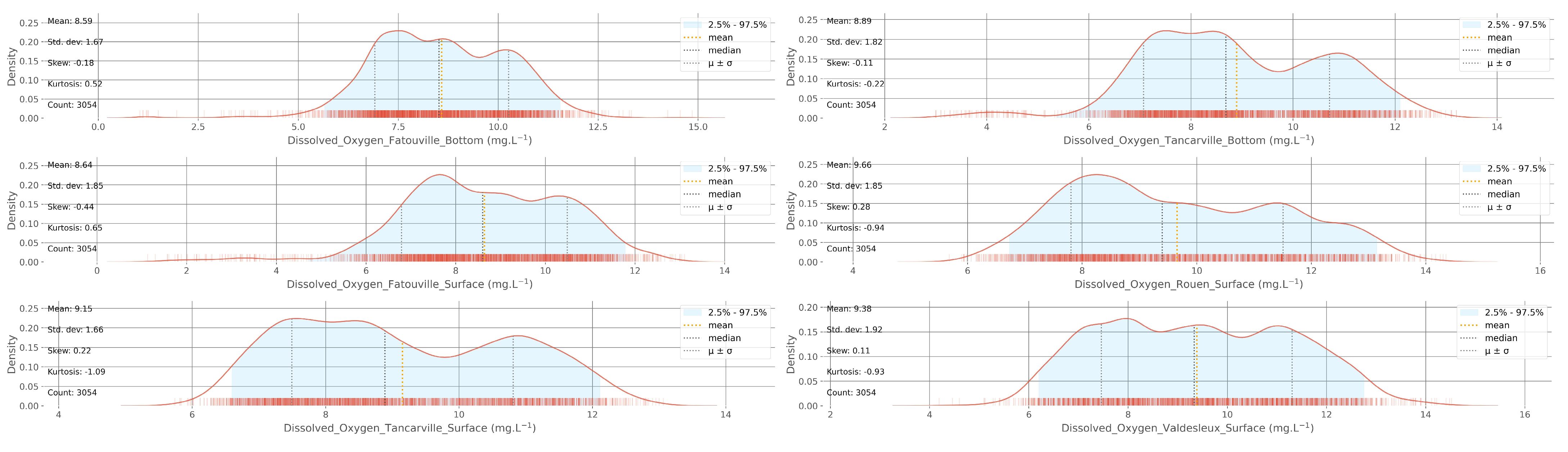
2.2. Data Analysis
2.3. Nomenclature and Abbreviation
2.4. Model Description
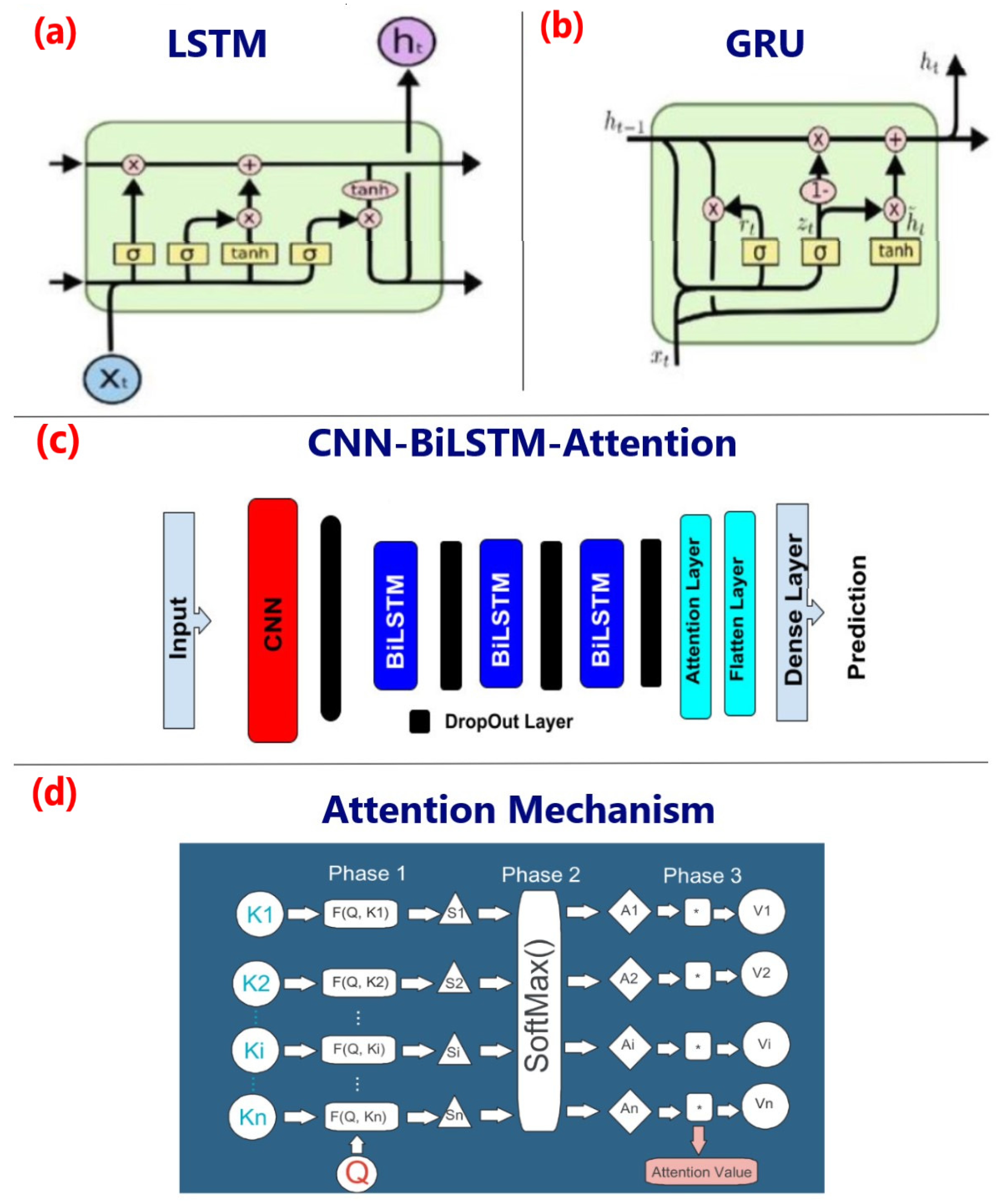
2.4.1. Models’ Architecture
Long Short-Term Memory (LSTM)
Bidirectional Long Short-Term Memory (BiLSTM)
Gated Recurrent Unit (GRU)
Convolution Neural Network (CNN)-Based Bi-Directional Long Short-Term Memory (BiLSTM) with Attention Mechanism
Attention Mechanism
2.4.2. Model Evaluation Metrics
2.4.3. Model Hyperparameters Tuning
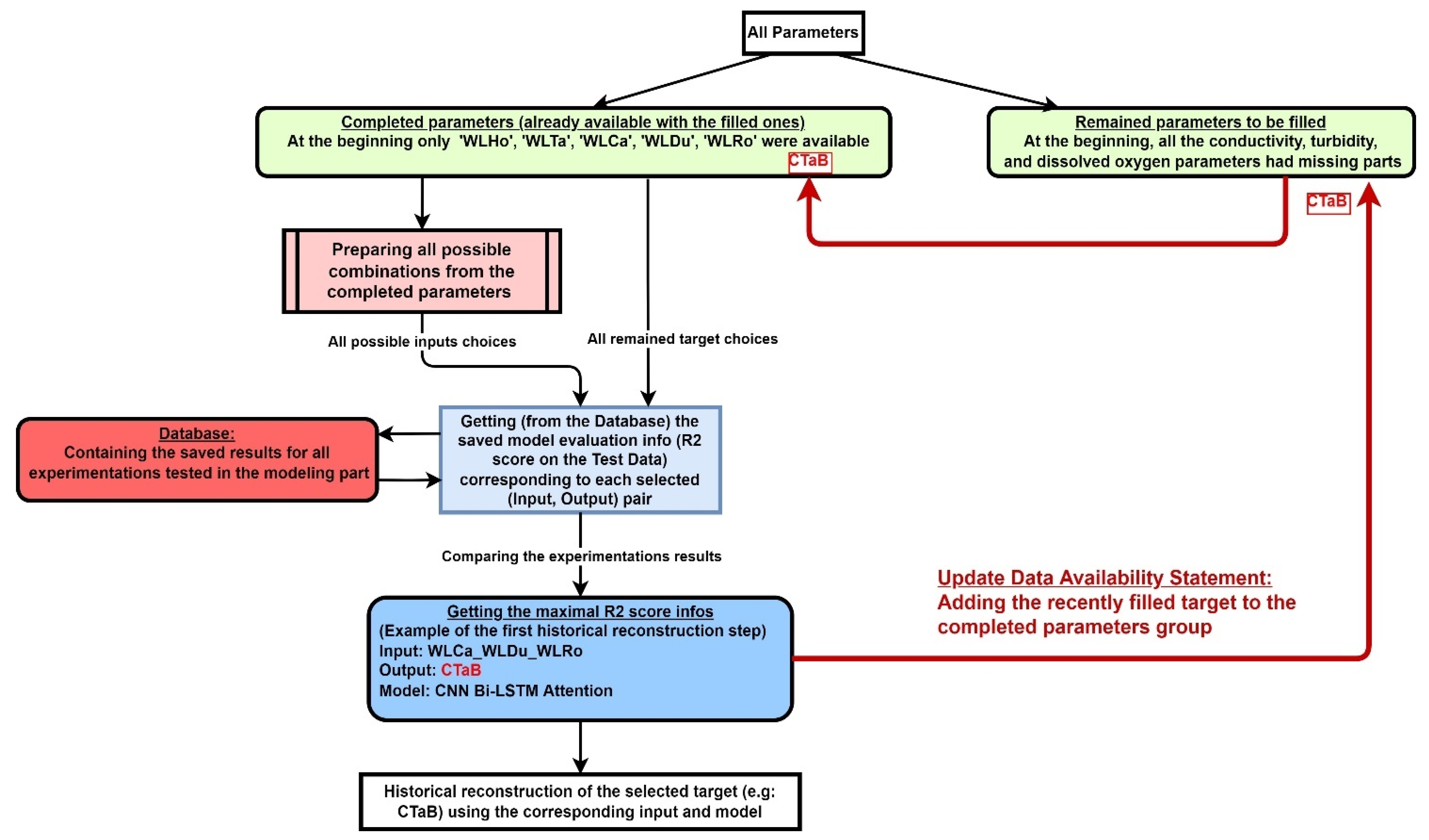
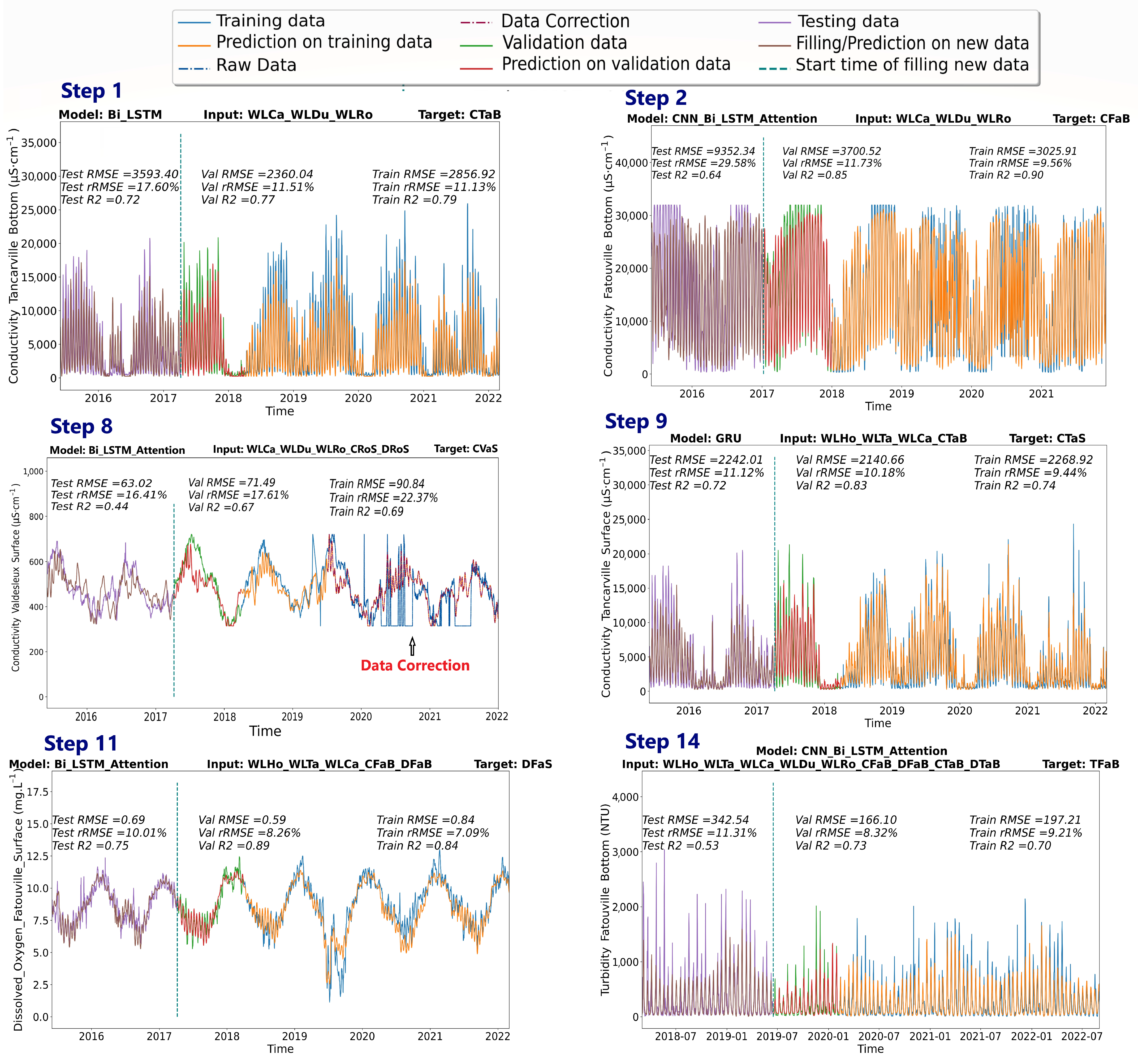
2.5. Modelling and Historical Reconstruction Approaches
3. Results and Discussion
3.1. Modelling Task
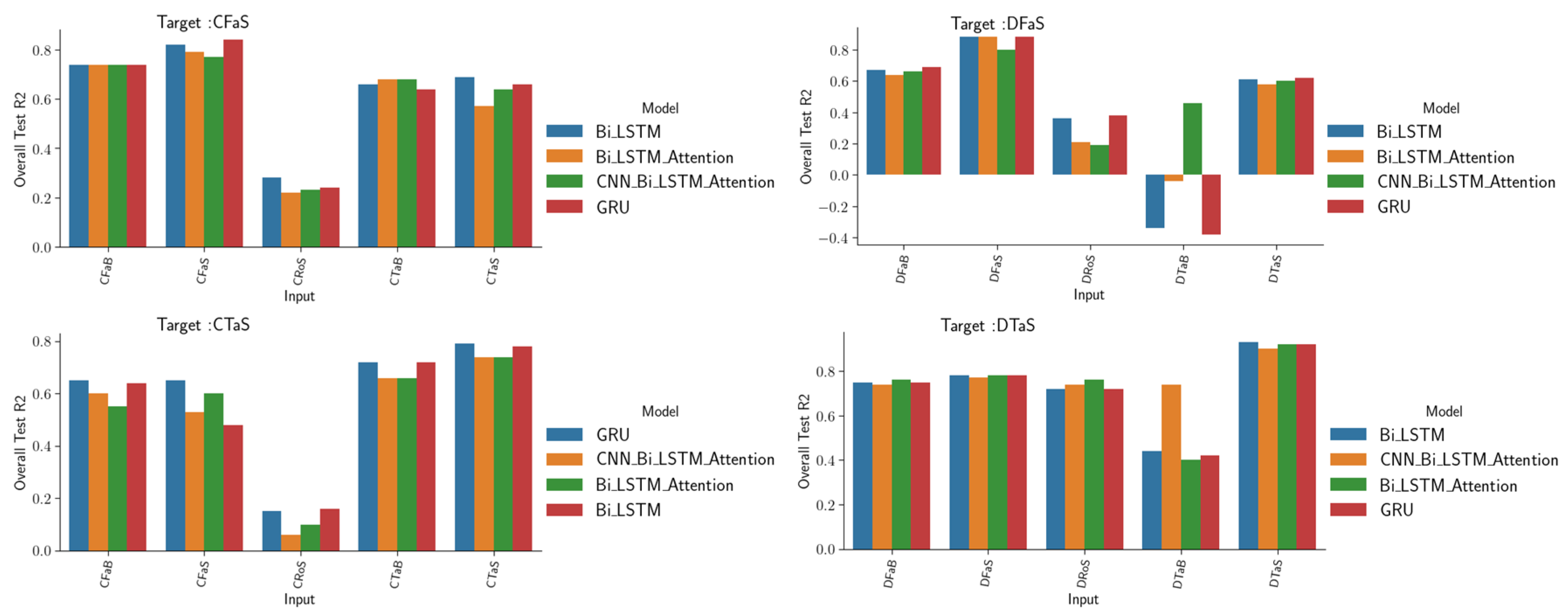
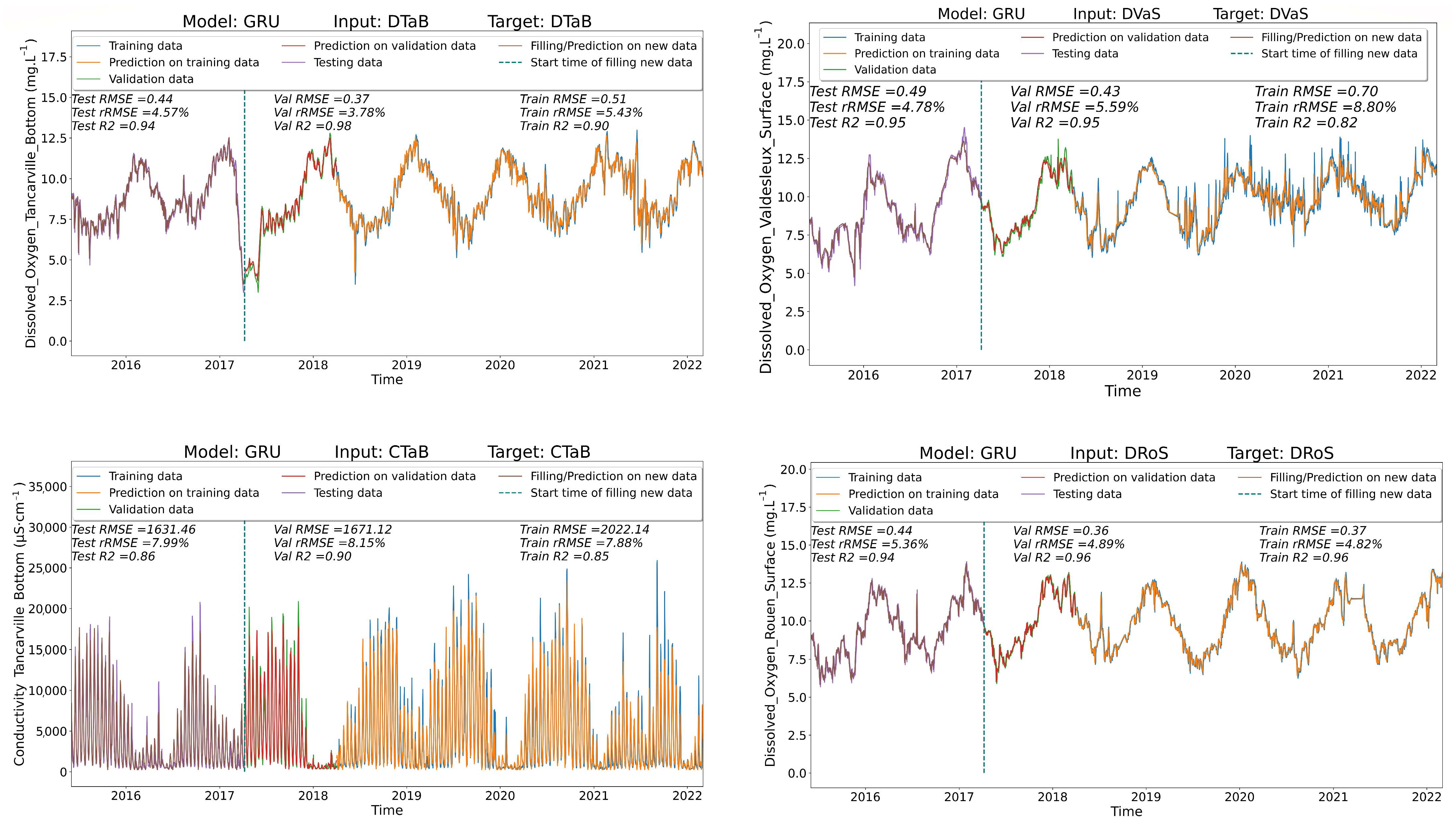
3.1.1. Simulating Water Quality Parameters Using Only Water Level Data
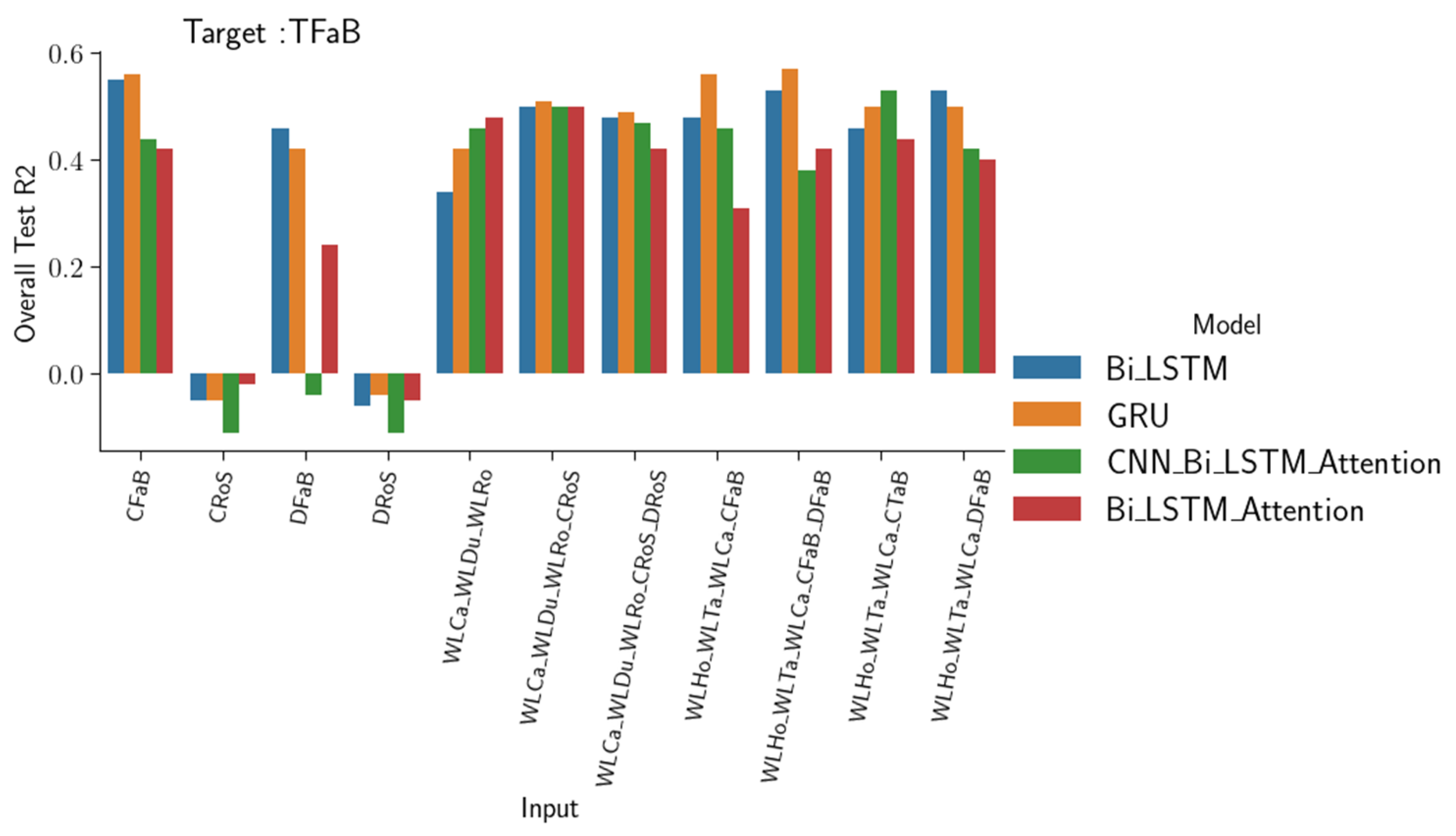
3.1.2. Simulating Water Quality Parameters in Many Scenarios
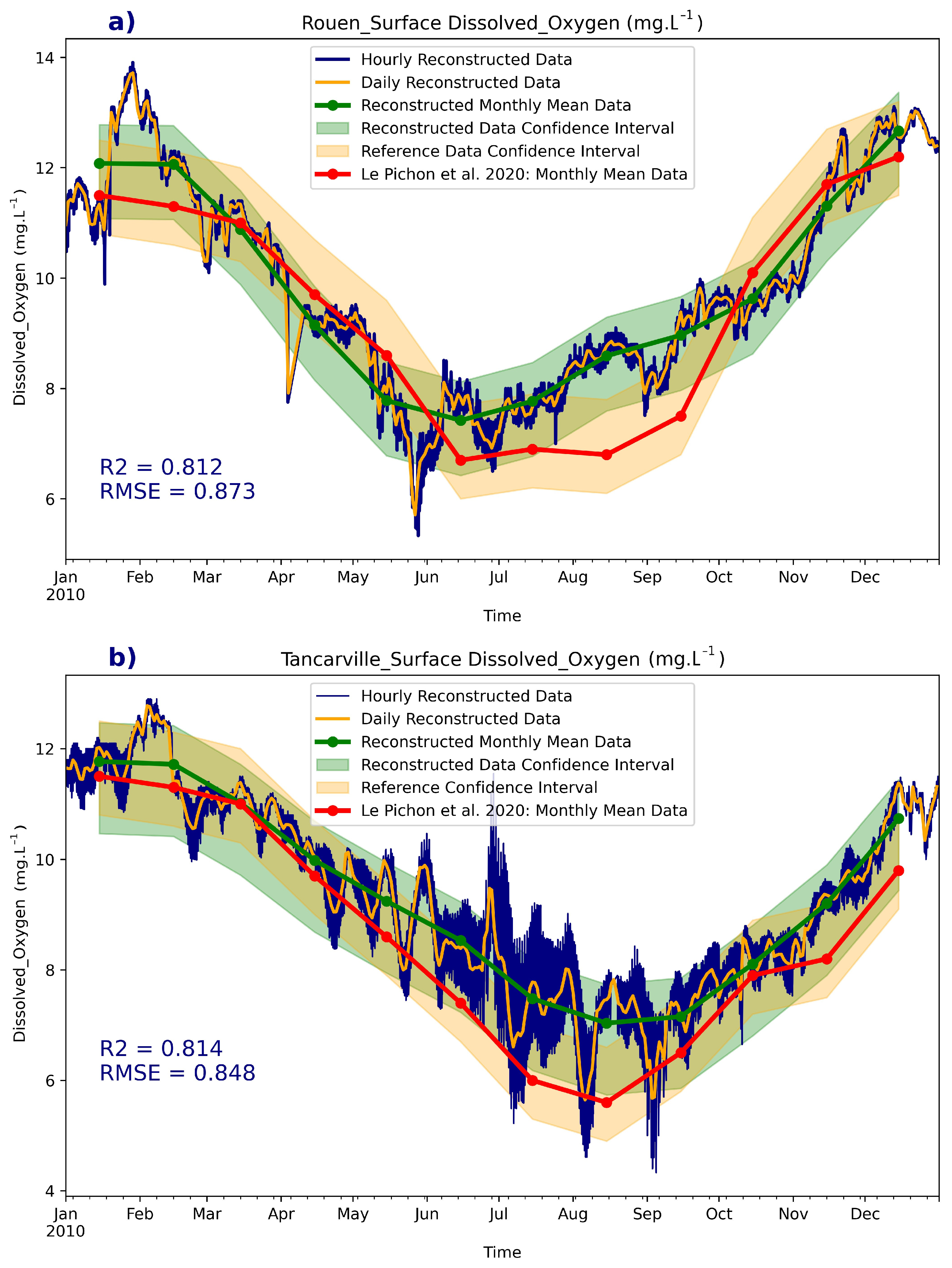
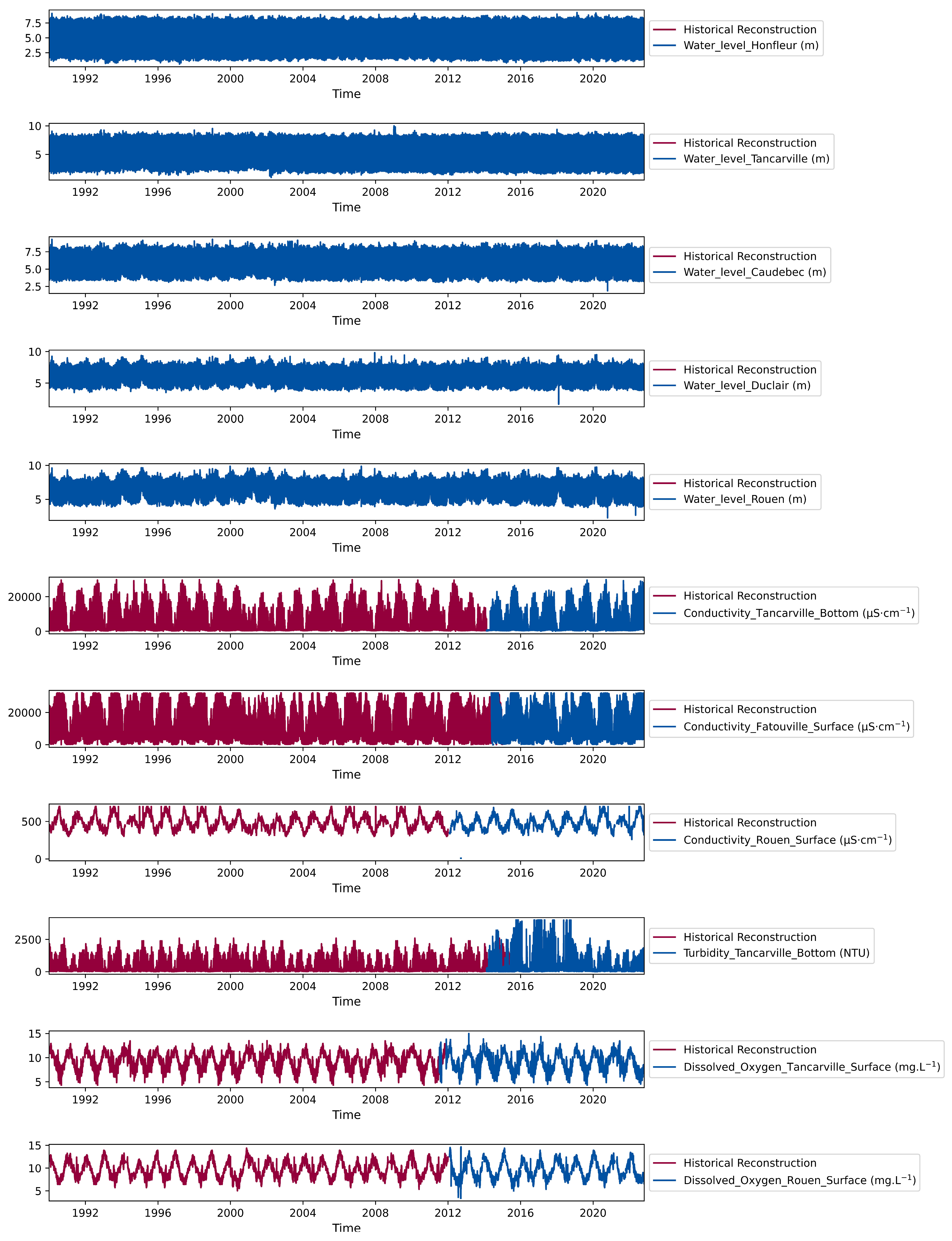
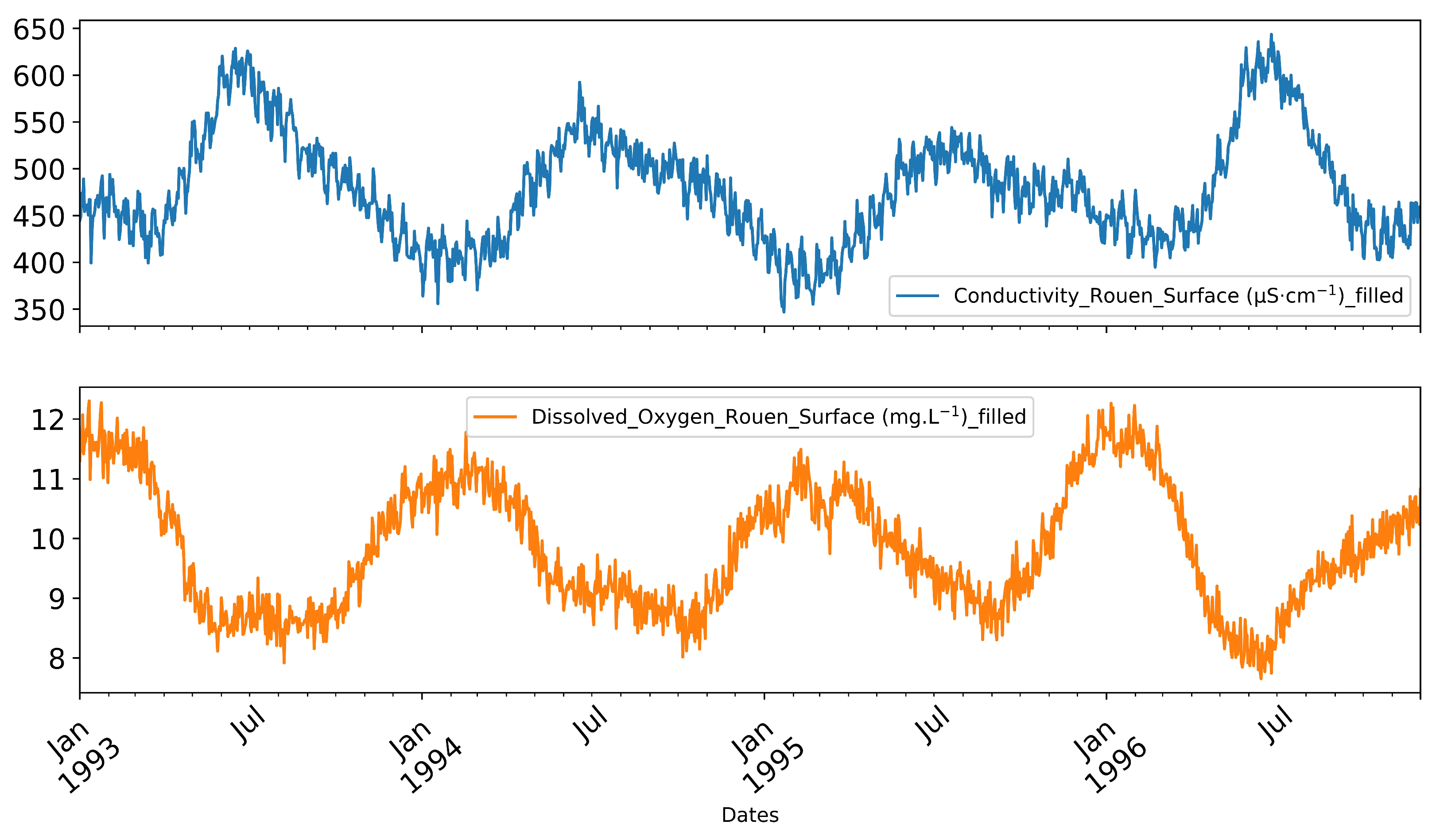
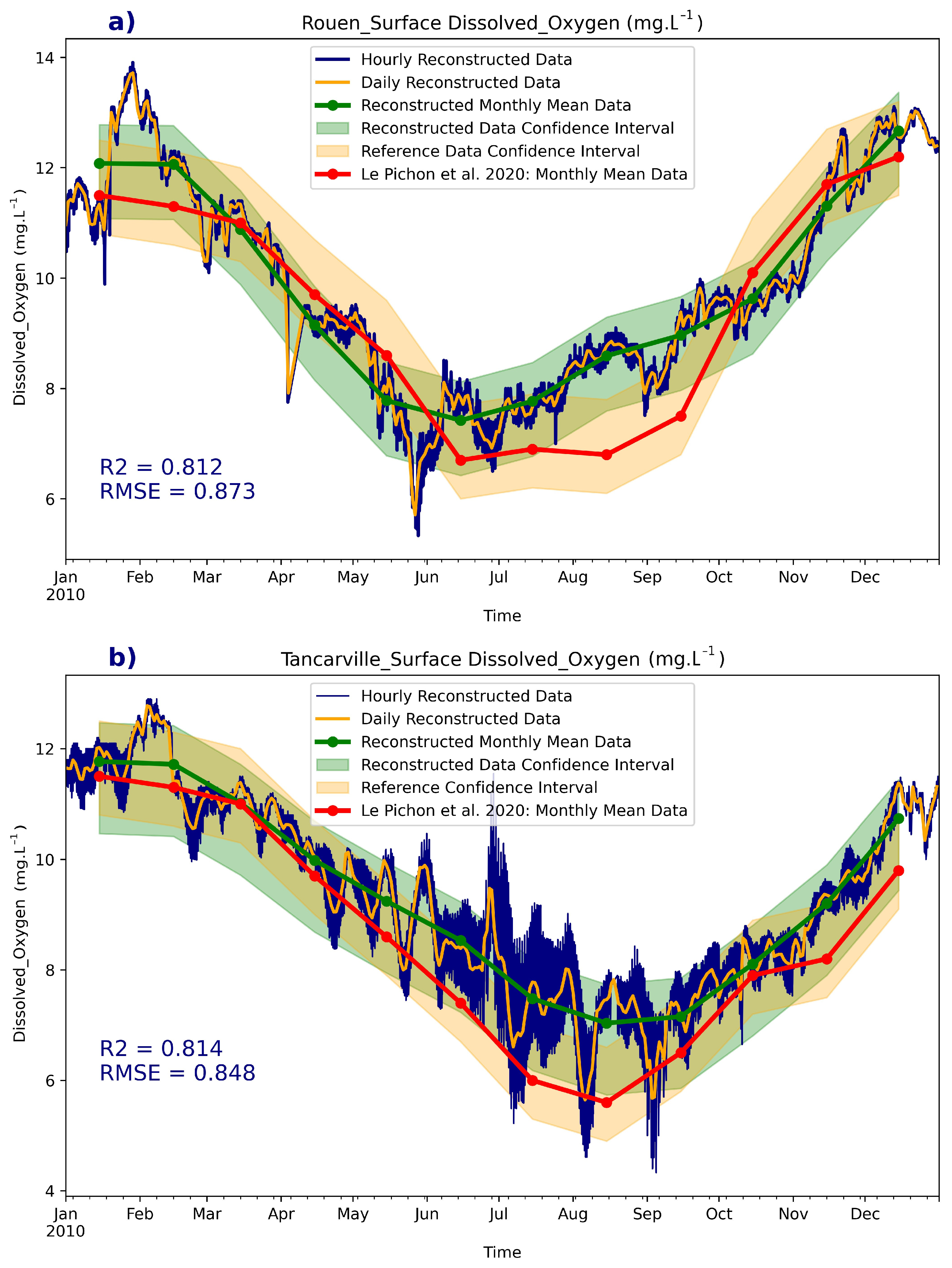
3.2. Historical Reconstruction
4. Conclusions and Future Works
- ✓
- The classical correlation analysis used to decrypt the relationships of interdependence between the parameters involved in this study does not allow us to identify clear relationships due to the strong nonlinearity that links them.
- ✓
- Training DL networks to reconstruct variations in water quality parameters based on water level has been shown to be effective, particularly in predicting electrical conductivity at stations located near the sea. This is because of the strong correlation between water level and increasing or decreasing seawater intrusion during tide oscillations. However, at predominantly fluvial stations, the water level data are not sufficient to simulate the electrical conductivity.
- ✓
- Reconstructing a water quality parameter for a given station using a network trained with the same parameter but collected at other stations proves to be an effective solution, especially when the data from the stations used are subject to the same environmental influences.
- ✓
- Deep learning tools are also powerful in identifying temporal interdependencies of each parameter to accurately predict missing data using available historical data. While our initial results using a small modelling data period are promising, it is important to consider that this approach may require longer records and additional parameters, including meteorological data, TSS, TDD, Chloride, etc., to achieve even greater accuracy and more reliable reconstructed data. Therefore, future studies should explore the potential benefits of using larger datasets.
- ✓
- The DL tools were able to extract the hidden correlations that exist between the different quality data recorded at the bottom and at the surface at each station. It was also found that the surface station data are more contaminated by noise and can be recovered with the DL tools using the bottom data as input.
- ✓
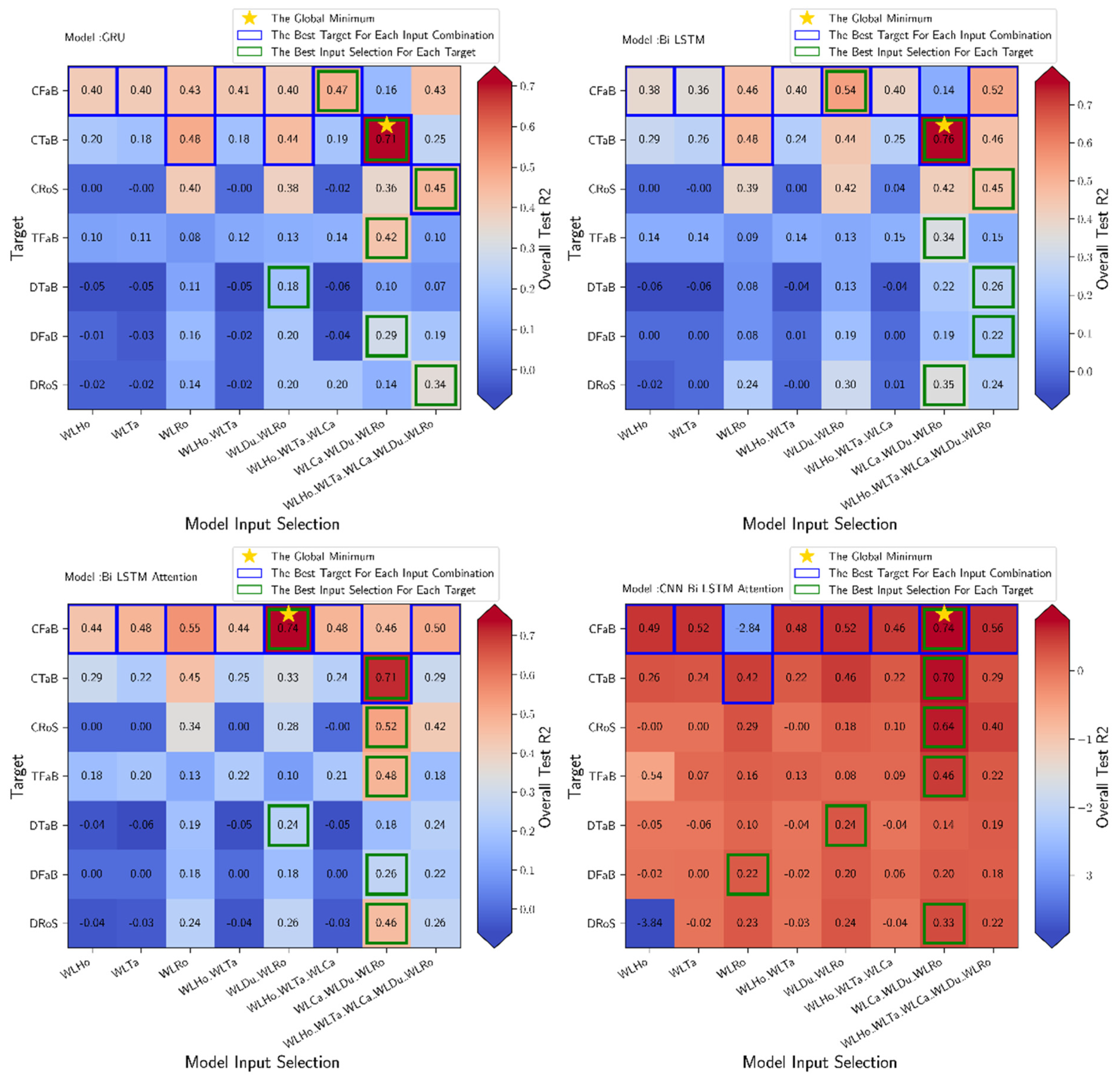
- Prediction of electrical conductivity data was more accurate than prediction of dissolved oxygen, which in turn was more accurate than prediction of turbidity. Therefore, the electrical conductivity data were reconstructed prior to the dissolved oxygen and turbidity data. This provided an important database for the final reconstruction of turbidity, which is the most complex parameter in this reconstruction.
- ✓
- The accuracy of the reconstructions depends on the type of network and the amount and nature of input data used. In this respect, the CNN-BiLSTM attention model outperformed the other networks in complex reconstructions, especially when the input data are varied. Meanwhile, the GRU model showed particularly strong performance when the input and target features had similar trends.
- ✓
- The historical reconstruction in high frequency was validated by some measurements in low frequency, with which we highlighted that the physico-chemical conditions of the studied area before 2000, which are different from those of the recent period over which the training data are acquired, make the reconstruction before this period inaccurate and valid for the period between 2000 and 2015. This highlights the strong dependence of ML tools on the nature of the features of the training data.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A






References
- Haslam, S.M. River Pollution: An Ecological Perspective; John Wiley & Son Ltd.: Hoboken, NJ, USA, 1991. [Google Scholar]
- Johnstone, D.W.M.; Horan, N.J. Institutional Developments, Standards and River Quality: A UK History and Some Lessons for Industrialising Countries. Water Sci. Technol. 1996, 33, 211–222. [Google Scholar] [CrossRef]
- Strobl, R.O.; Robillard, P.D. Network Design for Water Quality Monitoring of Surface Freshwaters: A Review. J. Environ. Manag. 2008, 87, 639–648. [Google Scholar] [CrossRef]
- Behmel, S.; Damour, M.; Ludwig, R.; Rodriguez, M.J. Water Quality Monitoring Strategies—A Review and Future Perspectives. Sci. Total Environ. 2016, 571, 1312–1329. [Google Scholar] [CrossRef] [PubMed]
- Chau, K. A Review on Integration of Artificial Intelligence into Water Quality Modelling. Mar. Pollut. Bull. 2006, 52, 726–733. [Google Scholar] [CrossRef] [PubMed]
- Chau, K.W.; Jiang, Y.W. Three-Dimensional Pollutant Transport Model for the Pearl River Estuary. Water Res. 2002, 36, 2029–2039. [Google Scholar] [CrossRef] [PubMed]
- Werner, A.D.; Gallagher, M.R. Characterisation of Sea-Water Intrusion in the Pioneer Valley, Australia Using Hydrochemistry and Three-Dimensional Numerical Modelling. Hydrogeol. J. 2006, 14, 1452–1469. [Google Scholar] [CrossRef]
- Downs, P.W.; Cui, Y.; Wooster, J.K.; Dusterhoff, S.R.; Booth, D.B.; Dietrich, W.E.; Sklar, L.S. Managing Reservoir Sediment Release in Dam Removal Projects: An Approach Informed by Physical and Numerical Modelling of Non-cohesive Sediment. Int. J. River Basin Manag. 2009, 7, 433–452. [Google Scholar] [CrossRef]
- Chen, Q.; Wu, W.; Blanckaert, K.; Ma, J.; Huang, G. Optimization of Water Quality Monitoring Network in a Large River by Combining Measurements, a Numerical Model and Matter-Element Analyses. J. Environ. Manag. 2012, 110, 116–124. [Google Scholar] [CrossRef]
- Martyr-Koller, R.C.; Kernkamp, H.W.J.; van Dam, A.; van der Wegen, M.; Lucas, L.V.; Knowles, N.; Jaffe, B.; Fregoso, T.A. Application of an Unstructured 3D Finite Volume Numerical Model to Flows and Salinity Dynamics in the San Francisco Bay-Delta. Estuar. Coast. Shelf Sci. 2017, 192, 86–107. [Google Scholar] [CrossRef]
- Rauch, W.; Henze, M.; Koncsos, L.; Reichert, P.; Shanahan, P.; SomlyóDy, L.; Vanrolleghem, P. River Water Quality Modelling: I. State of the Art. Water Sci. Technol. 1998, 38, 237–244. [Google Scholar] [CrossRef]
- Lesser, G.R.; Roelvink, J.A.; van Kester, J.A.T.M.; Stelling, G.S. Development and Validation of a Three-Dimensional Morphological Model. Coast. Eng. 2004, 51, 883–915. [Google Scholar] [CrossRef]
- Martin, J.L.; McCutcheon, S.C. Hydrodynamics and Transport for Water Quality Modeling; CRC Press: Boca Raton, FL, USA, 2018; ISBN 9781351439886. [Google Scholar]
- Shakibaeinia, A.; Dibike, Y.B.; Kashyap, S.; Prowse, T.D.; Droppo, I.G. A Numerical Framework for Modelling Sediment and Chemical Constituents Transport in the Lower Athabasca River. J. Soils Sediments 2017, 17, 1140–1159. [Google Scholar] [CrossRef]
- Kashyap, S.; Dibike, Y.; Shakibaeinia, A.; Prowse, T.; Droppo, I. Two-Dimensional Numerical Modelling of Sediment and Chemical Constituent Transport within the Lower Reaches of the Athabasca River. Environ. Sci. Pollut. Res. 2017, 24, 2286–2303. [Google Scholar] [CrossRef] [PubMed]
- Radwan, M.; Willems, P.; Berlamont, J. Sensitivity and Uncertainty Analysis for River Quality Modelling. J. Hydroinform. 2004, 6, 83–99. [Google Scholar] [CrossRef]
- Sharma, D.; Kansal, A. Assessment of River Quality Models: A Review. Rev. Environ. Sci. Bio/Technol. 2013, 12, 285–311. [Google Scholar] [CrossRef]
- Karimi, S.; Amiri, B.J.; Malekian, A. Similarity Metrics-Based Uncertainty Analysis of River Water Quality Models. Water Resour. Manag. 2019, 33, 1927–1945. [Google Scholar] [CrossRef]
- Liu, P.; Wang, J.; Sangaiah, A.; Xie, Y.; Yin, X. Analysis and Prediction of Water Quality Using LSTM Deep Neural Networks in IoT Environment. Sustainability 2019, 11, 2058. [Google Scholar] [CrossRef]
- Alizadeh, M.J.; Kavianpour, M.R.; Danesh, M.; Adolf, J.; Shamshirband, S.; Chau, K.-W. Effect of River Flow on the Quality of Estuarine and Coastal Waters Using Machine Learning Models. Eng. Appl. Comput. Fluid Mech. 2018, 12, 810–823. [Google Scholar] [CrossRef]
- Khullar, S.; Singh, N. Machine Learning Techniques in River Water Quality Modelling: A Research Travelogue. Water Supply 2020, 21, 1–13. [Google Scholar] [CrossRef]
- Khoi, D.N.; Quan, N.T.; Linh, D.Q.; Nhi, P.T.T.; Thuy, N.T.D. Using Machine Learning Models for Predicting the Water Quality Index in the La Buong River, Vietnam. Water 2022, 14, 1552. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N. Prabhat Deep Learning and Process Understanding for Data-Driven Earth System Science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef] [PubMed]
- Zounemat-Kermani, M.; Batelaan, O.; Fadaee, M.; Hinkelmann, R. Ensemble Machine Learning Paradigms in Hydrology: A Review. J. Hydrol. 2021, 598, 126266. [Google Scholar] [CrossRef]
- Wai, K.P.; Chia, M.Y.; Koo, C.H.; Huang, Y.F.; Chong, W.C. Applications of Deep Learning in Water Quality Management: A State-of-the-Art Review. J. Hydrol. 2022, 613, 128332. [Google Scholar] [CrossRef]
- Shen, C. A Transdisciplinary Review of Deep Learning Research and Its Relevance for Water Resources Scientists. Water Resour. Res. 2018, 54, 8558–8593. [Google Scholar] [CrossRef]
- Malekian, A.; Chitsaz, N. Chapter 4—Concepts, Procedures, and Applications of Artificial Neural Network Models in Streamflow Forecasting. In Advances in Streamflow Forecasting; Sharma, P., Machiwal, D., Eds.; Elsevier: Amsterdam, The Netherlands, 2021; pp. 115–147. ISBN 978-0-12-820673-7. [Google Scholar]
- Barzegar, R.; Aalami, M.T.; Adamowski, J. Short-Term Water Quality Variable Prediction Using a Hybrid CNN–LSTM Deep Learning Model. Stoch. Environ. Res. Risk Assess. 2020, 34, 415–433. [Google Scholar] [CrossRef]
- Baek, S.-S.; Pyo, J.; Chun, J.A. Prediction of Water Level and Water Quality Using a CNN-LSTM Combined Deep Learning Approach. Water 2020, 12, 3399. [Google Scholar] [CrossRef]
- Ubah, J.I.; Orakwe, L.C.; Ogbu, K.N.; Awu, J.I.; Ahaneku, I.E.; Chukwuma, E.C. Forecasting Water Quality Parameters Using Artificial Neural Network for Irrigation Purposes. Sci. Rep. 2021, 11, 24438. [Google Scholar] [CrossRef]
- Aldhyani, T.H.H.; Al-Yaari, M.; Alkahtani, H.; Maashi, M. Water Quality Prediction Using Artificial Intelligence Algorithms. Appl. Bionics Biomech. 2020, 2020, 6659314. [Google Scholar] [CrossRef]
- Jerry, R.; Rija, R.; Jean, R.; Lahatra, R.; Fils, R. Modelling of Lake Water Quality Parameters by Deep Learning Using Remote Sensing Data. Am. J. Geogr. Inf. Syst. 2019, 2019, 221–227. [Google Scholar] [CrossRef]
- Billen, G.; Garnier, J.; Ficht, A.; Cun, C. Modeling the Response of Water Quality in the Seine River Estuary to Human Activity in Its Watershed Over the Last 50 Years. Estuaries 2001, 24, 977–993. [Google Scholar] [CrossRef]
- Le Pichon, C.; Lestel, L.; Courson, E.; Merg, M.L.; Tales, E.; Belliard, J. Historical Changes in the Ecological Connectivity of the Seine River for Fish: A Focus on Physical and Chemical Barriers since the Mid-19th Century. Water 2020, 12, 1352. [Google Scholar] [CrossRef]
- Prathumratana, L.; Sthiannopkao, S.; Kim, K.W. The Relationship of Climatic and Hydrological Parameters to Surface Water Quality in the Lower Mekong River. Environ. Int. 2008, 34, 860–866. [Google Scholar] [CrossRef] [PubMed]
- Etcheber, H.; Schmidt, S.; Sottolichio, A.; Maneux, E.; Chabaux, G.; Escalier, J.M.; Wennekes, H.; Derriennic, H.; Schmeltz, M.; Quéméner, L.; et al. Monitoring Water Quality in Estuarine Environments: Lessons from the MAGEST Monitoring Program in the Gironde Fluvial-Estuarine System. Hydrol. Earth Syst. Sci. 2011, 15, 831–840. [Google Scholar] [CrossRef]
- Schmidt, S.; Diallo, I.I.; Derriennic, H.; Fallou, H.; Lepage, M. Exploring the Susceptibility of Turbid Estuaries to Hypoxia as a Prerequisite to Designing a Pertinent Monitoring Strategy of Dissolved Oxygen. Front. Mar. Sci. 2019, 6, 352. [Google Scholar] [CrossRef]
- Onabule, O.A.; Mitchell, S.B.; Couceiro, F. The Effects of Freshwater Flow and Salinity on Turbidity and Dissolved Oxygen in a Shallow Macrotidal Estuary: A Case Study of Portsmouth Harbour. Ocean Coast. Manag. 2020, 191, 105179. [Google Scholar] [CrossRef]
- Xudong Hong Xiao Zheng, J.X.L.W.W.X. Cross-Lingual Non-Ferrous Metals Related News Recognition Method Based on CNN with A Limited Bi-Lingual Dictionary. Comput. Mater. Contin. 2019, 58, 379–389. [Google Scholar] [CrossRef]
- Wang, J.; Zou, Y.; Lei, P.; Sherratt, S.; Wang, L. Research on Recurrent Neural Network Based Crack Opening Prediction of Concrete Dam. J. Internet Technol. 2020, 21, 1151. [Google Scholar] [CrossRef]
- Shen, Y.; Li, Y.; Sun, J.; Ding, W.; Shi, X.; Zhang, L.; Shen, X.; He, J. Hashtag Recommendation Using LSTM Networks with Self-Attention. Comput. Mater. Contin. 2019, 61, 1261–1269. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.Y.; Frasconi, P. Learning Long-Term Dependencies with Gradient Descent Is Difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Yang, Z.; Zhang, J.; Zhao, Z.; Zhai, Z.; Chen, G. Interpreting Network Knowledge with Attention Mechanism for Bearing Fault Diagnosis. Appl. Soft Comput. 2020, 97, 106829. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems; Guyon, I., Von Luxburg, U., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-Generation Hyperparameter Optimization Framework. arXiv 2019, arXiv:1907.10902. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Prechelt, L. Early Stopping—But When? In Neural Networks: Tricks of the Trade, 2nd ed.; Montavon, G., Orr, G.B., Müller, K.-R., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 53–67. ISBN 978-3-642-35289-8. [Google Scholar]
- Romero, E.; Le Gendre, R.; Garnier, J.; Billen, G.; Fisson, C.; Silvestre, M.; Riou, P. Long-term water quality in the lower Seine: Lessons learned over 4 decades of monitoring. Environ. Sci. Policy 2016, 58, 141–154. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Abbreviation |
|---|---|
| Water_Level_Honfleur (m) Water_Level_Tancarville (m) Water_Level_Caudebec (m) Water_Level_Duclair (m) Water_Level_Rouen (m) | WLHo WLTa WLCa WLDu WLRo |
| Electrical Conductivity_Tancarville_Surface (μS·cm−1) Electrical Conductivity_Tancarville_Bottom (μS·cm−1) Electrical Conductivity_Fatouville_Surface (μS·cm−1) Electrical Conductivity_Fatouville_Bottom (μS·cm−1) Electrical Conductivity_Rouen_Surface (μS·cm−1) Electrical Conductivity_Valdesleux_Surface (μS·cm−1) | CTaS CTaB CFaS CFaB CRoS CVaS |
| Turbidity_Tancarville_Bottom (NTU) Turbidity_Fatouville_Bottom (NTU) | TTaB TFaB |
| Dissolved_Oxygen_Tancarville_Surface (mg·L−1) Dissolved_Oxygen_Tancarville_Bottom (mg·L−1) Dissolved_Oxygen_Fatouville_Surface (mg·L−1) Dissolved_Oxygen_Fatouville_Bottom (mg·L−1) Dissolved_Oxygen_Rouen_Surface (mg·L−1) Dissolved_Oxygen_Valdesleux_Surface (mg·L−1) | DTaS DTaB DFaS DFaB DRoS DVaS |
| Hyper-Parameters | Range |
|---|---|
| BiLSTM/GRU Number of layers | From 1 to 4 |
| BiLSTM/GRU Number of Unit | From 10 to 500 |
| Batch-size | {32, 64, 128, 256} |
| Learning rate | From 0.001 to 0.1 |
| Drop-out | {0.1, 0.2, 0.3} |
| CNN Filter size | {4, 9, 16, 25, 36, 49, 64, 81} |
| CNN Activation Function | ‘Sigmoid’, ‘Relu’ |
| Look-Back (Input Sequence size) | From 1 day to 12 months |
| Steps | Target to Be Filled at the Specific Step | Selected Input | Selected Model |
|---|---|---|---|
| 1 | CTaB | WLCa_WLDu_WLRo | Bi_LSTM |
| 2 | CFaB | WLCa_WLDu_WLRo | CNN_Bi_LSTM_Attention |
| 3 | CFaS | CFaB | CNN_Bi_LSTM_Attention |
| 4 | CRoS | WLHo_WLTa_WLCa_CFaB | CNN_Bi_LSTM_Attention |
| 5 | DRoS | CRoS | Bi_LSTM |
| 6 | DTaS | WLCa_WLDu_WLRo_CRoS_DRoS | Bi_LSTM |
| 7 | CVaS | WLCa_WLDu_WLRo_CRoS_DRoS | Bi_LSTM_Attention |
| 8 | DVaS | DRoS | GRU |
| 9 | CTaS | WLHo_WLTa_WLCa_CTaB | GRU |
| 10 | DFaB | WLCa_WLDu_WLRo_DTaS | GRU |
| 11 | DFaS | WLHo_WLTa_WLCa_CFaB_DFaB | Bi_LSTM_Attention |
| 12 | DTaB | WLHo_WLTa_WLCa_CFaB_DFaB | CNN_Bi_LSTM_Attention |
| 13 | TFaB | WLHo_WLTa_WLCa_CFaB_DFaB_CTaB_DTaB | CNN_Bi_LSTM_Attention |
| 14 | TTaB | WLHo_WLTa_WLCa_TFaB | CNN_Bi_LSTM_Attention |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Janbain, I.; Jardani, A.; Deloffre, J.; Massei, N. Deep Learning Approaches for Numerical Modeling and Historical Reconstruction of Water Quality Parameters in Lower Seine. Water 2023, 15, 1773. https://doi.org/10.3390/w15091773
Janbain I, Jardani A, Deloffre J, Massei N. Deep Learning Approaches for Numerical Modeling and Historical Reconstruction of Water Quality Parameters in Lower Seine. Water. 2023; 15(9):1773. https://doi.org/10.3390/w15091773
Chicago/Turabian StyleJanbain, Imad, Abderrahim Jardani, Julien Deloffre, and Nicolas Massei. 2023. "Deep Learning Approaches for Numerical Modeling and Historical Reconstruction of Water Quality Parameters in Lower Seine" Water 15, no. 9: 1773. https://doi.org/10.3390/w15091773
APA StyleJanbain, I., Jardani, A., Deloffre, J., & Massei, N. (2023). Deep Learning Approaches for Numerical Modeling and Historical Reconstruction of Water Quality Parameters in Lower Seine. Water, 15(9), 1773. https://doi.org/10.3390/w15091773