1. Introduction
Precipitation plays a crucial role in the water cycle and is a vital environmental phenomenon that varies significantly over time and space [
1]. Precipitation modeling and forecasting can greatly assist in managing water resources and mitigating drought. Intelligent systems and machine learning methods are currently being used to model hydrological processes and water engineering, providing more accurate estimates of meteorological parameters using data from meteorological stations [
2]. Lake Urmia is a critical factor in the climate and weather conditions of the West Azerbaijan province, Iran, and its surrounding areas. This lake has made the climate of the region more moderate, but the occurrence of drought is one of the important facts of the basin of Lake Urmia, which can be attributed to the periodic fluctuations of the climate and lack of moist and rainy air masses, especially Mediterranean humid air masses [
3]. This lake, in recent years due to the climate change (decrease in rainfall), the excessive exploitation of underground water resources, the construction of numerous dams, the construction of a bridge through the lake, and a high consumption of water in agriculture, is suffering from water shortage and is facing a serious crisis. The investigation of the fluctuations of the lake water level has shown that the lake water level has been declining so far and will continue to decline in the coming years, which requires comprehensive management as soon as possible. If this important lake dries up, the weather of the region will turn into tropical weather with salt storms and the ecosystem of the region will change. Therefore, in the situation where the drying crisis of Lake Urmia is a serious matter, rainfall modeling and forecasting are very important and necessary to implement the best optimal restoration policies and manage the water resources of the basin as best as possible by applying new methods of water resources management. Lake Urmia’s drying up will negatively affect Azerbaijan and neighboring regions, impacting the economy, ecology, environment, and health of residents near the lake [
4]. Therefore, rainfall modeling and forecasting are necessary to implement optimal restoration policies and manage water resources in the basin through new methods. This study is the first to investigate the effect of distance from nearby seas on precipitation and its fluctuations in Lake Urmia. Unlike most of the studies that model the precipitation using meteorological variables only, this research wants to study the effect of the distance from the sea on the precipitation and also use the spatial variables according to the precipitation fronts.
Bao Pham et al. [
5] conducted a study in 2019 to model the prediction of daily rainfall in the Vu Gia-Thu Bon River basin in Central Vietnam. In the study, the potential of five different data-driven models including Multilayer Perceptron (MLP), Least Square Support Vector Machine (LSSVM), Neuro-fuzzy, Hammerstein–Weiner (HW), and autoregressive integrated moving average (ARIMA) was employed. Subsequently, hybrid ARIMA-MLP, ARIMA-LSSVM, ARIMA-NF, and ARIMA-HW models were also utilized to predict the daily rainfall at these stations. The quantitative analysis indicated that the HW model increased the prediction accuracy by 5%, 3%, and 2% at Hien, Ai Nghia, and Cau Lau stations, respectively, compared to the other models. Also, the results of hybrid ARIMA-NF and ARIMA-HW models showed the best performance in terms of predictive skills and were shown to increase the prediction accuracy in comparison to the single models.
Kumar Pau et al. [
6] investigated the sub-divisional rainfall data of India during the period of 1871 to 2016 using a wavelet analysis to decompose and de-noise the series into time–frequency components in order to study the local as well as global variation over different scales and time epochs. On the decomposed series, autoregressive integrated moving average (ARIMA) and artificial neural network (ANN) models were applied and by means of inverse wavelet transform, the prediction of rainfall for different sub-divisions was obtained. It is reported that the Wavelet–ANN and Wavelet–ARIMA approach outperforms the usual ARIMA model for forecasting of rainfall for the data under consideration.
Apaydin et al. [
7] conducted a similar study of rainfall modeling based on spatio-temporal changes for the coastal region of Turkey with a hybrid approach of geographic information systems and machine learning using several artificial intelligence models. In the study, spatial variables such as the latitude, longitude, altitude, distance to the sea, and aspect were obtained with the aid of GIS in the coastal zone of Turkey. Considering the monthly time index variable, monthly precipitation was estimated by artificial neural networks, deep learning, machine learning, and tree models. Among the used models, the LSTM model based on DL gave the best results. The most important deficit of this and similar studies is based on the stochastic structure of the precipitation data set.
De Oliveira et al. [
8] conducted spatio-temporal soil moisture modeling in Atlantic forests through machine learning algorithms. The study aimed to model the spatial–temporal dynamics of soil moisture in the Atlantic forest through four machine learning algorithms. A random forest (RF), support vector machine, average neural network, and weighted k-nearest neighbor were studied. The abilities of the models were evaluated by means of the root mean square error, mean absolute error, coefficient of determination (R
2), and Nash–Sutcliffe efficiency (NS) for two calibration approaches: (a) chronological and (b) randomized. RF was the best algorithm for modeling the spatio-temporal dynamics of soil moisture. This finding highlights the ability of RF to generalize a data set with contrasting weather conditions. Multilinear regression presented the lowest values of RMSE, MAE, R
2, and NS, and thus it was not able to properly model the spatio-temporal dynamics of the soil moisture. The temporal and spatial behavior of soil moisture has a highly non-linear pattern, which hampers multilinear regression and favors machine learning algorithms.
Di Nunno et al. [
9] carried out a study in 2022 on precipitation forecasting in northern Bangladesh using a hybrid machine learning model by using two machine learning algorithms: M5P and support vector regression.
The hybrid model M5P-SVR led to the best predictions among the models used in the study, with R2 values up to 0.87 and 0.92 for the stations of Rangpur and Sylhet, respectively.
Wahla et al. [
10] evaluated spatial–temporal mapping and climate change monitoring using standard precipitation evaporation and transpiration and an RF machine learning model. In this research, they predicted droughts by examining the changes in an acceptable index using appropriate climatic factors. This research demonstrates that the SPEI has the potential for use as a predictive tool for drought prediction and the RF model can be used to solve both regression and classification issues related to drought in short-term time periods, and that it performs well in both cases.
Fabio Di Nuno et al. [
11] conducted a study for a spatio-temporal analysis of drought in southern Italy with a combined clustering–forecasting approach based on the SPEI index and artificial intelligence algorithms. In the study, three clustering algorithms, K-mean, Hierarchical, and Expectation–Maximization, were first used to divide southern Italy into homogeneous drought regions, based on gridded data of the Standardized Precipitation Evapotranspiration Index forecasting with a 6-month time scale (SPEI6). The Hierarchical algorithm identified five well-distinct clusters characterized by drought events of different durations and severity, considering the different morphoclimatic characteristics of the study area. Then, the mean SPEI6 time series was evaluated for each cluster and used to assess the evolutionary drought trends. In addition, two machine learning (ML) algorithms, M5P and support vector regression (SVR), were also used to develop forecasting models for the SPEI6.
However, thus far, no comprehensive study has been conducted to investigate the spatio-temporal precipitation changes in the Lake Urmia basin in Iran. This study aims to accurately model spatio-temporal precipitation variations by utilizing the statistical rainfall period of 16 stations in the Lake Urmia basin. Multiple machine learning models were employed to achieve this goal, including RF, M5, SVR, GPR, and KNN. The depletion in Lake Urmia could result in a shift from temperate to tropical weather, which could have significant ecological implications. Hence, accurate precipitation prediction is crucial for effective restoration policies and optimal water resource management in the basin.
2. Materials and Methods
2.1. Study Area and the Data
Lake Urmia is 1300 m above sea level, and its area varies depending on the annual rainfall and evaporation rate [
12]. According to the country divisions of Iran, this lake is located northwest of the Iran between the two provinces of East and West Azerbaijan, and its water is supplied from 60 rivers, including the Zarinerood, Barandoz, Shahrchai, and Nazlo. Lake Urmia’s catchment area is one of Iran’s closed basins, one of the main basins in classifying Iran’s catchment areas. The area of this basin is 51,876 square kilometers, and the geographical location of this lake is 37 to 30.38 degrees north latitude and 45 to 46 degrees east longitude. The northern part of the Zagros Mountains, the southern slope of Sabalan Mountain, and the northern, western, and southern slopes of Sahand Mountain surround it.
Figure 1 shows the geographical location of the Lake Urmia basin. Considering the latitude and altitude of the basin area, its general climate is very similar to the middle latitude, semi-high plains with cold winters and relatively temperate summers. The occurrence of drought is an important fact regarding the watershed stations of Lake Urmia, which can be attributed to the seasonal fluctuations of the climate and the lack of passage of humid and rain-bearing air masses, especially humid Mediterranean air masses [
3]. The humid Mediterranean air masses significantly affect the precipitation in this basin, so the distance of the stations from the Mediterranean Sea is considered an important and influential input parameter.
The data from 16 meteorological stations in the Lake Urmia basin were considered in the present study. For each station, available rainfall data have been prepared from the beginning of its establishment until 2021, and then monthly averages of rainfall have been calculated from the available data for each month of the year, the details of which are presented in
Table 1.
The graph of the average monthly precipitation of all stations for the available years was drawn for each station compared to the basin average, which can be seen in
Figure 2. The watershed average was obtained using Arc GIS software (
https://www.esri.com/en-us/arcgis/about-arcgis/overview accessed on 4 March 2024) and the Thiessen method, with a value of 24.47 mm. The three stations of Marand, Oshnavieh, and Mahabad have the highest rainfalls, which are more than the 25 mm average of the basin, but the stations of Ajabshir, Sahand, Shabestar, Salmas, and Bonab have a significant difference in terms of the average rainfall.
After receiving the coordinates and precipitation data from meteorological stations, the average precipitation during the existing statistical period was calculated for each month for each station. After randomizing the data of 16 stations and 12 months for each station (192 data rows) in Excel, 70% of the data were used for training (135 data values), and 30% of the data (58 data values) were used as test data. All models were trained and tested using Weka software (
https://ml.cms.waikato.ac.nz//weka/, accessed on 4 March 2024).
Table 2 introduces the input parameters for selecting scenarios and their short names.
The Correlation Matrix and Relief attribute Eval methods were used to select the input parameters in each scenario. This was performed according to the parameters’ correlation and characteristics with the average monthly rainfall.
Table 3 shows the correlation of each parameter with the average monthly rainfall with the Correlation Matrix method, where their absolute values are considered, and how to select the most effective parameters with the Relief attribute Eval method. This method ranks them according to the characteristics of the parameters using a specific approach. Finally, after selecting the parameters with the Correlation Matrix and Relief attribute Eval methods, eight scenarios mentioned in
Table 3 with different inputs were introduced. As can be seen, the first five scenarios were selected according to the Correlation Matrix method, and the next three scenarios were selected according to the Relief method.
Eight scenarios defined in
Table 3 were entered into software, and all five mentioned models were implemented in each.
2.2. WEKA Software
The WEKA workbench is a collection of machine learning algorithms and data preprocessing tools and the name stands for ‘Waikato Environment for Knowledge Analysis’. Outside the university, the WEKA is a flightless bird with an inquisitive nature found only on the islands of New Zealand [
13]. This software is among the modeling and data mining software with an easy and user-friendly user interface. This software is a collection of modern machine learning algorithms and data preprocessing tools and it is designed in such a way that existing methods can be quickly and flexibly tested on new data sets. It provides extensive support for the whole process of experimental data mining, including preparing the input data, evaluating learning schemes statistically, and visualizing the input data and the result of learning [
13]. These days, WEKA enjoys widespread acceptance in both academia and business and has an active community [
14].
After running the Weka software, we selected the data file from the explorer section, and then selected and ran different models from the classifier section.
2.3. Machine Learning-Based Models
2.3.1. Decision Tree Model (M5)
The M5 tree model was first introduced by Quinlan [
15]. The tree model is based on the method of decision and overcoming [
2]. The decision tree method with a supervised approach is a powerful model for data prediction and classification, a subset of machine learning and data mining methods. This model can be used for qualitative and quantitative data [
16]. Because the decision tree method is a graphical method, the interpretation of the results may be simpler than other methods [
17]. The formula for calculating standard deviation reduction (
SDR) is as follows:
In this relation,
T is a set of samples (cases) that are entered into each node,
Ti represents a subset of samples that have the
i-th potential test result,
Sd represents the standard deviation,
yi represents the numerical value of the target feature of sample
i, and
N represents the number of data values [
18].
2.3.2. Random Forest Model (RF)
Random forests (RFs) are a modern base tree type with classification and regression trees [
19]. A random forest has great potential to become a popular method for future classifications because its performance is comparable to other ensemble methods [
20]. As an ensemble (voting) algorithm, the random forest model generates several different decision trees as base classifications and applies majority voting to combine with the results of the original trees. The most important feature of random forests is their high performance in measuring the importance of variables to determine what role each variable plays in predicting the response. The classification power of a single decision tree and the correlation between original trees are important issues determining the general errors of random forest classification [
21]. To classify a new object, the input vector is placed at the end of each of the trees of the random forest, each tree resulting in a classification that is said to vote for that class. A random forest is selected from the classification with the most votes (among all the trees in the forest) [
19].
2.3.3. Support Vector Regression (SVR)
SVMs are machine learning algorithms designed by Vapnik et al. [
22]. An SVM is the pinnacle of neural network art based on statistical learning [
22]. The SVR method is an SVM regression model for non-linear regression problems. An SVM is a type of supervised learning system used for grouping estimating and estimating the fitting function of the data in regression problems so that the least error occurs in the grouping of the data or the fitting function. This method is based on the statistical learning theory, which uses the structural error minimization (SRM) principle and leads to a general optimal solution [
22]. This method includes a framework with two layers. The unweighted non-linear kernel is the first layer, which consists of a series of input variables on the support vectors. The second layer is the weighted sum of the main results [
7]. SVR is less prone to overfitting than other non-linear regression techniques since it concentrates on discovering the best hyperplane that generalizes well to new data [
23]. The support vector regression formula is as follows [
24]:
The data set M in the above relation includes the input vectors xi and the corresponding output yi. n represents the number of samples in the data set. A regression analysis aims to determine the f(x) function so that its prediction output has minimum error compared to the desired output. The regression function is represented by the relation yi = (xi) + δ where δ is a random error with distribution (0, σ2).
2.3.4. Gaussian Regression (GPR)
Gaussian process regression is a probabilistic, non-parametric supervised learning method to estimate non-linear and complex relationships between a set of input data and output data [
25,
26]. GPR is very useful for controlling non-linear data due to kernel functions. In addition, an important advantage of GPR is that it can provide a reliable response to the input data [
27]. Gaussian process regression models are based on the assumption that observations should carry information about each other. Gaussian processes are a way to specify the priority directly on the function space. This work is a natural generalization of the Gaussian distribution, whose mean and variance are vectors and matrices [
27]. The formula of the Gaussian process is as follows:
N (0,
σf2) is the normal distribution function noise with a zero mean and
σf2 variance. Regression is a search for f(x) [
28].
2.3.5. Nearest Neighbor Model (KNN)
The nearest neighbor model uses no predefined mathematical function to estimate the different variables. This model is one of the data mining methods, the general purpose of which is to classify and estimate the characteristics of a series of unknown data according to the maximum similarity of these data with the known data located in their neighborhood [
29,
30]. The first step in using this model is to find a method and a relationship to calculate the distance between the test data and the training data. The following Euclidean distance is usually used to determine this distance [
31]:
where
X represents the training data with specified parameters (
xi) to (
xn) and
Y represents the training data with the same number of specified parameters (
yi) to (
yn).
2.4. Model Performance Evaluation
2.4.1. Correlation Coefficient Index
This index (
R) has a dimensionless value whose best value equals one. The closer the value of this index is to one, the more correlation and a stronger relationship between real and modeled data. Equation (6) shows the index of the correlation coefficient:
2.4.2. Nash–Sutcliffe Efficiency
The Nash–Sutcliffe model efficiency coefficient (NSE) is used to assess the predictive skill of hydrological models. The Nash–Sutcliffe efficiency is calculated as one minus the ratio of the error variance of the modeled time series divided by the variance of the observed time series. In the situation of a perfect model with an estimation error variance equal to zero, the resulting Nash–Sutcliffe efficiency equals 1 (NSE = 1). Equation (7) shows the Nash–Sutcliffe efficiency [
32]:
2.4.3. Mean Absolute Error
The mean absolute error (MAE) is a common measure of forecast error in a time series analysis. In statistics, the mean absolute error measures the errors between pairs of observations that describe a phenomenon. Equation (8) shows the average absolute error:
2.4.4. Root Mean Square Error
RMSE is the root mean square of the errors. The effect of each error on
RMSE is proportional to the squared size of the error. Therefore, larger errors have a disproportionately larger effect on
RMSE. Equation (9) shows the formula for calculating the
RMSE error:
where
xi and
yi are real and modeled values, respectively,
n is the number of data values, and
and
are the average of real and modeled values.
3. Results
3.1. Performance of Selected Models
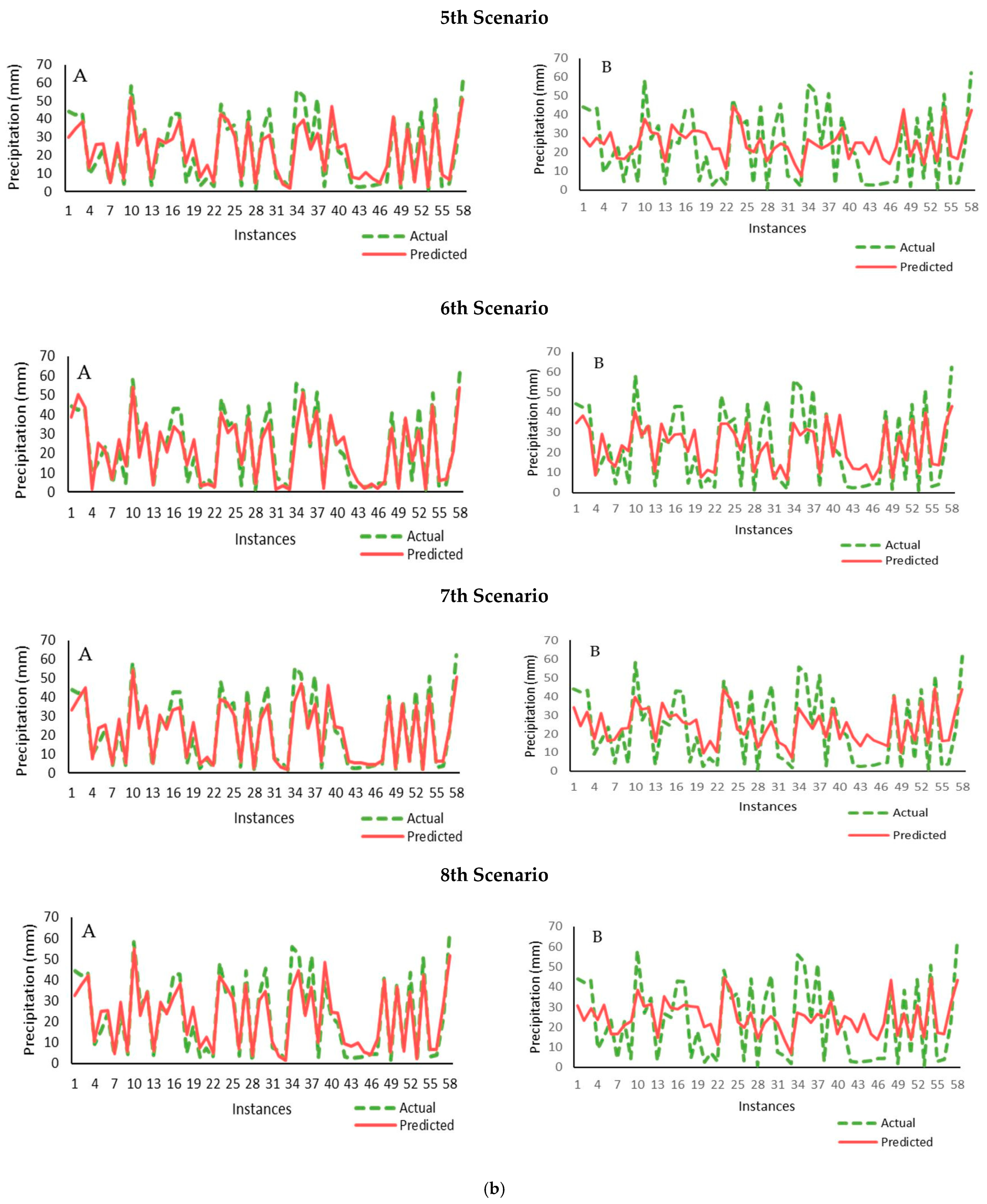
In the first scenario, the monthly index and latitude; the second scenario, the monthly index, latitude, and distance from Lake Urmia; the third scenario, the monthly index, latitude, distance from Lake Urmia, and distance to the Mediterranean Sea; the fourth scenario, the monthly index, latitude, longitude, distance from Lake Urmia, and distance to the Mediterranean Sea; and the fifth scenario, the monthly index, latitude, longitude, distance from Lake Urmia, distance to the Mediterranean Sea, and station height were entered as input data to five models. The inputs of the first five scenarios are designed under the Correlation Matrix method, but from the sixth scenario onwards, the inputs are selected under the Relief attribute Eval method. In the sixth scenario, the monthly index and distance from Lake Urmia; in the seventh scenario, the monthly index, latitude, altitude, and distance from Lake Urmia; and in the eighth scenario, the monthly index, longitude, latitude, altitude, and distance from Lake Urmia in five models under the title input data were entered. In all scenarios, the RF model was selected as the best model to predict the data to the greatest extent. The GPR was selected as the worst, with the remaining models sorted from the best to the worst for each scenario based on the correlation coefficient and Nash–Sutcliffe efficiency, as shown in
Table 4.
One method to assess the calibration and validation is through the use of scattergrams [
33,
34,
35] where predicted quantities are plotted against observed ones. In a scattergram, a regression straight line of the following form is also fitted through the data:
where
Pi and
Oi are the predicted and observed values. The slope γ is compared to the 1:1 slope (perfect match). The value of the slope γ is a measure of the over- (γ > 1.0) or under-prediction (γ < 1.0) of the model compared to the observed data. In addition, the square of the correlation coefficient R
2 of the regression line is computed. The lower the value of R
2 falls below 1.0, the worse the data correlation is, i.e., the greatest is the scatter of the data around the line. Therefore, the best calibration requires that values for both slope γ and R
2 be as close to 1.0 as possible [
36].
In the next step, a scatter diagram and a comparison were drawn for the best and worst models in each scenario, which can be seen in
Figure 3 and
Figure 4, respectively. The letters A show the performance of the best models, and the letters B show the worst models in each figure. A linear equation was drawn in scatter diagrams.
According to the scatter diagrams, in the third scenario (A), the equation line has the smallest distance with the points, indicating the best modeling. The γ value (i.e., slope value) is a significant parameter as it is a measure of the over- (γ > 1.0) or under-prediction (γ < 1.0) of the model compared to the observed data. In all scatter diagrams, the slope of the line is less than one, which indicates the under-prediction of the model in relation to the observational data.
In the third scatter diagram, the RF model has a slope equal to 0.889 and R2 equal to 0.912.
In the scatter diagrams, the vertical axis is the predicted data, and the horizontal axis is the actual precipitation data. In the profit diagrams, the vertical axis is the amount of precipitation, and the horizontal axis is an example of the amount of precipitation modeled.
3.2. Comparison Results of the Best Models of Each Scenario
In this step, the best model of each scenario, i.e., RFs, were selected to be compared with each other with the results presented in
Table 5. The highest correlation coefficient calculated in the comparison is 0.9676, which belongs to the RF model scenario number 3, and the lowest belongs to the RF scenario number 5 with a value of 0.9425. All the models have shown good performance and have been able to predict the rainfall data with high accuracy. Each has obtained a high correlation coefficient of 0.94, which shows its strength in rainfall modeling and the lowest amount of all errors. The RF model of scenario No. 3 has been obtained, whose inputs include the monthly index, latitude, and distance of the stations from Lake Urmia and the Mediterranean Sea. This shows that these factors have the greatest impact on precipitation in the Lake Urmia basin. Also, this result was obtained in scenario three using four parameters under this scenario and the RF model. This is an advantage because even with a few parameters, it created an accurate model with low errors and high efficiency for predicting the rainfall pattern in the basin of Lake Urmia. Rainfall modeling in this basin can be utilized in many ways in various issues, including engineering and managing water resources in the Lake Urmia basin and more fundamental planning and planning for the future.
The best RF models of different scenarios are compared and sorted from the best to the worst in this table according to the correlation coefficient. This table shows that the best random forest is under scenario number 3. The other scenarios, from the best to the worst in comparison, are scenario number 7, 2, 4, 1, 8, and 6, and finally scenario 5.
The Nash–Sutcliffe efficiency in scenario number 3 in the random forest model was the highest and equal to 0.911. Considering the high value of the correlation coefficient in scenario number 3 in the random forest model and the low amount of errors, the random forest model of scenario number three is the best.
Another mode was investigated for all scenarios and models. In this method, the RF model was assumed to be out of reach for these data. Then, by comparing the correlation coefficient between all models in all scenarios, the next best model, after removing all RFs, is the KNN model from scenario six and with neighborhood 3. Under this scenario, this model has an acceptable and reasonable coefficient with only two monthly index inputs and the distance from Lake Urmia.
3.3. Zoning Map of Rainfall Changes
Zoning maps of rainfall changes for real data, data obtained from the best modeling, and data from the best scenario and model (RF scenario number 3) were drawn with Arc GIS software and compared with each other as shown in
Figure 5a and b, respectively.
The IDW interpolation method was used to draw these maps to show the actual and predicted rainfall and ultimately shows that it has been able to model the precipitation accurately, and the result is very similar to the real precipitation map. Around Lake Urmia, especially east of the lake, there is very little precipitation in both real and modeled data. Shabestar and Miandoab stations have the lowest amount of precipitation.
4. Discussion
Today, rainfall modeling and forecasting are inseparable from engineering and water resources management. Therefore, both play an important role in managing water for irrigation, drinking water supply, and needs in the industrial and agricultural sectors. Precipitation in nature largely depends on spatial, temporal, and atmospheric variables, so it can be modeled by considering these parameters. Although various studies have been conducted to investigate precipitation in different parts of Iran, a comprehensive and detailed study and investigation have not been conducted in the Lake Urmia basin. In this study, the precipitation in the Lake Urmia basin was investigated completely and comprehensively with various models and spatial variables such as latitude and longitude, altitude, and station distance from the Mediterranean Sea and Lake Urmia. A relatively similar study was conducted in 2020 by Apaydin et al. [
7]. In the coastal region of Turkey, they used deep learning methods to model precipitation. They used artificial intelligence methods such as Gaussian process regression, support vector regression, the Broyden–Fletcher–Goldfarb–Shanno artificial neural network, M5, random forest, and long short-term memory. The study shows that the amount of precipitation can be estimated and a distribution map can be drawn by using spatio-temporal data and the deep learning and GIS hybrid method at points where the measurement is not performed.
In another study conducted by Garai et al. [
37] in 2024, algorithms based on complete ensemble empirical mode decomposition with adaptive noise combined with stochastic models like autoregressive integrated moving average and generalized autoregressive conditional heteroscedasticity; and machine learning techniques like a random forest, artificial neural network, support vector regression, and kernel ridge regression (KRR) have been proposed for predicting rainfall series. The proposed algorithms have been applied for predicting rainfall in three selected sub-divisions of India.
Another study was conducted by Parviz et al. [
38] to improve hybrid models by using an ensemble of linear and non-linear models. They used precipitation data of two weather stations in Iran, namely Tabriz, East Azerbaijan, and Rasht, Gilan, over 1992–2019. Preprocessing configurations and each of the Gene Expression Programming (GEP), support vector regression (SVR), and Group Method of Data Handling (GMDH) models were used as in the traditional hybrid models. They were compared against the proposed hybrid models with a combination of all these three models. The results showed that Theil’s coefficient, which measures the inequality degree to which forecasts differ from observations, improved by 9% and 15% for SVR and GMDH relative to GEP for the Tabriz station. Generally, the representation of the non-linear models within the improved hybrid models showed better performance than the traditional hybrid models.
The most important feature of this study was the relatively accurate prediction of monthly rainfall without the need for measured rainfall amounts. In this research, for the first time, precipitation modeling was performed using an artificial intelligence algorithm and spatio-temporal variables in the Lake Urmia basin, especially the distance from the sea, and machine learning algorithms, and for the first time, the effect of distance from nearby seas on the basin’s precipitation is investigated. Considering the monthly time index for different stations, monthly rainfall was modeled using five machine learning models under eight scenarios. In general, by examining and analyzing the results, the following can be pointed out:
The eight defined scenarios were entered into the Weka software, and the five mentioned models were implemented in each of these scenarios. In GPR and SVR models, three sub-branches of kernel functions, namely PolyKernel, PUK, and RBFKernel, were investigated in all scenarios. After examining and modeling these functions, the PUK function had the best result in both models. Therefore, the results of this function were introduced as the best results of these two models. For the nearest neighbor model, neighborhoods from one to ten were examined for each model in each scenario, and the neighborhoods with the best results in each scenario were selected. Among all the eight defined scenarios, the RF model always had the best performance, had the highest correlation with the real data, and had the lowest error under different scenarios. It was chosen as the most suitable model, showing its high rainfall modeling ability.
In contrast, the GPR model always performed the worst. The RF model of scenario number three had the highest correlation. This indicates the high accuracy of this model under this particular scenario for the available data. In this scenario, the input data included the monthly index, latitude, and distance from Lake Urmia and the Mediterranean Sea. Accurate precipitation modeling using its four parameters can be a suitable and acceptable result in modeling science. Therefore, these four parameters can be considered the most important influencing factors on the precipitation in the Lake Urmia basin or the climatic conditions. It is notable that this model also has the least error. The zoning maps of the changes showed this clearly as well. The monthly index, which indicates the number of the month, is affected by different rainfall in different seasons in different months. The latitude indicates this basin’s general location, climate, and influence.
The distance of the stations from Lake Urmia can indicate the influence of the precipitation air masses formed from Lake Urmia itself. Finally, the distance from the Mediterranean Sea, which indicates the effect of the rain-producing air fronts caused by it in the basin of Lake Urmia, is an important and influential factor in the precipitation of this basin.
Future studies may consider using this method for other points as well or using other deep learning algorithms. On the other hand, in the future, the effect of the open seas on the rainfall of coastal areas in other parts of the world can be investigated.
5. Conclusions
The most important feature of this research is the demonstration of accurate precipitation modeling based on monthly precipitation data without the need to measure precipitation. That is, rainfall modeling and rainfall maps can be drawn by interpolation in the GIS environment using the RF model under scenario three, which has relatively high accuracy for the points where rainfall measurements are absent. Although studies have been conducted in different parts of Iran, a comprehensive and detailed study has not been carried out in the Lake Urmia basin. Therefore, in this study, precipitation in the Lake Urmia basin was investigated in a complete and comprehensive manner with various models, and spatial variables such as the latitude and longitude, altitude, and station distance from the Mediterranean Sea and Lake Urmia were used to model precipitation. This study also examined the effect of proximity of nearby seas on precipitation and subsequent fluctuations in the Lake Urmia basin.
Lastly, considering the monthly time index for different stations, monthly rainfall was modeled using five machine learning models (M5 decision tree model, RF (random forest) model, SVR model, GPR (Gaussian regression) model, and KNN model) under eight different scenarios. Among all the eight defined scenarios, the RF model always had the best performance and was able to have the highest correlation with the real data and the lowest error under different scenarios, and was thus chosen as the most suitable model. The RF model of scenario number three was the best among the eight scenarios and had the highest correlation with a rate of 0.968. In this scenario, the input data included four parameters: the monthly index, latitude, and distance from Lake Urmia and the Mediterranean Sea. The monthly index, which indicates the number of the month, is affected by different rainfall in different seasons in different months. The latitude indicates the general location and climate of this basin and its influence. The distance of the stations from Lake Urmia can indicate the influence of the precipitation air masses formed from Lake Urmia itself. Finally, the distance from the Mediterranean Sea, which indicates the impact of the rain-producing air fronts caused by it in the Lake Urmia basin, is an important and influential factor in the precipitation of this basin. Accurate modeling of precipitation using its four parameters can be a very suitable and acceptable result in modeling science. Therefore, these four parameters can be considered as the most important influencing factors on precipitation in the Lake Urmia basin or climatic conditions.
This new approach can now be used in the engineering, planning, and management of water resources in the Lake Urmia basin, and important steps can be taken to revive the lake. One major limitation of this study is that the results cannot be generalized to other basins due to the unique climatic conditions of each region. However, the same approach could be followed in other basins. Additionally, the complexity of the machine learning models and tools used in this study may make it difficult for non-experts to apply them, which is a disadvantage from an applicable standpoint.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







