Abstract
The widespread use of pesticides, such as atrazine and malathion, in agricultural systems raises significant concerns regarding the contamination of groundwater, which serves as a critical resource for drinking water. This study applies machine learning techniques to predict the concentrations of atrazine and malathion in groundwater across Georgia, USA, using 2019 data. A Random Forest classifier was employed to integrate various environmental and demographic factors, including pesticide application rates, precipitation, lithology, and population density, to predict pesticide contamination in groundwater. The models demonstrated high training accuracies of 100% and moderate average testing accuracy of 55% for atrazine and 60% for malathion across five iterations. The low test accuracy of the model, ranging from 50% to 75%, is likely due to overfitting, which can be attributed to the small dataset size and the complex nature of pesticide-contamination patterns, making it challenging for the model to generalize to unseen data. Feature importance analysis revealed that average pesticide usage emerged as the most influential factor for atrazine, while aquifer lithology and precipitation played crucial roles in both models. These results provide valuable insights into the dynamics of pesticide contamination, highlighting areas at greater risk of contamination. The findings underscore the importance of integrating environmental, geological, and agricultural variables for more effective groundwater management and sustainable agricultural practices, contributing to the protection of water resources and public health.
1. Introduction
Pesticides are an integral component of modern agriculture, playing a pivotal role in protecting crops from pests, diseases, and invasive weeds [1,2]. Their widespread use has significantly enhanced food security by bolstering yields and mitigating post-harvest losses. Indeed, global pesticide usage now exceeds 5.6 billion pounds annually, with more than 1 billion pounds applied each year in the United States alone. Although such pervasive application is central to sustaining agricultural productivity, it also heightens concerns regarding health and environmental repercussions. In regions with limited resources and regulatory oversight, inadequate pesticide control measures often precipitate severe human exposure issues. An estimated 25 million agricultural workers worldwide suffer unintentional pesticide poisoning annually, reflecting stark inequalities in global agricultural safety [3]. Even in countries with tighter regulations, such as the United States, research from the Agricultural Health Study indicates that 16% of pesticide applicators experienced at least one poisoning event or unusually high exposure episode in their lifetime. Beyond human health, the ecological costs of pesticide usage are equally troubling. These chemicals often reach aquatic systems through surface runoff, contaminate vital groundwater resources via infiltration, and bind to soil particles, thereby disrupting soil biodiversity. Pesticides such as atrazine—a widely applied herbicide in corn production—and malathion—an insecticide with known neurotoxic effects—are frequently detected in water bodies and groundwater, representing a long-term risk to ecosystems and community health [4,5,6]. The result is often a degradation of aquatic habitats, a loss in biodiversity, and chronic exposure hazards for human populations relying on contaminated groundwater. In the face of these challenges, it is increasingly critical to balance the utility of pesticides with the imperative to preserve environmental integrity and public health. One of the principal difficulties in managing pesticide contamination stems from the multifaceted nature of its environmental transport and persistence. Factors like rainfall intensity, soil type, and groundwater table depth influence how pesticides are mobilized and dispersed through the environment [5,7]. This complexity makes prediction—and, consequently, mitigation—of pesticide pollution a daunting task. Traditional assessment methods may struggle to capture the interplay of these variables, thereby complicating efforts to enforce regulations, focus monitoring efforts, and implement remediation strategies effectively.
In this context, machine learning offers a promising avenue for deciphering intricate, multivariable relationships. Models such as Random Forest Classification can integrate extensive datasets encompassing precipitation patterns, lithology, population density, and pesticide usage, among other factors [8,9]. By identifying patterns and key drivers of contamination, these data-driven approaches can enhance predictive accuracy, guide more focused testing of water resources, and foster informed decision-making for environmental protection, public health interventions, and policy development [10].
As one of the top agricultural states in the southeastern United States, Georgia is renowned for its production of staple crops like peanuts, cotton, corn, and a variety of fruits and vegetables [11]. High-value crops of this nature often rely heavily on pesticide inputs: herbicides, insecticides, and fungicides, to ensure high yields and maintain competitiveness in national and global markets. This intensive use, while boosting agricultural output and underpinning the local economy, also introduces an increased risk of agrochemical runoff and infiltration. The state’s warm and humid climate supports a broad spectrum of pest species and plant pathogens, driving more frequent and sustained pesticide applications throughout growing seasons. Additionally, Georgia’s hydrogeological setting, characterized by variable soil profiles, diverse lithological conditions, and varying depths to groundwater, affects the mobility and persistence of these contaminants [12]. The presence of sandy soils in some regions can facilitate rapid infiltration, allowing pesticides to reach and persist in aquifers. In other areas, clayey soils or complex subsurface strata may slow water movement but potentially prolong contaminant retention and magnify chronic exposure risks over time. Groundwater in Georgia is a critical natural resource serving domestic, agricultural, and industrial water needs. Many communities rely on private wells and local aquifers for drinking water, making them vulnerable to contamination from nearby agricultural activities. Rural populations, in particular, may face heightened exposure if well monitoring and water treatment measures are not systematically implemented. This scenario underscores the importance of understanding both the scale and distribution of pesticide use, as well as the environmental processes governing contaminant transport and degradation.
Georgia is one of the leading agricultural states in the southeastern United States, producing high-value crops such as peanuts, cotton, corn, and various fruits and vegetables. The widespread use of pesticides in these agricultural systems raises significant concerns regarding groundwater contamination. Since groundwater supplies 92% of rural drinking water resources in Georgia, assessing the risks of pesticide infiltration is essential for safeguarding public health and ensuring effective environmental management [13]. Additionally, Georgia’s diverse hydrogeological conditions, including sandy soils that facilitate rapid infiltration and clayey formations that may retain contaminants, make it an ideal case study for evaluating groundwater pollution risk using machine learning-based modeling approaches. Various environmental models have been widely used to assess groundwater vulnerability by assigning weighted scores to hydrogeological parameters [14,15,16] (Table S1). While effective, these models often rely on predefined weight assignments that may not fully capture the complexity of contaminant transport. Machine learning, particularly the Random Forest classifier used in this study, provides a data-driven alternative that dynamically learns from contamination patterns and environmental conditions. By integrating multiple environmental predictors, machine learning enhances groundwater pollution risk assessment, offering improved accuracy and adaptability compared to traditional approaches. This study aims to apply a machine learning model to predict atrazine and malathion concentrations in the groundwater of Georgia, USA, using 2019 data.
The Random Forest Classifier was considered because of its robust nature in handling datasets with features related in a complex or diverse manner [17]. Two separate models were developed: atrazine and malathion. These models were designed to account for differences in environmental and chemical interactions between the two pesticides. By elucidating the most influential factors and accurately estimating contamination levels, this work contributes actionable insights for environmental monitoring, public health interventions, regulatory efforts, and the promotion of more sustainable agricultural practices to mitigate the impacts of pesticide-related contamination.
2. Materials and Methods
2.1. Data Acquisition
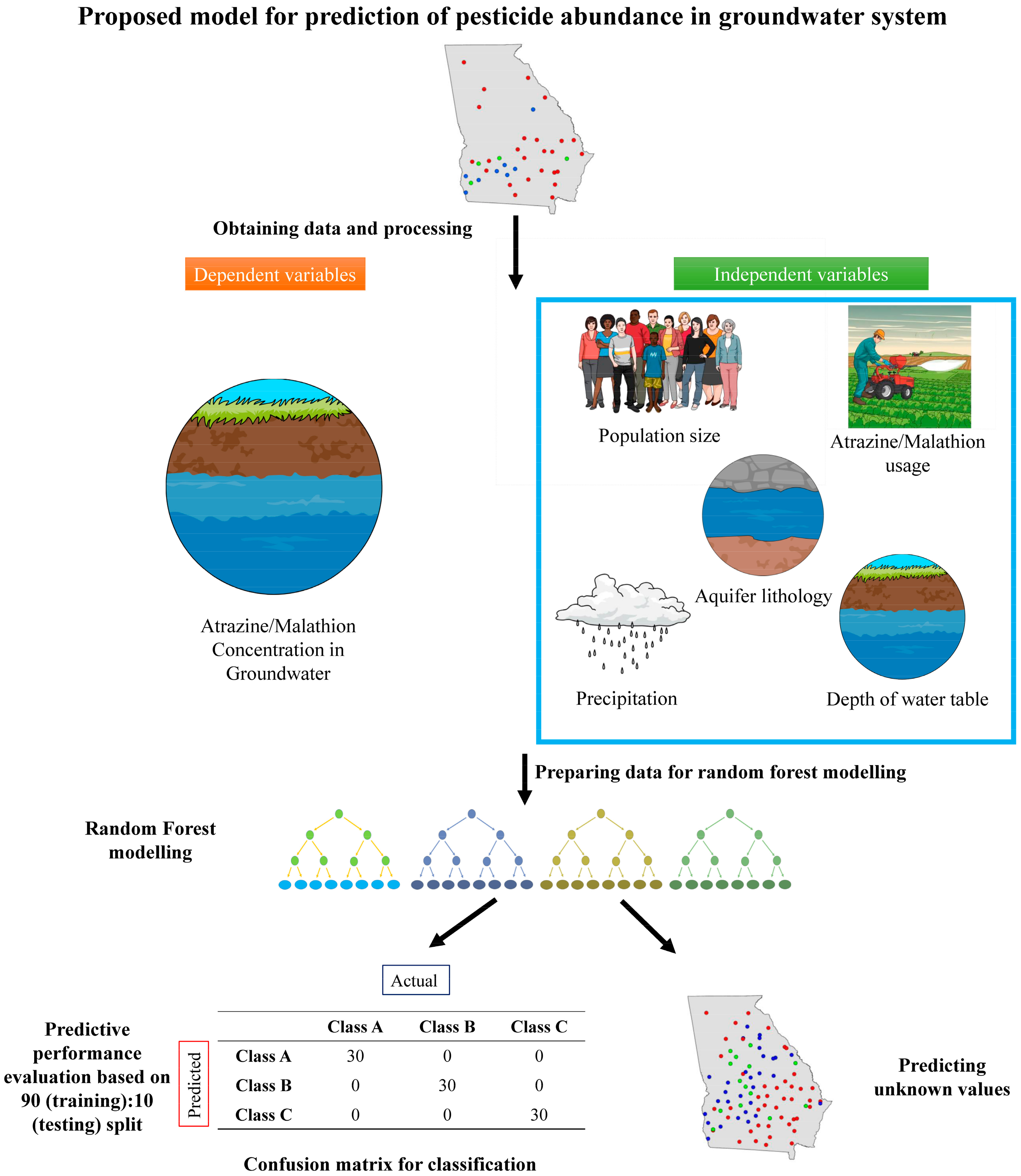
Pesticide usage data for atrazine and malathion were obtained from the U.S. Geological Survey (USGS) National Water Quality Assessment Program (NAWQA) database for the year 2019 [18]. Aquifer lithology was also obtained from the USGS dataset for the state of Georgia. County-level groundwater pesticide concentrations for atrazine and malathion in Georgia during 2019 were compiled from the same dataset. Population data were retrieved from the U.S. Census Bureau [19] via the data.census.gov portal. Precipitation data for Georgia in 2019 were obtained from the National Oceanic and Atmospheric Administration (NOAA) National Centers for Environmental Information (NCEI) [20]. Because pesticide usage and groundwater quality observations were not uniformly available for all regions of the state, only counties with complete records for the following parameters were included in the analysis: (1) population, (2) depth to water table, (3) precipitation, and (4) pesticide usage. These parameters constitute the independent variables, whereas the measured groundwater concentrations of atrazine and malathion serve as the dependent variables (Figure 1).
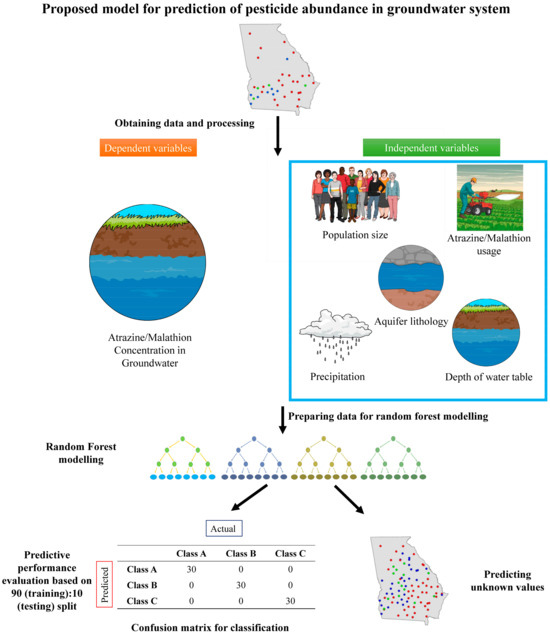
Figure 1.
Overall pipeline for random forest prediction of pesticide concentration in groundwater. The pipeline overview is mentioned in the Supplementary Information.
2.2. Dataset Preparation
The dataset utilized in this study comprised environmental and demographic variables (precipitation levels, water table depth, lithological classifications, population density, and pesticide application data) chosen for their direct relevance to the transport and contamination of pesticides in groundwater systems [21]. The first stage of this study involved meticulous data preparation to ensure the dataset’s suitability for machine learning applications. Multiple data sources representing distinct temporal and geographical contexts were integrated to create a single, unified dataset for model development and evaluation. In order to standardize the dataset, pesticide usage metrics and frequencies were averaged when appropriate, thereby maintaining consistency across variables.
Following this consolidation step, systematic reorganization and categorization of the raw data were conducted to meet the input requirements of the selected machine learning algorithms. Specifically, data were grouped by county, and relevant factors (such as precipitation and lithological information) were aligned with pesticide occurrence, the primary response variable. To address missing and incomplete data, mean imputation methods were applied, thus preserving dataset comprehensiveness [22]. Outlier detection and treatment were also carried out, particularly in the aquifer lithology datasets. Two aquifer systems (Floridan and Claiborne-Cretaceous) were successfully incorporated. The Blue Ridge aquifer system, however, could not be included in the model training phase due to a lack of pesticide occurrence data for counties overlapping this lithology. Since aquifer lithology is a categorical variable, one-hot encoding was conducted to separate them into two separate variables (since two aquifer systems were considered in this analysis). However, for evaluating the feature importance, the importance value for each aquifer type (separated during one-hot encoding) was added and renamed as the overall importance of aquifer lithology.
Once the data cleaning and restructuring processes were complete, the final dataset was converted into CSV format to enhance compatibility with Python (v. 3.9.4) -based machine learning libraries used in the Google Colab environment [23]. The dataset was then partitioned into training and testing subsets. This approach allowed a thorough evaluation of the predictive models under development by using previously unseen data, thereby enhancing the generalizability of the results across various settings.
Given the skewed distribution of pesticide concentrations and absence of absolute quantification of pesticide concentrations for some of the datapoints (data were present in ranges), a binning procedure was employed to facilitate better discrimination among different levels of contamination [24]. For the atrazine model, the concentrations were assigned to three categories: low, moderate, and high, using bin edges of [0, 0.00608, 0.007, 0.2296] and corresponding labels of [0, 1, 2]. This approach alleviated class imbalance and allowed the model to distinguish contamination levels more effectively. The pd.cut function [25] was used to create these bins, and the resulting categorical values were subsequently converted into a numeric format for use in a Random Forest classifier. The distribution of these bins was examined using pd.value_counts(bins) to confirm accurate categorization.
Likewise, the malathion model employed similar binning strategies, with bin edges set at [0, 0.016, 0.02509, 0.027] and labels [0, 1, 2], thereby categorizing the pesticide concentrations into low, moderate, and high levels. Again, the binned outcomes were transformed into numerical arrays for input into the Random Forest model, and pd.value_counts(bins) were used to verify the accuracy of the binning. Overall, this binning process was integral in addressing skewed distributions and ensuring more robust model performance.
To further standardize the predictors, continuous variables such as precipitation levels and depth to the water table were normalized using Scikit-learn’s StandardScaler [26]. Categorical factors, such as lithology classifications, were encoded into numerical formats suitable for machine learning [27]. Missing values, although few, were imputed to produce a complete dataset, and outliers were checked to prevent distortion during model training. This comprehensive data preprocessing protocol was essential to enhance the accuracy and reliability of subsequent predictive modeling.
2.3. Model Development and Cross-Validation
The final predictive model for malathion was trained using pesticide occurrence data from 37 counties in Georgia, while the model for atrazine was based on data from 31 Georgia counties. Both models were developed using the Random Forest algorithm in conjunction with a systematic, iterative evaluation methodology. These predictive models were developed using the Random Forest algorithm, based on a systematic and iterative evaluation methodology. It exploits the following functionalities of the Python library Scikit-learn: efficient data segregation, model training, and performance assessment for both models [25]. Crucial parameter selections are systematically justified with the use of graphical analysis for visual assessment of model efficacy in facilitating informed decisions.
The dataset was split into 90% training and 10% testing sets by the train_test_split function of Scikit-learn [28]. To better evaluate the reliability of the models, this division was performed five times. The random_state parameter was systematically altered to i + 25, with i being the iteration index. This adjustment ensures that every split of the data includes enough variation to reproduce different operational conditions while maintaining the reproducibility of the experiments. The choice of i + 25 allows for greater variability in the data splits, which is necessary if initial tests showed that smaller steps in the random seed were not enough to produce satisfactory diversity in the training and test datasets. The Python script for the model can be found in the following link: https://github.com/geomicrobiome/pandey2025-randomforest (last accessed on 9 March 2025).
A core part of the model configuration is deciding how many decision trees (n_estimators) to use. The decision to move forward by using 50 trees in the malathion model and 250 trees in the atrazine model was regarded as a trade-off between computational performance model efficiency. The data from malathion were such that relationships between the features and the respective target variable were more simplistic and hence allowed a more stable model with fewer trees. The improvement beyond 50 trees demonstrated minimal development in performance and so retains this choice as efficient and effective. On the other hand, the atrazine dataset had more complex feature-target relations, necessitating a bigger ensemble of 250 trees to capture such patterns well and reduce the variance in predictions. This approach ensured that every model achieved its performance targets while also optimizing the use of computational resources.
The model evaluation process required five independent iterations as the process of evaluation was dependent on independent data partitions of the dataset. In each iteration, a 90–10% train-test split was used. The reason for using a 90:10 split was the reduction in training data used to enable sufficient data for test performance evaluation. Using a very small test set, such as 5%, would provide unstable accuracy values in performance measures, while a large test set of 20% to 30% would decrease training data to the point of being below acceptable thresholds, given the dataset size. Each iteration added randomness through random_state = i + 25 but maintained data partition reproducibility because it included variance factors. The testing method performed multiple passes to analyze how different split combinations affected model performance.
After extensive preparation and systematic organization of the basic dataset for predictive modeling, an important test of practical effectiveness is applying the Random Forest models to a new dataset. Although the newly acquired dataset covers comparable characteristics of precipitation rates, depth of the water table, and lithological classification, they were processed to strictly conform to the standardized format devised during the initial stages of the research. The alignment being considered is critical to the good execution of the models, for it makes sure that the input data represent the conditions under which the models were developed, improving the reliability of the resulting predictions.
A thorough investigation into how these models adapt to alternative environmental conditions not featured in the training was conducted. Predictions on new data are then meticulously analyzed to estimate the accuracy of models and provide deeper insights into their robustness and portability. This type of analysis is very important, for it allows going into the depths of the functional behavior of the models in different geographical regions and under diverse environmental contexts. One final model was made for malathion where all the available data were used to train the model without any split in the dataset. A similar model was made for atrazine. These predictive tools were tested through application in a new dataset, consisting of 52 counties of Georgia for malathion as well as 50 counties of Georgia for atrazine with unknown pesticide concentrations (Tables S4 and S5). Therefore, the model assessed their performance within real-world environmental assessment and management contexts.
To visualize the predicted data, spatial plotting was performed using the ArcGIS online platform. Point data were generated for both predicted and actual malathion and atrazine concentrations by incorporating the coordinates of data points along with their respective concentration values.
Given that the occurrence of contaminants in groundwater is non-uniform across different regions, certain geographical areas may have disproportionately low or high contamination levels. To mitigate the effects of this imbalance, the study employed binning techniques to categorize pesticide concentration levels into low, moderate, and high classes, thereby reducing extreme variations in dataset distribution. The absence of absolute values for some independent variables may have impacted model accuracy. Specifically, certain environmental factors, such as pesticide application rates, were only available at county-level resolution, rather than site-specific or well-level granularity. In cases where pesticide concentration data were reported in ranges rather than continuous values, predictive precision was inherently constrained. The study implemented data processing to ensure consistency in data representation.
3. Results and Discussion
The Random Forest classifier was systematically evaluated over multiple runs to assess its ability to predict two selected pesticides, atrazine and malathion, in groundwater. In each run, the dataset was randomly partitioned into training and testing subsets, and predictive accuracy was recorded for both. The influence of various predictors on pesticide concentrations was also examined.
3.1. Model Performances
The classifier demonstrated a notable ability to predict the presence of atrazine and malathion, with testing accuracies ranging from 50% to 75% across five iterations (Table 1, Tables S2 and S3). The mean accuracy for atrazine was 55%, while that for malathion was 60%. These moderate accuracy levels likely reflect the complexity and imbalance of data involved in modeling contaminant distributions in groundwater. The variability observed in testing accuracy highlights the challenge of generalizing model performance to new data. The model exhibits a significant variation in the accuracy of its prediction, achieving a training accuracy of 100% and also, in comparison, a moderate range of trial accuracy between 50% and 75% for simultaneous atrazine and malathion prediction. This variation is mainly due to overfitting, a consequence of which the model successfully remembers the training set but cannot put into practice the current understanding obtained in order to recent datasets. The composition of the dataset, which used a range rather than precise measurements of pesticide concentrations, was one of the major subscribers to this complication. A number of pesticides have been registered in the scope (e.g., 0.016–0.025 mg/L), as any continuous numeral standards introduce uncertainty in the classification of information at different stages of contamination (low, moderate, and high). The use of range-based encoding revealed ambiguity in the study method since the actual concentration of a given statistical apex may fall anywhere within the range specified, and therefore, the classification was thrown out as being inaccurate. In addition, the data imbalance is also expected to increase the model’s shortcomings, as a few degrees of contamination are underrepresented in the dataset, causing the model to discriminate between the general classes. The model also deals with cases where sustainable elements do not synchronize effectively with expected contamination tendencies, such as counties together with increased pesticide application rates yet minimal record contamination tiers, expected due to variations in aquifer media or pesticide degradation rates, which were not captured in all aspects by the selected feature.

Table 1.
Details of classification-based random forest models showing accuracies for training and validation.
To improve generalization and mitigate overfitting, a larger and more representative dataset would be beneficial, as it would capture a broader range of environmental conditions and reduce model bias. Future research could also incorporate additional environmental variables pertinent to pesticide contamination. These improvements have the potential to reduce performance variability, enhance overall prediction accuracy, and increase confidence in the model’s applicability to diverse real-world scenarios.
3.2. Feature Importance Analysis
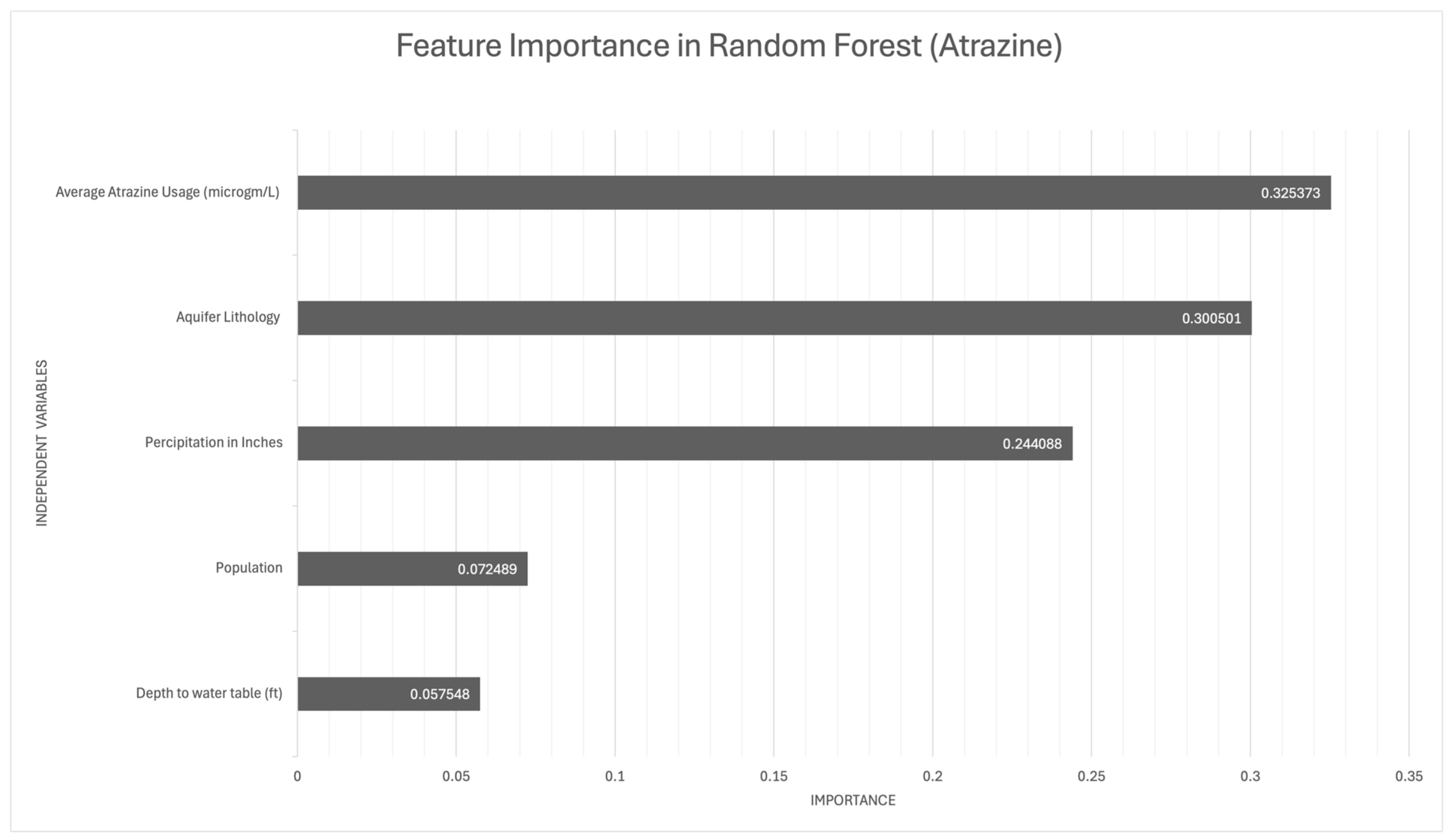
An analysis of feature importance revealed key variables that influence the presence of atrazine and malathion in agricultural settings (Figure 2 and Figure 3). For atrazine, average atrazine usage emerged as the most influential feature, indicating a direct relationship between its level of application and its environmental occurrence. Aquifer lithology and precipitation were also significant, highlighting the combined impact of geological and meteorological factors on atrazine’s distribution and persistence.
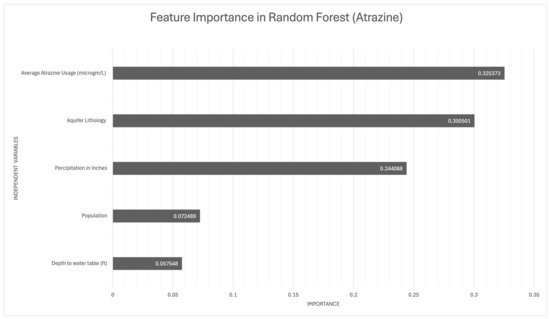
Figure 2.
Important predictor variables in the random forest models for atrazine occurrence in groundwater.
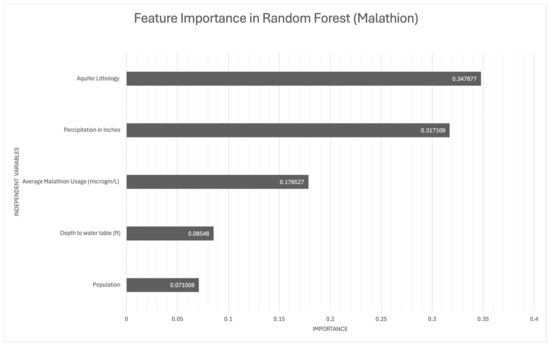
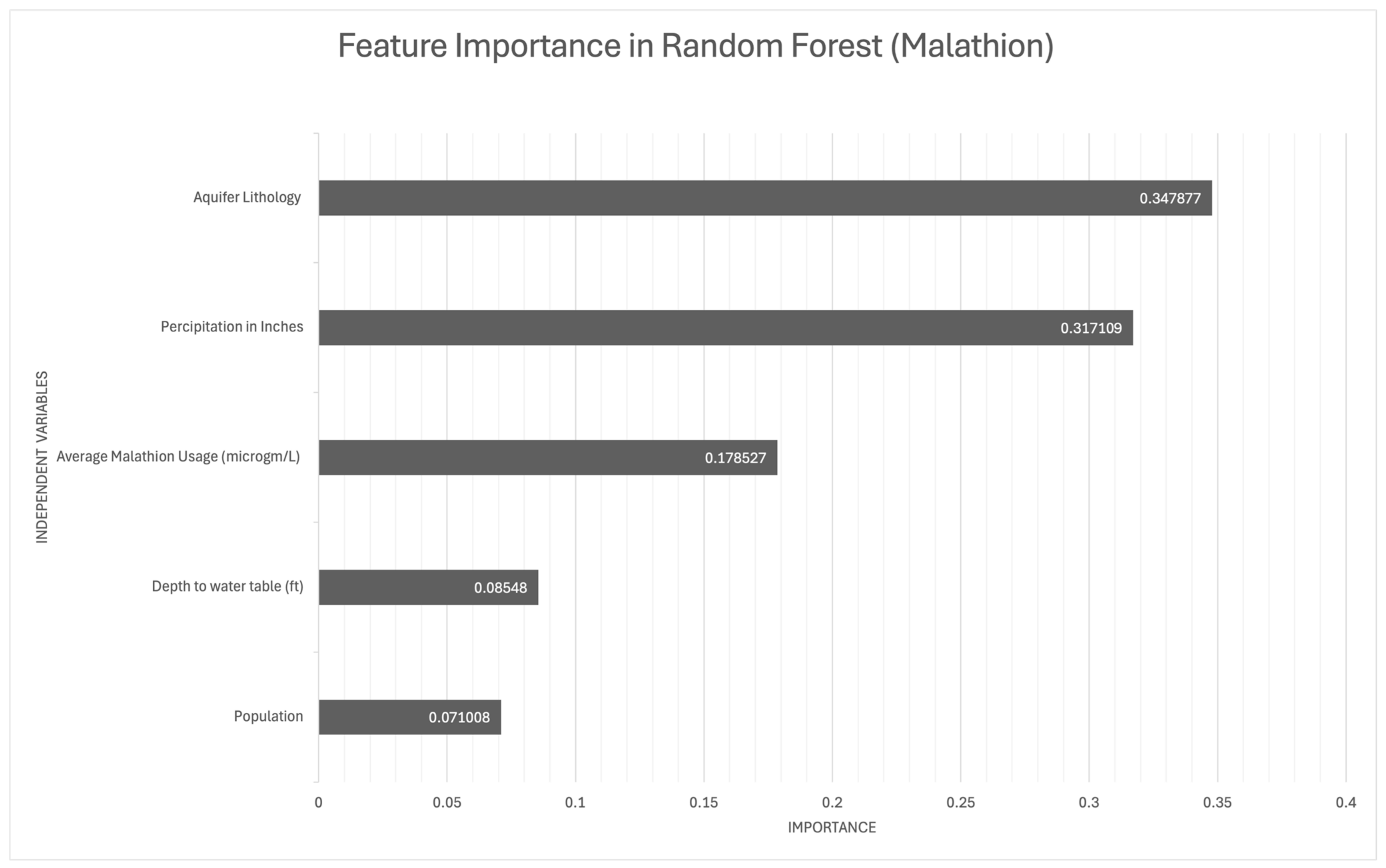
Figure 3.
Important predictor variables in the random forest models for malathion occurrence in groundwater.
In the malathion model, aquifer lithology played the most critical role, underscoring how subsurface geological characteristics affect the environmental fate of malathion. Average malathion application and precipitation were also highly influential, suggesting that the interplay between usage and weather conditions significantly shapes malathion’s transport. Although the population and depth to water table were less influential, they still contributed to the models, indicating their secondary yet notable impact on pesticide dynamics.
These findings underscore the complex interactions among anthropogenic, geological, and climatic variables that govern pesticide behavior in the environment. They further emphasize the need for holistic environmental risk assessments that account for the wide range of factors affecting pesticide fate. Future studies should expand the range of predictors to include broader environmental, social, and economic parameters, enabling more comprehensive management practices to protect groundwater and promote sustainability.
3.3. Pesticide Occurrence Predictions Across Georgia
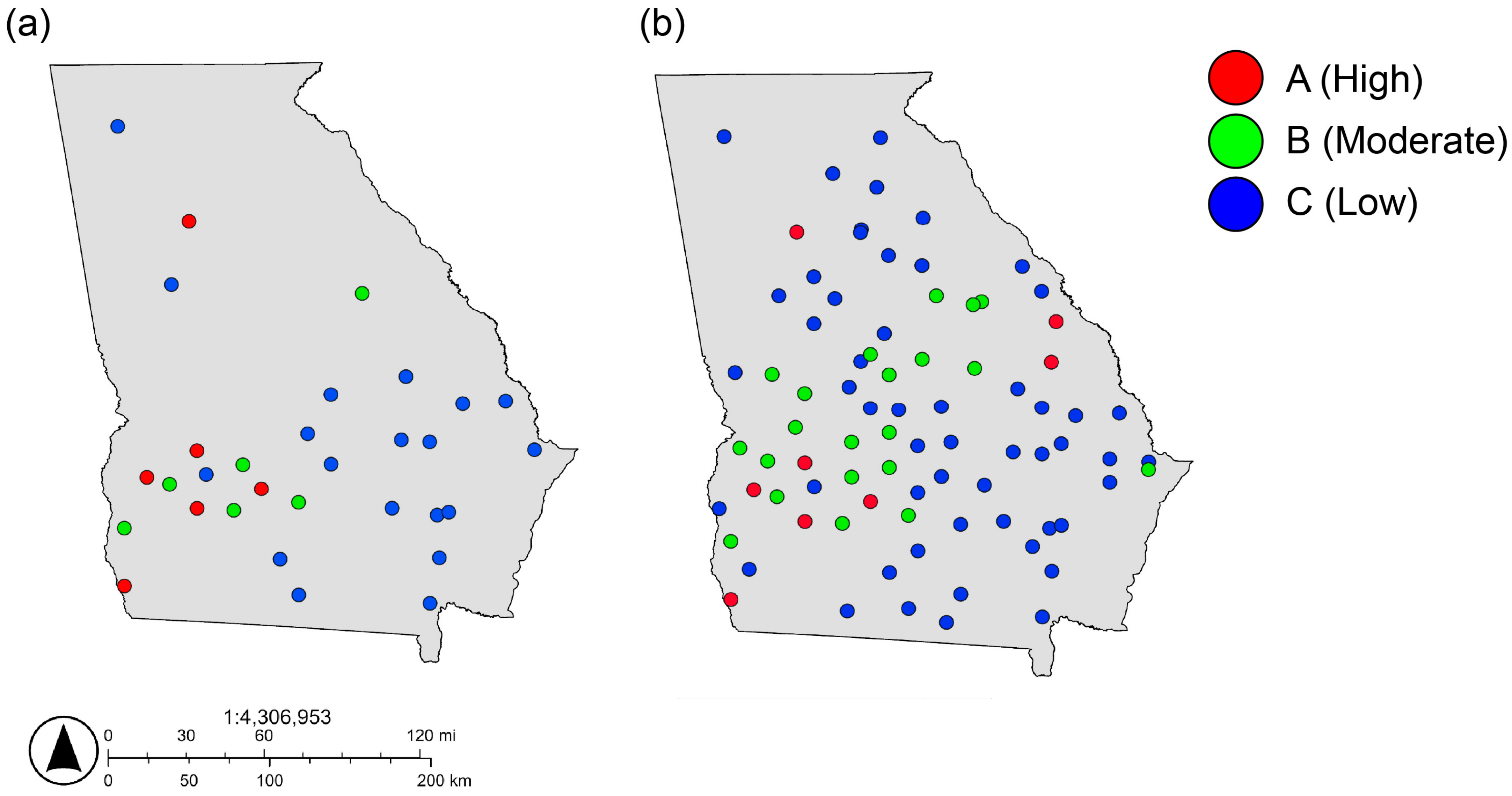
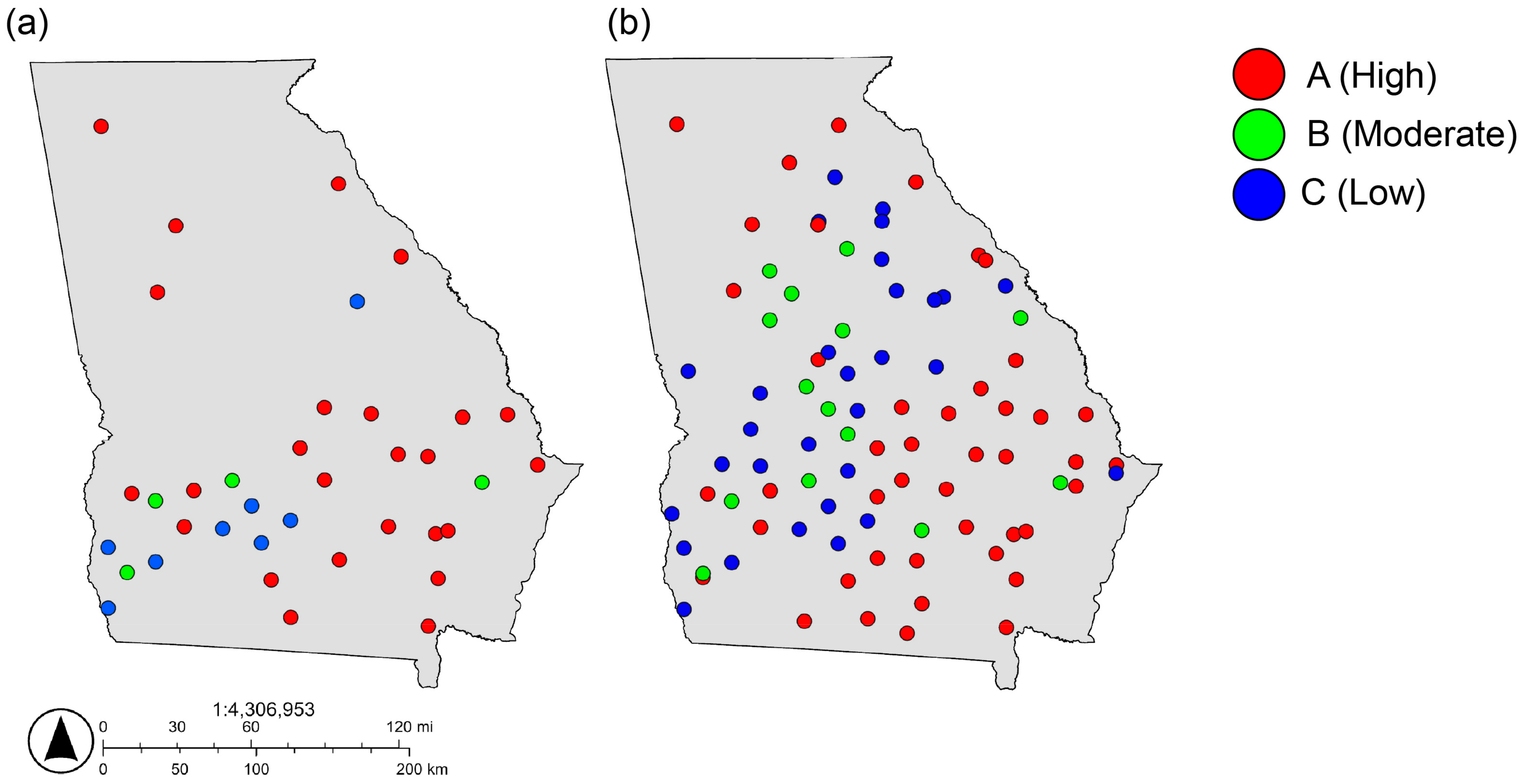
In a broader context, the robustness and adaptability of the Random Forest models for atrazine and malathion demonstrate their practicality for diverse environmental applications (Figure 4 and Figure 5; Tables S4 and S5). These models can reliably perform on new datasets, providing essential support for policymakers and helping to guide strategic decisions on pesticide management and groundwater protection.
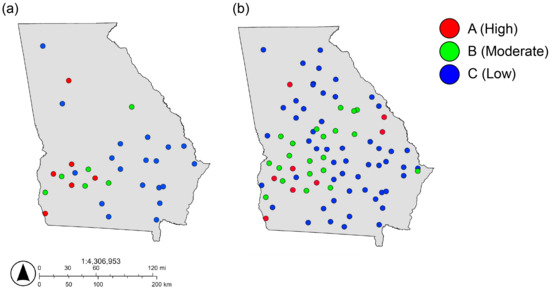
Figure 4.
Map showing the spatial distribution of (a) actual atrazine concentration and (b) predicted atrazine concentration in groundwater in Georgia.
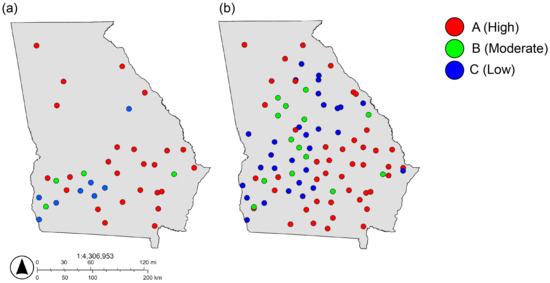
Figure 5.
Map showing the spatial distribution of (a) actual malathion concentration and (b) predicted malathion concentration in groundwater in Georgia.
When applied at regional or national levels, these models can identify areas at higher risk of pesticide contamination, thus enabling stakeholders to allocate resources more effectively for monitoring and regulation. By highlighting critical zones, mitigation efforts can be targeted with greater precision. The flexibility of these models allows for continued refinement. Including additional predictive variables or employing advanced machine learning techniques may lead to improved accuracy under specific environmental conditions, and real-time data acquisition can further enhance their utility by responding rapidly to evolving agricultural practices and weather patterns.
Although the dataset is not continuous across the study area and exhibits considerable skewness, the model’s robust performance suggests that if future data were more uniformly distributed and approximated a normal distribution with continuity across all independent parameters, the model could reliably predict not only pesticide occurrence but also broader chemical contaminant, particularly when accounting for advective transport in groundwater systems.
Application of these predictive models to new datasets at this junction brings out their ability to act as robust tools in the field of environmental management, able to adapt and cope with the assessment of a wide array of conditions. This provides the basis for continued improvement and updates within the modeling process and therefore assures the longevity of their utility and applicability amidst the fluidity that characterizes both environmental issues and data ecosystems. By using a cyclical framework of implementation, assessment, and enhancement, it is possible to hone the predictive models into robust tools for environmental monitoring and decision-making. Moreover, with better datasets, regression-based models can be made to accurately predict pesticide concentration in the groundwater systems.
This study’s focus on predicting pesticide contamination in groundwater is closely aligned with sustainable development goals (SDG 6.1), which aim to ensure universal and equitable access to safe and affordable drinking water. Groundwater serves as a critical drinking water source for millions of people worldwide, and contamination by pesticides such as atrazine and malathion directly threaten public health and water quality. By employing machine learning models specifically Random Forest algorithms to predict contaminant occurrence, the research provides valuable insights into where and under what conditions pesticide contamination is most likely to occur. This information is crucial for guiding mitigation strategies, allocating monitoring resources more effectively, and informing the development of policies that safeguard water sources. As a result, the outcomes of this study support the larger goal of protecting drinking water supplies and promoting sustainable management of water resources in both rural and urban settings.
4. Conclusions
The demonstrated accuracy of the Random Forest classifier, despite challenges posed by data imbalances and overfitting, underscores the significant potential of machine learning models to contribute to proactive groundwater protection strategies. In particular, the identification of aquifer lithology, pesticide usage rates, and precipitation patterns as critical predictors sheds light on the multifaceted nature of pesticide migration and accumulation in groundwater systems. These findings emphasize the need for a holistic approach that integrates both environmental variables (e.g., geological and hydrological conditions) and anthropogenic factors (e.g., agricultural intensity, and pesticide application practices) to fully understand how contaminants move and persist in aquifers. Although the study’s relatively small and uneven dataset contributed to the variability in testing accuracies, these results nonetheless provide a valuable framework for authorities and policymakers to pinpoint high-risk regions and design targeted interventions such as limiting pesticide usage in vulnerable areas or refining agricultural best management practices aimed at reducing the infiltration of harmful chemicals into water supplies.
When scaled up and applied in broader contexts, this modeling approach stands to make a substantial contribution to meeting SDG 6.1, which focuses on ensuring the availability of safe and affordable drinking water for all. More extensive and representative datasets, combined with real-time data acquisition and refined model architectures, could enhance predictive power and accommodate changing environmental and agricultural conditions. This increased accuracy would better equip decision-makers to allocate resources effectively, prioritize monitoring in at-risk areas, and enact evidence-based policy reforms that strengthen groundwater protection. Moreover, incorporating additional variables such as socio-economic indicators, land-use patterns, and detailed climatic projections would allow for a more comprehensive assessment of contamination risks, leading to more nuanced and adaptive management strategies. Ultimately, fostering closer collaboration among environmental scientists, data analysts, policymakers, and other stakeholders will be critical for continuously refining this machine learning tool and embedding it into integrated water resource management plans. By doing so, these predictive models can serve as a catalyst for sustainable groundwater management, safeguarding a crucial drinking water source for current and future generations. Future research will focus on expanding the dataset beyond Georgia to improve model generalizability across diverse regions. Additionally, direct groundwater sampling and analysis of atrazine and malathion will be conducted to validate model predictions. Further, developing regression-based models will enable the prediction of absolute pesticide concentrations, enhancing the precision of groundwater contamination assessments.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/w17060879/s1, Supplementary Information File S1. Table S1. Recent Studies on Groundwater Contamination and Machine Learning-Based Predictive Modeling. Table S2. Details of cross-validation models for predicting atrazine concentration in groundwater. Table S3. Details of cross-validation models for predicting malathion concentration in groundwater. Table S4. Predicted values for atrazine concentration in groundwater where actual atrazine concentration information does not exist. Table S5. Predicted values for malathion concentration in groundwater where actual malathion concentration information does not exist. References [29,30,31,32,33,34,35,36,37] are cited in the Supplementary Materials.
Author Contributions
Conceptualization, S.D. and A.D.; Methodology, S.P. and A.D.; Software, S.P.; Formal analysis, S.P.; Investigation, A.D.; Resources, S.D. and A.D.; Data curation, S.P.; Writing—original draft, S.P.; Writing—review & editing, S.D. and A.D.; Supervision, S.D. and A.D.; Project administration, A.D.; Funding acquisition, A.D. All authors have read and agreed to the published version of the manuscript.
Funding
This work is partially supported by the Department of Energy Office of Environmental Management under Award Number DE-EM0005228 to the University of Georgia Research Foundation. Shivank Pandey was awarded the CURO research award from the University of Georgia to conduct this study.
Data Availability Statement
The original contributions presented in this study are included in the article/Supplementary Material. Further inquiries can be directed to the corresponding authors.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Duttagupta, S.; Mukherjee, A.; Bhattacharya, A.; Bhattacharya, J. Wide exposure of persistent organic pollutants (PoPs) in natural waters and sediments of the densely populated Western Bengal basin, India. Sci. Total Environment. 2020, 717, 137187. [Google Scholar] [CrossRef] [PubMed]
- Basapuram, G.; Duttagupta, S.; Dutta, A. Detection and Screening of Organic Contaminants in A Riverine System of Georgia Using Non-Targeted Analysis. Environments 2024, 11, 89. [Google Scholar] [CrossRef]
- Alavanja, M.C. Introduction: Pesticides use and exposure, extensive worldwide. Rev. Environ. Health 2009, 24, 303–310. [Google Scholar] [CrossRef] [PubMed]
- Antoniou, M.N.; Robinson, C.; Castro, I.; Hilbeck, A. Agricultural GMOs and their associated pesticides: Misinformation, science, and evidence. Environ. Sci. Eur. 2023, 35, 76. [Google Scholar] [CrossRef]
- Beaulieu, M.; Cabana, H.; Taranu, Z.; Huot, Y. Predicting atrazine concentrations in waterbodies across the contiguous United States: The importance of land use, hydrology, and water physicochemistry. Limnol. Oceanogr. 2020, 65, 2966–2983. [Google Scholar] [CrossRef]
- Dhuldhaj, U.P.; Singh, R.; Singh, V.K. Pesticide contamination in agro-ecosystems: Toxicity, impacts, and bio-based management strategies. Environ. Sci. Pollut. Res. 2023, 30, 9243–9270. [Google Scholar] [CrossRef]
- Bedi, M.; Sapozhnikova, Y.; Ng, C. Evaluating contamination of seafood purchased from US retail stores by persistent environmental pollutants, pesticides and veterinary drugs. Food Addit. Contam. Part A 2024, 41, 325–338. [Google Scholar] [CrossRef]
- Huang, D.; Gao, L.; Zhu, S.; Qiao, L.; Liu, Y.; Ai, Q.; Xu, C.; Wang, W.; Lu, M.; Zheng, M. Target and non-target analysis of organochlorine pesticides and their transformation products in an agrochemical-contaminated area. Chemosphere 2023, 324, 138314. [Google Scholar] [CrossRef]
- Singh, P.; Mazumdar, P. Microbial pesticides: Trends, scope and adoption for plant and soil improvement. In Biopesticides; Woodhead Publishing: Sawston, UK, 2022; pp. 37–71. [Google Scholar]
- Javaid, M.; Haleem, A.; Singh, R.P.; Suman, R.; Gonzalez, E.S. Understanding the adoption of Industry 4.0 technologies in improving environmental sustainability. Sustain. Oper. Comput. 2022, 3, 203–217. [Google Scholar] [CrossRef]
- Georgia Department of Agriculture. Commodities & Industries. Available online: www.agr.georgia.gov/commodities-industries (accessed on 27 January 2025).
- Blake, J.M.; Walton-Day, K.; Gallegos, T.J.; Yager, D.B.; Teeple, A.; Humberson, D.; Stengel, V.; Becher, K. New Geochemical Framework and Geographic Information System Methodologies to Assess Element Occurrence, Persistence, and Mobility in Groundwater and Surface Water. Minerals 2022, 12, 411. [Google Scholar] [CrossRef]
- University of Georgia Extension. Protecting Georgia’s Surface Water Resources. Available online: https://extension.uga.edu/publications/detail.html?number=B1217&title=protecting-georgias-surface-water-resources (accessed on 11 March 2025).
- Akbar, T.A.; Lin, H.; DeGroote, J. Development and evaluation of GIS-based ArcPRZM-3 system for spatial modeling of groundwater vulnerability to pesticide contamination. Comput. Geosci. 2011, 37, 822–830. [Google Scholar] [CrossRef]
- Saha, D.; Alam, F. Groundwater vulnerability assessment using DRASTIC and Pesticide DRASTIC models in intense agriculture area of the Gangetic plains, India. Environ. Monit. Assess. 2014, 186, 8741–8763. [Google Scholar] [CrossRef] [PubMed]
- Duttagupta, S.; Mukherjee, A.; Das, K.; Dutta, A.; Bhattacharya, A.; Bhattacharya, J. Groundwater vulnerability to pesticide pollution assessment in the alluvial aquifer of Western Bengal basin, India using overlay and index method. Geochemistry 2020, 80, 125601. [Google Scholar] [CrossRef]
- Dutta, A.; Goldman, T.; Keating, J.; Burke, E.; Williamson, N.; Dirmeier, R.; Bowman, J.S. Machine learning predicts biogeochemistry from microbial community structure in a complex model system. Microbiol. Spectr. 2022, 10, e01909-21. [Google Scholar] [CrossRef]
- USGS. National Water Quality Assessment (NAWQA) Pesticide National Synthesis Project. U.S. Geological Survey. 2021. Available online: https://www.sciencebase.gov/catalog/item/6081a924d34e8564d68661a1 (accessed on 9 March 2025).
- U.S. Census. Georgia: Population and Housing Data. U.S. Census Bureau. 2021. Available online: https://data.census.gov/profile/Georgia?g=040XX00US13 (accessed on 9 March 2025).
- National Oceanic and Atmospheric Administration (NOAA). National Centers for Environmental Information (NCEI) Climate Data Online. 2019. Available online: https://www.climate.gov/maps-data/data-snapshots/data-source (accessed on 9 March 2025).
- Nath, A.; Bhuyan, P.; Gogoi, N.; Deka, P. Pesticides and Chemical Fertilizers: Role in Soil Degradation, Groundwater Contamination, and Human Health. In Xenobiotics in Urban Ecosystems: Sources, Distribution and Health Impacts; Springer Nature: Cham, Switzerland, 2023; pp. 131–160. [Google Scholar]
- Teegavarapu, R.S. Imputation Methods: An Overview. In Imputation Methods for Missing Hydrometeorological Data Estimation; Springer: Cham, Switzerland, 2024; pp. 27–41. [Google Scholar]
- Sukhdeve, D.S.; Sukhdeve, S.S. Google Colaboratory. In Google Cloud Platform for Data Science: A Crash Course on Big Data, Machine Learning, and Data Analytics Services; Apress: Berkeley, CA, USA, 2023; pp. 11–34. [Google Scholar]
- Munshi, A.; Moharil, R.M. Binning Based Data Driven Machine Learning Models for Solar Radiation Forecasting in India. Iran. J. Sci. Technol. Trans. Electr. Eng. 2024, 48, 1249–1260. [Google Scholar] [CrossRef]
- Kumar, S. Important Python Libraries. In Python for Accounting and Finance: An Integrative Approach to Using Python for Research; Springer Nature: Cham, Switzerland, 2024; pp. 59–88. [Google Scholar]
- Mishra, P. PyTorch Model Interpretability and Interface to Sklearn. In PyTorch Recipes: A Problem-Solution Approach to Build, Train and Deploy Neural Network Models; Apress: Berkeley, CA, USA, 2022; pp. 237–260. [Google Scholar]
- Ünsalan, C.; Höke, B.; Atmaca, E. Introduction to Machine Learning. In Embedded Machine Learning with Microcontrollers: Applications on STM32 Development Boards; Springer International Publishing: Cham, Switzerland, 2024; pp. 73–103. [Google Scholar]
- Vasundhara, S.; Tejaswini, S.; Sriyam, A.S. Machine Learning Algorithms–The Effect of Training and Testing Process. In Proceedings of the International Conference on Data Science, Machine Learning and Applications, Hyderabad, India, 15–16 December 2023; Springer Nature: Singapore, 2023; pp. 1071–1078. [Google Scholar]
- Uddin, M.G.; Imran, M.H.; Sajib, A.M.; Hasan, M.A.; Diganta, M.T.; Dabrowski, T.; Olbert, A.I.; Moniruzzaman, M. Assessment of human health risk from potentially toxic elements and predicting groundwater contamination using machine learning approaches. J. Contam. Hydrol. 2024, 261, 104307. [Google Scholar] [CrossRef]
- Barzegar, R.; Moghaddam, A.A.; Deo, R.; Fijani, E.; Tziritis, E. Mapping groundwater contamination risk of multiple aquifers using multi-model ensemble of machine learning algorithms. Sci. Total Environ. 2018, 621, 697–712. [Google Scholar] [CrossRef]
- Gómez-Escalonilla, V.; Montero-González, E.; Díaz-Alcaide, S.; Martín-Loeches, M.; del Rosario, M.R.; Martínez-Santos, P. A machine learning approach to site groundwater contamination monitoring wells. Appl. Water Sci. 2024, 14, 250. [Google Scholar] [CrossRef]
- Malakar, P.; Sarkar, S.; Mukherjee, A.; Bhanja, S.; Sun, A.Y. Use of machine learning and deep learning methods in groundwater. In Global Groundwater; Elsevier: Amsterdam, The Netherlands, 2021; pp. 545–557. [Google Scholar]
- Bhowmik, T.; Sarkar, S.; Sen, S.; Mukherjee, A. Application of machine learning in delineating groundwater contamination in present and climate change scenarios. Curr. Opin. Environ. Sci. Health 2024, 39, 100554. [Google Scholar] [CrossRef]
- Sarkar, S.; Mukherjee, A.; Duttagupta, S.; Bhanja, S.N.; Bhattacharya, A. Predicting regional-scale elevated groundwater nitrate contamination risk using machine learning on natural and human-induced factors. ACS EsT Eng. 2022, 2, 689–702. [Google Scholar] [CrossRef]
- Jibrin, A.M.; Al-Suwaiyan, M.; Aldrees, A.; Dan’azumi, S.; Usman, J.; Abba, S.I.; Yassin, M.A.; Scholz, M.; Sammen, S.S. Machine learning predictive insight of water pollution and groundwater quality in the Eastern Province of Saudi Arabia. Sci. Rep. 2024, 14, 20031. [Google Scholar] [CrossRef] [PubMed]
- Deng, Y.; Ye, X.; Du, X. Predictive modeling and analysis of key drivers of groundwater nitrate pollution based on machine learning. J. Hydrol. 2023, 624, 129934. [Google Scholar] [CrossRef]
- Nighojkar, A.; Pandey, S.; Naebe, M.; Kandasubramanian, B.; Soboyejo, W.W.; Plappally, A.; Wang, X. Using machine learning to predict the efficiency of biochar in pesticide remediation. NPJ Sustain. Agric. 2023, 1, 1. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).