
Uncertainty Analysis of Multi-Model Flood Forecasts


Abstract
:1. Introduction
1.1. Purpose of Study
1.2. Background
1.2.1. Model Selection
1.2.2. Model Calibration
1.2.3. Model Application for Discharge Forecasting
1.2.4. Performance Indicators
2. Bayesian Error Classification and Analysis
2.1. Preliminary Definitions
2.2. Class 0 Error Analysis
2.3. Class 1 Error Analysis
2.3.1. Model Class 1 Type k = 0
2.3.2. Model Class 1 Type k =1
2.3.3. Model Class 1 Type k = 2
2.3.4. Relative Importance of Rainfall and Model Uncertainties
2.4. Class 2 Error Analysis
2.4.1. Model Class 2: Type k,0
2.4.2. Model Class 2 Type w,0
Prior Density Distribution
Likelihood Density Distribution
Posterior Distribution
2.4.3. Model Class 2 Type 1,2
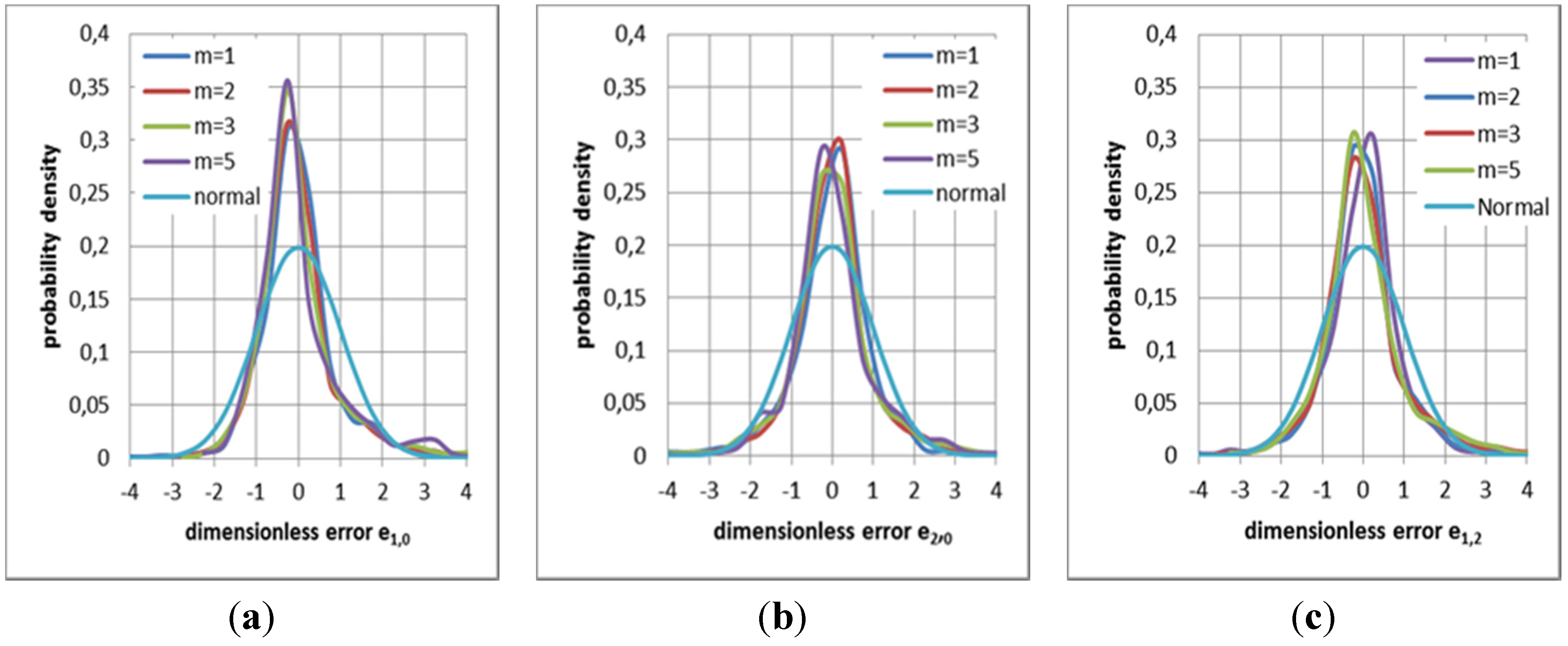
2.5. Results of the Error Analysis
2.6. Criterion for Forecast Quality
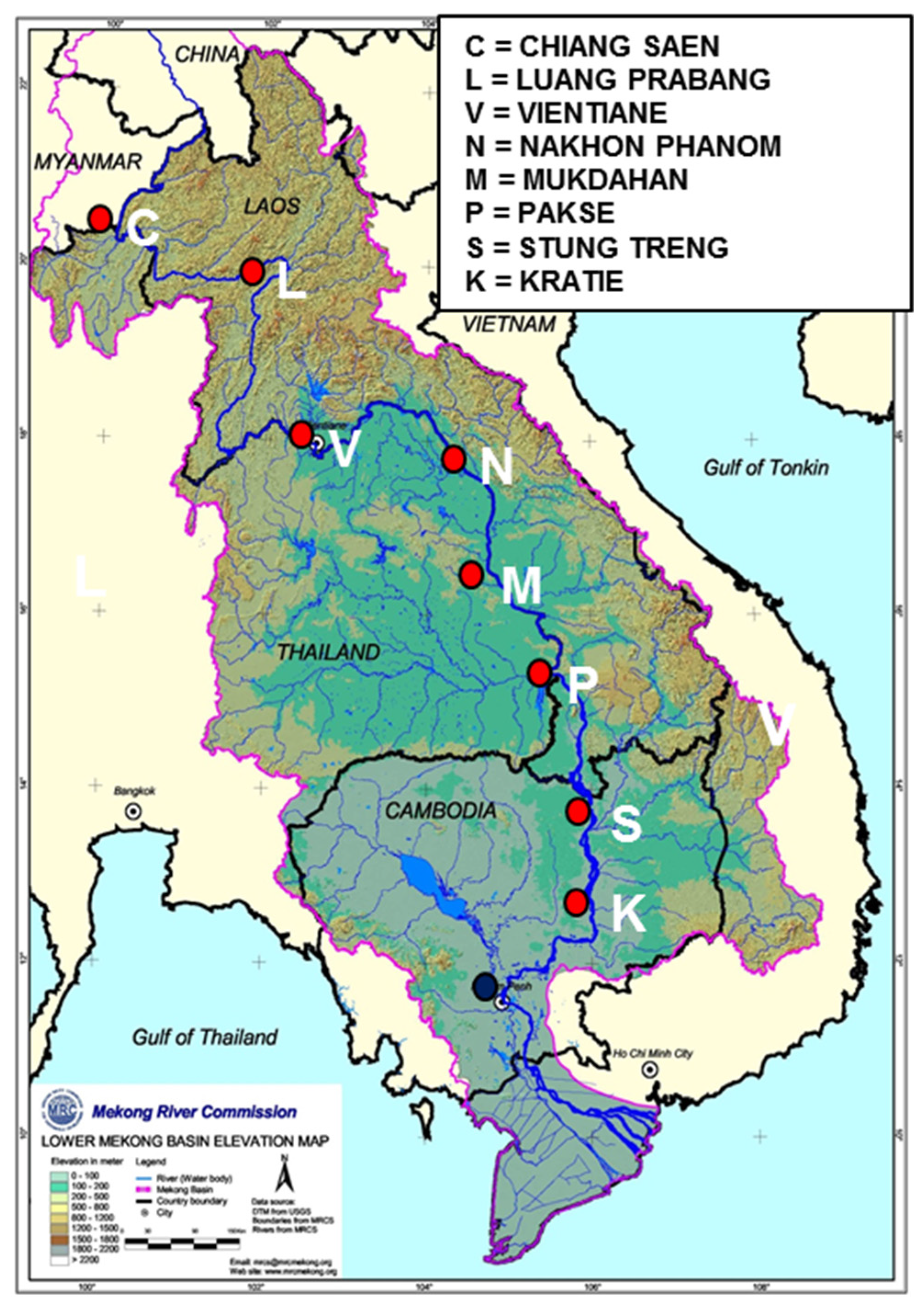
3. Application to Forecast Data for Mekong River

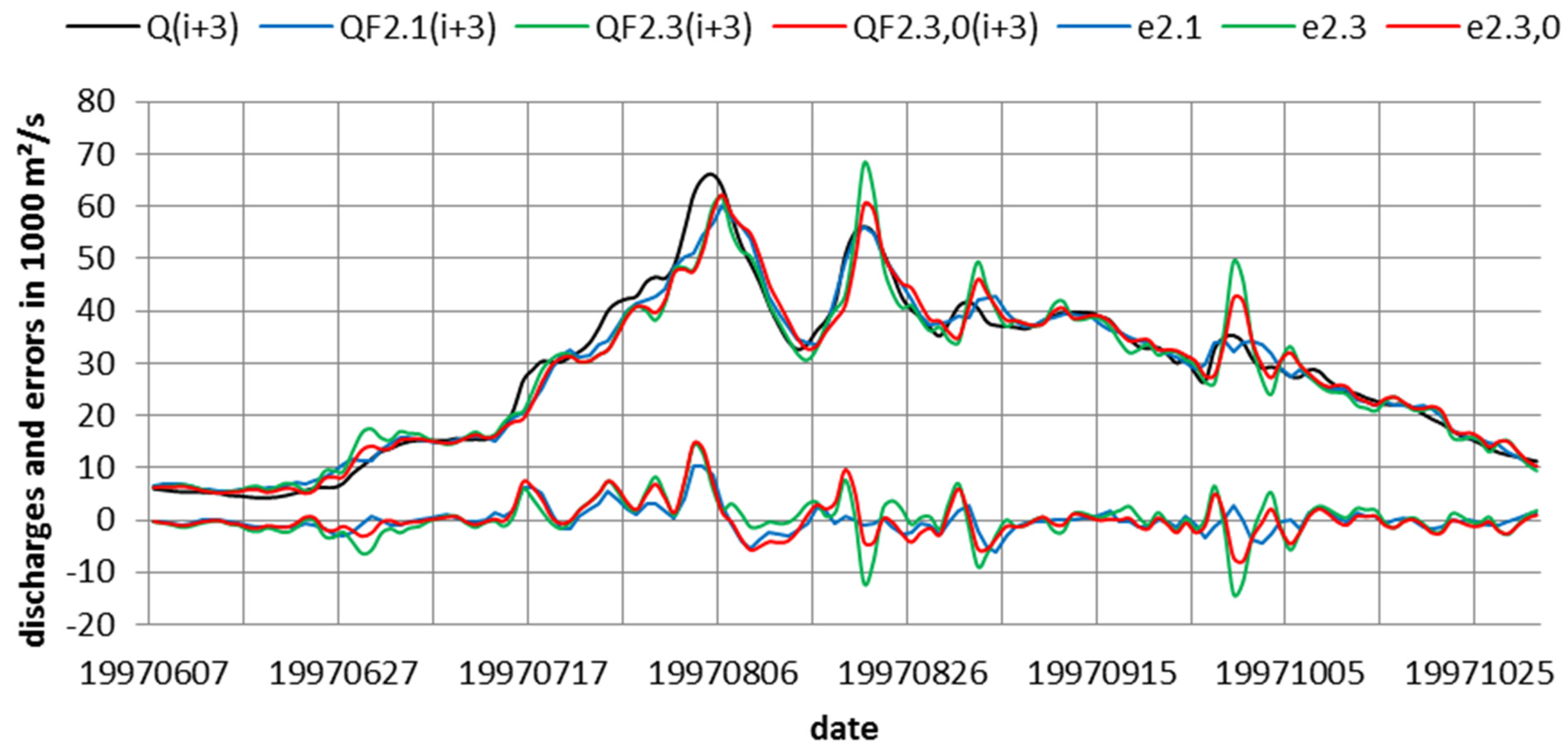
3.1. Application of Models 0, Model 1 and Model 0,1

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| m | a1,0 | b1,0 | std | skew | PIopt | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| e | e0 | e1 | e1,0 | ||||||||
| 1 | 0.991 | 0.996 | 0.996 | 1.157 | −0.162 | 1299 | 1886 | 1299 | 1284 | 0.602 | 0.54 |
| 2 | 0.971 | 0.986 | 0.988 | 1.110 | −0.126 | 2349 | 3350 | 2346 | 2330 | 0.602 | 0.52 |
| 3 | 0.946 | 0.969 | 0.981 | 1.096 | −0.129 | 3450 | 4547 | 3447 | 3429 | 0.568 | 0.43 |
| 4 | 0.919 | 0.949 | 0.973 | 1.045 | −0.099 | 4418 | 5533 | 4415 | 4404 | 0.517 | 0.37 |
| 5 | 0.891 | 0.926 | 0.965 | 0.971 | −0.048 | 5266 | 6355 | 5260 | 5258 | 0.462 | 0.32 |

3.2. Application of Model 2

| m | a2,0 | b2,0 | std | std | std | std | Skew | PIopt | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| e | e0 | e2.3 | e0, 2.3 | ||||||||
| 1 | 0.996 | 0.991 | 0.994 | 0.910 | 0.087 | 1216 | 1886 | 1215 | 1207 | 0.589 | 0.58 |
| 2 | 0.988 | 0.971 | 0.973 | 0.809 | 0.183 | 2195 | 3350 | 2193 | 2108 | 0.569 | 0.58 |
| 3 | 0.969 | 0.946 | 0.936 | 0.672 | 0.317 | 3478 | 4547 | 3478 | 3105 | 0.563 | 0.53 |
| 4 | 0.939 | 0.918 | 0.891 | 0.587 | 0.395 | 4822 | 5533 | 4809 | 4100 | 0.553 | 0.45 |
| 5 | 0.907 | 0.891 | 0.846 | 0.541 | 0.433 | 5956 | 6355 | 5879 | 4913 | 0.548 | 0.40 |
| m | S2·h | Standard Deviations for Different Model Combinations in m³/s | Fraction of Rainfall Uncertainty | ||||
|---|---|---|---|---|---|---|---|
| Persistence Model 0 | Model 2.1 | Combination Model 1 and Model 2.1 | Model 2.3 | Combination Model 1 and Model 2.3 | |||
| 1 | 0.991 | 1886 | 1187 | 1186 | 1215 | 1214 | 0.061 |
| 2 | 0.971 | 3350 | 1942 | 1927 | 2193 | 2051 | 0.155 |
| 3 | 0.946 | 4550 | 2517 | 2498 | 3478 | 2951 | 0.349 |
| 4 | 0.918 | 5533 | 3002 | 2989 | 4809 | 3846 | 0.487 |
| 5 | 0.891 | 6355 | 3398 | 3391 | 5879 | 4638 | 0.574 |
3.3. Application of Model 1 and Model 2 in Combination
| m | a1,2 | b1,2 | std | Skew | PIopt | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| e1 | e2.3 | e1,2.3 | ||||||||
| 1 | 0.996 | 0.996 | 0.998 | 0.334 | 0.662 | 1299 | 1215 | 1214 | 0.596 | 0.59 |
| 2 | 0.988 | 0.986 | 0.989 | 0.579 | 0.413 | 2346 | 2194 | 2051 | 0.584 | 0.63 |
| 2W | 0.987 | 0.989 | 0.991 | 0.398 | 0.595 | - | - | 2023 | 0.572 | |
| 3 | 0.969 | 0.969 | 0.965 | 0.501 | 0.485 | 3447 | 3479 | 2951 | 0.563 | 0.58 |
| 4 | 0.949 | 0.939 | 0.930 | 0.558 | 0.420 | 4415 | 4806 | 3846 | 0.529 | 0.52 |
| 5 | 0.926 | 0.907 | 0.893 | 0.574 | 0.394 | 5260 | 5880 | 4638 | 0.496 | 0.47 |
| 5W | 0.937 | 0.926 | 0.918 | 0.550 | 0.421 | - | - | 4623 | - | 0.47 |

3.4. Probability Densities of Final Errors

4. Summary and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix
A Method of Fitting Weibull Distributions to Data
References
- Krzysztofowicz, R. Bayesian system for probabilistic river stage forecasting. J. Hydrol. 2002, 268, 16–40. [Google Scholar] [CrossRef]
- Todini, E. From HUP to MCP: Analogies and extended performances. J. Hydrol. 2013, 477, 33–42. [Google Scholar] [CrossRef]
- Shahzad, M.K.; Plate, E.J. Flood forecasting for River Mekong with data-based models. Water Resour. Res. 2014, 50, 7115–7133. [Google Scholar] [CrossRef]
- Todini, E. A model conditional processor to assess predictive uncertainty in flood forecasting. Int. J. River Basin Manag. 2008, 6, 123–137. [Google Scholar] [CrossRef]
- Singh, V.J.; Woolhiser, D.A. Mathematical modeling of watershed hydrology. J. Hydrol. Eng. ASCE 2000, 7, 270–291. [Google Scholar] [CrossRef]
- Gouweleeuw, B.; Reggiani, P.; de Roo, A. A European Flood Forecasting System EFFS; European Report EUR 21 208; Office for Official Publications of the European Communities: Luxembourg, 2004. [Google Scholar]
- Wu, C.L.; Chau, K.W. Rainfall-runoff modeling using artificial neural network coupled with singular spectrum analysis. J. Hydrol. 2011, 309, 394–409. [Google Scholar] [CrossRef]
- Kachroo, R.K.; Liang, G.C. River flow forecasting. Part 2: Algebraic development of linear modeling techniques. J. Hydrol. 1992, 133, 17–40. [Google Scholar]
- Blöschl, G. Hydrological synthesis: Across processes, places, and scales. Water Resour. Res. 2006, 42. [Google Scholar] [CrossRef]
- Plate, E.J. Classification of hydrological models for flood management. J. Hydrol. Earth Syst Sci. HESS 2009, 13, 1–13. [Google Scholar]
- Fenicia, F.; Savenije, H.H.G.; Matgen, P.; Pfister, L. Understanding catchment behavior through stepwise model concept improvement. Water Resour. Res. 2008, 44. [Google Scholar] [CrossRef]
- Clarke, R.T. Uncertainty in the estimation of mean annual flood due to rating-curve indefinition. J. Hydrol. 1999, 222, 185–190. [Google Scholar] [CrossRef]
- Krzysztofowicz, R. Why should a forecaster and a decision maker use Bayes theorem? Water Resour. Res. 1983, 19, 327–336. [Google Scholar] [CrossRef]
- Martina, M.L.V.; Todini, E.; Libraton, A. A Bayesian decision approach to rainfall thresholds based flood warning. J. Hydrol. Earth Syst Sci. HESS 2006, 10, 413–426. [Google Scholar] [CrossRef]
- Singh, S.K.; Liang, J.; Bárdossy, A. Improving the calibration strategy of the physically-based model WaSiM-ETH using critical events. Hydrol. Sci. J. 2012, 57, 1487–1505. [Google Scholar] [CrossRef]
- Beven, K.J.; Freer, J.E. Equifinality, data assimilation, and uncertainty estimation in mechanistic modeling of of complex environmental systems using the GLUE method. J. Hydrol. 2001, 249, 11–29. [Google Scholar] [CrossRef]
- Beven, K.J.; Binley, A. The future of distributed models: Model calibration and uncertainty prediction. Hydrol. Process. 1992, 6, 279–288. [Google Scholar] [CrossRef]
- Freer, J.; Beven, K.J.; Ambroise, B. Bayesian estimation of uncertainty in runoff prediction and the value of data. An application of the GLUE approach. Water Resour. Res. 1996, 32, 2161–2173. [Google Scholar] [CrossRef]
- Gupta, H.V.; Sorooshian, S.; Yapo, P.O. Toward improved calibration of hydrological models: Multiple and non-commensurable measures of information. Water Resour. Res. 1998, 34, 751–763. [Google Scholar] [CrossRef]
- Hundecha, Y.; Ouarda, T.; Bárdossy, A. Regional estimation of parameters of a rainfall-runoff model at ungauged watersheds using the spatial structures of the parameters within a canonical physiographic-climatic space. Water Resour. Res. 2007. [Google Scholar] [CrossRef]
- Thiemann, M.; Trosset, M.; Gupta, H.; Sorooshian, S. Bayesian recursive parameter estimation for hydrological models. Water Resour. Res. 2001, 37, 2521–2535. [Google Scholar] [CrossRef]
- Marshall, L.; Sharma, A.; Nott, D. Modeling the catchment via mixtures: Issues of model specification and validation. Water Resour. Res. 2006, 42. [Google Scholar] [CrossRef]
- Krishnamurti, T.N.; Kishtawal, C.M.; LaRow, T.E.; Bachiochi, D.R.; Zhang, Z.; Williford, C.E.; Gadgil, S.; Surendran, S. Improved weather and seasonal climate forecasts from multimodel superensemble. Science 1999, 285, 1548–1550. [Google Scholar] [CrossRef] [PubMed]
- Werner, M.G.F.; van Dijk, M.; Schellekens, J. DELFT-FEWS: An open shell flood forecasting system. In Proceedings of the 6-th International Conference on Hydroinformatics, Singapore, 21–24 June 2004; World Scientific Publishing Co.: Singapore, 2004; pp. 1205–1212. [Google Scholar]
- Brath, A.; Montanari, A.; Toth, E. Neural networks and non-parametric methods for improving real-time flood forecasting through conceptual hydrological models. J. Hydrol. Earth Syst Sci. HESS 2002, 6, 627–640. [Google Scholar] [CrossRef]
- Burlando, P.; Rosso, R.; Cadavid, L.G.; Salas, J.D. Forecasting of short-term rainfall using ARMA models. J. Hydrol. 1993, 144, 193–211. [Google Scholar] [CrossRef]
- Toth, E.; Brath, A. Multistep ahead streamflow forecasting: Role of calibration data in conceptual and neural network modeling. Water Resour. Res. 2007, 43. [Google Scholar] [CrossRef]
- Hsu, K.-L.; Gupta, H.V.; Gao, X.G.; Sorooshian, S.; Imam, B. Self-organizing linear output map (SOLO), an artificial neural network suitable for hydrologic modeling and analysis. Water Resour. Res. 2002, 38, 1302–1314. [Google Scholar] [CrossRef]
- Dawson, C.W.; Abraham, R.J.; Shamseldin, A.Y.; Wilby, R.L. Flood estimation at ungauged sites using artificial neural networks. J. Hydrol. 2006, 319, 391–409. [Google Scholar] [CrossRef]
- Moradkhani, H.; Hsu, K.; Gupta, H.V.; Sorooshian, S. Improved Streamflow Forecasting Using Self-Organizing Radial Basis Function Artificial Neural Networks. J. Hydrol. 2004, 295, 246–262. [Google Scholar] [CrossRef]
- Damrath, U.; Doms, G.; Frühwald, D.; Heise, E.; Richter, B.; Steppeler, J. Operational quantitative precipitation forecasting at the German Weather Service. J. Hydrol. 2000, 239, 260–285. [Google Scholar] [CrossRef]
- Majewski, D.; Liermann, D.; Prohl, P.; Ritter, B.; Buchhold, M.; Hanisch, T.; Paul, G.; Wergen, W.; Baumgardner, J. The operational global icosahedral-hexagonal grid point model GME: Description and high resolution tests. Mon. Wea. Rev. 2002, 130, 319–338. [Google Scholar] [CrossRef]
- Jaun, S.; Ahrens, B. Evaluation of a probabilistic hydrometeorological forecasting system. Hydrol. Earth Syst. Sci. 2009, 13, 1031–1043. [Google Scholar] [CrossRef]
- Marsigli, C.; Boccanera, F.; Montani, A.; Paccagnella, T. The COSMO-LEPS mesoscale ensemble system: Validation of the methodology and verification. Nonlinear Process. Geophys. 2005, 12, 527–536. [Google Scholar] [CrossRef]
- Legates, D.R.; McCabe, G.J., Jr. Evaluating the use of goodness of fit measures in hydrology and hydroclimatic model validation. Water Resour. Res. 1999, 33, 233–241. [Google Scholar] [CrossRef]
- Pappenberger, F.; Ramos, M.H.; Cloke, H.L.; Wetterhall, F.; Alfieri, L.; Bogner, K.; Mieller, A.; Salamon, P. How do I know if my forecasts are better? Using benchmarks in hydrological ensemble prediction. J. Hydrol. 2015, 522, 697–713. [Google Scholar] [CrossRef]
- Bogner, K.; Pappenberger, F. Multiscale error analysis, correction, and predictive uncertainty estimation in flood forecasting systems. Water Resour. Res. 2011, 47, 1–24. [Google Scholar] [CrossRef]
- Gupta, H.V.; Kling, H.; Yilmaz, K.K.; Martinez, G.F. Decomposition of the mean squared error and NSE performance index criteria: Implications for hydrological modeling. J. Hydrol. 2011, 377, 80–91. [Google Scholar] [CrossRef]
- Kitanides, P.; Bras, R. Real time area forecasting with a conceptual hydrological model. 1. Analysis of uncertainty. Water Resour. Res. 1980, 16, 1025–1033. [Google Scholar] [CrossRef]
- Wilks, D.S. Statistical Methods in the Atmospheric Sciences, 2nd ed.; Academic Press: Amsterdam, The Netherlands, 2006; p. 627. [Google Scholar]
- Bürger, G.; Reusser, D.; Kneis, D. Early flood warnings from empirical (expanded) downscaling of the full ECMWF Ensemble Prediction System. Water Resour. Res. 2009, 45. [Google Scholar] [CrossRef]
- Dowell, C.A. Weather forecasting by humans—Heuristics and decision making. Weather Forecast. 2004, 19, 1115–1126. [Google Scholar] [CrossRef]
- Krzysztofowicz, R. Bayesian theory of probabilistic forecasting via deterministic hydrological models. Water Resour. Res. 1999, 35, 2739–2750. [Google Scholar] [CrossRef]
- Plate, E.J. Statistik und Angewandte Wahrscheinlichkeitslehre für Bauingenieure; Ernst & Sohn: Berlin, Germany, 1993; p. 685. (in German) [Google Scholar]
- Krzysztofowicz, R.; Herr, H.D. Hydrologic uncertainty processor for probabilistic river stage forecasting: Precipitation dependent model. J. Hydrol. 2001, 249, 46–68. [Google Scholar] [CrossRef]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis; Taylor & Francis Group: Boca Raton, FL, USA, 2003. [Google Scholar]
- Shahzad, K.M.; Karlsruhe Institute of Technology, Karlsruhe, Germany. A data based flood forecasting model for the Mekong River. Unpublished Dissertation. 2011. [Google Scholar]
- Todini, E. Hydrological catchment modelling: Past, present and future. J. Hydrol. Earth Syst. Sci. HESS 2007, 11, 468–482. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Plate, E.J.; Shahzad, K.M. Uncertainty Analysis of Multi-Model Flood Forecasts. Water 2015, 7, 6788-6809. https://doi.org/10.3390/w7126654
Plate EJ, Shahzad KM. Uncertainty Analysis of Multi-Model Flood Forecasts. Water. 2015; 7(12):6788-6809. https://doi.org/10.3390/w7126654
Chicago/Turabian StylePlate, Erich J., and Khurram M. Shahzad. 2015. "Uncertainty Analysis of Multi-Model Flood Forecasts" Water 7, no. 12: 6788-6809. https://doi.org/10.3390/w7126654
APA StylePlate, E. J., & Shahzad, K. M. (2015). Uncertainty Analysis of Multi-Model Flood Forecasts. Water, 7(12), 6788-6809. https://doi.org/10.3390/w7126654