1. Introduction
For any given time and location along a river, streamflow is derived from a combination of surface water, soil water, and groundwater, but ultimately originates from precipitation [
1]. The rainfall-runoff process is complex and includes many interconnected elements (e.g., evapotranspiration, infiltration, subsurface flow, spatial and temporal rainfall variations, land-use, topography, and soil type) that often cannot be accurately measured in a large study area [
2,
3,
4,
5,
6,
7,
8].
Streamflow forecasting is a critical component for many engineering applications and environmental management strategies, such as dam construction, reservoir design, hydro-power generation, irrigation, water resources allocation, flood control, environmental protection, ecosystem sustainability, and ecological integrity [
9,
10,
11,
12]. Short-term streamflow forecasting, such as hourly and daily, is important for flood prediction and protection, while long-term forecasting on monthly and annual scales is useful for water resources planning and management [
13].
Streamflow forecasting techniques are divided into two categories: process-driven and data-driven methods [
13,
14]. Process-driven methods describe the physical processes that govern streamflow in watersheds based on an understanding of physical phenomena. Data-driven methods are black-boxes that forecast streamflow by mapping inputs (hydro-meteorological) to the output (streamflow) mathematically, without considering the physical processes within a watershed [
13].
Although process-driven, physically-based methods can capture and predict the impacts of changes in landscape management practices on streamflow [
15,
16], they require intensive information on hydrogeology, soils, topography, etc., which are often difficult to obtain and measure [
17]. Utilization of physically-based models are complex, time consuming, and require intensive calculations and expert knowledge [
18], making their operation by watershed managers and stakeholders difficult [
19]. Meanwhile, stakeholder involvement is crucial in developing a successful watershed management plan [
20,
21,
22] and this cannot be achieved unless stakeholders and watershed managers are able to effectively use scientific tools for decision making [
23]. These drawbacks demand more cost-effective techniques for streamflow calculation, especially for assessing the impacts of different management scenarios on streamflow, which requires extensive model simulation.
In recent years, new data-driven methods, such as soft computing, have become effective alternative techniques to physically-based models in water resources management. Soft computing techniques are cost effective methods that can be utilized for solving complex problems by approximation [
24]. However, these methods fall short of capturing hydrological responses to significant changes in physiographical (e.g., land-use/land-cover) and climatological (e.g., climate change) characteristics of a watershed. Artificial neuro-fuzzy inference systems (ANFIS) and Bayesian regression methods have received more attention in recent years in the water resources field due to their ability to model sophisticated non-linear systems such as streamflow and contaminant transport [
25,
26,
27,
28,
29,
30,
31,
32,
33].
In this study we used a physically-based hydrological model, the Soil and Water Assessment Tool (SWAT), to simulate streamflow in a large and diverse watershed. We trained and tested two data-driven methods (ANFIS and Bayesian regression) to evaluate their capability in estimating streamflow both at the watershed outlet and at each subbasin outlet, as compared to the SWAT model. The application of data-driven methods will significantly reduce the computational time and effort required for examining future management scenarios while being simple enough to be used by stakeholders and watershed managers for decision making. They will save considerable time and resources usually spent on data collection and streamflow estimation because data-driven methods require fewer input parameters than physically-based models.
2. Materials and Methods
2.1. Study Area
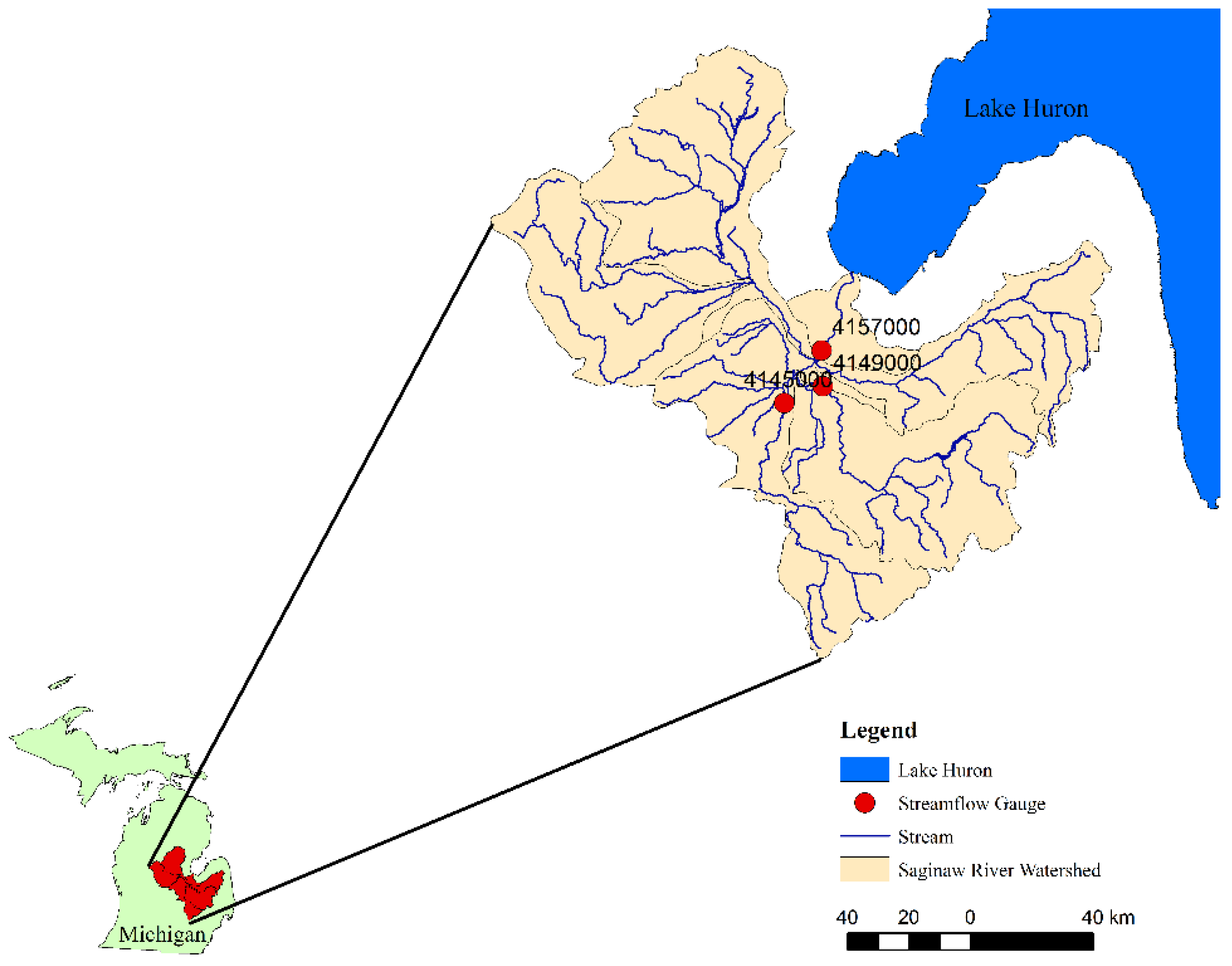
The Saginaw River Watershed (hydrologic unit code-HUC 040802) located in Michigan’s Lower Peninsula (
Figure 1), was selected for this study. This is the largest watershed in Michigan and consists of six eight-digit HUCs; the Tittabawassee (04080201), Pine (04080202), Shiawassee (04080203), Flint (04080204), Cass (04080205), and Saginaw (04080206). The watershed drains about 15% of Michigan’s land area into Lake Huron. The total watershed area is 22,260 km
2, of which 45% is forest, 38% is agriculture and pasture, 11% water and wetlands, and the remaining is urban area. The average watershed elevation is 242 m above mean sea level.
2.2. Modeling Procedures
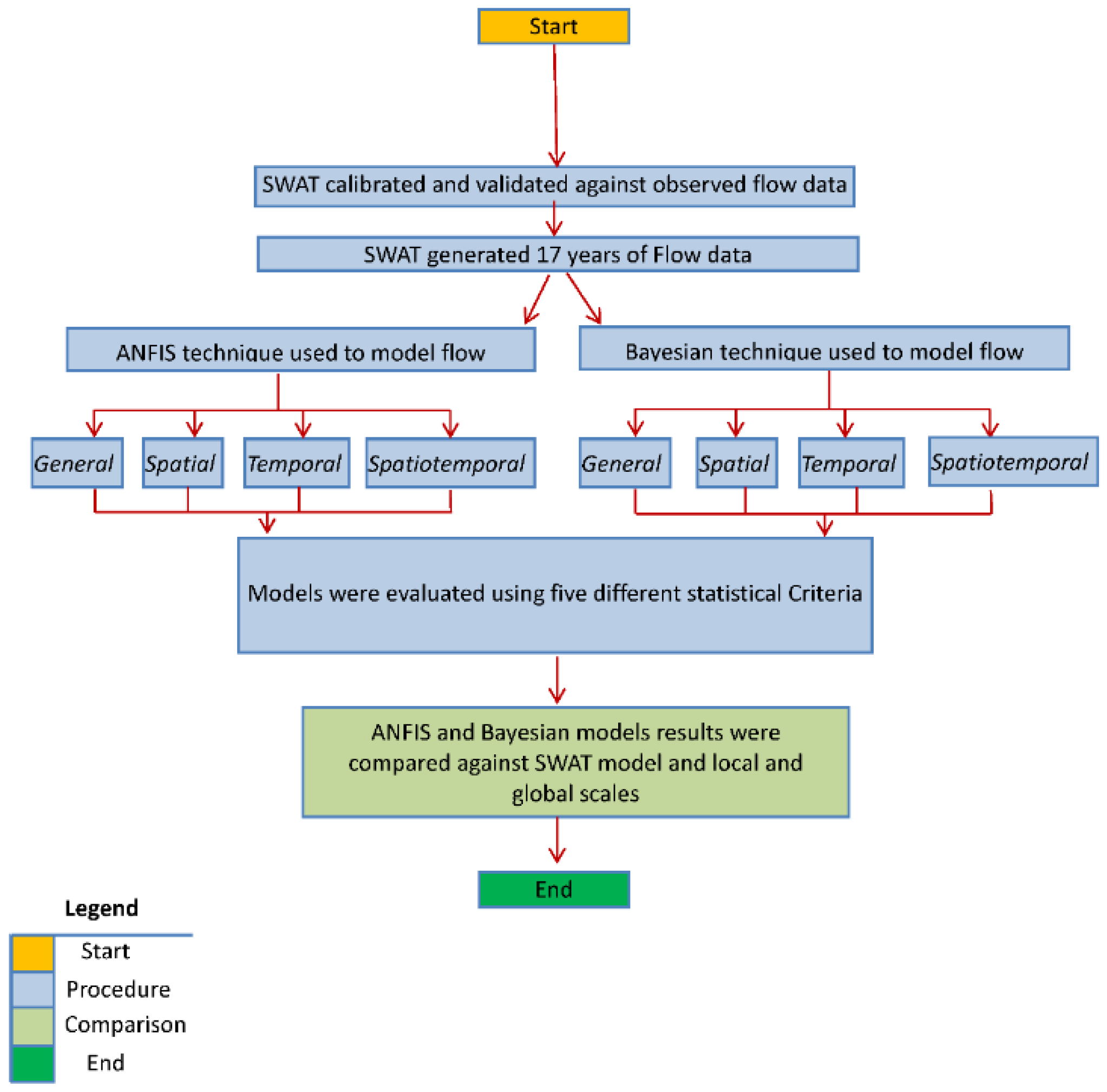
A multi-step modeling process was used to simulate streamflow within the Saginaw River watershed (
Figure 2). The process began with setup and calibration of the physically-based SWAT model. The model was run for 17 years to calculate annual average flow rate for 155 streams within the study area. The ANFIS and Bayesian regression techniques used unique sets of watershed parameters and SWAT model outputs to investigate streamflow predictions based on four model structures: general, spatial, temporal, and spatiotemporal. The results of these models were evaluated against streamflow data obtained from the calibrated SWAT model using five statistical criteria. These criteria were used to select the best data-driven method and model structure that can accurately predict streamflow data.
2.3. Physically-Based Hydrological Model Setup
SWAT was used to simulate long-term daily streamflow in the Saginaw River watershed. SWAT was developed by the United States Department of Agriculture–Agricultural Research Service (USDA–ARS) to simulate flow and pollution transport [
34]. SWAT is one of the most widely used spatially-explicit watershed models in the world [
35]. The model simulates flow, sediment, nutrient, and pesticide transport, crop growth, and management practices, providing insight for decision makers and watershed managers [
36]. In SWAT, basic computational units are known as hydrologic response units (HRUs), which are areas of homogeneous land-use, soil, and slope. Overland flow and pollutants in HRUs are aggregated to the subbasin level and routed through the river network.
Many datasets are required for setting up the SWAT and data-driven models, including soils, climate, land-use, and topography. Soil physical and chemical characteristics were obtained from the State Soil Geographic Database [
37] at a 1:250,000 resolution. Land-use information, including crop-specific classifications, was obtained from the 2008 Cropland Data Layer (56 m resolution) developed by the USDA National Agricultural Statistics Service [
38]. Topographic data was acquired in the form of a 90 m resolution digital elevation model (DEM) from the Better Assessment Science Integrating Point and Nonpoint Sources (BASINS version 4.1, United States Environmental Protection Agency: National Exposure Research Laboratory, Research Triangle Park, NC, USA) program [
39]. Stream network data was obtained from the United States Geological Survey (USGS) National Hydrography Dataset (NHD) [
40]. Based on the NHD and DEM data, the watershed was delineated into 155 subbasins. Climate data was obtained from the National Climatic Data Center (NCDC) with 19 years (1990–2008) of observed daily temperature and precipitation for 15 temperature stations and 19 precipitation stations. Meteorological data, such as solar radiation, wind speed, and relative humidity, were simulated using the SWAT built-in weather generator. The SWAT model included locally relevant agricultural management operations and rotations from Love and Nejadhashemi [
41].
Observed daily streamflow data for the period of 2002–2007 was obtained from USGS gauging stations 04145000, 04149000, and 04157000 (
Figure 1). The SWAT model was calibrated from 2002 to 2004 and validated from 2005 to 2007 on a daily time-step. Next, the calibrated SWAT model was run for 19 years (1990–2008), using the first two years for model warm-up, with the remaining 17 years representing the model simulation period. For the 155 subbasins, a total of 2635 annual streamflow data points were obtained for the watershed.
2.4. Data-Driven Hydrological Models Setup
The study watershed only contained observed streamflow data at four of 155 subbasins. Therefore, the calibrated SWAT model outputs were used to judge the predictive data-driven models’ capability in estimating flow at local and global scales. SWAT can estimate streamflow beyond the four gauging stations for all stream segments in the watershed. This information was used to develop two data-driven methods, ANFIS and Bayesian regression. Thirteen predictor variables were obtained from SWAT model outputs, including time period, geographical coordinates, precipitation data, the total upstream drainage area, four different land-uses (urban, forest, agriculture, and water), and four hydrologic soil groups (A, B, C, and D) to model daily average flow rate. The land-use and soil group variables were calculated as percentage of the total upstream area.
To investigate the effect of different spatial and temporal watershed parameters on streamflow predictions, general, spatial, temporal, and spatiotemporal model structures were considered. For the general model structure hydro-meteorological and watershed characteristics were considered without any spatial or temporal effects. For the spatial model structure, geographical coordinates were added (without time effects) to the set of predictor variables of the general model. For the temporal model structure, time period (without spatial effects) was added to the hydro-meteorological and watershed characteristics. For the spatiotemporal model structure, geographic coordinates and time period were added to the hydro-meteorological and watershed characteristics variables.
2.5. ANFIS
ANFIS is a hybrid model of artificial neural networks (ANN) and Sugeno fuzzy logic inference systems. This method uses the ANN learning ability for the fuzzy inference system to more efficiently compute fuzzy rules and implement three fuzzy control steps (fuzzification, inference, and defuzzification) [
42]. The MATLAB (version 7.12.0, MathWorks, Natick, MA, USA) fuzzy logic toolbox was used to perform ANFIS analysis. MATLAB’s “genfis2” function (which uses subtractive clustering to produce partitions for the data) was used to create fuzzy membership functions (MFs). The number of data subsets depends on the cluster radius value (a small radius results in more clusters and rules and vice versa). Gaussian MFs were used for all input variables and linear parameters were selected for the output MFs. To select the best model structure, ten-fold cross-validation was employed. Here, 90% of the data was used to build the model (the training dataset) and checked on the remaining 10% (the testing dataset). In this way, ten models were generated for all of the ten-folds of data. The average performance (smallest average root-mean-square error—RMSE) of the ten test sets was the criteria for selecting the best structure.
After selecting the most appropriate model structure (general, spatial, temporal, and spatiotemporal), the best model was selected from the ten generated models. Each model was tested against all of the ten test sets, and the lowest average error for all test sets was the criteria for selecting the best model [
32].
Variable Selection for ANFIS
The ANFIS modeling process started with selecting best set of predictor variables for each model structure. Afterward, the best model was used for flow prediction at global (watershed outlet) and local (individual subbasin) scales.
Cobaner [
43] and Sanikhani Kisi [
44] concluded that using a large number of input variables in fuzzy logic models significantly increases the noise in model prediction due to a substantial increase in the number of rules. Due to this limitation, a set of seven input variables were used. All possible variable combinations were explored for each model structure. Accordingly, predictor variables for the ANFIS general (non-random) model structures included upstream drainage area, precipitation, three types of land-use and two soil types. This technique leads to 20 possible variable combinations that were used to select the best variable set describing flow rate in the watershed. For the spatial model structure, total upstream area, precipitation, latitude, longitude, two types of land-use and one type of soil type were used, which resulted in 24 possible variable combinations. For the temporal model structure, upstream area, precipitation, time period (year), three types of land-use and one soil type were used, resulting in 16 possible variable combinations. For the spatiotemporal model structure, upstream total area, precipitation, latitude, longitude, time period, one type of land-use and one soil type were used, which resulted in 16 possible variable combinations.
2.6. Bayesian Regression Method
The Bayesian regression models were developed in MATLAB (version 7.12.0) [
45]. The four model structures were also used for the Bayesian regression method. For each model structure, a set of ten input variables (covariates) were used for the modeling process. The two variables of water from land-use and type-D from soil group were excluded from the variables to remove singularity of the design matrix (because the sum of the all land-uses and soil groups are equal to one) and because an intercept in the Bayesian regression model is included. Precipitation, total upstream area, urban land-use, forest land-use, agricultural land-use, type-A soil, type-B soil, and type-C soil variables were used in addition to a neighborhood matrix and a year-specific random effect. The selected covariates were standardized for the modeling process. The general model structure was created without any temporal and spatial random effects. For the temporal model structure only temporal random effects were included in the general model structure. For the spatial model structure only spatial random effects were included in the general model. Finally, for the spatiotemporal model structure both temporal and spatial random effects were included in the general model.
2.6.1. Bayesian Regression Model Specification
For a data containing response
Yst observed for
s = 1, 2, · · ·,
N geographic regions and
t = 1, 2, · · ·,
T years. The following multiplicative spatiotemporal model is presented in Equation (1).
In Equation (1),
j indexes the p-covariates, which includes the intercept. The regression coefficient β
j for the
jth predictor
Xstj measures its effect on the response variable.
ust is the multiplicative spatiotemporal random effect that captures the variability due to the spatial and temporal effects. ε
st is the residual. We assume
to measure the nugget effects and
u the multiplicative spatiotemporal random effect follows the distribution as following in Equation (2):
which assumes separable spatiotemporal dependence, i.e., the spatial correlation matrix
A(
φ) and the temporal correlation matrix
D(γ) are separately generated by two underlying Gaussian processes, that are both assumed to be Markovian, such as conditional autoregressive (CAR) structure for the spatial dependence, and autoregressive (AR) with order 1 for the temporal dependence. The
operator indicates the Kronecker product of two matrices. The assumption is made for simplicity and computational efficiency as both correlation matrices have closed inverse form for likelihood calculation. The model in Equation 1 assumes a single
NT × 1 spatiotemporal random effect that allows the interactions of the spatiotemporal dependences with a single τ
2 to measure its variation. The model can be again written in the canonical form of a mixed-effects model in Equation (3).
For a Gibbs sampler, the full conditional distributions of fixed-effects and random-effects are as shown in Equations (4) and (5) [
46].
The conditional distributions of variance components and spatiotemporal dependence are presented in Equations (6)–(10).
2.6.2. Bayesian Regression Models Comparisons
The proposed model structure can be implemented with only spatial components, only temporal components, or with both spatiotemporal components masked to evaluate the significance of each component. To compare the Bayesian regression models, the deviance information criterion (DIC) for the mixed-effects model is used. The DIC
4 based on complete likelihood [
47] is presented in Equation (11).
where
can be evaluated by sampling θ for each posterior sample of the random effects α and the obtained mean.
is the posterior expected value of the joint deviance, and
is the measure of model dimensionality. Therefore, a smaller
indicates a simpler model. A smaller DIC4 indicates better predictive power. For the multiplicative model (Equation (1)) the random effect α = u.
To assess the model fit given the
L posterior samples of parameters
, the fitted value
can be calculated in Equation (12).
where,
and
are posterior mean estimates.
2.7. Methods Evaluation Criteria
To compare performance of the Bayesian regression and ANFIS models, five different evaluation criteria were used: coefficient of determination (R2), RMSE, ratio of the root mean square error to the standard deviation of measured data (RSR), Nash-Sutcliffe efficiency coefficient (NSE), and percent bias (PBIAS).
The coefficient of determination is the squared Pearson product moment correlation coefficient, which shows the degree that two variables are related. It ranges between zero and one, where 1 indicates perfect correlation [
48].
where,
Yst and
are observed and predicted values for
s-th subbasin and
t-th year, respectively, with
N representing the total number of subbasins and
T representing study period.
and
are averages of observed and predicted values for
s-th subbasin and
t-th year, respectively.
R2 > 0.5 represents satisfactory model performance [
15].
An
RMSE of 0 is the best prediction of the observed values [
48,
49].
RSR is the standardized
RMSE using the observations’ standard deviation.
RSR of zero indicates perfect prediction, while
RSR > 0.7 represents unsatisfactory model performance [
49].
where, σ is the standard deviation of the observed values.
NSE is the relative magnitude of the residual variance compared to the measured data variance, where
NSE equal to 1 is the best prediction [
50].
PBIAS measures the average tendency of the predicted data to be larger or smaller than their corresponding observed values, where an optimal
PBIAS is equal to zero [
50].
4. Conclusions
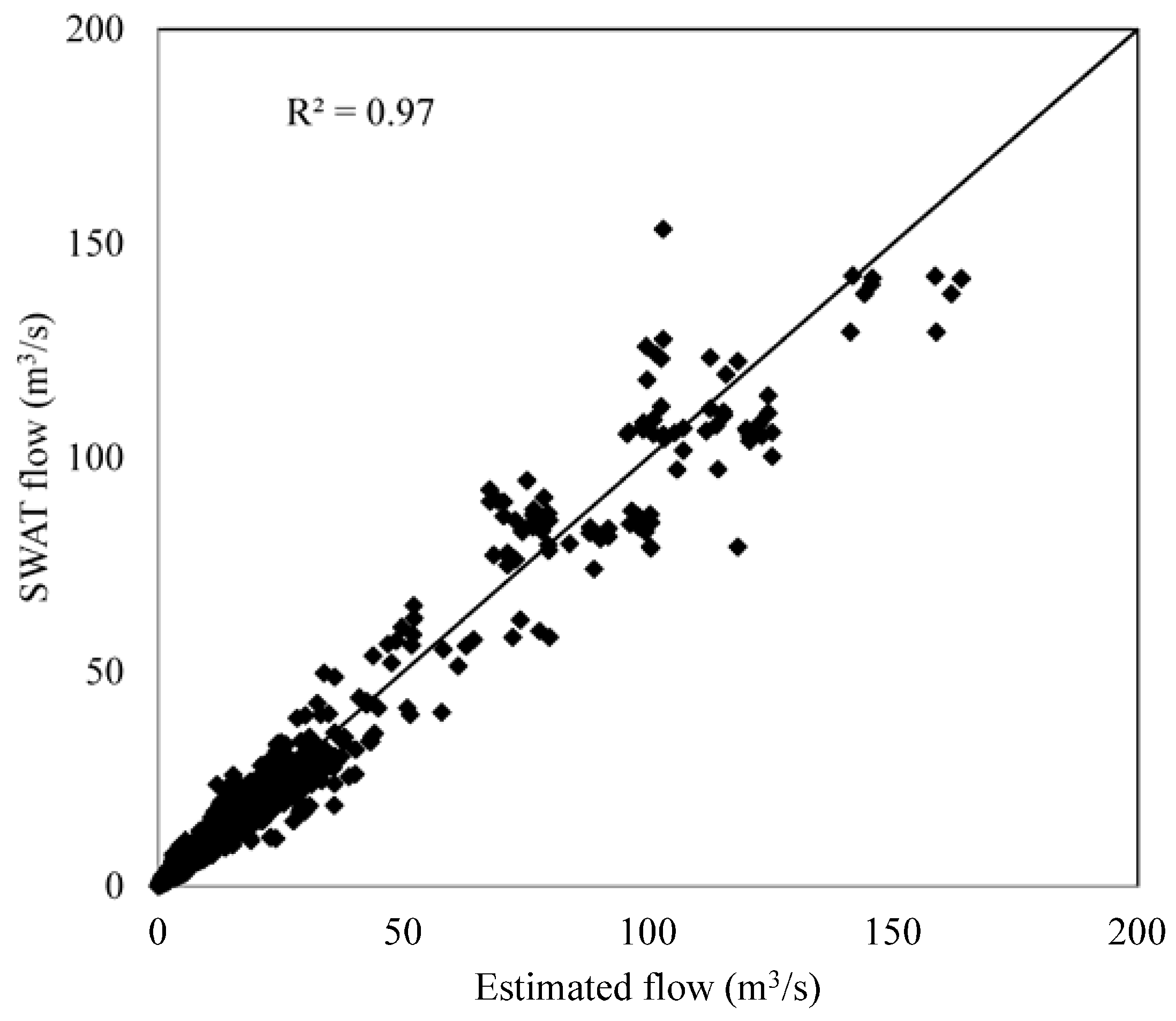
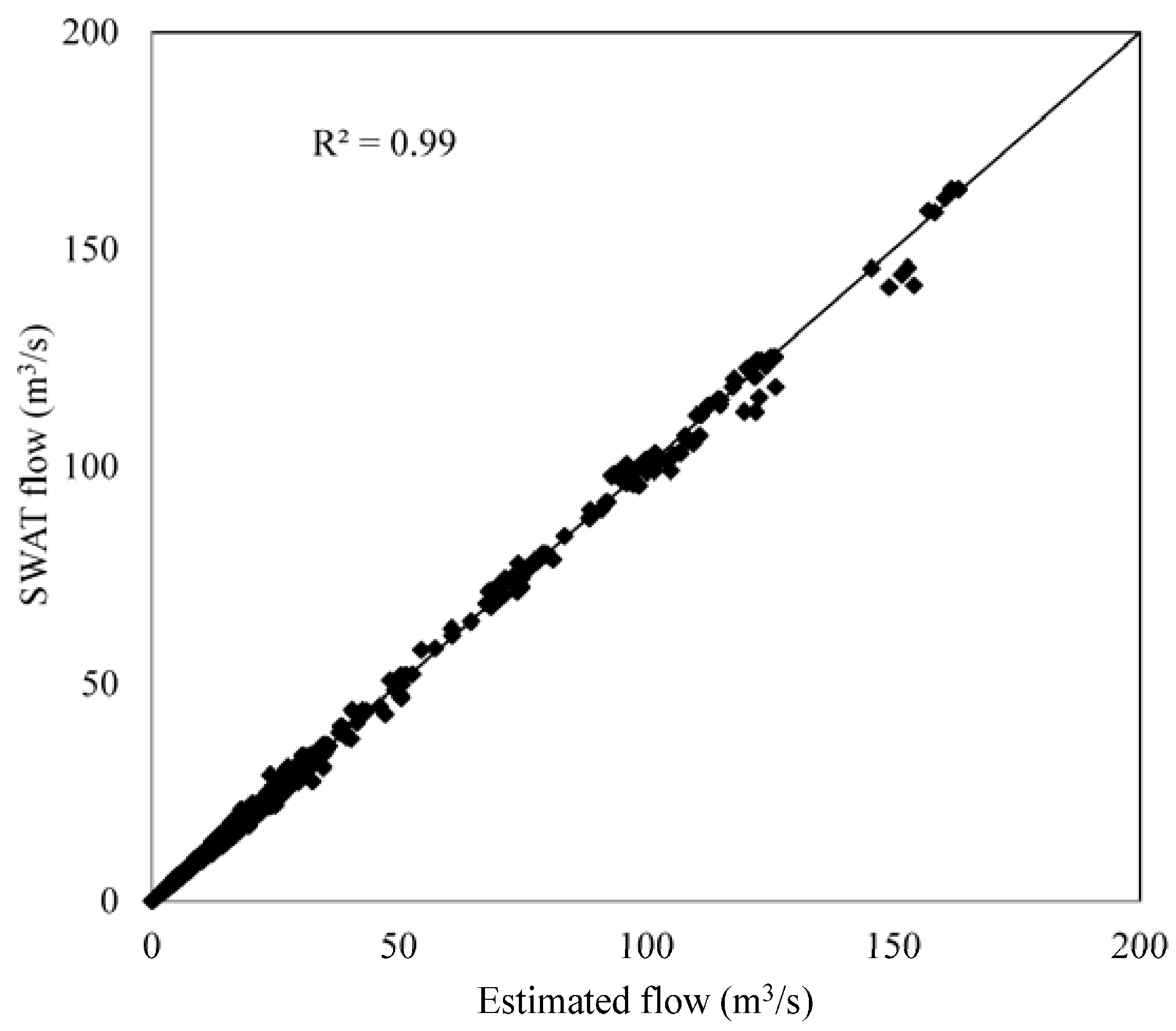
In this study, two soft computing methods (Bayesian regression and ANFIS) were tested as fast and cost-effective methods for estimating flow rate for the Saginaw River Watershed. All model structures for the ANFIS method were able to produce satisfactory results at the global level, while only two model structures for the Bayesian regression method produced satisfactory results at the global level. The Bayesian regression spatiotemporal model structure was the best streamflow predictor at the global level, while the ANFIS best model structure was spatial. At the subbasin and watershed levels the best performing models were the Bayesian regression methods (spatiotemporal and temporal model structures).
As ANFIS has a limitation on number of variables used, this limited the ability of the technique to capture both temporal and spatial variability in the dataset. This was more apparent at the subbasin level, which produced unsatisfactory results for many subbasins. Because fuzzy logic can produce approximate solutions for problems, all models developed by the ANFIS method produced acceptable results at the global and local scales regardless of model structure. Meanwhile, the Bayesian regression method was able to capture variability better than the ANFIS technique only for two model structures (spatiotemporal and temporal).
The results of this study confirmed that both Bayesian Regression and ANFIS methods can be used as an alternative technique for estimating annual flow rate for a watershed at both the global (watershed) and local (subbasin) levels. Meanwhile, it is important to note that the data-driven methods are not reliable if the status of key factors (e.g., land-use/land-cover) in a catchment are altered in the future. Under this circumstance, the process-driven methods are preferable and should be used.



 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}