This research was divided in five stages: (1) data collection and analysis; (2) application of HYDROTEL model to the basin under study; (3) calibration of the hydrological model; (4) spatial and temporal validation of the hydrological model; and (5) applications of distributed hydrological model: theoretical hydraulic potential estimation and streamflow simulation of extreme hydrometeorological events.
3.1. Data Collection and Analysis
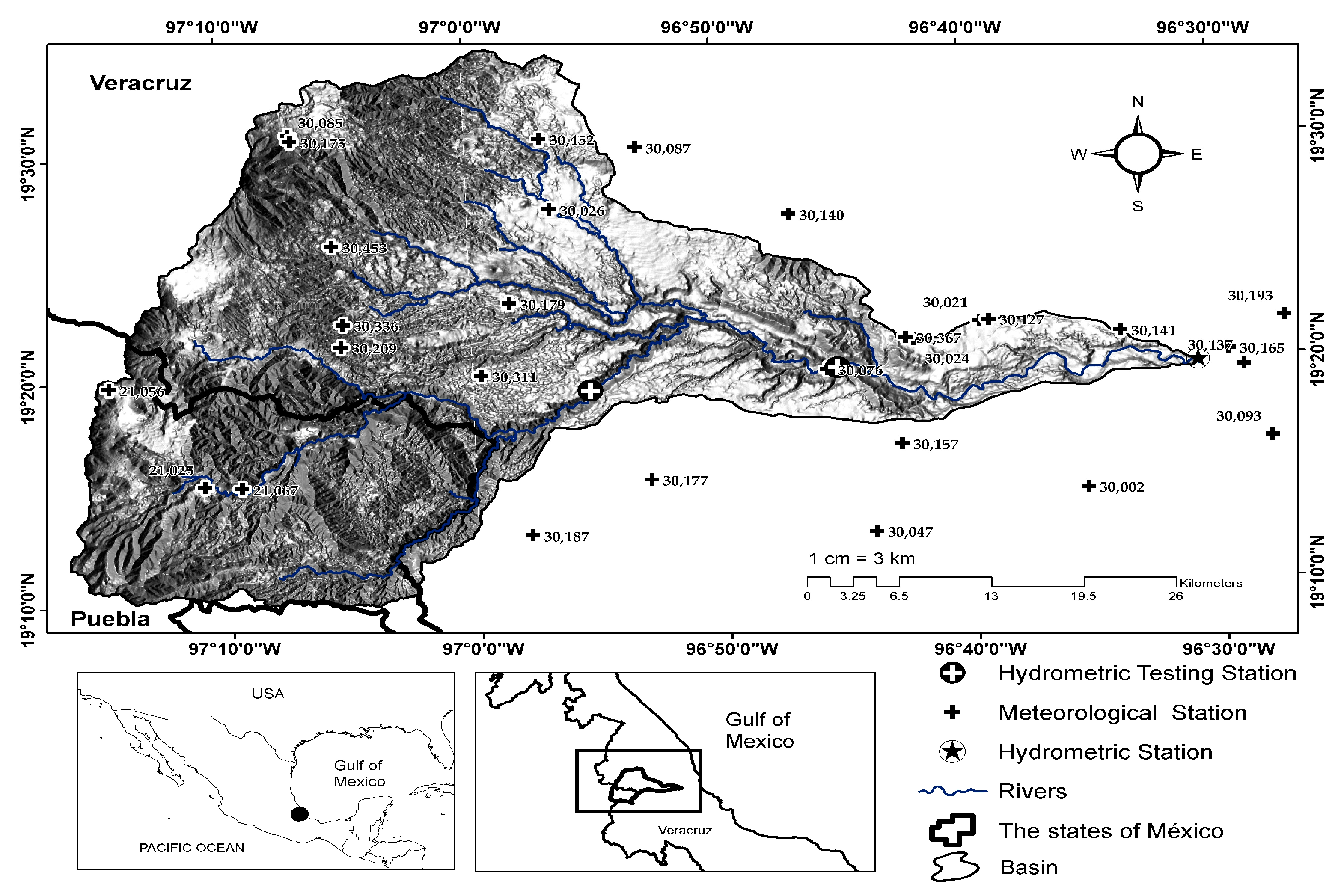
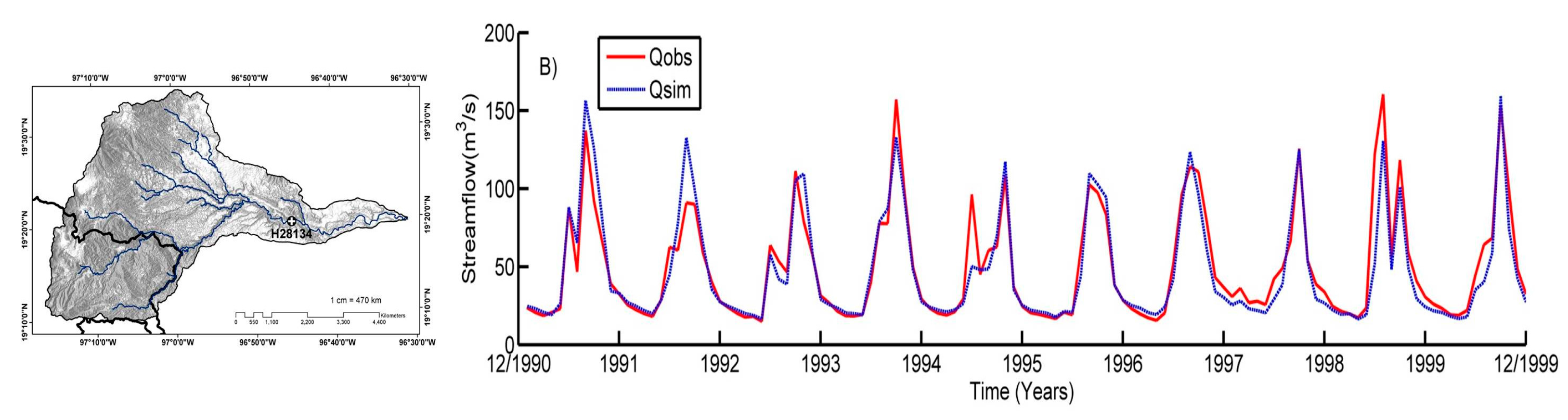
The essential data for distributed hydrological modeling requires two types of information: hydrometeorological and physiographic databases. The first class of data is required on a daily basis for the following variables: minimum temperature, maximum temperature, total precipitation, and streamflow at the outlet of the basin. The second class of data includes the digital elevation model, the land uses, and types of soil.
Subsequently, the data was subjected to a quality control, with the objective of detecting errors in the observation data that could be caused mainly by difficulties in the measurement plus errors due to manipulation and data capture and storage processes. These processes apply to the identification of errors, such as the maximum temperature being greater than the minimum or the precipitation being negative. Other errors have been filtered because they are outside the range of values of the region, such as temperatures above 50 °C or lower than −25 °C [
16].
Description of the Geographic Information System “PHYSITEL”
PHYSITEL [
17] was developed at the INRS-ETE (Institut national de la recherche scientifique centre Eau, Terre et Environnement) in Québec, Canada in 1985 [
18]. It is designed to be used in the preparation of the physiographic database of the HYDROTEL hydrological model [
19]. It allows the integration of various types of data from remote sensing and geographical information systems (GIS). The data used by PHYSITEL are of the raster type (DEM, soil types, and land use) and vector type (hydrographic network, limit of the watershed). PHYSITEL allows characterizing the internal flow structure of a watershed from a numerical elevation model. The determination of the internal flow structure serves as a basis for the characterization of the hydrological units (or sub-basins) that represent the spatial simulation units [
20].
The information on the surface conditions that affect the “evaporation-flow-infiltration” can be integrated to determine the hydrological parameters of the calculation units. PHYSITEL defines the watershed into relatively homogeneous hydrological units (RHHUs) [
21]. These hydrological units are established to contain only one section of the hydrological network. To each of these units is assigned a single value for soil type, which corresponds to the dominant formation for the entire unit. Each one of these units is also assigned the percentages represented by each land-use class [
17,
21]. At the end, PHYSITEL allows us to export to HYDROTEL the following data: altitude, slope, flow orientation, hydrographic network, and delineation of each RHHU, based on a user defined threshold that is set according to the desired level of detail.
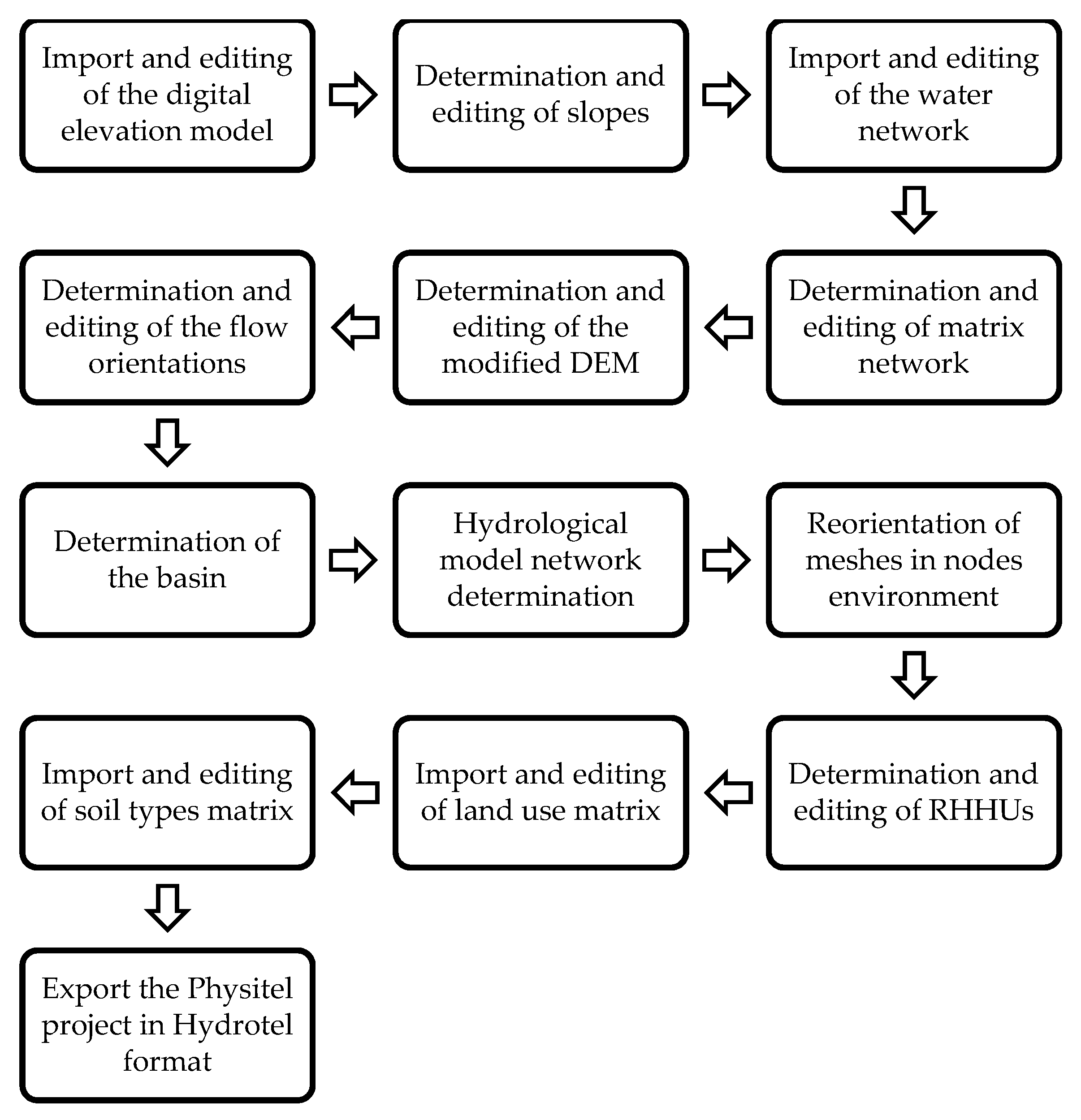
Figure 2 shows a block diagram of each characterization and quantification stage when PHYSITEL was utilized.
3.2. Application of the Distributed Hydrological Model (HYDROTEL)
HYDROTEL [
22] was developed by the INRS-ETE. It is a spatially distributed hydrological model with physical bases specifically developed to facilitate the use of remote sensing and GIS data. This approach brings a better representation of the spatial variability of the physiographic characteristics of river basins (topography, land use, soil types, etc.) and of the meteorological systems that affect the basins [
23].
HYDROTEL comprises six submodules, which run in successive steps. Each Submodule simulates a specific hydrological process.
The first submodule is the Interpolation of meteorological data: this module deals with the interpolation of meteorological variables, including liquid or solid precipitation, minimum and maximum temperatures, relative humidity, wind speed, and solar radiation (when the later three are available; the model can run based on temperature and precipitation data only, and the required input data depends on the selected modeling options as described hereafter). There are two simulation options: thiessen’s polygons or weighted mean of nearest three stations.
The second submodule is the Snow cover estimation: this module simulates the accumulation and melt of snowpack in each RHHU. It simulates daily changes of mean snowpack characteristics (thickness, water equivalent, mean density, thermal deficit, liquid water content, and temperature) using a modified energy budget approach developed by Riley et al., 1973 [
24] (for a complete description, see Turcotte et al., 2007 [
25]).
The third submodule is the Potential evapotranspiration (PET) estimation: this module calculates the PET for each RHHU using a choice of equations depending on available meteorological data: (i) Thornthwaite (1948) [
26]; (ii) Linacre (1977) [
27]; (iii) Penman–Monteith [
28]; (iv) Priestley and Taylor (1972) [
29], or (v) formulation developed by Hydro-Québec.
The fourth submodule is the Vertical water balance: the soil column moisture, rainfall, and/or snow melt are partitioned into infiltration and runoff. For simulation purposes, the soil column is divided into three layers. The first layer controls infiltration, the second layer can be associated with interflow, and the third layer with base flow. There are also two simulation options: vertical balance of three layers (BV3C) and the vertical water budget based on the CEQUEAU hydrological model [
17,
18,
19].
The fifth submodule is the Overland routing: this is the surface and subsurface flow transfer module. The available amount of free water from each soil layer of an RHHU is summed up and routed to the corresponding downslope to the river segments using an RHHU-specific geomorphological unit hydrograph (GUH) [
17,
18,
19]. This hydrograph is determined once for each RHHU using the kinematic wave approximation of the complete Saint-Venant system of equations, but is can be recomputed if necessary. For example, when there is a change in land cover. The shape of the specific GUH is determined by routing a reference water depth over all cells of na RHHU based on the slope and roughness of each cell. The resulting values are considered as lateral inflow to the river segment draining the RHHU [
23].
The sixth submodule is the Channel routing: two simulation options are the diffusive and the kinematic wave equations, both being approximations of the Saint-Venant equations. For more details on these aspects of HYDROTEL, the reader is referred to Fortin et al., 2001 [
19].
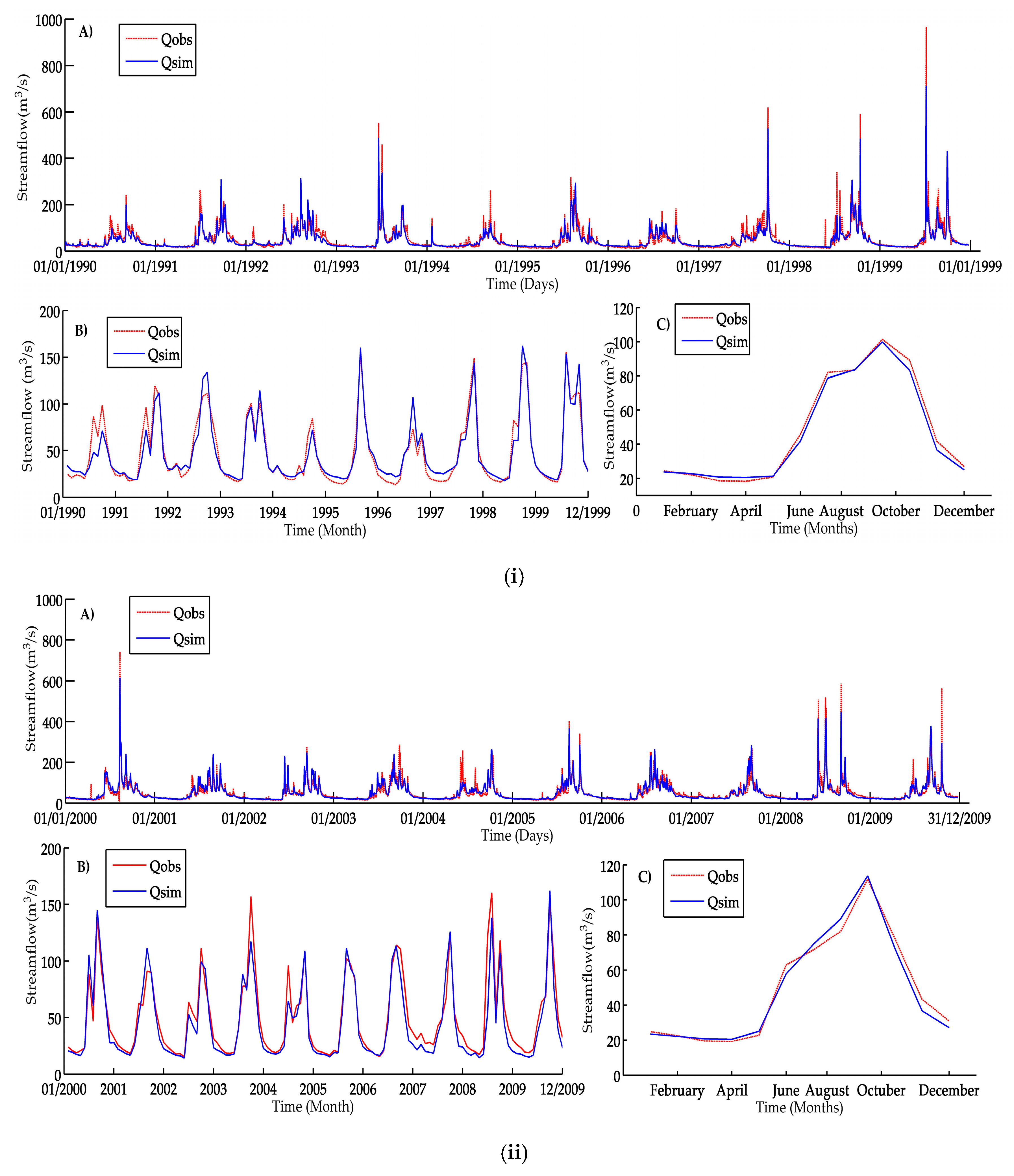
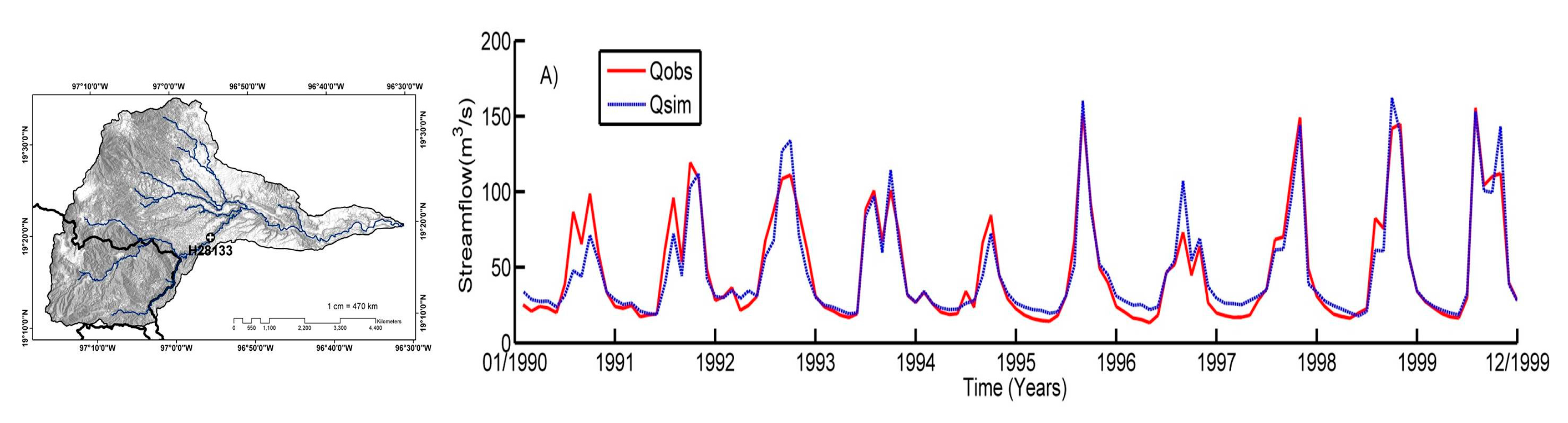
3.3. Calibration of the Distributed Hydrological Model
The hydrological models constitute an important tool in the management of surface water and therefore in hydro-informatics. In order to successfully implement these models, they have to be calibrated. In the calibration process of the model, the values of the parameters are identified, with the aim of improving the goodness of fit between the simulated data time series and the observed data. To evaluate the goodness of fit of the model, an “objective function” is used. This process can be performed in two ways: test-error (manually) and automatically. In the latter case, the calibration is performed using an optimization algorithm that is linked to the hydrological model [
30].
In this study, the Dynamically Dimensioned Search (DDS) algorithm was used. It is designed to be an efficient tool for calibration of complex and large-parameter-space hydrological models [
31]. The DDS algorithm automatically scales the search space to decrease the number of model evaluations required to reach the optimal region of best-quality fitness function [
32]. The single DDS parameter was set to the default value, as recommended by the authors of the algorithm (for more details about the DDS algorithm, refer to Tolson and Shoemaker [
32].
The calibration was evaluated by the statistical indicators. The indicators used in this study are the ones recommended by Moriasi et al., 2007 [
33], namely the Nash-Sutcliffe model efficiency index, which is equal to one minus the ratio of the Mean Square Error (MSE) and standard deviation of measured data time series [
34]. The Nash-Sutcliffe efficiency (
NSE) [
35] is computed as the relative magnitude of the residual variance compared to the variance of the observed data “information”. The
NSE is shown in Equation (1) (see also
Table 1 for signification of the
NSE values).
where
is the ith observation for the constituent being evaluated,
is the ith simulated value for the constituent being evaluated,
is the mean of observed data for the constituent being evaluated, and
n is the total number of observations.
NSE ranges between −∞ and 1.0 (1 inclusive), with
NSE = 1 meaning a perfect match between simulated and observed values. Values between 0.0 and 1.0 are generally viewed as acceptable levels of performance (
Table 1), whereas negative values mean that the mean of observed data is a better predictor than the simulated data [
35].
The RMSE-observations standard deviation ratio (
RSR) is calculated as the ratio of the Root Mean Square Error (RMSE) and standard deviation of measured data (Equation (2)) and was developed based on the recommendation by Singh et al. [
36]
RSR combines both an error index and the additional information recommended by Legates and McCabe [
37]. An
RSR of zero indicates the optimal value, while
RSR > 0.7 represents unsatisfactory model performance [
38] as shown in
Table 1.
Percent bias (
PBIAS) is the relative bias of data being evaluated, expressed as a percentage.
PBIAS measures the average tendency of the simulated data to be larger or smaller than their observed counterparts [
39]. The optimal value of
PBIAS is 0.0, with low-magnitude values indicating accurate model simulation. Positive values indicate model underestimation
PBIAS and negative values indicate model overestimation
PBIAS [
36,
37] (see
Table 1).
PBIAS is calculated with Equation (3):









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}