
Superpixel-Based Long-Range Dependent Network for High-Resolution Remote-Sensing Image Classification



Abstract
:1. Introduction
2. Method
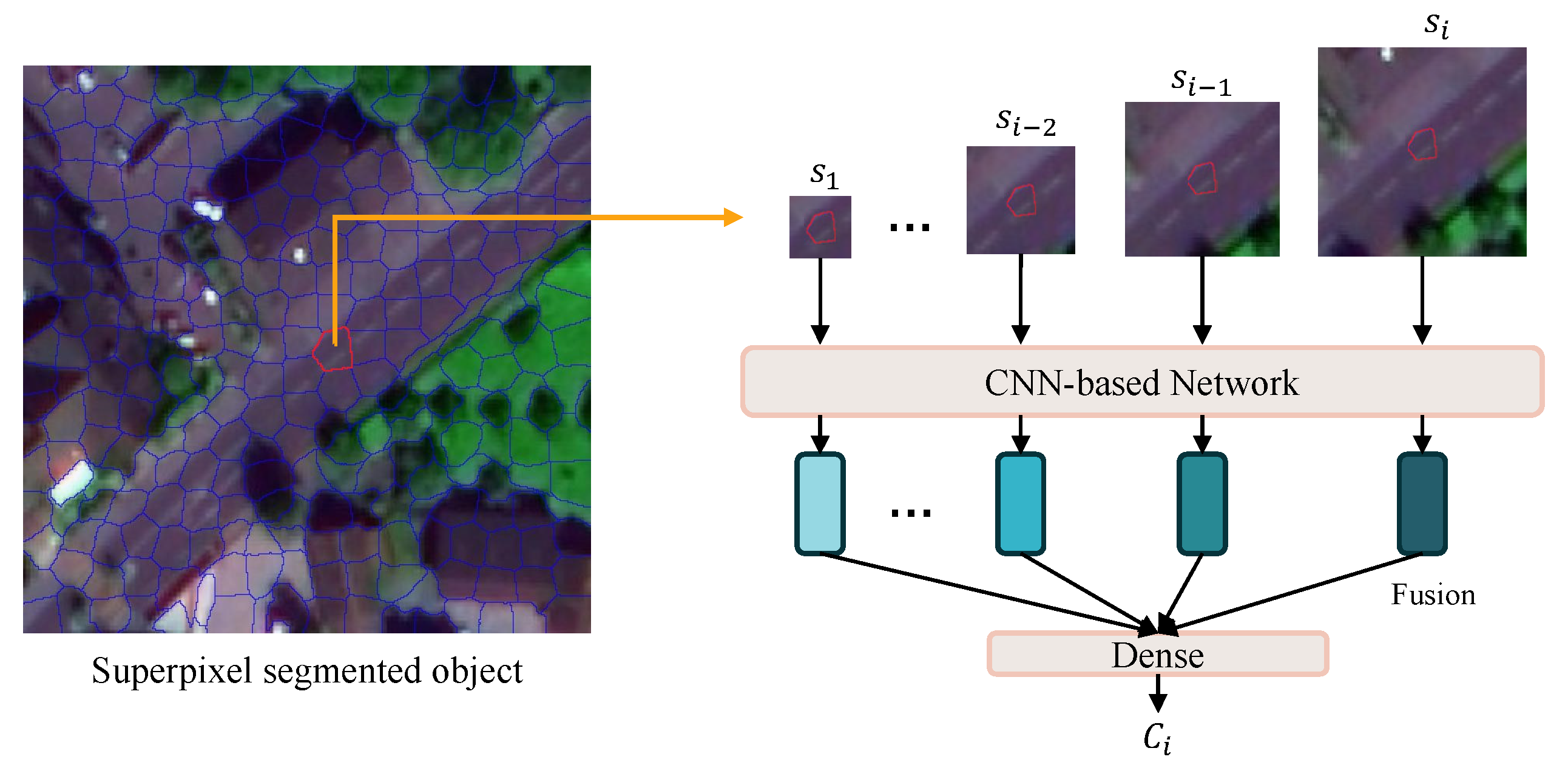
2.1. Methodological Framework
2.2. Superpixel Segmentation
- (1)
- The seed points (clustering centers) are initialized according to the set number of superpixels, and the seed points are distributed evenly within the image. Suppose the image has a total of N pixel points, pre-segmented into k superpixels of the same size; then, the size of each superpixel is , and the distance (step) of adjacent seed points is approximated as .
- (2)
- The seed points are reselected in the neighborhood, the gradient values of all pixel points in that neighborhood are calculated, and the seed points are moved to the place with the smallest gradient in that neighborhood.
- (3)
- Each pixel point is assigned class labels within the neighborhood around each seed point. The search range is limited to , which can accelerate the convergence of the algorithm. The desired superpixel size is , and the search range is .
- (4)
- Distance metric. The distance metric includes color and spatial distance. For each searched pixel point, they are calculated as the distance to that seed point. The distance is calculated as follows.where represents the color distance, represents the spatial distance, and is the maximum spatial distance within a class, defined as , which is applicable to each cluster. The maximum color distance varies both with pictures and with clusters, so we take a fixed constant m instead. The final distance metric is as follows.Since each pixel point is searched by multiple seed points, each pixel point is given a distance from the surrounding seed points, and the seed point corresponding to the minimum value is taken as the clustering center of that pixel point.
- (5)
- Iterative optimization. The above steps are iterated continuously until the error converges.
2.3. Long-Range Dependent Network
3. Data and Parameter Settings
3.1. Data
3.2. Parameter Settings
3.2.1. Semantic-Range Selection
3.2.2. Model-Training Parameters Setting
4. Experiment and Analysis
4.1. Classification Results
4.2. The Effect of Semantic Range on Classification Accuracy
4.3. Ablation Studies for Network Configuration
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yao, H.; Qin, R.; Chen, X. Unmanned aerial vehicle for remote sensing applications—A review. Remote Sens. 2019, 11, 1443. [Google Scholar] [CrossRef] [Green Version]
- Lv, Z.; Liu, T.; Benediktsson, J.A.; Falco, N. Land cover change detection techniques: Very-high-resolution optical images: A review. IEEE Geosci. Remote Sens. Mag. 2021, 10, 44–63. [Google Scholar] [CrossRef]
- Zhang, C.; Pan, X.; Li, H.; Gardiner, A.; Sargent, I.; Hare, J.; Atkinson, P.M. A hybrid MLP-CNN classifier for very fine resolution remotely sensed image classification. ISPRS J. Photogramm. Remote Sens. 2018, 140, 133–144. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Yao, X.; Feng, X.; Han, J.; Cheng, G.; Guo, L. Automatic weakly supervised object detection from high spatial resolution remote sensing images via dynamic curriculum learning. IEEE Trans. Geosci. Remote Sens. 2020, 59, 675–685. [Google Scholar] [CrossRef]
- Ghaffarian, S.; Valente, J.; Van Der Voort, M.; Tekinerdogan, B. Effect of attention mechanism in deep learning-based remote sensing image processing: A systematic literature review. Remote Sens. 2021, 13, 2965. [Google Scholar] [CrossRef]
- Kotaridis, I.; Lazaridou, M. Remote sensing image segmentation advances: A meta-analysis. ISPRS J. Photogramm. Remote Sens. 2021, 173, 309–322. [Google Scholar] [CrossRef]
- Pan, X.; Zhang, C.; Xu, J.; Zhao, J. Simplified object-based deep neural network for very high resolution remote sensing image classification. ISPRS J. Photogramm. Remote Sens. 2021, 181, 218–237. [Google Scholar] [CrossRef]
- Fang, Y.; Xu, L.; Peng, J.; Yang, H.; Wong, A.; Clausi, D.A. Unsupervised Bayesian classification of a hyperspectral image based on the spectral mixture model and Markov random field. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3325–3337. [Google Scholar] [CrossRef]
- Hoque, M.E.; Kipli, K.; Zulcaffle, T.M.A.; Mat, D.A.A.; Joseph, A.; Zamhari, N.; Sapawi, R.; Arafat, M.Y. Segmentation of retinal microvasculature based on iterative self-organizing data analysis technique (ISODATA). In Proceedings of the 2019 International UNIMAS STEM 12th Engineering Conference (EnCon), Kuching, Malaysia, 28–29 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 59–64. [Google Scholar]
- Ahmed, M.; Seraj, R.; Islam, S.M.S. The k-means algorithm: A comprehensive survey and performance evaluation. Electronics 2020, 9, 1295. [Google Scholar] [CrossRef]
- Navin, M.S.; Agilandeeswari, L. Land use land cover change detection using k-means clustering and maximum likelihood classification method in the javadi hills, Tamil Nadu, India. Int. J. Eng. Adv. Technol. (IJEAT) 2019, 9, 51–56. [Google Scholar] [CrossRef]
- Ruspini, E.H.; Bezdek, J.C.; Keller, J.M. Fuzzy clustering: A historical perspective. IEEE Comput. Intell. Mag. 2019, 14, 45–55. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L.; Zhang, L. Hierarchical feature learning with dropout k-means for hyperspectral image classification. Neurocomputing 2016, 187, 75–82. [Google Scholar] [CrossRef]
- Peng, J.; Li, L.; Tang, Y.Y. Maximum likelihood estimation-based joint sparse representation for the classification of hyperspectral remote sensing images. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 1790–1802. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Zhang, M.; Kang, J.; Hong, D.; Xu, J.; Zhu, X. Estimation of pmx concentrations from landsat 8 oli images based on a multilayer perceptron neural network. Remote Sens. 2019, 11, 646. [Google Scholar] [CrossRef] [Green Version]
- Sheykhmousa, M.; Mahdianpari, M.; Ghanbari, H.; Mohammadimanesh, F.; Ghamisi, P.; Homayouni, S. Support vector machine versus random forest for remote sensing image classification: A meta-analysis and systematic review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 6308–6325. [Google Scholar] [CrossRef]
- Izquierdo-Verdiguier, E.; Zurita-Milla, R. An evaluation of Guided Regularized Random Forest for classification and regression tasks in remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2020, 88, 102051. [Google Scholar] [CrossRef]
- Dong, L.; Du, H.; Mao, F.; Han, N.; Li, X.; Zhou, G.; Zhu, D.; Zheng, J.; Zhang, M.; Xing, L.; et al. Very High Resolution Remote Sensing Imagery Classification Using a Fusion of Random Forest and Deep Learning Technique—Subtropical Area for Example. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 113–128. [Google Scholar] [CrossRef]
- Fu, G.; Liu, C.; Zhou, R.; Sun, T.; Zhang, Q. Classification for high resolution remote sensing imagery using a fully convolutional network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef] [Green Version]
- Ren, Y.; Li, X.; Yang, X.; Xu, H. Development of a dual-attention U-Net model for sea ice and open water classification on SAR images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Niu, Z.; Liu, W.; Zhao, J.; Jiang, G. DeepLab-based spatial feature extraction for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2018, 16, 251–255. [Google Scholar] [CrossRef]
- Sandborn, A.; Engstrom, R.N. Determining the relationship between census data and spatial features derived from high-resolution imagery in Accra, Ghana. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1970–1977. [Google Scholar] [CrossRef]
- Ghamisi, P.; Maggiori, E.; Li, S.; Souza, R.; Tarablaka, Y.; Moser, G.; De Giorgi, A.; Fang, L.; Chen, Y.; Chi, M.; et al. New frontiers in spectral-spatial hyperspectral image classification: The latest advances based on mathematical morphology, Markov random fields, segmentation, sparse representation, and deep learning. IEEE Geosci. Remote Sens. Mag. 2018, 6, 10–43. [Google Scholar] [CrossRef]
- Li, Z.; Li, E.; Samat, A.; Xu, T.; Liu, W.; Zhu, Y. An Object-Oriented CNN Model Based on Improved Superpixel Segmentation for High-Resolution Remote Sensing Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2022, 15, 4782–4796. [Google Scholar] [CrossRef]
- Kim, M.; Warner, T.A.; Madden, M.; Atkinson, D.S. Multi-scale GEOBIA with very high spatial resolution digital aerial imagery: Scale, texture and image objects. Int. J. Remote Sens. 2011, 32, 2825–2850. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Zheng, C.; Wang, L. Semantic segmentation of remote sensing imagery using object-based Markov random field model with regional penalties. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 8, 1924–1935. [Google Scholar] [CrossRef]
- Hong, L.; Zhang, M. Object-oriented multiscale deep features for hyperspectral image classification. Int. J. Remote Sens. 2020, 41, 5549–5572. [Google Scholar] [CrossRef]
- Zhou, W.; Ming, D.; Lv, X.; Zhou, K.; Bao, H.; Hong, Z. SO–CNN based urban functional zone fine division with VHR remote sensing image. Remote Sens. Environ. 2020, 236, 111458. [Google Scholar] [CrossRef]
- Lv, X.; Ming, D.; Chen, Y.; Wang, M. Very high resolution remote sensing image classification with SEEDS-CNN and scale effect analysis for superpixel CNN classification. Int. J. Remote Sens. 2019, 40, 506–531. [Google Scholar] [CrossRef]
- Li, L.; Han, L.; Hu, H.; Liu, Z.; Cao, H. Standardized object-based dual CNNs for very high-resolution remote sensing image classification and standardization combination effect analysis. Int. J. Remote Sens. 2020, 41, 6635–6663. [Google Scholar] [CrossRef]
- Shao, Z.; Zhou, W.; Deng, X.; Zhang, M.; Cheng, Q. Multilabel remote sensing image retrieval based on fully convolutional network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 318–328. [Google Scholar] [CrossRef]
- Volpi, M.; Ferrari, V. Semantic segmentation of urban scenes by learning local class interactions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Operation | Feature Map | Size | Kernel Size | Stride | Activate |
|---|---|---|---|---|---|---|
| Input | - | - | - | - | ||
| 2× CNN | 64 | 3 × 3 | ReLU | |||
| Stage-1 | 2× CNN | 128 | 3 × 3 | ReLU | ||
| Stage-1 | Max Pooling | 128 | 3 × 3 | ReLU | ||
| Stage-2 | 2× CNN | 256 | 3 × 3 | ReLU | ||
| Stage-2 | Max Pooling | 256 | 3 × 3 | ReLU | ||
| Stage-3 | 2× CNN | 512 | 3 × 3 | ReLU | ||
| Stage-3 | Max Pooling | 512 | 3 × 3 | ReLU | ||
| Stage-4 | 2× CNN | 512 | 3 × 3 | ReLU | ||
| Stage-4 | Max Pooling | 512 | 3 × 3 | ReLU | ||
| FCN | FC | - | 256 | - | - | - |
| Reference Data | |||
|---|---|---|---|
| Classified data | TP | FP | |
| FN | TN | ||
| Method | Building | Road | Bare Ground | Vegetation | Water | ||
|---|---|---|---|---|---|---|---|
| Accuracy | OA | ||||||
| OBIA-SVM | |||||||
| Superpixel-DCNN | |||||||
| Deeplab V3 | |||||||
| Proposed | |||||||
| Method | Building | Road | Woodland | Vegetation | Water | ||
|---|---|---|---|---|---|---|---|
| Accuracy | OA | ||||||
| OBIA-SVM | |||||||
| Superpixel-DCNN | |||||||
| Deeplab v3 | |||||||
| Proposed | |||||||
| OBIA-SVM | Superpixel-DCNN | DeepLab v3 | Proposed | Superpixel-DCNN | DeepLab v3 | Proposed | |
|---|---|---|---|---|---|---|---|
| Backend | CPU | GPU | |||||
| GF | |||||||
| QB | |||||||
| Data | Object | MCCB | MCCB + NL | MCCB + YL | MCCB + YL (l = 3) | MCCB + YL (l = 4) | MCCB + YL (l = 5) |
|---|---|---|---|---|---|---|---|
| Building | 0.76 ± 0.03 | ||||||
| Road | 0.78 ± 0.06 | ||||||
| GF | Bare ground | 0.79 ± 0.06 | |||||
| Vegetation | 0.79 ± 0.07 | ||||||
| Water | 0.83 ± 0.06 | ||||||
| Building | 0.92 ± 0.03 | ||||||
| Road | 0.89 ± 0.07 | ||||||
| QB | Woodland | 0.92 ± 0.05 | |||||
| Vegetation | 0.93 ± 0.06 | ||||||
| Water | 0.94 ± 0.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Han, L.; Miao, Q.; Zhang, Y.; Jing, Y. Superpixel-Based Long-Range Dependent Network for High-Resolution Remote-Sensing Image Classification. Land 2022, 11, 2028. https://doi.org/10.3390/land11112028
Li L, Han L, Miao Q, Zhang Y, Jing Y. Superpixel-Based Long-Range Dependent Network for High-Resolution Remote-Sensing Image Classification. Land. 2022; 11(11):2028. https://doi.org/10.3390/land11112028
Chicago/Turabian StyleLi, Liangzhi, Ling Han, Qing Miao, Yang Zhang, and Ying Jing. 2022. "Superpixel-Based Long-Range Dependent Network for High-Resolution Remote-Sensing Image Classification" Land 11, no. 11: 2028. https://doi.org/10.3390/land11112028
APA StyleLi, L., Han, L., Miao, Q., Zhang, Y., & Jing, Y. (2022). Superpixel-Based Long-Range Dependent Network for High-Resolution Remote-Sensing Image Classification. Land, 11(11), 2028. https://doi.org/10.3390/land11112028