



Incorporation of Spatially Heterogeneous Area Partitioning into Vector-Based Cellular Automata for Simulating Urban Land-Use Changes



Abstract
:1. Introduction
2. Study Area and Datasets
3. Methodology
3.1. Spatially Heterogeneous Area Partitioning by DSC Method
3.1.1. Clustering Constrained by Spatial Proximity
3.1.2. Clustering Constrained by Attribute Similarity
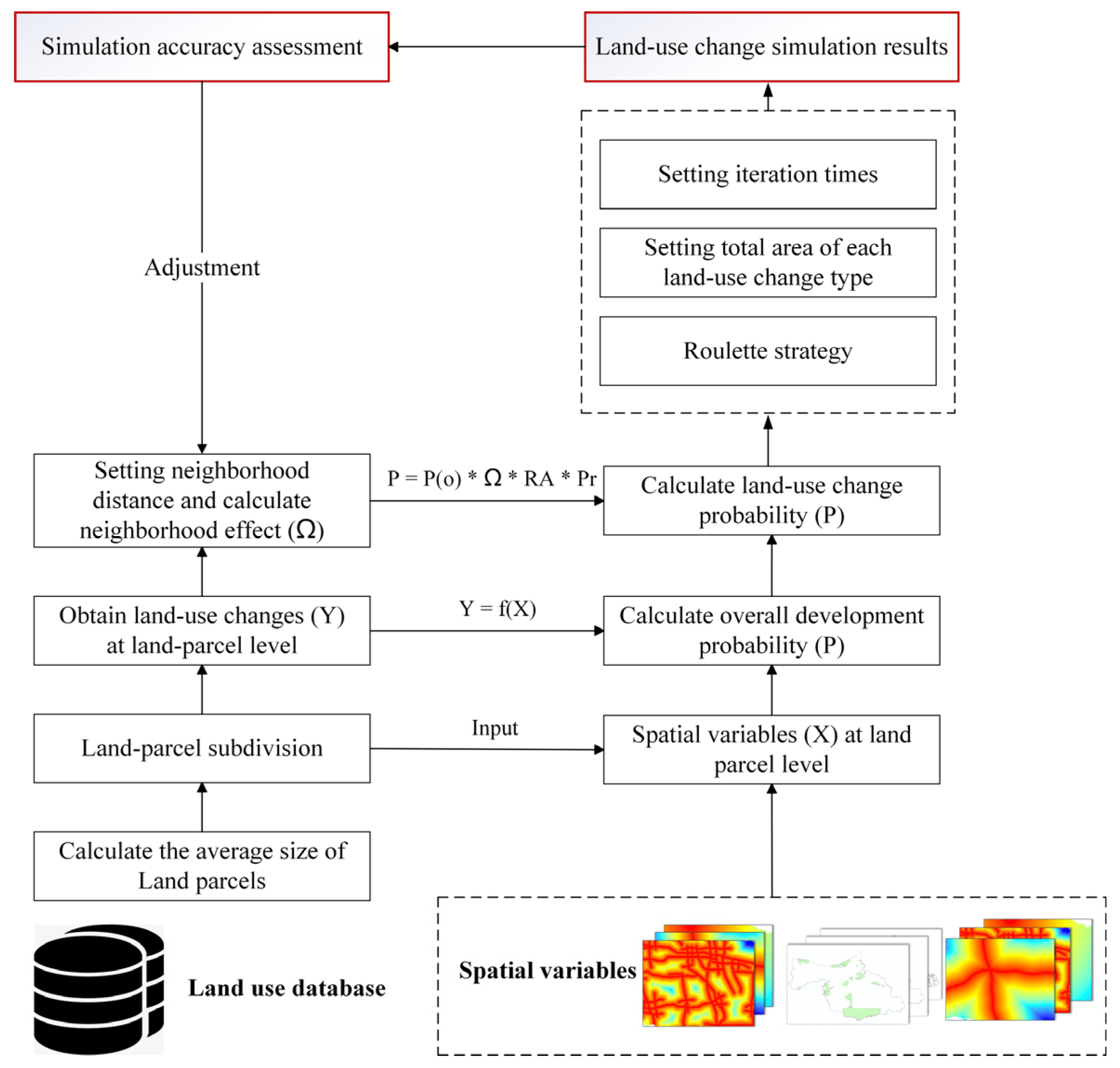
3.2. Urban Land-Use Change Simulation by UrbanVCA Model
3.2.1. Deriving the Minimum Vector Land Parcels
3.2.2. Mining the Urban Development Probability
3.3. Model Performance Assessment
4. Results and Discussions
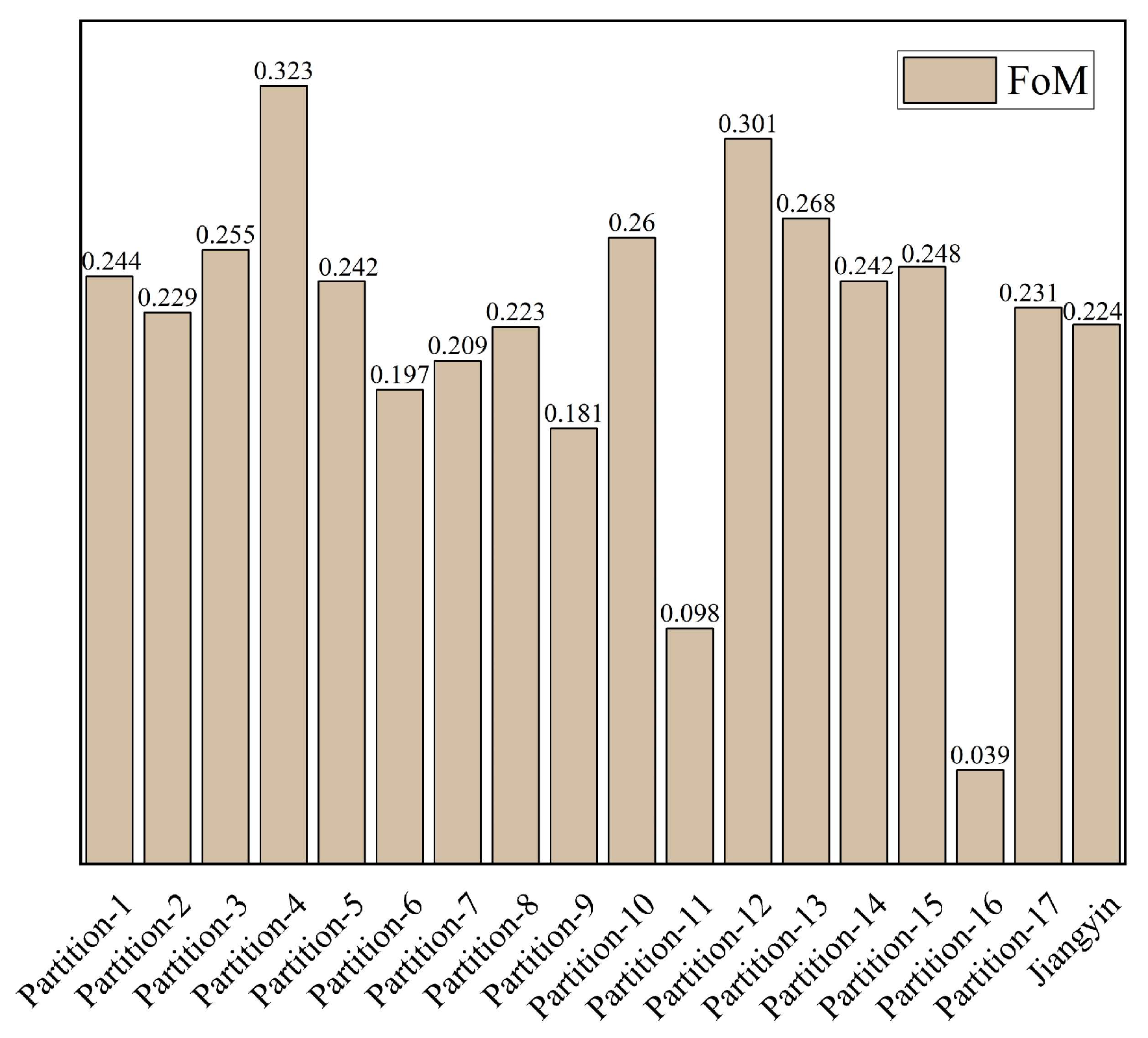
4.1. Area Partitioning Implementation
4.2. Spatial Stratified Heterogeneity Measurement
4.3. Urban Land-Use Changes Simulation
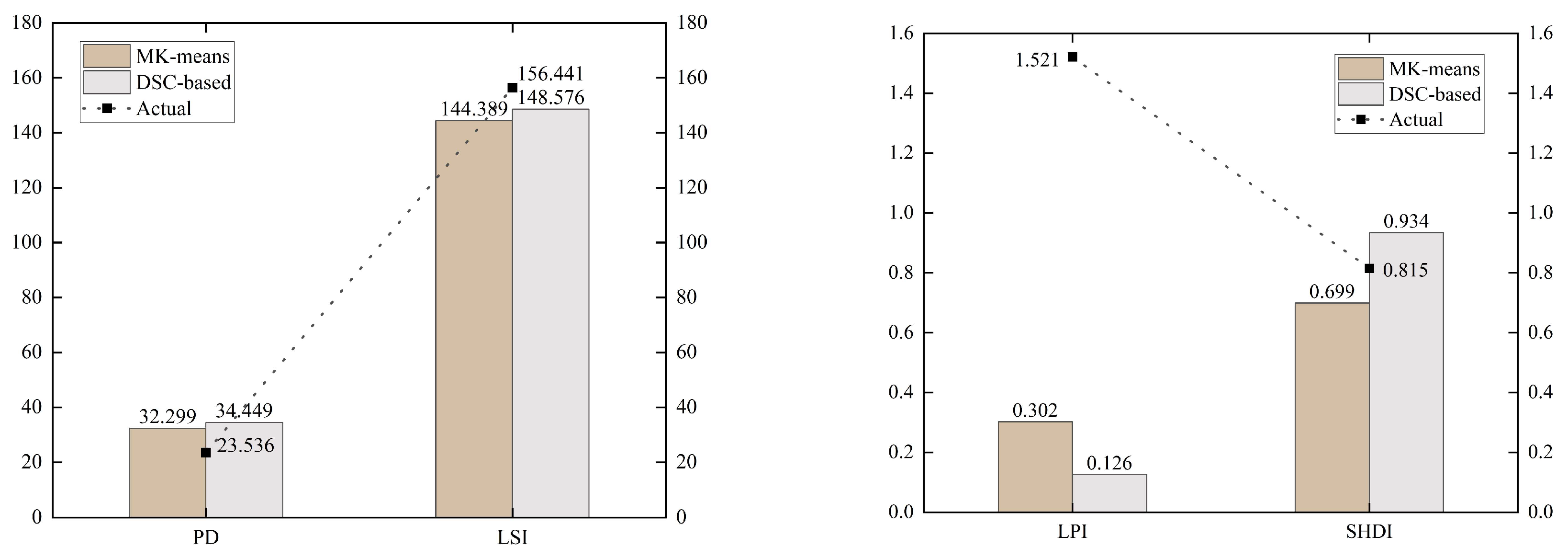
4.4. Model Comparison and Assessment
4.4.1. Comparison of Simulation Using Administrative-Based Zoning
4.4.2. Comparison of Simulation Using Traditional Dual Spatial Clustering Zoning
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, H.; Guo, J.; Zhang, B.; Zeng, H. Simulating urban land growth by incorporating historical information into a cellular automata model. Landsc. Urban Plan. 2018, 214, 104168. [Google Scholar]
- Gao, C.; Feng, Y.; Tong, X.; Lei, Z.; Chen, S.; Zhai, S. Modeling urban growth using spatially heterogeneous cellular automata models: Comparison of spatial lag, spatial error and GWR. Comput. Environ. Urban Syst. 2020, 81, 101459. [Google Scholar]
- Li, X.; Liu, X. An extended cellular automaton using case-based reasoning for simulating urban development in a large complex region. Int. J. Geogr. Inf. Sci. 2006, 20, 1109–1136. [Google Scholar] [CrossRef]
- Liu, X.; Liang, X.; Li, X.; Xu, X.; Ou, J.; Chen, Y.; Li, S.; Wang, S.; Pei, F. A future land use simulation model (FLUS) for simulating multiple land use scenarios by coupling human and natural effects. Landsc. Urban Plan. 2017, 168, 94–116. [Google Scholar]
- Li, X.; Yeh, G. Neural-network-based cellular automata for simulating multiple land use changes using GIS. Int. J. Geogr. Inf. Sci. 2002, 16, 323–343. [Google Scholar] [CrossRef]
- Moreno, N.; Ménard, A.; Marceau, D.J. VecGCA: A vector-based geographic cellular automata model allowing geometric transformations of objects. Environ. Plan. B 2008, 35, 647–665. [Google Scholar] [CrossRef]
- Pinto, N.; Antunes, A.P.; Roca, J. Applicability and calibration of an irregular cellular automata model for land use change. Comput. Environ. Urban Syst. 2017, 65, 93–102. [Google Scholar]
- Yao, Y.; Liu, X.; Li, X.; Liu, P.; Hong, Y.; Zhang, Y.; Mai, K. Simulating urban land-use changes at a large scale by integrating dynamic land parcel subdivision and vector-based cellular automata. Int. J. Geogr. Inf. Sci. 2017, 31, 2452–2479. [Google Scholar]
- Zhu, J.; Sun, Y.; Song, S.; Yang, J.; Ding, H. Cellular automata for simulating land-use change with a constrained irregular space representation: A case study in Nanjing city, China. Environ. Plan. B 2020, 48, 1841–1859. [Google Scholar] [CrossRef]
- Guan, X.; Xing, W.; Li, J.; Wu, H. HGAT-VCA: Integrating high-order graph attention network with vector cellular automata for urban growth simulation. Comput. Environ. Urban Syst. 2023, 99, 101900. [Google Scholar]
- Shi, W.; Pang, M.Y.C. Development of voronoi-based cellular automata -an integrated dynamic model for geographical information systems. Int. J. Geogr. Inf. Sci. 2000, 14, 455–474. [Google Scholar] [CrossRef]
- Semboloni, F. The growth of an urban cluster into a dynamic self-modifying spatial pattern. Environ. Plan. B 2000, 27, 549–564. [Google Scholar] [CrossRef]
- Gonzále, P.; Gómez-Delgado, M.; Benavente, F. Vector-based cellular automata: Exploring new methods of urban growth simulation with cadastral parcels and graph theory. In Proceedings of the International Conference on Computer in Urban Planning and Urban Management (CUPUM), Cambridge, MA, USA, 7–10 July 2015. [Google Scholar]
- Dahal, K.; Chow, T. Characterization of neighborhood sensitivity of an irregular cellular automata model of urban growth. Int. J. Geogr. Inf. Sci. 2015, 29, 475–497. [Google Scholar] [CrossRef]
- Dahal, K.; Chow, T. A GIS toolset for automated partitioning of urban lands. Environ. Model. Softw. 2014, 55, 222–234. [Google Scholar] [CrossRef]
- Feng, Y.; Tong, X. Dynamic land use change simulation using cellular automata with spatially nonstationary transition rules. GISci. Remote Sens. 2018, 55, 678–698. [Google Scholar] [CrossRef]
- Zeng, H.; Zhang, B.; Wang, H. A hybrid modeling approach considering spatial heterogeneity and nonlinearity to discover the transition rules of urban cellular automata models. Environ. Plan. B 2023, 50, 1898–1915. [Google Scholar] [CrossRef]
- Gong, Z.; Thill, J.-C.; Liu, W. ART-P-MAP neural networks modeling of land-use change: Accounting for spatial heterogeneity and uncertainty. Geogr. Anal. 2015, 47, 376–409. [Google Scholar]
- Feng, Y.; Tong, X. Incorporation of spatial heterogeneity-weighted neighborhood into cellular automata for dynamic urban growth simulation. GISci. Remote Sens. 2019, 56, 1024–1045. [Google Scholar] [CrossRef]
- Zhang, B.; Hu, S.; Wang, H.; Zeng, H. A size-adaptive strategy to characterize spatially heterogeneous neighborhood effects in cellular automata simulation of urban growth. Landsc. Urban Plan. 2023, 229, 104604. [Google Scholar]
- Wu, H.; Li, Z.; Clarke, K.C.; Shi, W.; Fang, L.; Lin, A.; Zhou, J. Examining the sensitivity of spatial scale in cellular automata Markov chain simulation of land use change. Int. J. Geogr. Inf. Sci. 2019, 33, 1040–1061. [Google Scholar] [CrossRef]
- Ménard, A.; Marceau, D. Exploration of spatial scale sensitivity in geographic cellular automata. Environ. Plan. B 2005, 32, 693–714. [Google Scholar]
- Liao, J.; Tang, L.; Shao, G.; Su, X.; Chen, D.; Xu, T. Incorporation of extended neighborhood mechanisms and its impact on urban land-use cellular automata simulations. Environ. Model. Softw. 2016, 75, 163–175. [Google Scholar]
- Roodposhti, M.S.; Hewitt, R.J.; Bryan, B.A. Towards automatic calibration of neighbourhood influence in cellular automata land-use models. Comput. Environ. Urban Syst. 2020, 79, 101416. [Google Scholar]
- Ke, X.; Qi, L.; Zeng, C. A partitioned and asynchronous cellular automata model for urban growth simulation. Int. J. Geogr. Inf. Sci. 2016, 30, 637–659. [Google Scholar] [CrossRef]
- Qian, Y.; Xing, W.; Guan, X.; Yang, T.; Wu, H. Coupling cellular automata with area partitioning and spatiotemporal con-volution for dynamic land use change simulation. Sci. Total. Environ. 2020, 722, 137738. [Google Scholar]
- Xia, C.; Zhang, B. Exploring the effects of partitioned transition rules upon urban growth simulation in a megacity region: A comparative study of cellular automata-based models in the Greater Wuhan Area. GISci. Remote Sens. 2021, 58, 693–716. [Google Scholar]
- Lu, Y.; Laffan, S.; Pettit, C. A geographically partitioned cellular automata model for the expansion of residential areas. Trans. GIS 2022, 26, 1548–1571. [Google Scholar] [CrossRef]
- Yang, J.; Zhu, X.; Chen, W.; Sun, Y.; Zhu, J. Modeling land-use change using partitioned vector cellular automata while considering urban spatial structure. Environ. Plan. B 2023, 23998083231152887. [Google Scholar]
- Xu, Q.; Zhu, A.-X.; Liu, J. Land-use change modeling with cellular automata using land natural evolution unit. Catena 2023, 224, 106998. [Google Scholar]
- Kazemzadeh-Zow, A.; Zanganeh Shahraki, S.; Salvati, L.; Samani, N. A spatial zoning approach to calibrate and validate urban growth models. Int. J. Geogr. Sci. 2017, 31, 763–782. [Google Scholar] [CrossRef]
- Xu, Q.; Wang, Q.; Liu, J.; Liang, H. Simulation of Land-Use Changes Using the Partitioned ANN-CA Model and Considering the Influence of Land-Use Change Frequency. ISPRS Int. J. Geo-Inf. 2021, 10, 346. [Google Scholar]
- Ke, X.; Deng, X.; Liu, C. Interregional Farmland Layout Optimization Model Based on the Partition Asynchronous Cellular Automata: A Case Study of the Wuhan City Circle. Prog. Geogr. 2010, 29, 1442–1450, (In Chinese with English Abstract). [Google Scholar]
- Liu, Q.; Wu, Z.; Deng, M.; Liu, W.; Liu, Y. Network-constrained bivariate clustering method for detecting urban black holes and volcanoes. Int. J. Geogr. Inf. Sci. 2020, 34, 1903–1929. [Google Scholar]
- Zhu, J.; Sun, Y.; Chen, L.; Zhou, W.; Meng, Y. A spatial clustering method based on uneven distribution of non-spatial at-tributes—Identifying city commercial center. Geomat. Inf. Sci. Wuhan Univ. 2017, 42, 1697–1701, (In Chinese with English Abstract). [Google Scholar]
- Zhu, J.; Zheng, J.; Di, S.; Wang, S.; Yang, J. A dual spatial clustering method in the presence of heterogeneity and noise. Trans. GIS 2020, 24, 1799–1826. [Google Scholar]
- Yang, J.; Dong, J.; Sun, Y.; Zhu, J.; Huang, Y.; Yang, S. A constraint-based approach for identifying the urban–rural fringe of polycentric cities using multi-sourced data. Int. J. Geogr. Inf. Sci. 2021, 36, 114–136. [Google Scholar]
- Zhu, J.; Lang, Z.; Yang, J.; Wang, M.; Zheng, J.; Na, J. Integrating Spatial Heterogeneity to Identify the Urban Fringe Area Based on NPP/VIIRS Nighttime Light Data and Dual Spatial Clustering. Remote Sens. 2022, 14, 6126. [Google Scholar]
- Yao, Y.; Li, L.; Liang, Z.; Cheng, T.; Sun, Z.; Luo, P.; Ye, X. UrbanVCA: A vector-based cellular automata framework to simulate the urban land-use change at the land-parcel level. arXiv 2021, arXiv:2103.08538. [Google Scholar]
- Zhai, Y.; Yao, Y.; Guan, Q.; Liang, X.; Li, X.; Pan, Y.; Yue, H.; Yuan, Z.; Zhou, J. Simulating urban land use change by integrating a convolutional neural network with vector-based cellular automata. Int. J. Geogr. Inf. Sci. 2020, 34, 1475–1499. [Google Scholar]
- Pakhira, M.K.; Bandyopadhyay, S.; Maulik, U. Validity index for crisp and fuzzy clusters. Pattern Recognit. 2004, 37, 487–501. [Google Scholar]
- Pontius, R.; Boersma, W.; Castella, J.; Clarke, K.; de Nijs, T.; Dietzel, C.; Verburg, P. Comparing the input, output, and vali-dation maps for several models of land change. Ann. Reg. Sci. 2008, 42, 11–37. [Google Scholar] [CrossRef]
- Yin, H.; Kong, F.; Yang, X.; James, P.; Dronova, I. Exploring zoning scenario impacts upon urban growth simulations using a dynamic spatial model. Cities 2018, 81, 214–229. [Google Scholar]
- Tong, X.; Feng, Y. A Review of Assessment Methods for Cellular Automata Models of Land-Use Change and Urban Growth. Int. J. Geogr. Inf. Sci. 2020, 34, 866–898. [Google Scholar]
- Peethambaran, J.; Muthuganapathy, R. A non-parametric approach to shape reconstruction from planar point sets through Delaunay filtering. Comput.-Aided Des. 2015, 62, 164–175. [Google Scholar]
- Wang, J.-F.; Zhang, T.-L.; Fu, B.-J. A measure of spatial stratified heterogeneity. Ecol. Indic. 2016, 67, 250–256. [Google Scholar]
- Zhang, B.; Wang, H. Exploring the advantages of the maximum entropy model in calibrating cellular automata for urban growth simulation: A comparative study of four methods. GISci. Remote Sens. 2022, 59, 71–95. [Google Scholar]
- Zhang, Y.; Liu, X.; Chen, G.; Hu, G. Simulation of urban expansion based on cellular automata and maximum entropy model. Sci. China Earth Sci. 2020, 63, 701–712. [Google Scholar]
- Lin, C.-R.; Liu, K.-H.; Chen, M.-S. Dual clustering: Integrating data clustering over optimization and constraint domains. IEEE Trans. Knowl. Data Eng. 2005, 17, 628–637. [Google Scholar]
- Liu, Q.L.; Deng, M.; Shi, Y.; Wang, J.Q. A density-based spatial clustering algorithm considering both spatial proximity and attribute similarity. Comput. Geosci. 2012, 46, 296–309. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, X.; Liu, D.; Liu, L. An adaptive dual clustering algorithm based on hierarchical structure: A case study of settlement zoning. Trans. GIS 2017, 21, 916–933. [Google Scholar]
- Guo, R.; Chen, D.; Fan, J. Territory spatial planning system and the convergence between different levels. Geogr. Res. 2019, 38, 2518–2526, (In Chinese with English Abstract). [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Comparison Method | Sub-Region | FoM |
|---|---|---|
| Administrative-based zoning | Chengdong | 0.192221 |
| Chengxi | 0.239187 | |
| Chengnan | 0.215116 | |
| Chengdongnan | 0.192636 | |
| Central | 0.256496 | |
| Jiangyin | 0.221000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, J.; Zhu, M.; Na, J.; Lang, Z.; Lu, Y.; Yang, J. Incorporation of Spatially Heterogeneous Area Partitioning into Vector-Based Cellular Automata for Simulating Urban Land-Use Changes. Land 2023, 12, 1893. https://doi.org/10.3390/land12101893
Zhu J, Zhu M, Na J, Lang Z, Lu Y, Yang J. Incorporation of Spatially Heterogeneous Area Partitioning into Vector-Based Cellular Automata for Simulating Urban Land-Use Changes. Land. 2023; 12(10):1893. https://doi.org/10.3390/land12101893
Chicago/Turabian StyleZhu, Jie, Mengyao Zhu, Jiaming Na, Ziqi Lang, Yi Lu, and Jing Yang. 2023. "Incorporation of Spatially Heterogeneous Area Partitioning into Vector-Based Cellular Automata for Simulating Urban Land-Use Changes" Land 12, no. 10: 1893. https://doi.org/10.3390/land12101893
APA StyleZhu, J., Zhu, M., Na, J., Lang, Z., Lu, Y., & Yang, J. (2023). Incorporation of Spatially Heterogeneous Area Partitioning into Vector-Based Cellular Automata for Simulating Urban Land-Use Changes. Land, 12(10), 1893. https://doi.org/10.3390/land12101893