
Assessing the Relative and Combined Effects of Network, Demographic, and Suitability Patterns on Retail Store Sales

Abstract
:1. Introduction
2. Materials and Methods
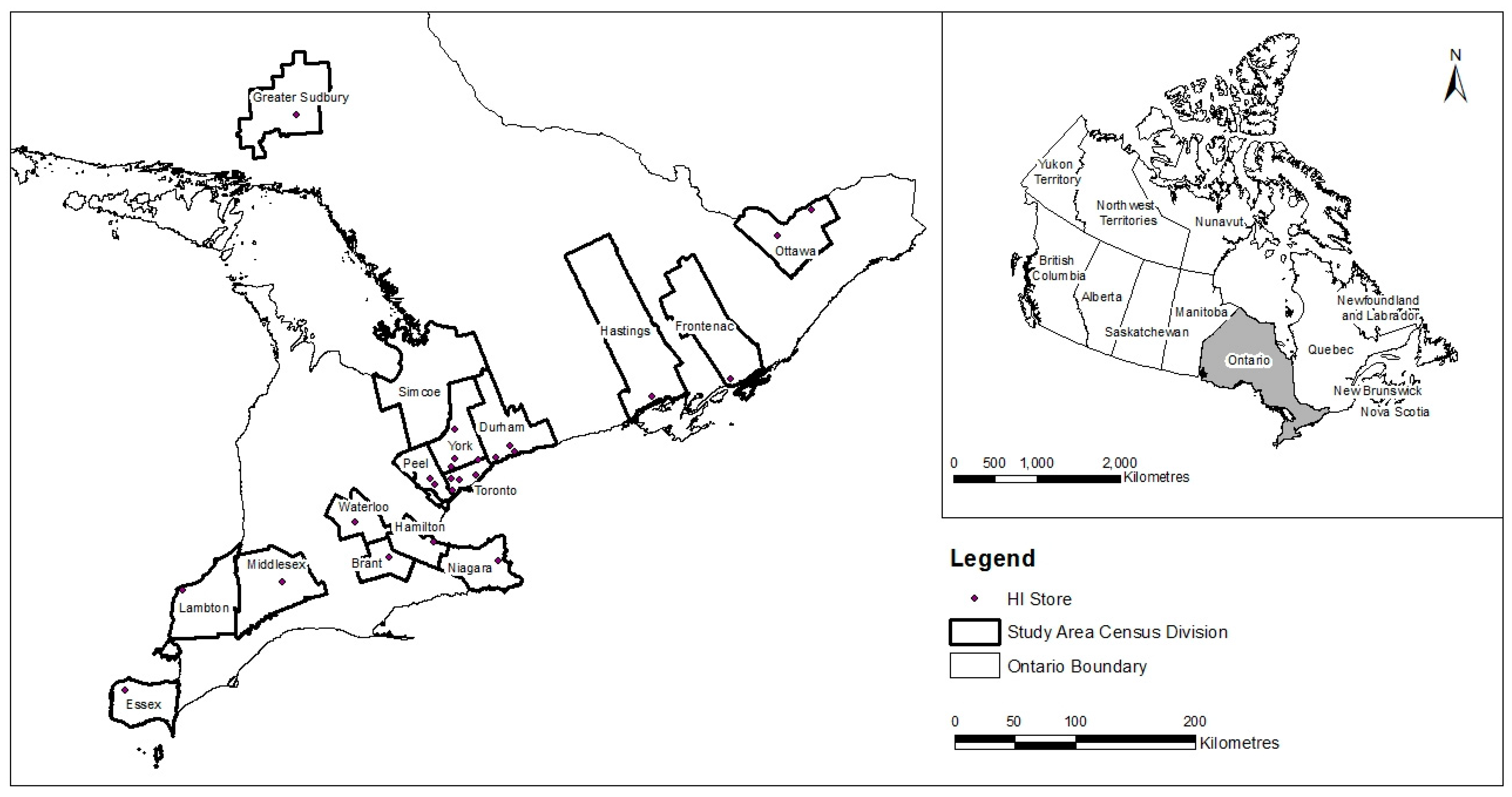
2.1. Study Area
2.2. Data
2.2.1. Road Network Metrics
2.2.2. Demographic Attributes
2.2.3. Suitability Criteria
2.3. Model Selection
3. Results
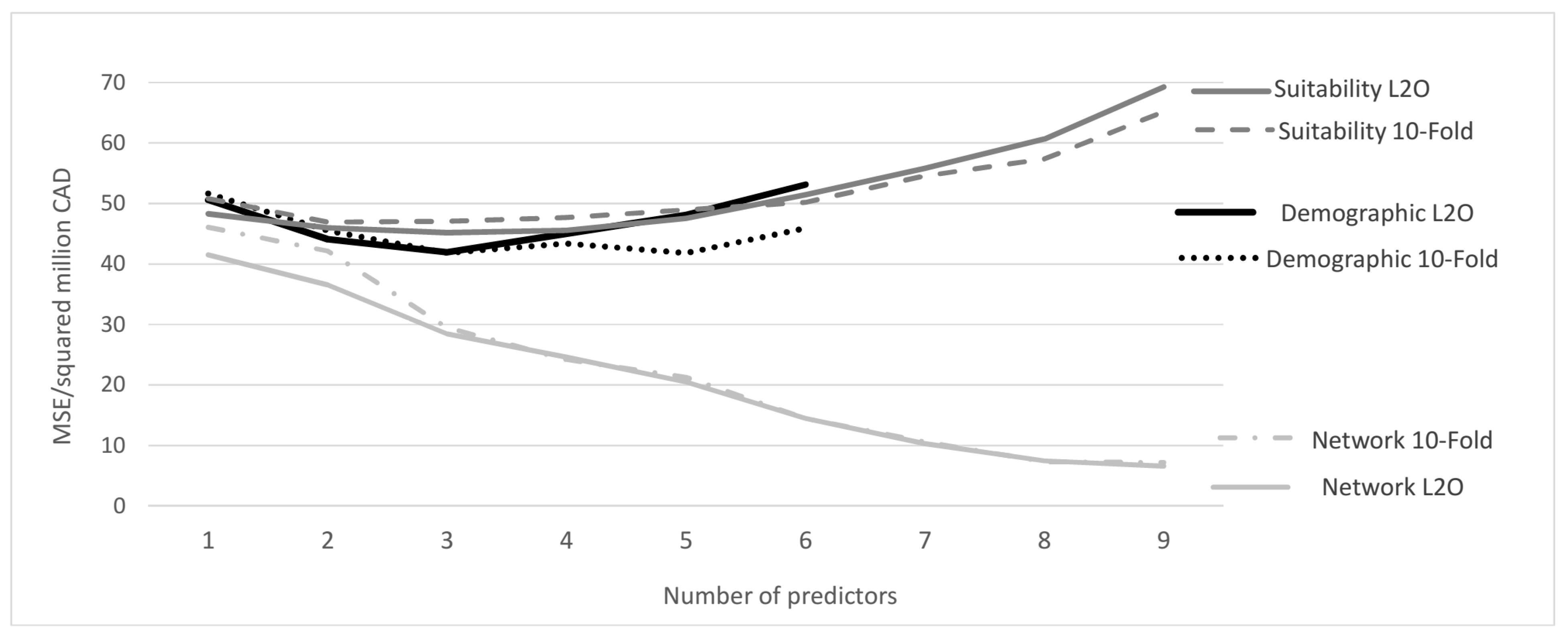
3.1. Model Selection
3.2. Partial Least Squares Regression of Store Sales
3.3. Mathematical Modeling
4. Discussion
Challenges and Opportunities
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Descriptions of Site Suitability Criteria

{kind=link}
{kind=link}
{kind=link}
| Criteria Category | Criteria Name | Criteria Definition and Calculation |
|---|---|---|
| Site variable | site maximum slope | The maximum value of the parcel’s slope. |
| Traffic and transportation variables | traffic visibility | Visibility is correlated with distance from the major highways and the traffic volume. : the suitability of parcel i; : the distance of parcel i to the nearest highway; : the distance threshold of visibility; : traffic volume of the adjacent highway; : the highest traffic volume in the census division. |
| highway accessibility | Travel time from a parcel to the nearest highway access point. | |
| distance to distribution center | The network distance to the nearest distribution centre. | |
| Market variables | market representation | Location quotient of a dissemination area. c: the number of NAICS 444 retailers in a DA’s trade area; C: the number of all retailers in the DA’s trade area; ro: the number of NAICS 444 retailors in Ontario; Ro: the number of all retailers in Ontario. |
| density of competitors | The number of competitors per unit area in the trade area. | |
| density of retail stores | The number of retailers per unit area in the trade area. | |
| Potential expenditures | Estimated expenditure without competitors using Huff’s model. | |
| Competitive expenditures | Estimated expenditure with competitors using Huff’s model. |
Appendix B. Model Selection and Model Details
| Number of Variables | Network L20 Best Groups | Network 10-Fold Best Groups | Network L20 Worst Groups | Network 10-Fold Worst Groups | ||||
|---|---|---|---|---|---|---|---|---|
| Variables | MSE | Variables | MSE | Variables | MSE | Variables | MSE | |
| 1 | ETP | 41.52 | ETP | 46.07 | NCC_sum | 52.38 | NCC_sum | 55.11 |
| 2 | ETP, CC_std | 36.52 | NCC_avg, DC1 | 42.17 | DC1, DC2 | 56.21 | NCC_sum, DC1 | 58.45 |
| 3 | NCC_sum, NCC_avg, DC1 | 28.45 | NCC_sum, NCC_avg, DC1 | 29.45 | BC, DC1, DC2 | 66.17 | NCC_sum, DC1, DC2 | 61.64 |
| 4 | CC_std, NCC_sum, NCC_avg | 24.61 | NCC_sum, NCC_avg, NLC | 24.22 | NCC_sum, BC, DC1, DC2 | 70.97 | NCC_sum, BC, DC1, DC2 | 67.87 |
| 5 | ETP, CC_std, NCC_sum, NCC_avg, DC1 | 20.49 | ETP, CC_std, NCC_sum, NCC_avg, DC1 | 21.27 | CC_std, NCC_sum, BC, DC1, DC2 | 77.85 | CC_std, NCC_sum, BC, DC1, DC2 | 69.97 |
| 6 | CC_std, NCC_sum, NCC_avg, BC, NLC, DC1 | 14.53 | CC_std, NCC_sum, NCC_avg, BC, NLC, DC1 | 14.47 | CC_std, NCC_sum, BC, NLC, DC1, DC2 | 82.35 | CC_std, NCC_sum, BC, NLC, DC1, DC2 | 71.32 |
| 7 | ETP, CC_std, NCC_sum, NCC _avg, NLC, DC1, DC2 | 10.31 | ETP, CC_std, NCC_sum, NCC_avg, NLC, DC1, DC2 | 10.62 | ETP, CC_std, NCC_sum, BC, NLC, DC1, DC2 | 55.16 | ETP, CC1, NCC_sum, NCC_avg, BC, DC1, DC2 | 50.14 |
| 8 | ETP, CC_std, NCC_sum, NCC _avg, BC, NLC, DC1, DC2 | 7.50 | ETP, CC_std, NCC_sum, NCC_avg, BC, NLC, DC1, DC2 | 7.34 | ETP, CC1, CC_std, NCC_avg, BC, NLC, DC1, DC2 | 34.00 | ETP, CC1, CC_std, NCC_avg, BC, NLC, DC1, DC2 | 32.61 |
| 9 | ETP, CC1, CC_std, NCC_sum, NCC_avg, BC, NLC, DC1, DC2 | 6.62 | ETP, CC1, CC _std, NCC _sum, NCC_avg, BC, NLC, DC1, DC2 | 7.19 | ETP, CC1, CC_std, NCC_sum, NCC_avg, BC, NLC, DC1, DC2 | 6.62 | ETP, CC1, CC _std, NCC _sum, NCC_ avg, BC, NLC, DC1, DC2 | 7.19 |
| Number of Variables | Demographic L20 Best Groups | Demographic 10-Fold Best Groups | Demographic L20 Worst Groups | Demographic 10-Fold Worst Groups | ||||
|---|---|---|---|---|---|---|---|---|
| Variables | MSE | Variables | MSE | Variables | MSE | Variables | MSE | |
| 1 | S | 50.61 | Imm, | 51.65 | DC | 52.13 | DC | 52.62 |
| 2 | Imm, DV | 44.07 | Imm, DV | 45.51 | Imm, DO | 59.81 | Imm, DO | 58.40 |
| 3 | DV, DC, Inc | 41.95 | DV, DC, Inc | 41.84 | Imm, DO, Inc | 65.33 | Imm, DO, Inc | 63.42 |
| 4 | DV, S, DC, Inc | 45.02 | DV, DO, DC, Inc | 43.41 | Imm, DO, S, Inc | 69.93 | Imm, DO, S, Inc | 65.28 |
| 5 | Imm, DV, DO, DC, Inc | 48.14 | Imm, DV, DO, DC, Inc | 41.80 | Imm, DO, S, DC, Inc | 73.72 | Imm, DO, S, DC, Inc | 67.20 |
| 6 | Imm, DV, DO, S, DC, Inc | 53.13 | Imm, DV, DO, S, DC, Inc | 45.90 | Imm, DV, DO, S, DC, Inc | 53.13 | Imm, DV, DO, S, DC, Inc | 45.90 |
| Number of Variables | Suitability L20 Best Groups | Suitability 10-Fold Best Groups | Suitability L20 Worst Groups | Suitability 10-Fold Worst Groups | ||||
|---|---|---|---|---|---|---|---|---|
| Variables | MSE | Variables | MSE | Variables | MSE | Variables | MSE | |
| 1 | v | 48.30 | d | 50.80 | ep | 51.74 | v | 62.64 |
| 2 | ep, ec | 46.01 | ep, ec | 46.93 | dc, dr | 57.56 | v, l | 67.43 |
| 3 | v, ep, ec | 45.18 | I, ep, ec | 47.07 | dc, dr, ec | 62.43 | v, I, dc | 71.54 |
| 4 | v, dc, ep, ec | 45.53 | I, dr, ep, ec | 47.67 | b, dc, dr, ec | 69.44 | b, v, I, dc | 77.15 |
| 5 | v, d, dr, ep, ec | 47.54 | d, I, dr, ep, ec | 48.96 | b, I, dc, dr, ec | 73.92 | b, v, I, dc, ec | 82.62 |
| 6 | v, r, d, dc, ep, ec | 51.43 | r, d, I, dr, ep, ec | 50.19 | b, d, I, dc, dr, ec | 78.93 | b, v, I, dc, dr, ec | 87.27 |
| 7 | v, r, d, I, dc, ep, ec | 55.80 | v, r, d, I, de, ep, ec | 54.56 | b, r, d, I, dc, dr, ec | 83.54 | b, v, r, I, dc, dr, ec | 91.54 |
| 8 | v, r, d, I, de, dr, ep, ec | 60.66 | v, r, d, I, dc, dr, ep, ec | 57.35 | b, v, r, d, I, dc, dr, ec | 85.51 | b, v, r, d, I, dc, dr, ec | 92.49 |
| 9 | b, v, r, d, I, dc, dr, ep, ec | 69.29 | b, v, r, d, I, de, dr, ep, ec | 65.21 | b, v, r, d, I, dc, dr, ep, ec | 69.29 | b, v, r, d, I, dc, dr, ep, ec | 65.21 |
| Variable | Model and Components | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PLS-N | PLS-D | PLS-S | PLS-ND | PLS-NS | PLS-DS | PLS-NDS | |||||||||||||||
| Comp1 | Comp2 | Comp1 | Comp2 | Comp1 | Comp2 | Comp1 | Comp2 | Comp3 | Comp4 | Comp1 | Comp2 | Comp3 | Comp4 | Comp1 | Comp2 | Comp1 | Comp2 | Comp3 | Comp4 | ||
| Response | Sales | 0.6700 | 0.0902 | 0.4625 | 0.4189 | 0.2563 | 0.7776 | 0.7138 | 0.2524 | 0.2226 | 0.2969 | 0.7033 | 0.1602 | 0.7567 | 0.1113 | 0.2800 | 0.5601 | 0.6866 | 0.1376 | 0.2741 | 0.4551 |
| Network | ETP | −0.9834 | 0.4842 | −0.9427 | 0.0854 | 0.6813 | −0.2864 | −0.9674 | 0.4700 | 0.5187 | −0.2719 | −0.8558 | −0.2121 | 0.6771 | −0.1173 | ||||||
| CCstd | −0.2882 | −0.8750 | −0.2886 | −0.4893 | −0.8424 | 0.7591 | −0.2999 | −0.9628 | −0.1793 | 0.3304 | −0.2763 | −0.0236 | −1.0755 | 0.7019 | |||||||
| Demography | Imm | −1.4985 | 0.3779 | −0.3600 | 0.8018 | −0.8204 | −0.0998 | −1.0921 | 0.2454 | −0.5142 | 0.5314 | −0.2293 | −0.2232 | ||||||||
| DV | −1.0250 | 0.9258 | −0.1507 | 0.8262 | −0.6887 | 0.5760 | −0.8079 | 0.7770 | −0.2893 | 0.5402 | −0.2352 | 0.6062 | |||||||||
| Suitability | ec | −1.4465 | 0.2973 | 0.1872 | 0.3477 | −1.9167 | 0.5578 | −1.0855 | 0.2769 | −0.4168 | 0.5616 | −0.1458 | −0.3315 | ||||||||
| ep | −1.2820 | 0.9548 | −0.0837 | 0.3544 | −1.0668 | 0.7112 | −0.9593 | 0.5415 | −0.2976 | 0.5772 | −0.1197 | −0.0537 | |||||||||
| Model | Solution |
|---|---|
| MM-N | Sales = 59,949,021 + 3,575,175.74850705 × ETP^2 × cos(7,569,808.40234965 × ETP) − 16,006,445.6002844 × ETP − 2,003,466,882,757.61 × CC2 − 3,575,175.52110255 × cos(7,676,585.41034939 × ETP) |
| MM-D | Sales = 22,834,008.3445785 + 27.8594262541033 × DV + 3,463,461.71205782 × cos(2.05360787074268 × DV) + 6,406,019.97129763 × cos(cos(4.56225343867134 − 2.05360793654371 × DV) − 2.25983877592123 × DV) − 5.94576071728043 × Imm |
| MM-S | Sales = 47,042,164 + 1.34651074261852 × 10−7 × ec^2 + 0.399358756840768 × ec × sin(4.67160825160463 + 6.24910901352305 × 10−12 × ep^2) − 2.68720110076568 × ec − 4.1233865982514 × 10−12 × ep^2 − 12,260,269.8078034 × sin(4.67160825160463 + 6.24910901352305 × 10−12 × ep^2) |
| MM-ND | Sales = 98,810,157 + 18.4712932990908 × DV × ETP^3 + −491,820/sin(sin(cos(0.273486737758484 − 18.1794559208219 × ETP^2))) − 48,771,421.1786275 × ETP − 5,343,228,102,286.45 × CC2 − 1.09731557757784 × 10−5 × Imm^2 |
| MM-NS | Sales = 41,593,617/ETP + 3.95138206990593 × ec × ETP + (571,637,654,447,161 + 325,352 × ep)/(ec × ETP) − 87,125,638.0497329 − 5,765,625,660,388.86 × CC2 − 8.18332187565871 × 10−10 × ep × ec × ETP − 3.95138206990593 × ETP × exp(3.95138206990593 × ETP^2) |
| MM-DS | Sales = 18,377,218 + 31.0449446400918 × DV + 0.417855463557243 × ec + 5,107,267 × sin(sin(0.363700031480952 + 0.255963092026961 × Imm)) − 11.0838224924106 × Imm − 4,892,962.07650244×sin(cos(DV) − 0.249994026057143 × Imm) |
| MM-NDS | Sales = 56,417,606 + ec + 3,879,411,089,253.75 × ETP × CC2 + 9.18861035767154 × ETP × cos(0.0916227305193614 × Imm)/CC2 − 0.00557917257642006 × ep − 22,626,353.0373718 × ETP − 6,525,672,363,595.11 × CC2 |
Appendix C. Correlation Analysis of Predictor Variables
| Roup | Variable | Sales | ETP | CCavg | CCstd | NCCsum | NCCavg | BC | NLC | DC1 | DC2 | lmm | DV | D0 | S | DC | Inc | b | v | r | d | l | dc | dr | ec |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Network | ETP | −0.43 ** | |||||||||||||||||||||||
| CCavg | 0.216 | −0.29 | |||||||||||||||||||||||
| CCstd | −0.24 | −0.31 | 0.248 | ||||||||||||||||||||||
| NCCsum | −0.17 | −0.07 | 0.677 *** | 0.248 | |||||||||||||||||||||
| NCCavg | 0.247 | −0.33 | 0.994 *** | 0.251 | 0.665 *** | ||||||||||||||||||||
| BC | 0.123 | 0.088 | −0.01 | −0.24 | −0.22 | 0.016 | |||||||||||||||||||
| NLC | 0.254 | 0.036 | −0.16 | −0.17 | −0.24 | −0.12 | 0.805 *** | ||||||||||||||||||
| DC1 | −0.11 | −0.14 | 0.717 *** | 0.115 | 0.383 * | 0.73 *** | 0.198 | 0.113 | |||||||||||||||||
| DC2 | 0.016 | −0.02 | 0.128 | −0.24 | −0.26 | 0.165 | 0.736 *** | 0.552 *** | 0.489 ** | ||||||||||||||||
| Demographic | lmm | −0.17 | −0.04 | 0.711*** | 0.183 | 0.798 *** | 0.696* ** | −0.22 | −0.41 ** | 0.472 ** | −0.23 | ||||||||||||||
| DV | 0.07 | −0.23 | 0.628 *** | 0.339 | 0.728 *** | 0.624* ** | −0.32 | −0.39 | 0.225 | −0.42 ** | 0.854 *** | ||||||||||||||
| D0 | −0.15 | −0.05 | 0.735 *** | 0.175 | 0.817 *** | 0.719 *** | –0.25 | –0.43 ** | 0.489 ** | −0.26 | 0.992 *** | 0.849 *** | |||||||||||||
| S | 0.093 | 0.101 | –0.22 | –0.08 | –0.20 | –0.22 | –0.28 | −0.04 | −0.2 | −0.13 | −0.14 | −0.05 | −0.16 | ||||||||||||
| DC | −0.14 | −0.05 | 0.739*** | 0.083 | 0.814*** | 0.724 *** | –0.21 | −0.38 | 0.53 *** | −0.19 | 0.98 *** | 0.826 *** | 0.989 *** | –0.18 | |||||||||||
| Inc | −0.15 | −0.07 | 0.739 *** | 0.191 | 0.821 *** | 0.723 *** | –0.25 | −0.41 ** | 0.493 ** | −0.25 | 0.987 *** | 0.871 *** | 0.995 *** | −0.14 | 0.989 *** | ||||||||||
| Suitability | b | −0.11 | 0.379 * | −0.12 | −0.29 | −0.01 | −0.09 | 0.421 ** | 0.323 | 0.098 | 0.287 | 0.042 | −0.05 | 0.024 | −0.49 ** | 0.05 | 0.019 | ||||||||
| v | –0.34 * | 0.614 *** | −0.16 | −0.32 | 0.026 | −0.20 | −0.07 | −0.1 | −0.06 | −0.02 | 0.025 | −0.20 | 0.025 | 0.196 | 0.051 | 0.026 | 0.042 | ||||||||
| r | 0.101 | −0.51 *** | −0.02 | 0.174 | 0.011 | –0.01 | 0.219 | 0.359 * | 0.012 | 0.087 | −0.13 | −0.04 | −0.13 | −0.22 | −0.11 | −0.12 | 0.032 | −0.43 ** | |||||||
| d | −0.12 | 0.004 | −0.27 | 0.032 | −0.47 ** | −0.24 | 0.483 *** | 0.595 *** | 0.25 | 0.644 *** | 0.53 *** | −0.48 ** | −0.54 *** | 0.119 | −0.49 ** | −0.5 ** | 0.141 | −0.09 | 0.156 | ||||||
| l | −0.03 | 0.141 | −0.75 *** | −0.3 | −0.7 *** | −0.76 *** | 0.194 | 0.239 | −0.53 *** | 0.176 | –0.85 *** | –0.77 *** | –0.85 *** | 0.116 | –0.83 *** | –0.83 *** | 0.022 | 0.062 | −0.01 | 0.424 *** | |||||
| dc | −0.03 | −0.08 | 0.692 *** | −0.05 | 0.656 *** | 0.682 *** | −0.02 | −0.29 | 0.479 ** | −0.03 | 0.837 *** | 0.707 *** | 0.866 *** | −0.26 | 0.893 *** | 0.867 *** | 0.085 | –0.05 | −0.05 | −–0.4 ** | −0.70 *** | ||||
| dr | −0.05 | −0.07 | 0.689 *** | −0.07 | 0.699 *** | 0.686 *** | −0.12 | −0.31 | 0.492 ** | −0.08 | 0.896 *** | 0.768 *** | 0.9 *** | −0.18 | 0.938 *** | 0.9 *** | 0.055 | –0.02 | −0.05 | −0.43 ** | −0.78 *** | 0.948 *** | |||
| ec | −0.11 | −0.07 | 0.727 *** | 0.081 | 0.82 *** | 0.716 *** | −0.22 | −0.38 | 0.502 *** | −0.19 | 0.968 *** | 0.821 *** | 0.979 *** | −0.14 | 0.988 *** | 0.979 *** | 0.044 | 0.021 | −0.1 | −0.49 ** | −0.81 *** | 0.905 *** | 0.938 *** | ||
| ep | 0.036 | −0.16 | 0.753 *** | 0.113 | 0.809 *** | 0.751*** | −0.36 | −0.43 ** | 0.457 ** | −0.28 | 0.894 *** | 0.824 *** | 0.917 *** | −0.17 | 0.935 *** | 0.924 *** | −0.02 | 0.00 | −0.09 | −0.52 *** | −0.83 *** | 0.825 *** | 0.884 *** | 0.939 *** |
Appendix D. Linear Regression of Store Sales
| Predictor | OLS-N | OLS -D | OLS -S | OLS -ND | OLS -NS | OLS -DS | OLS -NDS | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coefficient | p-Value | Coefficient | p-Value | Coefficient | p-Value | Coefficient | p-Value | Coefficient | p-Value | Coefficient | p-Value | Coefficient | p-Value | ||
| Network | ETP | −14,832,939 | 0.005 | −11,330,889 | 0.020 | −12,797,308 | 0.011 | −13,151,747 | 0.007 | ||||||
| CCstd | −2.50 × 1012 | 0.030 | −3.07 × 1012 | 0.007 | −2.52 × 1012 | 0.023 | −3.26 × 1012 | 0.004 | |||||||
| Demographic | Imm | −11.58 | 0.025 | -10.86 | 0.018 | −18.76 | 0.005 | ||||||||
| DV | 44.60 | 0.035 | 46.20 | 0.021 | 35.20 | 0.086 | 41 | 0.030 | |||||||
| Suitability | eC | −0.0086 | 0.033 | −0.00707 | 0.043 | 0 | −0.00488 | 0.026 | |||||||
| eP | 1.436 | 0.038 | 1.16 | 0.057 | 0.90 | 0.079 | |||||||||
| Constant | 59,523,945 | 0 | 19,406,816 | 0.003 | 18,980,303 | 0.005 | 43,436,080 | 0 | 46,995,868 | 0 | 12,804,930 | 0.067 | 49,748,610 | 0 | |
| Coefficients | 2 | 2 | 2 | 4 | 4 | 3 | 4 | ||||||||
| SSE/sqr million | 741.12 | 894.45 | 916.43 | 558.86 | 606.90 | 774.71 | 576.16 | ||||||||
| AIC | 810.03 | 814.92 | 815.55 | 808.07 | 810.22 | 813.75 | 808.87 | ||||||||
| R-Sq | 0.34 | 0.20 | 0.18 | 0.50 | 0.46 | 0.31 | 0.49 | ||||||||
| R-Sq(adj) | 0.28 | 0.14 | 0.11 | 0.41 | 0.36 | 0.22 | 0.39 | ||||||||
| 1 | Community detection was implemented by “community” algorithm in NetworkX package Derek T. Robinson. |
References
- Levy, M.; Weitz, A.B.; Grewal, D. Retailing Management; Irwin/McGraw-Hill: New York, NY, USA, 1998. [Google Scholar]
- Huff, D.L. Parameter Estimation in the Huff Model; ESRI, ArcUser: Redlands, CA, USA, 2003; pp. 34–36. [Google Scholar]
- Statistics Canada. Table 20-10-0072-01—Retail E-Commerce Sales, Unadjusted, Monthly (Dollars). CANSIM (Database). 2017. Available online: https://www150.statcan.gc.ca/t1/tbl1/en/tv.action?pid=2010007201 (accessed on 5 February 2023).
- Goodchild, M.F. LACS: A Location-Allocation Mode for Retail Site Selection. J. Retail. 1984, 60, 84–100. [Google Scholar]
- Clarkson, R.M.; Clarke-Hill, C.M.; Robinson, T. UK supermarket location assessment. Int. J. Retail. Distrib. Manag. 1996, 24, 22–33. [Google Scholar] [CrossRef]
- O’Malley, L.; Patterson, M.; Evans, M. Retailer use of geodemographic and other data sources: An empirical investigation. Int. J. Retail. Distrib. Manag. 1997, 25, 188–196. [Google Scholar] [CrossRef]
- Evans, J.R. Retailing in perspective: The past is a prologue to the future. Int. Rev. Retail. Distrib. Consum. Res. 2011, 21, 1–31. [Google Scholar] [CrossRef]
- Baumgartner, H.; Steenkamp, J.B. Retail Site Selection. SAGE Dict. Quant. Manag. Res. 2011, 31, 271. [Google Scholar]
- Clarke, I.; Bennison, D.; Pal, J. Towards a contemporary perspective of retail location. Int. J. Retail. Distrib. Manag. 1997, 25, 59–69. [Google Scholar] [CrossRef]
- Benoit, D.; Clarke, G.P. Assessing GIS for retail location planning. J. Retail. Consum. Serv. 1997, 4, 239–258. [Google Scholar] [CrossRef]
- Hernandez, T.; Bennison, D. The art and science of retail location decisions. Int. J. Retail. Distrib. Manag. 2000, 28, 357–367. [Google Scholar] [CrossRef]
- Newing, A.; Clarke, G.P.; Clarke, M. Developing and applying a disaggregated retail location model with extended retail demand estimations. Geogr. Anal. 2014, 47, 219–239. [Google Scholar] [CrossRef]
- Zhang, J.; Robinson, D. Investigating path dependence and spatial characteristics for retail success using location allocation and agent-based approaches. Comput. Environ. Urban Syst. 2022, 94, 101798. [Google Scholar] [CrossRef]
- Arentze, T.A.; Borgers, A.W.; Timmermans, H.J. An Efficient Search Strategy for Site-Selection Decisions in an Expert System. Geogr. Anal. 1996, 18, 126–146. [Google Scholar] [CrossRef]
- Onut, S.; Efendigil, T.; Kara, S.S. A combined fuzzy MCDM approach for selecting shopping center site: An example from Istanbul, Turkey. Expert Syst. Appl. 2010, 37, 1973–1980. [Google Scholar] [CrossRef]
- Cooper, L. Heuristic methods for location-allocation problems. Siam Rev. 1964, 6, 37–53. [Google Scholar] [CrossRef]
- Hakimi, S.L. Optimum locations of switching centers and the absolute centers and medians of a graph. Oper. Res. 1964, 12, 450–459. [Google Scholar] [CrossRef]
- Marshall, S. Streets and Patterns; Institute of Community Studies: London, UK, 2005. [Google Scholar]
- Luo, S. RTS-GAT Spatial Graph Attention-Based Spatio-Temporal Flow Prediction for Big Data Retailing. IEEE Access 2022, 10, 133232–133243. [Google Scholar] [CrossRef]
- Statistics Canada. NHS Profile. Retrieved from Statistics Canada. 2011. Available online: https://www150.statcan.gc.ca/n1/en/catalogue/99-004-X (accessed on 5 February 2023).
- Robinson, D.; Balulescu, A. Comparison of Methods for Quantifying Consumer Spending on Retail using Publicly Available Data. Int. J. Geogr. Inf. Sci. 2018, 32, 1061–1086. [Google Scholar] [CrossRef]
- Robinson, D.T.; Caradima, B. A multi-scale suitability analysis of home-improvement retail-store site selection for Ontario, Canada. Int. Reg. Sci. Review. 2022, 46, 016001762210924. [Google Scholar] [CrossRef]
- Balulescu, A.M. Estimating Retail Market Potential Using Demographics and Spatial Analysis for Home Improvement in Ontario; University of Waterloo: Waterloo, ON, Canada, 2015. [Google Scholar]
- Huff, D.L. A programmed solution for approximating an optimum retail location. Land Econ. 1966, 42, 293–303. [Google Scholar] [CrossRef]
- Scikit-Learn Developers. Cross-Validation: Evaluating Estimator Performance. 2017. Available online: http://scikit-learn.org/stable/modules/cross_validation.html (accessed on 5 February 2023).
- Hengl, T.; Heuvelink, G.B.; Stein, A. A generic framework for spatial prediction of soil variables based on regression-kriging. Geoderma 2004, 120, 75–93. [Google Scholar] [CrossRef] [Green Version]
- Spiess, A.-N.; Neumeyer, N. An evaluation of R2 as an inadequate measure for nonlinear models in pharmacological and biochemical research: A Monte Carlo approach. BMC Pharmacol. 2010, 10, 6. [Google Scholar] [CrossRef] [Green Version]
- VanVoorhis, C.R.; Morgan, B.L. Understanding power and rules of thumb for determining sample sizes. Tutor. Quant. Methods Psychol. 2007, 3, 43–50. [Google Scholar] [CrossRef]
- Abdi, H. Partial least squares regression. In Encyclopedia of Measurement and Statistics; Salkind, N., Ed.; Sage Publications: Thousand Oaks, CA, USA, 2007. [Google Scholar]
- Gyourko, J.; Saiz, A. Reinvestment in the housing stock: The role of construction costs and the supply side. J. Urban Econ. 2004, 55, 238–256. [Google Scholar] [CrossRef]
- Kaushal, N.; Lu, Y. Recent immigration to Canada and the United States: A mixed tale of relative selection. Int. Migr. Rev. 2015, 49, 479–522. [Google Scholar] [CrossRef] [Green Version]
- Di Biase, S.; Bauder, H. Immigrant settlement in Ontario: Location and local labour markets. Can. Ethn. Stud. 2005, 37, 114–135. [Google Scholar]
- Palameta, B. Low Income among Immigrants and Visible Minorities; Cataogue no. 75-001-XIE; Statistics Canada: Ottawa, ON, Canada, 2004. [Google Scholar]
- Kaneko, Y.; Yada, K. A deep learning approach for the prediction of retail store sales. In Proceedings of the IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 531–537. [Google Scholar] [CrossRef]
- Tensorflow Developers. TensorFlow (v2.9.3); Zenodo: online, 2022. [Google Scholar] [CrossRef]
- Carr, M.H.; Zwick, P.D. Smart Land-Use Analysis: The LUCIS Model Land-Use Conflict Identification Strategy; ESRI, Inc.: Redlands, CA, USA, 2007. [Google Scholar]
- Saaty, R. The Analytic Hierarchy Process-What and How It Is Used. Math. Model. 1987, 9, 161–176. [Google Scholar] [CrossRef] [Green Version]
- Applebaum, W. Methods for Determining Store Trade Areas, Market Penetration, and Potential Sales. J. Mark. Res. 1966, 3, 127–141. [Google Scholar] [CrossRef]
- Dalrymple, D.J. Sales Forecasting Methods and Accuracy. Bus. Horiz. 1975, 18, 69–73. [Google Scholar] [CrossRef]
- Gómez, M.I.; McLaughlin, E.W.; Wittink, D.R. Customer satisfaction and retail sales performance: An empirical investigation. J. Retail. 2004, 80, 265–278. [Google Scholar] [CrossRef]
- Zotteri, G.; Kalchschmidt, M. Forecasting practices: Empirical evidence and a framework for research. Int. J. Prod. Econ. 2007, 108, 84–99. [Google Scholar] [CrossRef]
- Strother, S.C.; Strother, B.L.; Martin, B. Retail Market Estimation for Strategic Economic Development. J. Retail. Leis. Prop. 2009, 8, 139–152. [Google Scholar] [CrossRef] [Green Version]

| Spatial Scale | Network Metric | |||||||
|---|---|---|---|---|---|---|---|---|
| Global | Local | |||||||
| Fractal | Entropy | Density | BC | LC | CC | NDC | NLC | |
| Census division | N/A | Entropy | Density | Mean & Standard Deviation | ||||
| Service area | ||||||||
| 5-km neighborhood | ||||||||
| Community | ||||||||
| Adjacent roads | N/A | N/A | ||||||
| Fractal area | Fractal | N/A | ||||||
| Group | Variable Name | Symbol | Description |
|---|---|---|---|
| Network | Entropy | ETP | Entropy at community level. |
| Closeness centrality mean | CCavg | Mean of closeness centrality at 5 km neighborhood area. | |
| Closeness centrality standard deviation | CCstd | Standard deviation of closeness centrality at community level. | |
| Node closeness centrality sum | NCCsum | Sum of node closeness centrality at community level. | |
| Node closeness centrality mean | NCCavg | Mean of node closeness centrality at community level. | |
| Betweenness centrality | BC | Standard deviation of betweenness centrality at community level. | |
| Node load centrality | NLC | Mean of node load centrality at adjacent roads. | |
| Degree centrality at service area | DC1 | Sum of degree centrality at service area. | |
| Degree centrality at 5 km | DC2 | Sum of degree centrality at 5 km. | |
| Demographic | Immigrants | Imm | Total population identified as immigrant in the service area. |
| Average dwelling value | DV | Average value of dwelling in the service area. | |
| Dwelling owner | DO | Count of owned dwellings in the service area. | |
| Store area | S | Area of a retail store footprint in square feet. | |
| Dwelling counts | Dc | Count of dwellings in the service area. | |
| Income over CAD 100,000 | Inc | Count of households with income over CAD 100,000. | |
| Suitability | Site maximum slope | b | Maximum value of the parcel’s slope. |
| Traffic visibility | v | Defined base on distance from the major highways and the traffic volume. | |
| Highway accessibility | r | Travel time from a parcel to the nearest highway access point (i.e., ramp). | |
| Distance to distribution centre | d | The network distance to the nearest distribution centre. | |
| Market representation | l | Location quotient of a dissemination area. | |
| Density of competitors | dc | The number of competitors per unit area in the service area. | |
| Density of retail stores | dr | The number of retailers per unit area in the service area. | |
| Potential expenditures | ep | Estimated expenditure without competitors in the service area. | |
| Competitive expenditures | ec | Estimated expenditure with competitors in the service area. |
| Index | Categories of Predictors |
|---|---|
| N | Network metrics |
| D | Demographic variables |
| S | Suitability criteria |
| ND | Network metrics and demographic variables |
| NS | Network metrics and suitability criteria |
| DS | Demographic variables and suitability criteria |
| NDS | Network metrics, demographic variables, and suitability criteria |
| Number of Variables | Network | Demographic | Suitability | |||
|---|---|---|---|---|---|---|
| L20 | 10-Fold | L20 | 10-Fold | L20 | 10-Fold | |
| 1 | 41.52 | 46.07 | 50.61 | 51.65 | 48.30 | 50.80 |
| 2 | 36.52 | 42.17 | 44.07 | 45.51 | 46.01 | 46.93 |
| 3 | 28.45 | 29.45 | 41.95 | 41.84 | 45.18 | 47.07 |
| 4 | 24.61 | 24.22 | 45.02 | 43.41 | 45.53 | 47.67 |
| 5 | 20.49 | 21.27 | 48.14 | 41.80 | 47.54 | 48.96 |
| 6 | 14.53 | 14.47 | 53.13 | 45.90 | 51.43 | 50.19 |
| 7 | 10.31 | 10.62 | - | - | 55.8 | 54.56 |
| 8 | 7.50 | 7.34 | - | - | 60.66 | 57.35 |
| 9 | 6.62 | 7.19 | - | - | 69.29 | 65.21 |
| Group | Variable | Sales | ETP | CCstd | Imm | DV | eC |
|---|---|---|---|---|---|---|---|
| Network | ETP | −0.43 ** | |||||
| CCstd | −0.24 | −0.31 | |||||
| Demographic | Imm | −0.17 | −0.04 | 0.183 | |||
| DV | 0.07 | −0.23 | 0.339 * | 0.854 *** | |||
| Suitability | eC | −0.11 | −0.07 | 0.081 | 0.968 | 0.821 *** | |
| eP | 0.036 | −0.16 | 0.113 | 0.894 *** | 0.824 *** | 0.939 *** |
| Predictor | PLS-N | PLS-D | PLS-S | PLS-ND | PLS-NS | PLS-DS | PLS-NDS | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coef | Std Coef. | Coef | Std Coef. | Coef | Std Coef. | Coef | Std Coef. | Coef | Std Coef. | Coef | Std Coef. | Coef | Std Coef. | ||
| Network | ETP | −14,832,900 | −0.5602 | −11,330,900 | −0.4280 | −12,797,300 | −0.4833 | −11,038,700 | −0.4169 | ||||||
| CCstd | −2.5 × 1012 | −0.4130 | −3.07 × 1012 | −0.5061 | −2.52 × 1012 | −0.4159 | −3.26 × 1012 | −0.5385 | |||||||
| Demographic | Imm | −12 | −0.8576 | −10.8624 | −0.8042 | −12 | −0.8640 | −7.83958 | −0.5804 | ||||||
| DV | 45 | 0.8026 | 46.1737 | 0.8304 | 42 | 0.7620 | 45.3097 | 0.8149 | |||||||
| Suitability | eC | 0 | −1.2417 | −0.0071 | −1.0266 | 0 | −0.4553 | −0.0037 | −0.5437 | ||||||
| eP | 1 | 1.2010 | 1.15981 | 0.9701 | 1 | 0.5653 | 0.4351 | 0.3639 | |||||||
| Constant | 59,523,900 | 0.0 | 19,406,816 | 0.0 | 2 × 107 | 0.0 | 4.3 × 107 | 0.0 | 4.7 × 107 | 0.0 | 1.4 × 107 | 0.0 | 4 × 107 | 0.0 | |
| Coefficients | 2 | 2 | 2 | 4 | 4 | 4 | 6 | ||||||||
| SSR/sqr million | 741.12 | 894.45 | 916.43 | 558.86 | 606.90 | 815.29 | 515.65 | ||||||||
| AIC | 811.51 | 816.40 | 817.03 | 808.17 | 810.31 | 817.99 | 810.08 | ||||||||
| R-Sq | 0.34 | 0.20 | 0.18 | 0.50 | 0.46 | 0.27 | 0.54 | ||||||||
| R-Sq(adj) | 0.28 | 0.14 | 0.11 | 0.41 | 0.36 | 0.14 | 0.40 | ||||||||
| MM-N | MM-D | MM-S | MM-ND | MM-NS | MM-DS | MM-NDS | |
|---|---|---|---|---|---|---|---|
| Number of Coefficients | 6 | 9 | 9 | 6 | 7 | 7 | 6 |
| MSE/sqr million | 7.62 | 8.92 | 13.74 | 7.88 | 9.22 | 6.22 | 5.16 |
| AIC | 787.64 | 804.54 | 815.78 | 788.52 | 796.37 | 786.16 | 777.48 |
| R2 | 0.82 | 0.79 | 0.68 | 0.82 | 0.79 | 0.86 | 0.88 |
| Search time | 2 h 25 min 8 s | 2 h 23 min 17 s | 2 h 22 min 17 s | 19 h 7 min 50 s | 19 h 7 min 23 s | 19 h 6 min 42 s | 48 h 12 min 56 s |
| Generations | 133,584 | 102,599 | 99,772 | 1,176,658 | 1,174,015 | 1,156,005 | 1.45 × 107 |
| Formula evaluations | 4.60 × 109 | 3.50 × 109 | 3.49 × 109 | 4.00 × 1010 | 4.00 × 1010 | 4.00 × 1010 | 4.90 × 1011 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Robinson, D.T. Assessing the Relative and Combined Effects of Network, Demographic, and Suitability Patterns on Retail Store Sales. Land 2023, 12, 489. https://doi.org/10.3390/land12020489
Wang J, Robinson DT. Assessing the Relative and Combined Effects of Network, Demographic, and Suitability Patterns on Retail Store Sales. Land. 2023; 12(2):489. https://doi.org/10.3390/land12020489
Chicago/Turabian StyleWang, Junyi, and Derek T. Robinson. 2023. "Assessing the Relative and Combined Effects of Network, Demographic, and Suitability Patterns on Retail Store Sales" Land 12, no. 2: 489. https://doi.org/10.3390/land12020489