1. Introduction
Land use/land cover maps can provide critical information to many applications, such as ecological and environmental management and urban planning. Researchers in different disciplines showed that land cover/use data have important values in many scientific fields, such as hydrology, agriculture and environment study [
1,
2]. Therefore, land cover/use data play an important role in the study and analysis of global and regional scenarios today [
2,
3,
4].
Satellite remote sensing and GIS are common methods for mapping and detection of land use/cover and its changes [
2,
5,
6,
7,
8], which can provide timely and visual geospatial information [
9,
10,
11,
12,
13,
14]. Due to the wide availability of satellite images, especially medium spatial resolution satellite images such as Landsat images, using satellite images to detect the spatial and temporal variation of land use/cover has been a subject undergoing intense study in remote sensing and GIS [
12]. Many techniques have been developed to classify land use/cover classes from satellite images, including pixel-based classification methods and object-based classification methods [
5,
15,
16,
17]. The advantages and disadvantages of those techniques have been discussed in many studies [
18,
19]. Pixel-based classification methods have been widely used in land use/cover classification for generating land use/cover maps from low or medium spatial resolution remotely sensed images [
11,
20,
21,
22]. However, due to spectral confusion and ignoring spatial correlation, classification results from traditional pixel-based methods are relatively low in accuracy and usually fragmented, with the salt-and-pepper effect [
23]. Although some methods (e.g., majority filter) may remove some noise, their capabilities in classification accuracy improvement are limited because they usually do not incorporate extra credible information from other sources to correct the misclassified pixels. In order to overcome this effect, object-based classification methods were proposed, which allows to group contiguous pixels with similar features into image objects for classification [
24,
25,
26]. Several studies have proved that object-based classification has better performance than pixel-based classification, especially in fine resolution images. The results generated by object-based methods are much more homogeneous than the results generated by pixel-based classification methods. For example, Niemeyer and Canty [
27] thought that object-oriented classification has advantages in detecting changes in finer resolution imagery [
28]. However, the results of object-based classification rely highly on the correctness of the object generation step. On the one hand, medium resolution satellite images may not provide clear boundaries of some ground surface objects; on the other hand, land use/cover classification at medium or coarser spatial resolutions does not require identifying the exact shapes of ground surface individual objects but rather aim to provide relatively large patches of generalized land use/cover classes such as built-up area and farmland. Thus, the classification results by object-based methods using medium resolution remotely sensed images may be relatively low in accuracy when the objects are over- or under-segmented and identified incorrectly due to various reasons, such as spectral confusion and over- or under-emphasis of spectral variations within/between large objects [
29].
Due to the importance of land cover/use information, the demand of accurate classification results is on the increase. In order to improve classification accuracy, many studies have been done to develop advanced classification methods [
30,
31,
32]. However, due to the complexity of the landscape, insufficient quality of remotely sensed data, limitations of classification methods and many other factors, classifying remotely sensed images into a high-quality thematic map remains a challenge [
32,
33]. Land use/cover maps derived from remotely sensed imagery are still insufficient in quality for many quantitative application purposes [
33,
34,
35,
36]. Manandhar et al. [
33] proved that the accuracy of land use/cover classification can be improved by integrating related ancillary data and knowledge-based rules into a classification. To improve the overall accuracy of a classification, the historical information about the land use/cover was employed to estimate the a priori probability of each class [
37,
38]. As an additional descriptive feature, ancillary data, such as height, slope or aspect, was also employed to improve classification accuracy in many studies [
38,
39].
In order to improve land use/cover classification accuracy, Li et al. [
40] suggested a Markov chain random field (MCRF) co-simulation approach for post-classifying the pre-classified image data by traditional methods. This method utilizes expert-interpreted sample data from multiple sources as high-quality sample data in MCRF co-simulation, which takes the pre-classified image data set by a conventional classifier as an auxiliary data set. On the one hand, human eye is no doubt the most convenient, comprehensive and reliable tool for identifying land use/cover classes; on the other hand, more and more data sources about ground surface landscapes, such as Google satellite images, become available. Thus, through expert-interpreted sample data and co-simulation, the method brings extra reliable class label information and spatial correlation information into a pre-classified image so that the classification quality can be improved. Zhang et al. [
41] demonstrated that the MCRF co-simulation (coMCRF) model can effectively improve the accuracies of land use/cover pre-classifications generated by several different pixel-based conventional classifiers for a relative large area with a complex landscape. To reduce the smoothing effect of spatial statistical models (mainly caused by the circular neighborhood) in post-classification, Zhang et al. [
42] modified the coMCRF model by incorporating spectral similarity measures into a spectral similarity-enhanced MCRF co-simulation (SS-coMCRF) model for land use/cover post-classification. The advantage of the SS-coMCRF model over the coMCRF model is that it can better capture the shape features of some land use/cover objects that have relatively distinct spectral values (e.g., waterbodies).
Object-based classification represents another commonly-used classification approach in land use/cover classification from remotely sensed imagery. How to improve the classification accuracy over object-based classifications has been thus an important research topic. Although there may be a variety of methods for improving the accuracy of object-based classifications, the SS-coMCRF model can be a unique way because it improves classification accuracy by incorporating extra reliable information (i.e., expert-interpreted sample data from multiple sources and land use/cover class spatial correlations). The objectives of this study are to (1) test whether and how much the MCRF post-classification method (using the SS-coMCRF model) can improve the accuracies of land use/cover classifications produced by an object-based classifier from medium resolution satellite images; and (2) test the post-classification effect on different landscapes with different classification schemes by choosing four different case study areas.
2. Materials
2.1. Remote Sensing Data
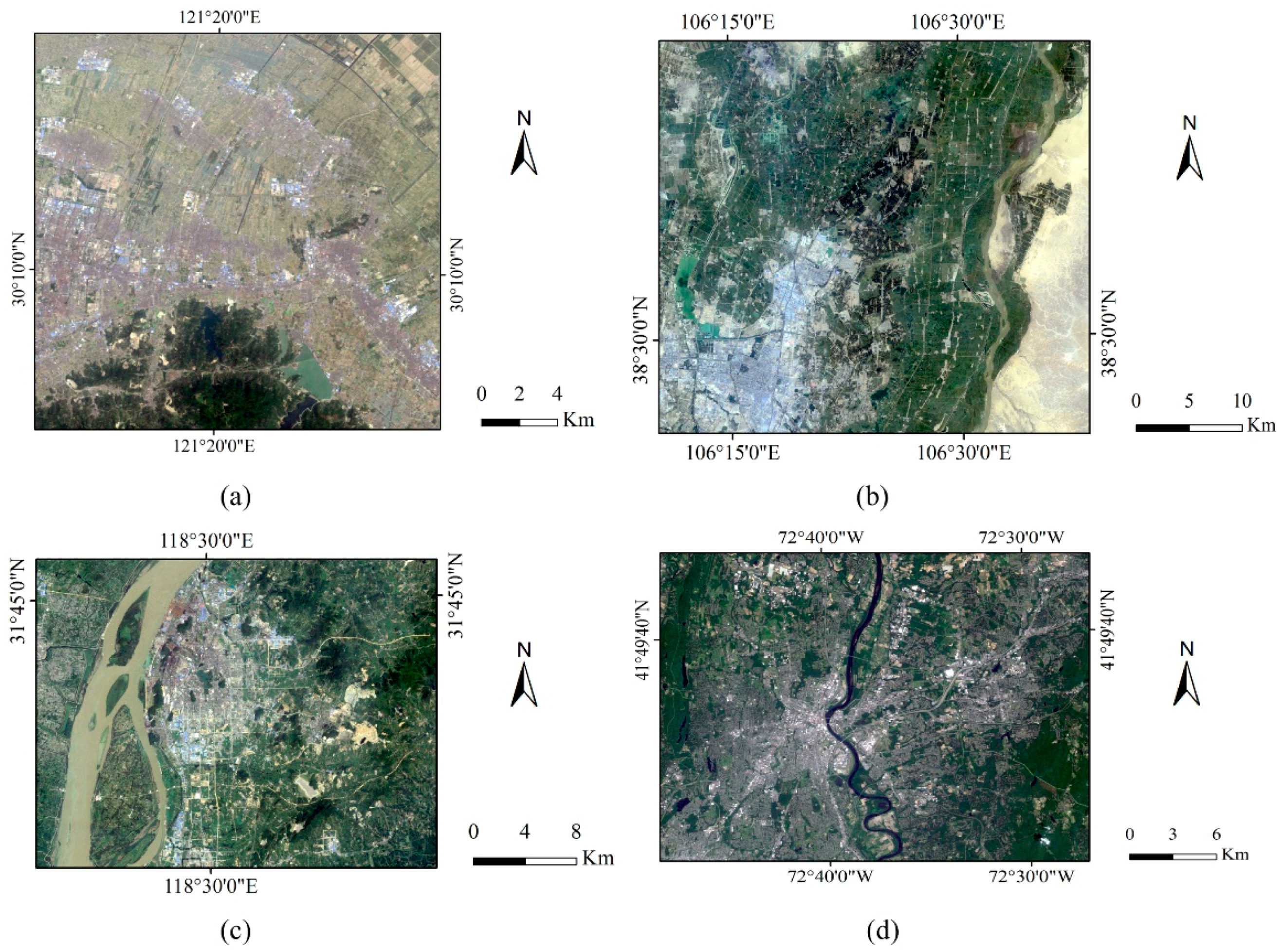
Four cases were chosen to be used in this research: (1) a part of Cixi city, Zhejiang, China, with upper left corner coordinates (121°13′47′′ E, 30°16′42″ N), recorded on 20 May 2011; (2) a part of Yinchuan city (including some area of nearby Shizuishan city), Ningxia, China, with upper left corner coordinates (106°10′33′′ E, 38°44′57″ N), recorded on 18 June 2011; (3) a part of Maanshan city, Anhui, China, with upper left corner coordinates (118°21′27″ E, 31°46′46″ N), recorded on 19 August 2010; (4) a part of Hartford, CT, USA, with upper left corner coordinates (72°48′4′′ W, 41°53′22″ N), recorded on 21 June 2011. Landsat 5 TM imagery was used in this study (see
Figure 1). The images consist of seven spectral bands, with a medium spatial resolution of 30 m for Bands 1 to 5 and 7 and a spatial resolution of 120 m for Band 6. Therefore, Bands 1 to 5 and 7 were extracted for the classification purpose. The images were corrected for atmospheric and geometric distortion prior to use.
The image for the Cixi study area contains 722 columns by 702 rows of pixels and covers a variety of landscape elements, including urban areas, agricultural lands, lakes, rivers and mountains. Therefore, four major land use/cover classes were mapped, namely, built-up area, farmland, woodland and waterbody. The image for the Yinchuan study area, which includes a part of the adjacent Shizuishan city, contains 1354 columns by 1206 rows of pixels, with a complex landscape, including urban areas, agricultural lands, lakes, rivers, mountains and a large area of bare lands. Therefore, four major land use/cover classes were classified, namely, built-up area, farmland, bare land and waterbody. Bare land refers to the areas of bare soils or rocks with little vegetation cover. Generally, vegetation accounts for less than 15% of total cover. The image of the Maanshan study area contains 1047 columns by 800 rows of pixels. It has a more complex landscape, including urban areas, agricultural lands, rivers, mountains and residues of iron mines. So, five major land use/cover classes were mapped, namely, built-up area, farmland, woodland, bare land and waterbody. The image of the Hartford study area contains 995 columns by 809 rows of pixels. The landscape covers urban areas, agricultural lands, rivers, lakes and hills. Five major land use/cover classes were considered in classification, namely, high intensity development, low intensity development, farmland, woodland and waterbody. High intensity development refers to the areas with mainly constructed materials, such as urban cores. Low intensity development means the areas with a mixture of constructed materials and vegetation.
2.2. Expert-Interpreted Data
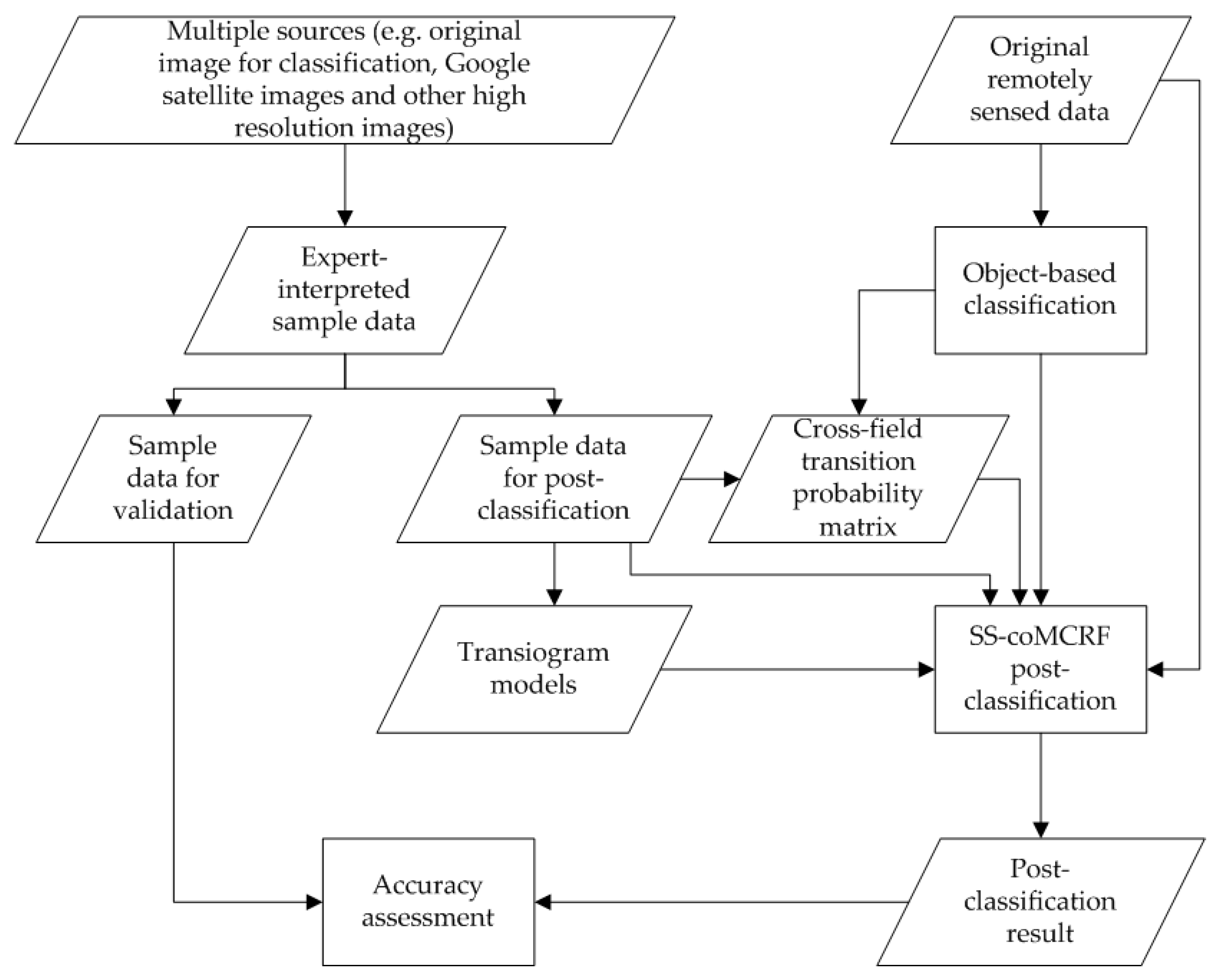
In this study, the SS-coMCRF model [
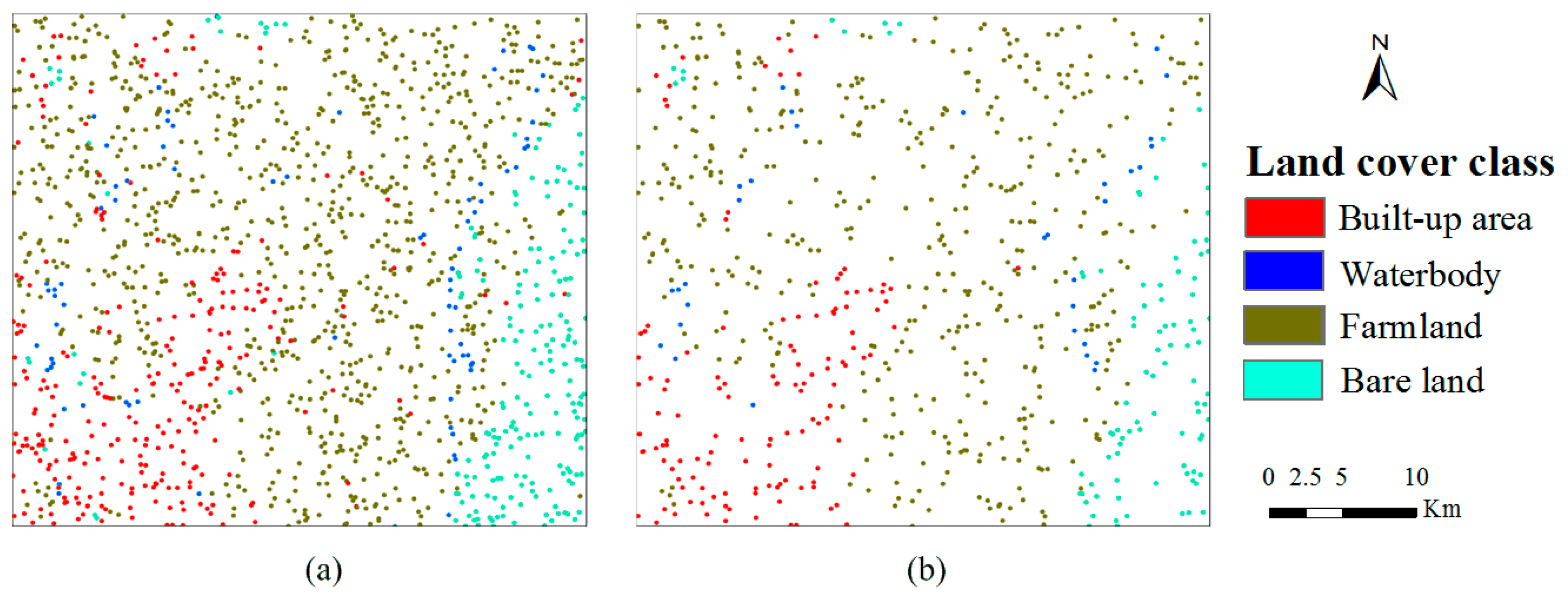
42] was used to improve the accuracy of land use/cover classification by taking a pre-classified image as auxiliary data. To achieve this goal, pre-classification map data and expert-interpreted sample data were needed. For the purposes of land use/cover class identification and accuracy assessment, besides the Landsat images, some other reference data sources were needed for expert-interpretation of sample data (including sample data for validation). The other data sources we used in this study include Google earth imagery, fine resolution images from Terra server and satellite images from DigitalGlobe. The locations of sample data were randomly selected using ArcGIS. During the expert-interpretation process, unidentifiable pixels at selected locations were discarded and only identifiable pixels were interpreted as sample data. For each case study area, specific quantities of expert-interpreted sample data for post-classification and validation for each land use/cover class are given in
Table 1. The total numbers of sample data (pixel class labels) used for post-classification for the four selected study areas are 1309 (0.258% of the total image pixels in the study area) for Cixi, 1428 (0.087% of the total image pixels in the study area) for Yinchuan, 1401 (0.167% of the total image pixels in the study area) for Maanshan and 1500 (0.186% of the total image pixels in the study area) for Hartford, respectively. As an example,
Figure 2 shows the spatial distributions of the expert-interpreted sample data for post-classification and the expert-interpreted sample data for validation for the Yinchuan study area.
4. Results and Discussions
4.1. Case 1
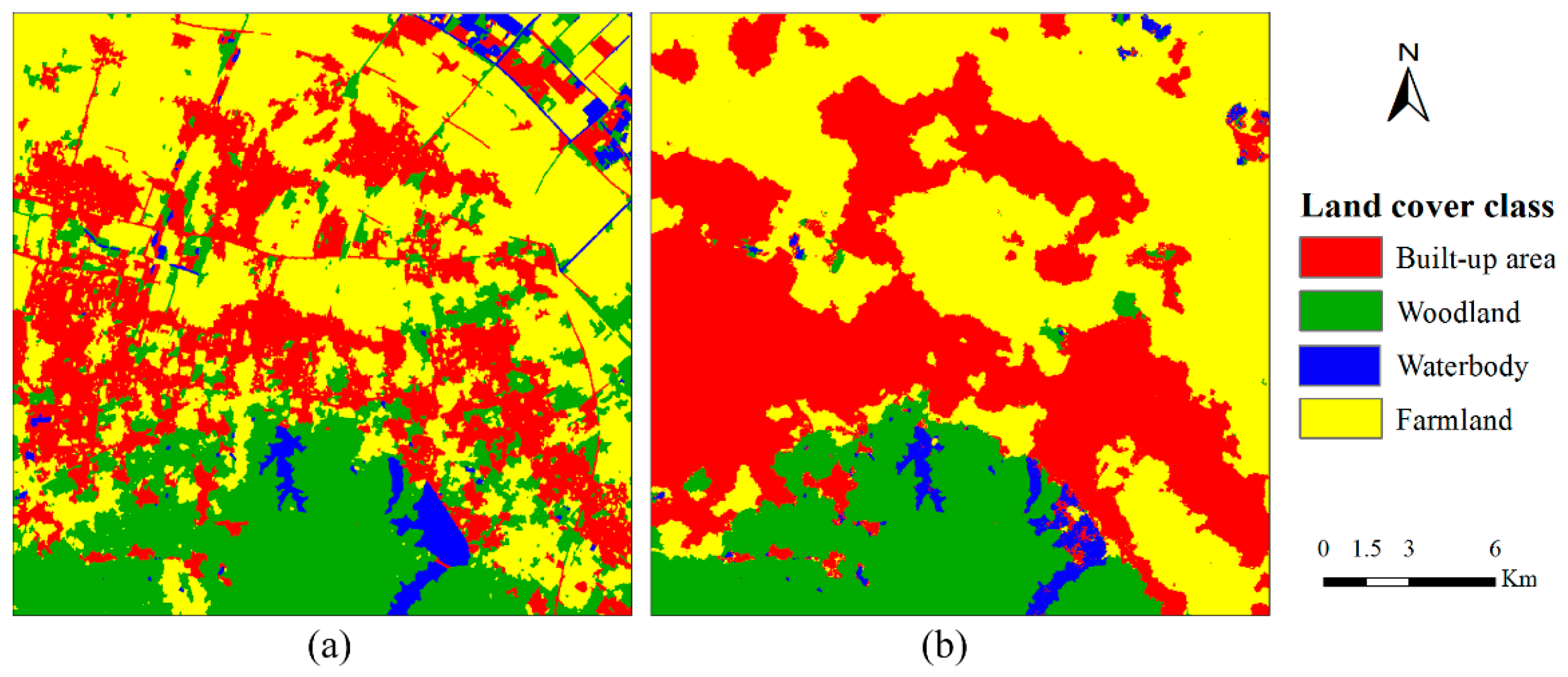
Figure 5 shows the pre-classification map and the corresponding MCRF post-classification map for the Cixi study area.
Table 3 provides a comparison of classification accuracies between the pre-classification and the MCRF post-classification. The overall accuracy (OA) of the pre-classification map is 70.6%. However, the OA for the MCRF post-classification map is 84.7%. The overall improvement in land use/cover classification accuracy is 14.1%. The MCRF post-classification increased kappa coefficient from 0.552 to 0.762. In the pre-classification map, some built-up area pixels were misclassified into woodland and farmland. Due to the complexity of the landscape in this area, it is difficult to distinguish built-up area from woodland and farmland by purely using the KNN OBC method. After post-processing by MCRF co-simulation using the SS-coMCRF model, there are obvious increases in the producer’s accuracies of built-up area (increase from 65% to 87%), woodland (increase from 82% to 89%) and farmland (increase from 71% to 84%). In terms of the user’s accuracies, MCRF post-classification made improvements in the classification of built-up area (increase from 79% to 84%) and woodland (increase from 56% to 85%). However, the producer’s accuracy of waterbody decreased (from 57% to 50%). Considering that waterbody is a minor class, its accuracy assessment is not reliable and has little impact on the overall accuracy. Apparently, MCRF post-classification corrected many misclassified pixels and also reduced small noise features. A drawback is that some linear features (mainly roads or water channels here, pre-classified as linear objects of built-up area, woodland or waterbody), which were partially captured by the pre-classification, were lost in the MCRF post-classification map (
Figure 5).
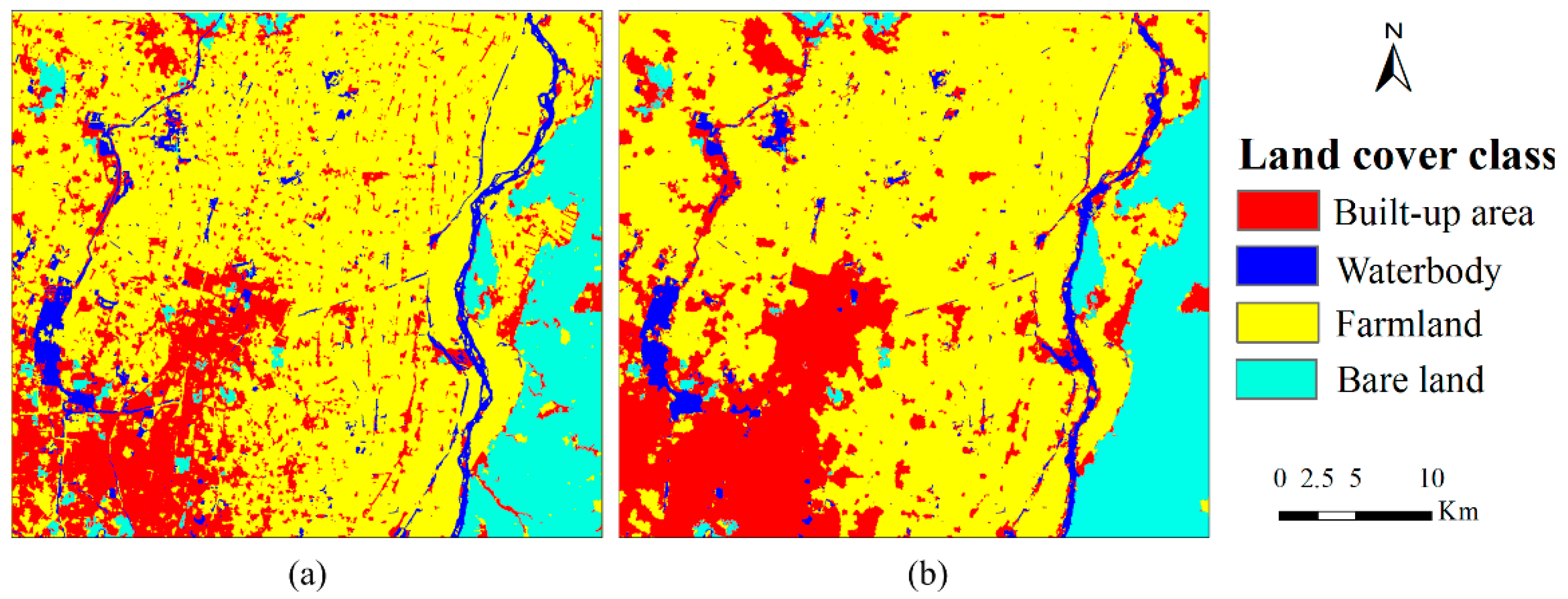
4.2. Case 2
Table 4 and
Figure 6 present the pre-classification results by OBC and the corresponding post-classification results by SS-coMCRF for the Yinchuan study area. Compared with the pre-classification, the MCRF post-classification improved the OA by 5%. All classes have improvement in both producer’s accuracy and user’s accuracy. The MCRF post-classification increased kappa coefficient from 0.650 to 0.746. In the pre-classification map, bare land and built-up area were highly misclassified due to the confusion of their spectral values with farmland in the remotely sensed image, thus resulting in low producer’s accuracy for built-up area (69%) and bare land (68%). Meanwhile, low user’s accuracy (65%) also occurred for the built-up area in the pre-classification map due to the misclassification of some built-up area pixels into bare land and farmland. The MCRF post-classification operation changed this situation by correcting some misclassifications. Both producer’s accuracies and user’s accuracies of the four land use/cover classes were increased after MCRF post-classification. Similarly, most noise was removed in the post-classification map.
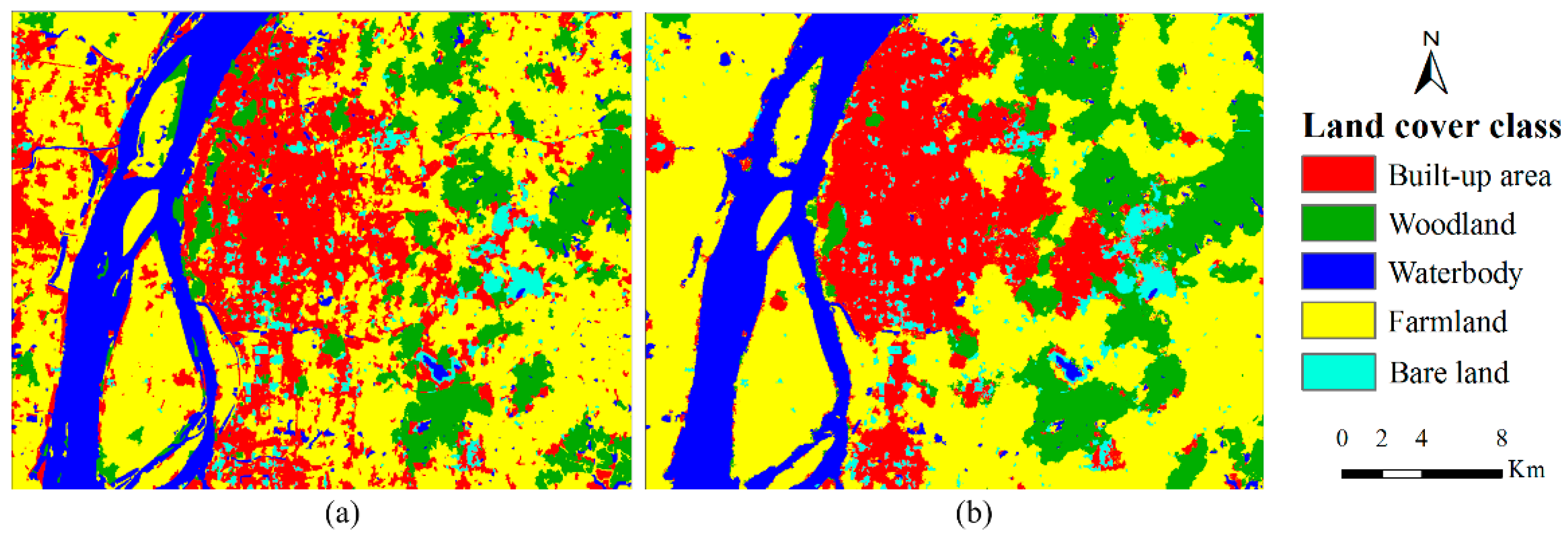
4.3. Case 3
Results for Case 3 are provided in
Figure 7 and
Table 5. There are some residues of iron mines existing in the Maanshan city, which were classified as bare land. It is difficult to distinguish this kind of bare land from built-up area in this study area. That is why the pre-classification map has a relatively low producer’s accuracy for bare land (58%). Before post-classification, some bare land pixels were misclassified as built up area. After post-processing by the SS-coMCRF model, some misclassified bare land pixels were corrected. In the pre-classification map, because of spectral overlap of farmland with built-up area and woodland in the remotely sensed image, some pixels of built-up area and woodland were misclassified as farmland and similarly some pixels of farmland were misclassified as built-up area and woodland, thus resulting in relatively low producer’s accuracies (e.g., 63% for woodland and 70% for farmland). Because some waterbody areas were covered by water plants or other vegetation and those pixels were misclassified as farmland or woodland, the producer’s accuracy of waterbody was 85%. The MCRF post-classification operation changed this situation by correcting many misclassifications and consequently increased the OA and kappa coefficient by 11.8% and 0.165 (from 0.591 to 0.756), respectively. Specifically, post-classification improved the producer’s accuracies of built-up area, woodland, farmland and bare land by 9%, 13%, 13% and 19%, respectively and improved their user’s accuracies by 19%, 13%, 8% and 9%, respectively. The filtering effect of the MCRF post-classification method to noise was also clear.
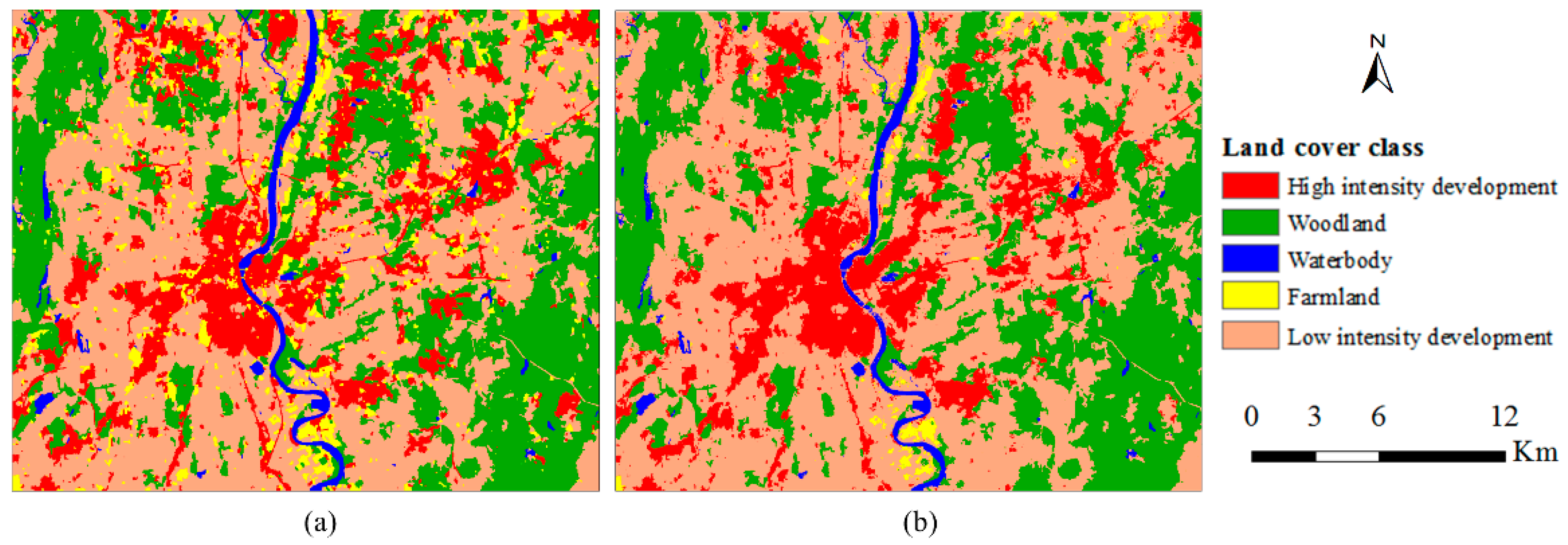
4.4. Case 4
Hartford area has quite different landscape compared with other cases. The landscape was classified into five classes, including high intensity development, low intensity development, waterbody, farmland and woodland (
Figure 8). Due to the complex landscape and the similarity between high intensity development and low intensity development, it is hard to distinguish these two classes. Therefore, many pixels of low intensity development were misclassified into high intensity development in the pre-classification map (
Table 6). Therefore, high intensity development had a relatively low producer’s accuracy (69%). MCRF post-classification was able to correct some misclassified pixels and the producer’s accuracy of high intensity development was improved to 79%. Meanwhile, farmland was also pre-classified with very low accuracy, mainly due to its spectral overlap with developed area (i.e., both high and low intensity development here). MCRF post-classification improved the producer’s accuracy of farmland by 6%. The complex landscape and the local living style (i.e., residential houses are usually scattered in forest or farmland) resulted in high spectral confusion among land use/cover classes except for waterbody. That should be the major reason why the pre-classification OA was relatively low (74.6%), even if waterbody was pre-classified with high accuracy. MCRF post-classification improved the OA by 5.6%. The MCRF post-classification increased kappa coefficient from 0.633 to 0.711.
4.5. Discussions
In this study, the KNN method was used to represent the OBC approach as the pre-classifier. The MCRF post-classification method improves land use/cover classification accuracy by taking extra reliable information (expert-interpreted sample data from multiple sources and class spatial correlations estimated from the sample data) into a pre-classification that is previously performed by a conventional pre-classifier, usually based on spectral data of an original remotely sensed image. It does not matter which method or what kind of methods was used to perform the pre-classification. Depending on image quality, landscape complexity, classification scheme and pre-classification operation, pre-classification accuracy may be relatively high or low; consequently, corresponding accuracy improvement by post-classification may be different (small or large). What we aim to explore in this study is that whether the MCRF post-classification method (here the SS-coMCRF model) can improve the accuracy of the classification results generated by the OBC approach, by incorporating extra reliable information that can be easily available. Although the OBC approach is segment-based and the SS-coMCRF model is pixel-based, this does not mean that the SS-coMCRF model cannot be applied to the classification maps generated by an object-based method. The testing cases in this study showed that the pre-classification results generated by the KNN method is relatively low and considerable accuracy improvement (5% to 14% depending on different landscape cases) could be achieved and some noise (including misclassified small segments) also could be removed by the MCRF post-classification method.
There are no strict requirements on multiple source reference images for interpreting sample data, because what the MCRF post-classification method needs are just the land cover/use class labels of some sample pixels rather than the whole images. So, reference images can include the original image for pre-classification, images at the same or similar resolutions and images with finer resolutions. Fine-resolution images are better for discerning the land cover/use classes of sample pixels. While widely-used classifiers mainly use spectral values for classification, human eye can utilize much more information (such as context information) to discern the land cover/use class of a pixel in an image. So, human eye observation may discern the correct land cover/use classes of many pixels in an image, even if some of them cannot be correctly classified in a classification. As long as the landscape did not change substantially (i.e., the nature of land cover/use did not change) in the study area during the time change, reference images at similar time or even in different seasons are suitable to use. In case some pre-selected pixels cannot be clearly discerned, they can be discarded or alternative discernable pixels at nearby places can be used. If one source (e.g., Google satellite imagery) is not sufficient for interpreting sample data, more data sources may be used. So, this sample data expert-interpretation process seems ambiguous but in fact it is practical, given the availability of many online and offline data sources at the present time.
One limitation of the MCRF post-classification method is that interpreting the needed sample dataset from multiple sources for performing co-simulation may be somewhat time consuming. Currently, this is the main overhead for improving land use/cover classification quality using the MCRF approach. Although a higher density of expert-interpreted sample data may result in larger accuracy improvement in post-classification, the accuracy improvement rate quickly decreases with increasing density of sample data, as demonstrated by Li et al. [
40] and Zhang et al. [
42]. Therefore, the basic requirement for the number of expert-interpreted sample data is that they should suit the estimation of reliable parameters for MCRF co-simulation.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}