A Novel Vertical Fragmentation Method for Privacy Protection Based on Entropy Minimization in a Relational Database

Abstract
:1. Introduction
2. Related Work
2.1. Vertical Fragmentation for Privacy Protection
2.2. Information Entropy
3. Problem Statement
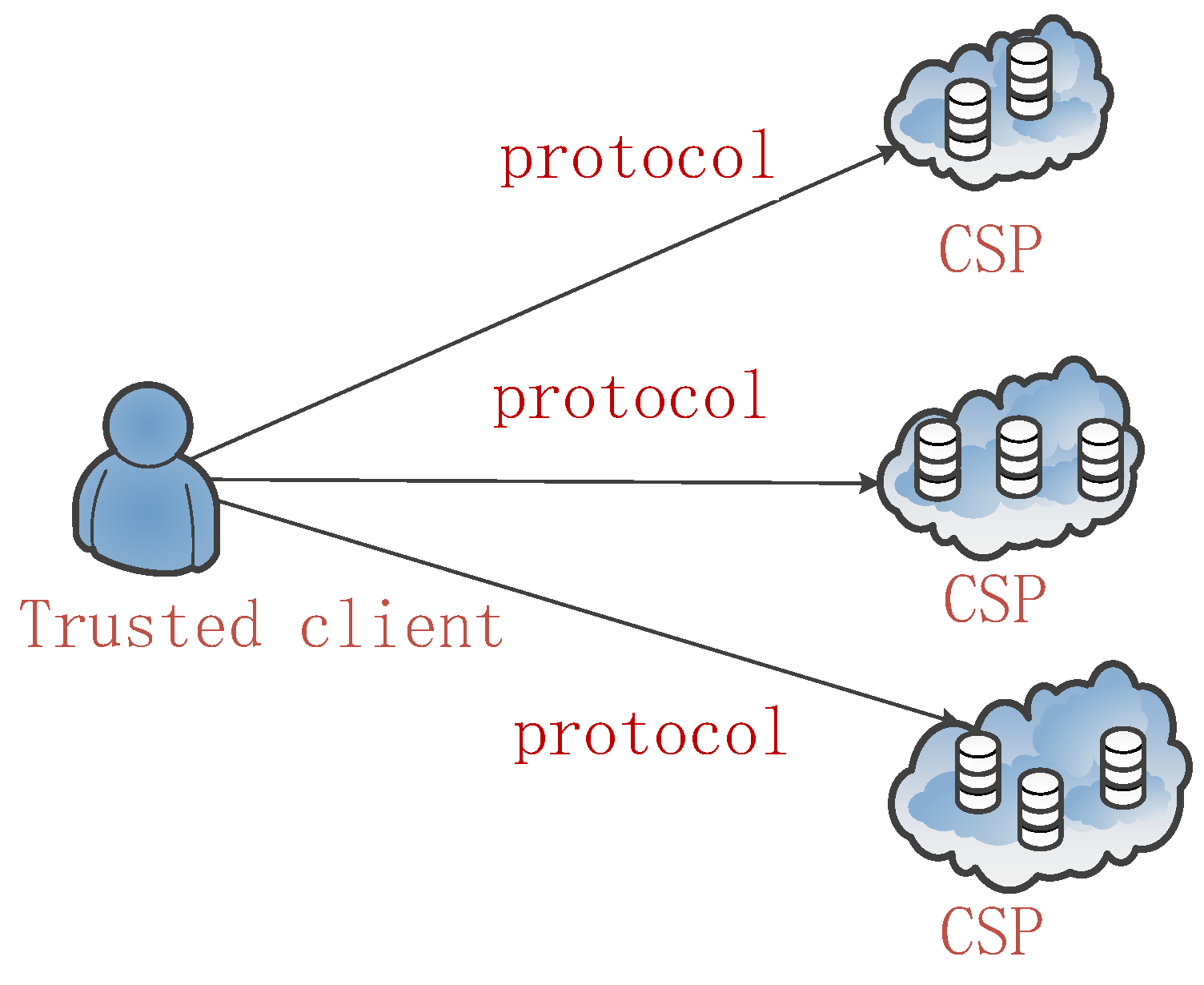
3.1. Vertical Fragmentation with Privacy Constraints
- (i)
- ,
- (ii)
- ,
- (iii)
- .
3.2. Evaluation Standard
4. Approach
4.1. Information Entropy to Quantify Privacy
| Algorithm 1 Automatically Generates Privacy Constraints Algorithm (Table A, Constraints) |
| Input: Input parameters TableA : the table to be fragmented |
| Output: Output Constraints : the privacy constraints |
| 1: |
| 2: |
| 3: for each do |
| 4: ; |
| 5: end for |
| 6: for i = 2 to n − 1 do |
| 7: |
| 8: for j = 1 to do |
| 9: |
| 10: for each do |
| 11: |
| 12: end for |
| 13: |
| 14: if then |
| 15: ; |
| 16: end if |
| 17: end for |
| 18: end for |
4.2. Calculate Minimal Fragmentation
4.3. Minimum Entropy Fragmentation Algorithm
| Algorithm 2 Minimum Entropy Fragmentation Algorithm (TableA, FS) |
| Input: Input parameters Table A : the table to be fragmented |
| Output: Output FS : the result array of fragmentation |
| 1: |
| 2: for each do |
| 3: |
| 4: end for |
| 5: |
| 6: |
| 7: |
| 8: for each do |
| 9: |
| 10: end for |
| 11: |
| 12: for each do |
| 13: |
| 14: |
| 15: |
| 16: for each do |
| 17: if then |
| 18: |
| 19: else |
| 20: |
| 21: end if |
| 22: end for |
| 23: |
| 24: |
| 25: end for |
5. Experiments
5.1. Implementation and Usability Aspects
5.2. Performance Evaluation
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mowbray, M.; Pearson, S. A client-based privacy manager for cloud computing. In Proceedings of the Fourth International ICST Conference on COMmunication System softWAre and MiddlewaRE, Dublin, Ireland, 16–19 June 2009; ACM: New York, NY, USA, 2009; p. 5. [Google Scholar]
- Gentry, C. A Fully Homomorphic Encryption Scheme; Stanford University: Stanford, CA, USA, 2009. [Google Scholar]
- Curtmola, R.; Garay, J.; Kamara, S.; Ostrovsky, R. Searchable symmetric encryption: Improved definitions and efficient constructions. J. Comput. Secur. 2011, 19, 895–934. [Google Scholar] [CrossRef] [Green Version]
- Kamara, S.; Papamanthou, C.; Roeder, T. Dynamic searchable symmetric encryption. In Proceedings of the 2012 ACM Conference on Computer and Communications Security, Raleigh, NC, USA, 16–18 October 2012; ACM: New York, NY, USA, 2012; pp. 965–976. [Google Scholar]
- Samarati, P.; Sweeney, L. Protecting Privacy When Disclosing Information: K-Anonymity and Its Enforcement Through Generalization and Suppression; Technical Report; SRI International: Menlo Park, CA, USA, 1998. [Google Scholar]
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef]
- Machanavajjhala, A.; Gehrke, J. l-Diversity: Privacy Beyond k-Anonymity; IEEE: New York, NY, USA, 2006; p. 24. [Google Scholar]
- Li, N.; Li, T.; Venkatasubramanian, S. t-closeness: Privacy beyond k-anonymity and l-diversity. In Proceedings of the IEEE 23rd International Conference on Data Engineering (ICDE 2007), Istanbul, Turkey, 15–20 April 2007; pp. 106–115. [Google Scholar]
- Hacigümüş, H.; Iyer, B.; Li, C.; Mehrotra, S. Executing SQL over encrypted data in the database-service-provider model. In Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data, Madison, WI, USA, 3–6 June 2002; ACM: New York, NY, USA, 2012; pp. 216–227. [Google Scholar]
- Hore, B.; Mehrotra, S.; Tsudik, G. A privacy-preserving index for range queries. In Proceedings of the Thirtieth International Conference on Very Large Data Bases, Toronto, ON, Canada, 31 August–3 September 2004; Volume 30, pp. 720–731. [Google Scholar]
- Wang, Z.F.; Dai, J.; Wang, W.; Shi, B.L. Fast query over encrypted character data in database. In Proceedings of the International Conference on Computational and Information Science, Shanghai, China, 16–18 December 2004; Springer: Berlin, Germany, 2004; pp. 1027–1033. [Google Scholar]
- Damiani, E.; Di Vimercati, S.D.C.; Foresti, S.; Samarati, P.; Viviani, M. Measuring inference exposure in outsourced encrypted databases. In Quality of Protection; Springer: Berlin, Germany, 2006; pp. 185–195. [Google Scholar]
- Boldyreva, A.; Chenette, N.; Lee, Y.; O’neill, A. Order-preserving symmetric encryption. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Cologne, Germany, 26–30 April 2009; Springer: Berlin, Germany, 2009; pp. 224–241. [Google Scholar]
- Ciriani, V.; Di Vimercati, S.D.C.; Foresti, S.; Jajodia, S.; Paraboschi, S.; Samarati, P. Fragmentation and encryption to enforce privacy in data storage. In Proceedings of the European sYmposium on Research in Computer Security, Dresden, Germany, 24–26 September 2007; Springer: Berlin, Germany, 2007; pp. 171–186. [Google Scholar]
- Di Vimercati, S.D.C.; Foresti, S.; Jajodia, S.; Paraboschi, S.; Samarati, P. Encryption policies for regulating access to outsourced data. ACM Trans. Database Syst. (TODS) 2010, 35, 12. [Google Scholar] [CrossRef]
- Di Vimercati, S.D.C.; Erbacher, R.F.; Foresti, S.; Jajodia, S.; Livraga, G.; Samarati, P. Encryption and fragmentation for data confidentiality in the cloud. In Foundations of Security Analysis and Design VII; Springer: Berlin, Germany, 2014; pp. 212–243. [Google Scholar]
- Di Vimercati, S.D.C.; Foresti, S.; Samarati, P. Selective and fine-grained access to data in the cloud. In Secure Cloud Computing; Springer: Berlin, Germany, 2014; pp. 123–148. [Google Scholar]
- Di Vimercati, S.D.C.; Foresti, S.; Livraga, G.; Samarati, P. Selective and private access to outsourced data centers. In Handbook on Data Centers; Springer: Berlin, Germany, 2015; pp. 997–1027. [Google Scholar]
- Di Vimercati, S.D.C.; Foresti, S.; Livraga, G.; Samarati, P. Practical techniques building on encryption for protecting and managing data in the cloud. In The New Codebreakers; Springer: Berlin, Germany, 2016; pp. 205–239. [Google Scholar]
- Di Vimercati, S.D.C.; Foresti, S.; Livraga, G.; Paraboschi, S.; Samarati, P. Confidentiality Protection in Large Databases. In A Comprehensive Guide through the Italian Database Research Over the Last 25 Years; Springer: Berlin, Germany, 2018; pp. 457–472. [Google Scholar]
- Xiong, L.; Goryczka, S.; Sunderam, V. Adaptive, secure, and scalable distributed data outsourcing: A vision paper. In Proceedings of the 2011 Workshop on Dynamic Distributed Data-Intensive Applications, Programming Abstractions, and Systems, San Jose, CA, USA, 8 June 2011; ACM: New York, NY, USA, 2011; pp. 1–6. [Google Scholar]
- Biskup, J.; Preuß, M.; Wiese, L. On the inference-proofness of database fragmentation satisfying confidentiality constraints. In Proceedings of the International Conference on Information Security, Xi’an, China, 26–29 October 2011; Springer: Berlin, Germany, 2011; pp. 246–261. [Google Scholar]
- Ganapathy, V.; Thomas, D.; Feder, T.; Garcia-Molina, H.; Motwani, R. Distributing data for secure database services. In Proceedings of the 4th International Workshop on Privacy and Anonymity in the Information Society, Uppsala, Sweden, 21–24 March 2011; ACM: New York, NY, USA, 2011; p. 8. [Google Scholar]
- Bkakria, A.; Cuppens, F.; Cuppens-Boulahia, N.; Fernandez, J.M.; Gross-Amblard, D. Preserving Multi-relational Outsourced Databases Confidentiality using Fragmentation and Encryption. JoWUA 2013, 4, 39–62. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Diaz, C.; Seys, S.; Claessens, J.; Preneel, B. Towards measuring anonymity. In Proceedings of the International Workshop on Privacy Enhancing Technologies, San Francisco, CA, USA, 14–15 April 2002; Springer: Berlin, Germany, 2002; pp. 54–68. [Google Scholar]
- Serjantov, A.; Danezis, G. Towards an information theoretic metric for anonymity. In Proceedings of the International Workshop on Privacy Enhancing Technologies, San Francisco, CA, USA, 14–15 April 2002; Springer: Berlin, Germany, 2002; pp. 41–53. [Google Scholar]
- Aggarwal, G.; Bawa, M.; Ganesan, P.; Garcia-Molina, H.; Kenthapadi, K.; Motwani, R.; Srivastava, U.; Thomas, D.; Xu, Y. Two can keep a secret: A distributed architecture for secure database services. In Proceedings of the Second Biennial Conference on Innovative Data Systems Research (CIDR 2005), Asilomar, CA, USA, 4–7 January 2005. [Google Scholar]
- Ciriani, V.; De Capitani di Vimercati, S.; Foresti, S.; Livraga, G.; Samarati, P. An OBDD approach to enforce confidentiality and visibility constraints in data publishing. J. Comput. Secur. 2012, 20, 463–508. [Google Scholar] [CrossRef]
- Deming, S.N. Multiple-criteria optimization. J. Chromatogr. A 1991, 550, 15–25. [Google Scholar] [CrossRef]
- Peng, C.G.; Ding, H.F.; Zhu, Y.J.; Tian, Y.L. Information entropy models and privacy metrics methods for privacy protection. J. Softw. 2016, 27, 1891–1903. [Google Scholar]
- Cattell, R. Scalable SQL and NoSQL data stores. ACM Sigmod Rec. 2011, 39, 12–27. [Google Scholar] [CrossRef]
- Okman, L.; Gal-Oz, N.; Gonen, Y.; Gudes, E.; Abramov, J. Security issues in nosql databases. In Proceedings of the 2011 IEEE 10th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Changsha, China, 16–18 November 2011; pp. 541–547. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| SSN | Name | DoB | Zip Code | Disease | Physician |
|---|---|---|---|---|---|
| 123-56-1234 | Alice | 08/03 | 98112 | Flu | M.White |
| 234-56-7890 | Bob | 10/07 | 94778 | Asthma | D.Warren |
| 345-67-8901 | David | 02/12 | 94139 | Gastritis | M.White |
| 456-78-9012 | Jery | 08/03 | 94139 | Flu | K.Jsery |
| 567-89-0123 | Semy | 03/04 | 94141 | Angina | D.Warren |
| 678-90-1234 | Fred | 12/01 | 94142 | Diabetes | M.Kity |
| Dataset | Number of Samples | Dimensions |
|---|---|---|
| Adult | 32,561 | 14 |
| Attributes | Entropy | Attributes | Entropy |
|---|---|---|---|
| 3 | 14.1583 | 1, 4, 6, 13 | 12.2393 |
| 1, 2, 4, 7 | 12.1658 | 1, 4, 7, 8 | 12.6782 |
| 1, 2, 4, 13 | 12.2012 | 1, 4, 7, 13 | 13.2738 |
| 1, 2, 5, 7 | 12.1658 | 1, 4, 8, 13 | 12.5190 |
| 1, 2, 5, 13 | 12.2012 | 1, 5, 6, 7 | 12.3872 |
| 1, 2, 7, 13 | 12.4623 | 1, 5, 6, 13 | 12.2393 |
| 1, 4, 6, 7 | 12.3872 | 1, 5, 7, 8 | 12.6782 |
| 1, 5, 7, 13 | 13.2738 | 1, 5, 8, 13 | 12.5190 |
| 1, 6, 7, 13 | 12.6807 | 1, 7, 8, 13 | 12.9189 |
| 1, 7, 9, 13 | 12.2523 | 1, 7, 10, 13 | 12.2812 |
| 1, 7, 11,13 | 12.0908 | 1, 7, 13, 14 | 12.1851 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, T.; Mei, S.; Wang, Z.; Ren, J. A Novel Vertical Fragmentation Method for Privacy Protection Based on Entropy Minimization in a Relational Database. Symmetry 2018, 10, 637. https://doi.org/10.3390/sym10110637
Hong T, Mei S, Wang Z, Ren J. A Novel Vertical Fragmentation Method for Privacy Protection Based on Entropy Minimization in a Relational Database. Symmetry. 2018; 10(11):637. https://doi.org/10.3390/sym10110637
Chicago/Turabian StyleHong, Tie, SongZhu Mei, ZhiYing Wang, and JiangChun Ren. 2018. "A Novel Vertical Fragmentation Method for Privacy Protection Based on Entropy Minimization in a Relational Database" Symmetry 10, no. 11: 637. https://doi.org/10.3390/sym10110637
APA StyleHong, T., Mei, S., Wang, Z., & Ren, J. (2018). A Novel Vertical Fragmentation Method for Privacy Protection Based on Entropy Minimization in a Relational Database. Symmetry, 10(11), 637. https://doi.org/10.3390/sym10110637