1. Introduction
Decision-making is an inevitable aspect of human life which involves uncertainty and vagueness. The process of selecting a suitable object for the task brings cognitive thought processes into the picture, which is dynamic and competing in nature [
1]. DMs often face difficulties in expressing their opinions in a sensible manner and to alleviate the issue to a certain extent; they adopt linguistic preference information [
2]. Previous studies on linguistic decision process [
2,
3,
4] have claimed that (a) linguistic preferences are simple and straightforward information which can be directly obtained from the DM, (b) also, these linguistic preferences mitigate the cost of inaccuracies to some extent. Motivated by these claims; scholars presented different decision-making framework under the linguistic context, of which, some are reviewed here. Zadeh [
5] framed the genesis of a linguistic variable and applied the same for approximate reasoning. Later, Herrera et al. [
2] fabricated the initial idea of the linguistic decision process and proposed a sequential decision framework in a linguistic environment. Following this, Herrera et al. [
3,
6] presented the consensus model for group decision-making under the linguistic context. Inspired by the power of linguistic theory, Xu [
7] extended the geometric mean and ordered weighted geometric aggregation operator for a linguistic domain. Further, He et al. [
8] put forward a new entropy measure for linguistic-based group decision-making.
Though linguistic decision-making is an attractive concept, DMs still face difficulties in rationally rating the objects. The main reason for this difficulty is the cognitive behavior of the human mind, which encourages pair-wise comparative analysis rather than a standalone rating [
9]. Motivated by the power of pair-wise comparison and linguistic term set (LTS), Herrera et al. [
10,
11] proposed the linguistic preference relation (LPR) concept for group decision-making and investigated some choice functions for the same. Following this, Xu [
12] put forward some deviation measures for decision-making process under LPR context. Recently, Molinera et al. [
13] developed new fuzzy ontologies for linguistic preference information and applied the same for decision-making. Wang and Xu [
14] put forward an interactive algorithm for filling the missing LPR values using consistency measures and repaired the consistency of the same using the repairing mechanism.
Inspired by the power of linguistic information and its substantial use in decision-making, Rodriguez [
15] proposed the hesitant fuzzy linguistic term set (HFLTS) which is an extension to LTS under hesitant fuzzy environment [
16]. The HFLTS allowed DMs to give different choices of preference for the same instance, which managed uncertainty to some extent. Motivated by the power of HFLTS, Zhu and Xu [
17] put forward the hesitant fuzzy linguistic preference relation (HFLPR), which is an extension to preference relation under HFLTS context. They also investigated some consistency measures for the same. Following this, Wang and Xu [
18] presented the concept of extended hesitant fuzzy preference relation and studied some consistency measures for the same. Wu [
19] presented a consensus model based on possibility distribution for HFLPR and validated the applicability of same for decision-making process. Recently, Song and Hu [
20] proposed a decision framework for handling incomplete HFLPR and applied the same for real-time group decision-making problem. Tuysuz and Simsek [
21] extended the popular AHP method under HFLTS context and applied the same for assessing the performance of cargo factory.
Though the HFLPR is able to manage DMs’ hesitation in preference information, the occurring probability (distribution assessment) of each linguistic term in the decision-making process is neglected. In many practical applications, all linguistic choices by the DM do not bear the same importance and hence, ignoring the occurring probability of each linguistic term is unreasonable and illogical. To circumvent this challenge, Zhang et al. [
22] introduced the concept of linguistic distribution assessment (LDA) and associated symbolic proportion for each linguistic term. Later, Pang et al. [
23] generalized the idea of LDA by allowing partial ignorance (
) in preference elicitation and termed it as probabilistic linguistic term set (PLTS) which is an extension to HFLTS with probability concept. Recently, Zhang et al. [
24] put forward the concept of incomplete LDA which is similar to PLTS and used in for decision-making. Inspired by the superiority of PLTS in associating occurring probability to each linguistic term; Bai et al. [
25] presented a new comparison method use area concept for PLTS. Later, Liao et al. [
26] extended the programming model to PLTS for multi-attribute decision-making (MADM). Liu and Teng [
27] extended the Muirhead mean aggregation operator to PLTS for group decision-making. Zhang et al. [
28,
29] put forward the probabilistic linguistic preference relation (PLPR) concept which is an extension to preference relation under PLTS context and some additive consistency and consensus reaching measures were also investigated. Recently, Xie et al. [
30] proposed probabilistic uncertain preference relation and applied the same for virtual reality application. Recently, attracted by the power of PLPR, Wu and Liao [
31] proposed gain-lost dominance score method under PLTS for consensus reaching. Xie et al. [
32] extended AHP (analytic hierarchy process) method and applied the same for assessing the performance of a new area. Since the concept of PLPR just began, we gained motivation to throw some light towards this concept and set our research focus in this direction.
Based on the review conducted above, some genuine challenges/lacunas are identified which are presented in a nutshell below:
- (1)
Investigation of decision process using the preference relation proves to be effective than investigation using attribute driven methods [
28]. The reason for this is evident from the ease of pair-wise comparison mechanism, which allows DMs to produce sensible preference information about each object with respect to a specific criterion. Also, the process of pair-wise comparison closely resembles with the practical decision process. Thus, motivated by the power of pair-wise comparison, we set our proposal in this context.
- (2)
Since PLPR is a recent research topic, the challenge of automatic filling of missing values under PLPR context needs to be addressed. DMs often get confused between objects (alternatives) due to external pressure and lack of sufficient knowledge. This forces DMs to be ignorant and hesitant towards a certain pair of objects which eventually leads to missing values in the preference relation(s).
- (3)
Checking and repairing the consistency of PLPRs in an automated fashion by using a systematic procedure is also an interesting challenge to be addressed. The consistency of preference relation is substantial aspect for rational and reasonable decision-making. Due to various external pressures, DMs often face difficulty in providing a consistent preference relation for evaluation and manual repairing of the preference relation is an ordeal and unreasonable. Though, Xie et al. [
32] presented a method for consistency check and repair, they are complex and computationally intensive as they involve logarithmic function and iterative calculation of Eigen vectors.
- (4)
Furthermore, extension of ranking methods under PLPR context is also an attractive challenge to be addressed for sensible prioritization of objects. DMs prefer systematic scientific procedure for selection of objects rather than random guess. Though, Xie et al. [
32] extended AHP method, they converted the PLTS information into single value by using possibility degree measure which causes potential loss of information leading to unreasonable prioritization of objects.
Motivated by these challenges and with the view of alleviating these challenges, in this paper, we propose a new scientific decision framework, which consists of two phases viz., (1)
missing value entry phase and (2)
ranking phase. Xu [
33] clearly pointed out that, (i) DMs are often unwilling to reconstruct the evaluation matrix and (ii) also the chance for the manually reconstructed matrix to be consistent is very less. Thus, motivated by these claims,
- (1)
In the first phase of the proposal, a new automated procedure for filling the missing values is presented.
- (2)
Following this, a new systematic procedure is proposed for checking the consistency of PLPRs and inconsistent PLPRs are repaired automatically in an iterative manner. Unlike method discussed in [
32], the proposed procedure uses simple and straightforward operational law(s) of PLEs.
- (3)
Further, in the second phase of the proposal, a new extension to AHP method under PLPR context is presented for suitable selection of the object from the set of objects. Unlike method [
32], the proposed extension for AHP retains the PLTS information throughout the formulation and mitigates information loss which allows reasonable prioritization of objects.
- (4)
Finally, the practicality, strength, and weakness of the proposal are realized by using green supplier selection problem.
The rest of the paper is constructed as
Section 2 for preliminaries,
Section 3 for calculation of missing values and ranking of objects.
Section 4 presents a numerical example for demonstrating the practical use of the framework.
Section 5 presents the comparative study and
Section 6 gives the concluding remarks and future works.
3. Proposed Decision Framework under Probabilistic Linguistic Preference Relation (PLPR) Context
3.1. Proposed Architecture of PLPR Based Decision Framework
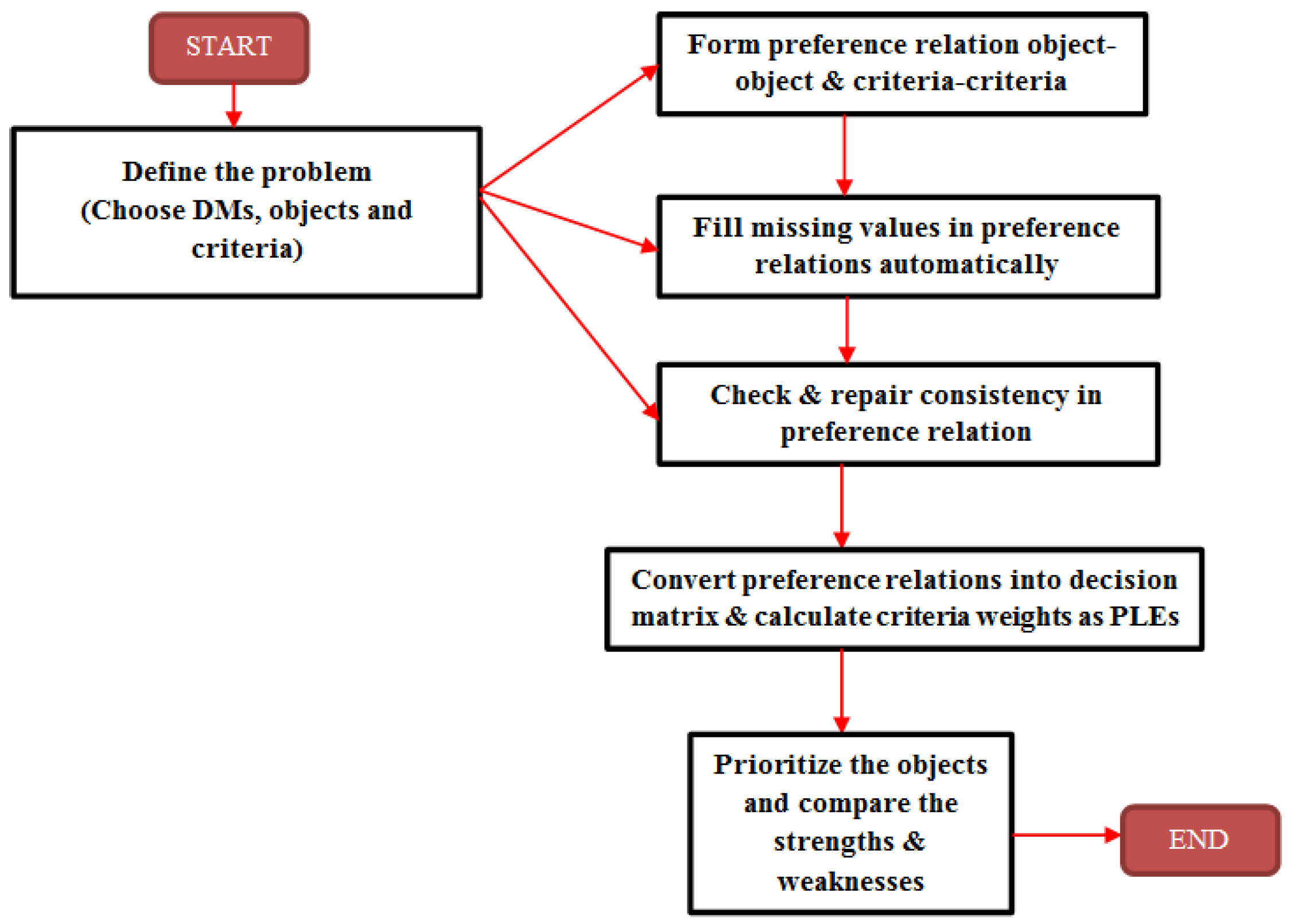
The architecture of the proposed scientific decision framework is presented in
Figure 1 which is simple and straightforward to understand.
3.2. Proposed Automatic Procedure for Filling Missing Values and Consistency Check and Repair for PLPRs
In this section, the procedure for finding the missing values of a PLPR is presented. Generally, DMs find pairwise comparison as an easier option for rating alternatives [
28]. DMs rate the alternatives upon each criterion and sometimes they are unwilling or confused between alternatives’ performance over a specific criterion and this forces them to ignore such rating. As a result, the decision matrix is now incomplete and further processing becomes difficult. To circumvent this issue, an automated procedure is proposed which automatically fits a value to the missing information. Zhang et al. [
33] claimed that “(a) manual entry of missing values by some random information is unreasonable and causes potential loss of information and (b) returning of decision matrix to the DM for re-entry is also unreasonable and computationally ineffective”. Motivated by such claims, in this paper, an automated procedure is presented under PLTS context for filling missing values.
The procedure for automated filling of missing value is given below:
Step 1: Consider a PLPR
which has PLEs. Identify the instance which is missing. If
, then the missing instance can be automatically estimated (follow steps below), else follow Equation (4).
where
is the subscript of the linguistic term,
is the associated occurring probability of the linguistic term and
is the order of the matrix.
Step 2: When , apply Equation (5) to automatically estimate the missing values.
and
where
is an operator given in Definition 4.
Note 2: The result from Equation (5) is also a PLE and the values that go out of bounds when operator is applied are transformed using Remark 2.
Step 3: Check the consistency of the matrix
by using Equations (6) and (7).
where
and
can be calculated by using Equation (7).
where
is an operator given in Definition 4.
Here linguistic terms are added as per Definition 4 and transformation procedure is applied to those terms that exceed the limits. However, the corresponding probability terms are calculated by using weighted geometry method to avoid unreasonable probability values. The personal opinion on each alternative is given by the DM with .
Step 4: Calculate the distance between
and
by using Equation (8) to determine the consistency index (
).
where
is the cardinality of the LTS,
is the subscript of the PLTS and
is the corresponding probability of the term set.
Note 3: The distance formula described in Equation (8) obeys the desirable distance properties viz., non-negative, non-degenerate, symmetric and transitive.
Step 5: The consistency values obtained from step 4 are compared with the standard consistency value (suggested as 0.05 by DMs). If then, is acceptable; else is unacceptable and automatic repairing must be done by following the steps below.
Step 6: Repair the inconsistent PLPR automatically by using Equation (9).
where
,
,
and
are parameters in the range [0,1].
Note that this repairing is an iterative process and until consistent matrix is obtained, we apply the procedure.
Step 7: Repeat the steps 5 and 6 iteratively till a PLPR of acceptable consistency is obtained.
3.3. Proposed Analytic Hierarchy Process (AHP) Method under PLPR Context
Analytic hierarchy process (AHP) is a classical ranking method that is based on the pairwise comparison concept [
34]. This ranking method works with preference relations and weight of each alternative is determined. Based on the weight values, alternative are ranked and the suitable object is selected for the process. Recently, Emrouznejad and Marra [
35] conducted a comprehensive review on AHP method and identified its diverse applicability in MCDM and the interesting variants of AHP. Clearly from the review, extension of AHP to PLTS context is a new idea for exploration and the work of Xie et al. [
32] framed the genesis for the same. Some lacunas are discussed in
Section 1 which motivates the proposed extension of AHP under PLPR context.
Now, we present the procedure for ranking objects using the proposed extension to AHP under PLPR context.
Step 1: Define the problem under multi-attributes decision-making context and determine the number of objects, attributes and DMs. Use PLEs as preference information.
Step 2: Suppose, m objects and n attributes are considered, n PLPRs of order is formed. Following this, a PLPR of order is formed for the attributes.
Step 3: Check the consistency of all PLPRs using the procedure presented in
Section 3.2 and repair the inconsistent PLPR. Apply Equation (2) to the PLPR of order
. This forms a weight vector for the attributes which is probabilistic linguistic in nature.
Step 4: Following step 3, we aggregate the PLEs from matrices using Equation (2) to form a decision matrix with PLTS information of order where m is the number of alternatives and n is the number of attributes.
Step 5: The attribute weights and decision matrix are taken from steps 3 and 4 respectively and Equation (2) is applied to obtain a vector of order for each of the alternatives.
Step 6: The vector obtained from step 6 contains PLTS information which is used for the final ranking by applying Equation (10).
where
is the subscript of the
ith object and
is the probability of the corresponding
ith object.
Thus, the object which has large value is ranked first and so on.




{kind=link}