Deep Temporal–Spatial Aggregation for Video-Based Facial Expression Recognition


Abstract
:1. Introduction
2. Related Work
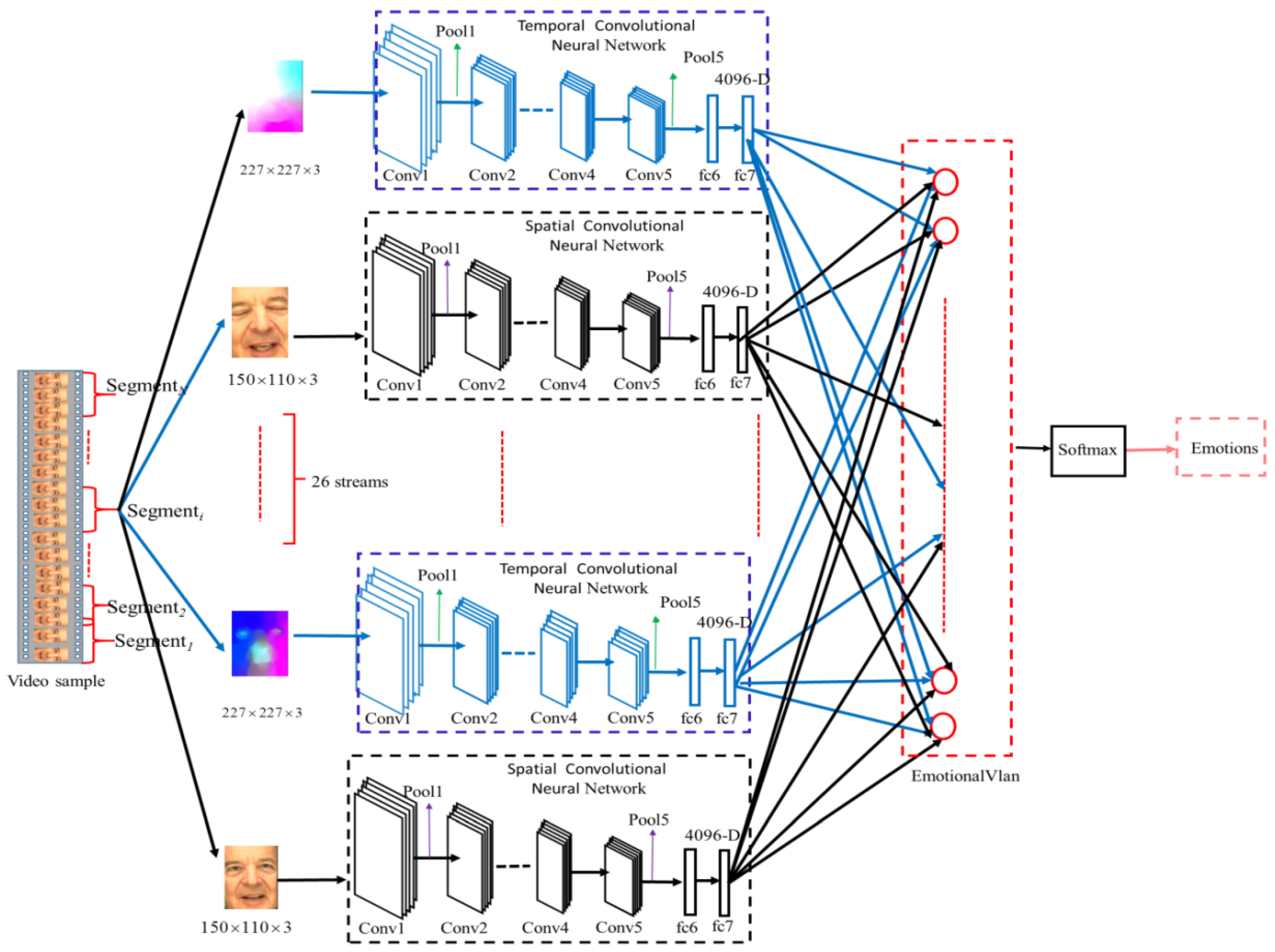
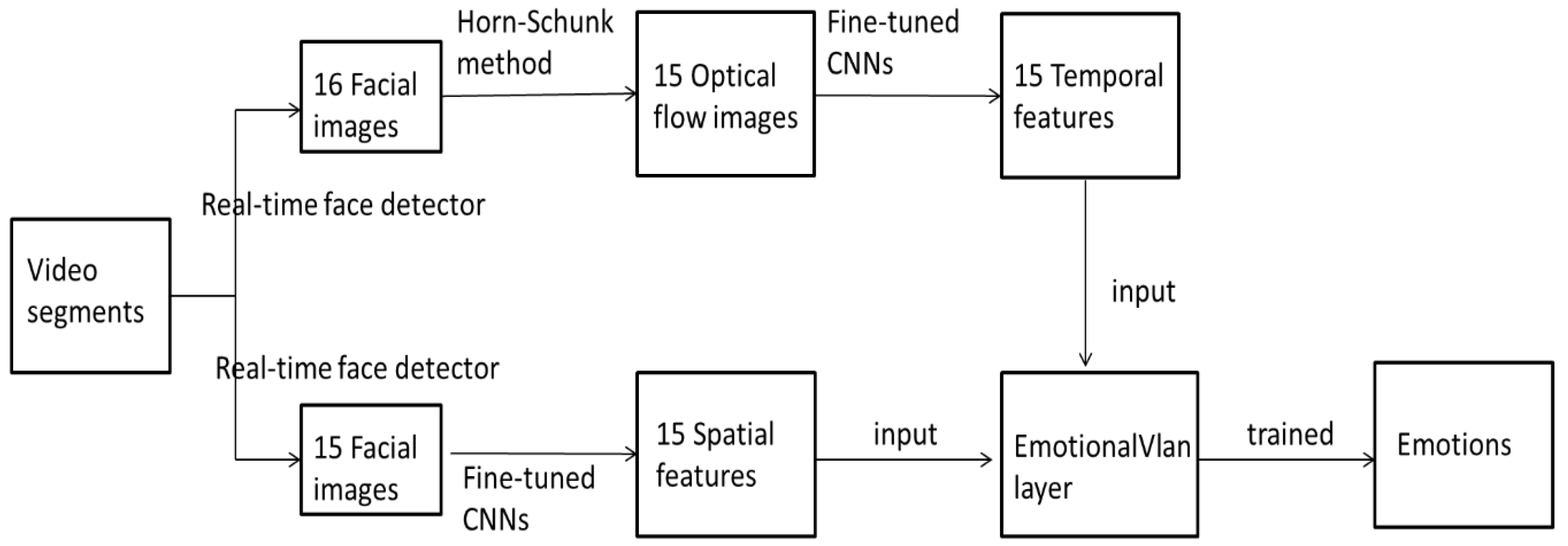
3. The Proposed Method
- Step 1:
- There are 16 facial images cropped from every video segment.
- Step 2:
- There are 15 optical flow images generated from 16 facial images.
- Step 3:
- 15 static facial images before and 15 optical flow images are fed into the 15 spatial CNNs and 15 temporal CNNs for fine-tuning, respectively.
- Step 4:
- 15 spatial features are extracted by 15 fine-tuned spatial CNNs, and 15 temporal features are extracted by 15 fine-tuned temporal CNNs.
- Step 5:
- The 15 spatial features and 15 temporal features are fed into EmotionalVlan layer for training and recognition of facial expressions.
| Algorithm 1. The algorithm of this work |
| Input: 15 static video-frames and 15 optical flow images Output: facial expressions 1. Copy AlexNet parameters to initialize our framework parameters: mini-batch is 40, and learning rate is 0.001 2. While epoch number<=5000{ //the forward propagation For each neuron k in the hidden layer, that is, before the EmotionalVlan layer{ F(k) = max(0,x) //the output of neuron k, x represents the input of neuron k, } For each neuron k in EmotionalVlan{ //the output of neuron k, and represents the output of fc7 layer in spatial streams and temporal streams separately. } // back propagation error For each neuron k in the output layer{ // compute error, represents the true emotional label, represents the prediction emotional label } For every hidden neuron { Update the weight } } |
3.1. Temporal–Spatial Aggregation Layer
3.2. Video Preprocessing
3.3. Network Training
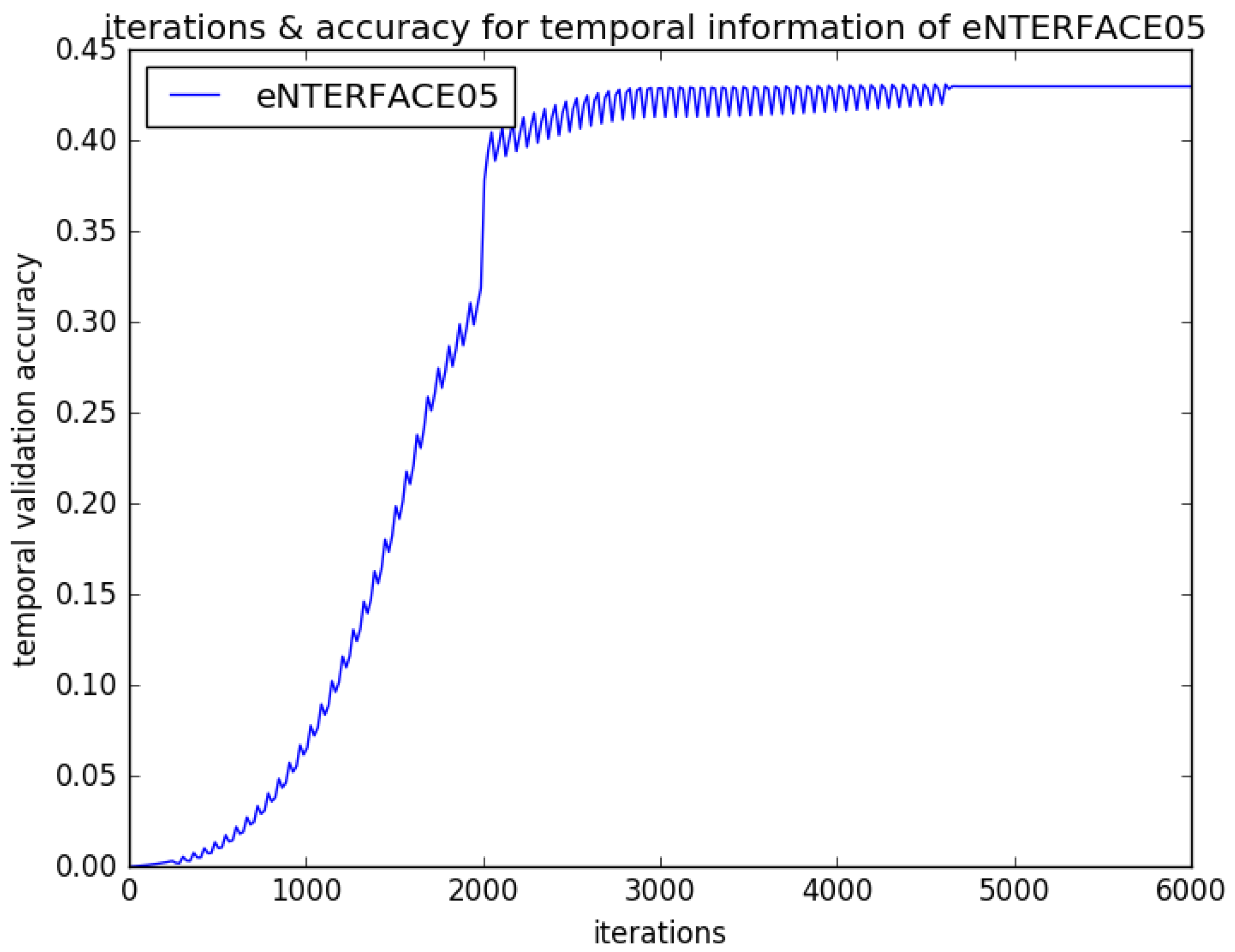
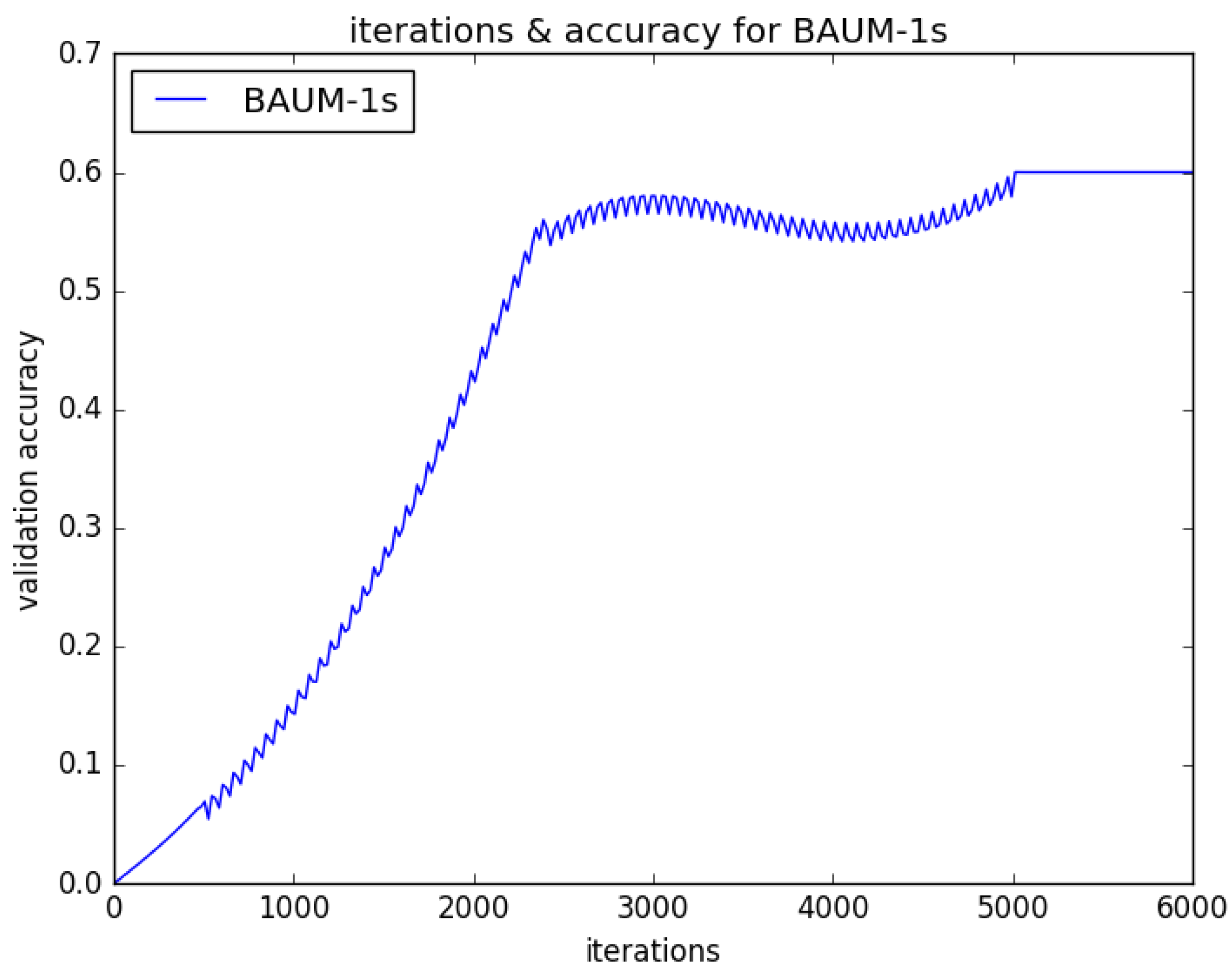
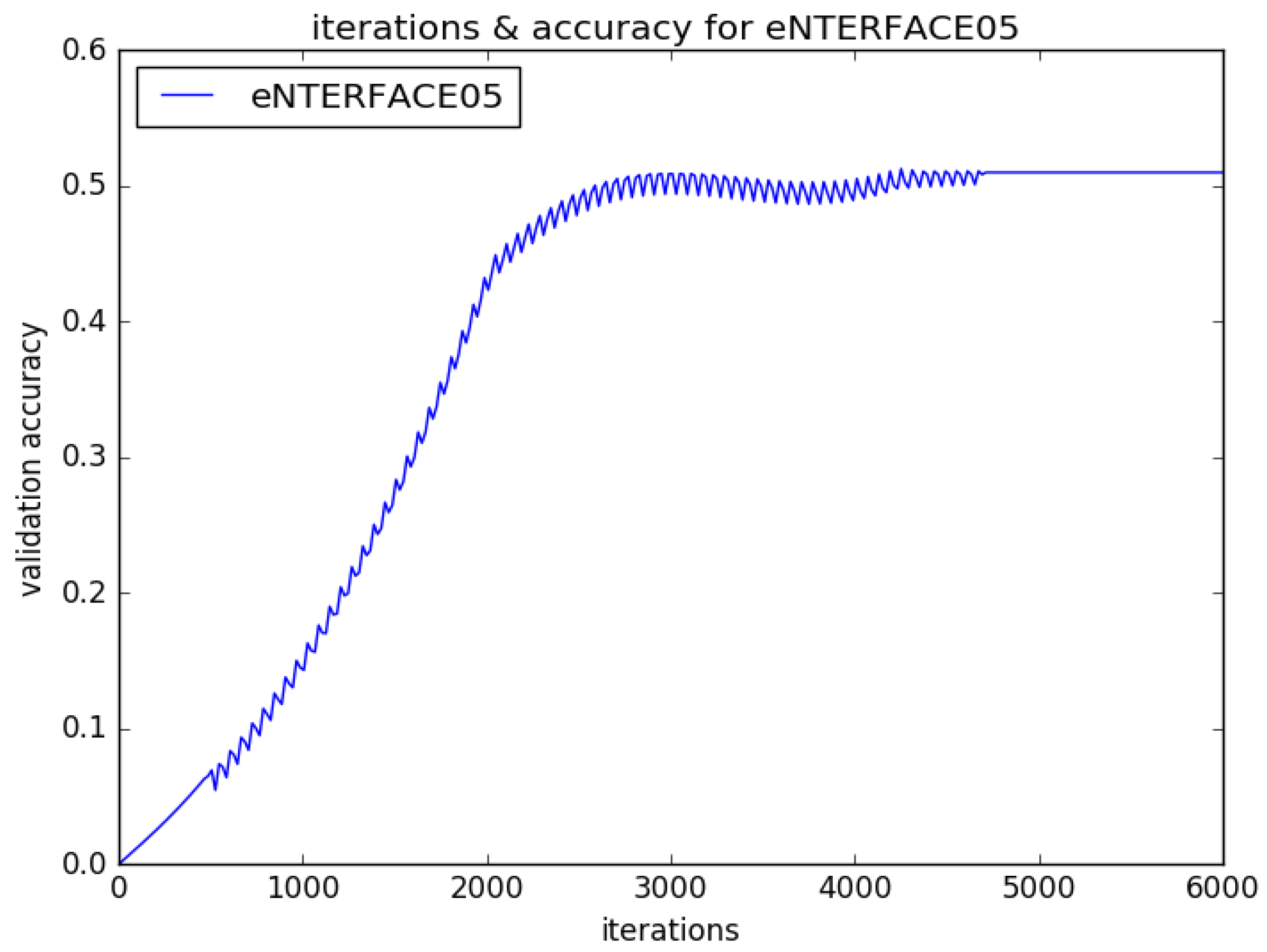
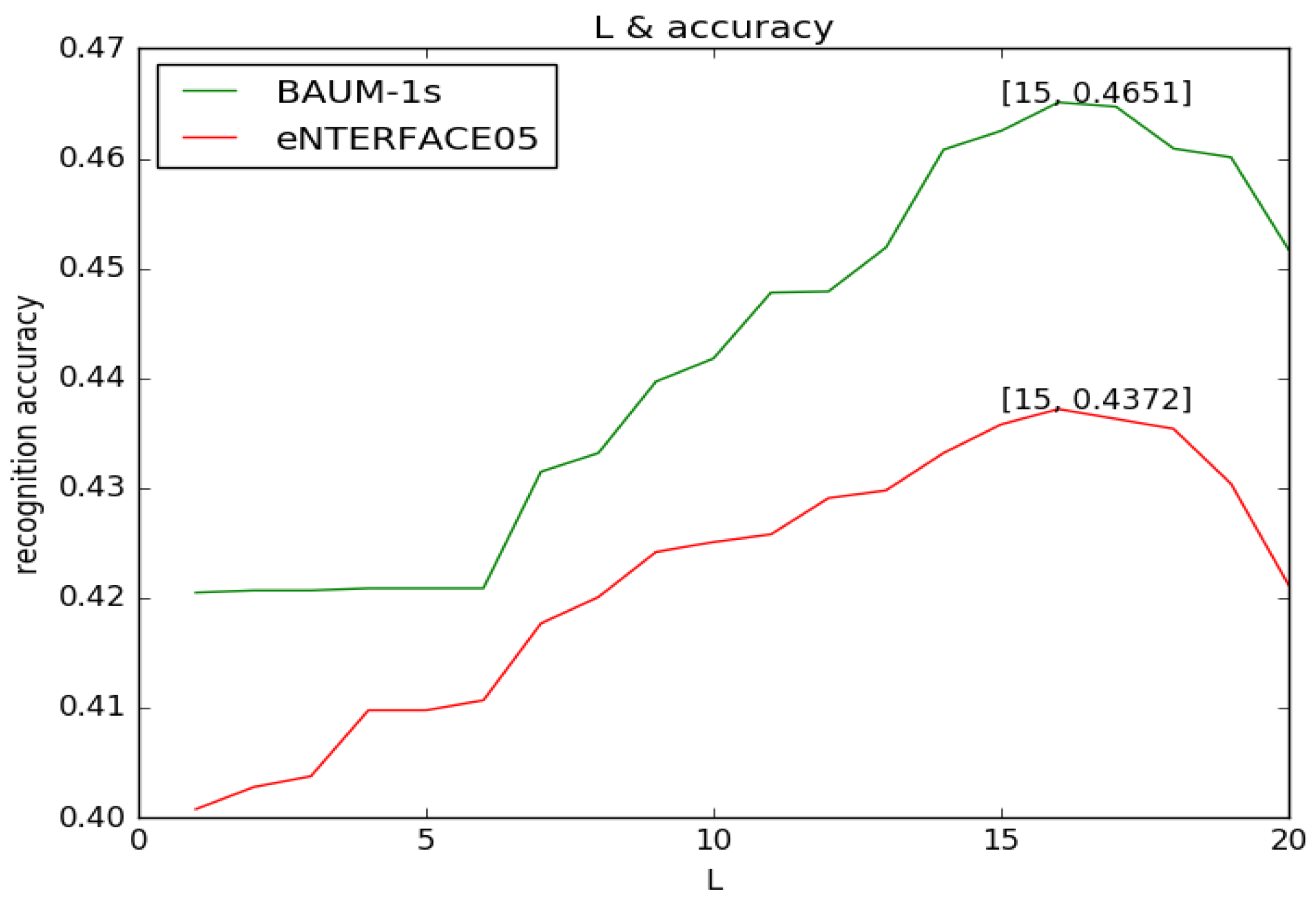
4. Experiment Studies and Result Analysis
4.1. Datasets
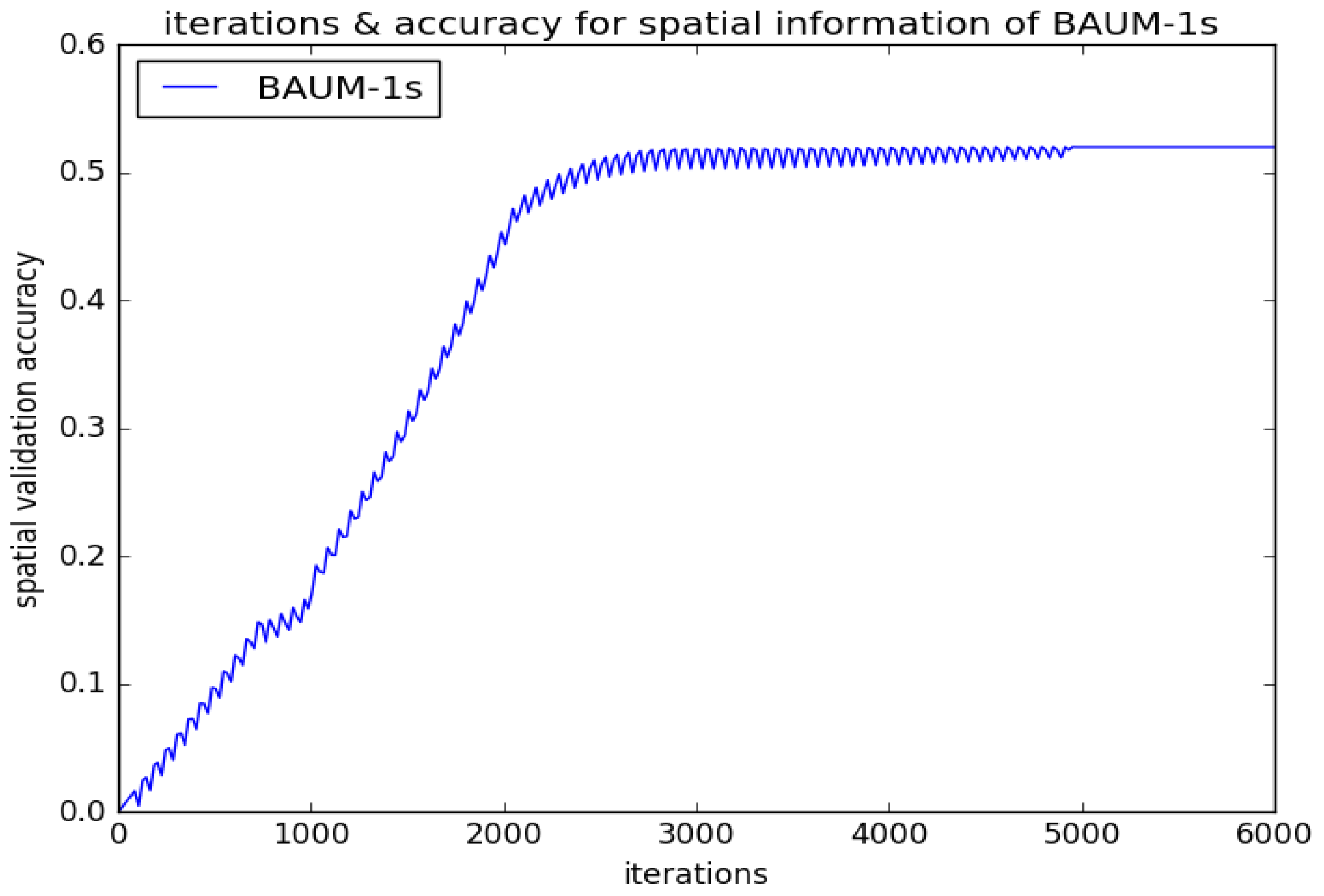
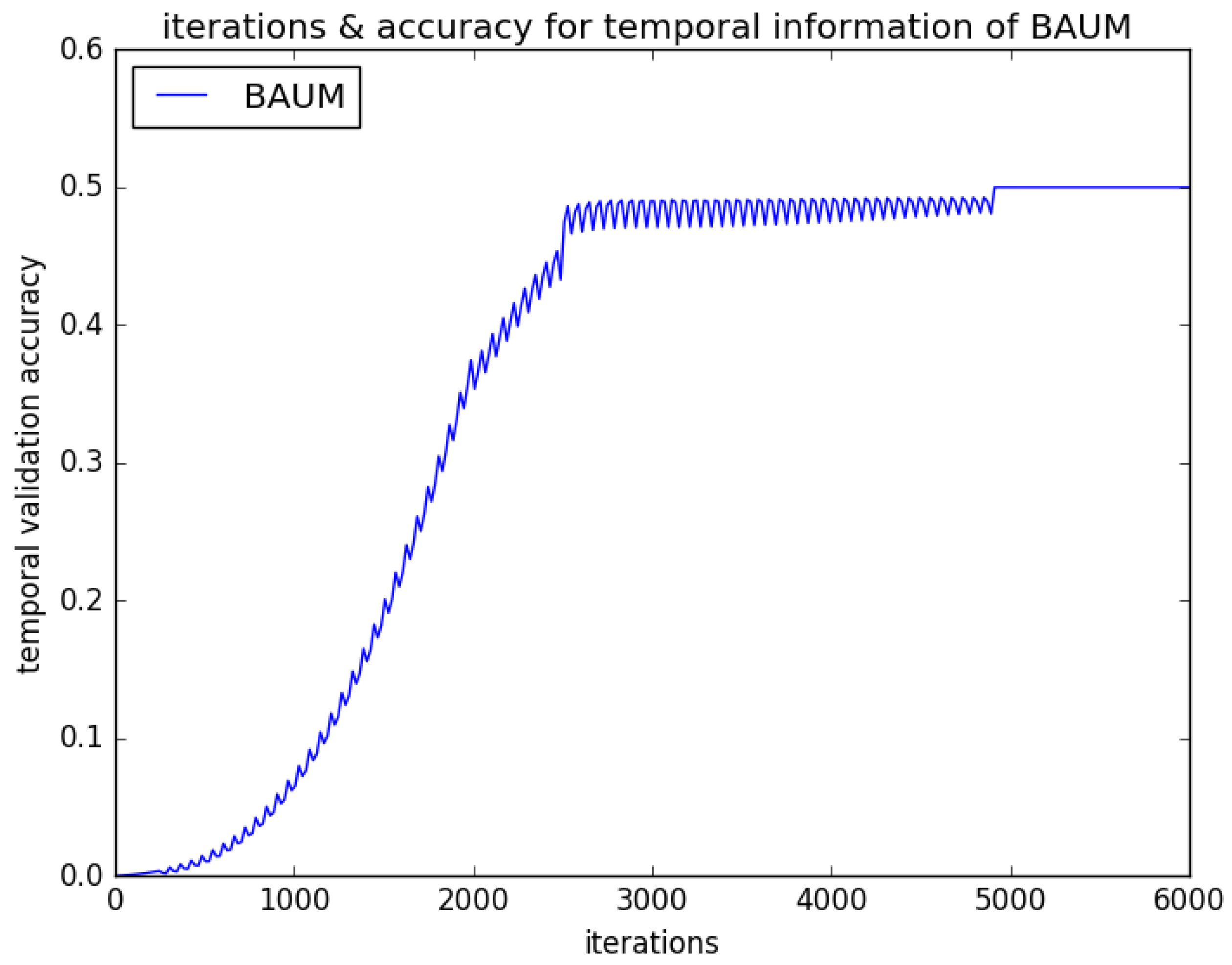
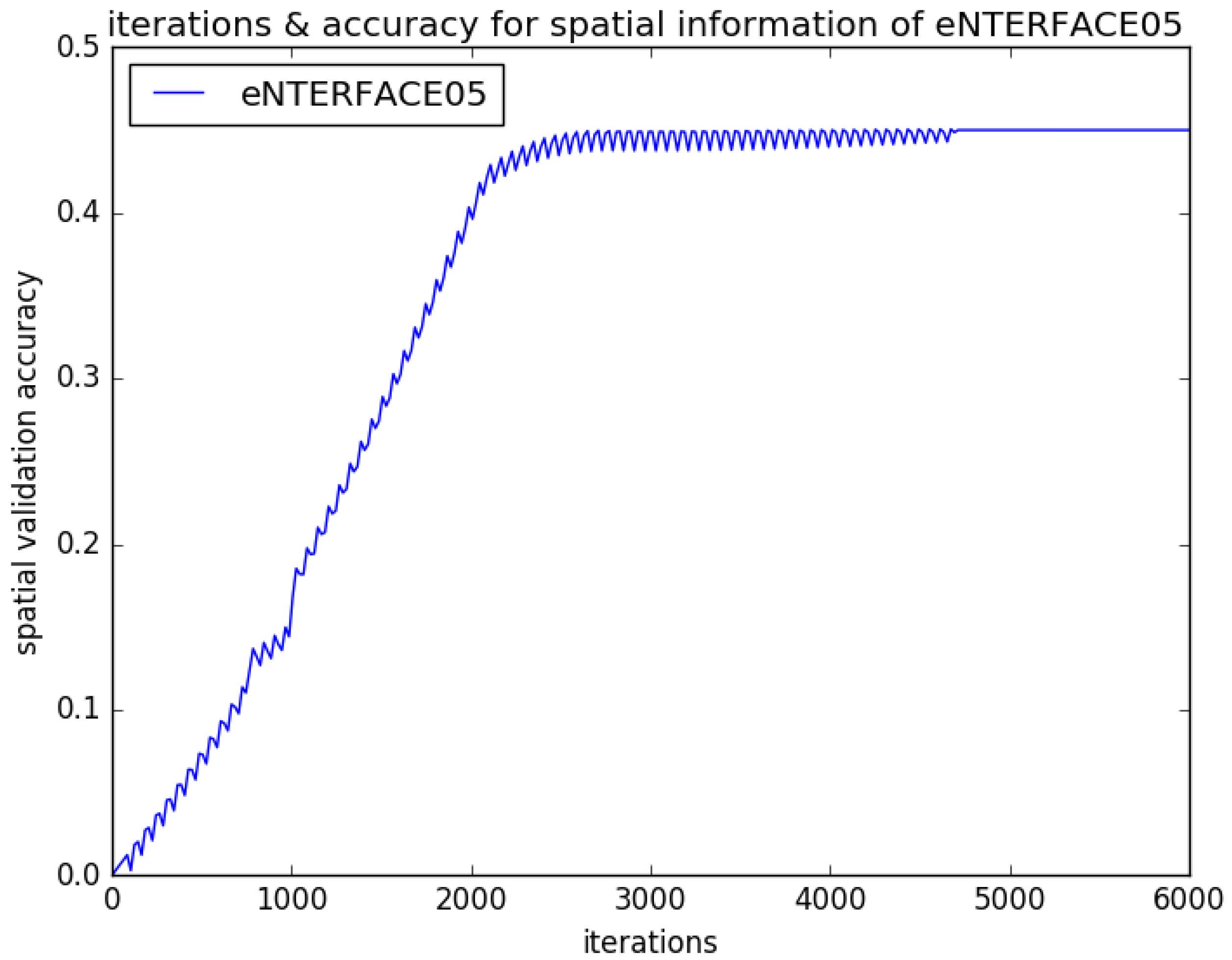
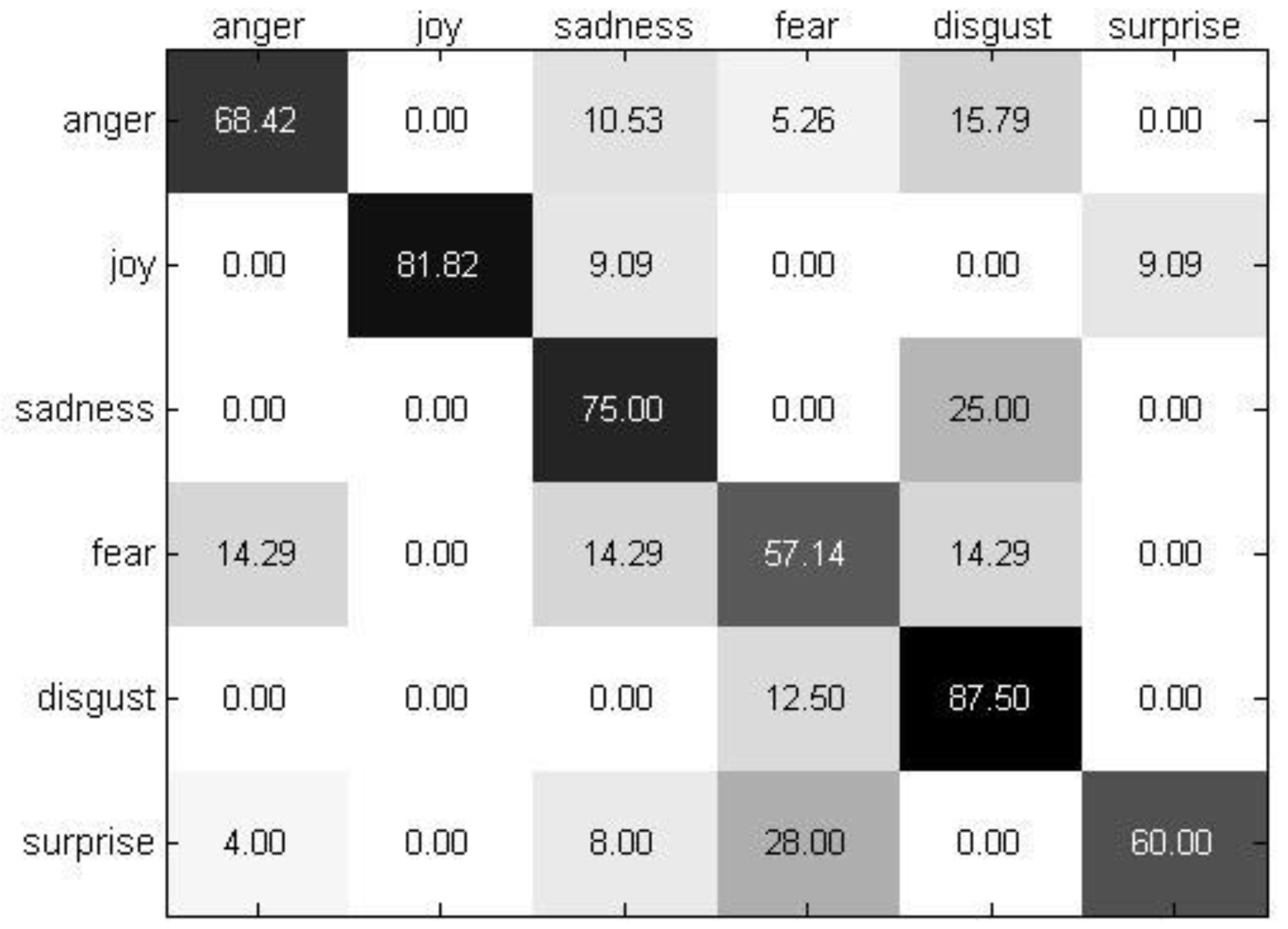
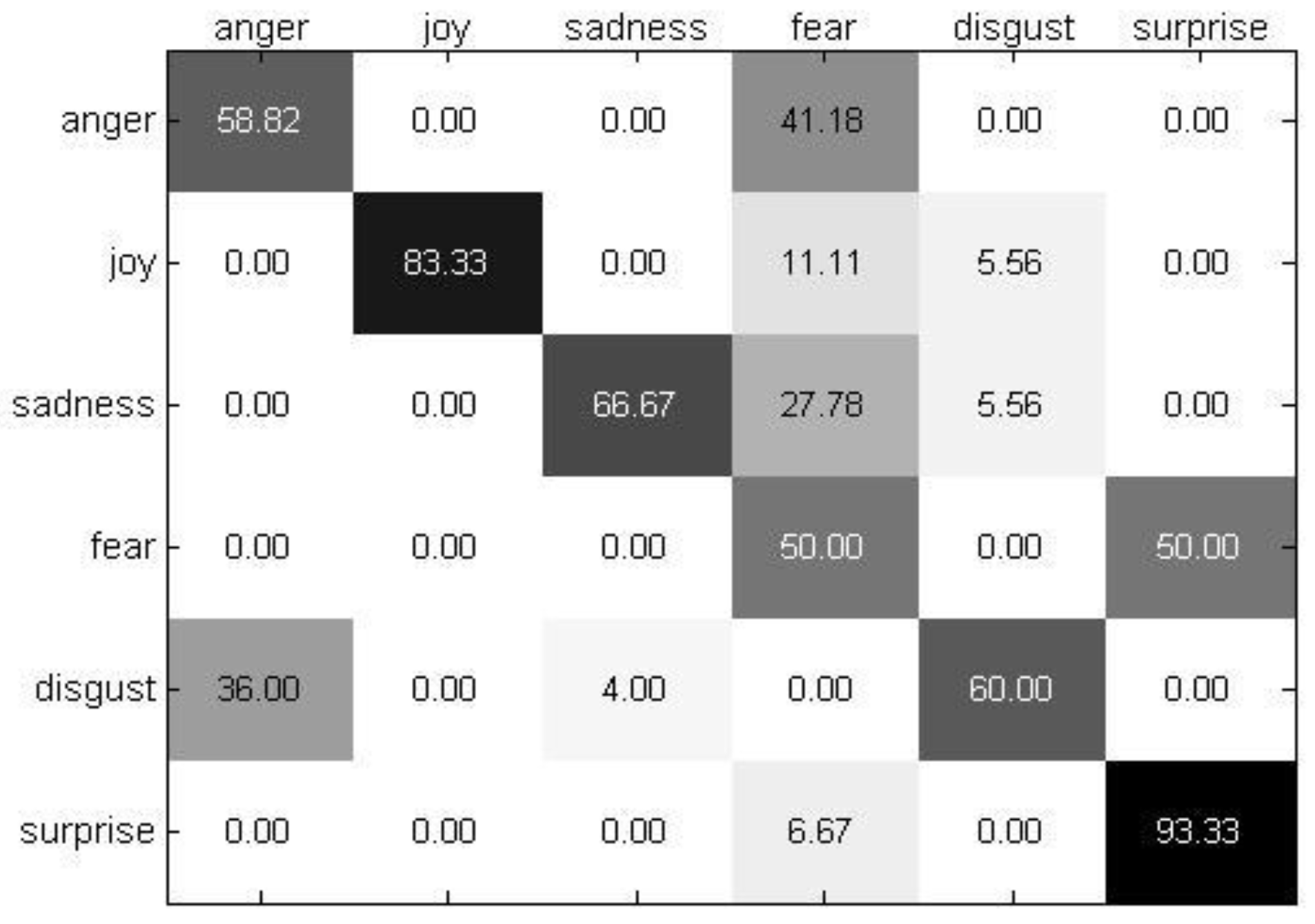
4.2. Experimental Results and Analysis
4.3. Comparisons with State-Of-The-Art Methods
5. Comparison and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, S.; Zhang, S.; Huang, T.; Gao, W.; Tian, Q. Learning Affective Features with a Hybrid Deep Model for Audio-Visual Emotion Recognition. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 3030–3043. [Google Scholar] [CrossRef]
- Williams, A.C. Facial expression of pain: An evolutionary account. Behav. Brain Sci. 2002, 25, 455–488. [Google Scholar] [CrossRef]
- Zhao, H.; Sun, M.; Deng, W.; Yang, X. A New Feature Extraction Method Based on EEMD and Multi-Scale Fuzzy Entropy for Motor Bearing. Entropy 2017, 19, 14. [Google Scholar] [CrossRef]
- Jabon, M.; Bailenson, J.; Pontikakis, E.; Takayama, L.; Nass, C. Facial expression analysis for predicting unsafe driving behavior. IEEE Pervasive Comput. 2011, 10, 84–95. [Google Scholar] [CrossRef]
- Deng, W.; Zhang, S.J.; Zhao, H.M.; Yang, X.H. A novel fault diagnosis method based on integrating empirical wavelet transform and fuzzy entropy for motor bearing. IEEE Access 2018, 6, 35042–35056. [Google Scholar] [CrossRef]
- Leo, M.; Carcagnì, P.; Distante, C.; Spagnolo, P.; Mazzeo, P.; Rosato, A.; Petrocchi, S.; Pellegrino, C.; Levante, A.; De Lumè, F.; et al. Computational Assessment of Facial Expression Production in ASD Children. Sensors 2018, 18, 3993. [Google Scholar] [CrossRef] [PubMed]
- Ekman, P. Facial expression and emotion. Am. Psychol. 1993, 48, 384–392. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Zhalehpour, S.; Onder, O.; Akhtar, Z.; Erdem, C.E. BAUM-1: A Spontaneous Audio-Visual Face Database of Affective and Mental States. IEEE Trans. Affect. Comput. 2017, 8, 300–313. [Google Scholar] [CrossRef]
- Martin, O.; Kotsia, I.; Macq, B.; Pitas, I. The eNTERFACE’ 05 Audio-Visual Emotion Database. In Proceedings of the International Conference on Data Engineering Workshops, Atlanta, GA, USA, 3–7 April 2006. [Google Scholar]
- Ren, Z.; Skjetne, R.; Gao, Z. A Crane Overload Protection Controller for Blade Lifting Operation Based on Model Predictive Control. Energies 2019, 12, 50. [Google Scholar] [CrossRef]
- Huibin, L.I.; Sun, J.; Zongben, X.U.; Chen, L. Multimodal 2D+3D Facial Expression Recognition with Deep Fusion Convolutional Neural Network. IEEE Trans. Multimed. 2017, 19, 2816–2831. [Google Scholar]
- Liu, M.; Li, S.; Shan, S.; Wang, R.; Chen, X. Deeply Learning Deformable Facial Action Parts Model for Dynamic Expression Analysis. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 143–157. [Google Scholar]
- Zhang, K.; Huang, Y.; Du, Y.; Wang, L. Facial Expression Recognition Based on Deep Evolutional Spatial-Temporal Networks. IEEE Trans. Image Process. 2017, 26, 4193–4203. [Google Scholar] [CrossRef] [PubMed]
- Zhao, S.; Liu, Y.; Han, Y.; Hong, R.; Hu, Q.; Tian, Q. Pooling the Convolutional Layers in Deep ConvNets for Video Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 1839–1849. [Google Scholar] [CrossRef]
- Zhao, H.; Yao, R.; Xu, L.; Yuan, Y.; Li, G.; Deng, W. Study on a Novel Fault Damage Degree Identification Method Using High-Order Differential Mathematical Morphology Gradient Spectrum Entropy. Entropy 2018, 20, 682. [Google Scholar] [CrossRef]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN architecture for weakly supervised place recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5297–5307. [Google Scholar]
- Borza, D.; Danescu, R.; Itu, R.; Darabant, A. High-Speed Video System for Micro-Expression Detection and Recognition. Sensors 2017, 17, 2913. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Li, Y.; Ma, X.; Song, R. Facial Expression Recognition with Fusion Features Extracted from Salient Facial Areas. Sensors 2017, 17, 712. [Google Scholar] [CrossRef] [PubMed]
- Xie, W.; Shen, L.; Yang, M.; Lai, Z. Active AU Based Patch Weighting for Facial Expression Recognition. Sensors 2017, 17, 275. [Google Scholar] [CrossRef] [PubMed]
- Sikka, K.; Wu, T.; Susskind, J.; Bartlett, M. Exploring bag of words architectures in the facial expression domain. In Proceedings of the International Conference on Computer Vision, Xiamen, China, 16–18 December 2012; pp. 250–259. [Google Scholar]
- Wang, Z.; Ruan, Q.; An, G. Facial expression recognition using sparse local Fisher discriminant analysis. Neurocomputing 2016, 174, 756–766. [Google Scholar] [CrossRef]
- Lyons, M.; Akamatsu, S.; Kamachi, M.; Gyoba, J. Coding facial expressions with Gabor wavelets. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998. [Google Scholar]
- Nanni, L.; Brahnam, S.; Lumini, A. Local phase quantization descriptor for improving shape retrieval/classification. Pattern Recognit. Lett. 2012, 33, 2254–2260. [Google Scholar] [CrossRef]
- Kayaoglu, M.; Erdem, C.E. Affect Recognition using Key Frame Selection based on Minimum Sparse Reconstruction. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 519–524. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Haryanto, I.; Ariyanto, M.; Caesarendra, W.; Dewoto, H.K. Development of Speech Control for Robotic Hand Using Neural Network and Stream Processing Method. Internetworking Indones. J. 2017, 9, 59–64. [Google Scholar]
- Caesarendra, W.; Wijaya, T.; Tjahjowidodo, T.; Pappachan, B.K.; Wee, A.; Roslan, M.I. Adaptive Neuro-Fuzzy Inference System for Deburring Stage Classification and Prediction for Indirect Quality Monitoring. Appl. Soft Comput. 2018, 72, 565–578. [Google Scholar] [CrossRef]
- Gajewski, J.; Vališ, D. The determination of combustion engine condition and reliability using oil analysis by MLP and RBF neural networks. Tribol. Int. 2017, 115, 557–572. [Google Scholar] [CrossRef]
- Wilk-Kolodziejczyk, D.; Regulski, K.; Gumienny, G.; Kacprzyk, B.; Kluska-Nawarecka, S.; Jaskowiec, K. Data mining tools in identifying the components of the microstructure of compacted graphite iron based on the content of alloying elements. Int. J. Adv. Manuf. Technol. 2018, 95, 3127–3139. [Google Scholar] [CrossRef]
- Kim, B.K.; Lee, H.; Roh, J.; Lee, S.Y. Hierarchical Committee of Deep CNNs with Exponentially-Weighted Decision Fusion for Static Facial Expression Recognition. In Proceedings of the ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 427–434. [Google Scholar]
- Deng, W.; Yao, R.; Zhao, H.M.; Yang, X.H.; Li, G.Y. A novel intelligent diagnosis method using optimal LS-SVM with improved PSO algorithm. Soft Comput. 2017, 1–18. [Google Scholar] [CrossRef]
- Mollahosseini, A.; Chan, D.; Mahoor, M.H. Going Deeper in Facial Expression Recognition using Deep Neural Networks. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016. [Google Scholar]
- Ding, H.; Zhou, S.K.; Chellappa, R.; Ding, H.; Zhou, S.K.; Chellappa, R. FaceNet2ExpNet: Regularizing a Deep Face Recognition Net for Expression Recognition. In Proceedings of the IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017. [Google Scholar]
- Kahou, S.E.; Michalski, V.; Konda, K.; Memisevic, R.; Pal, C. Recurrent Neural Networks for Emotion Recognition in Video. In Proceedings of the ACM International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 467–474. [Google Scholar]
- Rodriguez, P.; Cucurull, G.; Gonzalez, J.; Gonfaus, J.M.; Nasrollahi, K.; Moeslund, T.B.; Roca, F.X. Deep Pain: Exploiting Long Short-Term Memory Networks for Facial Expression Classification. IEEE Trans. Syst. Man Cybern. 2017. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.; Fu, Y.; Jiang, Y.G.; Xue, X. Frame-Transformer Emotion Classification Network. In Proceedings of the ACM on International Conference on Multimedia Retrieval, New York, NY, USA, 6–9 June 2017; pp. 78–83. [Google Scholar]
- Tang, Y.; Zhang, X.M.; Wang, H. Geometric-Convolutional Feature Fusion Based on Learning Propagation for Facial Expression Recognition. IEEE Access 2018, 6, 42532–42540. [Google Scholar] [CrossRef]
- Kim, D.H.; Baddar, W.; Jang, J.; Yong, M.R. Multi-Objective based Spatio-Temporal Feature Representation Learning Robust to Expression Intensity Variations for Facial Expression Recognition. IEEE Trans. Affect. Comput. 2017. [Google Scholar] [CrossRef]
- Ballester, P.L.; Araujo, R.M. On the performance of GoogLeNet and AlexNet applied to sketches. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 1124–1128. [Google Scholar]
- Bruhn, A.; Weickert, J.; Schnörr, C. Lucas/Kanade Meets Horn/Schunck: Combining Local and Global Optic Flow Methods. Int. J. Comput. Vis. 2005, 61, 211–231. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Robust Real-time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Zhang, S.; Zhao, X.; Chuang, Y.; Guo, W.; Chen, Y. Learning Discriminative Dictionary for Facial Expression Recognition. IETE Tech. Rev. 2017, 33, 1–7. [Google Scholar] [CrossRef]
- Müller, C. The INTERSPEECH 2010 Paralinguistic Challenge. In Proceedings of the Interspeech, Chiba, Japan, 26–30 September 2010; pp. 2794–2797. [Google Scholar]
- Deng, W.; Zhao, H.; Yang, X.; Xiong, J.; Sun, M.; Li, B. Study on an improved adaptive PSO algorithm for solving multi-objective gate assignment. Appl. Soft Comput. 2017, 59, 288–302. [Google Scholar] [CrossRef]
- Deng, W.; Zhao, H.; Zou, L.; Li, G.; Yang, X.; Wu, D. A novel collaborative optimization algorithm in solving complex optimization problems. Soft Comput. 2017, 21, 1–12. [Google Scholar] [CrossRef]
- Krishnapuram, B.; Carin, L.; Figueiredo, M.A.T.; Hartemink, A.J. Sparse multinomial logistic regression: Fast algorithms and generalization bounds. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 957–968. [Google Scholar] [CrossRef] [PubMed]
- Klaser, A.; Marszałek, M.; Schmid, C. A Spatio-Temporal Descriptor based on 3D Gradients (HOG3D). In Proceedings of the BMVC 2008—19th British Machine Vision Conference, Leeds, UK, 1–4 September 2008. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mansoorizadeh, M.; Charkari, N.M. Multimodal information fusion application to human emotion recognition from face and speech. Multimed. Tools Appl. 2010, 49, 277–297. [Google Scholar] [CrossRef]
- Bejani, M.; Gharavian, D.; Charkari, N.M. Audiovisual emotion recognition using ANOVA feature selection method and multi-classifier neural networks. Neural Comput. Appl. 2014, 24, 399–412. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | BAUM-1s | eNTERFACE05 |
|---|---|---|
| trained schema | 46.51% | 43.72% |
| non-trained schema | 46.02% | 42.97% |
| Method | BAUM-1s | eNTERFACE05 |
|---|---|---|
| fc7 | 46.51% | 43.72% |
| fc6 | 45.01% | 42.11% |
| Stream | BAUM-1s | eNTERFACE05 |
|---|---|---|
| Spatial–temporal streams | 46.51% | 43.72% |
| Spatial streams | 42.68% | 41.03% |
| Temporal streams | 41.09% | 39.75% |
| Method | BAUM-1s | eNTERFACE05 |
|---|---|---|
| Ours | 46.51% | 43.72% |
| HOG 3D | 43.02% | 41.23% |
| 3DCNN | 42.89% | 41.05% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, X.; Guo, W.; Guo, X.; Li, W.; Xu, J.; Wu, J. Deep Temporal–Spatial Aggregation for Video-Based Facial Expression Recognition. Symmetry 2019, 11, 52. https://doi.org/10.3390/sym11010052
Pan X, Guo W, Guo X, Li W, Xu J, Wu J. Deep Temporal–Spatial Aggregation for Video-Based Facial Expression Recognition. Symmetry. 2019; 11(1):52. https://doi.org/10.3390/sym11010052
Chicago/Turabian StylePan, Xianzhang, Wenping Guo, Xiaoying Guo, Wenshu Li, Junjie Xu, and Jinzhao Wu. 2019. "Deep Temporal–Spatial Aggregation for Video-Based Facial Expression Recognition" Symmetry 11, no. 1: 52. https://doi.org/10.3390/sym11010052
APA StylePan, X., Guo, W., Guo, X., Li, W., Xu, J., & Wu, J. (2019). Deep Temporal–Spatial Aggregation for Video-Based Facial Expression Recognition. Symmetry, 11(1), 52. https://doi.org/10.3390/sym11010052