Evaluation of Speech Quality Through Recognition and Classification of Phonemes

Abstract
:1. Introduction
2. Evaluation of Speech Quality Through Recognition and Classification of Phonemes
2.1. Methods of Syllable Recognition
- -
- the direct recognition of pronounced phonemes within a syllable. The main disadvantage of this approach is a large number of classes (which is equal to the number of phonemes). As a result, we have a high level of error. On the other hand, the positive aspects include the straightforward result in the form of a phoneme sequence and the ease of error determination;
- -
- the recognition of phonemes within a syllable as instances of classes formed of phonetic groups. The positive side is that the accuracy increases due to the reduced number of classes. However, it leads to a lack of direct interpretation, hence a lack of direct evaluation of the assessment according to GOST R 50840-95;
- -
- the identification of boundaries between phonetic segments using a neural network for the follow-up application of parametric approaches in comparing these segments. In this case, the accuracy of determining transitions between phonemes is more important than the classification accuracy. A measure of difference between the selected segments is determined on the basis of previously developed parametric methods [3]. The disadvantage of this option is the unavailability of quantitative assessment such as the classic syllable intelligibility (as defined in Section 2.1) in the output of the system.
2.2. Direct Recognition of Phonemes
- Dependence on a speaker. A model for assessing the quality of speech was built for each new speaker. There was no task to improve the quality of speech in relation to the already established manner of pronouncing phonemes or to the presence of speech defects. The task in the rehabilitation process was to maximize the conformity of a patientˈs after-surgery speech with their speech before the operative treatment. This limitation significantly simplifies the task because there is no need to use a large database of records from many speakers for training.
- Limited number of phonemes. We were primarily interested in the quality of pronouncing the phonemes that were most susceptible to change after the operation. For this reason, the table of syllables focuses specifically on those problematic phonemes.
- The assessment speed of one syllable, pronounced by a patient while practicing at the rehabilitation stage, should be as fast as possible. Currently, the evaluation takes 3 seconds per syllable. The training time of the convolutional neural network (CNN) takes less than one hour. The Adam optimizer with a mini-batch size of 128 was used for training of the neural network [23]. However, the training time did not matter much since the period of time between a before-surgery session and the first rehabilitation session was approximately one week.
- Within the framework of the paper, the term “syllable intelligibility” refers to the proportion of correctly recognized syllables among all of them pronounced by a patient in accordance with a predefined set of syllables. In the future, values of the output layer of the neural network will be used to assess the degree of similarity between a pronounced phoneme and the correct one in order to implement the biofeedback mechanism in the rehabilitation process. However, in this paper, the idea was to prove the applicability of this automated speech quality assessment approach to speech rehabilitation.
- It was known in advance which syllable was pronounced. There was no need to interpret the sequence of recognized phonemes, transforming it into a syllable; it was only necessary to estimate the proportion of correctly pronounced phonemes in that sequence.
2.3. Algorithm of Automatic Time Alignment at Phoneme Level
- Training a neural network (initially on data from an audio-aligned corpus).
- Recognition of a phonemic composition as phonetic sequences for each syllable.
- Determining time-aligned phonemic transcriptions of syllables.
- Adjustment of recognized phonemic compositions and selection of syllables with a correctly defined phonemic composition.
- Forming additional data from transcriptions of correctly recognized syllables.
- Going to step 1 and retraining the neural network on an updated dataset (including new data formed at step 5).
2.3.1. Phoneme Recognition and Time Alignment
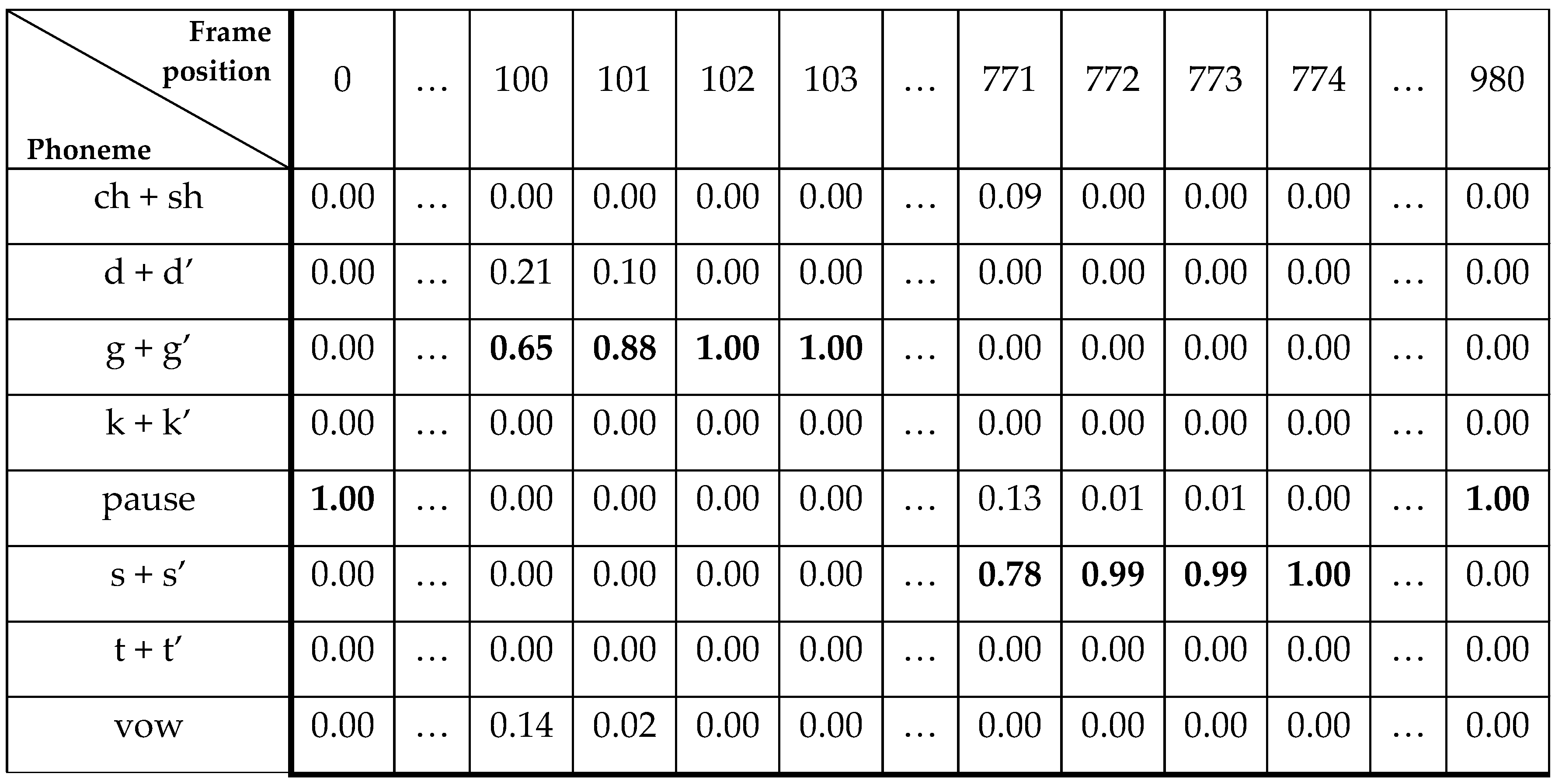
- The minimum length of a phoneme (the minimum number of consecutive frames labeled as the same phoneme) as min_seq_len.
- The maximum length of deviations from a consecutive sequence of the same phoneme labels as max_dev_len.
- SEQUENCE_1. 1:pause/ 2:pause/ 3:pause/ 4:pause/ 5:s + sˈ (dev_len = 1)/ 6:pause/ 7:g + gˈ (dev_len = 2 > max_dev_len, seq_len = 6 ≥ min_seq_len) ≥ “pause 1–6” is appended to the result
- SEQUENCE_2. 7:g + gˈ/ 8:g + gˈ/ 9:g + gˈ/ 10:g + gˈ/ 11:g + gˈ/ 12:g + gˈ/ 13:d + dˈ (dev_len = 1)/ 14:d+dˈ (dev_len = 2 > max_dev_len, seq_len = 6 ≥ min_seq_len) ≥ “g + gˈ 7–12” is appended to the result
- SEQUENCE_3. 13:d + dˈ/ 14:d + dˈ/ 15:d + dˈ/ 16:vow (dev_len = 1)/ 17:vow (dev_len = 2 > max_dev_len, seq_len = 3 < min_seq_len) ≥ nothing is appended to the result
- SEQUENCE_4. 16:vow/ 17:vow/ 18:vow/ 19:vow/ 20:vow/ 21:s + sˈ (dev_len = 1)/ 22:s + sˈ (dev_len = 2 > max_dev_len, seq_len = 5 ≥ min_seq_len) ≥ “vow 16–20” is appended to the result
- SEQUENCE_5. is formed in the same way as SEQUENCE_4. “s + sˈ 21–25” is appended to the result
- SEQUENCE_6. 26:pause/ 27:pause/ 28:pause/ 29:pause/ 30:pause (last frame reached, seq_len = 5 ≥ min_seq_len) ≥ “pause 26–30” is appended to the result
2.3.2. Adjustment of Recognized Phonemic Composition
- Substitution
- Shift
- Removal
3. Results of Experiments
3.1. The Direct Recognition of Problem Syllables
- In Table 2, even for a healthy speaker, the syllable intelligibility calculated by the CNN did not reach 100%, thus diverging from the opinion of the experts. However, mistakes mostly arose from “non-problematic” phonemes, which is explained by their small share in the syllable set table. In particular, some of the phoneme implementations in the table are missing, since recognition was not the ultimate goal of the system.
- On the other hand, for problematic phonemes, the results of which are presented in Table 3, the difference is statistically insignificant when using the Studentˈs t-test with the 0.95 significance level. In the future, it is possible to increase this value due to the variation in the structure of the neural network used and its adaptation to the problem being solved.
- The qualitative assessment of syllable intelligibility given by the CNN corresponds to the experts’ ones. This fact allows a discussion about the applicability of the proposed approach for solving the problem of speech quality assessment during speech rehabilitation. It also confirms the consistency at the level of ranking positions between the classical expert method for estimating syllable intelligibility and the proposed method using neural networks.
3.2. The Speaker-Dependent Neural Network for Class Segmentation
- 1 initial speaker-independent neural network trained on 7 sentences recorded by 10 speakers;
- 6 Russian-speaking patients (3 female and 3 male voices);
- 8 classes of phonemes were considered: [ch + sh], [d + dˈ], [g + gˈ], [k + kˈ], [pause], [s + sˈ], [t + tˈ], [vow];
- a set of 15 syllables (see Table 4).
- The proposed algorithm gives the expected result and may be applied for automatic identification of a phonemic composition of syllables as well as for determining the start and the end time points for each phoneme.
- The syllables [dˈokt] and [stˈɨt͡ɕ] turned out to be the most problematic syllables. This may be due to two consecutive voiceless phonemes, such as /k/, /t/ for [dˈokt] or /s/, /t/ for [stˈɨt͡ɕ].
- The efficiency of the algorithm may be improved by fine-tuning min_seq_len and max_dev_len parameters based on the specificities of phonemes.
4. Conclusions
- Verification of the system’s functioning using several trained neural networks that can act as separate auditors [29] (in accordance with GOST R 50840-95, the plan is to use five neural networks).
- Use of a fraction of correctly recognized phonemes in a time interval, as well as use of quantitative outputs of a neural network to increase the flexibility of the values obtained, currently at the level of a correctly/incorrectly recognized syllable.
- Verification of the obtained approach on the full extent of the available data for the rehabilitation process with real patients.
- Recurrent training with the addition of data allows researchers to increase the accuracy of speech information analysis.
- The total classification accuracy without reference to the speaker exceeds 82%.
- The number of training iterations, at which an increase in the resulting accuracy is recorded, does not exceed six cycles of additional training.
Author Contributions
Funding
Conflicts of Interest
References
- del Carmen Migueláñez-Medrán, B.; Pozo-Kreilinger, J.-J.; Cebrián-Carretero, J.-L.; Martínez-García, M.-Á.; López-Sánchez, A.-F. Oral squamous cell carcinoma of tongue: Histological risk assessment. A pilot study. Med. Oral. Patol. Oral Cir. Bucal. 2019, 24, e603–e609. [Google Scholar]
- Kishimoto, Y.; Suzuki, S.; Shoji, K.; Kawata, Y.; Shinichi, T. Partial glossectomy for early tongue cancer. Pract. Oto-Rhino-Laryngologica 2004, 97, 719–723. [Google Scholar] [CrossRef]
- Kostyuchenko, E.; Meshcheryakov, R.; Balatskaya, L.; Choinzonov, E. Structure and database of software for speech quality and intelligibility assessment in the process of rehabilitation after surgery in the treatment of cancers of the oral cavity and oropharynx, maxillofacial area. SPIIRAS Proc. 2014, 32, 116–124. [Google Scholar]
- Kostyuchenko, E.; Ignatieva, D.; Meshcheryakov, R.; Pyatkov, A.; Choynzonov, E.; Balatskaya, L. Model of system quality assessment pronouncing phonemes. In Proceedings of the 2016 Dynamics of Systems, Mechanisms and Machines, Omsk, Russia, 15–17 November 2016. [Google Scholar] [CrossRef]
- GOST R 50840-95. Speech Transmission over Varies Communication Channels. Techniques for Measurements of Speech Quality, Intelligibility and Voice Identification; National Institute of Standards: Moscow, Russia, 1995.
- Boersma, P. Praat, a system for doing phonetics by computer. Glot Int. 2002, 5, 341–345. [Google Scholar]
- Sjölander, K.; Beskow, J. Wavesurfer—An open source speech tool. In Proceedings of the Sixth International Conference on Spoken Language Processing (ICSLP 2000), Beijing, China, 16–20 October 2000; Volume 4, pp. 464–467. [Google Scholar]
- Song, J.; Chen, B.; Jiang, K.; Yang, M.; Xiao, X. The Software System Implementation of Speech Command Recognizer under Intensive Background Nosie. IOP Conf. Ser. Mater. Sci. Eng. 2019, 563, 052090. [Google Scholar] [CrossRef]
- Betkowska, A.; Shinoda, K.; Furui, S. Robust speech recognition using factorial HMMs for home environments. Eurasip J. Adv. Signal Process. 2007, 20593. [Google Scholar] [CrossRef]
- Mahadevaswamy; Ravi, D.J. Performance of isolated and continuous digit recognition system using Kaldi toolkit. Int. J. Recent Technol. Eng. 2019, 8, 264–271. [Google Scholar]
- Thimmaraja Yadava, G.; Jayanna, H.S. Creation and comparison of language and acoustic models using Kaldi for noisy and enhanced speech data. Int. J. Intell. Syst. Appl. 2018, 10, 22–32. [Google Scholar]
- Shewalkar, A.; Nyavanandi, D.; Ludwig, S.A. Performance Evaluation of Deep neural networks Applied to Speech Recognition: RNN, LSTM and GRU. J. Artif. Intell. Soft Comput. Res. 2019, 9, 235–245. [Google Scholar] [CrossRef]
- Tóth, L. Phone recognition with hierarchical convolutional deep maxout networks. Eurasip J. Audio Speech Music Process. 2015, 25, 1–13. [Google Scholar] [CrossRef]
- Mendiratta, S.; Turk, N.; Bansal, D. ASR system for isolated words using ANN with back propagation and fuzzy based DWT. Int. J. Eng. Adv. Technol. 2019, 8, 4813–4819. [Google Scholar]
- James, P.E.; Mun, H.K.; Vaithilingam, C.A. A hybrid spoken language processing system for smart device troubleshooting. Electronics 2019, 8, 681. [Google Scholar] [CrossRef]
- Novoa, J.; Wuth, J.; Escudero, J.P.; Fredes, J.; Mahu, R.; Yoma, N.B. DNN-HMM based Automatic Speech Recognition for HRI Scenarios. In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction, Chicago, IL, USA, 5–8 March 2018; pp. 150–159. [Google Scholar]
- Wang, D.; Wang, X.; Lv, S. An Overview of End-to-End 2000Automatic Speech Recognition. Symmetry 2019, 11, 1018. [Google Scholar] [CrossRef]
- Wang, D.; Wang, X.; Lv, S. End-to-End Mandarin Speech Recognition Combining CNN and BLSTM. Symmetry 2019, 11, 644. [Google Scholar] [CrossRef]
- Young, S.; Evermann, G.; Gales, M.; Hain, T.; Kershaw, D.; Liu, X.; Moore, G.; Odell, J.; Ollason, D.; Povey, D.; et al. The HTK Book (v3.4); Engineering Department, Cambridge University: Cambridge, UK, 2009. [Google Scholar]
- Trmal, J.; Wiesner, M.; Peddinti, V.; Zhang, X.; Ghahremani, P.; Wang, Y.; Manohar, V.; Xu, H.; Povey, D.; Khudanpur, S. The Kaldi OpenKWS System: Improving low resource keyword search. In Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), Stockholm, Sweden, 20–24 August 2017; pp. 3597–3601. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi Speech Recognition Toolkit. Available online: https://infoscience.epfl.ch/record/192584 (accessed on 14 October 2019).
- Lee, K.-F.; Hon, H.-W.; Reddy, R. An Overview of the SPHINX Speech Recognition System. IEEE Trans. Acoust. Speech Signal Process. 1990, 38, 35–45. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; p. 149801. [Google Scholar]
- Mathworks Homepage. Available online: https://www.mathworks.com/ (accessed on 14 October 2019).
- IDEF: Integrated Computer-Aided Manufacturing (ICAM) Architecture, Part II (1981) Volume VI—Function Modeling Manual, 3rd ed.; USAF Report Number AFWAL-TR-81-4023; Wright-Patterson AFB: Dayton, OH, USA, June 1981.
- Graves, A.; Fernandez, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning (ICML 2006), Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Scheidl, H.; Fiel, S.; Sablatnig, R. Word Beam Search: A Connectionist Temporal Classification Decoding Algorithm. In Proceedings of the 16th International Conference on Frontiers in Handwriting Recognition (ICFHR 2018), Niagara Falls, NY, USA, 5–8 August 2018; pp. 253–258. [Google Scholar]
- International Phonetic Association. Available online: https://www.internationalphoneticassociation.org (accessed on 30 April 2019).
- Karpov, A.A. An automatic multimodal speech recognition system with audio and video information. Autom. Remote Control 2014, 75, 2190–2200. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Phoneme | Start | End |
|---|---|---|---|
| 1 | pause | 1 | 6 |
| 2 | g + gˈ | 7 | 12 |
| 3 | vow | 16 | 20 |
| 4 | s + sˈ | 21 | 25 |
| 5 | pause | 26 | 30 |
| Person No. | Normal by the Experts | Without Tongue by the Experts | Normal by the CNN | Without Tongue by the CNN |
| Person1 | 1.00 | 0.43 | 0.64 | 0.24 |
| Person2 | 1.00 | 0.43 | 0.43 | 0.20 |
| Person3 | 1.00 | 0.57 | 0.50 | 0.29 |
| Patient No. | Before-Surgery by the Experts | After-Surgery by the Experts | Before-Surgery by the CNN | After-Surgery by the CNN |
| Patient1 | 1.00 | 0.44 | 0.53 | 0.21 |
| Patient2 | 0.99 | 0.68 | 0.47 | 0.31 |
| Patient3 | 1.00 | 0.57 | 0.56 | 0.20 |
| Person No. | Normal by the Experts | Without Tongue by the Experts | Normal by the CNN | Without Tongue by the CNN |
| Person1 | 1.00 | 0.43 | 0.95 | 0.60 |
| Person2 | 1.00 | 0.43 | 0.97 | 0.51 |
| Person3 | 1.00 | 0.57 | 0.97 | 0.65 |
| Patient No. | Before-Surgery by the Experts | After-Surgery by the Experts | Before-Surgery by the CNN | After-Surgery by the CNN |
| Patient1 | 1.00 | 0.44 | 0.99 | 0.56 |
| Patient2 | 0.99 | 0.68 | 0.97 | 0.69 |
| Patient3 | 1.00 | 0.57 | 0.99 | 0.59 |
| No. | Serial Number | Syllable (in accordance with the International Phonetics Association (IPA) [28]) | Phonemic Composition (in accordance with 8 classes) |
|---|---|---|---|
| 1 | 265 | [kˈasʲ] | [k + kˈ, vow, s + sˈ] |
| 2 | 271 | [dˈokt] | [d + dˈ, vow, k + kˈ, t + tˈ] |
| 3 | 282 | [kʲˈæsʲtʲ] | [k + kˈ, vow, s + sˈ, t + tˈ] |
| 4 | 283 | [kʲˈɵs] | [k + kˈ, vow, s + sˈ] |
| 5 | 289 | [ʂkʲˈet] | [ch + sh, k + kˈ, vow, t + tˈ] |
| 6 | 295 | [sˈosʲ] | [s + sˈ, vow, s + sˈ] |
| 7 | 298 | [sˈɨt͡ɕ] | [s + sˈ, vow, ch + sh] |
| 8 | 305 | [dˈɨs] | [d + dˈ, vow, s + sˈ] |
| 9 | 306 | [ɡˈɨs] | [g + gˈ, vow, s + sˈ] |
| 10 | 310 | [sʲˈit͡ɕ] | [s + sˈ, vow, ch + sh] |
| 11 | 311 | [sʲˈesʲ] | [s + sˈ, vow, s + sˈ] |
| 12 | 316 | [ksˈɛt] | [k + kˈ, s + sˈ, vow, t + tˈ] |
| 13 | 323 | [ʂˈɨsʲ] | [ch + sh, vow, s + sˈ] |
| 14 | 332 | [stˈɨt͡ɕ] | [s + sˈ, t + tˈ, vow, ch + sh] |
| 15 | 351 | [t͡ɕˈætʲ] | [ch + sh, vow, t + tˈ] |
| Patient No. | Gender | Fully Correct Recognized Syllables | Problematic Syllables | Number of Iterations |
|---|---|---|---|---|
| 1 | female | 13/15 | [dˈokt], [stˈɨt͡ɕ] | 6 |
| 2 | female | 12/15 | [kˈasʲ], [dˈokt], [ʂkʲˈet] | 6 |
| 3 | female | 12/15 | [ʂkʲˈet], [ɡˈɨs], [stˈɨt͡ɕ] | 5 |
| 4 | male | 12/15 | [dˈokt], [ksˈɛt], [stˈɨt͡ɕ] | 2 |
| 5 | male | 12/15 | [dˈokt], [ɡˈɨs], [sʲˈit͡ɕ] | 4 |
| 6 | male | 13/15 | [ksˈɛt], [stˈɨt͡ɕ] | 5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pekarskikh, S.; Kostyuchenko, E.; Balatskaya, L. Evaluation of Speech Quality Through Recognition and Classification of Phonemes. Symmetry 2019, 11, 1447. https://doi.org/10.3390/sym11121447
Pekarskikh S, Kostyuchenko E, Balatskaya L. Evaluation of Speech Quality Through Recognition and Classification of Phonemes. Symmetry. 2019; 11(12):1447. https://doi.org/10.3390/sym11121447
Chicago/Turabian StylePekarskikh, Svetlana, Evgeny Kostyuchenko, and Lidiya Balatskaya. 2019. "Evaluation of Speech Quality Through Recognition and Classification of Phonemes" Symmetry 11, no. 12: 1447. https://doi.org/10.3390/sym11121447