Implementation of Artificial Intelligence for Classification of Frogs in Bioacoustics

Abstract
:1. Introduction
2. Theory of Bioacoustics Signal Processing
2.1. Bioacoustic Feature Extraction
2.2. Frogs Classification Method
2.2.1. Feedforward Neural Network Approach
2.2.2. Support Vector Machine Approach
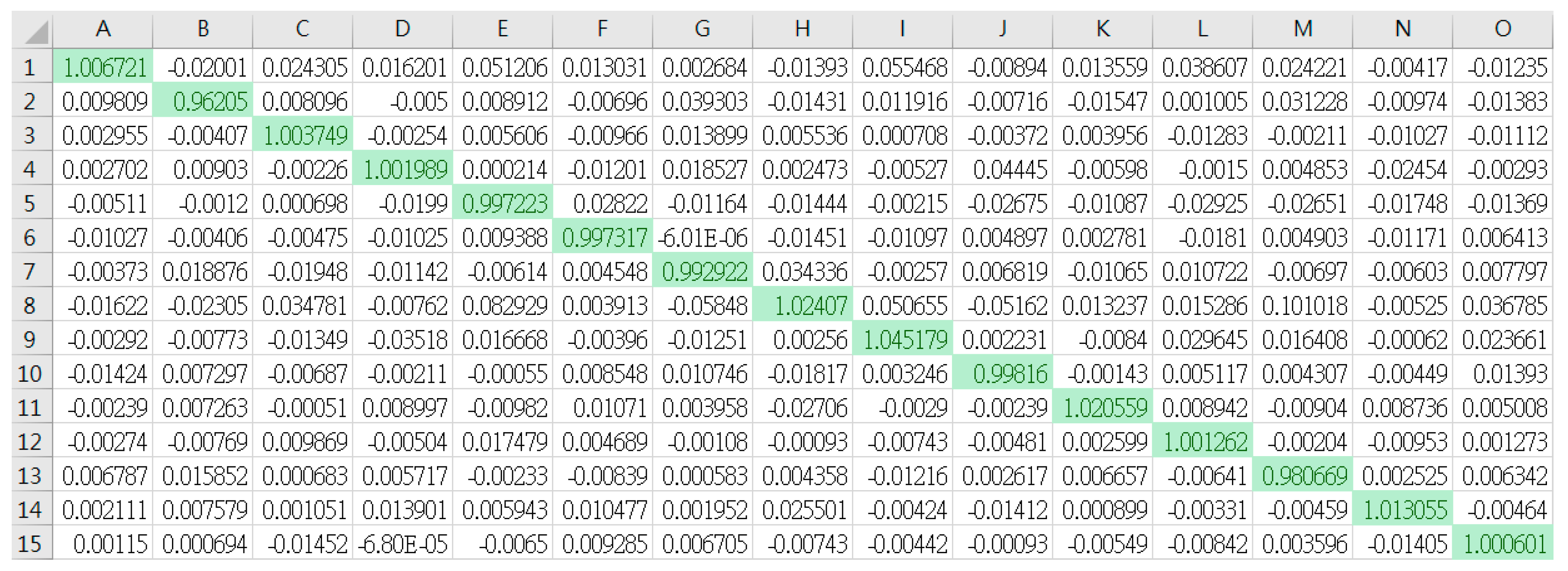
3. Results and Verification
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gretta, T.P.; Miguel, B.A.; Johann, D.B.; Julia, B.; Timothy, C.B.; Chen, I.C.; Timothy, D.C.; Robert, K.C.; Finn, D.; Birgitta, E.; et al. Biodiversity redistribution under climate change: Impacts on ecosystems and human well-being. Science 2017, 355, 9214. [Google Scholar]
- Davis, M.B.; Shaw, R.G. Range shifts and adaptive responses to quaternary climate change. Science 2001, 292, 673–679. [Google Scholar] [CrossRef] [PubMed]
- Peter, M.N.; Sebastiaan, W.F.M. Climate change and frog calls: Long-term correlations along a tropical altitudinal gradient. Proc. R. Soc. B 2014, 281. [Google Scholar] [CrossRef]
- Xie, J.; Towsey, M.; Zhang, J.; Paul, R. Detecting frog calling activity based on acoustic event detection and multi-label learning. Procedia Comput. Sci. 2016, 80, 627–638. [Google Scholar] [CrossRef]
- Amalia, L.; Javier, R.L.; Alejandro, C.; Julio, B. Non-sequential automatic classification of anuran sounds for the estimation of climate-change indicators. Expert Syst. Appl. 2018, 95, 248–260. [Google Scholar]
- John, J.V.; Colin, T.; Michael, K.; Alex, T.; Joah, M. Applications of machine learning in animal behaviour studies. Anim. Behav. 2017, 124, 203–220. [Google Scholar]
- Kelly, R.F.; Matthew, J.S.; Mason, A.P.; Noa, P.W. The use of multilayer network analysis in animal behaviour. Anim. Behav. 2019, 149, 7–22. [Google Scholar]
- Xie, J.; Karlina, I.; Lin, S.; Michael, T.; Zhang, J.; Paul, R. Acoustic classification of frog within-species and species-specific calls. Appl. Acoust. 2018, 131, 79–86. [Google Scholar] [CrossRef]
- Ahmad, A.; Miad, F. Acoustic signal classification of breathing movements to virtually aid breath regulation. IEEE J. Biomed. Health Inform. 2013, 17, 493–500. [Google Scholar]
- Chen, Y.T. An Intelligent Nocturnal Animal Sound Identification System. Master’s Thesis, National Dong Hwa University, Taiwan, July 2011. [Google Scholar]
- Amalia, L.; Jesús, G.B.; Alejandro, C.; Julio, B. Exploiting the symmetry of integral transforms for featuring anuran calls. Symmetry 2019, 11, 405. [Google Scholar]
- Wu, J.D.; Mingsian, R.B.; Su, F.C.; Huang, C.W. An expert system for the diagnosis of faults in rotating machinery using adaptive order-tracking algorithm. Expert Syst. Appl. 2009, 36, 5424–5431. [Google Scholar] [CrossRef]
- Tuomas, V.; Mark, D.P.; Daniel, P.W.E. Computational Analysis of Sound Scenes and Events; Spring International Publishing: Cham, Switzerland, 2017; pp. 303–333. [Google Scholar]
- Huang, C.J.; Yang, Y.J.; Yang, D.X.; Chen, Y.J. Frog classification using machine learning techniques. Expert Syst. Appl. 2009, 36, 3737–3743. [Google Scholar] [CrossRef]
- Jeffrey, A.N.; Sue, E.M.; Phyllis, J.S. A sound budget for the southeastern Bering Sea: Measuring wind, rainfall, shipping, and other sources of underwater sound. J. Acoust. Soc. Am. 2010, 128, 58–65. [Google Scholar]
- Lei, B.; Zhang, Y.; Yang, Y. Detection of sound field aberrations caused by forward scattering from underwater intruders using unsupervised machine learning. IEEE Access 2017, 7, 17608–17616. [Google Scholar] [CrossRef]
- Anshul, T.; Daksh, T.; Padmanabhan, R.; Aditya, N. Deep metric learning for bioacoustic classification: Overcoming training data scarcity using dynamic triplet loss. J. Acoust. Soc. Am. 2019, 146, 534–547. [Google Scholar]
- Anshul, T.; Padmanabhan, R. Deep archetypal analysis based intermediate matching kernel for bioacoustic classification. IEEE J. Selec. Top. Sign. Process. 2019, 13, 298–309. [Google Scholar]
- Juan, J.N.A.; Carlos, M.T.; David, S.R.; Malay, K.D.; Garima, V. Automatic classification of frogs calls based on fusion of features and SVM. In Proceedings of the Eighth International Conference on Contemporary Computing (IC3), Noida, India, 20–22 August 2015. [Google Scholar]
- Lincon, S.S.; Bernardo, B.G.; Kazuhiro, F. Classification of bioacoustic signals with tangent singular spectrum analysis. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Stavros, N. Automatic acoustic classification of insect species based on directed acyclic graphs. J. Acoust. Soc. Am. 2019, 145, 541–546. [Google Scholar]
- Kirsten, M.P.; Meah, V.L.; Joanne, M.A.N. Frogs call at a higher pitch in traffic noise. Ecol. Soc. 2009, 14, 1–24. [Google Scholar]
- Oscar, E.O.; Luis, J.V.R.; Carlos, J.C.B. Variable response of anuran calling activity to daily precipitation and temperature: Implications for climate change. Ecosphere 2013, 4, 1–12. [Google Scholar]
- Paul, S.C.; Jeff, H. Designing better frog call recognition models. Ecol. Evol. 2017, 7, 3087–3099. [Google Scholar]
- Qian, K.; Zhang, Z.; Alice, B.; Björn, S. Active learning for bird sound classification via a kernel-based extreme learning machine. J. Acoust. Soc. Am. 2017, 142, 1796–1804. [Google Scholar] [CrossRef]
- Wang, Y.; Wei, Z.; Yang, J. Feature trend extraction and adaptive density peaks search for intelligent fault diagnosis of machines. IEEE Trans. Ind. Inform. 2019, 15, 105–115. [Google Scholar] [CrossRef]
- Frogs’ World. Available online: http://learning.froghome.org/ (accessed on 1 January 2010).
- Xie, J.; Michael, T.; Zhang, J.; Paul, R. Frog call classification: A survey. Artif. Intell. Rev. 2018, 49, 375–391. [Google Scholar] [CrossRef]
- Xie, J.; Michael, T.; Zhang, J.; Paul, R. Investigation of acoustic and visual features for frog call classification. J. Sign. Process. Syst. 2019. [Google Scholar] [CrossRef]
- Marc, G.; Damian, M. Environmental sound monitoring using machine learning on mobile devices. Appl. Acoust. 2020, 159, 107041. [Google Scholar]
- Jesús, B.A.; Josué, C.; Rohit, S.; Carlos, M.T.; Federico, B.; Adrián, G.; Alexander, V.; Mark, W. Automatic anuran identification using noise removal and audio activity detection. Expert Syst. Appl. 2017, 72, 83–92. [Google Scholar]
- Juan, G.C.; Marco, C.; Mario, S.J.; Eduardo, F.N. An incremental technique for real-time bioacoustic signal segmentation. Expert Syst. Appl. 2015, 42, 7367–7374. [Google Scholar]
- Sebastian, R.; Vahid, M. Python Machine Learning, 2nd ed.; Packt Publishing: Birmingham, UK, 2017. [Google Scholar]
- Sumeet, D.; Xian, D. Data Mining and Machine Learning in Cybersecurity, 1st ed.; Auerbach Publications: New York, NY, USA, 2011; pp. 7–26. [Google Scholar]
- Francesco, C.; Alessandro, V. Machine Learning for Audio, Image and Video Analysis, 2nd ed.; Springer: London, UK, 2015; pp. 99–105. [Google Scholar]
- Lindasalwa, M.; Mumtaj, B. Voice recognition algorithms using Mel frequency cepstral coefficient (MFCC) and dynamic time warping (DTW) techniques. J. Comput. 2010, 2, 138–143. [Google Scholar]
- Gong, C.A.; Su, C.S.; Chuang, Y.C.; Tseng, K.H.; Li, T.H.; Chang, C.H.; Huang, L.H. Feature extraction of rotating apparatus using acoustic sensing technology. In Proceedings of the 11th International Conference on Ubiquitous and Future Networks, Split, Croatia, 2–5 July 2019. [Google Scholar]
- Gopi, E.S. Digital Speech Processing Using Matlab; Springer: Trichy, India, 2013; pp. 105–125. [Google Scholar]
- Hiroshi, I. Social Big Data Mining, 1st ed.; CRC Press: Boca Raton, FL, USA, 2015; pp. 125–135. [Google Scholar]
- Tobias, G.; Mahmoud, K.; Robert, P.C.; Brian, C.J.M. Using recurrent neural networks to improve the perception of speech in non-stationary noise by people with cochlear implants. J. Acoust. Soc. Am. 2019, 146, 705–718. [Google Scholar]
- Sovan, L.; Jean, F.G. Artificial Neuronal Networks: Application to Ecology and Evolution; Springer: Berlin, Germany, 2012; pp. 3–11. [Google Scholar]
- James, A.A.; Edward, R. Neurocomputing: Foundations of Research; A Bradford Book; The MIT Press: Cambridge, MA, USA, 1989. [Google Scholar]
- Fu, L. Neural Networks in Computer Intelligence; McGraw-Hill Inc.: New York, NY, USA, 1994. [Google Scholar]
- Bhavani, T.; Latifur, K.; Mamoun, A.; Wang, L. Design and Implementation of Data Mining Tools, 1st ed.; Auerbach Publications: Boca Raton, FL, USA, 2019. [Google Scholar]
- Pan, Y.P.; Liu, Y.Q.; Xu, B.; Yu, H.Y. Hybrid feedback feedforward: An efficient design of adaptive neural network control. Neural Netw. 2016, 76, 122–134. [Google Scholar] [CrossRef]
- Dreyfus, G. Neural Neetworks Methodology and Applications; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Corinna, C.; Vladimir, V. Support-vector networks. Mach. Learn. 2007, 20, 273–297. [Google Scholar]
- Guandong, X.; Zong, Y.; Yang, Z. Applied Data Mining, 1st ed.; CRC Press: Boca Raton, FL, USA, 2013; pp. 112–115. [Google Scholar]
- Almo, F. Soundscape Ecology: Principles, Patterns, Methods and Applications; Springer: Dordrecht, The Netherlands; New York, NY, USA, 2014. [Google Scholar]
- Gingras, B.; Boeckle, M.; Herbst, C.T.; Fitch, W.T. Call acoustics reflect body size across four clades of anurans. J. Zool. 2012, 289, 143–150. [Google Scholar] [CrossRef]
- Gnitecki, J.; Moussavi, Z.M. Separating Heart Sounds from Lung Sounds Accurate Diagnosis of Respiratory Disease Depends on Understanding Noises. IEEE Eng. Med. Biol. Mag. 2007, 6, 20–29. [Google Scholar] [CrossRef] [PubMed]
- Daryush, D.M.; Matías, Z.; Feng, S.W.; Harold, A.C.; Robert, E.H. Mobile Voice Health Monitoring Using a Wearable Accelerometer Sensor and a Smartphone Platform. IEEE Trans. Biomed. Eng. 2012, 59, 3090–3096. [Google Scholar]
- James, M.G.; Jose, A.G.; Lam, A.C.; Stephen, R.E.; Phil, G.; Roger, K.M.; Edward, H. Restoring speech following total removal of the larynx by a learned transformation from sensor data to acoustics. J. Acoust. Soc. Am. 2017, 141, 307–313. [Google Scholar]
- Jacob, B.; Man, M.S.; Huang, Y.A. Springer Handbook of Speech Processing; Springer: Berlin/Heidelberg, Germany, 2008; pp. 161–180. [Google Scholar]
- Sandro, S. Introduction to Deep Learning from Logical Calculus to Artificial Intelligence; Springer International Publishing: Berlin, Germany, 2018; pp. 51–119. [Google Scholar]
- Marco, A.A.F. Artificial Intelligence Emerging Trends and Applications; Intech: London, UK, 2018; pp. 275–291. [Google Scholar]
- Leanne, L. Artificial Intelligence for Fashion: How AI Is Revolutionizing the Fashion Industry, 1st ed.; Apress: New York, NY, USA, 2018; pp. 53–66, 141–144. [Google Scholar]
- Mohamed, A.F.; Makhlouf, D.; Mithun, M.; Abdelouahid, D.; Leandros, M.; Helge, J. Blockchain technologies for the internet of things: Research issues and challenges. IEEE Internet Things J. 2019, 6, 2188–2204. [Google Scholar]
- Christopher, J.C.B. A Tutorial on Support Vector Machine for Pattern Recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar]
- Pandian, V. Artificial Intelligence Techniques and Algorithms; Baker & Taylor: Charlotte, NC, USA, 2014; pp. 191–192. [Google Scholar]


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Machine Learning Processor | Optimizer Function | Final Epochs | Total Time (Second) | R-Scores |
|---|---|---|---|---|
| GPU | 12,234 | 9.228 | 0.99798 | |
| CPU | 9668 | 577.4620 | 0.99818 | |
| GPU | 183 | 4.3264 | 0.99832 | |
| CPU | 191 | 11.5490 | 0.99800 |
| Machine Learning Algorithm | Total Time (Second) | R-Scores |
|---|---|---|
| Neural networks (conducted by GPU with training function SCG) | 4.3264 | 0.99832 |
| Support vector machine | 5.1480 | 1.00000 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chao, K.-W.; Hu, N.-Z.; Chao, Y.-C.; Su, C.-K.; Chiu, W.-H. Implementation of Artificial Intelligence for Classification of Frogs in Bioacoustics. Symmetry 2019, 11, 1454. https://doi.org/10.3390/sym11121454
Chao K-W, Hu N-Z, Chao Y-C, Su C-K, Chiu W-H. Implementation of Artificial Intelligence for Classification of Frogs in Bioacoustics. Symmetry. 2019; 11(12):1454. https://doi.org/10.3390/sym11121454
Chicago/Turabian StyleChao, Kuo-Wei, Nian-Ze Hu, Yi-Chu Chao, Chin-Kai Su, and Wei-Hang Chiu. 2019. "Implementation of Artificial Intelligence for Classification of Frogs in Bioacoustics" Symmetry 11, no. 12: 1454. https://doi.org/10.3390/sym11121454