Measurement-Based Power Optimization Technique for OpenCV on Heterogeneous Multicore Processor


Abstract
:1. Introduction
2. Background
2.1. OpenCV
2.2. Genetic Algorithm (GA)
3. Proposed Optimization Technique
3.1. Optimization Part
| Algorithm 1 Procedure of GA for the DSE of the proposed technique. |
|
3.2. Measurement Part
| Algorithm 2 An OpenCV code modification example using the proposed technique for the canny edge detection application. |
|
4. Evaluations
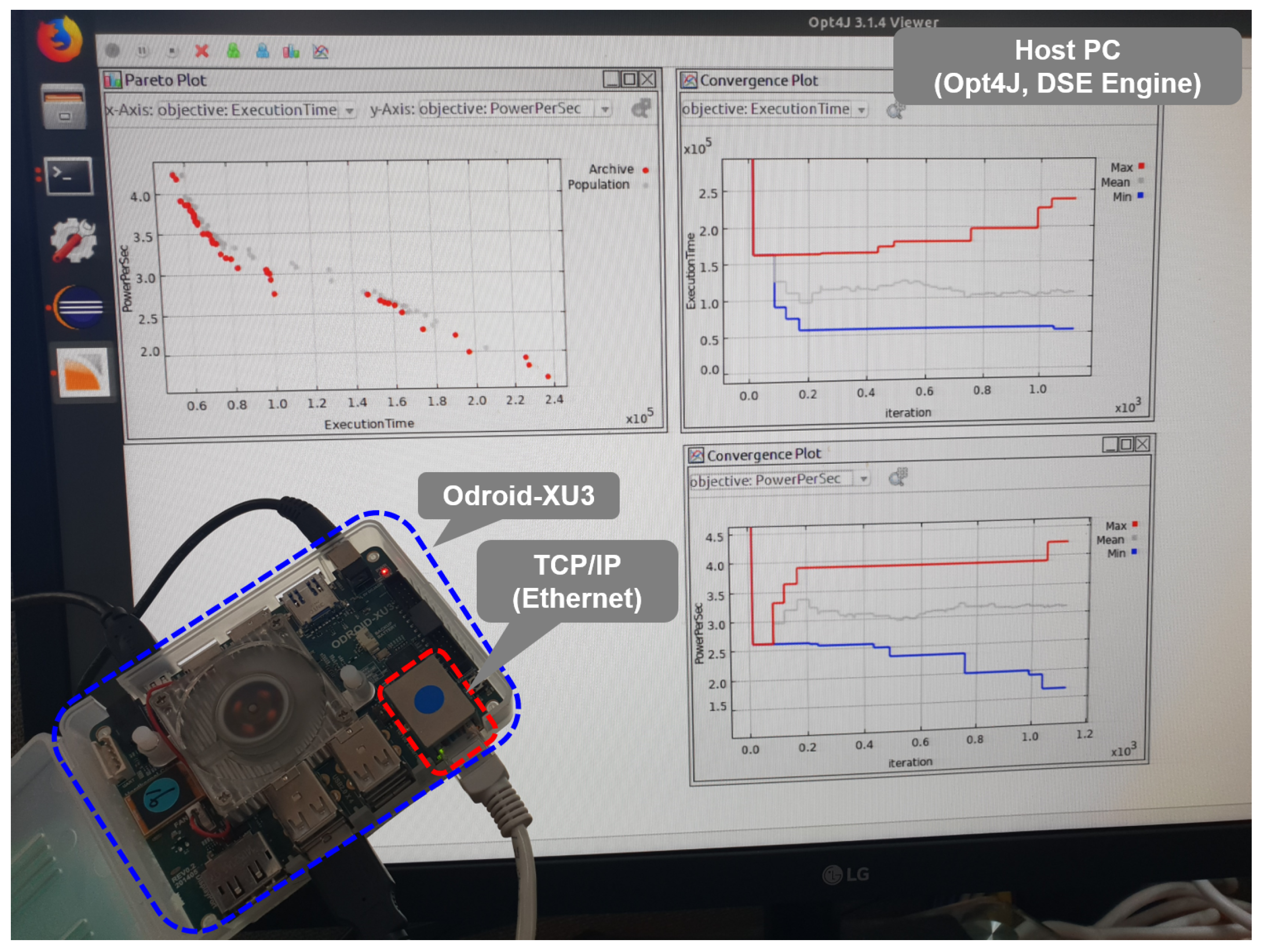
4.1. Experimental Setup
4.2. OpenCV Examples Used for Evaluation
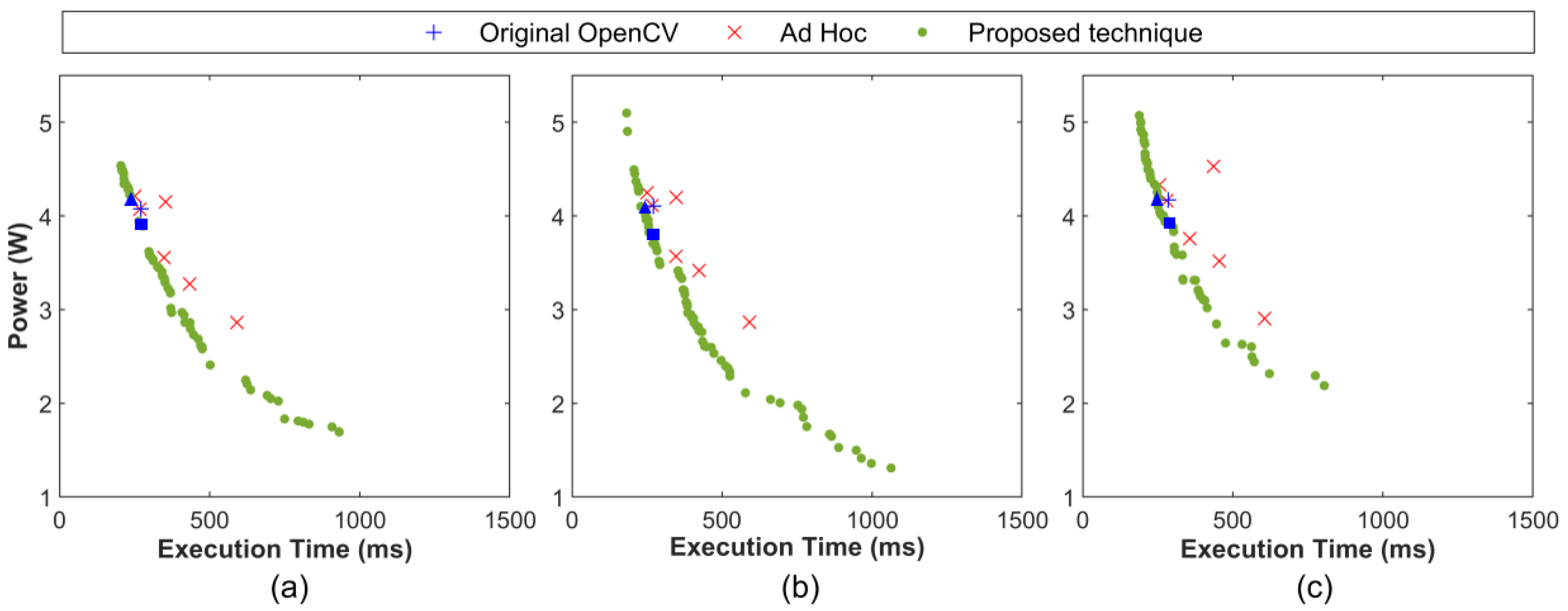
4.3. Latency-Power Co-Optimization of OpenCV Applications
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Ohya, I.; Kosaka, A.; Kak, A. Vision-based navigation by a mobile robot with obstacle avoidance using single-camera vision and ultrasonic sensing. IEEE Trans. Robot. Autom. 1998, 14, 969–978. [Google Scholar] [CrossRef]
- Omidyeganeh, M.; Shirmohammadi, S.; Abtahi, S.; Khurshid, A.; Farhan, M.; Scharcanski, J.; Hariri, B.; Laroche, D.; Martel, L. Yawning detection using embedded smart cameras. IEEE Trans. Instrum. Meas. 2016, 65, 570–582. [Google Scholar] [CrossRef]
- Giusti, A.; Guzzi, J.; Cireşan, D.C.; He, F.L.; Rodríguez, J.P.; Fontana, F.; Faessler, M.; Forster, C.; Schmidhuber, J.; Di Caro, G.; et al. A machine learning approach to visual perception of forest trails for mobile robots. IEEE Robot. Autom. Lett. 2015, 1, 661–667. [Google Scholar] [CrossRef] [Green Version]
- Soyata, T.; Muraleedharan, R.; Funai, C.; Kwon, M.; Heinzelman, W. Cloud-vision: Real-time face recognition using a mobile-cloudlet-cloud acceleration architecture. In Proceedings of the 2012 IEEE Symposium on Computers and Communications (ISCC), Cappadocia, Turkey, 1–4 July 2012; pp. 59–66. [Google Scholar]
- Levy, M.; Conte, T.M. Embedded multicore processors and systems. IEEE Micro 2009, 29, 7–9. [Google Scholar] [CrossRef]
- Singh, A.K.; Shafique, M.; Kumar, A.; Henkel, J. Mapping on multi/many-core systems: survey of current and emerging trends. In Proceedings of the 2013 50th ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 29 May–7 June 2013; pp. 1–10. [Google Scholar]
- Bhattacharyya, S.S.; Murthy, P.K.; Lee, E.A. Synthesis of embedded software from synchronous dataflow specifications. J. VLSI Signal Proces. Syst. Signal Image Video Technol. 1999, 21, 151–166. [Google Scholar] [CrossRef]
- Stefanov, T.; Zissulescu, C.; Turjan, A.; Kienhuis, B.; Deprettere, E. System design using Kahn process networks: the Compaan/Laura approach. In Proceedings of the Conference on Design, Sutomation and Test in Europe-Volume 1, Paris, France, 16–20 February 2004; IEEE Computer Society: Washington, DC, USA; p. 10340. [Google Scholar]
- Bradski, G. The OpenCV Library. Dr. Dobbs J. Softw. Tools 2000, 120, 122–125. [Google Scholar]
- Ng, T.E.; Chu, Y.H.; Rao, S.G.; Sripanidkulchai, K.; Zhang, H. Measurement-based optimization techniques for bandwidth-demanding peer-to-peer systems. In Proceedings of the IEEE INFOCOM 2003. Twenty-second Annual Joint Conference of the IEEE Computer and Communications Societies (IEEE Cat. No. 03CH37428), San Francisco, CA, USA, 30 March–3 April 2003; Volume 3, pp. 2199–2209. [Google Scholar]
- Rapita Systems Ltd. RapiTime. Available online: http://www.rapitasystems.com (accessed on 30 July 2019).
- Anuar, A.; Saipullah, K.M.; Ismail, N.A.; Soo, Y. OpenCV based real-time video processing using android smartphone. Int. J. Comput. Technol. Electron. Eng. (IJCTEE) 2011, 1, 58–63. [Google Scholar]
- Gurav, R.M.; Kadbe, P.K. Real time finger tracking and contour detection for gesture recognition using OpenCV. In Proceedings of the 2015 International Conference on Industrial Instrumentation and Control (ICIC), Pune, India, 28–30 May 2015; pp. 974–977. [Google Scholar]
- Li, D.; Liang, B.; Zhang, W. Real-time moving vehicle detection, tracking, and counting system implemented with OpenCV. In Proceedings of the 2014 4th IEEE International Conference on Information Science and Technology, Shenzhen, China, 26–28 April 2014; pp. 631–634. [Google Scholar]
- Pulli, K.; Baksheev, A.; Kornyakov, K.; Eruhimov, V. Real-time computer vision with OpenCV. Commun. ACM 2012, 55, 61–69. [Google Scholar] [CrossRef]
- Sung, H.W.; Chang, Y.M.; Wang, S.C.; Lee, J.K. OpenCV Optimization on Heterogeneous Multi-core Systems for Gesture Recognition Applications. In Proceedings of the 2016 45th International Conference on Parallel Processing Workshops (ICPPW), Philadelphia, PA, USA, 16–19 August 2016; pp. 59–65. [Google Scholar]
- Coombs, J.; Prabhu, R. OpenCV on TI’s DSP+ ARM® platforms: Mitigating the challenges of porting OpenCV to embedded platforms. Texas Instrum. 2011. Available online: https://www.embedded-vision.com/platinum-members/texas-instruments/embedded-vision-training/documents/pages/opencv-ti%E2%80%99s-dsparm%C2%AE-plat (accessed on 6 December 2019).
- Monson, J.; Wirthlin, M.; Hutchings, B.L. Implementing high-performance, low-power FPGA-based optical flow accelerators in C. In Proceedings of the 2013 IEEE 24th International Conference on Application-Specific Systems, Architectures and Processors, Washington, DC, USA, 5–7 June 2013; pp. 363–369. [Google Scholar]
- Pheatt, C. Intel® Threading Building Blocks. J. Comput. Sci. Coll. 2008, 23, 298. [Google Scholar]
- Dagum, L.; Menon, R. OpenMP: An Industry-Standard API for Shared-Memory Programming. IEEE Comput. Sci. Eng. 1998, 5, 46–55. [Google Scholar] [CrossRef] [Green Version]
- Martorell, X.; Ayguadé, E.; Navarro, N.; Corbalán, J.; González, M.; Labarta, J. Thread fork/join techniques for multi-level parallelism exploitation in NUMA multiprocessors. In Proceedings of the 13th International Conference on Supercomputing, Rhodes, Greece, 20–25 June 1999; Volume 20, pp. 294–301. [Google Scholar]
- Amer, A.; Maruyama, N.; Pericàs, M.; Taura, K.; Yokota, R.; Matsuoka, S. Fork-join and data-driven execution models on multi-core architectures: Case study of the FMM. In Proceedings of the 2013 28th International Supercomputing Conference, Berlin, Germany, 16–20 June 2013; pp. 255–266. [Google Scholar]
- Shafer, J.; Rixner, S.; Cox, A.L. The hadoop distributed filesystem: Balancing portability and performance. In Proceedings of the 2010 IEEE International Symposium on Performance Analysis of Systems & Software (ISPASS 2010), White Plains, NY, USA, 28–30 March 2010; pp. 122–133. [Google Scholar]
- Hornby, G.; Globus, A.; Linden, D.; Lohn, J. Automated antenna design with evolutionary algorithms. In Proceedings of the Space 2006, San Jose, CA, USA, 19–21 September 2006; p. 7242. [Google Scholar]
- Nakaya, S.; Koide, T.; Wakabayashi, S. An adaptive genetic algorithm for VLSI floorplanning based on sequence-pair. In Proceedings of the 2000 IEEE International Symposium on Circuits and Systems. Emerging Technologies for the 21st Century. Proceedings (IEEE Cat No. 00CH36353), Geneva, Switzerland, 28–31 May 2000; Volume 3, pp. 65–68. [Google Scholar]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the strength Pareto evolutionary algorithm. TIK-Rep. 2001, 103. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Kang, S.H.; Yang, H.; Schor, L.; Bacivarov, I.; Ha, S.; Thiele, L. Multi-objective mapping optimization via problem decomposition for many-core systems. In Proceedings of the 2012 IEEE 10th Symposium on Embedded Systems for Real-Rime Multimedia, Tampere, Finland, 11–12 October 2012; pp. 28–37. [Google Scholar]
- Lukasiewycz, M.; Glaß, M.; Reimann, F.; Teich, J. Opt4J—A Modular Framework for Meta-heuristic Optimization. In Proceedings of the Genetic and Evolutionary Computing Conference (GECCO 2011), Dublin, Ireland, 12–16 July 2011; pp. 1723–1730. [Google Scholar]
- Hardkernel. Odroid-XU3. Available online: https://www.hardkernel.com/shop/odroid-xu3 (accessed on 30 July 2019).
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Kim, C.; Hwang, J.N. Fast and automatic video object segmentation and tracking for content-based applications. IEEE Trans. Circuits Syst. Video Technol. 2002, 12, 122–129. [Google Scholar]
- Al-Jarrah, R.; Al-Jarrah, M.; Roth, H. A novel edge detection algorithm for mobile robot path planning. J. Robot. 2018, 2018, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. arXiv 2014, arXiv:1408.5093. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition CVPR09, Miami Beach, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. Squeezeseg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3d lidar point cloud. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–26 May 2018; pp. 1887–1893. [Google Scholar]
- Treml, M.; Arjona-Medina, J.; Unterthiner, T.; Durgesh, R.; Friedmann, F.; Schuberth, P.; Mayr, A.; Heusel, M.; Hofmarcher, M.; Widrich, M.; et al. Speeding up semantic segmentation for autonomous driving. In Proceedings of the MLLITS, NIPS Workshop, Barcelona, Spain, 5–10 December 2016. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| API Types | API Names | Functionalities |
|---|---|---|
| TransmissionManager | send() | Transfer power and execution time to the host PC |
| receive() | Receive P and from the host PC | |
| ParallelConfiguration | setEnable() | Turn on or off the measurement mode for openCV |
| getEnable() | Check if the measurement mode is on or not | |
| set() | Apply the configuration of P to the target parallel function | |
| MeasurementUnit | start()/stop() | Set the starting and end point of the measurement |
| getProfiling() | Obtain the measured power consumption and execution time | |
| getProfilingStatistics() | Obtain the statistics value for the given value |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, H.; Koo, K.; Yang, H. Measurement-Based Power Optimization Technique for OpenCV on Heterogeneous Multicore Processor. Symmetry 2019, 11, 1488. https://doi.org/10.3390/sym11121488
Jung H, Koo K, Yang H. Measurement-Based Power Optimization Technique for OpenCV on Heterogeneous Multicore Processor. Symmetry. 2019; 11(12):1488. https://doi.org/10.3390/sym11121488
Chicago/Turabian StyleJung, Hyeonseok, Kyoseung Koo, and Hoeseok Yang. 2019. "Measurement-Based Power Optimization Technique for OpenCV on Heterogeneous Multicore Processor" Symmetry 11, no. 12: 1488. https://doi.org/10.3390/sym11121488