In this section, the video-coding-efficiency improvement algorithm is described. Firstly, in order to generate a more accurate motion-vector predictor, the spatial correlations-based MVP algorithm is presented to improve encoding efficiency. Then, the spatial correlations-based CU depth-prediction algorithm is proposed to reduce computation complexity. It is noted that, in H.265/HEVC, normal mode and merge/skip mode have different methods for MVP. In the proposed approach, the method is common.
3.1. Definition of Spatial-Neighborhood Set
Considering video content with strong spatial correlations, the motion-vector predictor of the current PU for intercoded CU can be generated by the surrounding PUs. Moreover, the depth level of the current CU can be predicted from neighboring CUs where there is a similar texture or there are continuous motions.
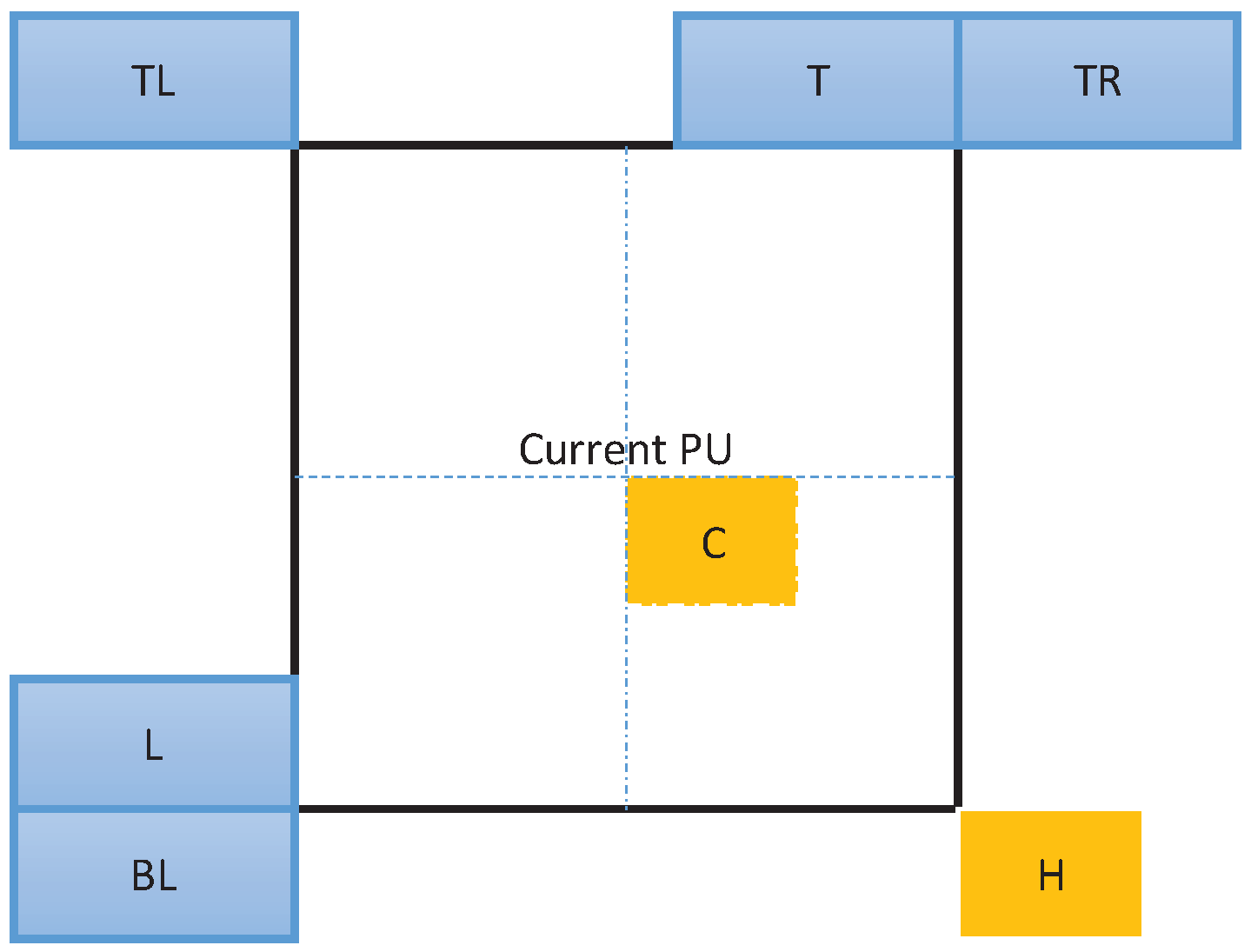
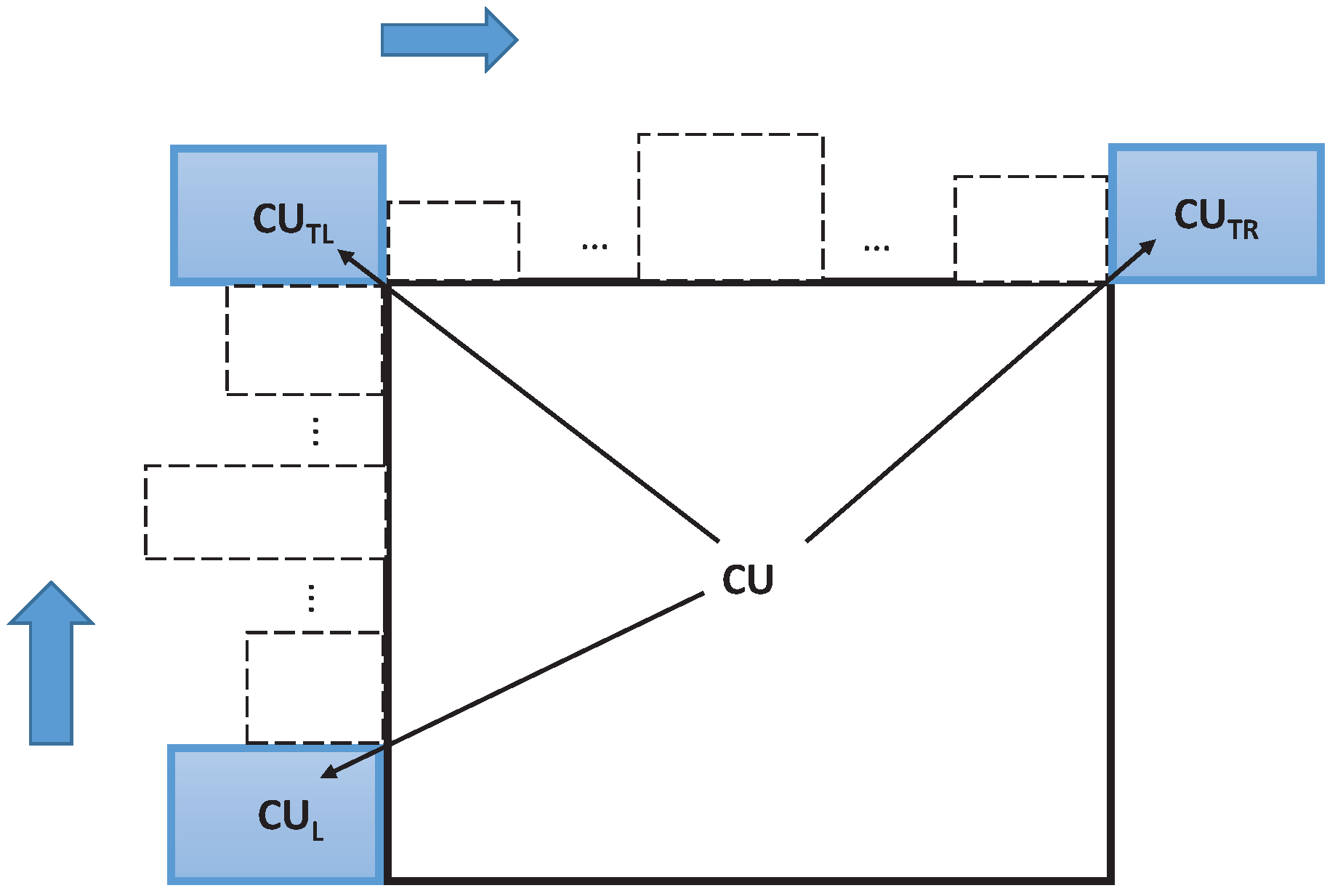
Different from fixed-pattern AMVP technology, spatial neighborhood set
G is composed of all spatial neighborhood CUs. Set
G is shown in
Figure 3, where
,
and
denote the left, top-right, and top-left CU of the current CU, respectively. Set
G is defined as
On the one hand, the MVs and depth information of
G can be used to predict the MVP and depth level of the current CU. CU contains one, two, or four PUs depending on partition mode, and each PU contains MV information. For set
G, the surrounding PU directly connected with the current PU is selected in this work. Furthermore, the minimum surrounding PU size is set to
, because the MVs of the
and
surrounding PUs are not regular, and the significance of reference is small for MV prediction. On the other hand, computation complexity is high by checking all information. Therefore, a relatively reliable subset should be developed for the MVP and depth prediction. In order to utilize the spatial correlation, subset
M is defined as
where subset
M is contained in set
G (
). The basic idea of the spatial-correlation method is to prejudge the MVP and depth of the current CU according to the MVs and depths of adjacent CUs. When subset
M is available, the information of
M is used to predict the MVP and depth of the current CU. In contrast, when subset
M is unavailable, which means that none of spatial neighborhood CUs (
) exist, the information of
G is used to predict the MVP and depth of the current CU.
In this work, the spatial correlation-based method consists of two parts: a motion-vector-prediction algorithm and CU depth-prediction algorithm. Firstly, the MVP can be selected by exploiting the spatial correlation of neighboring PUs. When there is motion consistency of the neighboring PUs, a simple MV can be selected as the optimized MV for the current PU. Otherwise, more MVs of neighboring PUs can be checked to select the optimized MV. Secondly, the depth level of the current CU can be predicted by exploiting the spatial correlation of neighboring CUs. When the texture complexity of neighboring CUs tends to simple, the content of texture of the current CU tends to be not complex. On the contrary, the texture complexity of neighboring CUs tends to be complex, and the texture content of the current CU tends to be not simple.
3.2. Spatial Correlation-Based Motion-Vector-Prediction Algorithm
The performance of motion estimation highly depends on the MVP [
13,
14,
15,
16]. If the MVP is close to the calculated MV, the MVD between the MVP and the calculated MV is small, and the MVP is more accurate. However, in the H.265/HEVC standard, a total of seven spatial and temporal MVs are added to the candidate list to predict the MVP. There are two disadvantages to the current AMVP mechanism in H.265/HEVC [
17]. For one thing, the number of reference MVs is limited. For another, a fixed selecting pattern is not adaptive to selecting reference MVs; therefore, it is not generating an accurate MVP by using the current AMVP mechanism. In order to further improve encoding efficiency, more reference MVs can be added to the candidate list. Owing to spatial and temporal motion consistency, the MVs surrounding the current PU are useful for determining the MVP. However, too many MVP candidates may cause a large number of calculations, so it is necessary to reduce the calculation redundancy of the MVP decision.
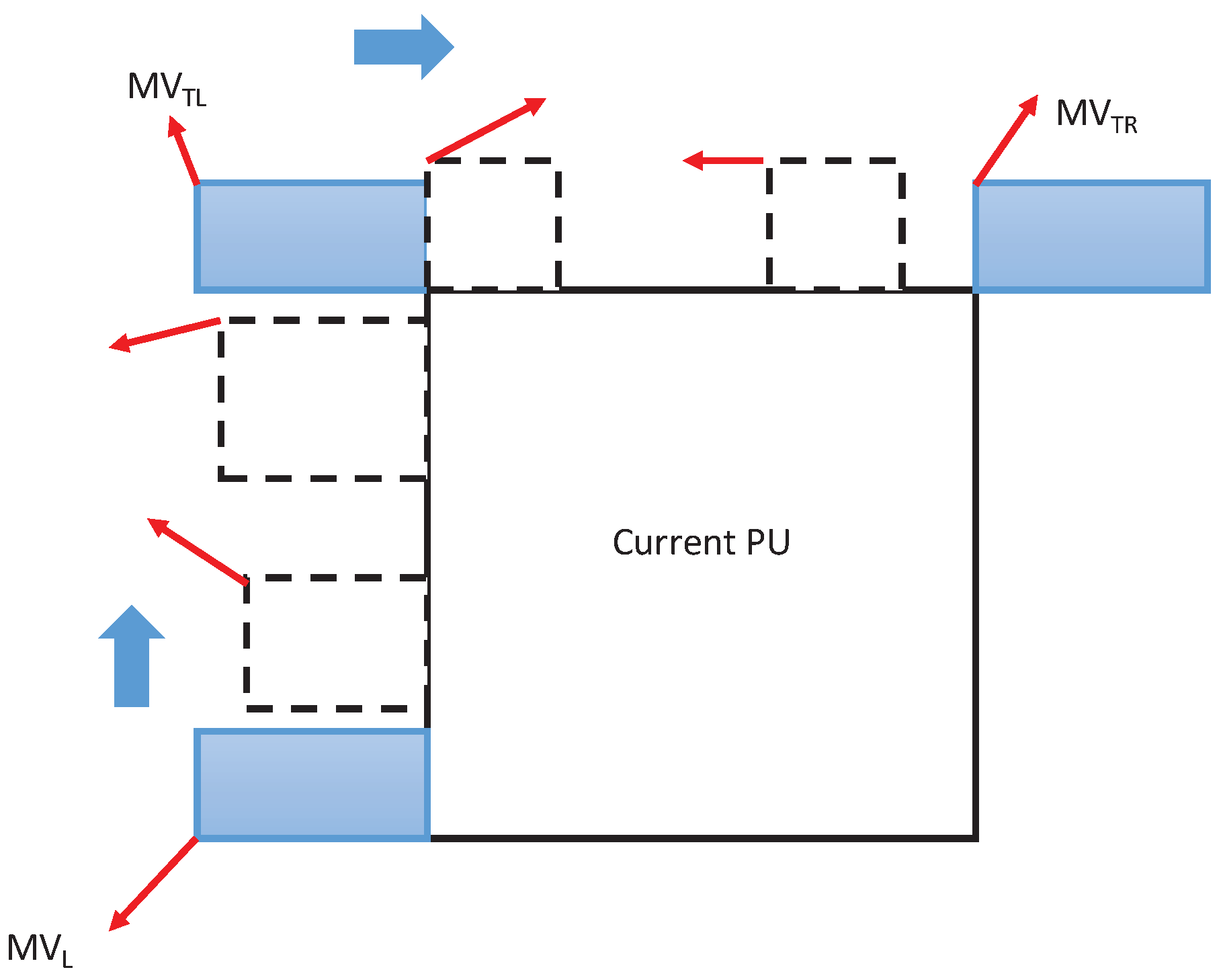
Based on the above-mentioned views, the reference MVs of the current PU can be used to search for an accurate MVP. In neighborhood subset
M, the MVs of the neighboring CUs are shown in
Figure 4, where
,
and
indicate the MV candidates in the left, top right, and top left of the current PU, respectively. In H.265/HEVC, the simplified rate-distortion optimization (RDO) method is performed to estimate the motion vector [
12]. In the RDO process, the rate-distortion cost (RD-cost) function (
) is minimized by the encoder, where
is the Lagrange multiplier,
represents the distortion between the original block and reference block, and
represents the number of coding bits. The MVD between the MVP and the calculated MV is also signalled in the
.
For the different texture of video content, the reliability of candidate MVs can be evaluated by the MVs of spatial neighborhood subset
M: {
,
,
}. When these three MVs are equal, the MVs of adjacent CUs tend to the same direction. In this case, the reliability of candidate MVs is the highest, and a simple MV can be selected as the final MVP. That is, reference MVs satisfy as
Then,
is selected as the optimized MVP.
Furthermore, when the MV absolute difference of
and
is more than the MV absolute difference of
and
, motion consistency in the top of PU is lower than motion consistency to the left of PU. In this case, the reliability of the MVs in the left of PU is higher than the reliability of the MVs in the top of PU. Otherwise, the reliability of the MVs in the top of PU is higher than the reliability of the MVs in the left of PU. Thus, when reference MVs satisfy as
the MVP position tends to the left of PU. Then,
and
are selected as MVP candidates. Otherwise, the MVP position tends to the top of PU, and
and
are selected as MVP candidates.
When the MVs of subset M are not available, the reliability of candidate MVs is the lowest in the spatial domain, and it is hard to obtain an accurate MVP by using the fixed AMVP mechanism. In this case, the MVP position may tend to the left of PU, and it is also possible to tend to the top of PU. Therefore, all available MVs of spatial neighborhood set G need to be checked. In order to obtain a more accurate MVP, all surrounding MVs of G can be added to the candidate MVs, and the cost of these MVs is checked to obtain an optimized MVP by comparing one with a method. When all components of G are not available, MV (0, 0) is added to the candidate list, which is the same as that in H.265/HEVC.
It is noted that the encoder codes
for indicating the number of coded bits for the MVP candidates. Different from the H.265/HEVC standard, in this work, the indicating method for the codec is that
is designed as a variable-length code, and the length of
is expressed as
L. The relationship between the coded bits of
and MVP is shown as in
Table 1. When M is available, the length of
satisfies
. However, when M is not available, the maximum value of
L with a different PU size is shown in
Table 2.
It can be seen from
Table 2 that, when the current PU size is equal to
, the maximum value of
can be calculated as follows: (1) if the smaller surrounding PU size is
, the number of coded bits that need to index the MVP candidates is
. Thus, the length of
satisfies
L = 4 bit. (2) if the smaller surrounding PU size is
, the number of coded bits that need to index the MVP candidates is
. Thus, the length of
satisfies
L = 3 bit. (3) if the smaller surrounding PU size is
, the number of coded bits that need to index the MVP candidates is
. Thus, the length of
satisfies
L = 2 bit. (4) If both surrounding PUs are
in size, the number of coded bits that need to index the MVP candidates is
. Thus, the length of
satisfies
L = 1 bit. In this case, the maximum-value length of
satisfies
L = 4 bit. Moreover, in order to clearly specify the length of
,
Figure 5 shows the length range of
with
PU size. For others PU size (
,
,
,
,
, and
), the maximum value length of
satisfies
L = 4 bit. Similarly, when the current PU size is equal to
, the maximum value of
satisfies
L = 3 bit. When the current PU size is equal to
, the maximum value of
satisfies
L= 2 bit. When the current PU size is equal to
, and the smaller surrounding PU size is
, the number of coded bits that need to index the MVP candidates is
. In this case, the length of
satisfies
L = 1 bit.
In H.265/HEVC standards, the distribution of the selected spatial-motion candidates is far greater than the distribution of the temporal-motion candidates [
4]. In this work, the more-available spatial candidates are used to decide the MVP, and the temporal-motion candidates have little overall effect on coding efficiency. Thus, the temporal-motion candidates have been removed in the proposed method.
As per the aforementioned approaches, the spatial correlation-based motion-vector-prediction selection algorithm for interprediction is shown in Algorithm 1. Firstly, the MVP candidate list is established by using the proposed spatial-neighborhood motion vector. After that, the rate-distortion-optimal MVP is generated by executing motion estimation in the MVP candidate list, which is the search center to search for the optimal MV. Motion estimation (ME) is the process of determining a motion vector by using a block-matching algorithm [
18], which is regarded as a time-consuming process. There are two advantages of this proposed method: (1) MVP accuracy was improved with the proposed method. Thus, the MVD of the current PU becomes smaller for InterMode. The length of
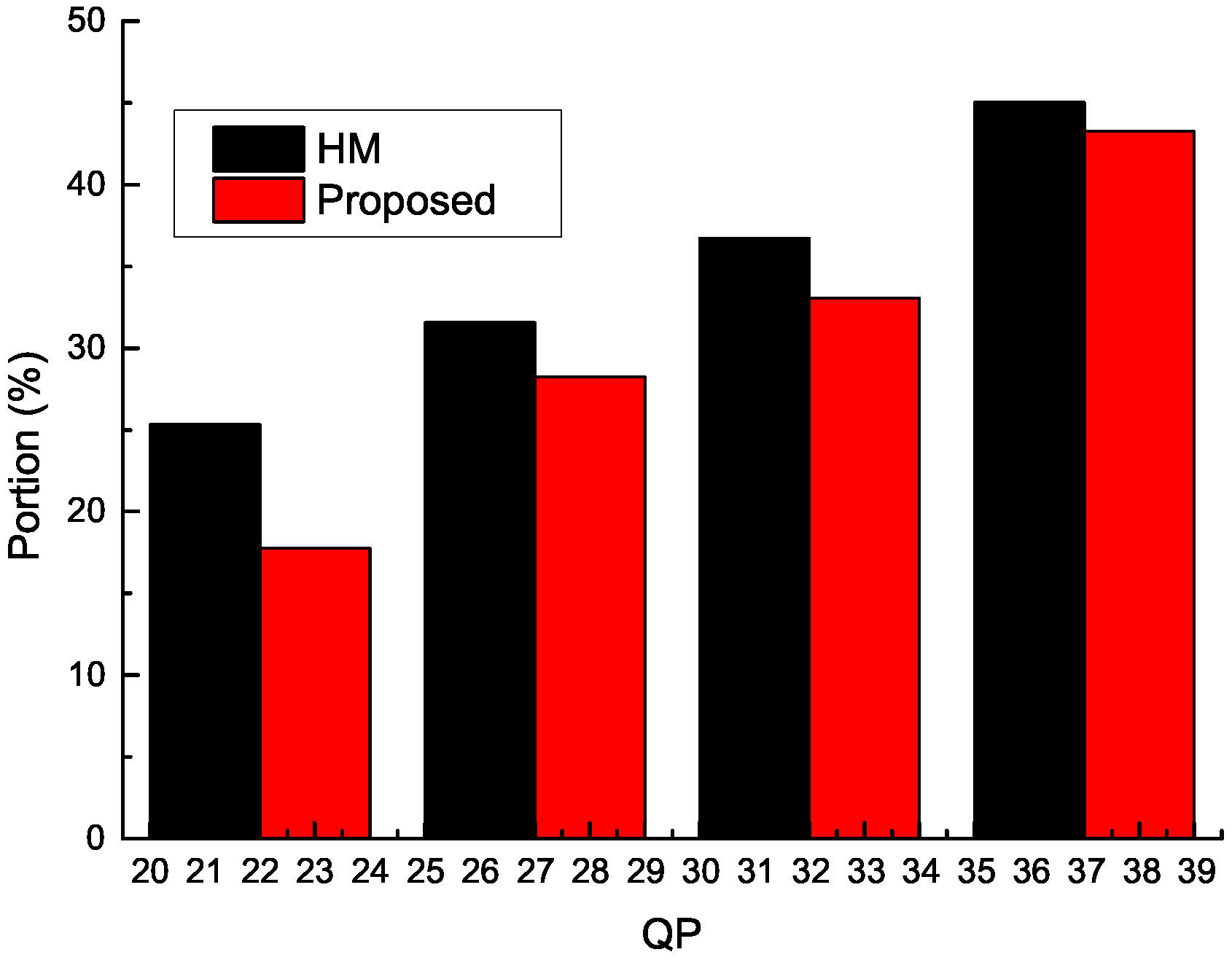
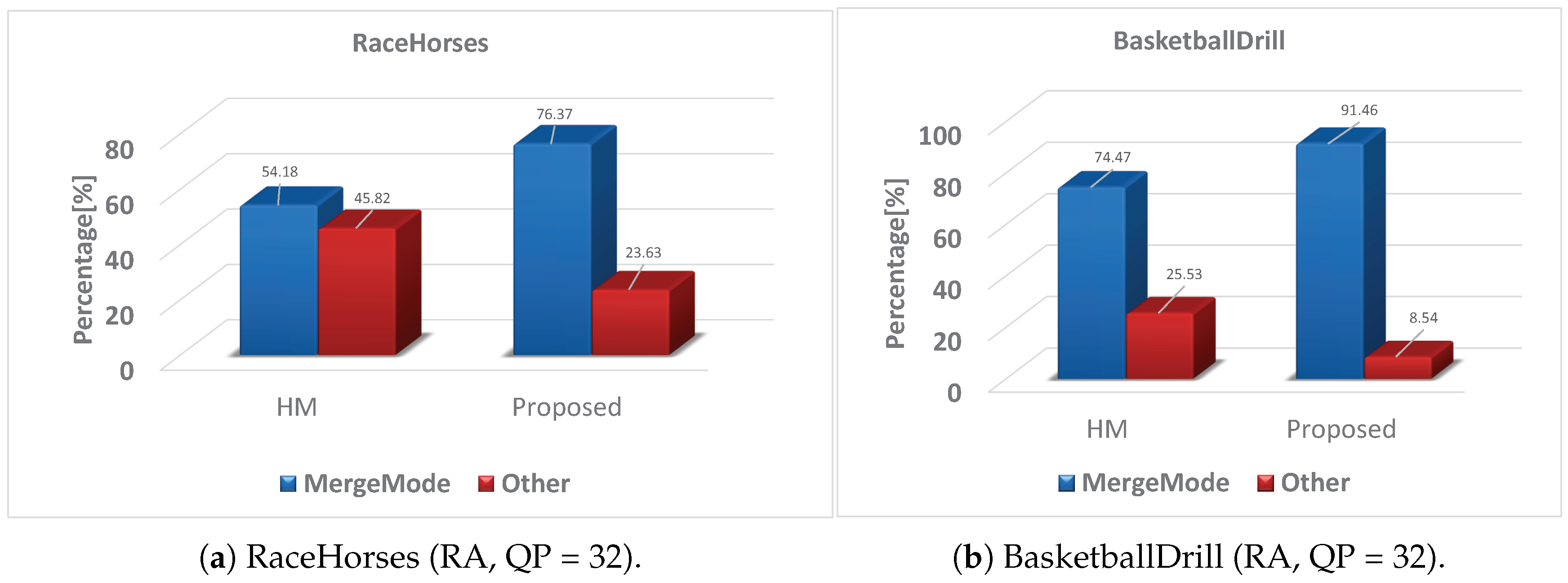
is variable. (2) Using the proposed method, the possibility that the MV and MVP of the current PU are consistent increased, and the probability that CU selects MergeMode increased. In the case when MVD is equal to zero, the majority of CUs select MergeMode. Therefore, by using the proposed algorithm, the effect of the proposed method (MVD becoming zero) and the effect of MergeMode overlap. The length of
from the merge candidate list in MergeMode is fixed, which is the same as the definition in H.265/HEVC standards. As a result, the proposed algorithm can significantly reduce the amount of bits.
| Algorithm 1: Spatial correlation-based MVP algorithm. |
![Symmetry 11 00129 i001]() |
The main idea of this work is the sacrifice of computational complexity for higher coding efficiency. Thus, more MVs surrounding the current PU are added to the MV candidate list by the proposed method; therefore, most computational cost in this work is to search for an accurate MVP with the RDO process.
3.3. Spatial Correlation-Based CU Depth-Prediction Algorithm
The above spatial correlation-based MVP algorithm can significantly improve coding efficiency, while computation complexity is increased by a lot. There are quite a few related works that can reduce computation complexity [
13,
14,
19]. However, three important issues are carefully considered to design the conditions. Firstly, arithmetic-complexity reduction is the design motivation. Secondly, the robustness of the design condition is higher. Thirdly, owing to high availability, depth information should be used. In this paper, a spatial correlation-based CU depth-prediction algorithm is presented. In order to evaluate depth-level prediction, several experiments were performed on different conditions with different configurations. In the experiments, the accuracy rate when the predicted depth level was equal to the depth level selected by the original H.265/HEVC test model was verified.
Generally, the texture complexity of image content is directly related to the depth of the image. When the depth range of the CU is higher, the texture complexity of the CU tends to be complex. On the contrary, when CU depth range is lower, CU texture complexity tends to be simple. Based on CU depth, CU texture complexity (
) is classified into simple or complex as
where
represents the texture complexity of a CU.
D is the maximal depth of the
in the motion-estimation processing, and default value
D is set to 3 in H.265/HEVC reference software.
In this verification, the test conditions have to be carefully designed. It is clear that when the
of the left neighboring
, the top-right neighboring
, and the top-left neighboring
are simple, the
of the current CU tends to be not complex. On the contrary, when the
of the left neighboring
, the top-right neighboring
, and the top-left neighboring
are complex, the
of the current CU tends to be not simple. Thus, based on the above conclusions, two conditions (C1 and C2) are proposed as follows:
where
,
,
, and
are the maximal depth of
,
,
, and the current CU, respectively.
In order to verify the accuracy of the two conditions, accuracy rate
is defined as
while
represents the number of correct-matching test cases by using the depth of the neighboring CUs to predict the depth of the current CU, and
N represents the total number of test cases. In this work, four typical sequences (PeopleOnStreet, BasketballDrill, BQSquare, Vidyo1) were applied to test with low-delay (LD) and random-access (RA) profiles. From the results of
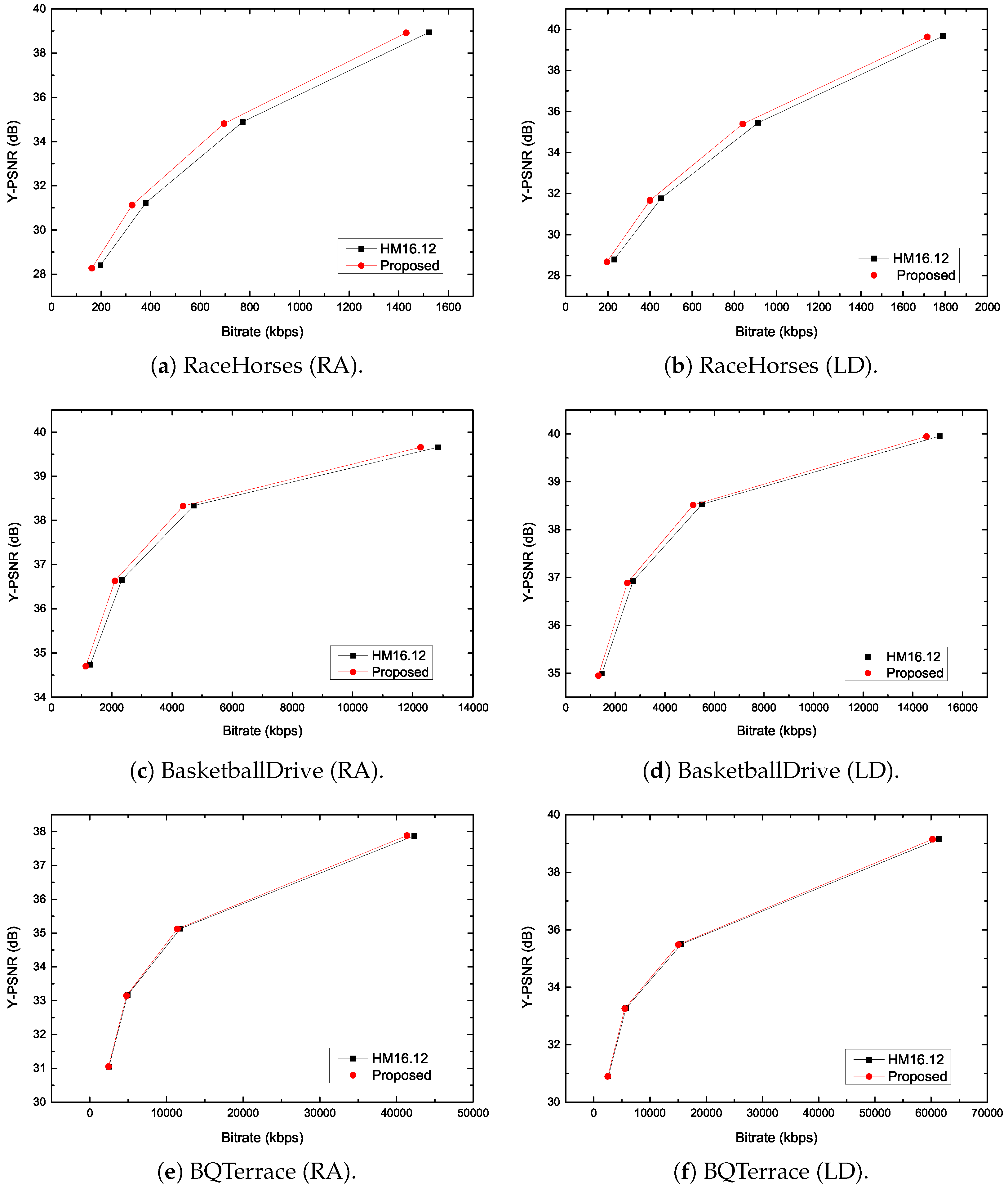
Table 3, the rates of Condition 1 and Condition 2 are about 99% and 93%, respectively. That is, the depth of
,
, and
has strong spatial correlation with the depth of the current CU. Thus, it is high availability to predict the depth of the current CU by utilizing the depth of the neighboring CUs.
Hence, the spatial correlation-based CU depth-prediction algorithm for interprediction is shown in Algorithm 2. Firstly, the predicted depth range of the current CU is determined by the depth of the neighboring CUs. Secondly, the RD-cost of the current CU is checked in the predicted depth range. The advantage of this method is simple and easy to achieve. Moreover, the robustness of this method is high.
| Algorithm 2: Spatial correlation-based CU depth-prediction algorithm. |
![Symmetry 11 00129 i002]() |
3.4. Overall Algorithm
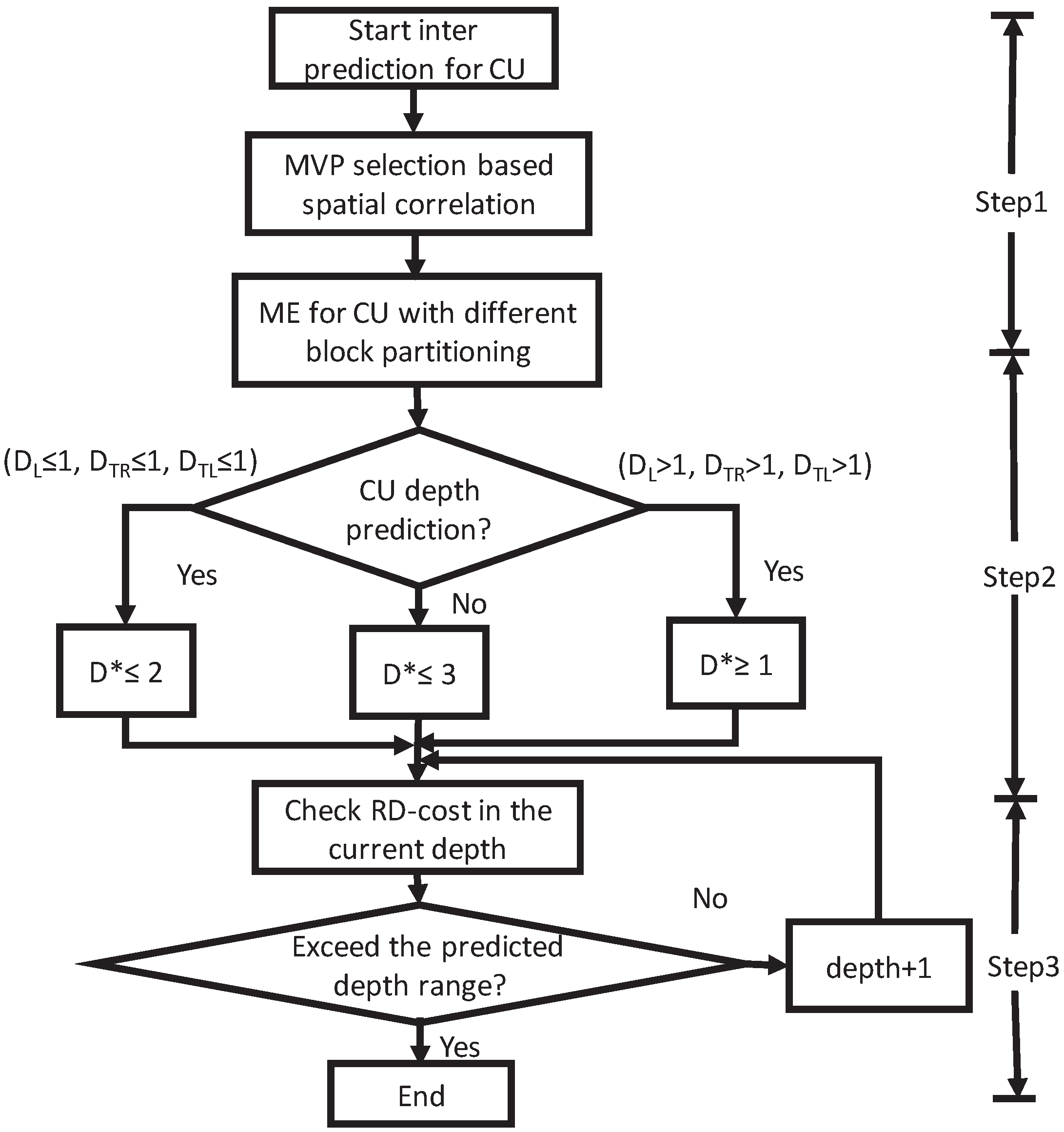
Based on the spatial-correlation model, the MVs of the neighboring PUs are used to obtain the optimized MVP. This method can improve coding efficiency, while computation complexity is increased by a lot. In order to achieve a better trade-off between coding efficiency and computation complexity, by jointing CU depth prediction, the overall algorithm can significantly improve coding performance. The flowchart of the overall algorithm is shown in
Figure 6, which can be divided into three distinctive steps, as follows:
Step 1: spatial correlation-based motion-vector prediction.
The MVP is selected by using the spatial-correlation model for interprediction. Firstly, If = = , is selected as the optimized MVP. Secondly, If > , and are added to the candidates. Otherwise, and are added to the candidates. Lastly, If , , and are invalid, All MVs surrounding the current PU are added to the candidates, and the redundant MVP candidate can be reduced by comparing one with one. Executing motion estimation is to determine the rate-distortion-optimal MVP.
Step 2: spatial correlation-based CU depth prediction.
Start depth prediction with the RDO method for a CU with different block partitioning. If the maximal depths of , , and are less than or equal to 1, the predicted depth range of the current CU is 0, 1, and 2. Else, if the maximal depths of , , and are more than 1, the predicted depth range of the current CU is 1, 2, and 3. Otherwise, the predicted depth range of the current CU is 0, 1, 2, and 3.
Step 3: If the current depth of the CU exceeds the predicted depth range, RD-cost computation is stopped. Otherwise, depth is incremented by 1 and recursively checks the RD-cost in the current depth.
It should be pointed out that the overall algorithm is a recursive process, and spatial correlation-based CU depth prediction is not applied to intra.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}