Handling Semantic Complexity of Big Data using Machine Learning and RDF Ontology Model


Abstract
:1. Introduction
2. Related Work
3. EM-Based Classification of RDF Model Elements
4. Used Approach
4.1. Bag of Words Representation
4.2. Sparse Representation
4.3. Feature Vectorisation
| >>> from sklearn.feature extraction.textimport Count Vectorizer |
| >>>vectorizer = CountVectorizer(min_df = 1) >>>vectorizer CountVectorizer(analyzer = …’word’, binary = False, charset = None, charset_error = None, decode_error =…’strict’, dtype = <…‘numpy.int64’>, encoding =…’utf-8’, input =…’content’, lowercase = True, max_df = 1.0, max_features=None, min_df = 1, ngram_range = (1,1), preprocessor = None, stop_words = None, strip_accents = None, token_pattern =…’(?u)\\b\\w\\w+\\b’, tokenizer = None, vocabulary = None) |
| >>>corpus = [ … ‘This is the first example.’, … ‘This is the second example.’, … ‘And the third one.’, … ‘Is this the first example?’, … ] >>> X = vectorizer.fit_transform(corpus) >>> X <4x9 sparse matrix of type ‘<… ‘numpy.int64’>’ with 19 stored elements in Compressed Sparse … format> |
| >>>analyze = vectorizer.build_analyzer() >>>analyze(“This is a text example to vectorized.”) == ( … [‘this’,’is’,’text’,’example’,’to’,’vectorized’]) True |
| >>>vectorizer.get_feature_names() == ( ... [‘and’,’document’,’first’,’is’,’one’, ... ‘second’,’the’,’third’,’this’]) True >>>X.toarray() array ([[0, 1, 1, 1, 0, 0, 1, 0, 1], [0, 1, 0, 1, 0, 2, 1, 0, 1], [1, 0, 0, 0, 1, 0, 1, 1, 0], [0, 1, 1, 1, 0, 0, 1, 0, 1]]...) |
| >>>vectorizer.transform([‘For new example.’]).toarray() ... array ([[0, 0, 0, 0, 0, 0, 0, 0, 0]]...) |
| >>>bigram_vectorizer = CountVectorizer (ngram_range = (1,2), ... token_pattern = r’\b\w+\b’, min_df = 1) >>>analyze = bigram_vectorizer.build_analyzer() >>>analyze(‘Bi-grams are cool!’) == ( ... [‘bi’,’grams’,’are’,’cool’,’bigrams’,’gramsare’,’are cool’]) True |
| >>>X_2 = bigram_vectorizer.fit_transform(corpus).toarray() >>>X_2 … array([[0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0], [0, 0, 1, 0, 0, 1, 1, 0, 0, 2, 1, 1, 1, 0, 1, 0, 0, 0, 1, 1, 0], [1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0], [0, 0, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1]]…) |
| >>>feature_index = bigram_vectorizer.vocabulary_.get(‘is this’) >>>X_2[:,feature_index] |
4.4. Term Weighting
| >>>fromsklearn.feature_extraction.textimportTfidfTransformer >>>transformer = TfidfTranformer() >>>transformer TfidfTransformer(norm =…’12’, smooth_idf = True, sublinear_tf = False, use_idf = True) |
| >>>counts=[[3,0,1], … [2,0,0], … [3,0,0], … [4,0,0], … [3,2,0], … [3,0,2], … >>>tfidf=transformer.fit_transform(counts) >>>tfidf <6x3 sparse matrix of type ‘<… ‘numpy.float64’>’ With 9 stored elements in Compressed sparse … format> >>>tfidf.toarray() array([[ 0.85…, 0. …, 0.52…], [ 1. …, 0. …, 0. …], [ 1. …, 0. …, 0. …], [ 1. …, 0. …, 0. …], [ 0.55…, 0.83…, 0. …], [ 0.63…, 0. …, 0.77…]]) |
4.5. Vocabulary Classification to RDF
4.6. RDF Model Modelling using Jena
| public static void main(String[[] args) { // TODO Auto-generated method stub // some definitions String personURI = “http://somewhere/Islamia University”; String fistName = “Islamia”; String SecondName = “University”; String fullName = firstName + “” + secondName; // create the resource // and add the properties cascading style Resource IslamiaUniversity = model.createResource(personURI) .addProperty(VCARD.FN, fullName).addProperty(VCARD.N, model.createResource().addProperty(VCARD.Given, firstName) . addProperty(VCARD.Family, secondName)); //johsmith.addProperty(p, “hello world”, XSDDatatype.XSDstring); Model.write(System.out, “Trutle”); |
| <http://somewhere/Islmia University> <http://www.w3.org/2001/vcard-rdf/3.0#FN> “Islamia University”; <http://www.w3.org/2001/vcard-rdf/3.0#Name> [ <http://www.w3.org/2001/vcard-rdf/3.0#firstName> Islamia <http://www.w3.org/2001/vcard-rdf/3.0#secondName> University ] |
5. Experiments and Results
| It is obligatory that the system shall let, each Patron who is logged into the Cafeteria Ordering System, place at least one order for at least one or more meals. |
| It is obligatory that the system shall confirm that the ‘Patron’ is registered for payroll deduction to place at least one order. |
| If the Patron is not registered for payroll deduction, It is obligatory that the system shall give the Patron options to register and continue placing at least one order, to place at least one order for pickup in the cafeteria, or to exit from the COS. |
| It is obligatoy the system shall prompt the Patron for the meal date. |
| If the meal date is the current date and the current time is after the order cutoff time, it is obligatory that the system shall inform the Patron that it’s too late to place at least one order for today. |
| It is possibility that the Patron may change the meal date or cancel the order. |
| It is obligatory the Patron shall specify whether the order is to be picked or delivered. |
| If the order is to be delivered and there still are available delivery times for the meal date, it is obligatory that the Patron shall provide at least one valid delivery location. |
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tadikonda, V.; Rosca, D. Informed and Timely Business Decisions-A Data-driven Approach. In Proceedings of the SEKE, San Francisco, CA, USA, 1–3 July 2016; pp. 24–30. [Google Scholar]
- OMG. Semantics of Business Vocabulary and Business Rules (SBVR), Version 1.4. May 2017. Available online: https://www.omg.org/spec/SBVR (accessed on 11 July 2018).
- Bajwa, I.S.; Lee, M.G.; Bordbar, B. SBVR Business Rules Generation from Natural Language Specification. In Proceedings of the AAAI Spring Symposium: AI for Business Agility, Palo Alto, CA, USA, 23 March 2011; pp. 2–8. [Google Scholar]
- Grover, V.; Chiang, R.H.; Liang, T.P.; Zhang, D. Creating Strategic Value from Big Data Analytics: A Research Framework. J. Manag. Inf. Syst. 2018, 35, 388–423. [Google Scholar] [CrossRef]
- Carroll, J.; Herman, I.; Patel-Schneider, P.F. OWL 2 Web Ontology Language RDF-Based Semantics; W3C Recommendation; Available online: https://www.w3.org/TR/owl2-rdf-based-semantics/ (accessed on 13 August 2018).
- Čebirić, Š.; Goasdoué, F.; Manolescu, I. Query-oriented summarization of RDF graphs. Proc. VLDB Endow. 2015, 8, 2012–2015. [Google Scholar]
- Ceravolo, P.; Fugazza, C.; Leida, M. Modeling semantics of business rules. In Proceedings of the Inaugural IEEE-IES Digital EcoSystems and Technologies Conference, 2007 (DEST’07), Cairns, Australia, 21–23 February 2007; pp. 171–176. [Google Scholar]
- Choksi, A.T.; Jinwala, D.C. A Novel Way to Relate Ontology Classes. Sci. World J. 2015, 1, 724196. [Google Scholar] [CrossRef] [PubMed]
- Corcho, O.; Fernández-López, M.; Gómez-Pérez, A. Methodologies, tools and languages for building ontologies. Where is their meeting point? Data Knowl. Eng. 2003, 46, 41–64. [Google Scholar] [CrossRef] [Green Version]
- Dai, W.; Xue, G.R.; Yang, Q.; Yu, Y. Transferring naive bayes classifiers for text classification. In Proceedings of the National Conference on Artificial Intelligence, Vancouver, BC, Canada, 22–26 July 2007; AAAI Press: Menlo Park, CA, USA; Cambridge, MA, USA; London, UK, 1999; Volume 22, p. 540. [Google Scholar]
- Ferreira, R.; de Souza Cabral, L.; Lins, R.D.; e Silva, G.P.; Freitas, F.; Cavalcanti, G.D.; Lima, R.; Simske, S.J.; Favaro, L. Assessing sentence scoring techniques for extractive text summarization. Expert Syst. Appl. 2013, 40, 5755–5764. [Google Scholar] [CrossRef]
- Jena.apache.org. Apache Jena—Jena Ontology API. N.p. 2016. Available online: https://jena.apache.org/documentation/ontology/ (accessed on 1 March 2018).
- Krieger, H.U. A Detailed Comparison of Seven Approaches for the Annotation of Time-Dependent Factual Knowledge in RDF and OWL. In Proceedings of the 10th Joint ISO-ACL SIGSEM Workshop on Interoperable Semantic Annotation, Reykjavik, Iceland, 26 May 2014; p. 1. [Google Scholar]
- Liang, P.; Klein, D. Online EM for unsupervised models. In Proceedings of the Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Boulder, CO, USA, 31 May–5 June 2009; pp. 611–619. [Google Scholar]
- Lin, Y.S.; Jiang, J.Y.; Lee, S.J. A similarity measure for text classification and clustering. Knowl. Data Eng. 2014, 26, 1575–1590. [Google Scholar] [CrossRef]
- Lin, H.T.; Bui, N.; Honavar, V. Learning classifiers from remote RDF data stores augmented with RDFS subclass hierarchies. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015; pp. 1807–1813. [Google Scholar]
- Nigam, K.; McCallum, A.K.; Thrun, S.; Mitchell, T. Text classification from labelled and unlabelled documents using EM. Mach. Learn. 2000, 39, 103–134. [Google Scholar] [CrossRef]
- Nigam, K.; McCallum, A.; Mitchell, T. Semi-Supervised Text Classification Using EM. Semi-Supervised Learning. MIT Press: Boston. 2006, pp. 33–56. Available online: http://parnec.nuaa.edu.cn/seminar/2012_Spring/20120323/%E8%92%8B%E8%90%8D/Semi-Supervised%20Text%20Classification%20Using%20EM.pdf (accessed on 19 February 2019).
- Paik, J.H. A novel TF-IDF weighting scheme for effective ranking. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013; pp. 343–352. [Google Scholar]
- Saggion, H.; Funk, A.; Maynard, D.; Bontcheva, K. Ontology-based information extraction for business intelligence. In Proceedings of the 6th International Conference on Semantic Web, Busan, Korea, 11–15 November 2007; pp. 843–856. [Google Scholar]
- Scikit-learn.org. 4.1. Feature Extraction Scikit-Learn 0.15.2 Documentation. 2015. Available online: http://scikit-learn.org/stable/modules/feature_extraction.html#feature-extraction (accessed on 15 February 2015).
- Baudel, T.; Frank, V. Rule correlation to rules input attributes according to disparate distribution analysis. U.S. Patent No. 88,25,588, 2 September 2014. [Google Scholar]
- Guissé, A.; Lévy, F.; Nazarenko, A. From regulatory texts to BRMS: How to guide the acquisition of business rules? In Proceedings of the International Workshop on Rules and Rule Markup Languages for the Semantic Web, Montpellier, France, 27–29 August 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 77–91. [Google Scholar]
- Sitharamulu, V.; Babu, B.R. A Novel Proposal for Bridging Gap between RDB-RDF Semantic Web using Bidirectional Approach. Int. J. Appl. Eng. Res. 2016, 11, 4456–4460. [Google Scholar]
- Paulheim, H.; Plendl, R.; Probst, F.; Oberle, D. Mapping pragmatic class models to reference ontologies. In Proceedings of the 2011 IEEE 27th International Conference on Data Engineering Workshops (ICDEW), Hannover, Germany, 11–16 April 2011; pp. 200–205. [Google Scholar]
- Lu, R.; Sadiq, S. A survey of comparative business process modeling approaches. In Proceedings of the International Conference on Business Information Systems, Poznan, Poland, 25–27 April 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 82–94. [Google Scholar]
- Cimiano, P.; Haase, P.; Herold, M.; Mantel, M.; Buitelaar, P. Lexonto: A model for ontology lexicons for ontology-based NLP. In Proceedings of the OntoLex07 Workshop Held in Conjunction with ISWC’07, Busan, Korea, 11–15 November 2007. [Google Scholar]
- W3.org. RDF Schema 1.1. 2014. Available online: http://www.w3.org/TR/2014/PER-rdf-schema-20140109/ (accessed on 30 January 2015).
- Alani, H.; Kim, S.; Millard, D.E.; Weal, M.J.; Hall, W.; Lewis, P.H.; Shadbolt, N.R. Automatic ontology-based knowledge extraction from web documents. Intell. Syst. IEEE 2003, 18, 14–21. [Google Scholar] [CrossRef]
- SRS for Cafeteria Ordering System—Seidenberg School of... (n.d.). Available online: http://csis.pace.edu/~marchese/SE616_New/Samples/SE616_SRS.doc (accessed on 13 August 2018).
- Umber, A.; Bajwa, I.S. A Step towards Ambiguity less Natural Language Software Requirements Specifications. Int. J. Web Appl. 2012, 4, 12–21. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Terms | d1 | d2 | d3 |
|---|---|---|---|
| A | 6 | 17 | 3 |
| About | 0 | 0 | 1 |
| Accept | 1 | 0 | 0 |
| Achievement | 0 | 0 | 1 |
| Administrator | 0 | 0 | 1 |
| Advance | 1 | 0 | 0 |
| Agrees | 0 | 1 | 0 |
| Alike | 0 | 0 | 1 |
| All | 0 | 0 | 4 |
| Allowed | 1 | 0 | 0 |
| Also | 2 | 0 | 0 |
| Terms | Occ(ti,di)/occ(tmam,di)*log N/n(t) | ||
|---|---|---|---|
| A | 0 | 0 | 0 |
| Accept | 0.079520209 | 0 | 0 |
| Advance | 0.079520209 | 0 | 0 |
| Also | 0.029348543 | 0 | 0.058697086 |
| And | 0.079520209 | 0 | 0 |
| Any | 0 | 0 | 0.159040418 |
| Are | 0.318080836 | 0 | 0 |
| Ask | 0.079520209 | 0 | 0 |
| Assigned | 0.079520209 | 0 | 0 |
| At | 0 | 0 | 0 |
| Available | 0.159040418 | 0 | 0 |
| Be | 0 | 0.02934854 | 0.058697086 |
| Been | 0.029348543 | 0.02934854 | 0 |
| Booking | 0 | 0 | 0.159040418 |
| Branch | 0 | 0 | 0 |
| By | 0.079520209 | 0 | 0 |
| Can ………. | 0.079520209 ………….. | 0 ………. | 0 …….. |
| Data Type | Total Terms | Correct Terms | Missed Terms | Incorrect Terms | Recall | Precision |
|---|---|---|---|---|---|---|
| Concept Name Classification | 21 | 18 | 1 | 2 | 85.71% | 90.00% |
| Semantic Annotation | 6 | 5 | 1 | 1 | 83.33% | 83.33% |
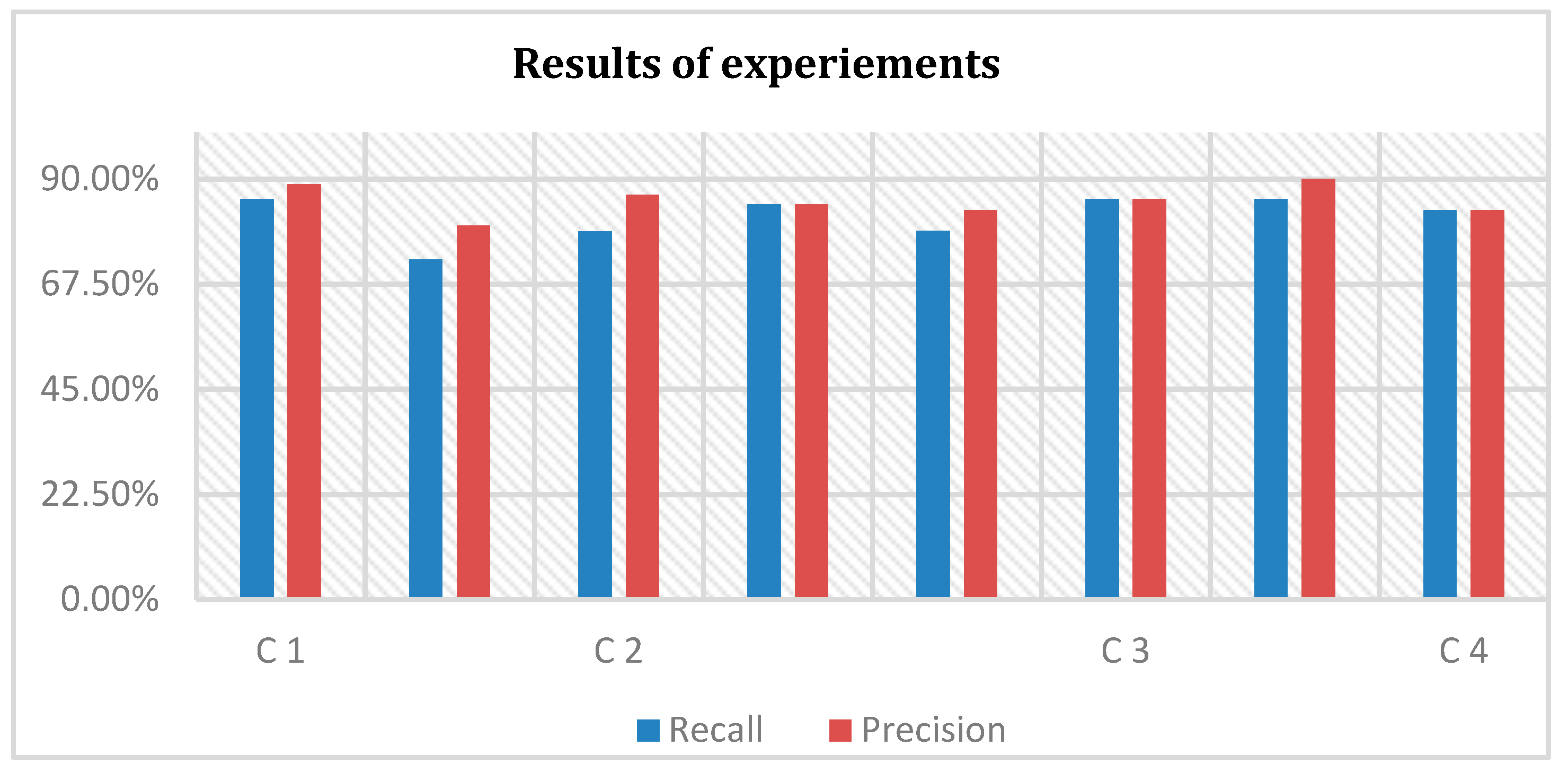
| Case Study | Total Terms | Correct Terms | Missed Terms | Incorrect Terms | Recall | Precision |
|---|---|---|---|---|---|---|
| C 1 | 28 | 24 | 3 | 1 | 85.71% | 88.88% |
| 11 | 8 | 1 | 2 | 72.72% | 80.00% | |
| C 2 | 33 | 26 | 3 | 4 | 78.78% | 86.66% |
| 13 | 11 | 0 | 2 | 84.61% | 84.61% | |
| C 3 | 19 | 15 | 1 | 3 | 78.94% | 83.33% |
| 7 | 6 | 0 | 1 | 85.71% | 85.71% | |
| C 4 | 21 | 18 | 1 | 2 | 85.71% | 90.00% |
| 6 | 5 | 1 | 1 | 83.33% | 83.33% | |
| Average | 81.93% | 85.32% | ||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sajjad, R.; Bajwa, I.S.; Kazmi, R. Handling Semantic Complexity of Big Data using Machine Learning and RDF Ontology Model. Symmetry 2019, 11, 309. https://doi.org/10.3390/sym11030309
Sajjad R, Bajwa IS, Kazmi R. Handling Semantic Complexity of Big Data using Machine Learning and RDF Ontology Model. Symmetry. 2019; 11(3):309. https://doi.org/10.3390/sym11030309
Chicago/Turabian StyleSajjad, Rauf, Imran Sarwar Bajwa, and Rafaqut Kazmi. 2019. "Handling Semantic Complexity of Big Data using Machine Learning and RDF Ontology Model" Symmetry 11, no. 3: 309. https://doi.org/10.3390/sym11030309
APA StyleSajjad, R., Bajwa, I. S., & Kazmi, R. (2019). Handling Semantic Complexity of Big Data using Machine Learning and RDF Ontology Model. Symmetry, 11(3), 309. https://doi.org/10.3390/sym11030309