2.1. BP Neural Network Method
In this subsection, we shall give a few necessary backgrounds on back-propagation (BP) neural network. We will merely mention a few mathematical statements necessary for a good understanding for the present paper, and more details can be found in [
22,
23,
24,
25,
26].
BP neural network is a kind of artificial neural networks on the basis of error back-propagation algorithm. Usually, BP neural network consists of one input layer, one or more hidden layer, and one output layer.
Let m, k, respectively, denote the neural number of input layer and the neural number of output layer, and L denotes the number of hidden layers. Additionally, denotes the target vector, denotes the input vector of BP neural network, denotes the output vector of BP. BP uses as the neuron activation function in the lth layer, . The 1st layer of the neural network is input layer, from the 2nd layer to the layer are hidden layers, and layer Lth is the output layer. Let denotes the weight from node i of layer (l − 1)th to node j of layer lth, and denotes the bias of node j in layer lth.
In BP neural network, the neurons just in adjacent layers are fully connected; nevertheless, there is no connection in the same neurons’ layer. After each training process, the output value (the vector of predicted labels) is compared with the target value (the vector of correct labels), and then we can amend weights and thresholds of the input layer and the hidden layer with error feedback. With a hidden layer, BP neural network can express any continuous function accurately.
Let
denotes the output of node
j in layer
lth, and let
denotes the assemble of inputs in node
j of layer
lth, and it can be expressed as follows [
23]
Therefore, the output
of node
in layer
lth is expressed as follows
where
is the activation function of layer
lth.
There are three transfer functions in the BP neural network such that tan-sigmod, log-sigmoid, and purelin. Tan-sigmod or purelin transfer function maps any input value into an output value between −1 and 1. Log-sigmoid transfer function maps any input value into an output value between 0 and 1. The transfer functions in neural network can mix freely without unifying, so that we can reduce the network’s parameters and hidden layer’s nodes during the establishment of BP.
Since
is the target vector, and
is output vector, the error function
can be expressed as follows [
23]
where
k denotes the number of output layer nodes.
In this paper, we use the following mean square error (MSE) as the error output function of BP neural network [
23]
where
denotes the input of each train sample, and
denotes the number of train samples. It can decrease the global error of training dataset and the local error when each data point inputs.
In order to reduce the
MSE gradually so that the predicted output value can be closer and closer to expectations booked in advance, BP neural network needs to adjust its weights and bias values constantly [
24].
The classification accuracy of BP neural network is heavily dependent on the selected topology and on the selection of the training algorithm [
25]. In this paper, we use Widrow-Hoff LMS method [
26] to adjust the weight
and bias
, that is
where
is used to control its amendment speed, which can be variable or constant, generally speaking
.
According to the basic principle of BP neural network, we can obtain the update formula of weight and bias in each layer.
We write
for the value of
, which can be expressed as follows
where
of the formula above is the first-order partial derivatives of the activation function of layer
lth
.
And we write
for the value of
, which can be expressed as follows
since
we have
, then
can be defined by recurrence as follows:
Similarly, we can prove that [
23]
Consequently, the basic idea of BP neural network is summarized as follows. Firstly, input training data into neural network. Then during the processing of continuous learning and training, BP neural network will modify the weights and threshold values step by step, and when it reaches the precision error setup in advance, it will stop the learning. Finally, the output value is acquired.
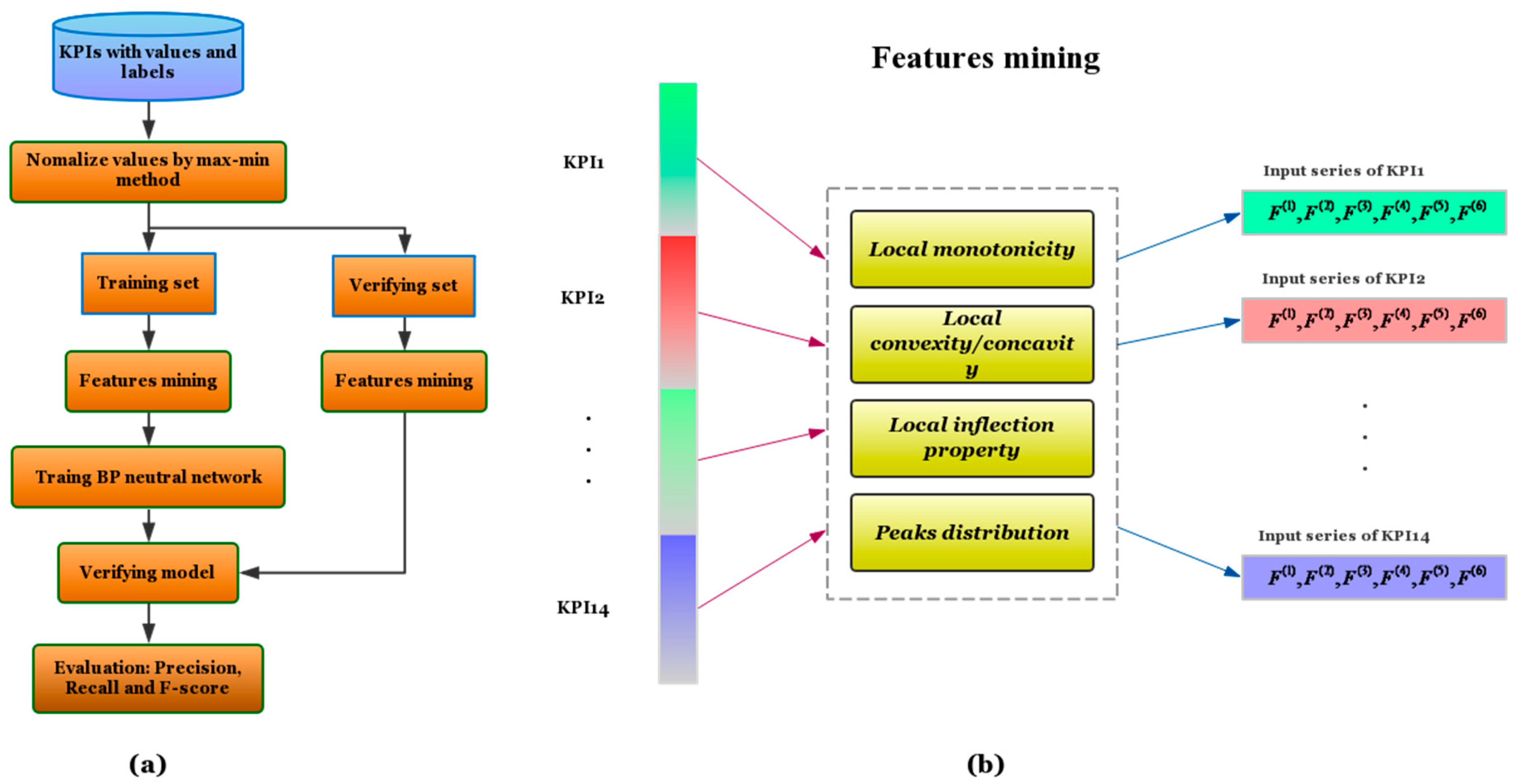
2.2. Features Mining Method
By means of vectorization description on a normalized KPIs dataset innovatively, the local geometric characteristics of one time series curve could be well described in a precise mathematical way. We shall mine six local data features to describe the local monotonicity, convexity/concavity, the local inflection properties of one series curve.
2.2.1. Normalization by Max–Min Method
For a KPIs data with value set
, we firstly use a max–min method to normalize each of the values as follows:
where
The purpose of normalization is to avoid large differences between different values in a KPI time series.
2.2.2. The Definition of Six Local Data Features
For a resulting normalized value dataset , we divide it into a train part and a verifying or test part . We shall use the train part to establish the model while use the verifying part to test the performance of the model.
Local monotonicity, convexity/concavity, local inflection properties, and peaks distribution are four essential features of a given data set, which describe the local increasing/decreasing rates of the data set. With this in mind, we mine the following six features of the resulting normalized value dataset
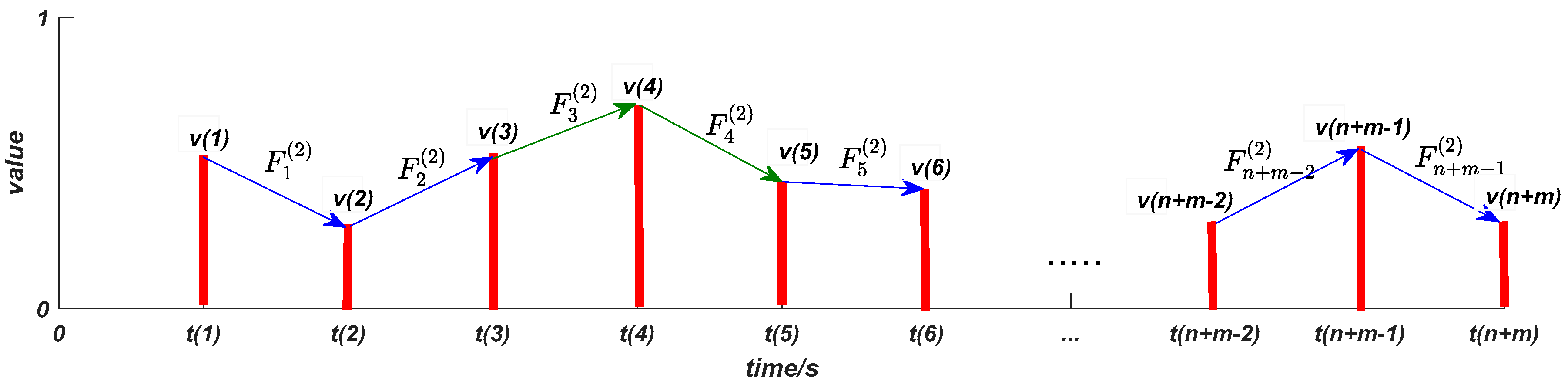
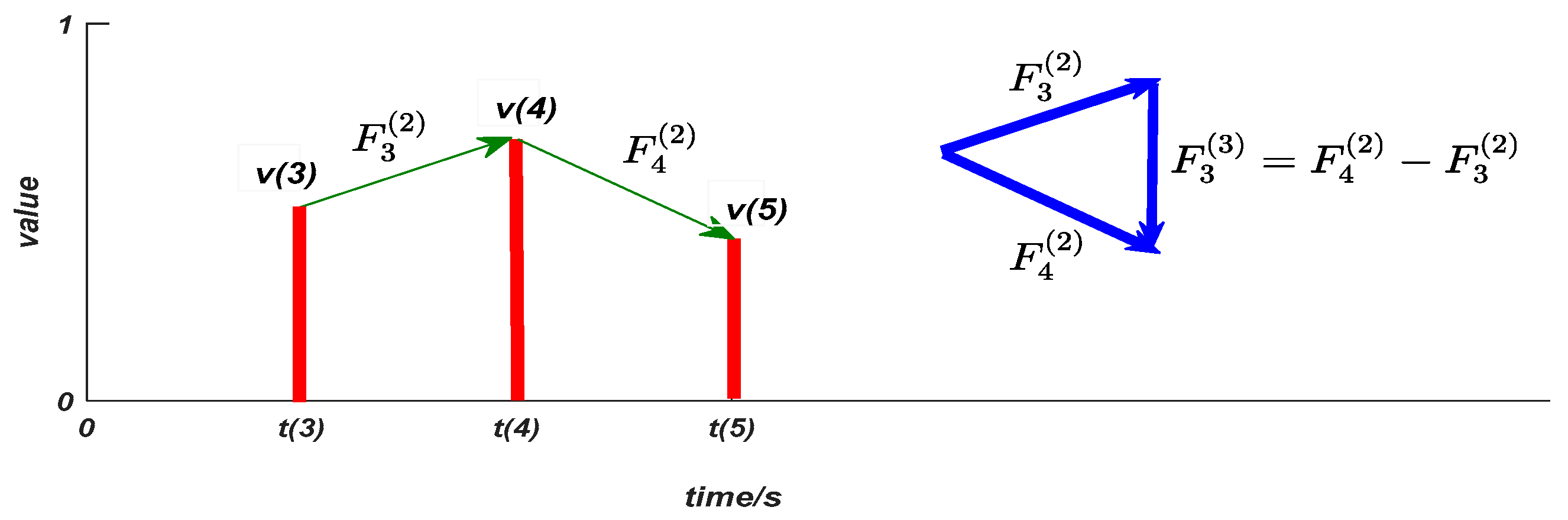
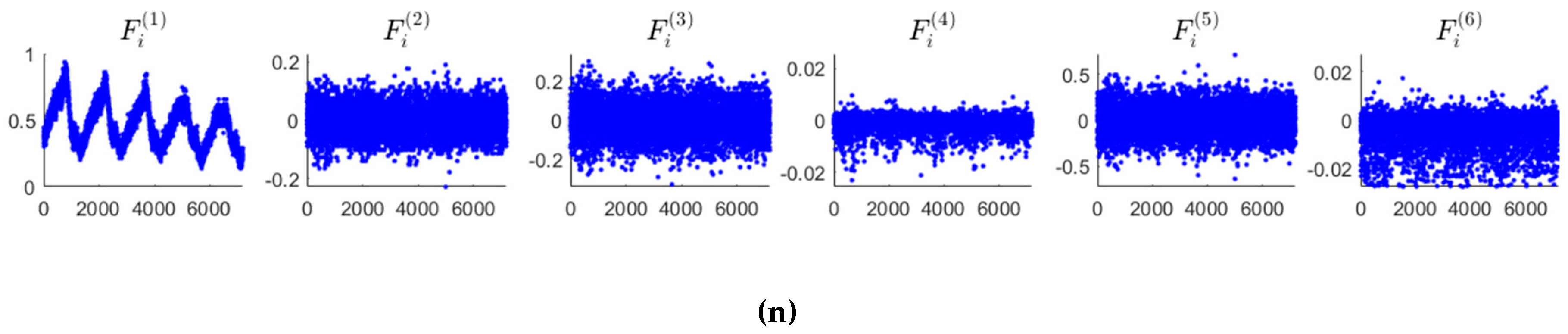
We give some geometric explanations on the six mined features. The feature
can describe peaks distribution of the normalized value data. As shown in
Figure 3 and
Figure 4, the feature
and
are in fact the first and second difference of the normalized value data, respectively, which can describe the local monotonicity and convexity/concavity of the normalized value data. For example, with
and
, the normalized value data is both monotonically increasing and convex locally (in other words, the normalized value data has a faster and faster increasing rate locally).
The feature can describe the local inflection property of the normalized value data. For example, with that is or , it implies that the normalized value data has a local switch between “increasing” and “decreasing” values. The feature is the third difference of the normalized value data, and the feature can describe the local switch of the sign of .
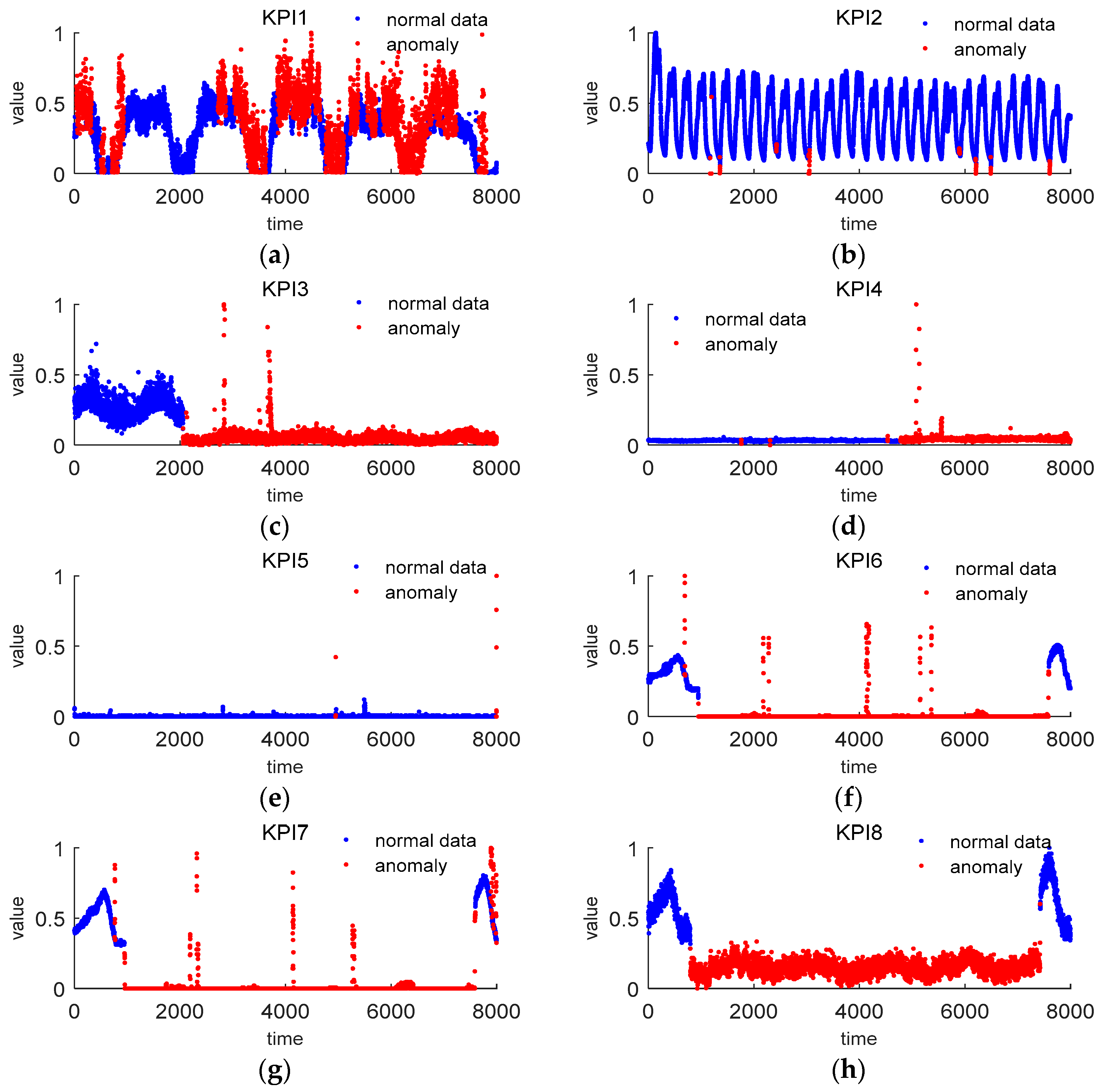
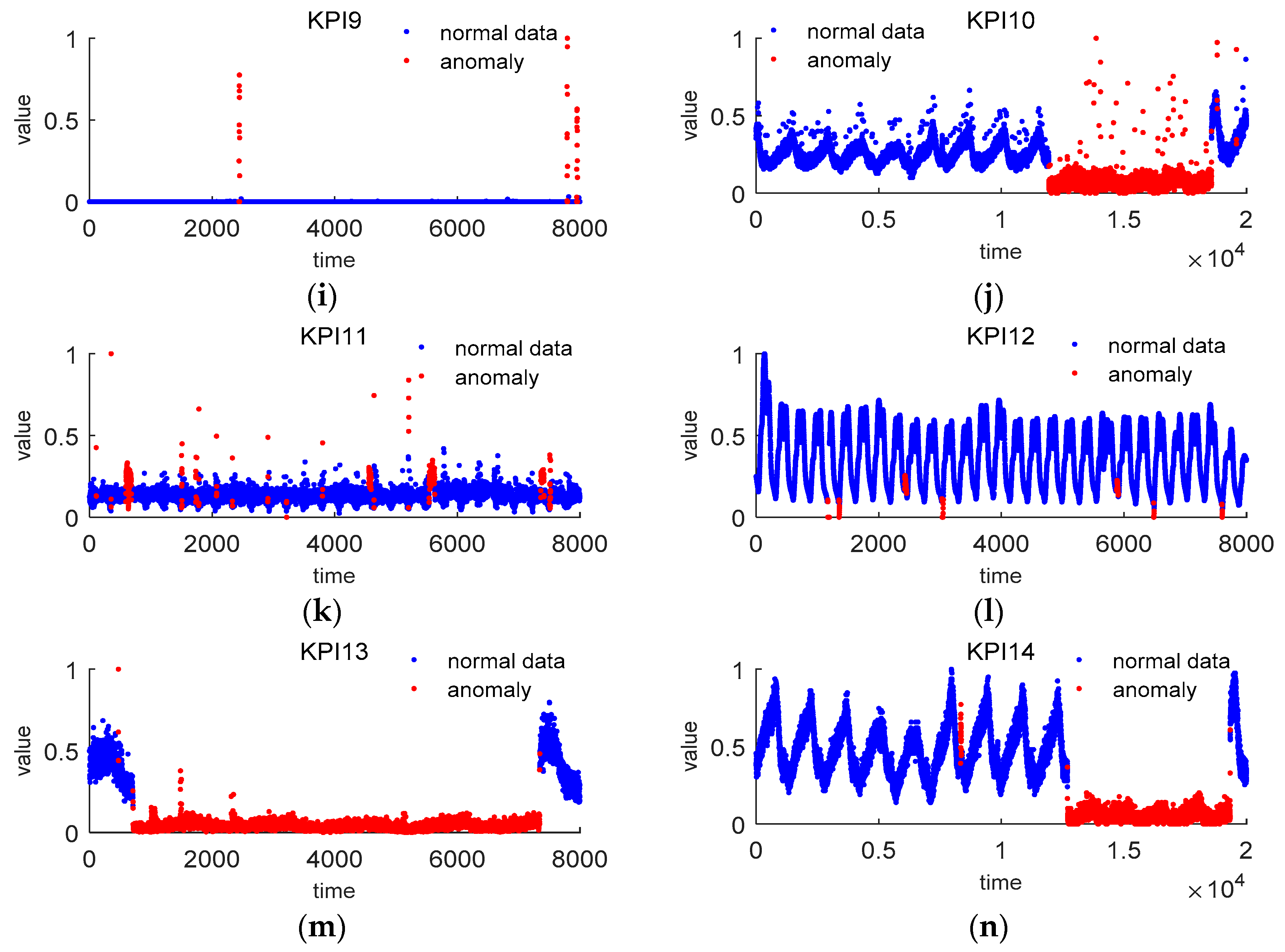
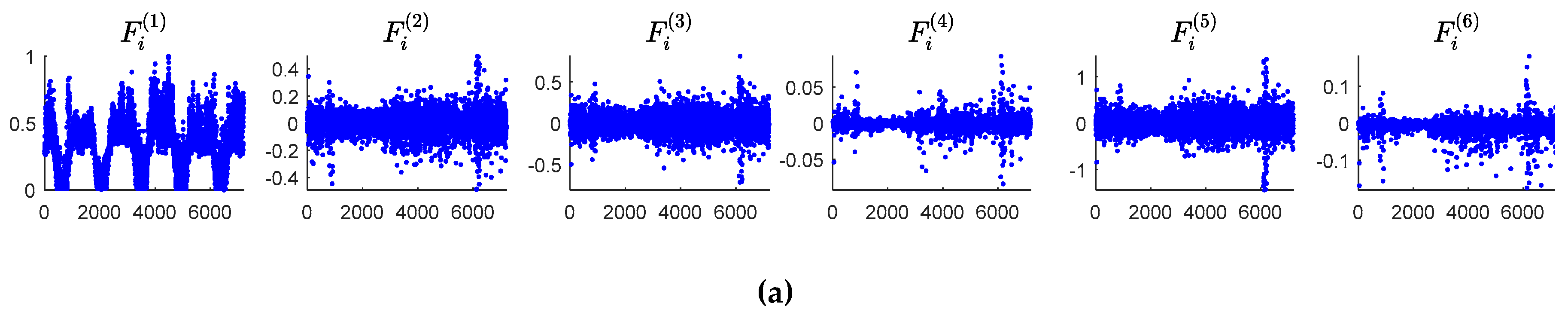
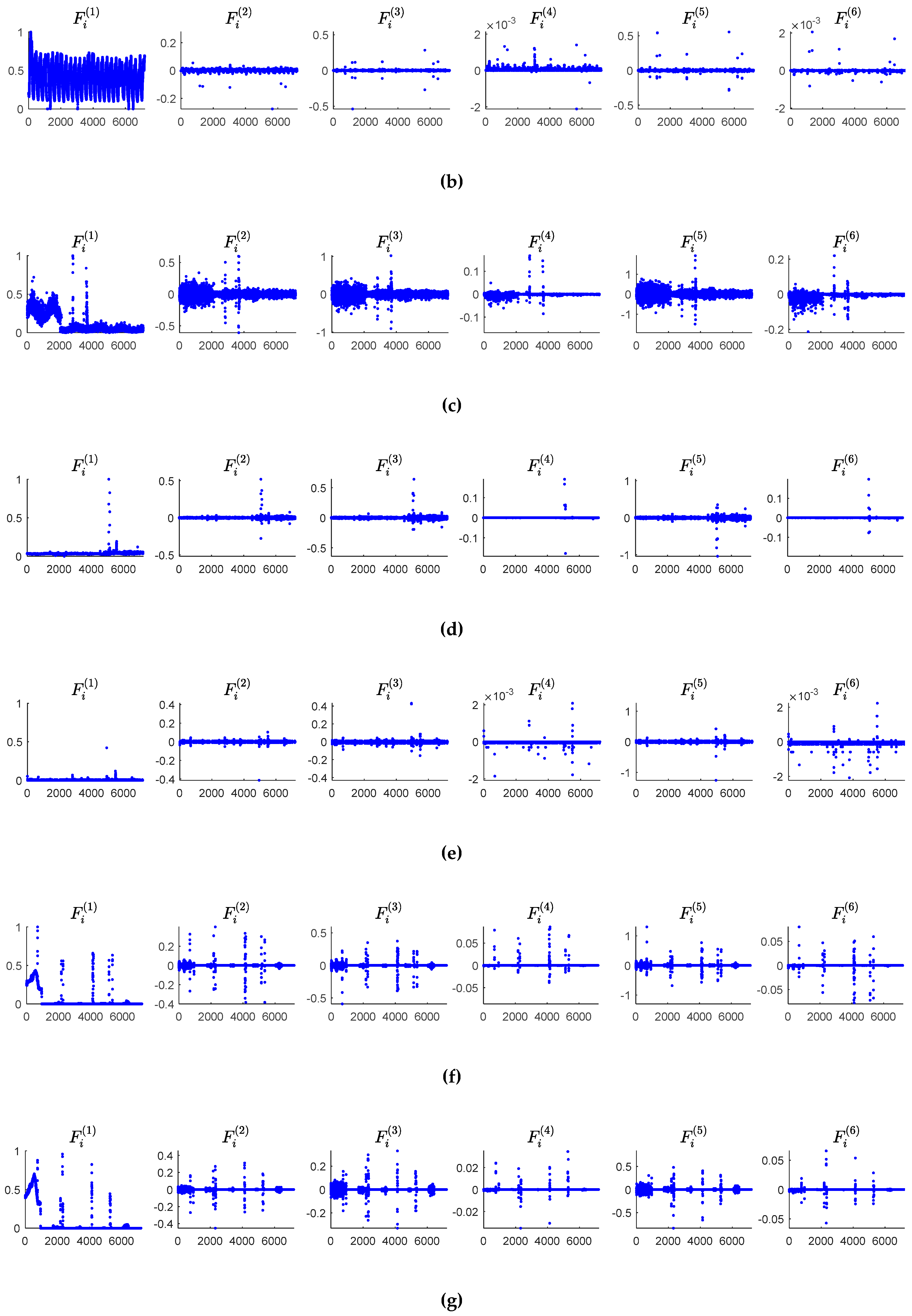
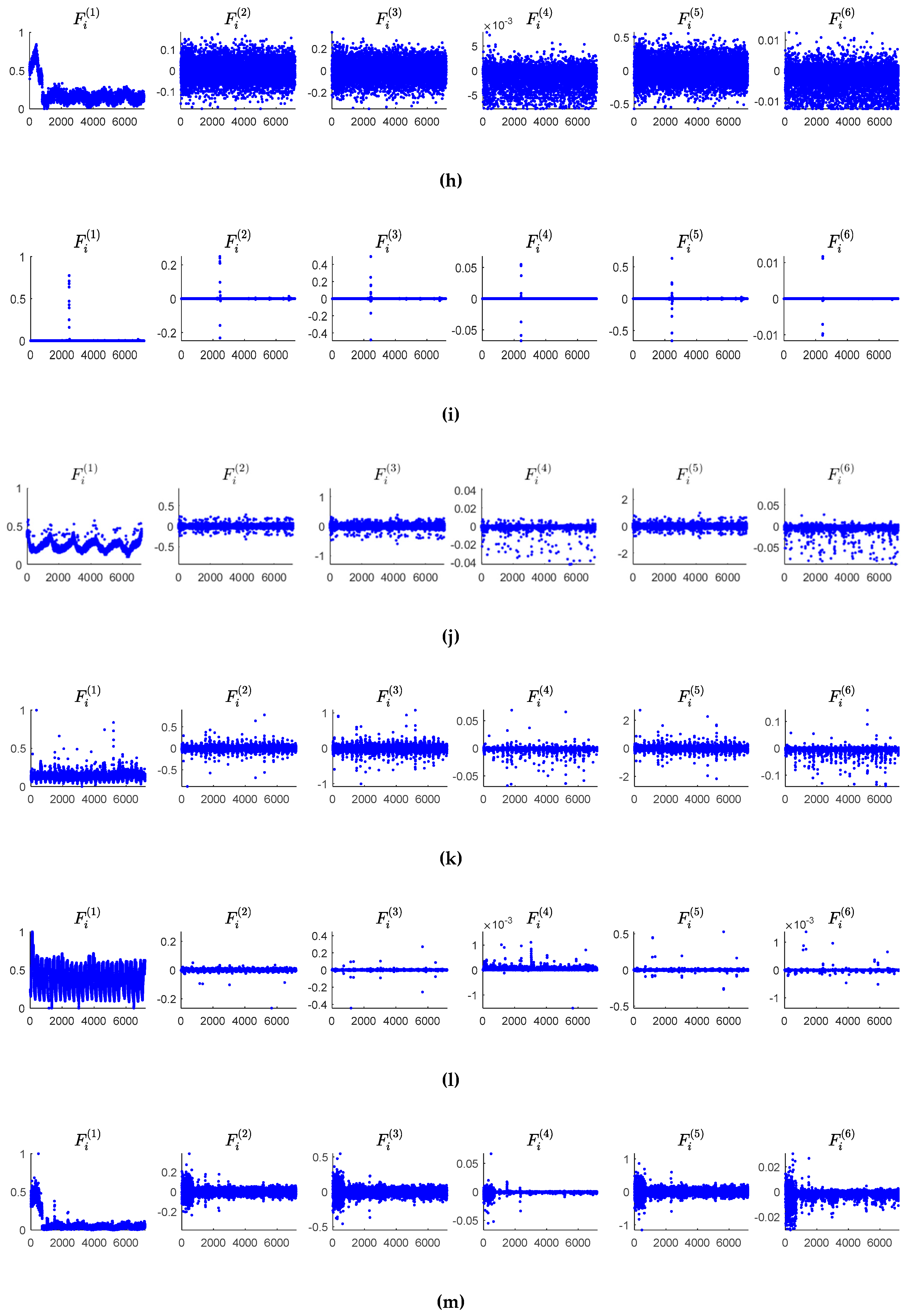
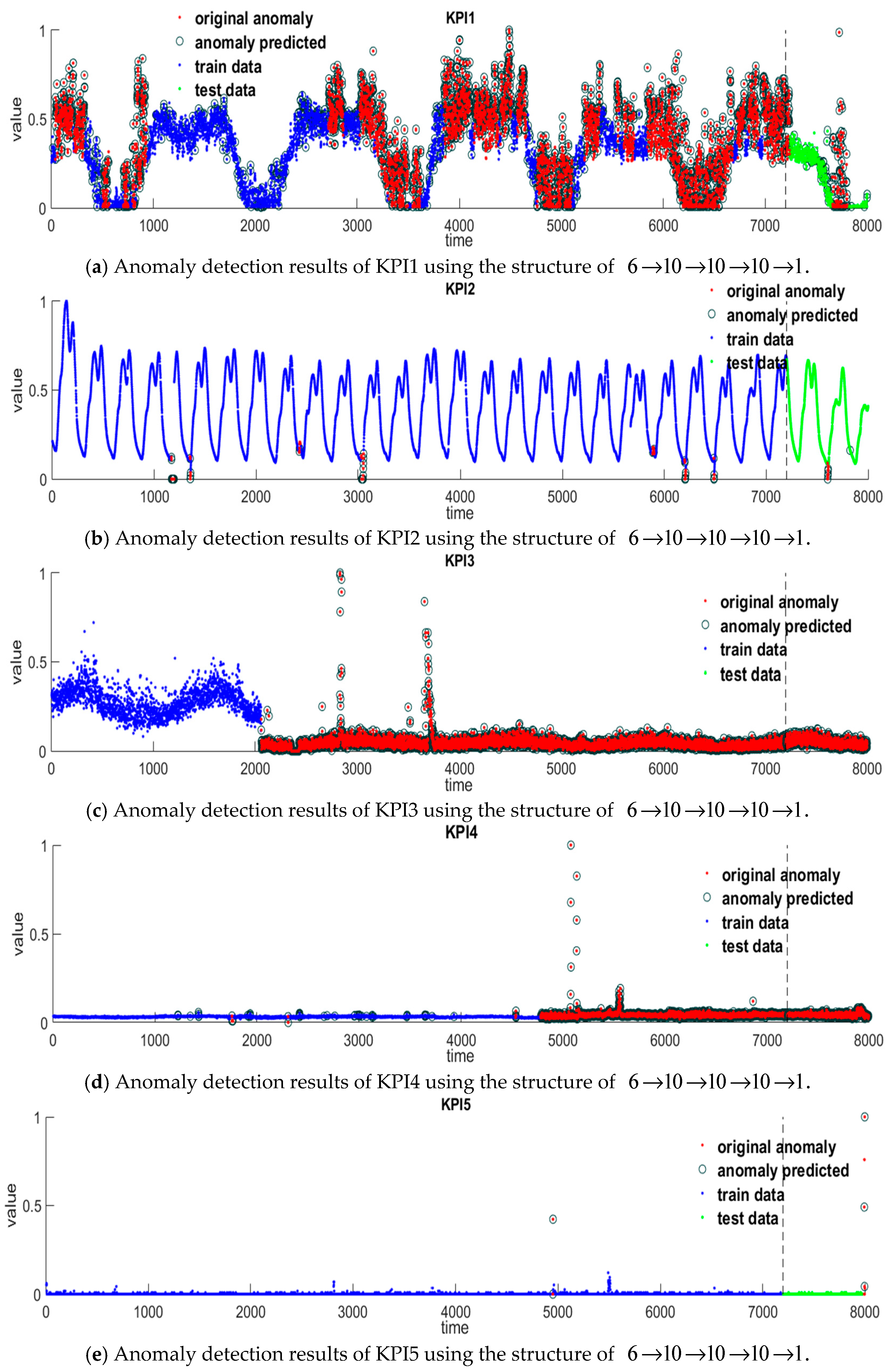
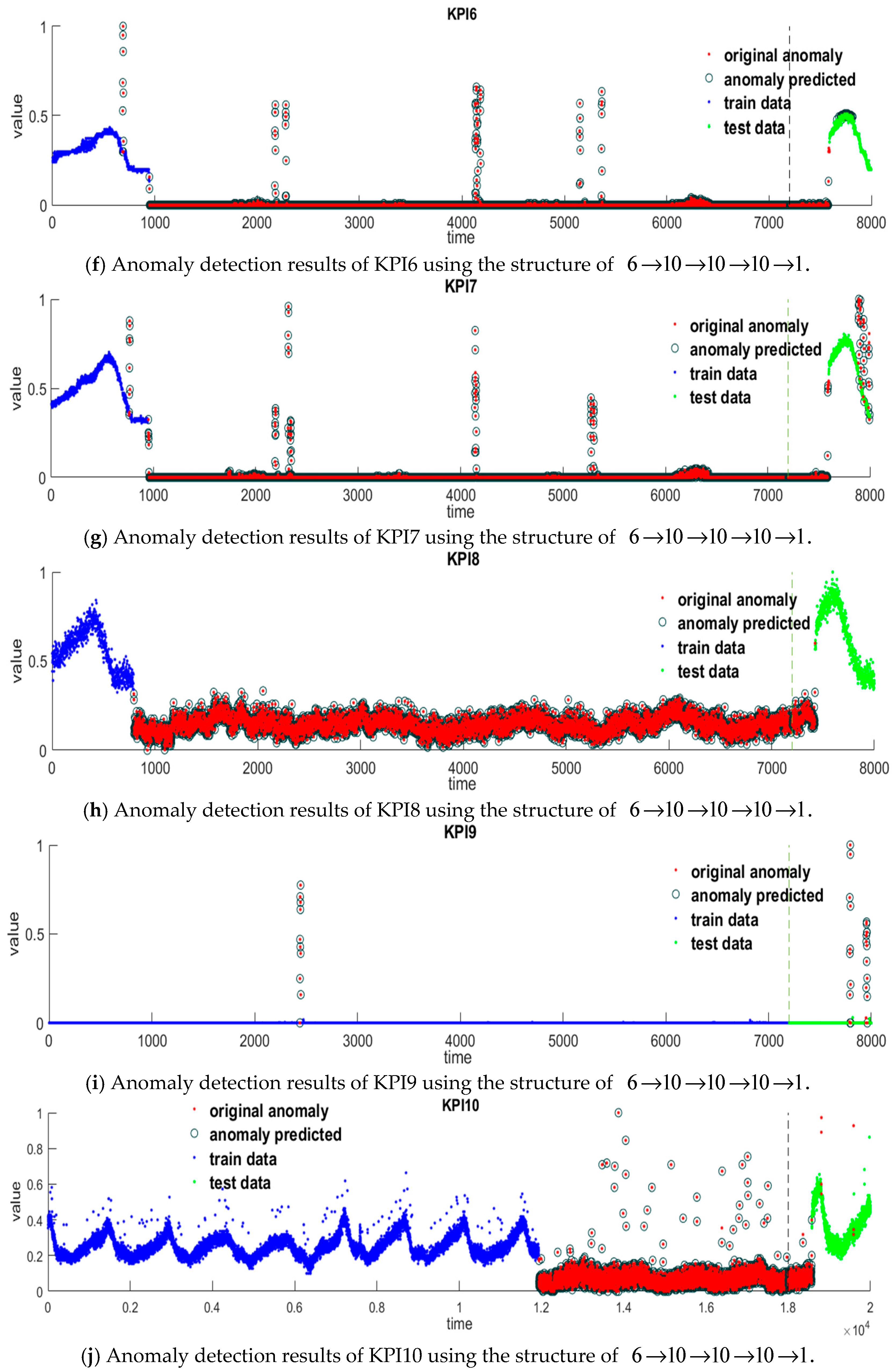
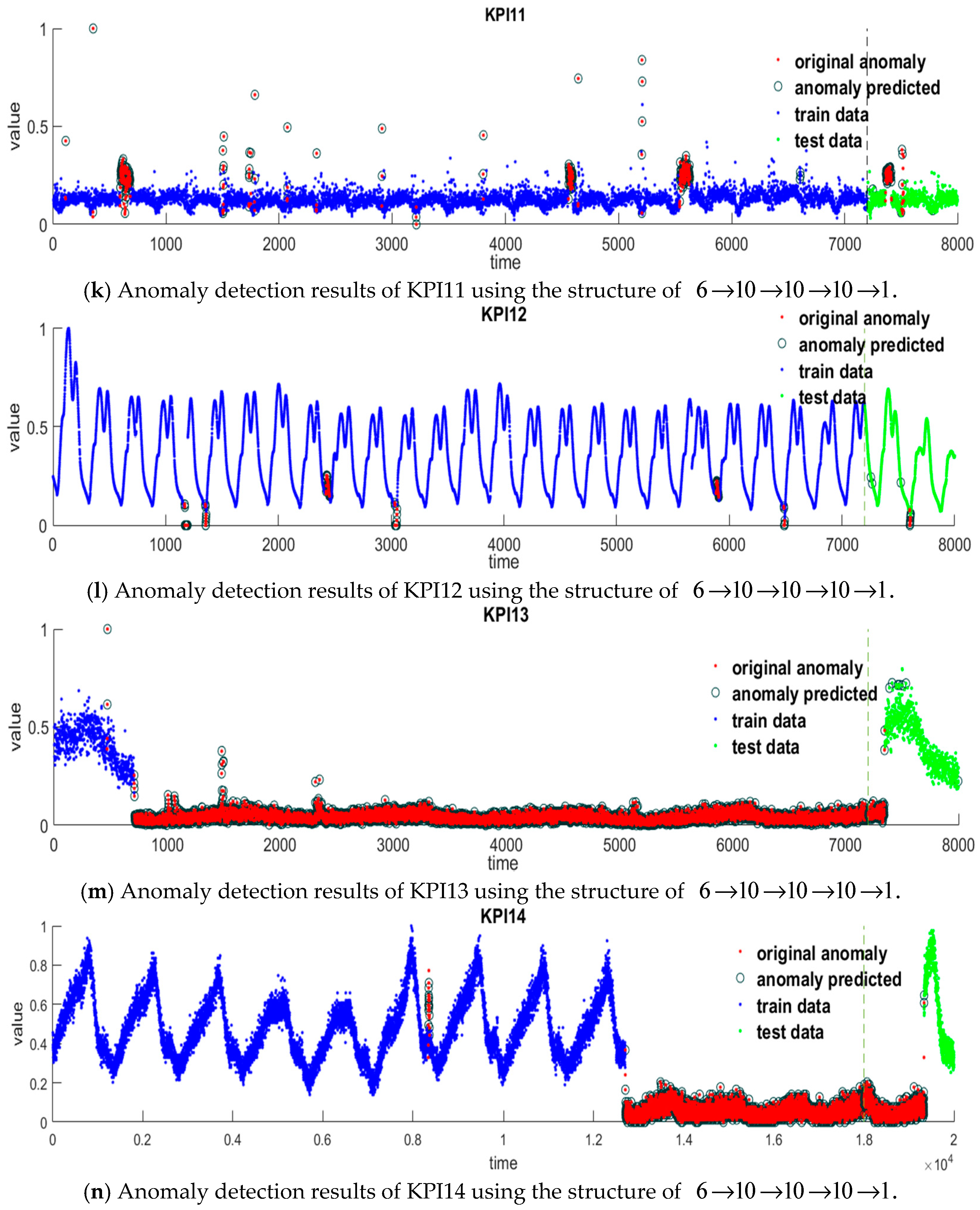
Figure 5 shows the numerical results of the six features mined of 14 KPIs. From this figure, we can see that the first, second, and third difference
and
distinguish anomalies and normal data significantly. The point whose values of
and
differ from that of the other points extraordinarily may be considered as an anomaly. The features
and
reveal the anomalies in a subtle way, which can prevent the misjudgments given by
, and
.
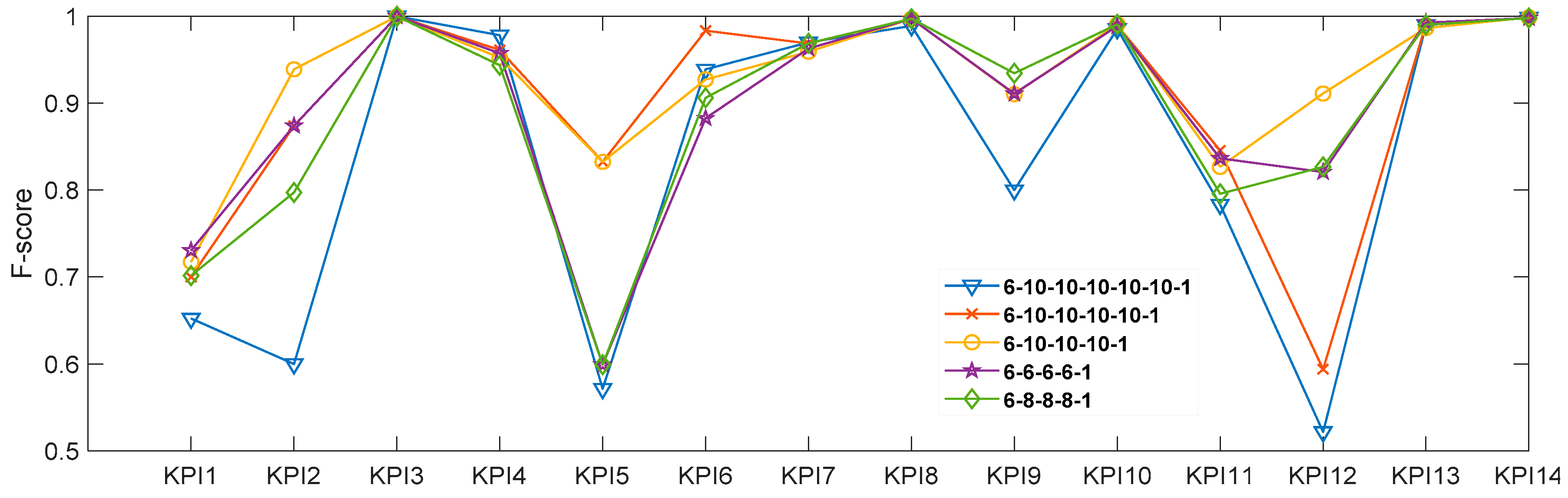
2.4. Evaluation Method of Model Performance
In this experiment, confusion matrices (TP, TN, FP, and FN) have been applied to define the evaluation criterion. The meaning corresponding to confusion matrices are categorized in
Table 2, where true positive (TP) means the number of anomalies precisely diagnosed as anomalies, whereas true negative (TN) means the number of normal data correctly diagnosed as normal. In the same way, false positive (FP) means the number of normal data diagnosed as anomalous by mistake, and false negative (FN) means the number of anomalies inaccurately diagnosed as normal.
In order to give the evaluations of the performance of the proposed model, evaluation criteria such as Recall, Precision, and F
1-score are considered [
18]
Recall, which is computed by Equation (16), denotes the number of anomalies detected by the anomaly detection technology. Precision, which is computed by Equation (17), denotes the numbers of the values being accurately categorized as anomalies. It is the most intuitive performance evaluation criterion. F
1-score, which is computed by Equation (18), consists of a harmonic mean of precision and recall while accuracy is the ratio of correct predictions of a classification model [
27,
28]. In the next numerical experiments, we shall adopt the F
1-score to evaluate the performance of the model.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}