1. Introduction
Due to the continuing advance of networks in recent years, it has become increasingly convenient and necessary for users to transmit messages to each other through the Internet. This, however, also creates many security problems, including the opportunity for a malicious attacker to destroy the transmitted information or tamper with data due to the openness of the Internet. To address these issues, researchers have explored different approaches, such as conventional cryptographic algorithms and information hiding methods. The former transforms the encrypted message into a meaningless format, but may leave clues for attackers. In contrast, the latter un-perceptively embeds the protected message into cover media. In terms of avoiding attacker attention, the information hiding approach outperforms conventional cryptographic algorithms.
Over the past decade, a variety of information hiding schemes have been proposed [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19]. These information hiding schemes can be divided into two categories based on the subject that is embedded into a cover media. One is used for secret message transmission [
1,
2,
3,
4,
6,
7,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19] and the other is used for claim of ownership [
5,
8,
9] which is also called watermark scheme. The cover media used to carry a secret message can be image, text, audio or video. Currently, images are the primary media used to conceal secret messages because they can be easily found from the Internet. To embed a secret message into a cover image, there are three alternatives, including: spatial domain [
1,
2,
3,
4], frequency domain [
5,
6,
7,
8] and compression domain [
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20]. Spatial domain-based information hiding schemes conceal a secret message into a cover image by simply modifying pixel values of the cover image. A representative example is Least Significant Bit (LSB) substitution [
1]. Frequency domain-based information hiding schemes need to transform a cover image into the frequency domain by using discrete wavelet transform (DWT) [
21], discrete cosine transform (DCT) [
22], etc. The frequency coefficients are then modified to carry a secret message. For compression domain-based information hiding, a secret message is embedded into the compression codes of a cover image and the compression codes are generated by any kind of compression algorithm, such as VQ [
23], SMVQ [
24], block truncation coding (BTC) [
20] or JPEG. Among the above three types of information hiding schemes, frequency domain methods offer relatively higher protection compared to the others. Based on the reversibility feature of the proposed information hiding schemes, information hiding schemes can be further classified into those that are irreversible [
1,
2,
5,
6] and reversible [
3,
4,
7,
8,
9,
10,
11,
12,
14,
15,
16,
17,
18,
19,
20,
25,
26,
27,
28,
29,
30,
31,
32,
33]. The former can only extract information that is embedded in the media. Decoders still cannot completely restore the original cover image even after the hidden message has been extracted.
For example, in 2004, Chen et al. provided an irreversible scheme that embeds the secret data into a cover image by exploiting the Least Significant Bit (LSB) [
1]. Decoders can determine the secret bit according to the LSB value of each pixel. However, decoders cannot recover each pixel back to the original, because this method directly changes the LSB value without recording any information regarding the replaced bits. However, irreversible information hiding schemes are not suitable for concealing a secret message into a cover image that requires exact restoration after data extraction, such as in military or medical applications.
In 1997, Barton [
27] first proposed a reversible data hiding method. In this approach, the bits to be overlaid were compressed in advance and added to the bitstring. After that, the bitstring carrying hidden compressed bits was embedded into data block in the cover image. In 2002, Celik et al. [
28] presented a method called generalized least significant bit, G-LSB for short, where they utilized a variant of an arithmetic compression algorithm (CALIC) [
29] to encode a message and hide the resulting interval number along with extra information that was exploited to recover the cover image. In 2003, Tian [
30] proposed a novel reversible information hiding method called difference expansion (DE) by embedding the secret message into the difference values between each pixel pair in a cover image. In 2004, Alattat [
31] improved Tian’s method by exploiting the difference in expansion of vectors instead of two adjacent pixels to enhance embedding capacity. In 2006, Ni et al. proposed a reversible scheme that hides secret data using histogram shifting [
3]. They calculated the frequency of each pixel in the cover image and found zero and peak points to embed the secret data based on the histogram modification. When the receiver extracts the secret message from the cover image, the modified pixel can be recovered back to the original pixel value according to the modified method.
In 2009, Tai et al. [
4] designed an efficient extension of the histogram modification technique by constructing a histogram of a cover image based on the differences between pixel values of each pixel pair to enhance the hiding capacity of Ni et al.’s scheme. In 2011, Li et al. [
32] proposed a novel reversible watermarking scheme by exploiting prediction-error expansion (PEE), adaptive hiding and pixel selection. Their scheme concentrated on highly relevant regions and pixels of the cover image, and it obtains a high embedding capacity with less distortion. In 2012, in order to provide good visual quality and higher embedding capacity, Chang et al. [
33] proposed a reversible data hiding scheme that determines whether a pixel is embeddable or not by calculating the absolute difference of its neighboring pixels. In Chang et al.’s scheme, once the derived absolute difference is larger than the predetermined threshold, the corresponding pixel remains unchanged to maintain a high image quality. However, these methods described above are mainly designed for the spatial domain rather than the compression domain. In general applications, images needed to be compressed before they are transmitted over the Internet because the size of raw images can be large. Since image compression is very popular, it is necessary to design reversible data hiding techniques for the compression domain.
Over the last few years, many hiding schemes designed for the compression domain have been proposed to reduce the transmission size of multimedia files during transmission and to increase the number of alternatives for cover media. Among these methods, many hiding schemes have been proposed based on block truncation coding (BTC) [
14,
15,
16,
17,
18,
19], which has been the most efficient and fastest compression method. In 2008, Chang et al. presented an information hiding scheme based on BTC [
14]. They applied a genetic algorithm to substitute the original three bitmaps by finding an approximate optimal common bit map. Subsequently, the common bit map and block quantization levels for each block are used to hide the secret information. Side matching and quantization level orders are utilized to make the method reversible. In 2011, Li et al. proposed a reversible data hiding scheme based on BTC [
15]. In their scheme, they utilized two quantization levels to generate a histogram. Histogram shifting and bitplane flipping are used to hide the secret data into a compressed code stream to improve the hiding capacity and to retain acceptable image quality. For example, if the secret bit is 1 then the high value and low value will be swapped with each other in the compression code, etc. In 2013, Sun et al. presented a novel BTC-based reversible hiding scheme by adopting a joint neighbor coding technique to embed the secret data into quantization levels [
16]. In 2015, Lin et al. also proposed a reversible information hiding method based on BTC. In their scheme, they embed the secret information into the bit map of each image block [
19]. However, their method only utilized the concept of BTC, and they did not compress the image so that the stego-image is not the BTC codestream. Although many BTC-based reversible data hiding schemes have been proposed, we found that these schemes are limited by a blocking effect problem. As such, in this paper, we try to propose a BTC-based reversible data hiding scheme without a blocking effect problem. To solve the blocking effect problem while offering a reversibility feature, we utilized Zero-Point Fixed Histogram Shifting (ZPF-HS) to embed the secret information and adaptive block truncation coding based on edge-based quantization (ABTC-EQ) to improve image quality and obtain a high embedding capacity.
The reminder of this paper is divided into five sections.
Section 2 introduces the ABTC-EQ method, which forms the basis of our proposed reversible data hiding scheme.
Section 3 briefly describes our proposed reversible data hiding scheme.
Section 4 presents experiments to prove the performance of the proposed scheme. Finally, conclusions are given in
Section 5.
2. Related Work
2.1. Histogram Shifting Technique (HS)
In 2006, Ni et al. presented an information hiding method based on the histogram shifting technique (HS) [
3]. HS is a simple and efficient reversible data hiding method. In their scheme, they calculated the frequency of each pixel value in a cover image and generated an image histogram. Some pixel values from the histogram are selected and modified to embed the secret data. The modified pixel values can be recovered when the secret information is extracted, such that reversible data hiding is achieved. Their scheme is described as follows:
Step 1. Input an sized cover image I.
Step 2. Compute the frequency of each pixel value and construct an image histogram. Peak and zero are the values of peak point and zero point, respectively.
Step 3. Shift the pixel values according to a pair for
peak and
zero. If
, the histogram ranging from
to
will be shifted to the left side by decreasing 1. Otherwise, the histogram ranging from
to
will be shifted to the right side by adding 1.
where
and
are the pixel values at the locations (
) of cover image
I and modified cover image
, respectively.
Step 4. Embed the secret information into the modified cover image
. If the secret bit S is “1” and the pixel value is equal to
peak, it will be increased or decreased by 1. Otherwise, its value remains unchanged.
Step 5. Repeat Step 4 until all are processed.
Step 6. Output stego-cover image .
2.2. ABTC-EQ
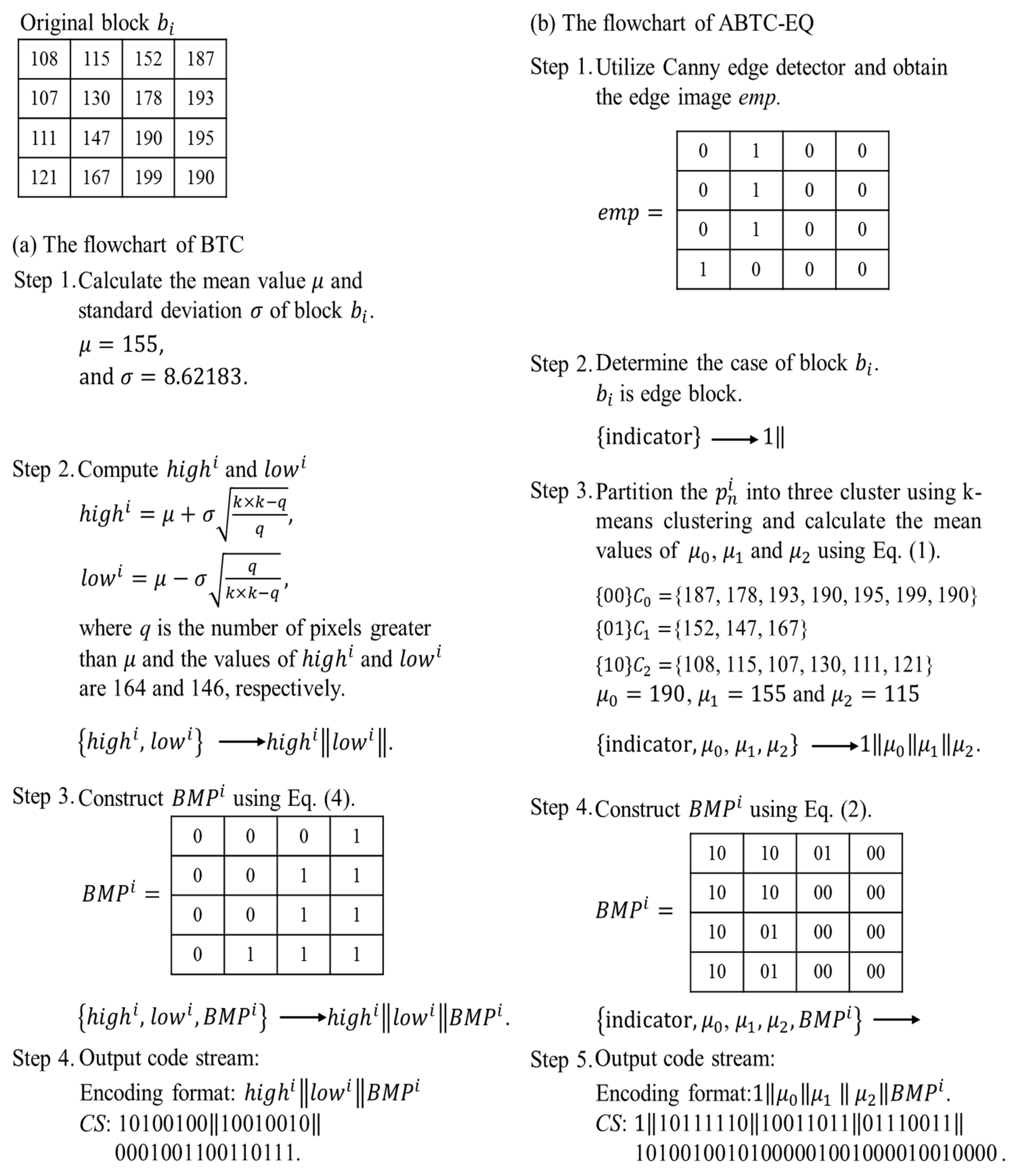
In 2015, Mathews et al. [
23] proposed a novel adaptive block truncation coding technique called ABTC-EQ. It is introduced in detail in this section to offer a better understanding of our proposed method. The cover image is compressed according to the result presented in the edge image that is derived by Canny edge detection [
21]. Next, a quantization approach is processed based on the edge information of each block. If a block is determined as non-edge-block, it proceeds with bi-clustering. In contrast, an edge-block proceeds with tri-clustering. All steps are described as follows:
Step 1. Input cover image
I sized as
pixels and divide it into
non-overlapping blocks
’s, where
and
Step 2. Utilize Canny edge detection to obtain the edge map of the whole cover image denoted as .
Canny edge detection is an optimal algorithm including three steps to detect edge information from the given cover image. The first step is to reduce the noise by using Gaussian filter. Next, find the gray levels and apply a non-maximum suppression technique to thin the edge. Then, utilize double thresholds and connectivity analysis to indicate the edge map emp for the given cover image I.
Step 3. Divide the
emp into
non-overlapping edge-blocks
’s.
Step 4. Perform block classification based on edge-blocks generated by Step 3.
If there is only one edge value, it is 1 in edge-block and the rest of the values are 0, and block can be determined as an edge-block with three quantization levels and goes to Step 5. Otherwise, it belongs to the non-edge-block with two quantization levels and goes to Step 6.
Step 5. Employ k-means clustering [
22] to partition the pixels in the current block
into three clusters,
,
and
, respectively.
Then calculate the mean values of each cluster using Equation (3), and these three mean values will serve as three quantization levels.
where
,
,
is the member of each cluster and
’s mean the members in each cluster.
The
in
will be defined according to Equation (4).
where
is the bit map of
,
is the value in
and
.
Step 6. Find the maximum (max) and minimum (min) values of gray levels in block . Then, compute the average value of block .
Calculate the value of threshold
T using Equation (5).
Construct the
by using Equation (6) and calculate the two quantization levels
and
by using Equations (7) and (8).
Here is the pixel value in block , is the number of pixels that are greater than T, means the numbers that are smaller than or equal to T, is the high value in and is the low value.
Step 7. Repeat Step 4 to Step 6 until all block ’s are processed and then obtain ABTC-EQ compressed codes.
Figure 1a,b show the encoding flowcharts of BTC [
13] and ABTC-EQ [
23], respectively. To simplify our example shown in
Figure 1, a single block
sized
pixels using BTC and ABTC-EQ, respectively, is demonstrated. We used Equation (9) to calculate the Mean Square Error (
MSE) of BTC and ABTC-EQ, whose values were 698 and 55, respectively. Obviously, ABTC-EQ has good performance when a block is in the complexity area.
where
and
are the values of the decompressed pixel and the original pixel values.
3. Proposed Scheme
This section presents the proposed scheme. In our method, we utilized ABTC-EQ to compress the cover image because its reconstructed image quality is relatively good compared to other BTC variant techniques. Next, ZPF-HS was used to embed the secret information into an ABTC-EQ compressed code stream. To further enlarge the hiding capacity of our proposed method, we also embed the secret data into quantization levels. As background for our proposed scheme,
Section 3.1 reviews the zero-point fixed histogram shifting (ZPF-HS) that will be used for data embedding in our approach. Our proposed scheme contains two phases: a data embedding phase and the data extraction and recovery phase, which are demonstrated in
Section 3.2 and
Section 3.3, respectively.
3.1. Zero-Point Fixed Histogram Shifting (ZPF-HS)
The histogram shifting technique [
3], called HS for short, is a simple and efficient hiding method, and has been widely adopted in various reversible data hiding schemes. In this section, the features of HS are explored and then expanded to support a zero-point fixed scenario as zero-point fixed histogram shifting, called ZPF-HS for short. Finally, ZPF-HS is adopted in our proposed scheme.
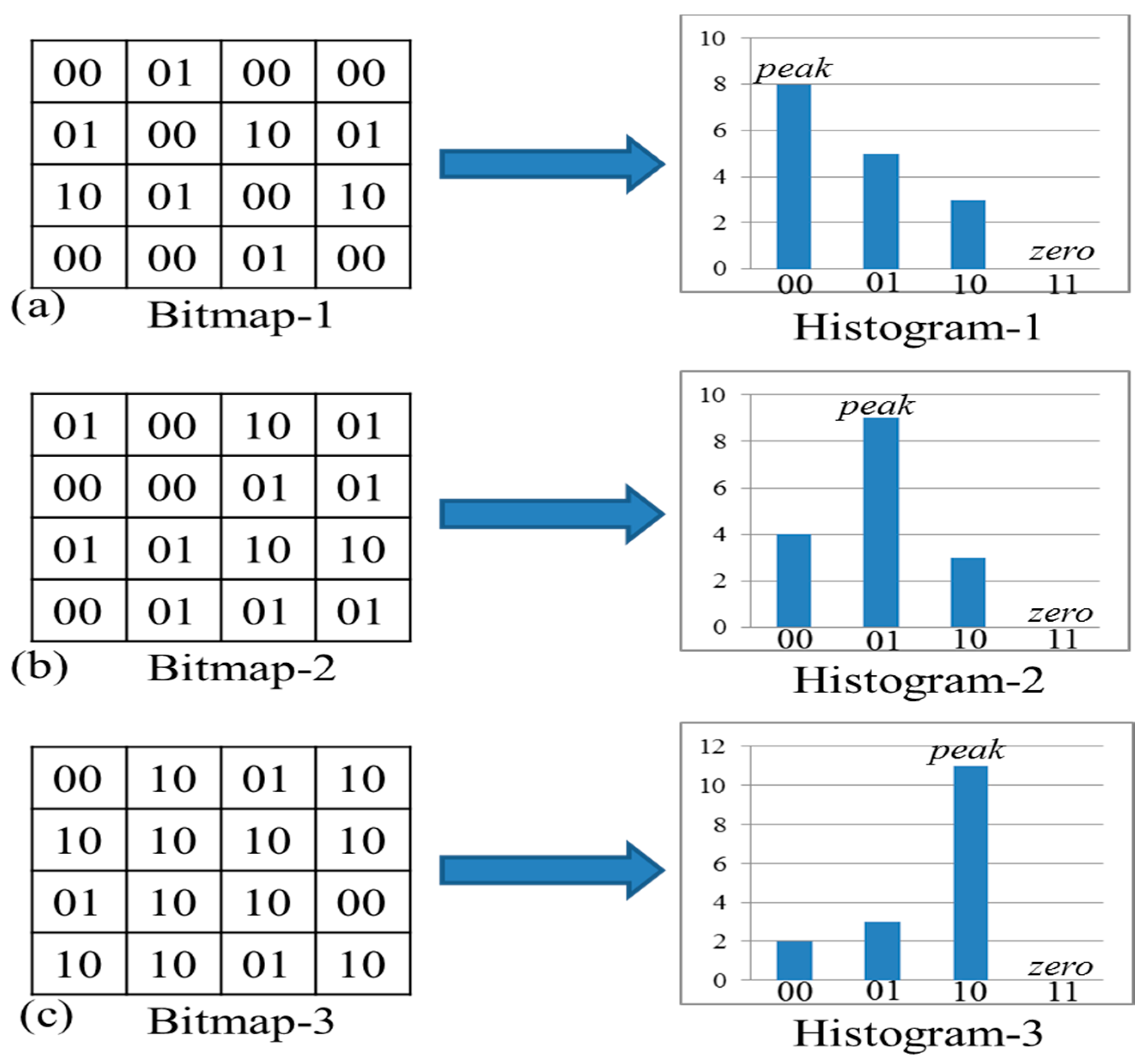
In our proposed method, there are only three histogram bins that need to addressed if the compressed blocks are determined as edge-blocks and the corresponding bit map is the source for our ZPF-HS.
Figure 2 shows examples of three possible cases of the bit map for an edge-block. In ABTC-EQ, bits 11 are not being used, as shown in
Figure 2. In our scheme, zero point (
zero) is always set as 11 and the peak point (
peak) is defined as the bit values in the bit map which has a large population.
Take
Figure 2a for example: there are 8 bit values “00”, 5 bit values “01” and 3 bit values “10” in bit map-1. Therefore, peak point is defined as “00”. We exploit the first case shown in
Figure 2a as an example to explain in detail our proposed ZFP-HS in
Figure 3.
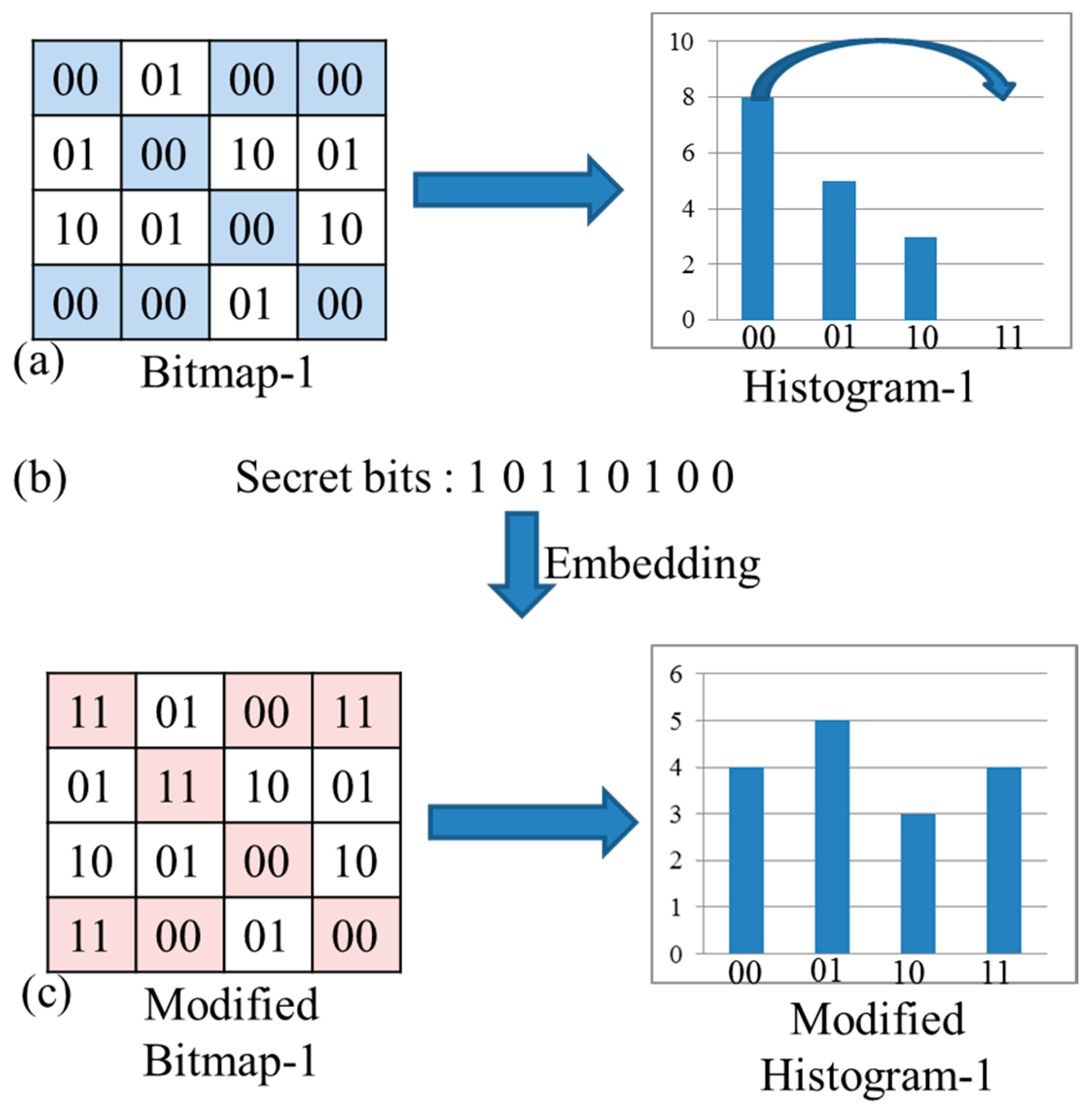
Figure 3a shows the original bit map and its corresponding histogram,
Figure 3b presents the secret data and
Figure 3c is the result of the modified bit map and its corresponding histogram after embedding. In this example,
peak is defined as “00” and
zero is defined as “11”, then according to Equation (10) with a zig-zag scan, the secret data can be embedded into the original bit map and the modified bit map is shown in
Figure 3c.
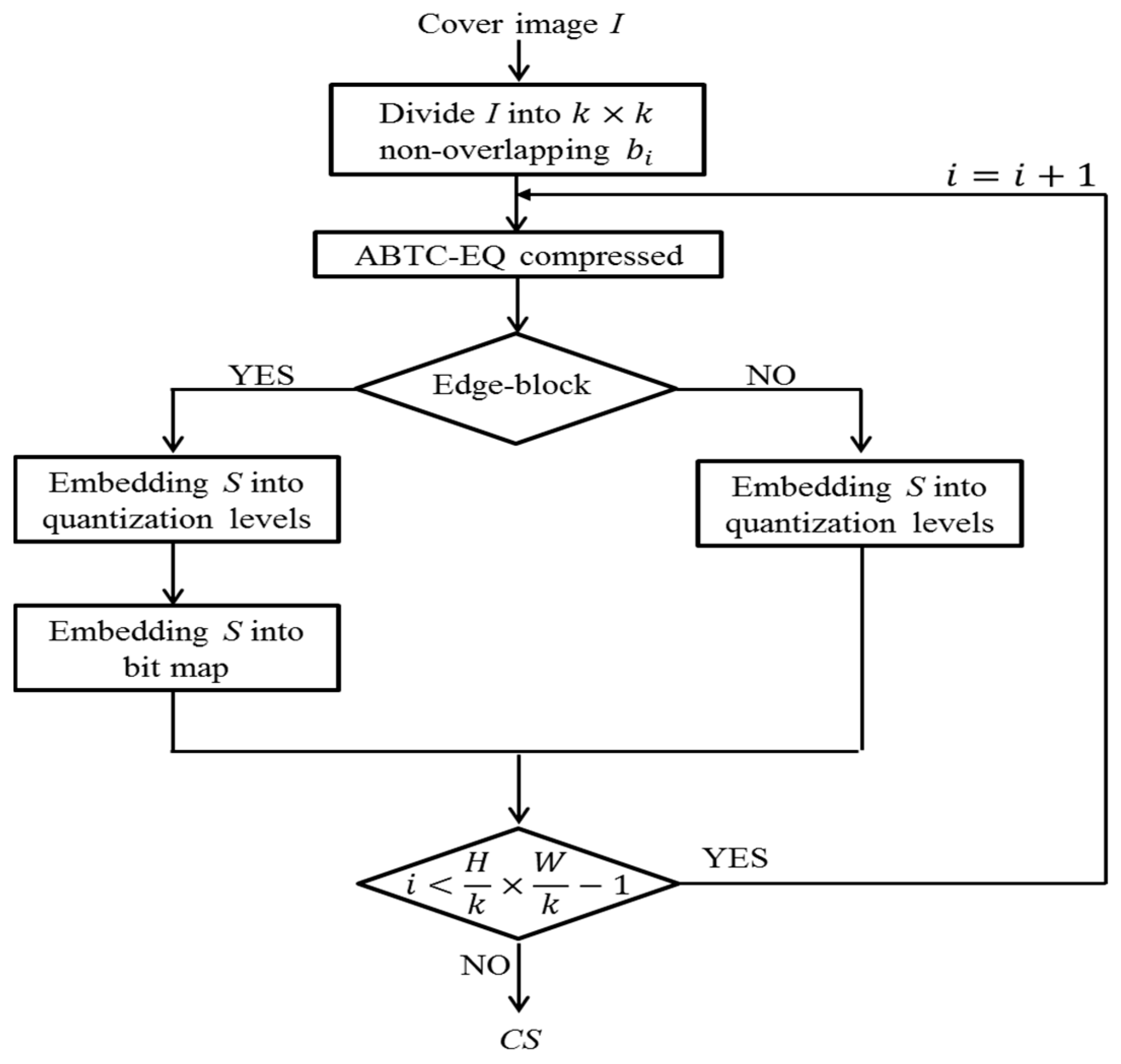
3.2. Data Embedding Phase
In our proposed data embedding phase, the embedding operations and encoding phase of ABTC-EQ are merged seamlessly. Blocks are identified as non-edge-block and edge-block after Canny edge detection. Therefore, two block types are identified and two cases of data hiding operations need to be explored in our embedding phases as shown in
Figure 4. For an edge-block case, both quantization levels and a bit map are used for data hiding. By contrast, only quantization levels are used for data embedding in a non-edge-block.
In our data embedding phase, the input cover image is sized as
. Each block
is sized
pixels, where
. Note that the ABTC-EQ procedure is also included as shown in
Figure 4. Secret information
S is a bitstream in binary form, and
is the value of a secret bit in
S, where
and
.
N is the number of maximum capacity of cover image
I. And
S is embedded into the ABTC-EQ compressed code stream of cover image
I.
Input: Cover image I and secret information S.
Output: Code stream CS.
Step 1. Divide I into non-overlapping blocks ’s.
Step 2. Utilize ABTC-EQ to compress the current processing block .
Step 3. Determine block to be edge-block or non-edge-block. If block is an edge-block, then go to Step 4. Otherwise, go to Step 8.
Step 4. Insert one bit to serve as the indicator and set it as 1. Then, use Equation (3) to compute the mean values , and of three clusters , and , respectively. Finally, cluster w, which has a large population will be encoded as , where || represents the concatenation operation and .
Step 5. Read the next from S, if , and the remaining clusters will be encoded as , where and . Otherwise, encode by .
Step 6. Embed the next from S into the and obtain a modified by using Equation (10).
Step 7. Output to be part of CS.
Step 8. Insert one bit as the indicator and set it as 0. Then, use Equations (7) and (8) to compute two quantization levels and .
Step 9. Determine the next , if the next = 0, indicator, and will be encoded by . Otherwise, it will be encoded by .
Step 10. Output the indicator, that is the sequence according to the corresponding embedding order of two quantization levels, and the original bit map to be part of CS.
Step 11. Repeat Step 2 to Step 10 until all blocks ’s are processed.
Step 12. Obtain output code stream CS.
We obtain the modified code stream
CS, which concealed the
S after all the steps are completed. An example of our proposed data embedding phase is shown in
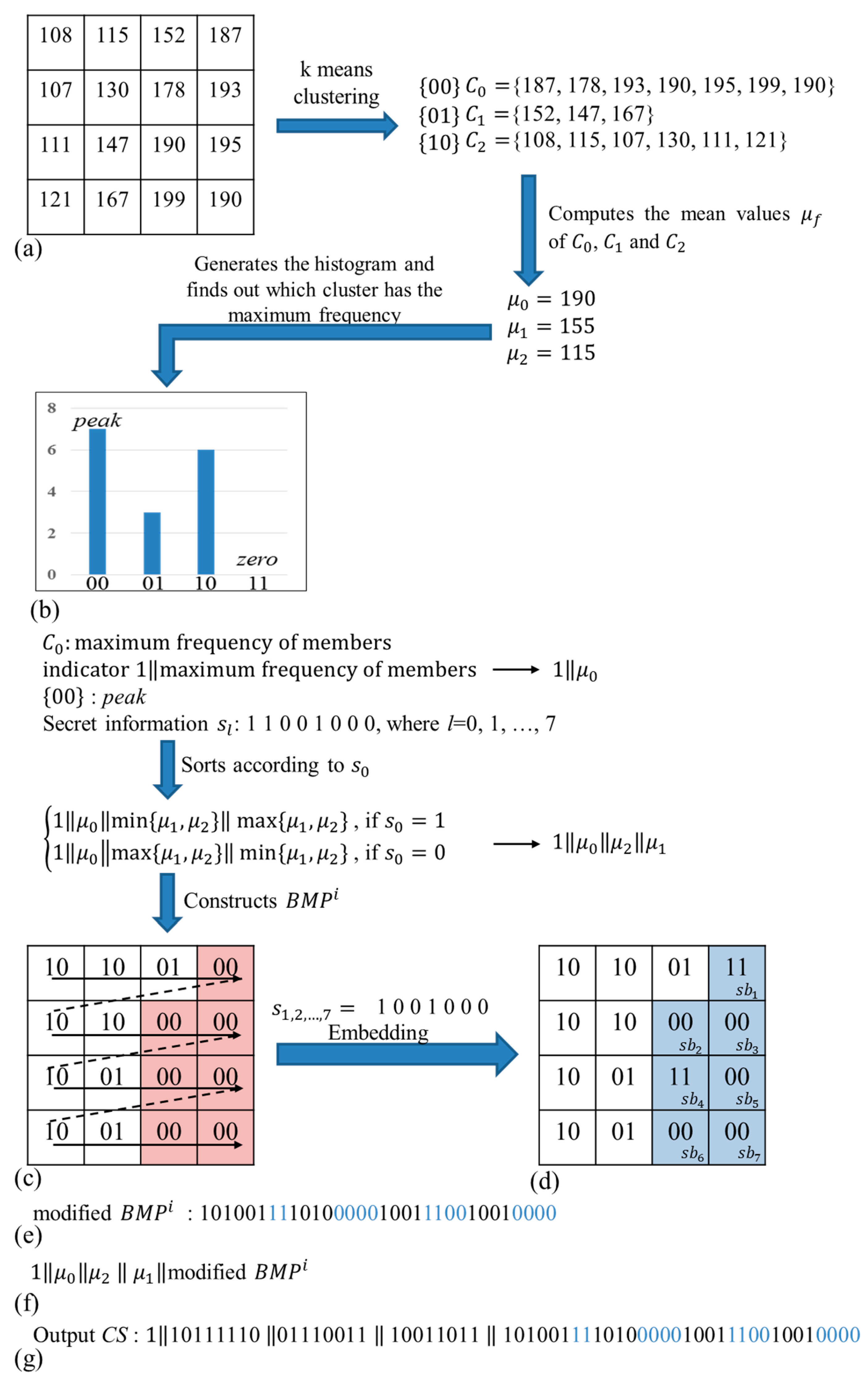
Figure 5 to explain each step in detail.
Figure 5a shows an example of a
sized block
.
Figure 5b presents the histogram of three clusters corresponding
in block
.
Figure 5c,d present the original
and the modified
, respectively.
Figure 5e provides the code stream of a modified
.
Figure 5f is the sequence of the indicator, three quantization levels and modified
.
Figure 5f presents the binary form of
Figure 5g. In
Figure 5, all pixels in block
will be partitioned into three clusters exploiting k-means clustering. Then, compute the mean values
of three clusters using Equation (3). Because
has the largest population, the
corresponding to
is
peak. The indicator and three quantization levels
’s will be encoded by
while the next
is 1. In the next step, construct
, embed the next
into
using Equation (10) and obtain the modified
. Finally, we obtain the modified code stream
CS.
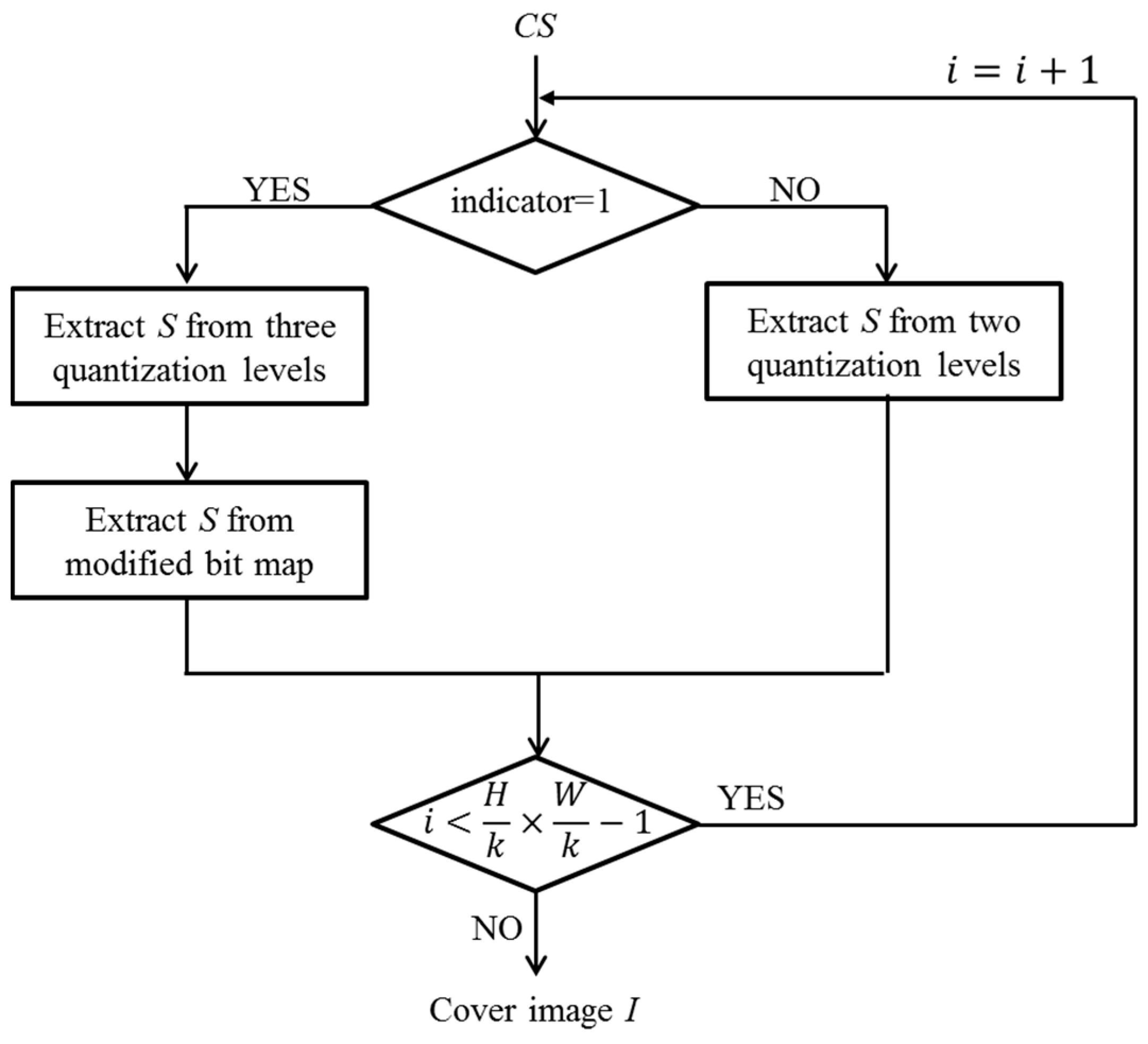
3.3. Extraction and Recovery Phase
In this section, hidden secret information
S is extracted from code stream
CS. Because one indicator has been added during our data embedding phase, a decoder can be guided by the indicator to conduct the extraction operation. If the indicator is 1, block
will be judged as an edge-block. Three quantization levels will be extracted and among three quantization levels of
will serve as the
peak. In other words, our proposed scheme does not need extra information to record the value of
peak to recover the
, as the histogram shifting technique is adopted in our scheme. Flowchart for extraction and recovery phase is shown in
Figure 6.
Input: Code stream CS.
Output: Cover image I and secret information S.
Step 1. Read the 1-bit indicator in the CS and determine the value of the indicator, if the indicator value is 1, then go to Step 2. Otherwise, go to Step 8.
Step 2. Read the next 56 bits, then obtain the bit stream of three quantization levels , and , and the modified . Its sequence is .
Step 3. Determine the maximum of and . If , the hidden . Otherwise, the hidden .
Step 4. Construct the and sort , and in descending order. The value of peak is ’s corresponding .
Step 5. Extract the next from the . If , the hidden . And if , the hidden .
Step 6. Modify zero back to peak where .
Step 7. Decompress block according to each ’s corresponding quantization level.
Step 8. Read the next 32 bits, then obtain the bit stream of two quantization levels and , and the original . Its sequence is .
Step 9. Determine the maximum of and . If , the hidden . Otherwise, the hidden .
Step 10. Sort and in descending order and decompress block according to each ’s corresponding quantization level.
Step 11. Repeat Steps 1 to 10 until all bits in CS are read and proceeded.
Step 12. Obtain secret information S and decompressed cover image I.
After all steps are completed, decompressed cover image
I and secret information
S are obtained. We also provide an example to further clarify the extraction and recovery phases, which is shown in
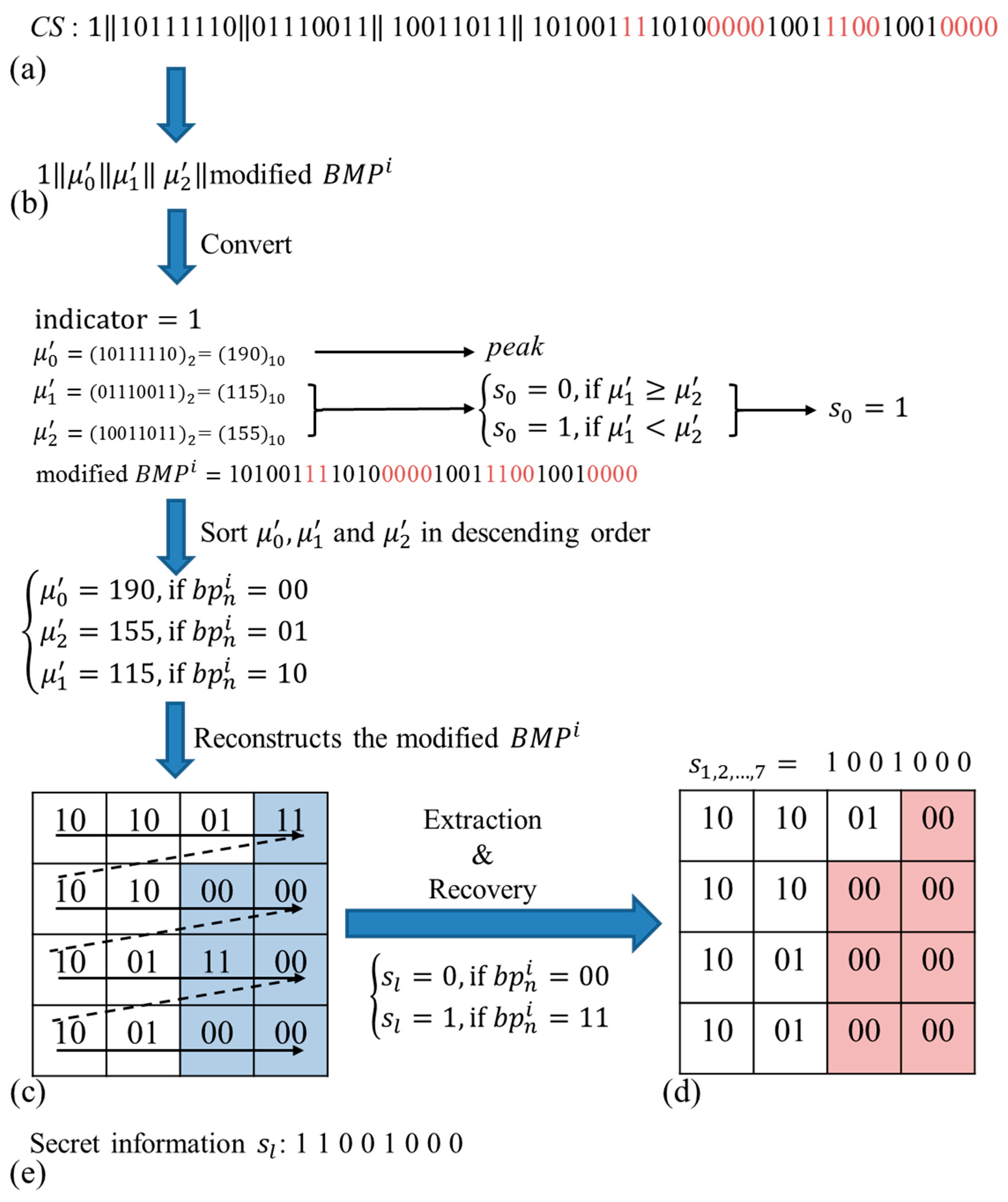
Figure 7.
Figure 7a shows the
CS in binary form,
Figure 7b presents the sequence of indicator, three quantization levels and modified
,
Figure 7c shows the modified
,
Figure 7d presents the original
and
Figure 7e provides the extracted
S. In Step 1, three quantization levels
, and
are converted into decimal values. Because
, hidden
. In Step 2,
, and
are sorted in descending order, and
corresponding to
is
peak, so the
of
peak is determined as 00. As the next step, the modified
is constructed and
are extracted from a modified
. If
, the hidden
. If
, the hidden
. After extracting all
S from the modified
, change all
values of 11 into
peak. Finally, we can obtain the original
as shown in
Figure 7d.
4. Experimental Results
We describe some experimental results in this section to demonstrate hiding capacity, output code stream size and the compression ratio in our proposed method. The eleven
test grayscale cover images as shown in
Figure 8 were used for our experiments. The results of their edge images based on Canny edge detection are shown in
Figure 9.
To illustrate the performance of our proposed method, the results of our scheme with two different block sizes,
pixels and
, are shown in
Table 1 and
Table 2, respectively. In
Table 1 and
Table 2, we present embedding capacity (number of bits), the size of
CS (number of bits), compressed ratio (
CR) (%) and peak signal-to-noise-ratio (
PSNR) (dB) of ABTC-EQ and BTC in two different block sizes,
pixels and
, respectively. Obviously, compressing the image to exploit ABTC-EQ can obtain an overall better image quality than BTC, as seen in
Table 1 and
Table 2 by exploiting Equation (12). Because our scheme embeds the secret data into the compression code stream, a decompressed image cannot be directly obtained from the
CS that carries the hidden secret data. As for
PSNR (db), it denotes the decompressed image of the recovery
CS. The
CR of conventional BTC is 0.25 using Equation (11). The size of output
CS (number of bits) and
PSNR (dB) using ABTC-EQ in the case of an
block size for
is similar to the result of the BTC of the
block size for
. In our scheme, we utilize the characteristic of ABTC-EQ to apply our proposed ZPF-HS to embed the secret data, and we see that the size of
CS before and after hiding are the same in our method. Despite the size, our
CS (number of bits) is very large because of the cost of bits, while
is the edge-block. But the problem of a blocking effect can be better solved with our method than with other compression methods. The average hiding capacity (number of bits) and
PSNR (dB) in our experiment are 74,138 (number of bits) and 36.327 (number of bits), respectively. Additionally, the PSNR (dB) means the resulting image after extracting the secret information in
Table 1 and
Table 2.
From
Table 1, we can see that the average capacity is around 74,000 bits and the
CR is about 0.3358% when the block size is
pixels.
In comparison, we can see that the average capacity is up to 90,000 bits and the
CR is about 0.2409% when the block size is
pixels as shown in
Table 2. Certainly, the average image quality will be slightly decreased to 33.368 dB, but it is significantly higher than the average PSNR offered by conventional BTC.
To demonstrate the performance results for our proposed scheme, the proposed method in this experiment was compared to previous schemes, i.e., Chang et al. [
14], Li et al. [
15], Sun et al. [
16] and Lin et al. [
19] in terms of embedding capacity (number of bits) and embedding efficiency (
EF) (%), the results of which are shown in
Table 3. These four existing schemes are selected and compared with our proposed scheme because they are reversible data hiding schemes and they are either designed for BTC or AMBTC. Moreover, their hiding strategies are embedding secrets into bitmap and two quantization levels, which are the same as ours. Here,
EF was used to evaluate embedding efficiency, which is defined as follows:
where
is the size of the output
CS and Capacity is the embedding capacity of each test image.
In this experiment, the size of all test images were
pixels and the block size was set as
. In this experiment, our embedding capacity was better than three previous schemes [
14,
16,
17]. While Lin et al.’s scheme provides good hiding capacity performance, their scheme extracts the secret data from the
resulting images instead of extracting the secret information from the output
CS (number of bits). Therefore, the size of each
CS (number of bits) in Lin et al.’s scheme is
. The size of our
CS (number of bits) remains unchanged even after embedding the secret information. In our scheme, the sizes of
CS’s for, “Lena,” “F-16,” “Sailboat,” “Girl,” “Toys” and “Barbara” are 480,096 (number of bits); 474,264 (number of bits); 495,432 (number of bits); 544,104 (number of bits); 455,112 (number of bits) and 510,048 (number of bits), respectively, and are shown in
Table 3. For the purpose of having a better comparison with the previous four methods, we utilize
EF (%) to analyze the performance of our scheme and compare to other schemes using Equation (13). Our proposed scheme obtained a higher
EF than the previous four methods. Moreover, the
EF offered by Lin et al.’s scheme is lower than ours because their results are presented as images rather than from the code stream.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}