A System of Mining Semantic Trajectory Patterns from GPS Data of Real Users

Abstract
:1. Introduction
2. Problem Statement and Solution Process
2.1. Problem Statement
2.2. Solution Process
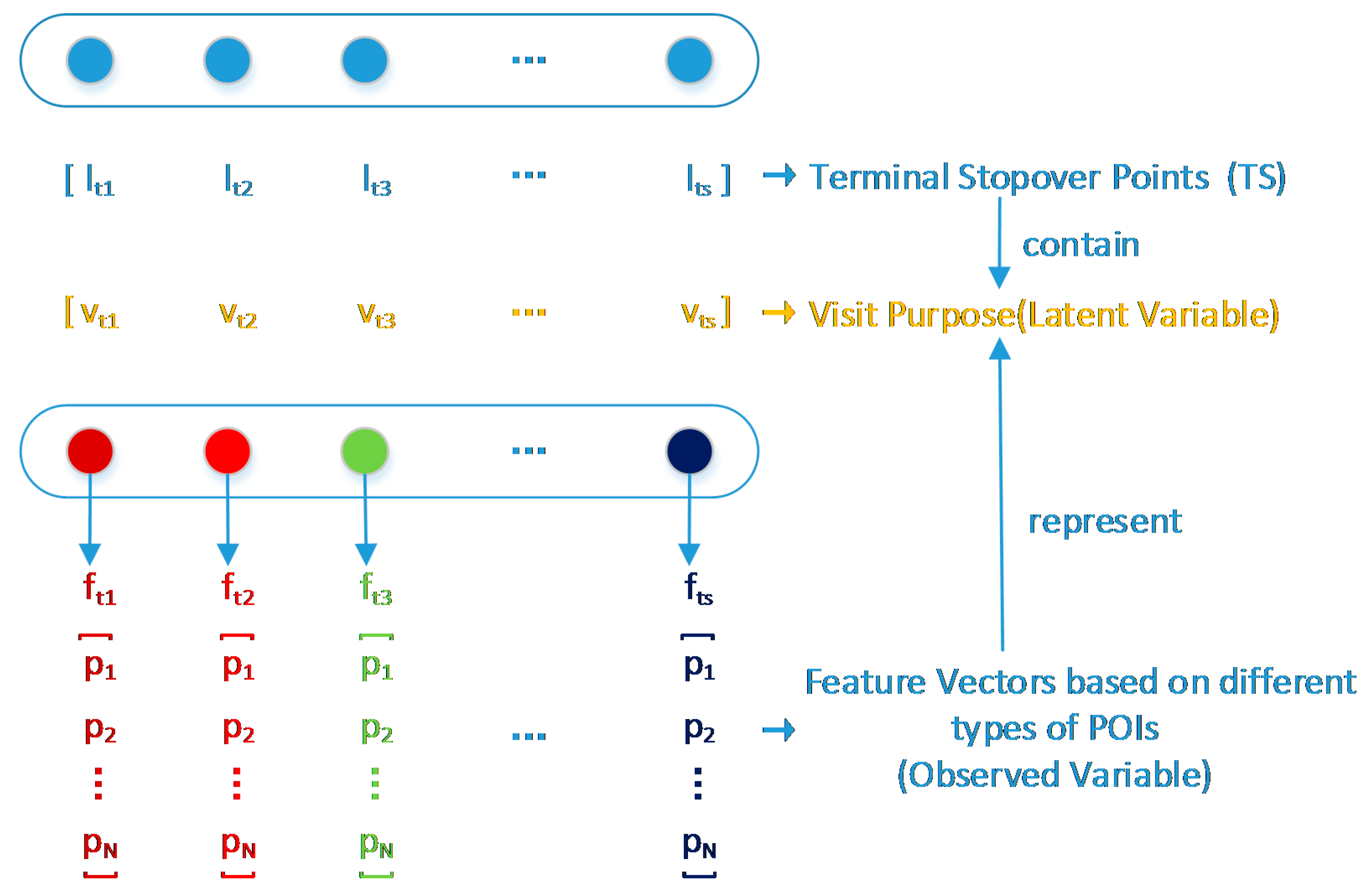
2.2.1. Stopover Points Extraction
2.2.2. Map Matching
2.2.3. Semantic Trajectory Patterns Mining
3. Experimental Evaluation
3.1. Research Datasets
3.2. Compared Methods and Performance Metrics
3.3. Case Study
- It usually takes the user 20 min to have dinner at the New Dining Hall at around 17:30.
- After dinner, the user is fond of going to the gymnasium for about half an hour.
- At around 20:00, the user likes going to the library for about an hour and a half.
- The user is probably a graduate student of the university.
- The user may have the habit of breaking for lunch for around 25 min at their apartment.
3.4. Comparative Study
4. Further Work
Author Contributions
Funding
Data Availability
Conflicts of Interest
References
- Yuan, J.; Zheng, Y.; Xie, X. Discovering regions of different functions in a city using human mobility and pois. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012. [Google Scholar]
- Lee, A.J.T.; Chen, Y.-A.; Ip, W.-C. Mining frequent trajectory patterns in spatial-temporal databases. Inf. Sci. 2009, 179, 2218–2231. [Google Scholar] [CrossRef]
- Monreale, A.; Pinelli, F.; Trasarti, R.; Giannotti, F. Wherenext: A location predictor on trajectory pattern mining. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009. [Google Scholar]
- Lee, J.-G.; Han, J.; Li, X. A unifying framework of mining trajectory patterns of various temporal tightness. IEEE Trans. Knowl. Data Eng. 2015, 27, 1478–1490. [Google Scholar] [CrossRef]
- Frentzos, E. Trajectory Data Management in Moving Object Databases. Ph.D. Thesis, University of Piraeus, Piraeus, Greece, 2008. [Google Scholar]
- Güting, R.H.; Schneider, M. Moving Objects Databases, 1st ed.; Morgan Kaufmann: Orlando, FL, USA, 2005. [Google Scholar]
- Han, J.; Lee, J.-G.; Gonzalez, H.; Li, X. Mining Massive RFID, Trajectory, and Traffic Data Sets (Tutorial). In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008. [Google Scholar]
- Jeung, H.; Yiu, M.L.; Zhou, X. Discovery of Convoys in Trajectory Databases. In Proceedings of the 34th International Conference on Very Large Data Bases (VLDB), Auckland, New Zealand, 24–30 August 2008; pp. 1068–1080. [Google Scholar]
- Li, Z.; Ji, M.; Lee, J.-G. MoveMine: Mining Moving Object Databases. In Proceedings of the ACM SIGMO Conference, Indianapolis, IN, USA, 6–11 June 2010; pp. 1203–1206. [Google Scholar]
- González, M.C.; Hidalgo, C.A.; Barabási, A.L. Understanding Individual Human Mobility Patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef] [PubMed]
- Rawassizadeh, R.; Dobbins, C.; Akbari, M.; Pazzani, M. Indexing Multivariate Mobile Data through Spatio-Temporal Event Detection and Clustering. Sensors 2019, 19, 448. [Google Scholar] [CrossRef] [PubMed]
- Ghahramani, M.; Zhou, M.C.; Hon, C.T. Mobile Phone Data Analysis: A Spatial Exoloration Toward Hotspot Detection. IEEE Trans. Autom. Sci. Eng. 2019, 16, 351–362. [Google Scholar] [CrossRef]
- Bhattacharya, T.; Kulik, L.; Bailey, J. Automatically Recognizing Places of Interest from Unreliable GPS Data Using Spatio-temporal Density Estimation and Line Intersections. Pervasive Mob. Comput. 2015, 19, 86–107. [Google Scholar] [CrossRef]
- Christensen, R.; Wang, L.; Li, F.; Yi, K.; Tang, J.; Villa, N. STORM: Spatio-Temporal Online Reasoning and Management of Large Spatio-Temporal Data. In Proceedings of the ACM SIGMOD Conference, Melbourne, Australia, 31 May–4 June 2015; pp. 1111–1116. [Google Scholar]
- Geolife GPS Trajectories. Available online: https://www.microsoft.com/en-us/download/confirmation.aspx?id=52367 (accessed on 10 March 2019).
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An efficient k-means clustering algorithm: Analysis and implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- Palma, A.T.; Bogorny, V.; Kuijpers, B.; Alvares, L.O. A cluster-based approach for discovering interesting places in trajectories. In Proceedings of the 2008 ACM Symposium on Applied Computing, Fortaleza, Brazil, 16–20 March 2008; pp. 863–868. [Google Scholar]
- Kim, Y.; Han, J.; Yuan, C. Toptrac: Topical trajectory pattern mining. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2015; pp. 587–596. [Google Scholar]
- Rawassizadeh, R.; Pierson, T.; Peterson, R.; Kotz, D. NoCloud: Experimenting with Network Disconnection by Design. IEEE Pervasive Comput. 2018, 17, 64–75. [Google Scholar] [CrossRef]
- Wang, Y. Definition and Categorization of Dew Computing. Open J. Cloud Comput. 2016, 3, 1–7. [Google Scholar]
- Gusev, M. A dew computing solution for IoT streaming devices. In Proceedings of the MIPRO, Opatija, Croatia, 22–26 May 2017; pp. 387–392. [Google Scholar]
- Jie, L.; Shuhui, C.; Jinshu, S. Implementation of TCP large receive offload on multi-core NPU platform. In Proceedings of the ICTC, Jeju, Korea, 15 July 2016; pp. 258–263. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Users (Source) | Semantic Trajectory Patterns | Support |
|---|---|---|
| 1(GPS) | 1241 | |
| 2(BDS) | 774 | |
| 3(GPS) | 658 | |
| 4(GPS) | 519 | |
| 5(BDS) | 443 |
(No.2 Graduate Students’ Apartment to Laboratory) | (Laboratory to New Dining Hall) | (New Dining Hall to Gymnasium) | (Gymnasium to Library) |
|---|---|---|---|
| 14:06→14:30 | 17:21→17:40 | 18:30→19:03 | 20:03→21:30 |
| 13:57→14:25 | 17:35→17:50 | 18:50→19:17 | 19:53→21:25 |
| 13:56→14:40 | 17:30→17:47 | 18:45→19:13 | 20:01→21:32 |
| 14:10→14:32 | 17:41→17:57 | 19:01→19:28 | 20:10→21:29 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Wang, X.; Huang, Z. A System of Mining Semantic Trajectory Patterns from GPS Data of Real Users. Symmetry 2019, 11, 889. https://doi.org/10.3390/sym11070889
Zhang W, Wang X, Huang Z. A System of Mining Semantic Trajectory Patterns from GPS Data of Real Users. Symmetry. 2019; 11(7):889. https://doi.org/10.3390/sym11070889
Chicago/Turabian StyleZhang, Wanlong, Xiang Wang, and Zhitao Huang. 2019. "A System of Mining Semantic Trajectory Patterns from GPS Data of Real Users" Symmetry 11, no. 7: 889. https://doi.org/10.3390/sym11070889