1. Introduction
We are concerned with the problem of solving a system of nonlinear equations
This problem can precisely be stated as to find a solution vector
such that
, where
is the given nonlinear vector function
and
. The vector
can be computed as a fixed point of some function
by means of fixed point iteration
Many applied problems in Science and Engineering are reduced to solve numerically the system
of nonlinear equations (see, for example [
1,
2,
3,
4,
5,
6]). A plethora of iterative methods are developed in literature for solving such equations. A classical method is cubically convergent Chebyshev’s method (see [
7])
where
. This one-point iterative scheme depends explicitly on the first two derivatives of
F. In [
7], Ezquerro and Hernández present modification in Chebyshev’s method that avoids the computation of second derivative
while maintaining third-order of convergence. It has the following form:
There is an interest in constructing derivative free iterative processes obtained by considering an approximation of the first derivative of
F from a divided difference of first order. One class of such methods is called the class of Secant-type methods which is obtained by replacing
with the divided difference operator
. Using this operator a family of derivative free methods is given in [
8]. The authors call this family the Chebyshev-Secant-type method and it is defined as
where
and
c are non-negative parameters.
Another class of derivative free methods is the class of Steffensen-type processes that replaces
with operator
, wherein
. The work presented in [
9] analyzes Steffensen-type iterative method which is given as
For
and
,
is an arbitrary non-zero constant, this method possesses third order convergence. In this case
is Traub-Steffensen iteration [
6]. For
,
belongs to Steffensen iteration [
10]. Both of these iterations are quadratically convergent.
The two-step third order Traub-Steffensen-type method, i.e., the case of (
6) for
, can be written as
where
is the quadratically convergent Traub-Steffensen scheme. Here and in the sequel, the symbol
is used for denoting an
i-th iteration function of convergence order
p. It can be observed that the third order scheme (
7) is computationally more efficient than quadratically convergent Traub-Steffensen scheme. The reason is that the convergence order is increased from two to three at the cost of only one function evaluation without adding extra inverse operator. We discuss computational efficiency in later sections.
Researchers have always been trying to develop the iterative method with increasing efficiency since different methods converge to the solution with different convergence speed. This can be done either by increasing the convergence order or by decreasing the computational cost or both. In [
11], Ren et al. have derived a fourth order derivative-free method that uses three
F, three divided differences and two matrix inversions per iteration. Zheng et al. [
12] have constructed two families of fourth order derivative-free methods for scalar nonlinear equations, that are extendable to solve systems of nonlinear equations. First family requires to evaluate three
F, three divided differences and two matrix inversions, whereas the second family needs three
F, three divided differences and three matrix inversions. Grau et al. presented a fourth order derivative-free method in [
13] utilizing four
F, two divided differences and two matrix inversions. Sharma and Arora [
14] presented a fourth order derivative-free method that uses the evaluations of three
F, three divided differences and one matrix inversion per each step.
In search of more fast techniques, researchers have also introduced sixth and seventh order derivative-free methods in [
13,
15,
16,
17,
18]. The sixth order method in [
13] proposed by Grau et al. requires five
F, two divided differences and two matrix inverses. Sharma and Arora [
17] also developed a method of at least sixth order which requires evaluation of five functions, two divided difference and one matrix inversion per iteration. The seventh order method proposed by Sharma and Arora [
15] utilizes four
F, five divided differences and two matrix inversions per iteration. The seventh order methods presented by Wang and Zhang [
16] use four
F, five divided differences and three matrix inversions. Ahmad et al. [
18] proposed eighth order derivative free method without memory which uses six functions evaluations, three divided difference and one matrix inversion.
The main goal in this study is to develop a derivative-free method of high computational efficiency, that means a method with high convergence speed and low computational cost. Consequently, we present a Traub-Steffensen-type method of fifth order of convergence which requires the evaluations four
F, two divided differences and only one matrix inversion per step. The scheme of the present contribution is simple and consists of three steps. Of the three steps, the first two are that of cubically convergent Traub-Steffensen-type scheme (
7) whereas the third is derivative-free modification of Chebyshev’s scheme (
3). We show that the proposed method is more efficient than existing methods of similar nature.
The content of the rest of the paper is summarized as follows. Basic definitions relevant to the present work are stated in
Section 2. In
Section 3, the scheme of fifth order method is introduced and its convergence behavior is studied. In
Section 4, the computational efficiency of the new method is examined and also compared with the existing derivative-free methods. In
Section 5, the basins of attractors are presented to check the stability and convergence of the new method. Numerical tests are performed in
Section 6 to verify the theoretical results as proved in
Section 3 and
Section 4.
Section 7 contains the concluding remarks.
3. The Method and Analysis of Convergence
Let us begin with the following three-step scheme
where
,
I is
identity matrix and
.
Note that this is a scheme whose first two steps are that of third order Traub-Steffensen-type method (
7) whereas third step is based on Chebyshev’s method (
3). The scheme requires first and second derivatives of
F at
. To make this a derivative-free method, we describe an approach as follows:
Consider the Taylor expansion of
about
Using the fact that
(see, for example [
4,
5]), we can write (
15) as
Then, using the second step of (
13) in the above equation, it follows that
Let us assume
, then (
17) implies
In addition, we have that
Using (
18) in (
19), we obtain that
Now, we can write the third-step of (
13) in modified form as
Thus, we define the following new method:
wherein
.
Since the scheme (
22) is composed of Traub-Steffensen like steps, we call it the Traub-Steffensen-like method.
In order to explore the convergence properties of Traub-Steffensen-like method, we recall some important results from the theory of iteration functions. First, we state the following well-known result (see [
3,
23]):
Lemma 1. Assume that has a fixed point and is differentiable on α. Ifthen α is a point of attraction for the iteration , where ρ is a spectral radius of . Next, we state a result which has been proven in [
24] by Madhu et al. and that shows
is a point of attraction for a general iteration function of the form
.
Lemma 2. Let be sufficiently differentiable at each point of an open convex set D of , which is a solution of the nonlinear system . Suppose that are sufficiently differentiable functions (depending on F) at each point in the set D with the properties , , . Then, there exists a ballon which the mappingis well defined. Moreover, is differentiable at α, thus Let us also recall the definition (
10) of divided difference operator. Then, expanding
in (
10) by Taylor series at the point
x and thereafter integrating, we have that
where
Let
. Assuming that
exists, then expanding
and its first three derivatives in a neighborhood of
by Taylor’s series, we have that
and
where
and
.
We are in a situation to analyze the behavior of Traub-Steffensen-like method. Thus, the following theorem is proved:
Theorem 1. Let be sufficiently differentiable at each point of an open convex set D of , which is a solution of . Assume that and is continuous and nonsingular at α, and close to α. Then, α is a point of attraction of the sequence generated by the Traub-Steffensen-like method (22). Furthermore, the sequence so developed converges locally to α with order at least 5. Proof. First we show that
is a point of attraction of Traub-Steffensen-like iteration. In this case, we have that
Now, since
,
, we have
so that
and by Lemma 1,
is a point of attraction of (
22).
Let
Then using (
25), it follows that
Setting
,
,
in Equation (
24) and then using (
26)–(
29), we can write
where
,
,
and
.
Expansion of the inverse of preceding divided difference operator is given as
By using (
25) and (
31) in the first step of method (
22), we get
Taylor expansion of
about
yields,
From the second step of (
22), on using (
31) and (
33), it follows that
By Taylor expansion of
about
,
Equation (
24), for
,
and
, yields
From (
31) and (
36), we have
Equations (
31) and (
37) yield
Applying Equations (
34), (
35) and (
38) in the last step of method (
22) and then simplifying, we get the error equation
This completes the proof of Theorem 1. □
Thus, the Traub-Steffensen-like method (
22) defines a one-parameter
family of derivative-free fifth order methods. Now onwards we denote it by
. In terms of computational cost
utilizes four functions, two divided difference and one matrix inversion per each step. In the next section we will compare the computational efficiency of the new method with the existing derivative-free methods.
4. Computational Efficiency
In order to find the computational efficiency we will use the definition given in
Section 2.3. The various evaluations and arithmetic operations that contribute towards the cost of computation are described as follows. For the computation of
F in any iterative function we evaluate
m scalar functions
and when computing a divided difference
(see,
Section 2.2) we evaluate
scalar functions, wherein
and
are evaluated separately. Furthermore, one has to add
divisions from any divided difference. For the computation of inverse linear operator, a linear system can be solved that requires
products and
divisions in the LU decomposition process, and
products and
m divisions in the resolution of two triangular linear systems. Moreover, we add
m products for the multiplication of a vector by a scalar and
products for multiplying a matrix by a vector or of a matrix by a scalar.
The comparison of computational efficiency of the present method
is drawn with second order method
; third order method
; fourth order methods by Ren et al. [
11], Grau et al. [
13] and Sharma-Arora [
14]; fifth order method by Kumar et al. [
25]; sixth order method by Grau et al. [
13]; seventh order methods by Sharma-Arora [
15] and Wang-Zhang [
16]. These methods are expressed as follows:
Fourth order method by Ren et al. (
):
where
.
Fourth order method by Grau et al. (
):
where
and
.
Sharma-Arora fourth order method (
):
where
,
is a non-zero constant.
Fifth order method by Kumar et al. (
):
where
.
Sixth order method by Grau et al. (
):
Wang-Zhang seventh order method (
):
where
.
Sharma-Arora seventh order method (
):
Let us denote efficiency indices of the methods
by
and their computational costs by
. Then, using the definition of the
Section 2.3 taking into account the above considerations of evaluations and operations, we have that
To compare the efficiency of considered iterative methods, say
against
we consider the ratio
It is clear that when , the iterative method is more efficient than
versuscase:
For this case the ratio (
50) is given by
It can be easily shown that for . This implies that for . Thus, is more efficient than as we have stated in the introduction section.
versuscase:
The ratio (
50) is given by
It is easy to prove that
for
. Thus, we conclude that
for
.
versuscase:
The ratio (
50) is given by
It can be checked that for . Thus, we have that for .
versuscase:
In this case the ratio
for
, which implies that
for
versuscase:
Here the ratio
for
which implies that
for
.
versuscase:
Here the ratio
for
which implies that
for
.
versuscase:
In this case the ratio
for
which means
for
.
versuscase:
Here the ratio
for
which means
for
.
versuscase:
Here also the ratio
for
which means
for
.
versuscase:
Here also the ratio
for
which means
for
.
The above results are summarized in the following theorem:
Theorem 2. We have that
- (a)
- (b)
- (c)
- (d)
- (e)
5. Complex Dynamics of Methods
Our aim is to analyze the complex dynamics of the new method based on graphical tool ‘basins of attraction’ of the zeros of polynomial
in complex plane. Visual display of the basins gives important information about the stability and convergence of iterative methods. This idea was introduced initially by Vrscay and Gilbert [
26]. In recent times, many authors have used this concept in their work, see, for example [
27,
28] and references therein. We consider the method (
22) to analyze the basins of attraction.
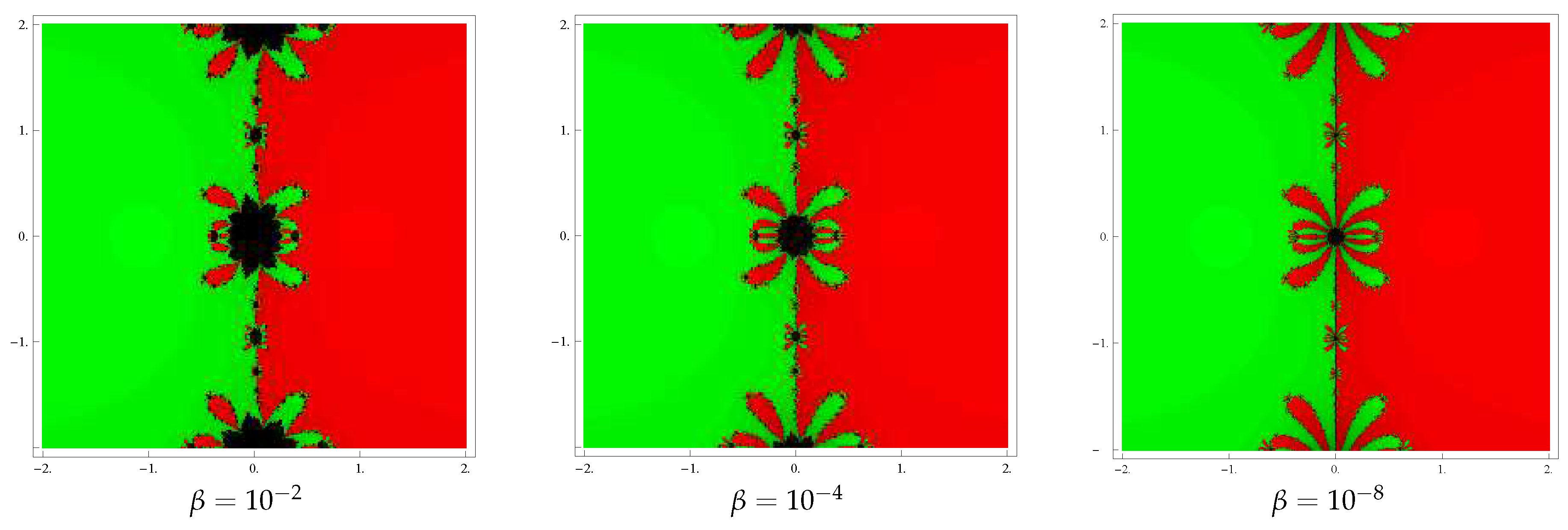
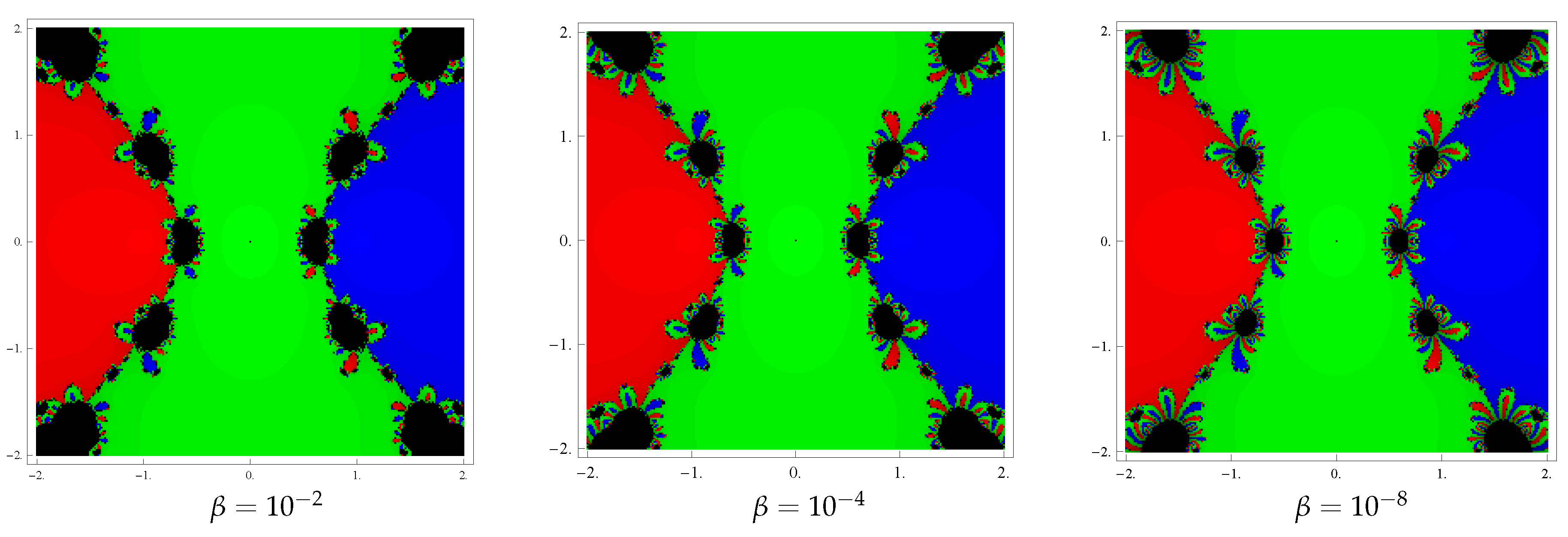
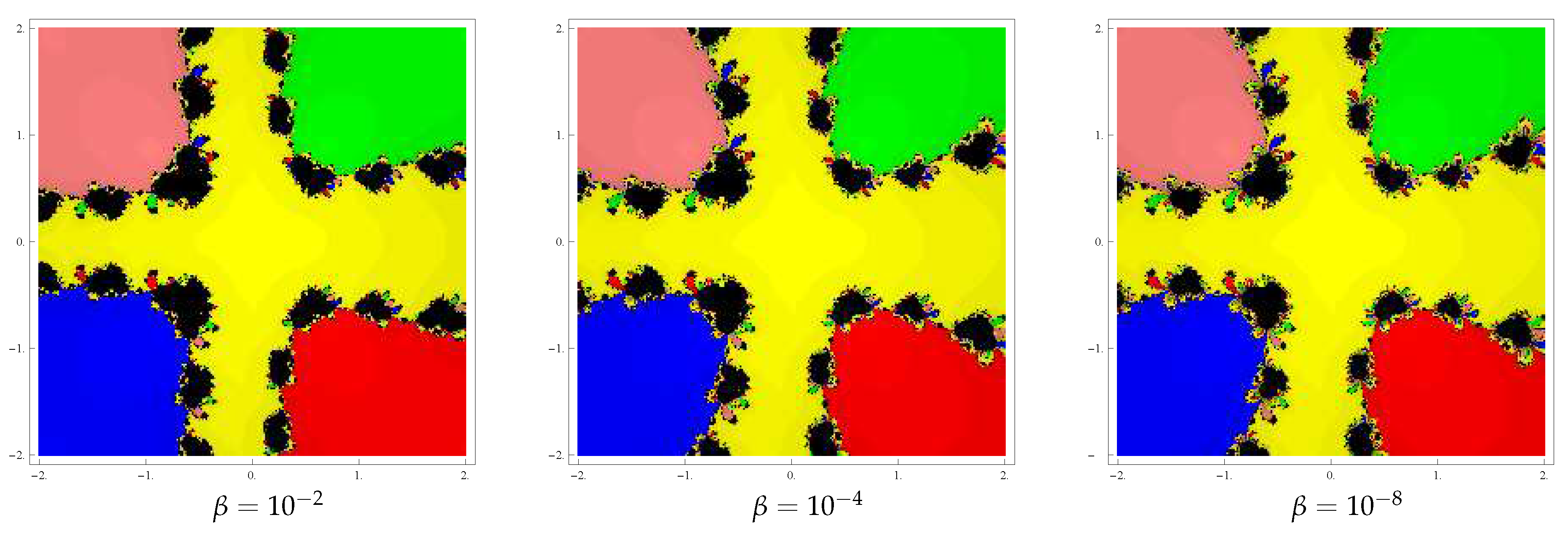
To start with we take the initial point in a rectangular region that contains all the zeros of a polynomial The iterative method, when starting from point in a rectangle, either converges to the zero or eventually diverges. Stopping condition for convergence is considered as to a maximum of 25 iterations. If the required tolerance is not achieved in 25 iterations, we conclude that the iterative scheme starting at point does not converge to any root. The strategy adopted is as follows: A color is allocated to each initial point in the basin of attraction of a zero. If the iteration initiating at converges, then it represents the attraction basin with that assigned color to it, otherwise in the failing (divergence) situation in 25 iterations the iteration represents the black color.
We analyze the basins of attraction of the new method (for the choices ) on following three polynomials:
Example 1. In the first case, consider the polynomial which has zeros . A grid of points in a rectangle of size is used for drawing the graphics. We assign the color red to each initial point in the basin of attraction of zero ‘1’
and the color green to the points in the basin of attraction of zero ‘’. The graphics are shown in Figure 1 corresponding to . Observing the behavior of the basins of the new method, we conclude that the convergence domain becoming wider as parameter β assumes smaller values since black zones (divergent points) are getting smaller in size. Example 2. Let us consider the next polynomial as having zeros . To draw the dynamical view, we select a rectangle containing grid points. Then, allocate the colors green, blue and red to each point in the basin of attraction of 0, 1
and , respectively. Basins for this example are exhibited in Figure 2 corresponding to parameter choices in the proposed methods. In addition, observe that the basins are becoming larger and larger with the smaller values of β. Example 3. Lastly, we consider the polynomial as having zeros . To draw the dynamical view, we select a rectangle containing grid points. Then, allocate the colors green, blue, red, yellow and pink to each point in the basin of attraction of , , , and , respectively. Basins for this example are exhibited in Figure 3 corresponding to parameter choices in the proposed methods. We observe that the basins are getting larger with the smaller values of β. 6. Numerical Tests
In this section, some numerical tests on different problems are performed to demonstrate the convergence behavior and computational efficiency of the method
. A comparison between the performance of
with the existing methods
,
,
and
is also drawn. The programs are performed in the processor with specifications Intel (R) Core (TM) i5-4210U CPU @ 1.70 GHz 2.40 GHz (64-bit Operating System) Microsoft Windows 10 Professional and are complied by
Mathematica 10.0 using multiple-precision arithmetic. We record the number of iterations
required to converge to the solution such that the stopping condition
is satisfied. In order to verify the theoretical order of convergence, the computational order of convergence
is obtained by using the Formula (
8). In the comparison of performance of considered methods, we also include the real CPU time elapsed during the execution of program computed by the
Mathematica command “TimeUsed[ ]”.
The methods , , and are tested by using the value for the parameter . In numerical experiments we consider the following five problems:
Example 4. Let us consider the system of two equations (selected from [29]): The initial guess assumed is for obtaining the solution Example 5. Now considering the mixed Hammerstein integral equation (see [4]):wherein ; and the kernel G isThe above equation is transformed to a finite-dimensional problem by using the Gauss-Legendre quadrature formulawhere the weights and abscissas are obtained for by Gauss-Legendre quadrature formula. Then, setting , we obtain the following system of nonlinear equationswherewherein the abscissas and the weights are known and produced in Table 1 for . The initial approximation assumed isand the solution of this problem is: Example 6. Consider the system of 20 equations (see [29]): This problem has the following two solutions:and We intend to find the first solution and so choose the initial value: .
Example 7. Consider the boundary value problem: Assuming the following partitioning of the interval :
Setting If we discretize the problem by using the finite difference approximation for second derivativewe obtain a system of equations in variables: In particular, let us solve this problem for that is for by choosing as the initial value. The solution vector α of this problem is
.
Example 8. Consider the following Burger’s equation (see [30]):where and function satisfies the boundary conditions Assuming the following partitioning of the domain : Let us define and for . Then the boundary conditions would be , , and . If we discretize Burger’s equation by using the numerical formulas for the partial derivativesthen we obtain the following system of nonlinear equations in variables:where . In particular, we solve this nonlinear system for so that by selecting for as the initial value. The solution of this system of nonlinear equations is given in Table 2. In
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7 we present the numerical results produced for the methods
,
,
,
,
and
. Displayed in each table are the errors
of first three consecutive approximations to corresponding solution of Examples 4–8, number of iterations
needed to converge to the required solution, computational order of convergence
, computational cost
, computational efficiency
and elapsed CPU-time (e-time) measured in seconds. In each table the meaning of
is
. Numerical values of computational cost and efficiency are obtained according to the corresponding expressions given by (
40)–(
49). The e-time is calculated by taking the average of 50 performances of the program, where we use
as the stopping condition in a single performance of the program.
From the numerical results displayed in
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7, it can be observed that like that of the existing methods the proposed new method shows consistent convergence behavior. Seventh order methods produce approximations with large accuracy due to their higher order of convergence, but they are less efficient. In Example 6,
and
do not converge to the required solution
. Instead, they converge to solution
which is far off from initial approximation chosen. Calculation of computational order of convergence shows that the order of convergence of the new method is preserved in all the numerical examples. However, this is not true for some existing methods, e.g.,
,
,
and
, in Example 8. Values of the efficiency index shown in the penultimate column of each table also verify the theoretical results stated in Theorem 2. The efficiency results are also in complete agreement with the CPU time utilized in the execution of the program since the method with large efficiency uses less computing time than the method with small efficiency. Moreover, the proposed method utilizes less CPU time than existing higher order methods which points to the dominance of the method. In fact, the new method is especially more efficient for large systems of nonlinear equations.







{kind=link}
{kind=link}
{kind=link}