Application of Fuzzy Sets to the Expert Estimation of Scrum-Based Projects



Abstract
1. Introduction
- Utilise fuzzy numbers as estimates;
- Be based on strict rules of achieving final consensus;
- Not disregard the human factor in the process of consensus elaboration.
2. Effort Estimation Methods for Scrum—State of Art
2.1. Statistical Group Estimation Method
2.2. Unstructured Group
2.3. Planning Poker
2.4. Planning Game and Blitz Planning
2.5. Plan Delphi and Wideband Delphi
- Neither fuzzy approach nor any other modelling approach is employed by them for uncertainty/risk modelling;
- As for the consensus elaboration, two extremes are used: a purely mathematical or purely behavioural approach. No trade-off of both has been suggested.
3. Voting
- Majority criterion—each candidate which in a majority of votes is a winner should be the final winner;
- Condorcet criterion [41]—let us assume that all the candidates are combined in all the possible pairs for assessment. Then the winner shall be the candidate which is preferred by the majority of voters in this process;
- Monotonicity criterion—this criterion can be reduced to the requirement that it is neither possible to prevent the election of an elected candidate by ranking it higher in subsequent voting, nor it is possible to elect an otherwise unelected candidate by ranking it lower in subsequent voting (while nothing else is altered);
- Independence of irrelevant alternatives criterion—if the elections have been held and a winner has been chosen, the winning candidate should still be the winner in the event of recalculation of votes, when one or more of the losing candidates have been removed from voting.
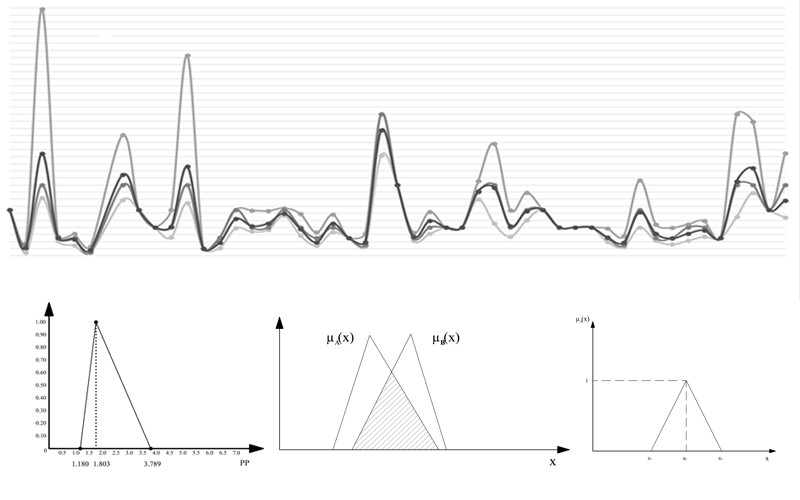
4. Theoretical Basis of Fuzzy Numbers
- (symbol means the common part of intervals)
- (a)
- Distance betweendenoted as, is defined as
- (b)
- Similarity degree between, denoted asis defined as.
5. Theory of Consensus Using Fuzzy Numbers
6. Assumptions and Basic Theory for Fuzzy Expert Estimation Method for Scrum
6.1. Assumptions to Be Fulfilled by the Method
- (1)
- Each member of the Development Team who is involved in the effort estimation gives their individual opinion about the estimate in subsequent interactions, and participates in the final decision. All the Development Team members share the general objective (a successful termination of the project in question), but may differ in their detailed views on how this objective should be achieved and on the amount of effort needed to do so;
- (2)
- No estimate value is preferred a priori;
- (3)
- Each member of the Development Team estimates the same set of feasible Product Backlog items;
- (4)
- Individual estimates are expressed in the form of fuzzy numbers;
- (5)
- There is a special actor (moderator), whose task is to ensure that the rules of the method are observed. She or he is responsible of informing the members of the Development Team about the results, but his or her opinion cannot affect the consensus;
- (6)
- Members of the Development Team accept the final decision obtained by means of the method as the final opinion of the entire Development Team.
- (7)
- The estimation method to be developed should use a quasi-fair voting procedure.
6.2. Fuzzy Representation of Effort Estimation for Product Backlog Items
7. Fuzzy Method for Expert estimation of the Effort Needed to Accomplish Product Backlog Items
- i*:
- If the experts agree to give a high weight to an estimate , so that , where is a small number, then , thus the final solution is close to the estimate clearly preferred by the majority of experts. In other words, a candidate preferred by the majority of experts is the winner.
- ii*:
- for each pair of indices it holds that if then < , thus for each pair of candidate numbers the final solution is closer to the one which is more preferred by the Development Team. In other words, a candidate preferred by the majority of experts in pairwise comparisons is the winner;
- iii*:
- Let and , where for all and Then we have, for , and . In other words, an increase in the weight assigned to an estimate reduces its distance to the final solution and a decrease amplifies it, which means that increasing weights increases the chances of the relevant candidate to win and decreasing weights has the contrary effect;
- iv:
- removing a candidate reduces to assigning a zero weight to it. The same reasoning as for iii* shows that this decision decreases the distance of the final solution from the removed candidate number. In other words, the winner does not lose its position in case of the removal of some other candidates.
8. Case Studies
- the first case study is an IT project in which the organisation used Scrum for the first time. Scrum is a fairly new method, still in the dynamic development stage, thus IT companies are generally little willing to reveal the data about their projects [68].
- the second case study is an R&D project of innovative and unique nature, which additionally put into question the financial management of a big university at that time. Such projects are encountered extremely rarely and organisations involved are rather reluctant to reveal detailed information.
- participant observation—one of the authors was either an external coach supporting the implementation of Scrum in the project, conducting and moderating the estimation process for the whole project (first case study) or project manager (second case study);
- informal individual interviews with project team members and estimators.
- all possible effort was put to ensuring that the behaviour of the observed reality (the team estimating the project) be unaffected by and independent of our observing and measuring. The coach and the project manager tried not to influence the project estimation process by their presence;
- the coach and the project manager also tried not to be affected in their observing and measuring by the behaviour of the project team and the estimators;
- an initial state (at the beginning of the case study) and evolution (modification of the estimation method) were distinguished, and the initial state definition was independent of the observing activity.
8.1. Case Study nb 1
8.1.1. Project Description
8.1.2. Implementation of Fuzzy Effort Estimation Method
- Traditional approach: no fuzzy numbers were applied, simple voting and majority rule after the 4th round determined the final estimate. This means that for the j-th Product Backlog item the crisp estimate from the set was selected which obtained the maximum number of expert votes. In case two or more estimates received the same number of votes, the highest of them (i.e., the most pessimistic one) was retained as the final result. Let us denote it as , j = 1, …, 49.
- New, fuzzy numbers based approach: for each expert i = 1, …, 8 and Product Backlog item j = 1, …, 49, triangular fuzzy numbers were constructed in the following way:
- ○
- , the most likely variant of the estimate, was the one proposed in the last round (i.e., it was equal to );
- ○
- , the pessimistic variant, was the maximum of the four relevant estimates (i.e., was set as );
- ○
- analogously, , the optimistic variant, was assumed to be equal to .
8.1.3. Results of Case Study nb 1
- In 14 cases a fuzzy number with both uncertainty degrees equal to 0 was obtained ( and the traditional, crisp estimate fully harmonised with this result ( For these items the usage of fuzzy numbers did not contribute any new information, it seems that the experts agreed that the production of these Product Backlog items was not linked to any uncertainty;
- In 7 cases the minimal uncertainty degree (of the in plus and in minus ones) was greater than 0.4, in two cases it was greater than 0.5, while it held . The accomplishment of these items was linked to a rather high uncertainty and the usage of fuzzy numbers indicates it clearly, contrary to the traditional approach. Decision makers should focus especially on them—their accomplishment may require substantially less or substantially more effort that indicated by the traditional approach. This knowledge was tacitly present in the expert team, but it was only the fuzzy approach which allowed it to come to light.
- In 14 cases the in plus uncertainty degree exceeded by at least 0.2 the in minus one. These cases correspond to those Product Backlog items where the possibility of exceeding the value was substantially higher than the chances of being inferior to it. Also this type of information, made available thanks to the proposed method, is valuable, as it indicates the estimates which are more uncertain in the negative than in the positive sense;
- In 7 cases it held (among them in 2 cases we had , in 11 cases (among which in 6 cases ), in 15 cases (among which in 9 cases and in 18 (among which in 11 case ). All these cases are a clear proof of the usefulness of the new method. Although both estimates, the traditional and the “new” one, were delivered by the same experts, in a considerable number of cases the occurrence of the traditional estimate (measured by means of the membership function ) was, in the opinion of the experts, not very possible. The most alarming cases are those where was low and at the same time the inequality held. In these cases the traditional estimates are in the left hand wing of the triangle from Figure 1 and as such, differ substantially from the most dangerous values, those from the right hand wing, which may occur with a positive possibility degree (according to the same experts). It means that in these cases decisions made on the basis of traditional estimates can be described as essentially biased with a high negative uncertainty and risk of exceeding the available resource pool or not being able to complete the items selected for the Sprint.
- Let us consider the estimation of the total effort (needed for the implementation of all the Product Backlog items):
- ○
- estimated in the traditional way as equal to (rounded to the nearest integer) ;
- ○
- estimated according to the new method as (also rounded to the nearest integer) as .
8.1.4. Cancellation of the Project
8.1.5. Summary of Case Study nb 1
- The fuzzy approach brings to light the tacit knowledge and opinion of experts which in the traditional approach is revealed only partially and often in a distorted form (when for example an estimate is selected in the traditional approach which in the fuzzy approach turns off to be rather impossible and very different from the maximal possible values).
- The application of the proposed method in practice does not have to mean an additional effort for the experts. In the case study the experts worked as if only the traditional method was used. Uniquely the moderator additional task was to apply the respective formula from Section 7 and calculate the fuzzy estimates.
- The results, although not juxtaposed with actual values, intrigued the experts. They were surprised by the apparent defectiveness of their traditional estimates. If the necessary time had been available, they would have gladly discussed the fuzzy estimates—what is in fact a part of the proposed method (weights (5) can be changed by the experts).
- The idea of a buffer for the planned Sprint effort, which could be determined by means of the proposed method, was highly appreciated, as well as the possibility of -levels application, which represent the estimates whose occurrence is characterized by the possibility equal to or exceeding A maximal accepted uncertainty (risk) level 1-t can be selected and the values from unaccepted -levels can be analysed, in order to prevent a too high uncertainty (risk) from occurring.
8.2. Case study nb 2
8.2.1. Project Description
- Analysis of the organisational structure of the university in question. Analysis of the current cost structure. Identification of potential data sources.
- Elaboration of the system concept, definition of its basic elements and of cost flows. Initial validation of the concept.
- Analysis of costing systems existing in the market. Formulation of hardware requirements for the system. Formulation of recommendations and development plan for the university in terms of cost management.
- Implementation of the concept in EXCEL, selection of the university division to implement the system, analysis of the results, conclusions for future work.
8.2.2. Application of the Fuzzy Estimation Method
- An estimate they would enter in the application form for project funds (a crisp one);
- A fuzzy estimate, composed of three numbers: the optimistic, most possible and pessimistic duration;
- The consensus was reached through the application of arithmetical mean and rounding up or down to the closest integer or integer plus 0.5 value. In this way a crisp consensus (j = I, II, III, IV) and the fuzzy consensus (j = I, II, III, IV) were generated. The obtained numbers could be compared with the actual values from the final project report. The results are shown in Table 3, where stands for the actual duration (all the durations are given in months).
8.2.3. Results of Case Study nb 2
9. Summary and Discussion
- Fuzzy numbers are used as estimates, contrary to the existing methods, where crisp numbers are the only option. Fuzzy numbers allow the experts to express formally the whole knowledge and intuition they have about a Product Backlog item and the effort needed to produce it. As Product Backlog items are most often to a certain degree innovative, it seems natural that their estimation must, at least in numerous cases, encompass also the information about the inherent uncertainty. Fuzzy numbers introduce this possibility into the estimation process;
- Although, like in most existing estimation method, also the proposed method leaves to the experts some time for free discussion and interaction, contrary to most of the methods it proposes a fully defined solution for the case when, after a pre-set time, no consensus has been reached.
Author Contributions
Funding
Conflicts of Interest
References
- Dingsøyr, T.; Hanssen, G.K.; Dybå, T.; Anker, G.; Nygaard, J.O. Developing software with scrum in a small cross-organizational project. In Proceedings of the 13th European Conference (EuroSPI 2006), Joensuu, Finland, 11–13 October 2006; Volume 4257, pp. 5–15. [Google Scholar]
- Fitzgerald, B.; Hartnett, G.; Conboy, K. Customising agile methods to software practices at Intel Shannon. Eur. J. Inf. Syst. 2006, 15, 200–213. [Google Scholar] [CrossRef]
- Scrum Alliance. State of Scrum; Scrum Alliance: Westminster, CO, USA, 2018. [Google Scholar]
- Fogelström, N.D.; Gorschek, T.; Svahnberg, M.; Olsson, P. The impact of agile principles on market-driven software product development. J. Softw. Maint. Evol. 2010, 22, 53–80. [Google Scholar] [CrossRef]
- Sehra, S.K.; Brar, Y.S.; Kaur, N.; Sehra, S.S. Research patterns and trends in software effort estimation. Inf. Softw. Technol. 2017, 91, 1–21. [Google Scholar] [CrossRef]
- Hussain, I.; Kosseim, L.; Ormandjieva, O. Approximation of COSMIC functional size to support early effort estimation in Agile. Data Knowl. Eng. 2013, 85, 2–14. [Google Scholar] [CrossRef]
- Alahyari, H.; Svensson, R.B.; Gorschek, T. A study of value in agile software development organizations. J. Syst. Softw. 2017, 125, 271–288. [Google Scholar] [CrossRef]
- Jørgensen, M. A review of studies on expert estimation of software development effort. J. Syst. Softw. 2004, 70, 37–60. [Google Scholar] [CrossRef]
- Lawrence, M.J.; Edmundson, R.H.; O’Connor, M.J. An examination of the accuracy of judgmental extrapolation of time series. Int. J. Forecast. 1985, 1, 25–35. [Google Scholar] [CrossRef]
- Webby, R.; O’Connor, M. Judgemental and statistical time series forecasting: A review of the literature. Int. J. Forecast. 1996, 12, 91–118. [Google Scholar] [CrossRef]
- Toma, S.-V.; Chirita, M.; Şarpe, D. Risk and Uncertainty. Procedia Econ. Financ. 2012, 3, 975–980. [Google Scholar] [CrossRef]
- Negoita, C.; Ralescu, D. Representation theorems for fuzzy concepts. In Readings in Fuzzy Sets for Intelligent Systems; Dubois, D., Yager, H.P.R., Eds.; Morgan Kaufmann: Burlington, MA, USA, 1993; pp. 65–70. [Google Scholar]
- Turksen, I.B. Measurement of membership functions and their acquisition. Fuzzy Sets Syst. 1991, 40, 5–38. [Google Scholar] [CrossRef]
- Türkşen, I.B. An Ontological and Epistemological Perspective of Fuzzy Set Theory; Elsevier: Amsterdam, The Netherlands, 2006. [Google Scholar]
- Moløkken-Østvold, K.; Haugen, N.C.; Benestad, H.C. Using planning poker for combining expert estimates in software projects. J. Syst. Softw. 2008, 81, 2106–2117. [Google Scholar] [CrossRef]
- Alostad, J.M.; Abdullah, L.R.A.; Aali, L.S. A Fuzzy based model for effort estimation in scrum projects. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 270–277. [Google Scholar]
- Moore, C.; Harris, C.; Rogers, E. Fuzzy Logic Based Estimators and Predictors for Agile Target Tracking Applications. IFAC Proc. Vol. 1996, 29, 4178–4183. [Google Scholar] [CrossRef]
- Raslan, A.; Ramadan, N.; Hefny, H. Towards a Fuzzy based Framework for Effort Estimation in Agile Software Development. Int. J. Comput. Sci. Inf. Secur. 2015, 13, 37–45. [Google Scholar]
- Mohammed, A.H.; Darwish, N.R. A Proposed Fuzzy based Framework for Calculating Success Metrics of Agile Software Projects. Int. J. Comput. Appl. 2016, 137, 17–22. [Google Scholar]
- Lin, C.-T.; Chiu, H.; Tseng, Y.-H. Agility evaluation using fuzzy logic. Int. J. Prod. Econ. 2006, 101, 353–368. [Google Scholar] [CrossRef]
- Kim, S.H.; Ahn, B.S. Interactive group decision making procedure under incomplete information. Eur. J. Oper. Res. 1999, 116, 498–507. [Google Scholar] [CrossRef]
- Chen, S.J.; Chen, S.M. A new method for handling multicriteria fuzzy decision-making problems using FN-IOWA operators. Cybern. Syst. 2003, 34, 109–137. [Google Scholar] [CrossRef]
- Büyüközkan, G.; Ruan, D. Evaluation of software development projects using a fuzzy multi-criteria decision approach. Math. Comput. Simul. 2008, 77, 464–475. [Google Scholar] [CrossRef]
- Wan, S.; Dong, J. A possibility degree method for interval-valued intuitionistic fuzzy multi-attribute group decision making. J. Comput. Syst. Sci. 2014, 80, 237–256. [Google Scholar] [CrossRef]
- Wilson, K.J. An investigation of dependence in expert judgement studies with multiple experts. Int. J. Forecast. 2017, 33, 325–336. [Google Scholar] [CrossRef]
- Tikhomirova, A.N.; Sidorenko, E.V. Optimization of the process of scientific and technical expertise projects in nanobiomedical technologies. Nanotechnics 2012, 1, 26–28. [Google Scholar]
- Rosen, J. The Concept of Symmetry. In Symmetry Rules. The Frontiers Collection; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Schwaber, K.; Sutherland, J. The Scrum Guide The Definitive Guide to Scrum: The Rules of the Game. Available online: http://www.scrum.org (accessed on 1 June 2019).
- Rowe, G.; Wright, G. Expert Opinions in Forecasting: The Role of the Delphi Technique. Princ. Forecast. 2001, 30, 125–144. [Google Scholar]
- Grenning, J. Planning Poker or How to Avoid Analysis Paralysis while Release Planning. 2002. Available online: https://renaissancesoftware.net/files/articles/PlanningPoker-v1.1.pdf (accessed on 10 May 2019).
- Tamrakar, R.; Jørgensen, M. Does the use of Fibonacci numbers in planning poker affect effort estimates? In Proceedings of the 16th International Conference on Evaluation & Assessment in Software Engineering (EASE 2012), Ciudad Real, Spain, 14–15 May 2012; pp. 228–232. [Google Scholar]
- Cohn, M. Agile Estimating and Planning; Prentice Hall PTR: Upper Saddle River, NJ, USA, 2005. [Google Scholar]
- Wood, S.; Michaelides, G.; Thomson, C. Successful extreme programming: Fidelity to the methodology or good teamworking? Inf. Softw. Technol. 2013, 55, 660–672. [Google Scholar] [CrossRef]
- Shore, J.; Warden, S. The Art of Agile Development Pragmatic Guide to Agile Software Development, 1st ed.; O’Reilly Media: Sebastopol, CA, USA, 2007. [Google Scholar]
- Cockburn, A. Crystal Clear a Human-Powered Methodology for Small Teams, 1st ed.; Addison-Wesley Professional: Boston, MA, USA, 2004. [Google Scholar]
- Dalkey, N.; Helmer, O. An Experimental Application of the DELPHI Method to the Use of Experts. Manag. Sci. 1963, 9, 458–467. [Google Scholar] [CrossRef]
- Boehm, B.W. Software Engineering Economics. IEEE Trans. Softw. Eng. 1984, 10, 4–21. [Google Scholar] [CrossRef]
- Büyüközkan, G.; Güleryüz, S. A new integrated intuitionistic fuzzy group decision making approach for product development partner selection. Comput. Ind. Eng. 2016, 102, 383–395. [Google Scholar] [CrossRef]
- Attanasi, G.; Corazzini, L.; Passarelli, F. Voting as a lottery. J. Public Econ. 2017, 146, 129–137. [Google Scholar] [CrossRef]
- Chutia, R. Ranking of fuzzy numbers by using value and angle in the epsilon-deviation degree method. Appl. Soft Comput. J. 2017, 60, 706–721. [Google Scholar] [CrossRef]
- Gehrlein, W.V. The Condorcet criterion and committee selection. Math. Soc. Sci. 1985, 10, 199–209. [Google Scholar] [CrossRef]
- Arrow, K. Social Choice and Individual Values; John Wiley & Sons: Hoboken, NJ, USA, 1951. [Google Scholar]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- De Luca, A.; Termini, S. A definition of a nonprobabilistic entropy in the setting of fuzzy sets theory. Inf. Control 1972, 20, 301–312. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H.; Zadeh, L.A. Fundamentals of Fuzzy Sets; Springer: New York, NY, USA, 2000. [Google Scholar]
- Deng, H. Comparing and ranking fuzzy numbers using ideal solutions. Appl. Math. Model. 2014, 38, 1638–1646. [Google Scholar] [CrossRef]
- Chi, H.T.X.; Yu, V.F. Ranking generalized fuzzy numbers based on centroid and rank index. Appl. Soft Comput. J. 2018, 68, 283–292. [Google Scholar] [CrossRef]
- Zwick, R.; Carlstein, E.; Budescu, D.V. Measures of similarity among fuzzy concepts: A comparative analysis. Int. J. Approx. Reason. 1987, 1, 221–242. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Spillman, B.; Spillman, R. A fuzzy relation space for group decision theory. Fuzzy Sets Syst. 1978, 1, 255–268. [Google Scholar] [CrossRef]
- Kacprzyk, J.; Fedrizzi, M. A ‘soft’ measure of consensus in the setting of partial (fuzzy) preferences. Eur. J. Oper. Res. 1988, 34, 316–325. [Google Scholar] [CrossRef]
- Butler, C.T.L.; Rothstein, A. On Conflict and Consensus: A Handbook on Formal Consensus Decisionmaking; Food Not Bombs: Tuscon, AZ, USA, 2007. [Google Scholar]
- Cabrerizo, F.J.; Martínez, M.A.; Herrera, M.; Herrera-Viedma, E. Consensus in a Fuzzy Environment: A Bibliometric Study. In Proceedings of the 3rd International Conference on Information Technology and Quantitative Management ITQM 2015, Rio De Janeiro, Brazil, 21–24 July 2015; Volume 55, pp. 660–667. [Google Scholar]
- Kacprzyk, J. Group decision making with a fuzzy linguistic majority. Fuzzy Sets Syst. 1986, 18, 105–118. [Google Scholar] [CrossRef]
- Zhang, L.; Li, T.; Xu, X. Consensus model for multiple criteria group decision making under intuitionistic fuzzy environment. Knowl.-Based Syst. 2014, 57, 127–135. [Google Scholar] [CrossRef]
- Szmidt, E.; Kacprzyk, J. A new concept of a similarity measure for intuitionistic fuzzy sets and its use in group decision making. In Proceedings of the 2rd International Conference on Modeling Decisions for Artificial Intelligence, Tsukuba, Japan, 25–27 July 2005; Volume 3558, pp. 272–282. [Google Scholar]
- Liu, P.; Jin, F. A multi-attribute group decision-making method based on weighted geometric aggregation operators of interval-valued trapezoidal fuzzy numbers. Appl. Math. Model. 2012, 36, 2498–2509. [Google Scholar] [CrossRef]
- Herrera-Viedma, E.; Herrera, F.; Chiclana, F. A consensus model for multiperson decision making with different preference structures. Syst. Man Cybern. Part A Syst. Hum. IEEE Trans. 2002, 32, 394–402. [Google Scholar] [CrossRef]
- Beliakov, G.; Calvo, T.; James, S. Consensus measures constructed from aggregation functions and fuzzy implications. Knowl.-Based Syst. 2014, 55, 1–8. [Google Scholar] [CrossRef]
- Chiclana, F.; Herrera-Viedma, E.; Herrera, F.; Alonso, S. Some induced ordered weighted averaging operators and their use for solving group decision-making problems based on fuzzy preference relations. Eur. J. Oper. Res. 2007, 182, 383–399. [Google Scholar] [CrossRef]
- Wu, J.; Li, J.-C.; Li, H.; Duan, W.-Q. The induced continuous ordered weighted geometric operators and their application in group decision making. Comput. Ind. Eng. 2009, 56, 1545–1552. [Google Scholar] [CrossRef]
- Wu, J.; Cao, Q.-W.; Zhang, J.-L. Some properties of the induced continuous ordered weighted geometric operators in group decision making. Comput. Ind. Eng. 2010, 59, 100–106. [Google Scholar] [CrossRef]
- Wu, J.; Cao, Q.-W.; Zhang, J.-L. An ILOWG operator based group decision making method and its application to evaluate the supplier criteria. Math. Comput. Model. 2011, 54, 19–34. [Google Scholar] [CrossRef]
- Wu, J.; Cao, Q.-W. Some issues on properties of the extended IOWA operators in fuzzy group decision making. Expert Syst. Appl. 2011, 38, 7059–7066. [Google Scholar] [CrossRef]
- Hsu, H.-M.; Chen, C.-T. Aggregation of fuzzy opinions under group decision making. Fuzzy Sets Syst. 1996, 79, 279–285. [Google Scholar]
- Rees, W.D.; Porter, C. The use of case studies in management training and development. Part 1. Ind. Commer. Train. 2002, 34, 5–8. [Google Scholar] [CrossRef]
- Dyer, W.G.; Wilkins, A.L. Better Stories, Not Better Constructs, To Generate Better Theory: A Rejoinder to Eisenhardt. Acad. Manag. Rev. 1991, 16, 613–619. [Google Scholar] [CrossRef]
- Mahnič, V.; Hovelja, T. On using planning poker for estimating user stories. J. Syst. Softw. 2012, 85, 2086–2095. [Google Scholar] [CrossRef]
- Peters, F.; Menzies, T. Privacy and utility for defect prediction: Experiments with MORPH. In Proceedings of the 2012 34th International Conference on Software Engineering (ICSE), Zurich, Switzerland, 2–9 June 2012; pp. 189–199. [Google Scholar]
- Gerring, J. Case Study Research: Principles and Practices; Cambridge University Press: New York, NY, USA, 2007. [Google Scholar]
- Charette, R.N. Why software fails [software failure]. IEEE Spectr. 2005, 42, 42–49. [Google Scholar] [CrossRef]
- Sauer, C.; Gemino, A.; Reich, B.H. The impact of size and volatility on IT project performance. Commun. ACM 2007, 50, 79–84. [Google Scholar] [CrossRef]
- El Emam, K.; Koru, A.G. A replicated survey of IT software project failures. IEEE Softw. 2008, 25, 84–90. [Google Scholar] [CrossRef]
- Standish Group. The Standish Group Report. 2017. Available online: https://www.projectsmart.co.uk/white-papers/chaos-report.pdf (accessed on 10 April 2019).
- Reddy, P.; Sudha, K.R.; Sree, P.R.; Ramesh, S. Software effort estimation using radial basis and generalized regression neural networks. arXiv 2010, arXiv:1005.4021. [Google Scholar]
- Kuchta, D. A new concept of project robust schedule—Use of buffers. Procedia Comput. Sci. 2014, 31, 957–965. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Estimates [User Story Point, Denoted as PP] | |||
|---|---|---|---|
| i-th Expert | |||
| 1 | 1 | 2 | 3 |
| 2 | 2 | 2 | 3 |
| 3 | 1.5 | 2 | 3 |
| 4 | 1 | 1.5 | 5 |
| 5 | 0.5 | 1.5 | 5 |
| j | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 13 | 13 | 13 | 13 | 1 | 1 | 0 | 0 |
| 2 | 0.90 | 2.23 | 3.62 | 3 | 0.45 | 0 | 0.60 | 0.62 |
| 3 | 16.32 | 28.87 | 69.70 | 20 | 0.29 | 1 | 0.43 | 1.41 |
| 4 | 4.16 | 5 | 5.47 | 5 | 1 | 1 | 0.17 | 0.09 |
| 5 | 2.96 | 4.63 | 6.18 | 5 | 0.76 | 0 | 0.36 | 0.34 |
| 6 | 0.92 | 1.61 | 2.61 | 1 | 0.11 | 1 | 0.43 | 0.62 |
| 8 | 15.81 | 22.87 | 34.07 | 20 | 0.59 | 1 | 0.31 | 0.49 |
| 9 | 13 | 13 | 13 | 13 | 1 | 1 | 0 | 0 |
| 10 | 8 | 8 | 8 | 8 | 1 | 1 | 0 | 0 |
| 11 | 5.20 | 8.22 | 13 | 8 | 0.93 | 1 | 0.37 | 0.58 |
| 12 | 14.89 | 25.18 | 56.59 | 20 | 0.50 | 1 | 0.41 | 1.25 |
| 13 | 2 | 2 | 2 | 2 | 1 | 1 | 0 | 0 |
| 14 | 2.20 | 3.67 | 5.22 | 5 | 0.14 | 0 | 0.40 | 0.42 |
| 15 | 7.78 | 10.39 | 13 | 13 | 0 | 0 | 0.25 | 0.25 |
| 16 | 6.84 | 8.37 | 12.81 | 8 | 0.76 | 1 | 0.18 | 0.53 |
| 17 | 7.34 | 9.13 | 12.68 | 8 | 0.37 | 1 | 0.20 | 0.39 |
| 18 | 11.33 | 11.90 | 13.47 | 13 | 0.30 | 0 | 0.05 | 0.13 |
| 19 | 5.75 | 7.53 | 11.82 | 8 | 0.89 | 0 | 0.24 | 0.57 |
| 20 | 2.87 | 3.76 | 6.55 | 5 | 0.55 | 0 | 0.24 | 0.74 |
| 21 | 6.65 | 9.09 | 11.61 | 8 | 0.55 | 1 | 0.27 | 0.28 |
| 22 | 5 | 5 | 5 | 5 | 1 | 1 | 0 | 0 |
| 23 | 2.62 | 3.82 | 6.26 | 3 | 0.32 | 1 | 0.31 | 0.64 |
| 24 | 28.31 | 35.46 | 40 | 40 | 0 | 0 | 0.20 | 0.13 |
| 25 | 20 | 20 | 20 | 20 | 1 | 1 | 0 | 0 |
| 26 | 4.27 | 5.38 | 6.54 | 5 | 0.66 | 1 | 0.21 | 0.22 |
| 27 | 6.21 | 9.90 | 12.44 | 8 | 0.48 | 1 | 0.37 | 0.26 |
| 28 | 8 | 8 | 8 | 8 | 1 | 1 | 0 | 0 |
| 29 | 8 | 8 | 8 | 8 | 1 | 1 | 0 | 0 |
| 30 | 15.97 | 18.24 | 21.06 | 18 | 0.89 | 1 | 0.12 | 0.15 |
| 31 | 9.11 | 19.23 | 31.71 | 20 | 0.94 | 0 | 0.53 | 0.65 |
| 32 | 5.38 | 8.40 | 12.90 | 8 | 0.87 | 1 | 0.36 | 0.54 |
| 33 | 10.07 | 12.56 | 17.81 | 13 | 0.92 | 0 | 0.20 | 0.42 |
| 34 | 13 | 13 | 13 | 13 | 1 | 1 | 0 | 0 |
| 35 | 8 | 8 | 8 | 8 | 1 | 1 | 0 | 0 |
| 36 | 8 | 8 | 8 | 8 | 1 | 1 | 0 | 0 |
| 37 | 8 | 8 | 8 | 8 | 1 | 1 | 0 | 0 |
| 38 | 3.97 | 5.21 | 7.70 | 5 | 0.83 | 1 | 0.24 | 0.48 |
| 39 | 2.46 | 3.71 | 5.54 | 3 | 0.43 | 1 | 0.34 | 0.49 |
| 40 | 7.97 | 12.31 | 21.31 | 13 | 0.92 | 0 | 0.35 | 0.73 |
| 41 | 4.27 | 6.25 | 8.88 | 5 | 0.37 | 1 | 0.32 | 0.42 |
| 42 | 3.21 | 4.87 | 7.93 | 5 | 0.96 | 0 | 0.34 | 0.63 |
| 43 | 4.27 | 6.25 | 8.88 | 8 | 0.33 | 0 | 0.32 | 0.42 |
| 44 | 5.37 | 7.17 | 9.86 | 8 | 0.69 | 0 | 0.25 | 0.38 |
| 45 | 5 | 5 | 5 | 5 | 1 | 1 | 0 | 0 |
| 46 | 10.99 | 21.01 | 40 | 20 | 0.90 | 1 | 0.48 | 0.90 |
| 47 | 17.74 | 24.71 | 37.87 | 20 | 0.32 | 1 | 0.28 | 0.53 |
| 48 | 13 | 13 | 13 | 13 | 1 | 1 | 0 | 0 |
| 49 | 10.83 | 15.58 | 28.97 | 20 | 0.67 | 0 | 0.30 | 0.86 |
| j | Comment | |||||
|---|---|---|---|---|---|---|
| I | 2.5 | 3 | 3.5 | 2.5 | 3 | Fuzzy estimate closer to the actual value than the crisp estimate |
| II | 4 | 4.5 | 5 | 4 | 5 | Fuzzy estimate closer to the actual value than the crisp estimate |
| III | 4 | 5 | 5,5 | 4.5 | 2 | Crisp estimate closer to the actual value than the fuzzy estimate |
| IV | 5.5 | 6 | 7 | 5.5 | 7 | Fuzzy estimate closer to the actual value than the crisp estimate |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rola, P.; Kuchta, D. Application of Fuzzy Sets to the Expert Estimation of Scrum-Based Projects. Symmetry 2019, 11, 1032. https://doi.org/10.3390/sym11081032
Rola P, Kuchta D. Application of Fuzzy Sets to the Expert Estimation of Scrum-Based Projects. Symmetry. 2019; 11(8):1032. https://doi.org/10.3390/sym11081032
Chicago/Turabian StyleRola, Paweł, and Dorota Kuchta. 2019. "Application of Fuzzy Sets to the Expert Estimation of Scrum-Based Projects" Symmetry 11, no. 8: 1032. https://doi.org/10.3390/sym11081032
APA StyleRola, P., & Kuchta, D. (2019). Application of Fuzzy Sets to the Expert Estimation of Scrum-Based Projects. Symmetry, 11(8), 1032. https://doi.org/10.3390/sym11081032