Goal Recognition Control under Network Interdiction Using a Privacy Information Metric


Abstract
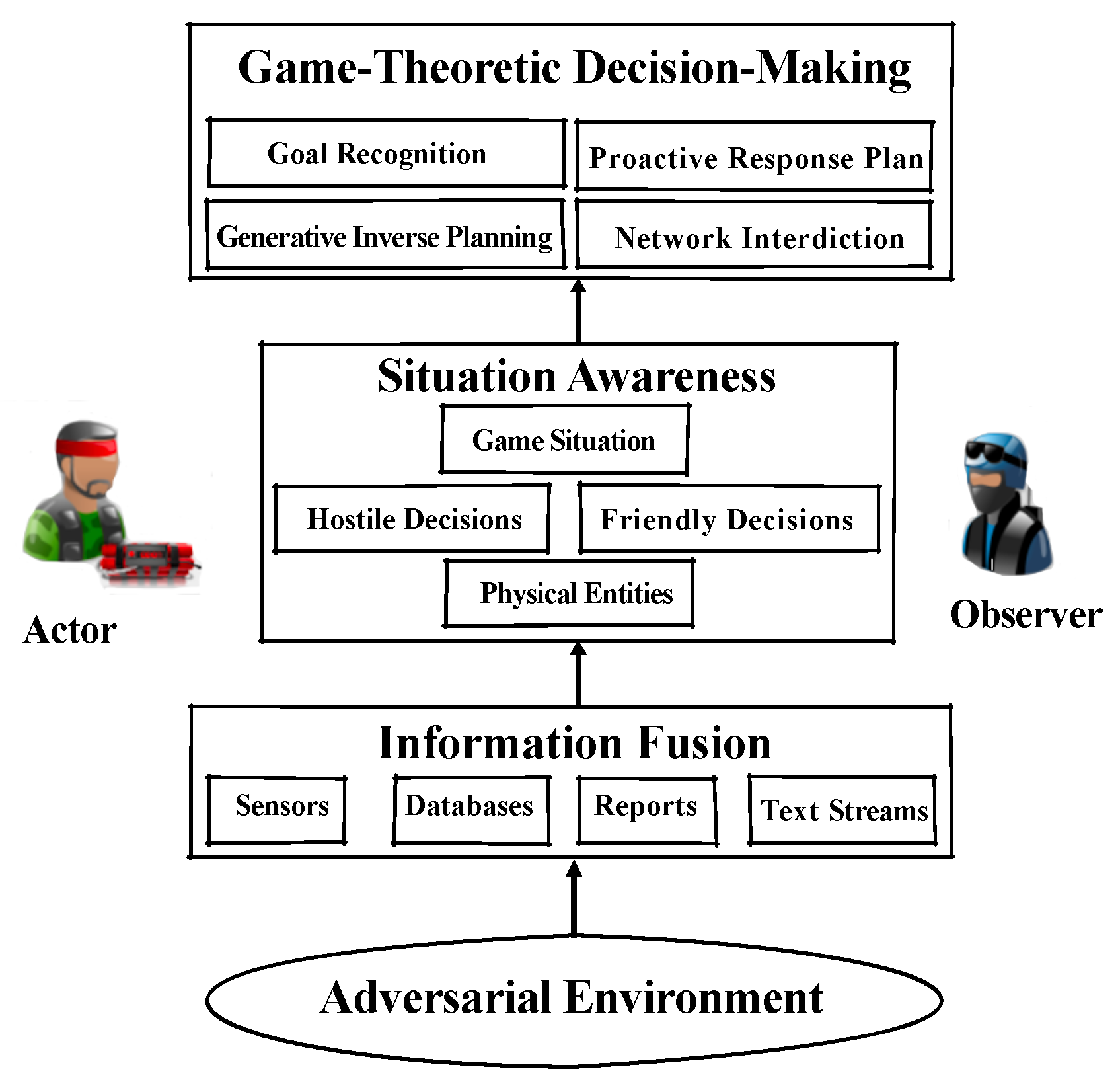
1. Introduction
- We start by introducing one game-theoretic decision-making framework, and then present the generative inverse path-planning and network interdiction for goal recognition, and some information metrics for the signaling behavior.
- We adopt a min-entropy based privacy information metric to quantify the privacy information leakage of the actions and states about the goal.
- We define the InfoGRC and InfoGRCT using the privacy information metric, and provide a more compact solution method for the observer to control the goal uncertainty by incorporating the information metric as additional path cost.
- We conduct some experimental evaluations to demonstrate the effectiveness of the InfoGRC and InfoGRCT model in controlling the goal recognition process under network interdiction.
2. Background and Related Work
2.1. Path-Planing and Network Interdiction
2.1.1. Path-Planning
- is a non-empty set of location nodes;
- is a set of actions related edges between nodes;
- returns the cost of traversing each edge.
- is the path planning domain;
- is the start location;
- is a set of candidate goals, where is the real goal;
- denotes the posterior probability of a goal given a sequence of observations (or last state in that sequence), which can be the model of the observer;
- is the set of m observations that can be emitted as results of the actions and the states;
- is a many-to-one observation function which maps the action taken and the next state reached to an observation in Ω.
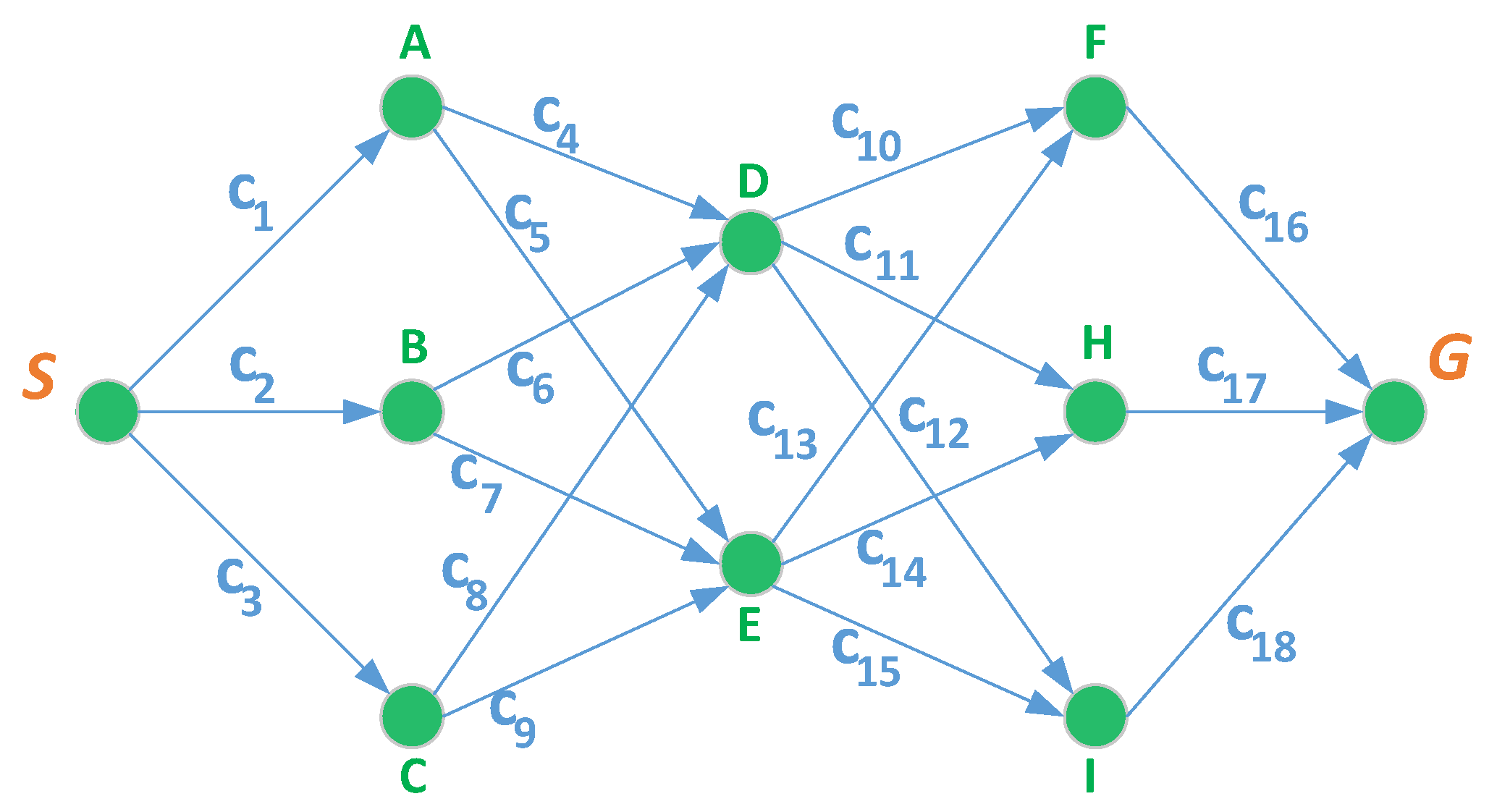
2.1.2. Network Interdiction
- denotes an optimal interdiction solution for the observer.
- Flow-balance constraints of variables , route one unit of flow from s to g, the inner minimum is a standard shortest path model with edge cost .
- is the nominal cost of edge a and is the interdicted cost; represents the additional path cost, if sufficiently large, represents complete destruction of edge a.
- is a small positive integer, representing how many resources are required to interdict edge a.
- R is the total available resource, the observer has possible interdiction combinations, which will grow exponentially with R.
- y denotes a traverse path of the actor.
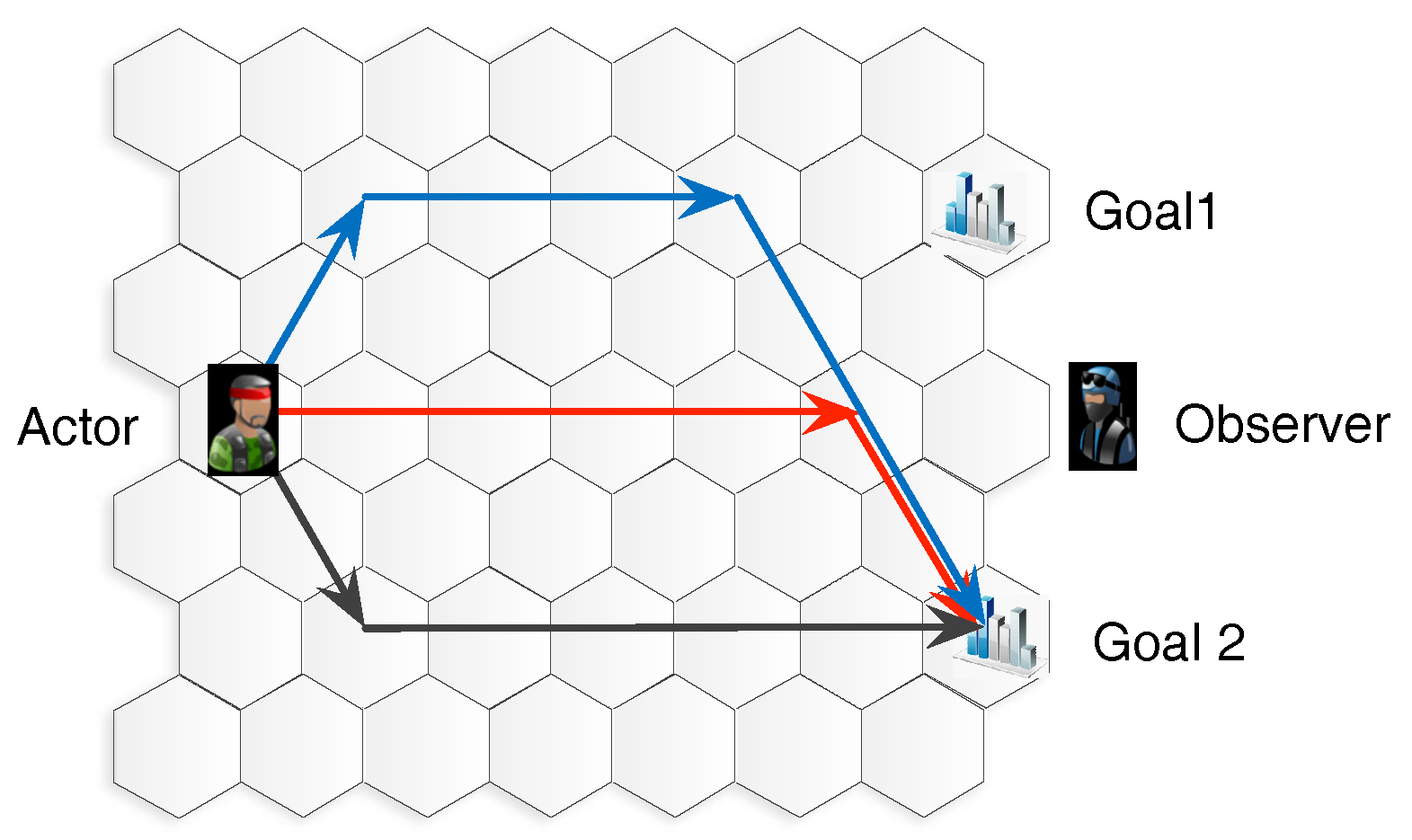
2.2. Goal Recognition
2.2.1. Probabilistic Goal Recognition
- is a path planning domain;
- is the set of candidate goals locations;
- is the start location;
- , where and for all , is a sequence of observation;
- represents the prior probabilities of the goals.
2.2.2. Goal Recognition Design
- is a planning domain formulated in STRIPS;
- is a set of possible goal;
- The output is such that ,
2.2.3. Trend and Dual-Use
2.3. Behavioral Information Metrics
3. Goal Recognition Control
3.1. Privacy Information Metrics
- initial uncertainty:
- remaining uncertainty: .
- information leakage
3.2. InfoGRC and InfoGRCT
3.2.1. Accelerate and Delay
3.2.2. Control and Threshold
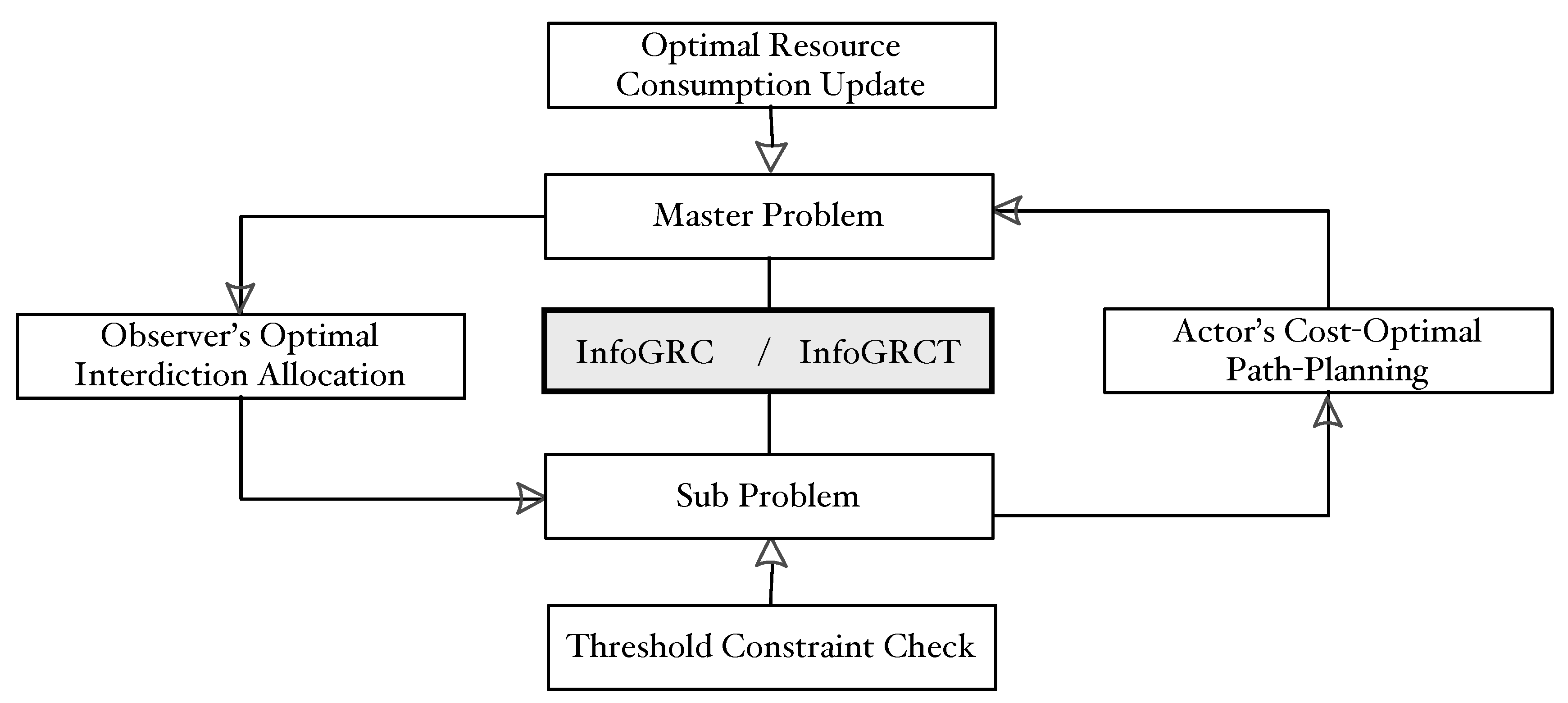
3.3. Dual Reformulation
| Algorithm 1 The Benders decomposition based problem-solving algorithm for InfoGRCT |
|
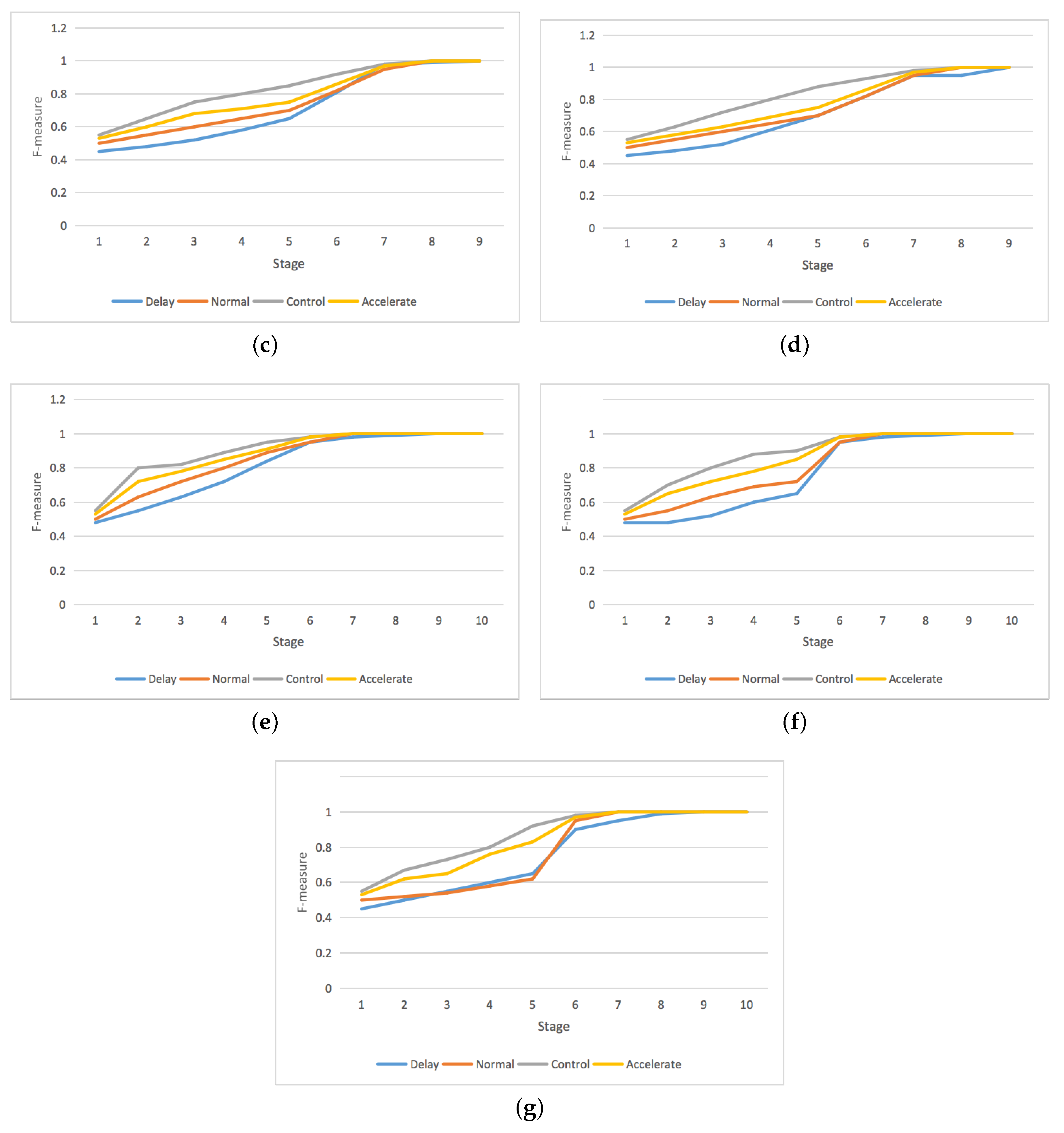
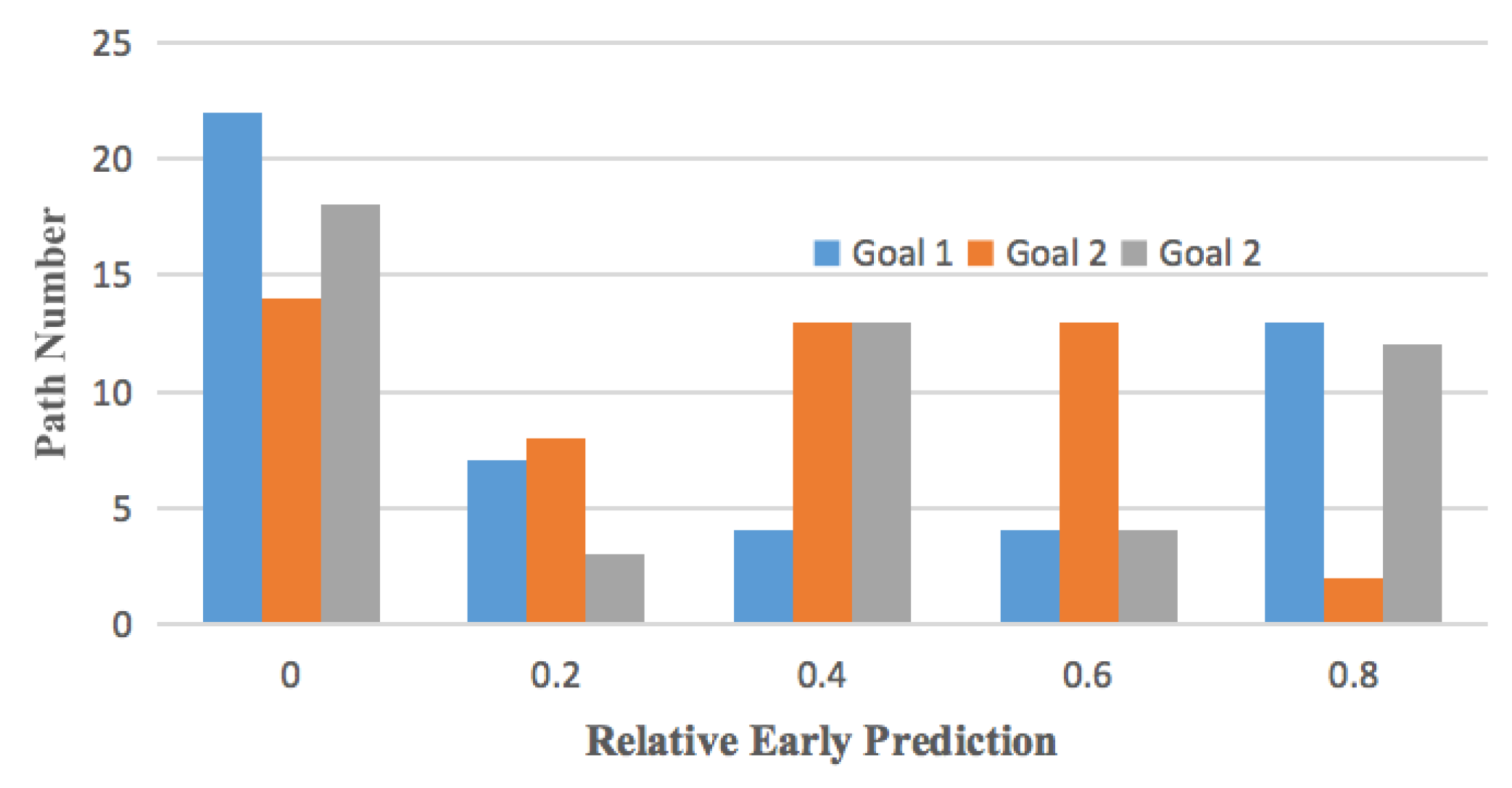
4. Experiments
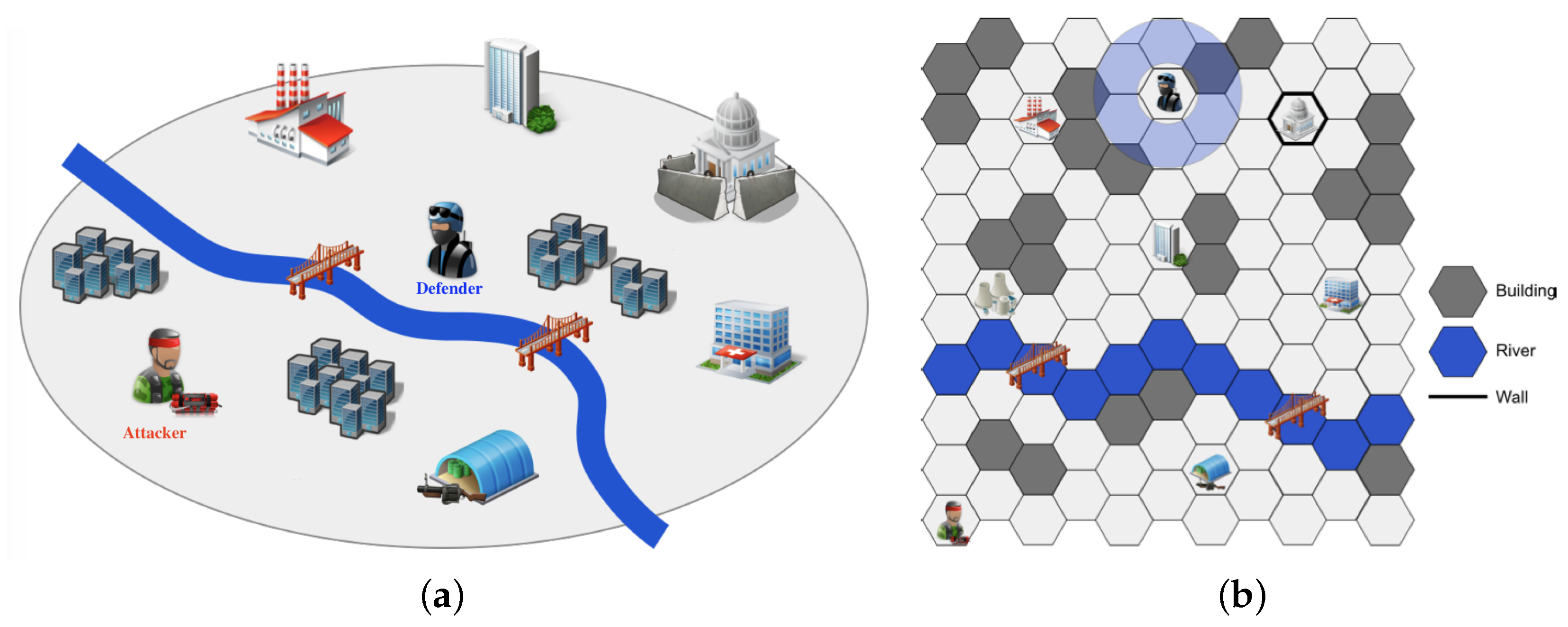
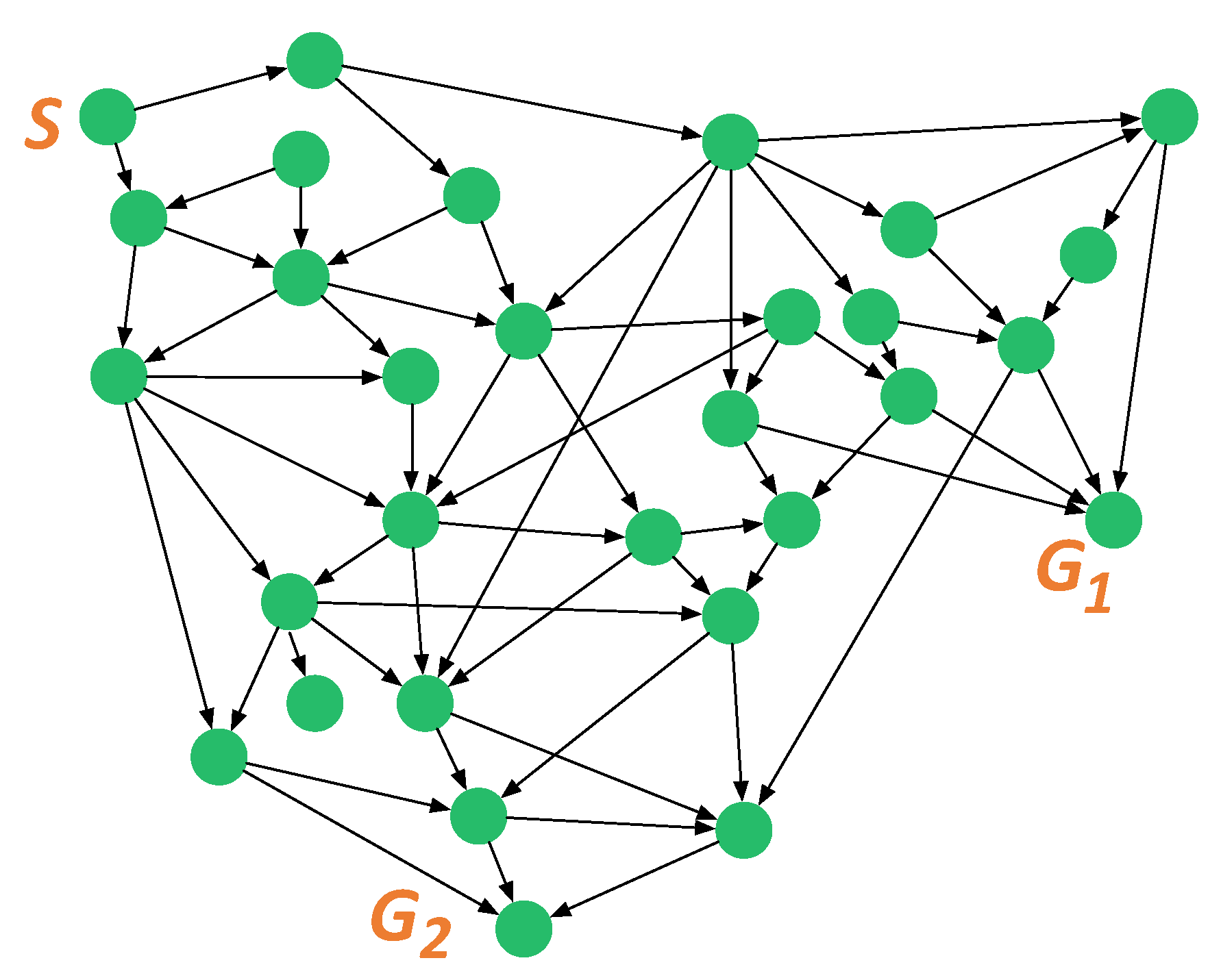
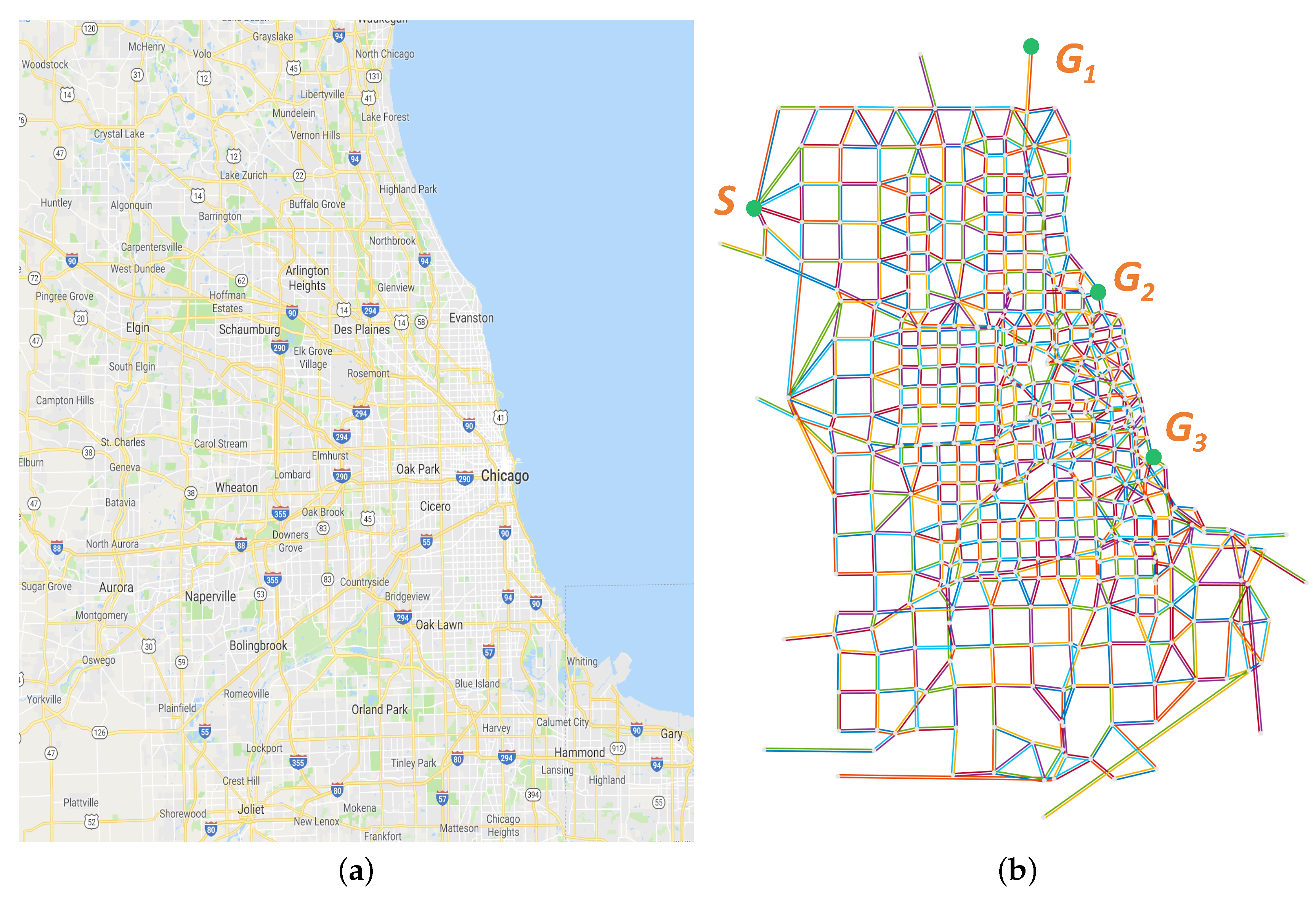
4.1. Experimental Setup
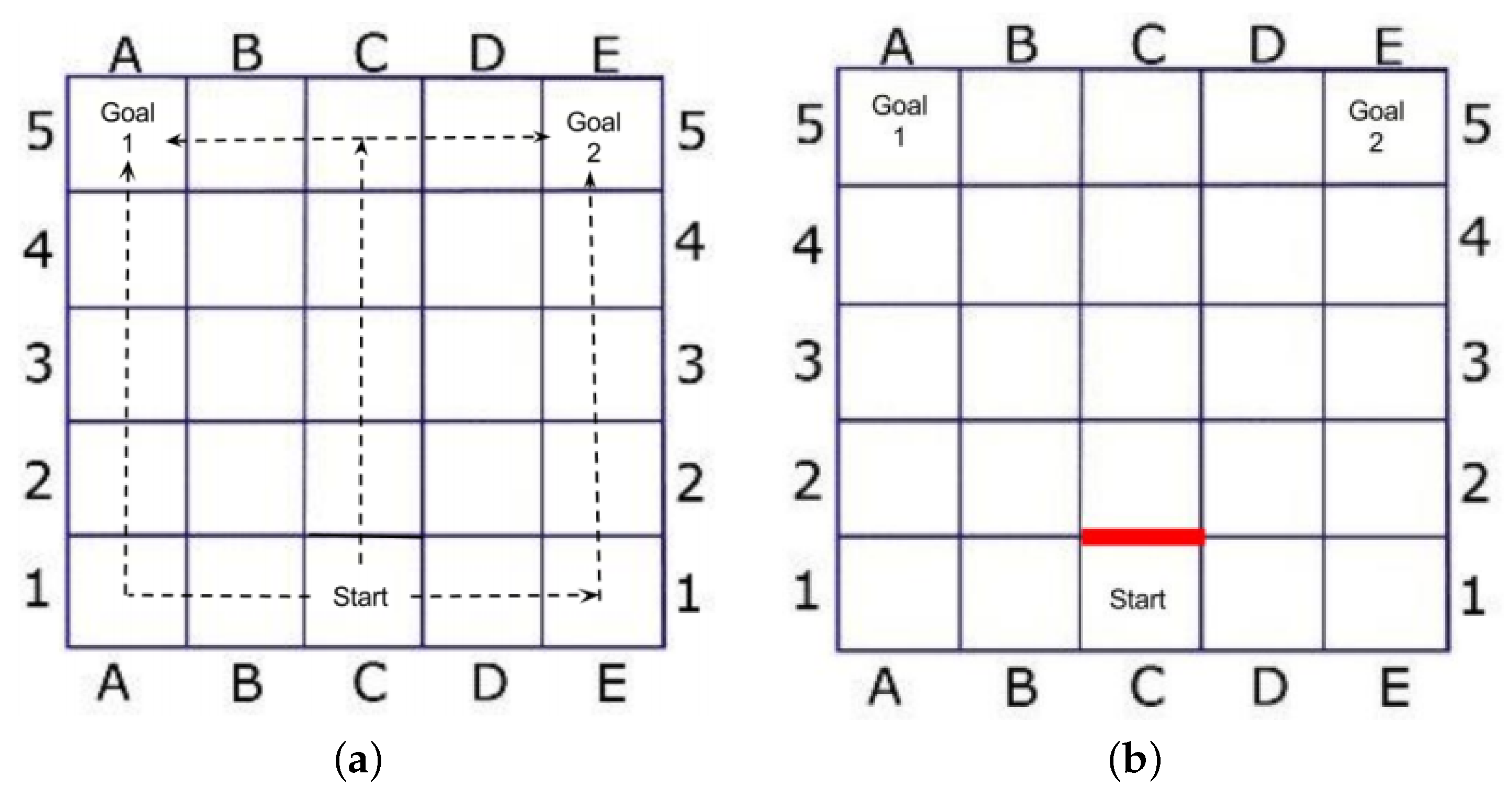
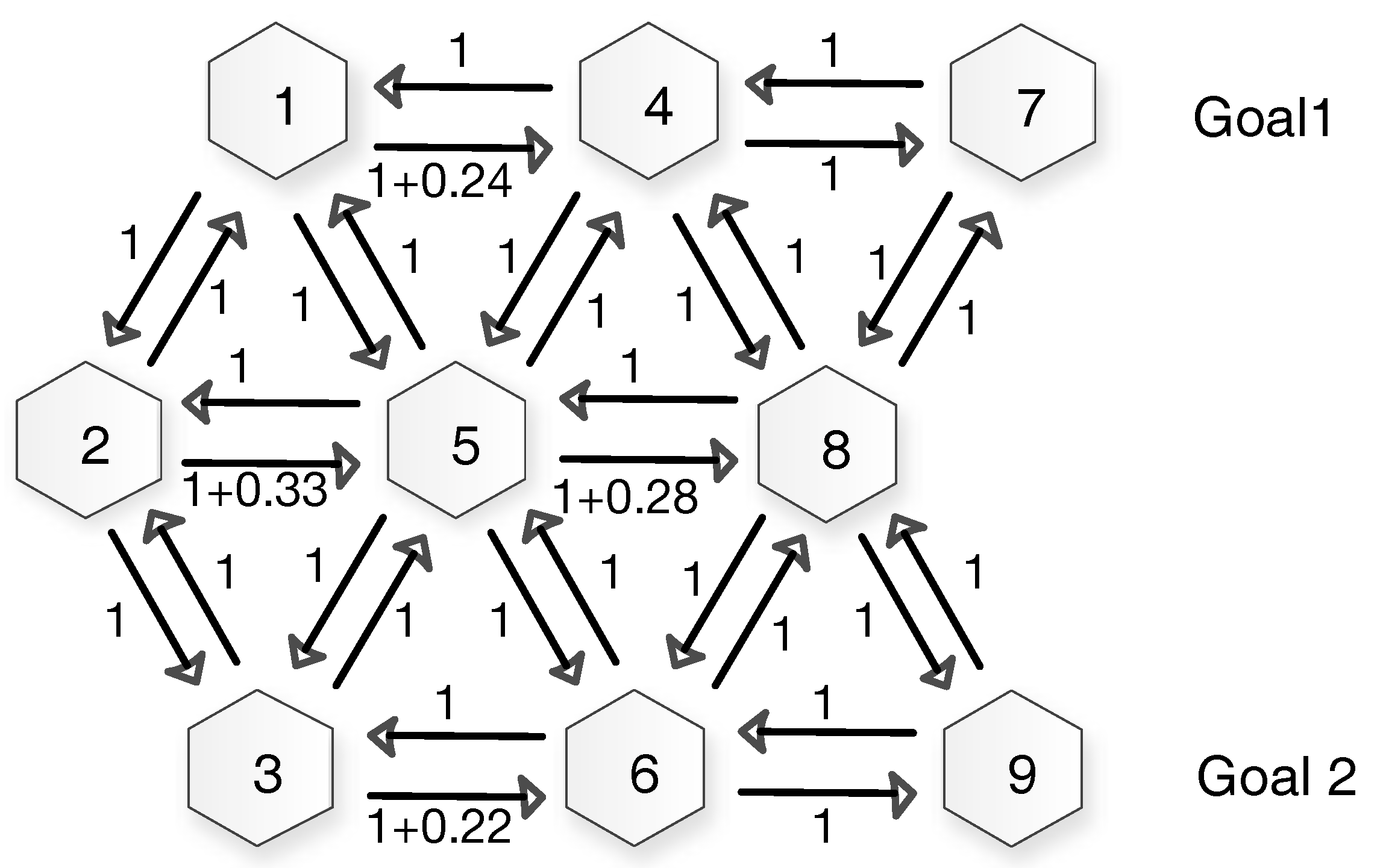
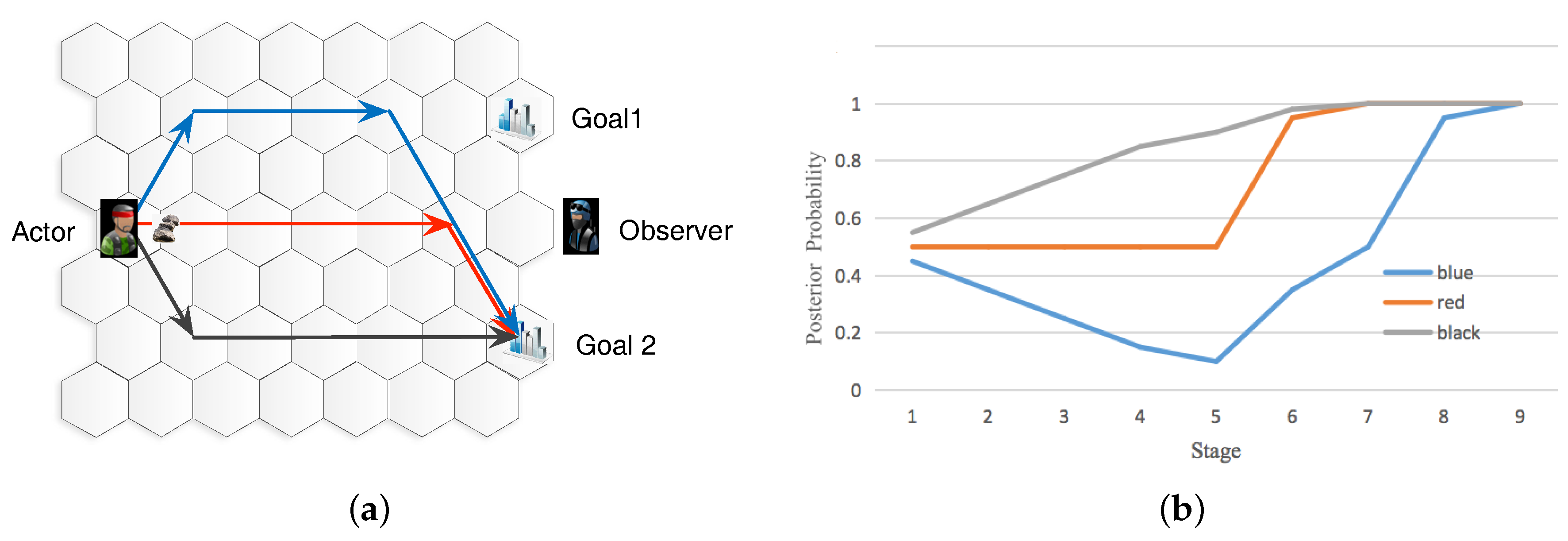
4.2. Experimental Scenarios
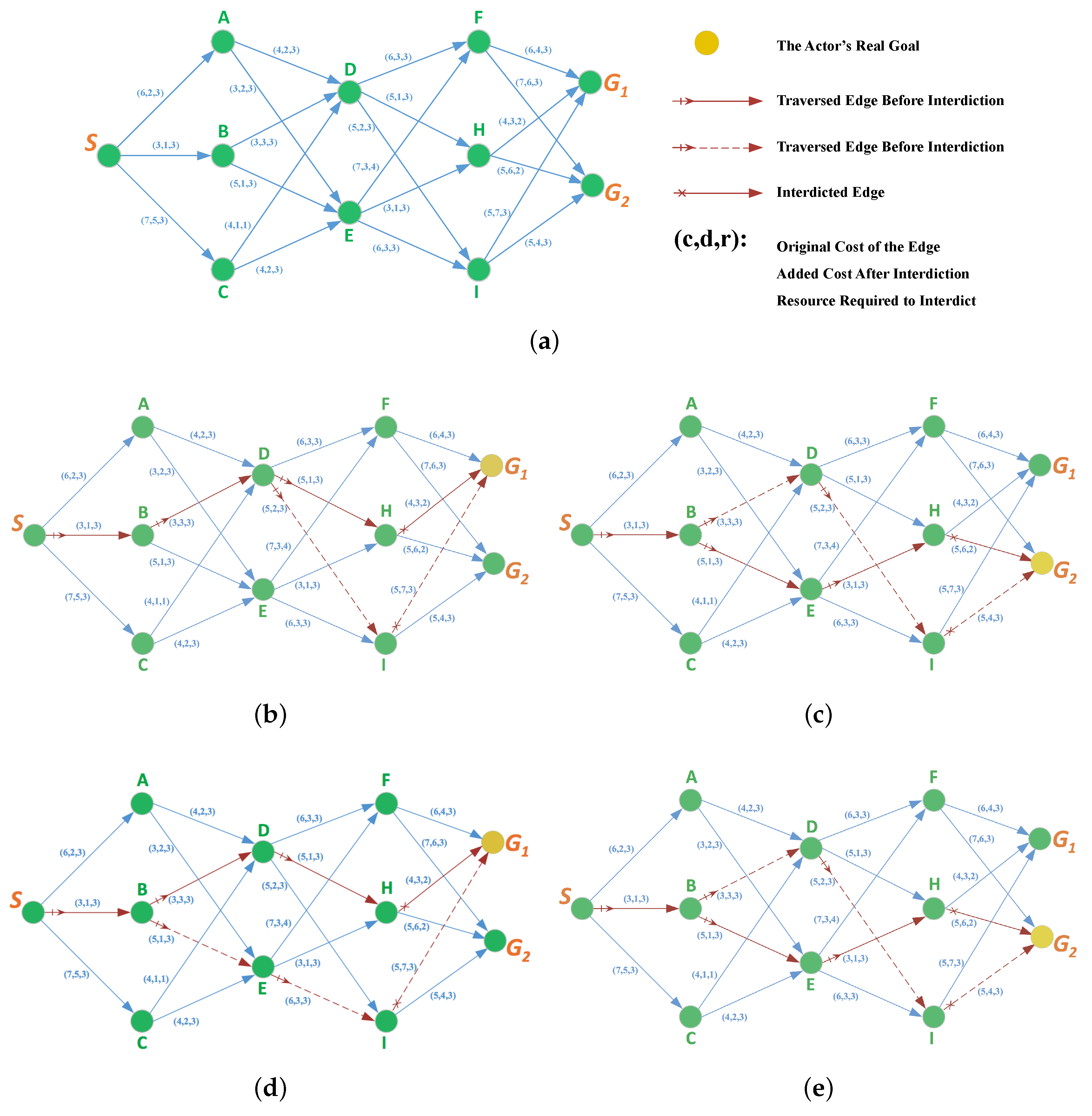
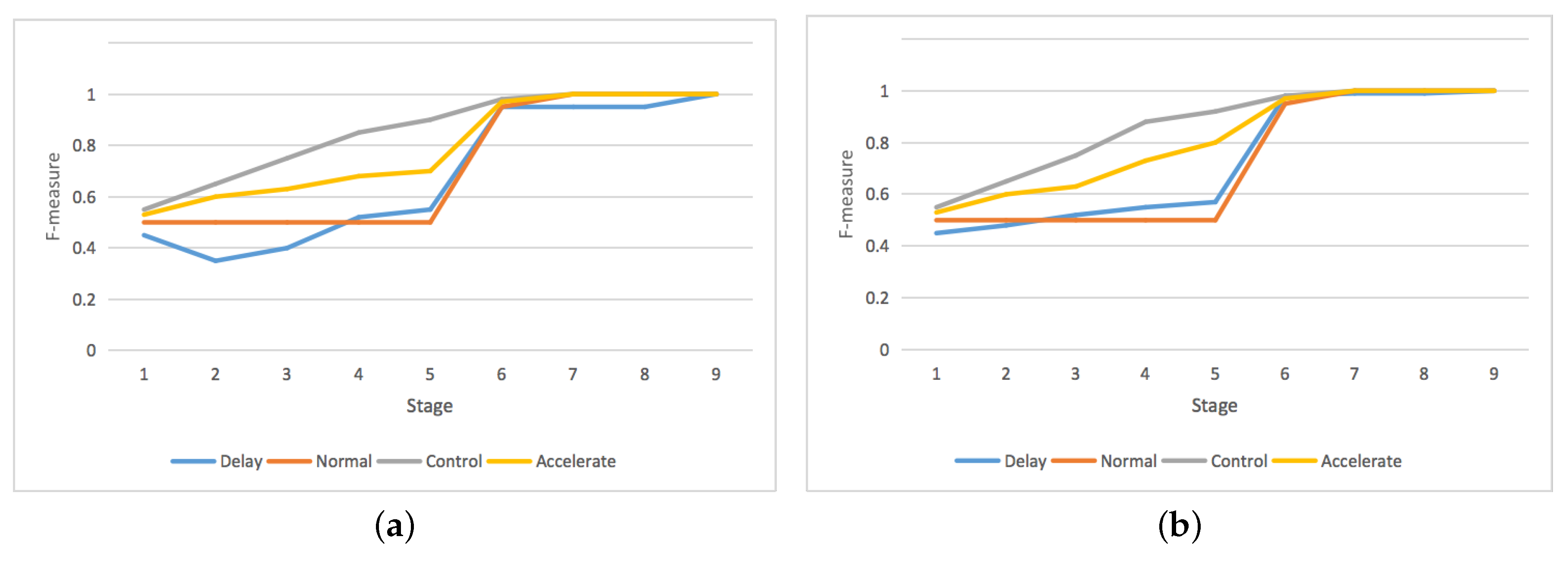
4.3. Goal Recognition Control under Network Interdiction
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| GR | Goal recognition |
| GRD | Goal recognition design |
| GRC | Goal recognition control |
| CIP | Critical infrastructure protection |
| PAIR | Plan activity and intent recognition |
| HAIP | Human–AI planning |
| XAIP | Explainable planning |
| HMI | Human–machine interaction |
| COA | Course Of action |
| HTN | Hierarchical task network |
| BLMIP | Bi-level mixed-integer programming |
| worst-case distinctiveness | |
| MXFI | Maximum-flow network interdiction |
| SPNI | Shortest path network interdiction |
| MXSP | Maximizing the shortest path |
| KKT | Karush–Kuhn–Tucker |
References
- Sadri, F. Logic-based approaches to intention recognition. In Handbook of Research on Ambient Intelligence and Smart Environments: Trends and Perspectives; IGI Global: Hershey, PA, USA, 2011; pp. 346–375. [Google Scholar]
- Aha, D.W. Goal reasoning: Foundations, emerging applications, and prospects. AI Mag. 2018, 39, 3–24. [Google Scholar] [CrossRef]
- Keren, S.; Gal, A.; Karpas, E. Goal recognition design. In Proceedings of the Twenty-Fourth International Conference on Automated Planning and Scheduling, Portsmouth, NH, USA, 21–26 June 2014. [Google Scholar]
- Sukthankar, G.; Geib, C.; Bui, H.H.; Pynadath, D.; Goldman, R.P. Plan, Activity, and Intent Recognition: Theory and Practice; Newnes: Burlington MA, USA, 2014. [Google Scholar]
- Chakraborti, T.; Kambhampati, S.; Scheutz, M.; Zhang, Y. AI challenges in human-robot cognitive teaming. arXiv 2017, arXiv:1707.04775. [Google Scholar]
- Albrecht, S.V.; Stone, P. Autonomous agents modelling other agents: A comprehensive survey and open problems. Artif. Intell. 2018, 258, 66–95. [Google Scholar] [CrossRef]
- Le Guillarme, N. A Game-Theoretic Planning Framework for Intentional Threat Assessment. Ph.D. Thesis, Université de Caen, Caen, France, 2016. [Google Scholar]
- Heinze, C. Modelling Intention Recognition for Intelligent Agent Systems; Technical Report; Defence Science and Technology Organisation Salisbury (AUSTRALIA): Melbourne, Australia, 2004.
- Chakraborti, T.; Sreedharan, S.; Grover, S.; Kambhampati, S. Plan explanations as model reconciliation. In Proceedings of the 14th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Daegu, Korea, 11–14 March 2019; pp. 258–266. [Google Scholar]
- Fox, M.; Long, D.; Magazzeni, D. Explainable planning. arXiv 2017, arXiv:1709.10256. [Google Scholar]
- Bayrak, H.; Bailey, M.D. Shortest path network interdiction with asymmetric information. Networks 2010, 52, 133–140. [Google Scholar] [CrossRef]
- Vijay, G.; Justin, G.; Jeremy, K.; Albert, R.; Hayley, R.; Siddharth, S.; Jonathan, S.; David, M. AI Enabling Technologies: A Survey. arXiv 2019, arXiv:1905.03592v1. [Google Scholar]
- Hellström, T.; Bensch, S. Understandable robots-what, why, and how. Paladyn J. Behav. Robot. 2018, 9, 110–123. [Google Scholar] [CrossRef]
- Štolba, M.; Tožička, J.; Komenda, A. Quantifying privacy leakage in multi-agent planning. ACM Trans. Internet Technol. 2018, 18, 28. [Google Scholar] [CrossRef]
- Lichtenthäler, C.; Lorenzy, T.; Kirsch, A. Influence of legibility on perceived safety in a virtual human-robot path crossing task. In Proceedings of the IEEE RO-MAN: The 21st IEEE International Symposium on Robot and Human Interactive Communication, Paris, France, 9–13 September 2012; pp. 676–681. [Google Scholar]
- Dragan, A.D.; Lee, K.C.; Srinivasa, S.S. Legibility and predictability of robot motion. In Proceedings of the 8th ACM/IEEE International Conference on Human-Robot Interaction, Tokyo, Japan, 3–6 March 2013; pp. 301–308. [Google Scholar]
- Wortham, R.H.; Theodorou, A. Robot transparency, trust and utility. Connect. Sci. 2017, 29, 242–248. [Google Scholar] [CrossRef]
- Chakraborti, T.; Kulkarni, A.; Sreedharan, S.; Smith, D.E.; Kambhampati, S. Explicability? legibility? predictability? transparency? privacy? security? The emerging landscape of interpretable agent behavior. arXiv 2019, arXiv:1811.09722. [Google Scholar]
- Rosenfeld, A.; Richardson, A. Explainability in human-agent systems. Auton. Agents Multi-Agent Syst. 2019. [Google Scholar] [CrossRef]
- Gong, Z.; Zhang, Y. Behavior Explanation as Intention Signaling in Human-Robot Teaming. In Proceedings of the 27th IEEE International Symposium on Robot and Human Interactive Communication, Nanjing and Tai’an, China, 27 August–1 September 2018; pp. 1005–1011. [Google Scholar]
- Rowe, N.C.; Andrade, S.F. Counterplanning for Multi-Agent Plans Using Stochastic Means-Ends Analysis. In Proceedings of the 2002 IASTED IASTED Artificial Intelligence and Applications Conference, Malaga, Spain, 9–12 September 2002. [Google Scholar]
- Pozanco, A.; E-Martín, Y.; Fernandez, S.; Borrajo, D. Counterplanning using Goal Recognition and Landmarks. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Stockholm, Sweden, 13–19 July 2018; pp. 4808–4814. [Google Scholar]
- Masters, P.; Sardina, S. Deceptive Path-Planning. In Proceedings of the Twenty-sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Sarah, K.; Avigdor, G.; Karpas, E. Privacy Preserving Plans in Partially Observable Environments. In Proceedings of the Twenty-five International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Leaute, T.; Faltings, B. Protecting privacy through distributed computation in multi-agent decision making. J. Artif. Intell. Res. 2013, 47, 649–695. [Google Scholar] [CrossRef]
- Wu, F.; Zilberstein, S.; Chen, X. Privacy-Preserving Policy Iteration for Decentralized POMDPs. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Wen, Y.; Yang, Y.; Luo, R.; Wang, J.; Pan, W. Probabilistic recursive reasoning for multi-agent reinforcement learning. arXiv 2019, arXiv:1901.09207. [Google Scholar]
- Štolba, M. Reveal or Hide: Information Sharing in Multi-Agent Planning. Ph.D. Thesis, Czech Technical University in Prague, Prague, Czech Republic, 2017. [Google Scholar]
- Strouse, D.; Kleiman-Weiner, M.; Tenenbaum, J.; Botvinick, M.; Schwab, D. Learning to Share and Hide Intentions using Information Regularization. arXiv 2018, arXiv:1808.02093. [Google Scholar]
- Strouse, D. Optimization of Mutual Information in Learning: Explorations in Science. Ph.D. Thesis, Princeton University, Princeton, NJ, USA, 2018. [Google Scholar]
- Wray, K.H.; Kumar, A.; Zilberstein, S. Integrated cooperation and competition in multi-agent decision-making. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Sanjab, A.; Saad, W.; Başar, T. Prospect theory for enhanced cyber-physical security of drone delivery systems: A network interdiction game. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Hota, A.R.; Sundaram, S. Interdependent security games on networks under behavioral probability weighting. IEEE Trans. Control Netw. Syst. 2016, 5, 262–273. [Google Scholar] [CrossRef]
- Tsitsiklis, J.N.; Xu, K. Delay-predictability trade-offs in reaching a secret goal. Oper. Res. 2018, 66, 587–596. [Google Scholar] [CrossRef]
- Xu, K.; Yin, Q.; Qi, Z. A New Metric and Method for Goal Identification Control. In Proceedings of the IJCAI Workshop on Goal Reasoning, Stockholm, Sweden, 13–19 July 2018; pp. 13–18. [Google Scholar]
- Smith, J.C.; Song, Y. A Survey of Network Interdiction Models and Algorithms. Eur. J. Oper. Res. 2019. [Google Scholar] [CrossRef]
- Dahan, M.; Amin, S. Security Games in Network Flow Problems. arXiv 2016, arXiv:1601.07216. [Google Scholar]
- Smith, J.C.; Lim, C. Algorithms for network interdiction and fortification games. In Pareto Optimality, Game Theory and Equilibria; Springer Optimization and Its Applications; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Kennedy, K.T.; Deckro, R.F.; Moore, J.T.; Hopkinson, K.M. Nodal interdiction. Math. Comput. Model. 2011. [Google Scholar] [CrossRef]
- Xiao, K.; Zhu, C.; Zhang, W.; Wei, X.; Hu, S. Stackelberg network interdiction game: Nodal model and algorithm. In Proceedings of the 2014 5th International Conference on Game Theory for Networks, GameNets 2014, Beijing, China, 25–27 November 2014. [Google Scholar] [CrossRef]
- Avrahami-Zilberbrand, D.; Kaminka, G.A. Incorporating observer biases in keyhole plan recognition (efficiently!). In Proceedings of the Twenty-First AAAI Conference on Artificial Intelligence, Boston, MA, USA, 16–20 July 2006; Volume 7, pp. 944–949. [Google Scholar]
- Cohen, P.R.; Perrault, C.R.; Allen, J.F. Beyond question answering. Strateg. Nat. Lang. Process. 1981, 245274. [Google Scholar]
- Mirsky, R.; Gal, K.; Stern, R.; Kalech, M. Goal and Plan Recognition Design for Plan Libraries. ACM Trans. Intell. Syst. Technol. 2019, 10, 14. [Google Scholar] [CrossRef]
- Ramírez, M.; Geffner, H. Plan recognition as planning. In Proceedings of the Twenty-First International Joint Conference on Artificial Intelligence, Pasadena, CA, USA, 14–17 July 2009. [Google Scholar]
- Zeng, Y.; Xu, K.; Yin, Q.; Qin, L.; Zha, Y.; Yeoh, W. Inverse Reinforcement Learning Based Human Behavior Modeling for Goal Recognition in Dynamic Local Network Interdiction. In Proceedings of the Workshops at the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Masters, P.; Sardina, S. Cost-Based Goal Recognition in Navigational Domains. J. Artif. Intell. Res. 2019, 64, 197–242. [Google Scholar] [CrossRef]
- Wayllace, C.; Hou, P.; Yeoh, W. New Metrics and Algorithms for Stochastic Goal Recognition Design Problems. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 4455–4462. [Google Scholar]
- Wayllace, C.; Hou, P.; Yeoh, W.; Son, T.C. Goal recognition design with stochastic agent action outcomes. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Kulkarni, A.; Klenk, M.; Rane, S.; Soroush, H. Resource Bounded Secure Goal Obfuscation. In Proceedings of the AAAI Fall Symposium on Integrating Planning, Diagnosis and Causal Reasoning, Arlington, VA, USA, 18–20 October 2018. [Google Scholar]
- Braynov, S. Adversarial planning and plan recognition: Two sides of the same coin. In Proceedings of the Secure Knowledge Management Workshop, Brooklyn, NY, USA, 28–29 September 2006. [Google Scholar]
- Wayllace, C.; Keren, S.; Yeoh, W.; Gal, A.; Karpas, E. Accounting for Partial Observability in Stochastic Goal Recognition Design: Messing with the Marauder’s Map. In Proceedings of the 10th Workshop on Heuristics and Search for Domain-Independent Planning (HSDIP), Delft, The Netherlands, 26 June 2018; p. 33. [Google Scholar]
- Ang, S.; Chan, H.; Jiang, A.X.; Yeoh, W. Game-theoretic goal recognition models with applications to security domains. In Proceedings of the International Conference on Decision and Game Theory for Security, Vienna, Austria, 23–25 October 2017; pp. 256–272. [Google Scholar]
- Keren, S.; Pineda, L.; Gal, A.; Karpas, E.; Zilberstein, S. Equi-reward utility maximizing design in stochastic environments. In Proceedings of the HSDIP 2017, Pittsburgh, PA, USA, 20 June 2017; p. 19. [Google Scholar]
- Shen, M.; How, J.P. Active Perception in Adversarial Scenarios using Maximum Entropy Deep Reinforcement Learning. arXiv 2019, arXiv:1902.05644. [Google Scholar]
- Zenklusen, R. Network flow interdiction on planar graphs. Discret. Appl. Math. 2010, 158, 1441–1455. [Google Scholar] [CrossRef]
- Vorobeychik, Y.; Pritchard, M. Plan Interdiction Games. arXiv 2018, arXiv:1811.06162. [Google Scholar]
- Panda, S.; Vorobeychik, Y. Near-optimal interdiction of factored mdps. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, Sydney, Australia, 11–15 August 2017. [Google Scholar]
- Sreekumaran, H.; Hota, A.R.; Liu, A.L.; Uhan, N.A.; Sundaram, S. Multi-agent decentralized network interdiction games. arXiv 2015, arXiv:1503.01100. [Google Scholar]
- Smith, G. On the foundations of quantitative information flow. In Proceedings of the International Conference on Foundations of Software Science and Computational Structures, York, UK, 22–29 March 2009; pp. 288–302. [Google Scholar]
- Crooks, G.E. On measures of entropy and information. Tech. Note 2017, 9, v4. [Google Scholar]
- Clark, C.R. The Threshold Shortest Path Interdiction Problem for Critical Infrastructure Resilience Analysis; Technical Report; Naval Postgraduate School Monterey United States: Monterey, CA, USA, 2017. [Google Scholar]
- Geoffrion, A.M. Generalized Benders decomposition. J. Optim. Theory Appl. 1972. [Google Scholar] [CrossRef]
- Israeli, E.; Wood, R.K. Shortest-Path Network Interdiction. Networks 2002. [Google Scholar] [CrossRef]
- Erdős, P.; Rényi, A. On random graphs. I. Publ. Math. 1959, 4, 3286–3291. [Google Scholar]
- Bar-Gera, H. Transportation Networks for Resear. Available online: https://github.com/bstabler/TransportationNetworks (accessed on 1 March 2019).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Meaning |
|---|---|
| Sets and indices | |
| Road graph network with nodes and edges | |
| Node i in | |
| Edge in | |
| Start node s | |
| Goal node g | |
| Edges set directed into or out of node i | |
| Data | |
| Cost of edge a, vector form | |
| Interdiction increment if edge a is interdicted, vector form | |
| The privacy information metric of action a | |
| Resource required to interdict edge a, vector form | |
| R | Total amount of interdiction resource available |
| Threshold of the shortest path | |
| Upper bound with full interdiction | |
| Lower bound without interdiction | |
| Decision Variables | |
| Observer’s interdiction resource allocation, if edge a is interdicted | |
| Actor’s traveling edge, if edge a is traveled by the actor | |
| Scenario 1 | Scenario 2 | Scenario 3 | |
|---|---|---|---|
| InfoGRC | 65.4/63.7 | 62.7/78.4 | 88.7/77.5/90.8 |
| InfoGRCT | 65.1/63.3 | 62.1/78.1 | 88.2/77.2/90.4 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, J.; Ji, X.; Gao, W.; Zhang, W.; Chen, S. Goal Recognition Control under Network Interdiction Using a Privacy Information Metric. Symmetry 2019, 11, 1059. https://doi.org/10.3390/sym11081059
Luo J, Ji X, Gao W, Zhang W, Chen S. Goal Recognition Control under Network Interdiction Using a Privacy Information Metric. Symmetry. 2019; 11(8):1059. https://doi.org/10.3390/sym11081059
Chicago/Turabian StyleLuo, Junren, Xiang Ji, Wei Gao, Wanpeng Zhang, and Shaofei Chen. 2019. "Goal Recognition Control under Network Interdiction Using a Privacy Information Metric" Symmetry 11, no. 8: 1059. https://doi.org/10.3390/sym11081059
APA StyleLuo, J., Ji, X., Gao, W., Zhang, W., & Chen, S. (2019). Goal Recognition Control under Network Interdiction Using a Privacy Information Metric. Symmetry, 11(8), 1059. https://doi.org/10.3390/sym11081059