Behavioral Habits-Based User Identification Across Social Networks

Abstract
:1. Introduction
- Integrate user information from multiple accounts, enabling more accurate judgement of the user’s hobbies, etc. and thus the ability to offer better recommendations and services [3];
- Improve analysis and prediction of user behavior patterns in ways that cannot be achieved on a single social network [4];
- Provide researchers with more complete user data [5];
- Detect malicious users in a timely manner and provide targeted assistance to the network security field.
- We analyzed the redundant information contained in the display name and extract the length feature, character feature, and letter feature;
- We adopted the variant entropy value to assign weights to the features contained in the display name;
- We used the latent Dirichlet allocation (LDA) model to analyze the content posted by users and extract the user’s interest graph;
- In order to improve user identification performance, we combined one-to-one constraint with the Gale–Shapley algorithm to optimize the user account matching results.
2. Related Works
2.1. User Profile Data-Based User Identification
2.2. Network Structure-Based User Identification
2.3. User-Generated Content-Based User Identification
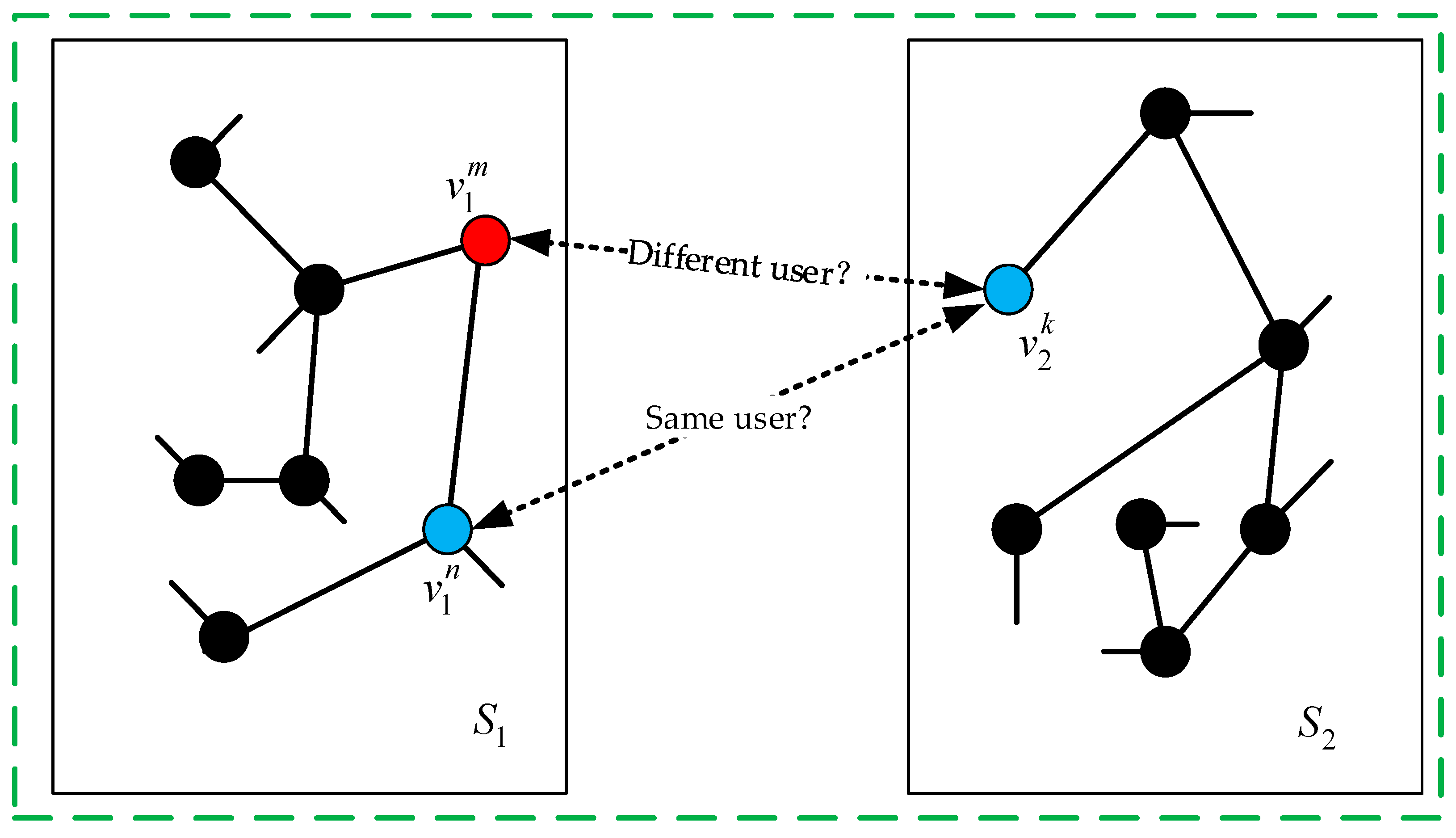
3. Problem Definition
4. The Method of User Identification
4.1. Display Name Analysis
4.1.1. Length Feature
4.1.2. Character Feature
4.1.3. Letter Feature
4.1.4. Weight Assignment Based on Variant Entropy Value
| Algorithm 1: Display Name Feature Weight Assignment |
| Input: Source network account feature vector , feature vectors for all accounts in the target network, feature vector to be matched account in the target network Output: (the weight of the ith feature of accounts j and k) 1: For each in (m represents the number of all accounts to be matched in the target network) 2: for i = 1 to n 3: Calculate display name similarity of accounts C and D by using equations (2) (3) (4) 4: end 5: for i = 1 to n 6: The attribute weights of display name features are assigned using Equation (5) (6) (7) (8)(9) 7: end 8: Return |
4.2. User-Published Content Analysis
- The abovementioned introduction to the basic knowledge and related symbols of LDA. For user-generated documents, the prior distribution of the topic is a Dirichlet distribution. In other words, for any document d, the probability distribution of the document on the k topics is generated from the Dirichlet distribution;
- For the cth word in the document:
- (a)
- We first need to show the distribution of topics corresponding to the cth word, then the specific subject of its expression is derived from a multivariate distribution: ;
- (b)
- Next, we should find out the specific words that correspond to the topic, generate a concrete word that expresses the subject from a multivariate distribution: ;
- Generate a probability distribution of the topic k on all words from the Dirichlet distribution.
| Algorithm 2: Similarity Calculation of User Interest Graph |
| Input: Behavior data of user accounts i and j, related parameter settings including , , and T. Output: Interest graph similarity between accounts i and j. 1: Set the time interval window 2: The topic distribution of user account is calculated via the LDA model 3: Form the topic matrix B 4: Calculate the KL divergence of the user topic by Equation (14) 5: Calculate the similarity between topics by Equation (15) 6: The user’s interest graphs are obtained by comparing the threshold T 7: Reconstitute topic matrix 8: Interest graph similarity of accounts i and j is calculated using cosine similarity 9: Return |
4.3. User Account Matching
| Algorithm 3: User Matching with One-To-One Constraint |
| Input: Output: 1: For each user account , belonging to and 2: Two probability sets and are formed by the classifier, respectively 3: while or 4: Select from , 5: If not matched 6: Add to R 7: Else 8: Compare the priorities of user account and in (Assume that and are matched accounts.) 9: If > 10: Remove from R 11: Add to R 12: Else 13: ignore 14: Return R |
5. Experimental Results and Analysis
5.1. Dataset analysis
5.2. Evaluation Metrics
5.3. Selection of Experimental Parameters
5.3.1. Threshold Setting of Interest Graph
5.3.2. KL Divergence Distribution of User Interests
5.3.3. Time Interval Window Selection
5.4. Impact of Data Used on Identification Performance
5.4.1. Impact of User Data on User Identification
5.4.2. Impact of Weight on User Identification
5.5. Complexity Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Most Famous Social Network Sites Worldwide as of April 2019, Ranked by Number of Active Users. Available online: https://www.statista.com/statistics/272014/global-social-networks-ranked-by-number-of-users/ (accessed on 10 August 2019).
- Liu, J.; Zhang, F.; Song, X.; Song, Y.I.; Lin, C.Y.; Hon, H.W. What’s in a name? An unsupervised approach to link users across communities. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining, Rome, Italy, 4–8 February 2013; pp. 495–504. [Google Scholar]
- Zheng, J.X.; Li, D.Y.; Kumar, S.A. Group user profile modeling based on neural word embeddings in social networks. Symmetry 2018, 10, 435. [Google Scholar] [CrossRef]
- Li, C.; Lin, S. Matching users and items across domains to improve the recommendation quality. In Proceedings of the KDD, New York, NY, USA, 24–27 August 2014; ACM: New York, NY, USA, 2014; pp. 801–810. [Google Scholar]
- Nie, Y.; Jia, Y.; Li, S.; Zhu, X.; Li, A.; Zhou, B. Identifying users across social networks based on dynamic core interests. Neurocomputing 2016, 210, 107–115. [Google Scholar] [CrossRef]
- Li, Y.J.; Peng, Y.; Ji, W.L.; Zhang, Z.; Xu, Q.Q. User identification based on the display name across online social network sites. IEEE Access 2017, 5, 17342–17353. [Google Scholar] [CrossRef]
- Zhou, X.P.; Liang, X.; Zhang, H.Y.; Ma, Y.F. Cross-platform identification of anonymous identical users in multiple social media networks. IEEE Trans. Knowl. Data Eng. 2016, 28, 411–424. [Google Scholar] [CrossRef]
- Shu, K.; Wang, S.; Tang, J.; Zafarani, R.; Liu, H. User identity linkage across online social networks: A review. ACM SIGKDD Explor. 2017, 18, 5–17. [Google Scholar] [CrossRef]
- Deng, K.K.; Xing, L.; Zheng, L.S.; Wu, H.H.; Xie, P.; Gao, F.F. A user identification algorithm based on user behavior analysis in social networks. IEEE Access 2019, 9, 47114–47123. [Google Scholar] [CrossRef]
- Deng, K.K.; Xing, L.; Zhang, M.C.; Wu, H.H.; Xie, P. A multiuser identification algorithm based on internet of things. Wirel. Commun. Mob. Comput. 2019, 2019, 6974809. [Google Scholar] [CrossRef]
- Zafarani, R.; Liu, H. Connecting corresponding identities across communities. In Proceedings of the International Conference on Weblogs and Social Media, San Jose, CA, USA, 17–20 May 2009; Volume 9, pp. 354–357. [Google Scholar]
- Perito, D.; Castelluccia, C.; Kaafar, M.A.; Manils, P. How unique and traceable are usernames. In International Symposium on Privacy Enhancing Technologies Symposium; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6794, pp. 1–17. [Google Scholar]
- Wang, Y.B.; Liu, T.W.; Tan, Q.F.; Shi, J.Q.; Guo, L. Identifying users across different sites using usernames. Procedia Comput. Sci. 2016, 80, 376–385. [Google Scholar] [CrossRef]
- Vosecky, J.; Hong, D.; Shen, V.Y. User identification across multiple social networks. In Proceedings of the 2009 First International Conference on Networked Digital Technologies, Ostrava, Czech, 28–31 July 2009; pp. 360–365. [Google Scholar]
- Motoyama, M.; Varghese, G. I seek you: Searching and matching individuals in social networks. In Proceedings of the 11th International Workshop on Web Information and Data Management, Hong Kong, China, 2 November 2009; pp. 67–75. [Google Scholar]
- Raad, E.; Chbeir, R.; Dipanda, A. User profile matching in social networks. In Proceedings of the 13th International Conference on Network-Based Information Systems, Takayama, Japan, 14–16 September 2010; pp. 297–304. [Google Scholar]
- Iofciu, T.; Fankhauser, P.; Abel, F.; Bischoff, K. Identifying users across social tagging systems. In Proceedings of the 5th International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 1 January 2011; pp. 522–525. [Google Scholar]
- Ye, N.; Zhao, L.; Dong, L.; Bian, G.; Liu, E.; Clapworthy, G.J. User identification based on multiple attribute decision making in social networks. China Commun. 2013, 10, 37–49. [Google Scholar]
- Li, Y.J.; Peng, Y.; Zhang, Z.; Yin, H.Z.; Xu, Q.Q. Matching user accounts across social networks based on username and display name. World Wide Web. 2018, 22, 1075–1097. [Google Scholar] [CrossRef]
- Narayanan, A.; Shmatikov, V. De-anonymizing social networks. In Proceedings of the 30th IEEE Symposium on Security and Privacy, Los Alamitos, CA, USA, 17–20 May 2009; Volume 1, pp. 173–187. [Google Scholar]
- Cui, Y.; Pei, J.; Tang, G.T.; Luk, W.S.; Jiang, D.X.; Hua, M. Finding email correspondents in online social networks. World Wide Web. 2013, 16, 195–218. [Google Scholar] [CrossRef]
- Kong, X.; Zhang, J.; Yu, P.S. Inferring anchor links across multiple heterogeneous social networks. In Proceedings of the 22nd ACM International Conference on Information and Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 179–188. [Google Scholar]
- Korula, N.; Lattanzi, S. An efficient reconciliation algorithm for social networks. Proc. VLDB Endow. 2014, 7, 377–388. [Google Scholar] [CrossRef]
- Tan, S.L.; Guan, Z.Y.; Cai, D.; Qin, X.Z.; Bu, J.J.; Chen, C. Mapping users across networks by manifold alignment on hypergraph. In Proceedings of the 28th AAAI Conference on Artificial Intelligence, Québec, QC, Canada, 27–31 July 2014; pp. 159–165. [Google Scholar]
- Zhou, X.P.; Liang, X.; Du, X.Y.; Zhao, J.C. Structure based user identification across social networks. IEEE Trans. Knowl. Data Eng. 2018, 30, 1178–1191. [Google Scholar] [CrossRef]
- Almishari, M.; Tsudik, G. Exploring linkability of user reviews. Comput. Secur.-ESORICS 2012, 7459, 307–324. [Google Scholar]
- Sha, Y.; Liang, Q.; Zheng, K.J. Matching user accounts across social networks based on users message. Procedia Comput. Sci. 2016, 80, 2423–2427. [Google Scholar] [CrossRef]
- Roedler, R.; Kergl, D.; Rodosek, G.D. Profile matching across online social networks based on geo-tag. Adv. Nat. Biol. Inspired Comput. 2016, 419, 417–428. [Google Scholar]
- Li, Y.J.; Zhang, Z.; Peng, Y.; Yin, H.Z.; Xu, Q.Q. Matching user accounts based on user generated content across social networks. Future Gener. Comput. Syst. 2018, 83, 104–115. [Google Scholar] [CrossRef]
- Li, Y.J.; Peng, Y.; Zhang, Z.; Wu, M.J.; Xu, Q.Q. A deep dive into user display names across social networks. Inf. Sci. 2018, 447, 186–204. [Google Scholar] [CrossRef] [Green Version]
- Dubins, L.; Freedman, D. Machiavelli and the Gale-Shapley algorithm. Am. Math. Mon. 1981, 88, 485–494. [Google Scholar] [CrossRef]
- He, Z.M.; Li, W.J. Research on user identification across multiple social networks based on preference. In Proceedings of the 2018 5th IEEE International Conference on Cloud Computing and Intelligence Systems, Nanjing, China, 23–25 November 2018; pp. 122–128. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Data Type | Number |
|---|---|---|
| Sina weibo | Display name | 2000 |
| User published content | Six months | |
| Douban | Display name | 2000 |
| User published content | Six months |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xing, L.; Deng, K.; Wu, H.; Xie, P.; Gao, J. Behavioral Habits-Based User Identification Across Social Networks. Symmetry 2019, 11, 1134. https://doi.org/10.3390/sym11091134
Xing L, Deng K, Wu H, Xie P, Gao J. Behavioral Habits-Based User Identification Across Social Networks. Symmetry. 2019; 11(9):1134. https://doi.org/10.3390/sym11091134
Chicago/Turabian StyleXing, Ling, Kaikai Deng, Honghai Wu, Ping Xie, and Jianping Gao. 2019. "Behavioral Habits-Based User Identification Across Social Networks" Symmetry 11, no. 9: 1134. https://doi.org/10.3390/sym11091134
APA StyleXing, L., Deng, K., Wu, H., Xie, P., & Gao, J. (2019). Behavioral Habits-Based User Identification Across Social Networks. Symmetry, 11(9), 1134. https://doi.org/10.3390/sym11091134