1. Introduction
Among the existing distributions with support over the unit interval, the so-called Topp-Leone distribution, introduced by [
1], is one of the most useful. This success is explained by the tractability of the corresponding functions, only depending on a single parameter
. More precisely, its cumulative distribution function (cdf) and probability density function (pdf) are given by, respectively,
and
This last function is known to be a perfect example of bounded J-shaped pdf. Also, the corresponding hazard rate function (hrf) is given by
A feature of this hrf is to be of great flexibility; it can have bathtub shape or be non-increasing, depending on the values of
. Other nontrivial properties on the Topp-Leone distribution can be found in, e.g., [
2,
3,
4]. For the use of the Topp-Leone distribution in different applied statistical settings, we refer the reader to [
5,
6,
7,
8]. Some extensions of the Topp-Leone distribution can be found in [
9,
10]. On the other side, in the recent years, the Topp-Leone distribution reveals to be particularly efficient to define general families of distributions enjoying nice properties, including a great ability to model different practical data sets. Among these families, there are the Topp-Leone-G family studied via different approaches by [
11,
12,
13,
14], the Topp-Leone-G power series family by [
15,
16], the type II Topp-Leone-G family by [
17], the Topp-Leone odd log-logistic family by [
18], the type II generalized Topp-Leone-G family by [
19], the Fréchet Topp- Leone-G family by [
20], the exponentiated generalized Topp-Leone-G family by [
21] and the transmuted Topp-Leone-G family by [
22]. Now, for the purposes of this paper, let us describe the general family introduced by [
23]. It is based on the so-called power Topp-Leone distribution defined with the cdf and pdf given by, respectively,
and
The power Topp-Leone distribution corresponds to the distribution of the random variable
, where
X is a random variable following the Topp-Leone distribution (with parameter
). Obviously, the role of the parameter
is to give more flexibility to the former Topp-Leone distribution. In order to take benefit of this new parameter and open new perspectives, ref. [
23] developed the power Topp-Leone-G family defined by the following cdf:
,
, where
denotes the cdf of a continuous distribution depending on a parameter vector
.
In this paper, we explore a new direction of work by investigating the type II version of the power Topp-Leone-G family. Indeed, we define the type II power Topp-Leone-G (TIIPTL-G) family by the cdf given by
i.e.,
To the best of our knowledge, the mathematical foundations of this family has no equivalence in the statistical literature, opening the door of new modelling. Let us just notice that, for
, the corresponding cdf is reduced to
, which corresponds to the cdf of the type II Topp-Leone-G family developed by [
17]. In this sense, the TIIPTL-G family can be viewed as a generalization of the type II Topp-Leone-G family. The overall motivations behind the TIIPTL-G family are to
create distributions with different shapes for the pdf and hrf,
transform symmetrical distributions into skewed distributions,
construct heavy-tailed distributions,
increase the flexibility of the mode(s), mean, variance, skewness and kurtosis of the baseline distribution,
provide better fits than other general families (including those based on the Topp-Leone distribution) with the same baseline distribution and possibly more complex (with more parameters).
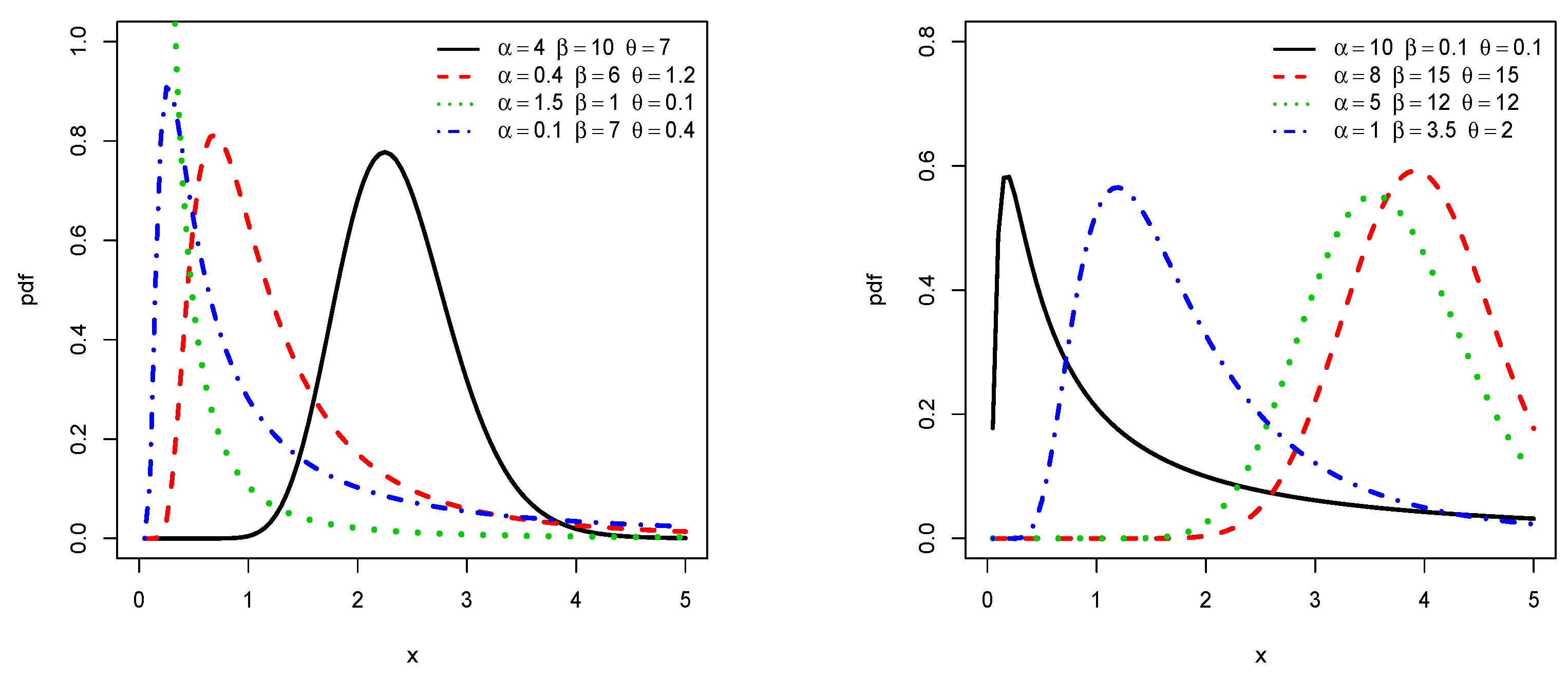
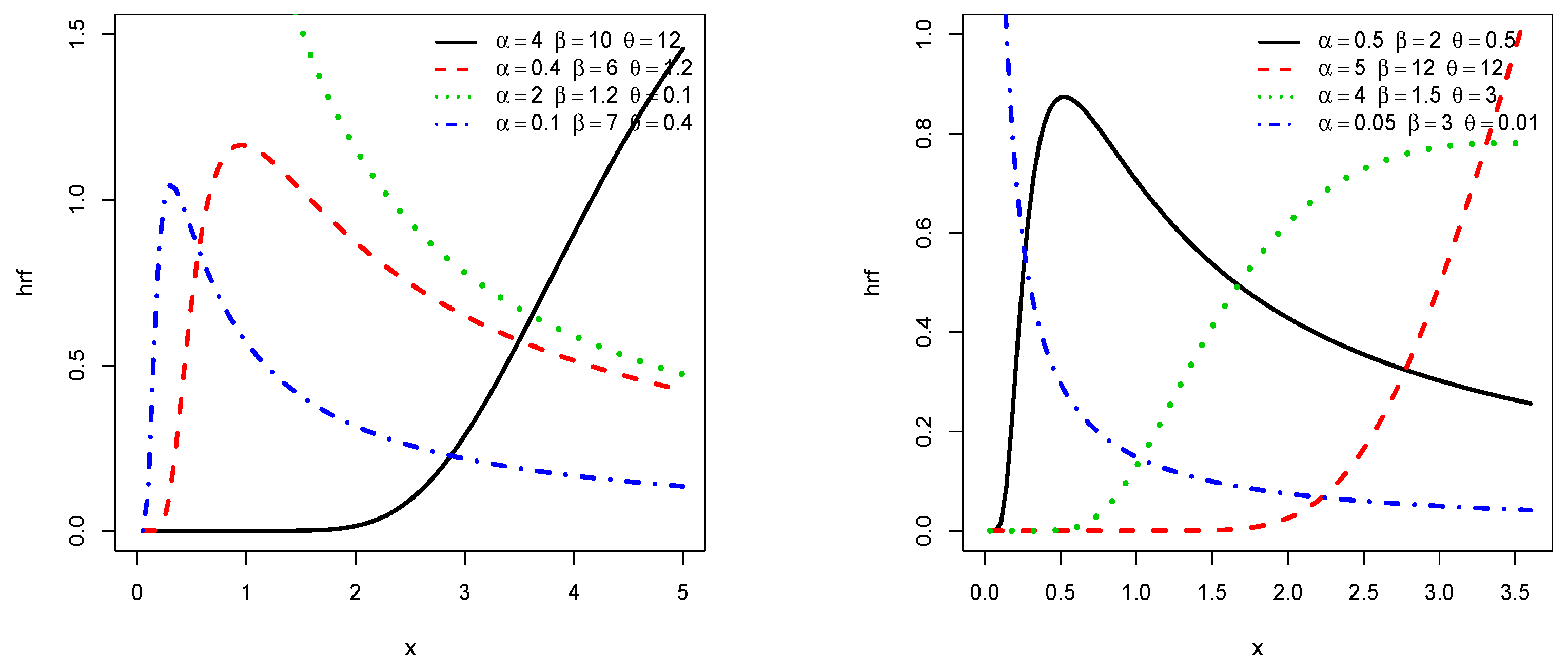
Most of these points are developed in detail in our study, with the consideration of the inverse exponential distribution as baseline. In order to motivate this choice of baseline, let us recall that the inverse exponential distribution was introduced by [
24] as a suitable alternative to the standard exponential distribution. In particular, the inverse exponential model is more appropriated than the exponential one when lifetime data present an inverted bathtub failure rate. We refer to [
25] for a complete discussion in this regard. As indicated by its name, if
X denotes a random variable following the exponential distribution with parameter
, the inverse of
X, i.e.,
, follows the inverse exponential distribution with parameter
. That is, the corresponding cdf and pdf are given by, respectively,
and
Thanks to the structure of the TIIPTL-G family, we significantly increase the practical properties of the inverse exponential distribution (more flexible shapes for the corresponding pdf, hrf, mode, skewness, kurtosis, etc.). In particular, we show that the resulting distribution can have better results in fitting data sets than seven adversary distributions, including five also based on the inverse exponential distribution.
The rest of the paper is arranged as follows.
Section 2 defines the TIIPTL-G family, with a focus on the special member previously mentioned, i.e., using the inverse exponential distribution as baseline. In
Section 3, some of general mathematical properties of the TIIPTL-G family are derived, including the quantile function, mixture representations of the corresponding cdf and pdf, several kinds of moments, stochastic ordering, reliability and order statistics. The
Section 4 is devoted to the special TIIPTL-G model using the inverse exponential distribution as baseline, with estimation of the model parameters via three different well-established methods: the maximum likelihood, percentile and right-tail Anderson-Darling methods. The TIIPTL-G models aim to be used in a data analysis setting. In this regard,
Section 5 is devoted to the analyzes of two practical data sets, with comprehensible comparison to seven other models having the same baseline distribution. The discussion ends in a conclusion presented in
Section 6.
4. Estimation and Simulation
In this section, we discuss the inferential properties of the TIIPTLIEx model (see
Section 2.4). The model parameters, i.e.,
,
and
, are investigated by three different methods: the maximum likelihood, percentile and right-tail Anderson-Darling methods, with a simulation study illustrating their convergence properties. Hereafter, we consider a random variable
X following the TIIPTLIEx distribution, as well as
n independent realizations
of
X and their rearrangements in increasing order denoted by
.
4.1. Maximum Likelihood Method of Estimation
In the context of the TIIPTLIEx model, by using (
7), the likelihood function is given by
The maximum likelihood estimates (MLEs) are given by maximizing this function according to
,
and
. They are also defined as the maximum of the log-likelihood function defined by
That is, the MLEs are the solutions of the three following equations:
,
and
, where
and
The solutions of these equations have no close form; mathematical software must be used to have a numerical evaluation of the MLEs. In this study, we use the R software (see [
28]).
4.2. Percentile Method of Estimation
We now explore the percentile method of estimation pioneered by [
29]. By using the qf of the TIIPTLIEx distribution given by (
10), we introduce the following function:
where
. Then, the percentile estimates (PCEs) of
,
and
are obtained by minimizing
according to
,
and
, which is equivalent to solve the three following equations simultaneously:
,
and
, where
and
with
and
For practical purposes, these PCEs can evaluated numerically.
4.3. Right-Tail Anderson-Darling Method of Estimation
We now discuss the right-tail Anderson-Darling estimates (RTADEs) of
,
and
pioneered by [
30]. First of all, by using the cdf and chrf of the TIIPTLIEx distribution given by (
6) and (
8), respectively, we introduce the following function:
Then, the RTADEs can be obtained by minimizing
according to
,
and
, which is equivalent to solve the three following equations simultaneously:
,
and
, where
and
with
and
The quantities , and are defined in a similar manner to , and , respectively, with instead of .
Numerical solutions are available in R to evaluate these RTADEs.
4.4. A Simulation Study
Here, we perform a simulation study giving numerical results to compare the performance of the previously presented estimation methods. Our methodology is described as follows. By using the corresponding qf, we generate
random samples of size
, 100, 200 and 500 from the TIIPTLIEx distribution. Then, four sets of the parameters are assigned as: Set1:
, Set2:
, Set3:
and Set4:
. Then, we consider the following measures: the (mean) estimates and the corresponding mean squared errors (MSEs) defined as follows:
where
,
or
, and
is the estimates of
for
via the considered method: MLE, PCE or RTADE. The obtained numerical results are documented in
Table 2,
Table 3,
Table 4 and
Table 5.
One can observe from
Table 6 that the maximum likelihood method outperforms the other methods (with the final score of 20.5). Therefore, the use of the MLEs to estimate the TIIPTLIEx model parameters is justified.
5. Applications
This section shows the potential of the TIIPTL-G family distribution in a practical setting. We consider the TIIPTLIEx model and all the consider model parameters will be estimated by the maximum likelihood method, with the use of the R software. We compare the TIIPTLIEx model with seven three(or less)-parameter models connected to the IEx model, namely: the Kumaraswamy inverse exponential (KIEx) model (see [
31]), beta inverse exponential (BIEx) model (see [
32]) by keeping shape parameter is equal to one, alpha-power inverse Weibull (AIW) model (see [
33]), logistic inverse exponential (LIEx) model (see [
34]), inverse Weibull inverse exponential (IWIEx) model (see [
35]), type II Topp-Leone generalized inverse Rayleigh (TIR) model (see [
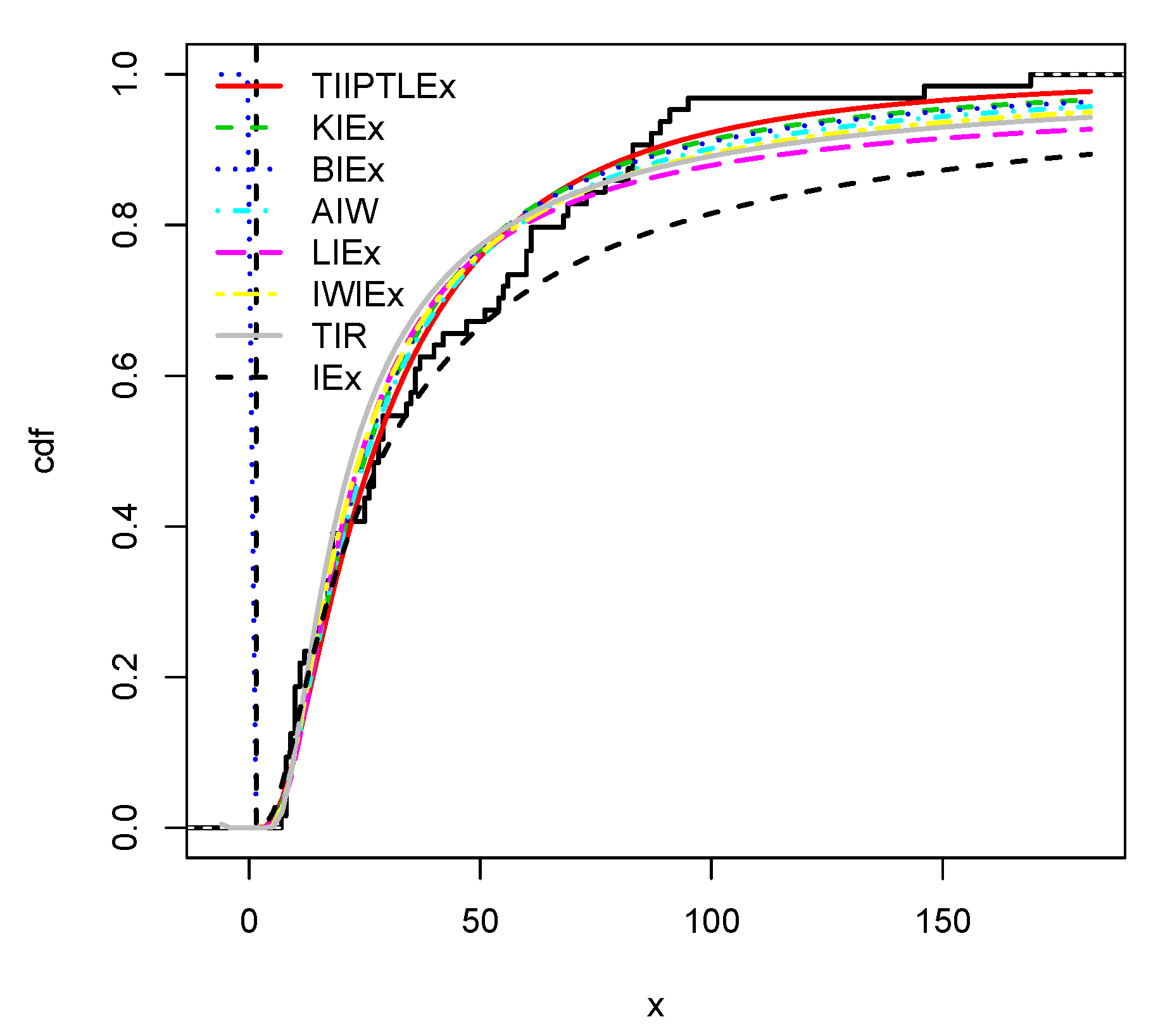
36]) and standard IEX model.
Two practical data sets are analyzed. The first data set contains the ball bearing data, which indicates the number of revolutions before failure for ball bearing (see [
37]). The data are as follows: 33.00, 68.64, 173.40, 41.52, 42.12, 68.64, 68.88, 45.60, 48.48, 84.12, 93.12, 98.64, 105.12, 105.84, 51.84, 51.96, 54.12, 17.88, 55.56, 127.92, 128.04, 67.80, 67.80, 28.92.
The second considered data set contains the waiting times (in seconds), between 65 successive eruptions of the Kiama Blowhole. These values were recorded by Jim Irish on July 12, 1998, and recently has been referenced by [
38]. The data are as follows: 83, 51, 87, 60, 28, 95, 8, 27, 15, 10, 18, 16, 29, 54, 91, 8, 17, 55, 10, 35, 47, 77, 36, 17, 21, 36, 18, 40, 10, 7, 34, 27, 28, 56, 8, 25, 68, 146, 89, 18, 73, 69, 9, 37, 10, 82, 29, 8, 60, 61, 61, 18, 169, 25, 8, 26, 11, 83, 11, 42, 17, 14, 9, 12.
The MLEs of the model parameters are documented in
Table 7 and
Table 8 for the first and second data sets, respectively. The standard goodness-of-fit measures are computed in
Table 9 and
Table 10, indicating the estimated log-likelihood
, Akaike information criterion (AIC), corrected Akaike information criterion (CAIC), Bayesian information criterion (BIC), Hannan-Quinn information criterion (HQIC), Cramer-von Mises (W*) statistic and Anderson-Darling (A*) statistic. The lower the values of these numerical criteria, the better the fit. We thus see that the TIIPTLIEx model is the best. With a focus on the TIIPTLIEx model, the P-P (Probability-Probability) plot and various fits involving estimated cdfs, sfs and pdfs over for the first and second data sets can be seen in
Figure 3 and
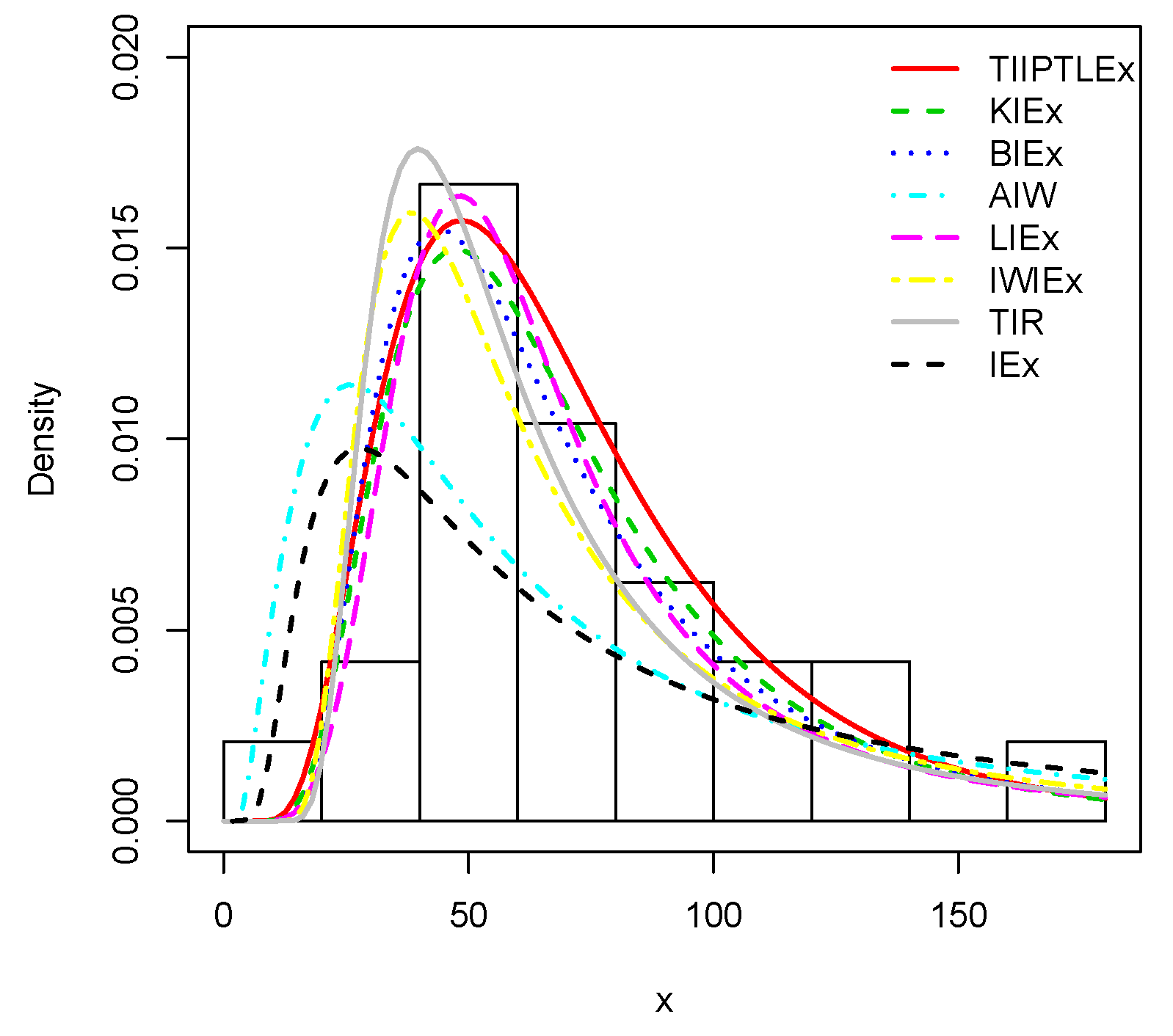
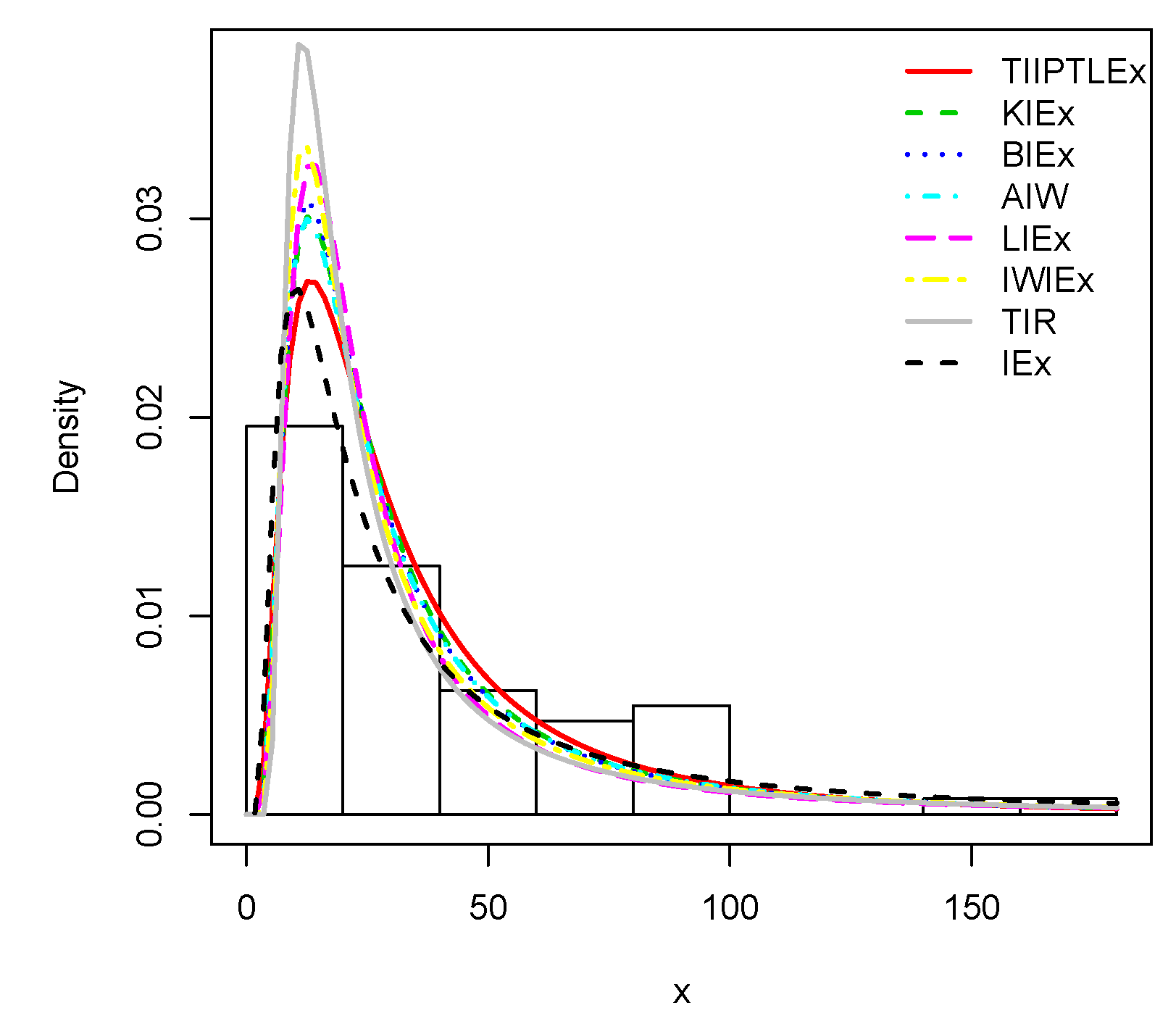
Figure 4. All of them illustrate the nice fits of the TIIPTLIEx model, showing its potential of interest for the practitioner in an analysis of data setting. We complete these analyzes by showing the fits of the estimated pdfs in
Figure 5 and
Figure 6 over the histograms of the first and second data sets, respectively. On the other hand, estimated cdfs over the empirical cdf can be seen in
Figure 7 and
Figure 8 for the first and second data sets, respectively. As remark, from the fits of the plain red line (TIIPTLIEx) and the dashed black line (IEx) in the above figures, one can notice that the TIIPTLIEx model significantly increases the flexible properties of the former IEx model, reaching new perspectives of statistical modelling for various kinds of data sets.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}