Attention-Based LSTM with Filter Mechanism for Entity Relation Classification



Abstract
:1. Introduction
2. Related Work
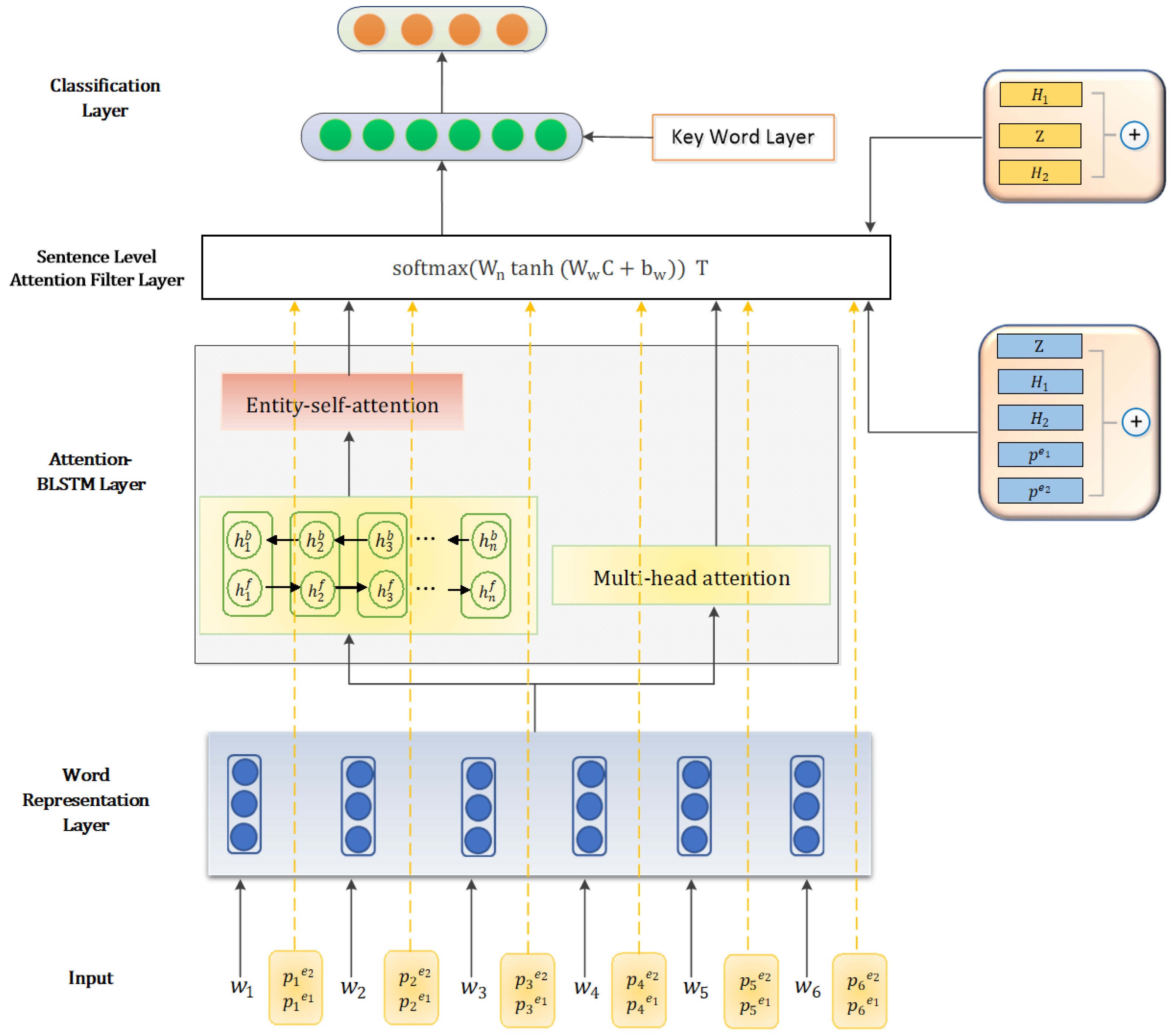
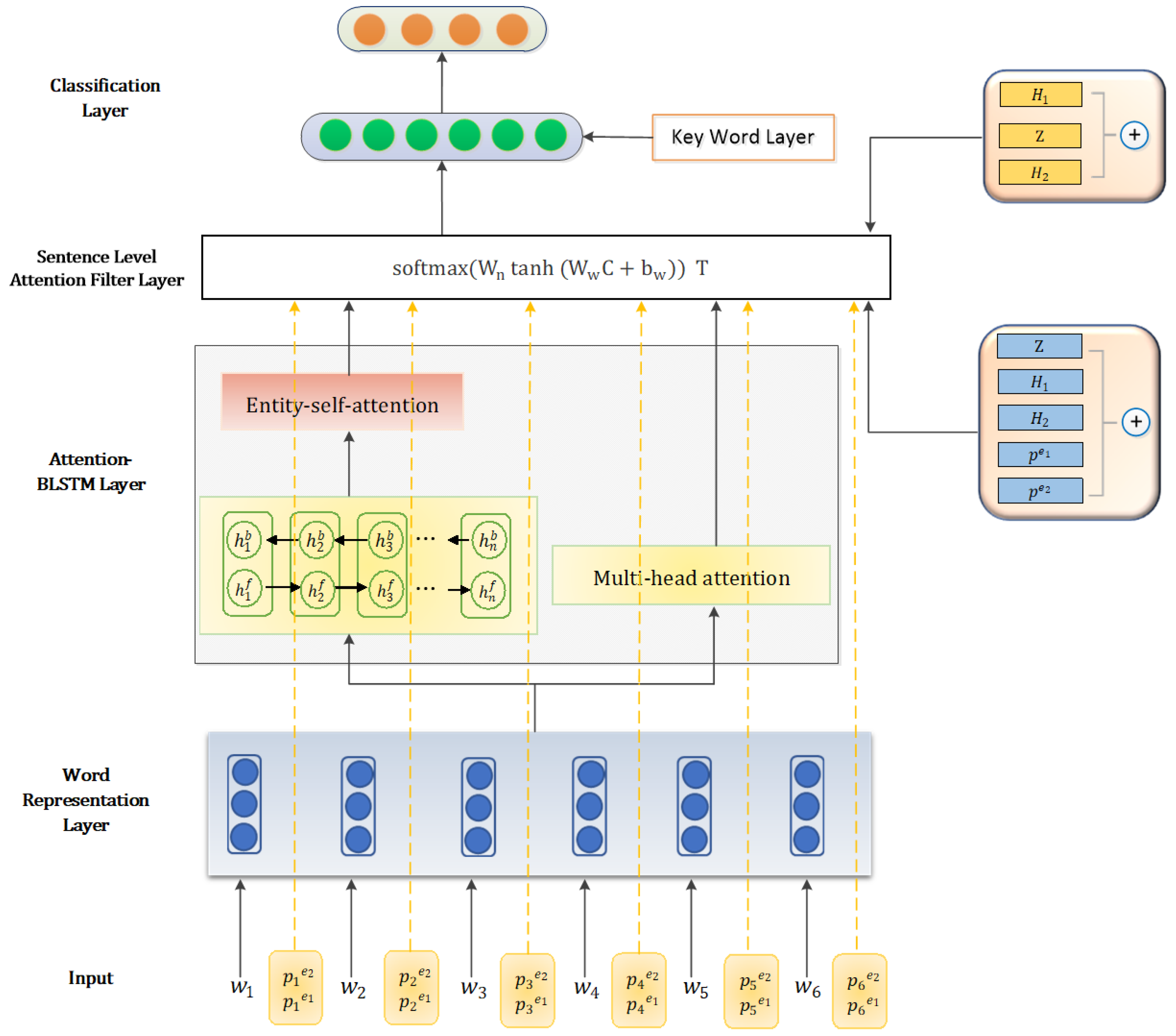
3. Our Model
- Word Representation Layer: The sentence is mapped into a real-valued vector named word embeddings.
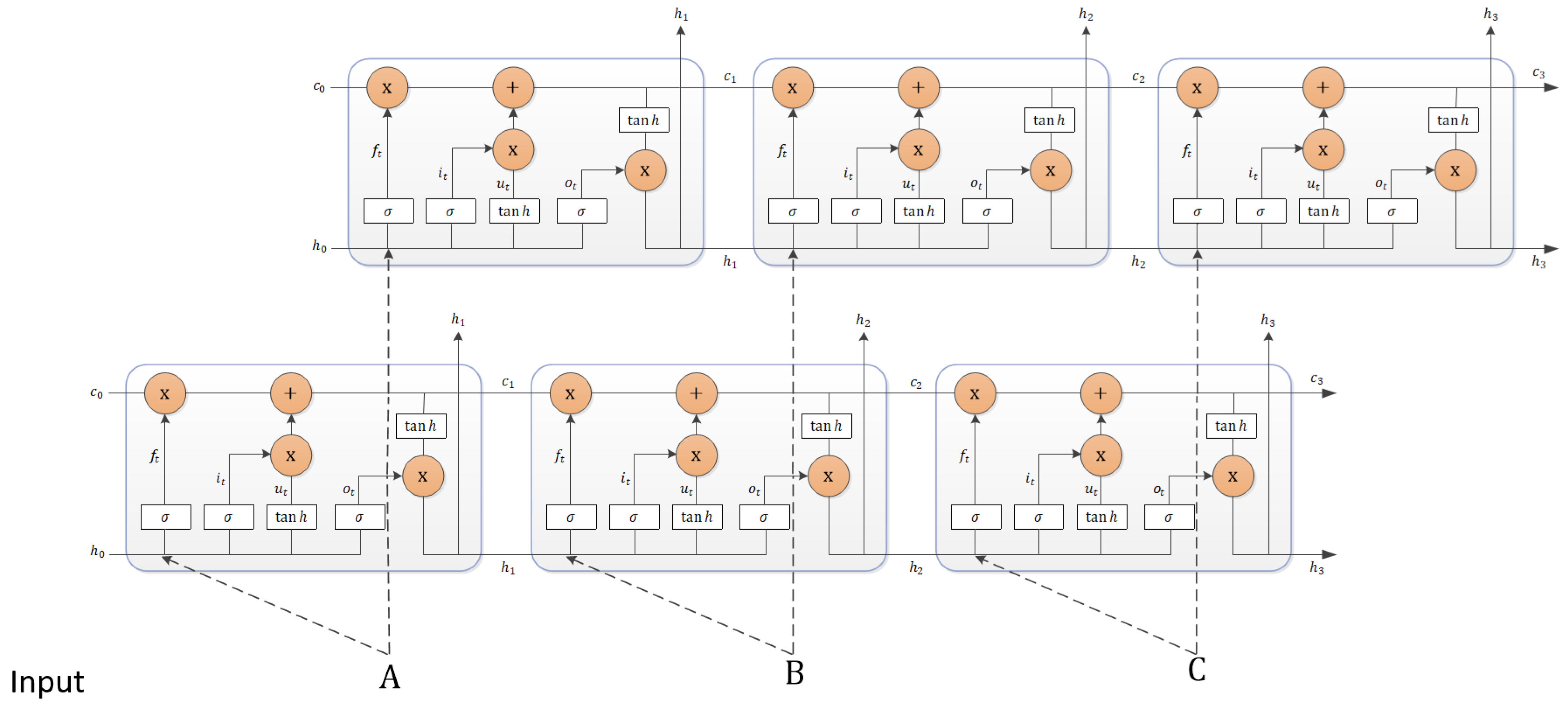
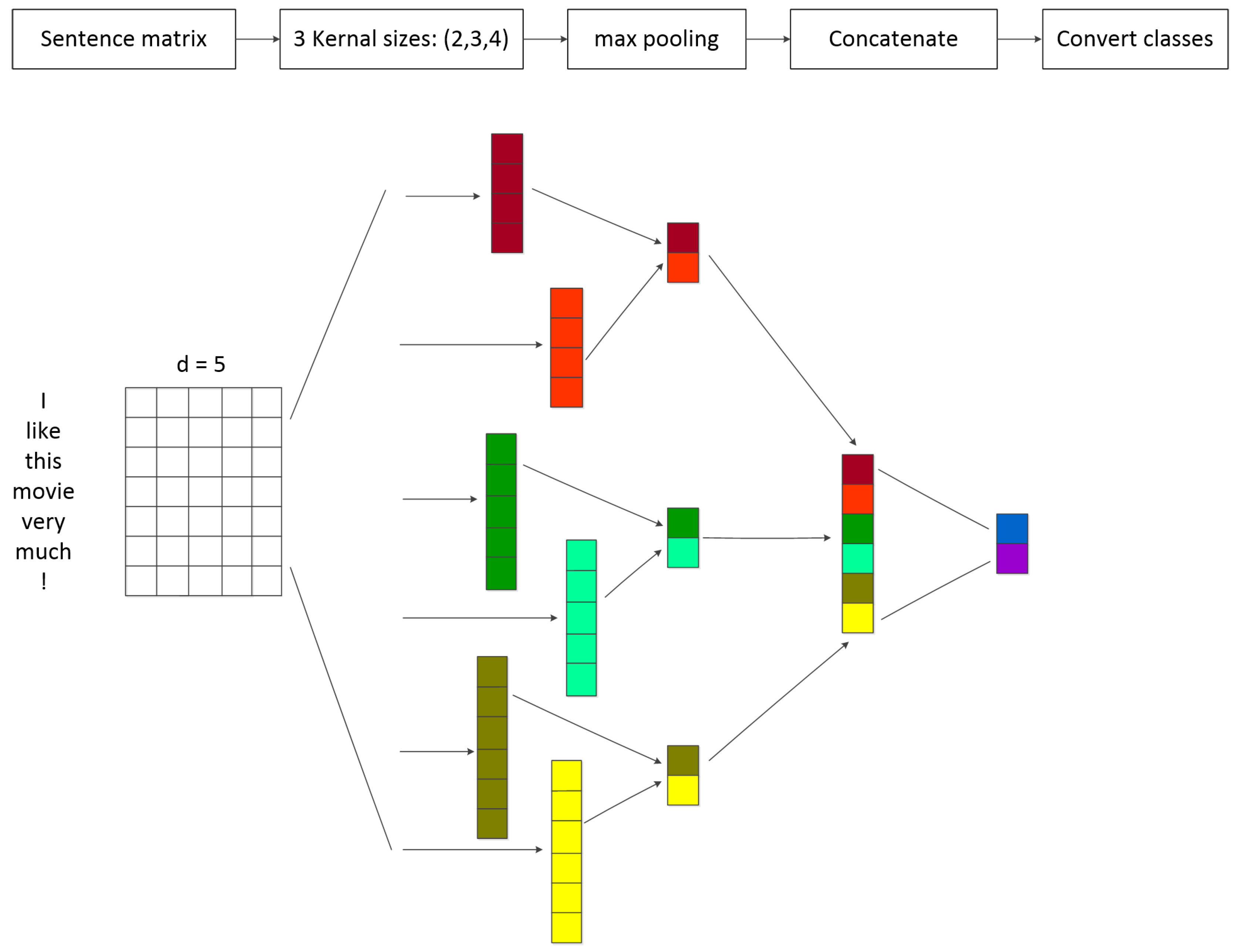
- Attention-based BLSTM Layer: This layer consists of two channels for extracting the world level features. One channel uses Bidirectional LSTM to capture context information and focus on the available features by attention mechanism Another channel directly utilizes attention mechanism to capture the similarity between words. We construct two channels to fit the feature better.
- Sentence Level Attention Filter Layer: This layer constructs a filter module to process the noise. We take all lexical level features into account aim to filter out noise and retain effective information for classification.
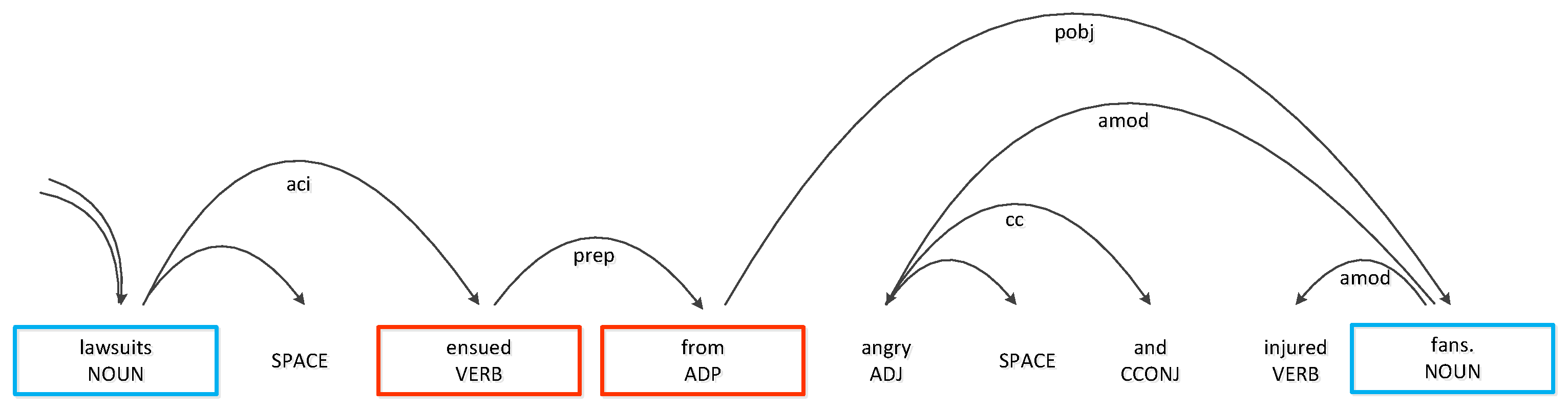
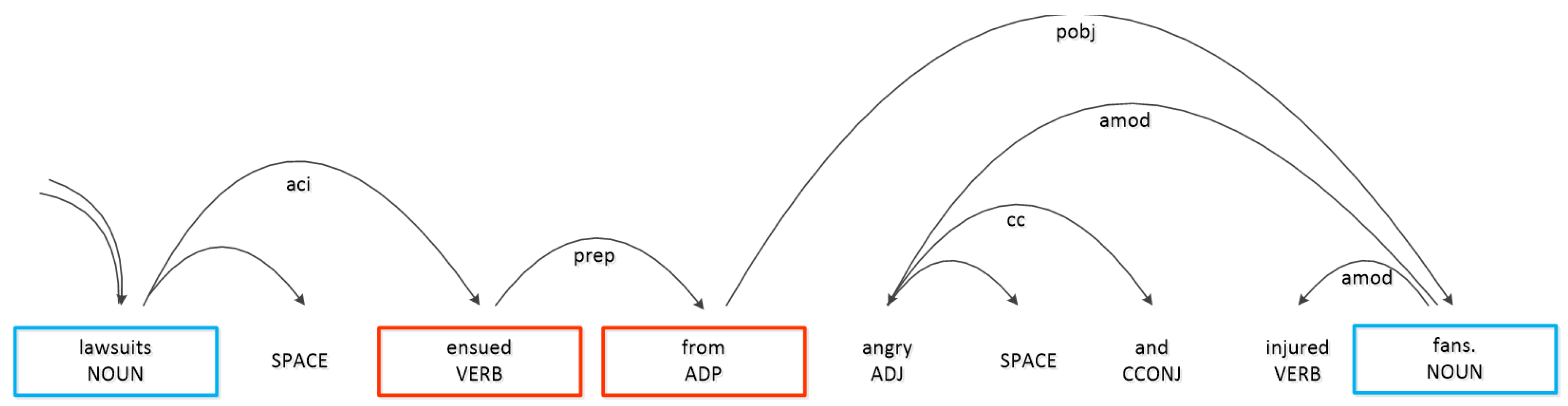
- Key Word Layer: In this layer, we analyze the sentence structure between the two target words, extract the key words for convolution, and provide auxiliary effects for classification.
- Classification Layer: High-level features will be fed into this layer. We calculate the relationship score to identify the relationship.
4. Experiment
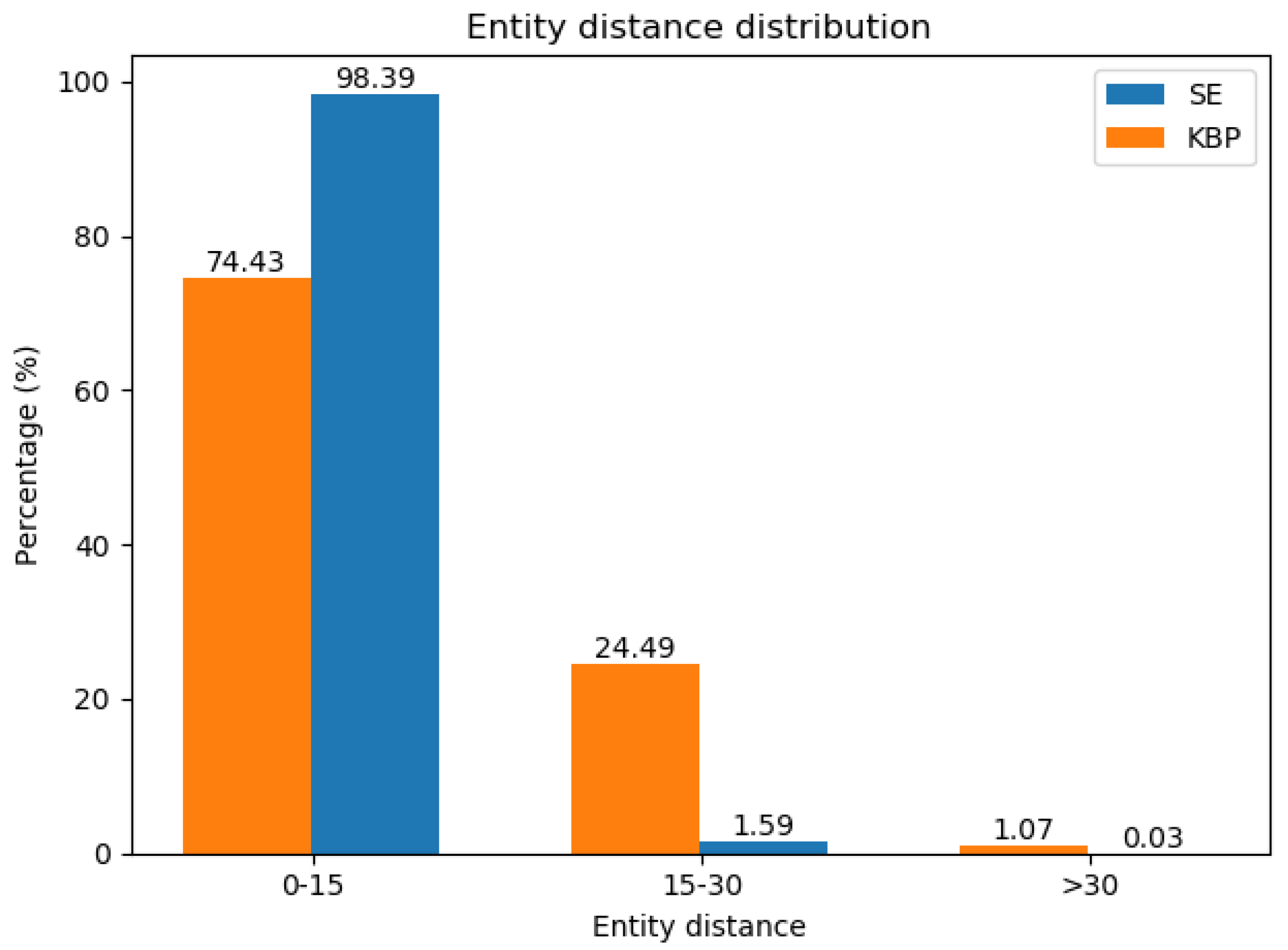
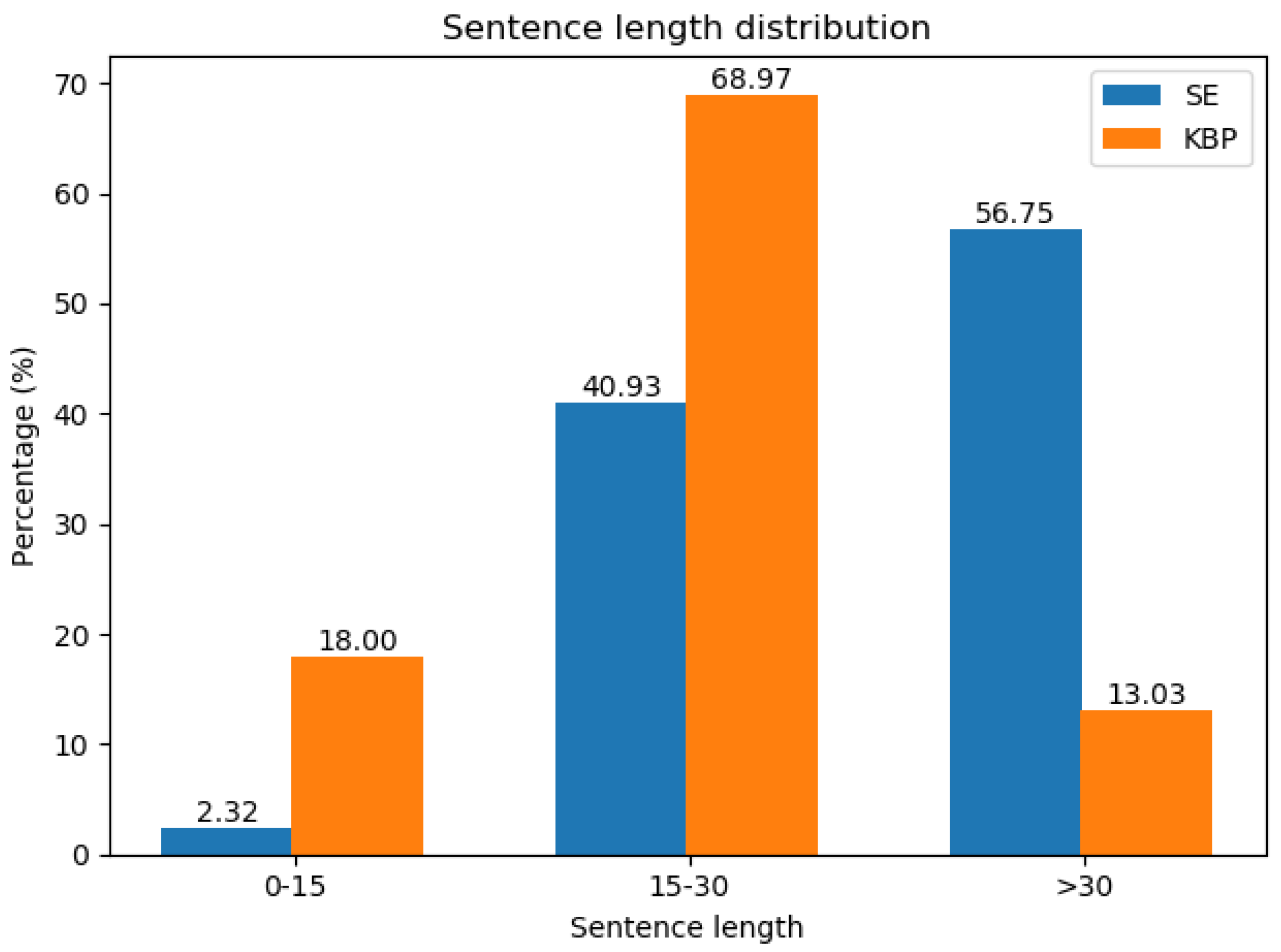
4.1. Datasets
4.2. Experiment Settings
4.3. Experiment Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fader, A.; Soderland, S.; Etzioni, O. Identifying relations for open information extraction. In Proceedings of the Empirical Methods Natural Language Processing (EMNLP), Stroudsburg, PA, USA, 27–31 July 2011; pp. 1535–1545. [Google Scholar]
- Banko, M.; Cafarella, M.J.; Soderland, S.; Broadhead, M.; Etzioni, O. Open information extraction from the web. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Hyderabad, India, 6–12 January 2007; pp. 2670–2676. [Google Scholar]
- Hao, Y.; Zhang, Y.; Liu, K.; He, S.; Liu, Z.; Wu, H.; Zhao, J. An end-to-end model for question answering over knowledge base with cross-attention combining global knowledge. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 221–231. [Google Scholar]
- Sorokin, D.; Gurevych, I. Context-aware representations for knowledge base relation extraction. In Proceedings of the Empirical Methods Natural Language Processing (EMNLP), Copenhagen, Denmark, 7–11 September 2017; pp. 1784–1789. [Google Scholar]
- Sun, R.; Jiang, J.; Fan, Y. Using syntactic and semantic relation analysis in question answering. In Proceedings of the 14th Text REtrieval Conference (TREC), Gaithersburg, MD, USA, 15–18 November 2005; p. 243. [Google Scholar]
- Yih, W.-T.; He, X.; Meek, C. Semantic parsing for single-relation question answering. In Proceedings of the Association for Computational Linguistics (ACL), Baltimore, MD, USA, 22–27 June 2014; pp. 643–648. [Google Scholar]
- Verga, P.; Belanger, D.; Strubell, E.; Roth, B.; McCallum, A. Multilingual Relation Extraction Using Compositional Universal Schema. Available online: https://arxiv.gg363.site/abs/1511.06396 (accessed on 18 July 2020).
- Minard, A.-L.; Ligozat, A.L.; Grau, B. Multi-class SVM for Relation Extraction from Clinical Reports. In Proceedings of the Recent Advances in Natural Language Processing, RANLP 2011, Hissar, Bulgaria, 12–14 September 2011; pp. 604–609. [Google Scholar]
- Jiang, J.; Zhai, C. A systematic exploration of the feature space for relation extraction. In Proceedings of the Human Language Technologies: The Conference of the North American Chapter of the Association for Computational Linguistics, Rochester, NY, USA, 22–27 April 2007; pp. 113–120. [Google Scholar]
- Yang, Y.; Tong, Y.; Ma, S.; Deng, Z.-H. A position encoding convolutional neural network based on dependency tree for relation classification. In Proceedings of the Empirical Methods Natural Language Processing (EMNLP), Austin, TX, USA, 1–5 November 2016; pp. 65–74. [Google Scholar]
- Dai, Y.; Guo, W.; Chen, X.; Zhang, Z. Relation classification via LSTMs based on sequence and tree structure. IEEE Access 2018, 6, 64927–64937. [Google Scholar] [CrossRef]
- Liu, Y.; Wei, F.; Li, S.; Ji, H.; Zhou, M.; Wang, H. A Dependency-Based Neural Network for Relation Classification. July 2015. Available online: https://arxiv.gg363.site/abs/1507.04646 (accessed on 10 July 2020).
- Xu, J.; Wen, J.; Sun, X.; Su, Q. A Discourse-Level Named Entity Recognition and Relation Extraction Dataset for Chinese Literature Text. June 2019. Available online: https://arxiv.org/abs/1711.07010 (accessed on 13 July 2020).
- Rink, B.; Harabagiu, S. UTD: Classifying semanticrelations bycombining lexical and semantic resources. In Proceedings of the 5th International Workshop on Semantic Evaluation, Los Angeles, CA, USA, 15–16 July 2010; pp. 256–259. [Google Scholar]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL), Berlin, Germany, 7–12 August 2016; pp. 207–212. [Google Scholar]
- Zhang, S.; Zheng, D.; Hu, X.; Yang, M. Bidirectional long short-term memory networks for relation classification. In Proceedings of the 29th Pacific Asia Conference on Language, Information and Computation (PACLIC), Shanghai, China, 30 October–1 November 2015; pp. 73–78. [Google Scholar]
- Zhang, D.; Wang, D. Relation Classification via Recurrent Neural Network. December 2015. Available online: https://arxiv.org/pdf/1508.01006.pdf (accessed on 18 June 2020).
- Dos Santos, C.N.; Xiang, B.; Zhou, B. Classifying relations by ranking with convolutional neural networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics (ACL), Beijing, China, 24 May 2015; Volume 1, pp. 626–634. [Google Scholar]
- Xiao, M.; Liu, C. Semantic relation classification via hierarchical recurrent neural network with attention. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 1254–1263. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Relation extraction: Perspective from convolutional neural networks. In Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing, Denver, CO, USA, 5 June 2015; pp. 39–48. [Google Scholar]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation classification via convolutional deep neural network. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- Ma, D.; Li, S.; Zhang, X.; Wang, H. Interactive attention networks for aspect-level sentiment classification. In Proceedings of the International Joint Conferences on Artificial Intelligence (IJCAI), Melbourne, Australia, 19–25 August 2017; pp. 4068–4074. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. LSTM can solve hard long time lag problems. In Proceedings of the Advances in Neural Information Processing Systems, Cambridge, MA, USA, December 1996; p. 473. [Google Scholar]
- Yan, X.; Mou, L.; Li, G.; Chen, Y.; Peng, H.; Jin, Z. Classifying Relations via Long Short Term Memory Networks along Shortest Dependency Path. arXiv 2015, arXiv:1508.03720. [Google Scholar]
- Shen, Y.; Huang, A. Attention-based convolutional neural network for semantic relation extraction. In Proceedings of the 26th International Conference on Computational Linguistics: Technical Papers (COLING 2016), Osaka, Japan, 11–16 December 2016; pp. 2526–2536. [Google Scholar]
- Zhang, X.; Chen, F.; Huang, R. A combination of RNN and CNN for attention-based relation classification. Procedia Comput. Sci. 2018, 131, 911–917. [Google Scholar] [CrossRef]
- Cao, P.; Chen, Y.; Liu, K.; Zhao, J. Adversarial Training for Relation Classification with Attention Based Gate Mechanism. In Proceedings of the China Conference on Knowledge Graph and Semantic Computing (CCKS), Tianjin, China, 14–18 August 2018; pp. 91–102. [Google Scholar]
- Lee, J.; Seo, S.; Choi, Y.S. Semantic Relation Classification via Bidirectional Lstm Networks with Entity-Aware Attention Using Latent Entity typing June 2019. Available online: https://www.mdpi.com/2073-8994/11/6/785 (accessed on 27 July 2020).
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A Neural Probabilistic Language Model. J. Mach. Learn. Res. 2003, 3, 137–1155. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Zhu, Z.; Su, J.; Zhou, Y. Improving Distantly Supervised Relation Classification with Attention and Semantic Weight. IEEE Access 2019, 7, 91160–91168. [Google Scholar] [CrossRef]
- Roze, C.; Braud, C.; Muller, P. Which aspects of discourse relations are hard to learn? September 2019. Available online: https://www.aclweb.org/anthology/W19-5950/ (accessed on 7 June 2020).
- Adilova, L.; Giesselbach, S. Making efficient use of a domain expert’s time in relation extraction. arXiv 2018, arXiv:1807.04687. [Google Scholar]
- Du, J.; Gui, L.; He, Y.; Xu, R.; Wang, X. Convolution-based neural attention with applications to sentiment classification. IEEE Access 2019, 7, 27983–27992. [Google Scholar] [CrossRef]
- Wang, P.; Wu, Q.; Shen, C.; Dick, A.; van den Hengel, A. Fvqa: Fact-based visual question answering. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2413–2427. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jin, Y.; Xie, J.; Guo, W.; Luo, C.; Wu, D.; Wang, R. LSTM-CRF Neural Network with Gated Self Attention for Chinese NER. IEEE Access 2019, 7, 136694–136709. [Google Scholar] [CrossRef]
- Sun, J.; Li, Y.; Shen, Y.; Ding, W.; Shi, X.; Zhang, L.; Shen, X.; He, J. Joint Self-Attention Based Neural Networks for Semantic Relation Extraction. J. Inf. Hiding Priv. Prot. 2019, 1, 69. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Xiang, F.; Tan, Y.; Shi, Y.; Tang, Q. Relation classification via BiLSTM-CNN. In Proceedings of the International Conference on Data Mining and Big Data, Shanghai, China, 17–22 June 2018; pp. 373–382. [Google Scholar]
- Tao, G.; Gan, Y.; He, Y. Subsequence-Level Entity Attention LSTM for Relation Extraction. In Proceedings of the 2019 16th International Computer Conference on Wavelet Active Media Technology and Information Processing, Chengdu, China, 14–15 December 2020. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| word emb dim | 1024 |
| word dropout | 0.3 |
| pos emb dim | 50 |
| LSTM dropout | 0.3 |
| LSTM hidden size | 300 |
| batch size | 20 |
| multi-heads | 4 |
| dropout | 0.5 |
| Regularization | 0.001 |
| learning rate | 0.1 |
| latent_type | 3 |
| decay rate | 0.9 |
| att_size | 50 |
| Model | F1 |
|---|---|
| Perspective -CNN (Nguyen et al. 2015) | 82.8 |
| ATT-RCNN (Zhang et al. 2018) | 83.7 |
| ATT-BLSTM (Zhou et al. 2016) | 84 |
| CRCNN (dos Santos et al. 2015) | 84.1 |
| BLSTM+ATT+AT+GATE (Cao et al. 2018) | 84.3 |
| Supervised Ranking CNN (Adilova et al. 2018) | 84.39 |
| BiLSTM-CNN+PI (Zhang et al. 2018) | 82.1 |
| BiLSTM-CNN+PF+PI (Zhang et al. 2018) | 83.2 |
| Subsequence-Level Entity Attention LSTM (G.Tao et al. 2019) | 84.7 |
| Entity-ATT-LSTM (J Lee et al. 2019) | 85.2 |
| MALNet (without filter layer and key word layer) | 84.3 |
| MALNet (without filter layer) | 85.6 |
| MALNet (without key word layer) | 85.1 |
| MALNet | 86.3 |
| Model | F1 |
|---|---|
| Perspective -CNN (Nguyen et al. 2015) | 57.1 |
| ATT-RCNN (Zhang et al. 2018) | 59.4 |
| ATT-BLSTM (Zhou et al. 2016) | 58.8 |
| CRCNN (dos Santos et al. 2015) | 58.5 |
| Supervised Ranking CNN (Adilova et al. 2018) | 61.26 |
| BiLSTM-CNN+PI (Zhang et al. 2018) | 59.1 |
| BiLSTM-CNN+PF+PI (Zhang et al. 2018) | 60.1 |
| Entity-ATT-LSTM (J Lee et al. 2019) | 58.1 |
| MALNet (without filter layer and key word layer) | 58.3 |
| MALNet (without filter layer) | 59.3 |
| MALNet (without key word layer) | 60.1 |
| MALNet | 61.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, Y.; Wu, D.; Guo, W. Attention-Based LSTM with Filter Mechanism for Entity Relation Classification. Symmetry 2020, 12, 1729. https://doi.org/10.3390/sym12101729
Jin Y, Wu D, Guo W. Attention-Based LSTM with Filter Mechanism for Entity Relation Classification. Symmetry. 2020; 12(10):1729. https://doi.org/10.3390/sym12101729
Chicago/Turabian StyleJin, Yanliang, Dijia Wu, and Weisi Guo. 2020. "Attention-Based LSTM with Filter Mechanism for Entity Relation Classification" Symmetry 12, no. 10: 1729. https://doi.org/10.3390/sym12101729
APA StyleJin, Y., Wu, D., & Guo, W. (2020). Attention-Based LSTM with Filter Mechanism for Entity Relation Classification. Symmetry, 12(10), 1729. https://doi.org/10.3390/sym12101729