An Effective and Improved CNN-ELM Classifier for Handwritten Digits Recognition and Classification


 , and
, and
Abstract
:1. Introduction
2. Related Work
3. Frameworks
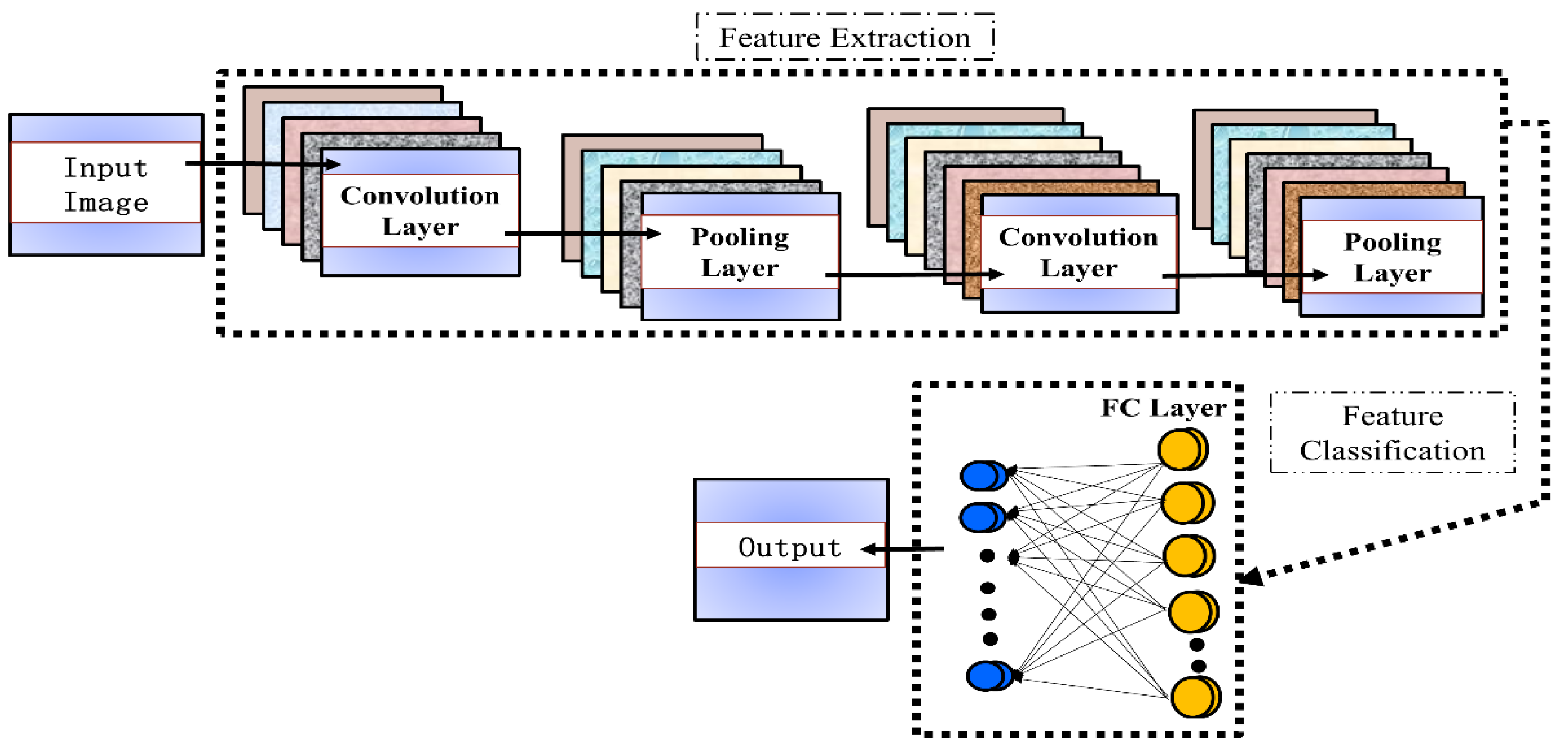
3.1. Convolution Neural Network Framework
3.2. Extreme Learning Machine Framework
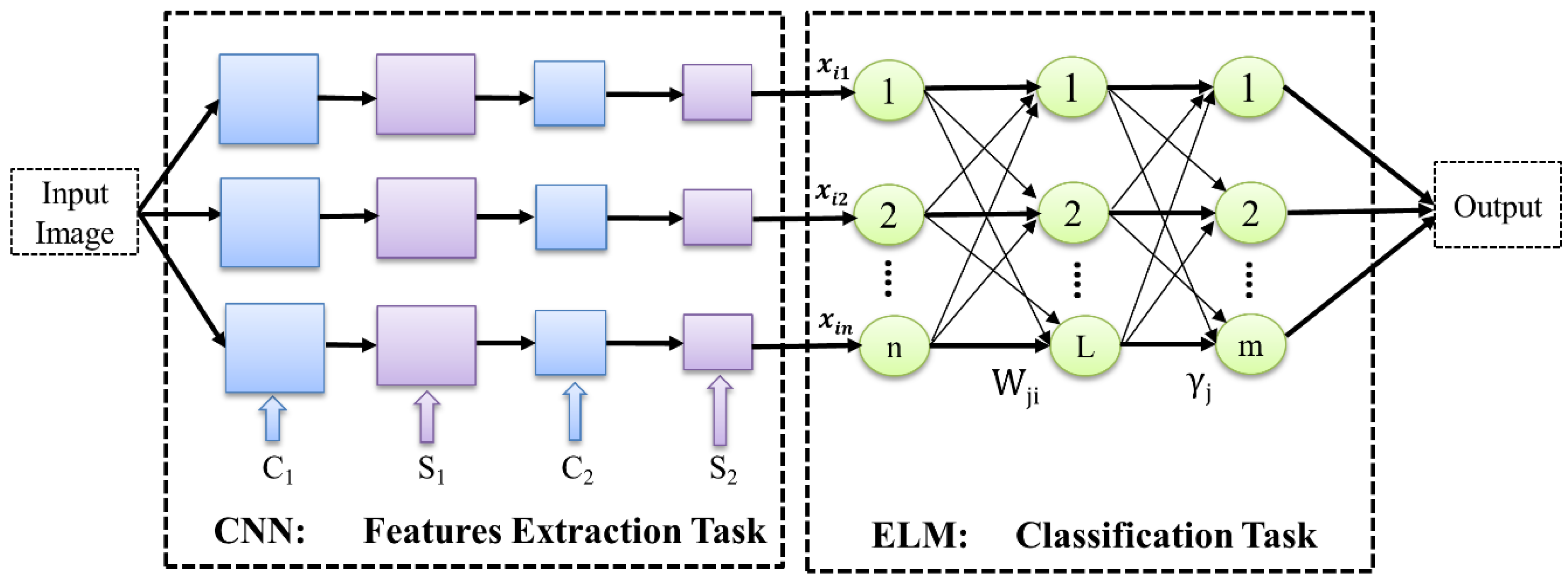
3.3. Combined and Improved CNN-ELM-DL4J Framework
4. Material and Methods
4.1. Used Datasets
4.2. Own Test Dataset and Preprocessing
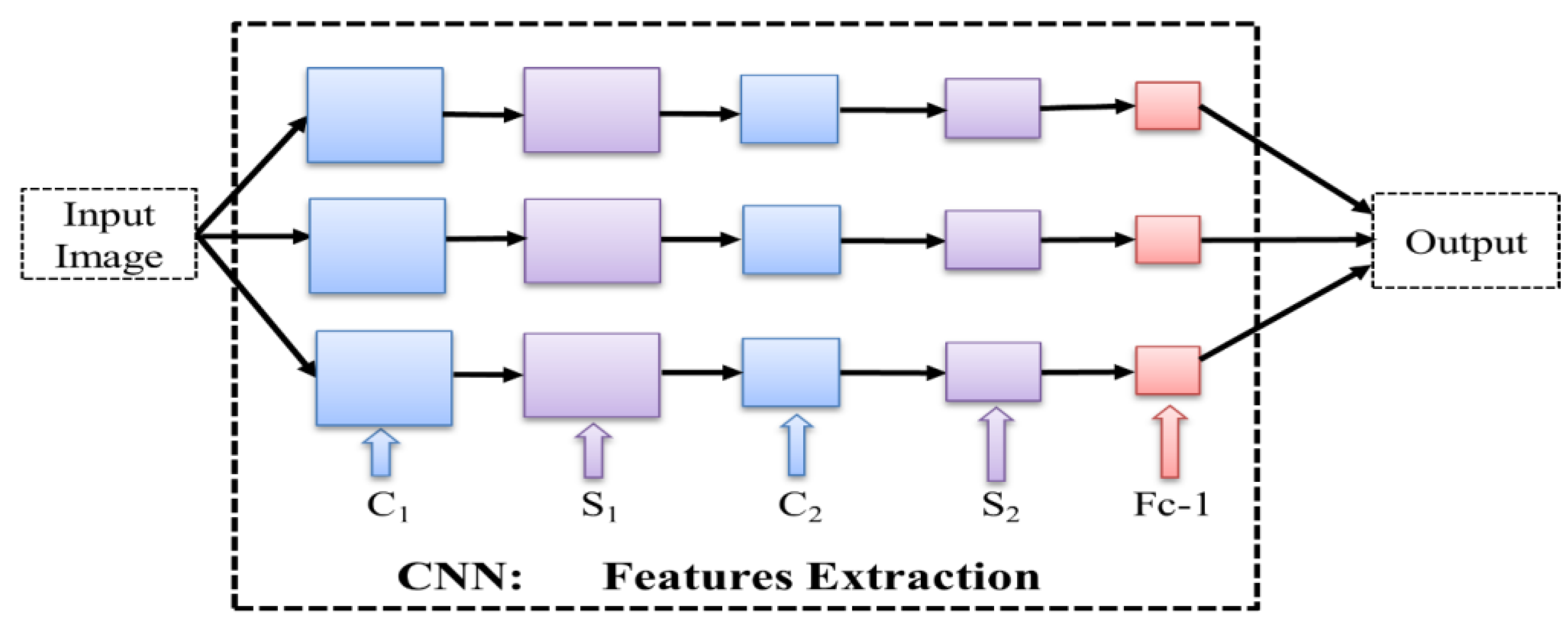
4.3. CNN-ELM-DL4J Model Details
4.4. The Training of CNN
- For n-th layer of the convolutional layer, m-th feature map derived by the following equation,where belongs to the input set, belongs to the nonlinear activation function, is the convolutional filter, and is the bias.
- Similarly, for n-th number of subsampling layers, its m-th feature map is obtained bywhere belongs to weights, is a pooling function, and is the bias.
5. Results and Discussion
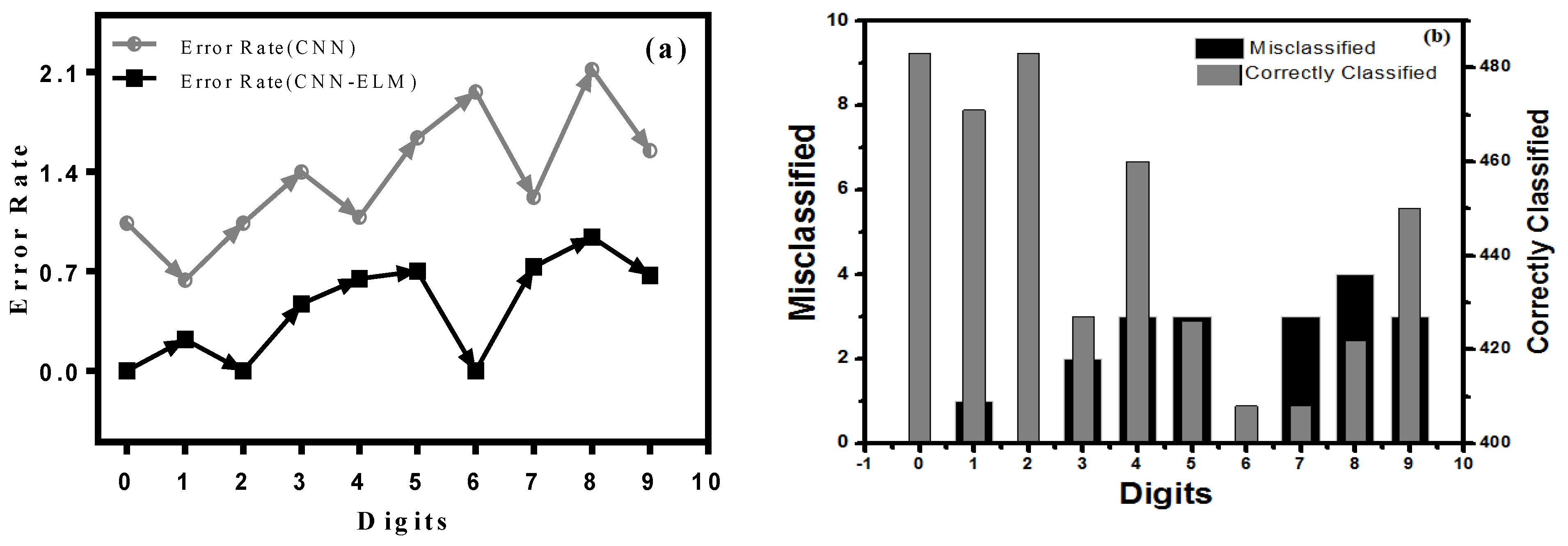
5.1. Digits vs. Error Rate
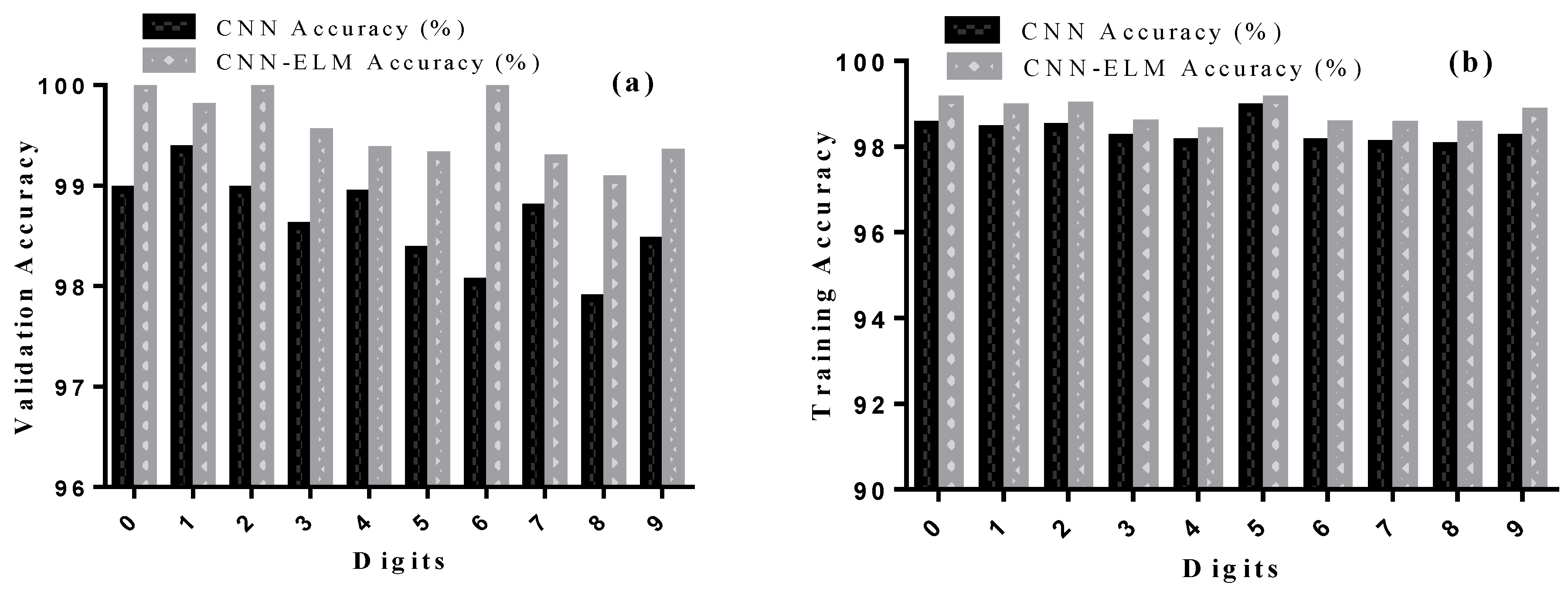
5.2. Training and Validation Accuracy
5.3. Analysis through Confusion Matrix
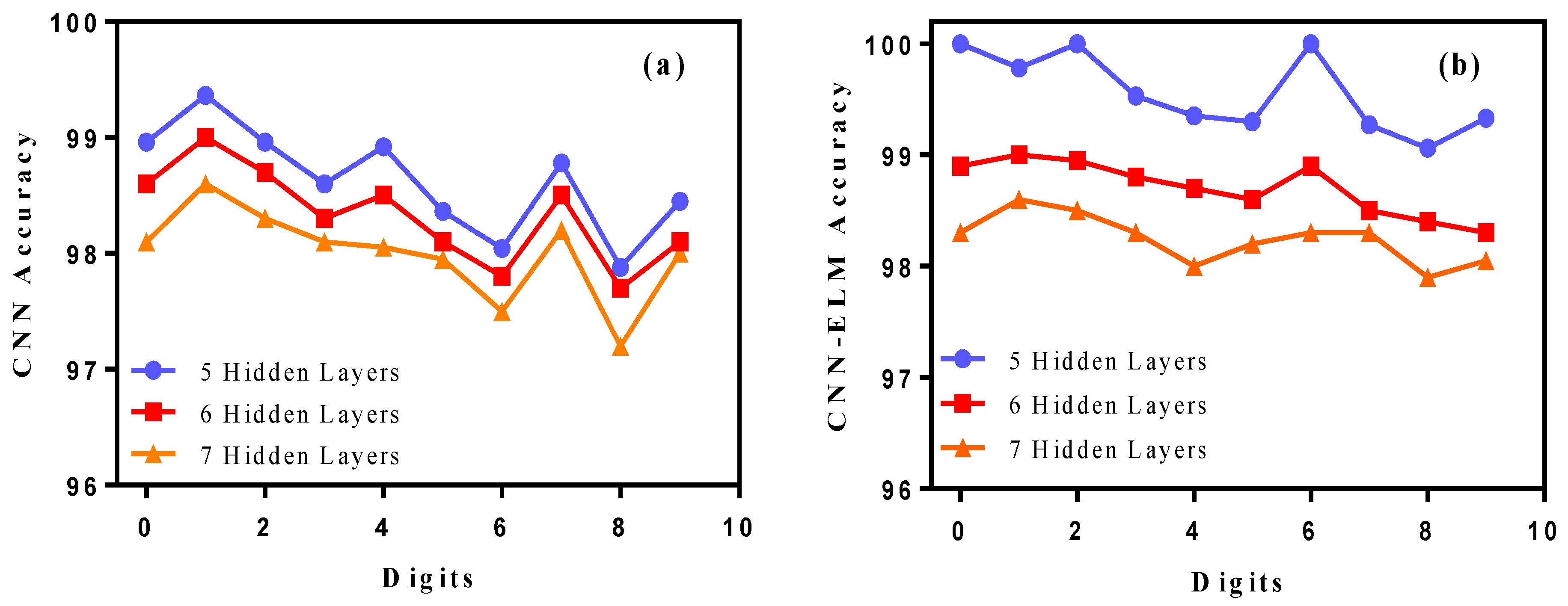
5.4. Comparison of Different Number of Hidden Layers
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Billah, M.; Ruman, M.K.; Sadat, N.; Islam, M.M. Bangladeshi Post Office Automation System Using Neural Network. In Proceedings of the 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’s Bazar, Bangladesh, 7–9 February 2019; pp. 1–4. [Google Scholar]
- Dansena, P.; Bag, S.; Pal, R. Differentiating pen inks in handwritten bank cheques using multi-layer perceptron. In Proceedings of the 2017 International Conference on Pattern Recognition and Machine Intelligence, Kolkata, India, 5–8 December 2017; pp. 655–663. [Google Scholar]
- Selmi, Z.; Halima, M.B.; Alimi, A.M. Deep learning system for automatic license plate detection and recognition. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 1132–1138. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar]
- Xiao, J.; Zhu, X.; Huang, C.; Yang, X.; Wen, F.; Zhong, M. A new approach for stock price analysis and prediction based on SSA and SVM. Int. J. Inf. Technol. Decis. Mak. 2019, 18, 287–310. [Google Scholar] [CrossRef]
- Wang, D.; Huang, L.; Tang, L. Dissipativity and synchronization of generalized BAM neural networks with multivariate discontinuous activations. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 3815–3827. [Google Scholar] [PubMed]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Kuang, F.; Zhang, S.; Jin, Z.; Xu, W. A novel SVM by combining kernel principal component analysis and improved chaotic particle swarm optimization for intrusion detection. Soft Comput. 2015, 19, 1187–1199. [Google Scholar] [CrossRef]
- Li, Y.-H.; Aslam, M.S.; Yang, K.-L.; Kao, C.-A.; Teng, S.-Y. Classification of Body Constitution Based on TCM Philosophy and Deep Learning. Symmetry 2020, 12, 803. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Boukharouba, A.; Bennia, A. Novel feature extraction technique for the recognition of handwritten digits. Appl. Comput. Inform. 2017, 13, 19–26. [Google Scholar] [CrossRef] [Green Version]
- Mohebi, E.; Bagirov, A. A convolutional recursive modified Self Organizing Map for handwritten digits recognition. Neural Netw. 2014, 60, 104–118. [Google Scholar] [CrossRef]
- Alwzwazy, H.A.; Albehadili, H.M.; Alwan, Y.S.; Islam, N.E. Handwritten digit recognition using convolutional neural networks. Int. J. Innov. Res. Comput. Commun. Eng. 2016, 4, 1101–1106. [Google Scholar]
- Jain, A.; Subrahmanyam, G.R.S.; Mishra, D. Rotation invariant digit recognition using convolutional neural network. In Proceedings of the 2018 2nd International Conference on Computer Vision & Image Processing, Chengdu, China, 16–18 June 2018; pp. 91–102. [Google Scholar]
- Akhtar, M.S.; Qureshi, H.A.; Alquhayz, H. High-quality wavelets features extraction for handwritten arabic numerals recognition. Int. J. Adv. Sci. Eng. Inf. Technol. 2019, 9, 700–710. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Convolutional deep belief networks on cifar-10. Unpublished Work. 2010, 40, 1–9. [Google Scholar]
- Arora, S.; Bhatia, M.S. Handwriting recognition using Deep Learning in Keras. In Proceedings of the 2018 International Conference on Advances in Computing, Communication Control and Networking (ICACCCN), Greater Noida (UP), India, 12–13 October 2018; pp. 142–145. [Google Scholar]
- Malik, H.; Roy, N. Extreme Learning Machine-Based Image Classification Model Using Handwritten Digit Database. In Applications of Artificial Intelligence Techniques in Engineering; Springer: Berlin/Heidelberg, Germany, 2019; pp. 607–618. [Google Scholar]
- Ali, I.; Ali, I.; Subhash, A.K.; Raza, S.A.; Hassan, B.; Bhatti, P. Sindhi Handwritten-Digits Recognition Using Machine Learning Techniques. Int. J. Comput. Sci. Netw. Secur. 2019, 19, 195–202. [Google Scholar]
- Bishnoi, D.K.; Lakhwani, K. Advanced approaches of handwritten digit recognition using hybrid algorithm. Int. J. Commun. Comput. Technol. 2012, 1, 45–50. [Google Scholar]
- Cruz, R.M.; Cavalcanti, G.D.; Ren, T.I. Handwritten digit recognition using multiple feature extraction techniques and classifier ensemble. In Proceedings of the 2010 17th International Conference on Systems, Signals and Image Processing, Rio de Janeiro, Brazil, 17–19 June 2010; pp. 215–218. [Google Scholar]
- Kochura, Y.; Stirenko, S.; Alienin, O.; Novotarskiy, M.; Gordienko, Y. Comparative analysis of open source frameworks for machine learning with use case in single-threaded and multi-threaded modes. In Proceedings of the 2017 12th International Scientific and Technical Conference on Computer Sciences and Information Technologies (CSIT), Lviv, Ukraine, 5–8 September 2017; pp. 373–376. [Google Scholar]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No. 04CH37541), Budapest, Hungary, 25–29 July 2004; pp. 985–990. [Google Scholar]
- Tan, H.H.; Lim, K.H.; Harno, H.G. Stochastic diagonal approximate greatest descent in neural networks. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1895–1898. [Google Scholar]
- Hamid, N.A.; Sjarif, N.N.A. Handwritten recognition using SVM, KNN and neural network. arXiv 2017, arXiv:1702.00723. [Google Scholar]
- Xu, Q.; Pan, G. SparseConnect: Regularising CNNs on fully connected layers. Electron. Lett. 2017, 53, 1246–1248. [Google Scholar] [CrossRef]
- Ghosh, M.M.A.; Maghari, A.Y. A comparative study on handwriting digit recognition using neural networks. In Proceedings of the 2017 International Conference on Promising Electronic Technologies (ICPET), Deir El-Balah, Palestine, 16–17 October 2017; pp. 77–81. [Google Scholar]
- Polania, L.F.; Barner, K.E. Exploiting restricted Boltzmann machines and deep belief networks in compressed sensing. IEEE Trans. Signal Process. 2017, 65, 4538–4550. [Google Scholar] [CrossRef]
- Deng, L. A tutorial survey of architectures, algorithms, and applications for deep learning. APSIPA Trans. Signal Inf. Process. 2014, 3, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Teow, M.Y. Understanding convolutional neural networks using a minimal model for handwritten digit recognition. In Proceedings of the 2017 IEEE 2nd International Conference on Automatic Control and Intelligent Systems (I2CACIS), Kota Kinabalu, Malaysia, 21 October 2017; pp. 167–172. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Ercoli, S.; Bertini, M.; Del Bimbo, A. Compact hash codes for efficient visual descriptors retrieval in large scale databases. IEEE Trans. Multimed. 2017, 19, 2521–2532. [Google Scholar] [CrossRef] [Green Version]
- Abouelnaga, Y.; Ali, O.S.; Rady, H.; Moustafa, M. CIFAR-10: KNN-based Ensemble of Classifiers. In Proceedings of the 2016 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 15–17 December 2016; pp. 1192–1195. [Google Scholar]
- Wang, H.; Chen, P.; Kwong, S. Building correlations between filters in convolutional neural networks. IEEE Trans. Cybern. 2016, 47, 3218–3229. [Google Scholar] [CrossRef]
- Chherawala, Y.; Roy, P.P.; Cheriet, M. Feature set evaluation for offline handwriting recognition systems: Application to the recurrent neural network model. IEEE Trans. Cybern. 2015, 46, 2825–2836. [Google Scholar] [CrossRef] [PubMed]
- Katayama, N.; Yamane, S. Recognition of rotated images by angle estimation using feature map with CNN. In Proceedings of the 2017 IEEE 6th Global Conference on Consumer Electronics (GCCE), Nagoya, Japan, 9–12 October 2018; pp. 1–2. [Google Scholar]
- Pang, S.; Yang, X. Deep convolutional extreme learning machine and its application in handwritten digit classification. Comput. Intell. Neurosci. 2016, 2016, 1–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, C.; Kang, H.; Yao, T.; Li, X. An effective classifier based on convolutional neural network and regularized extreme learning machine. Math. Biosci. Eng. MBE 2019, 16, 8309–8321. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Li, S.; Liang, T.; Sun, T. Sample selection-based hierarchical extreme learning machine. Neurocomputing 2020, 377, 95–102. [Google Scholar] [CrossRef]
- Das, D.; Nayak, D.R.; Dash, R.; Majhi, B. An empirical evaluation of extreme learning machine: Application to handwritten character recognition. Multimed. Tools Appl. 2019, 78, 19495–19523. [Google Scholar] [CrossRef]
- Ding, S.; Guo, L.; Hou, Y. Extreme learning machine with kernel model based on deep learning. Neural Comput. Appl. 2017, 28, 1975–1984. [Google Scholar] [CrossRef]
- Sukittanon, S.; Surendran, A.C.; Platt, J.C.; Burges, C.J. Convolutional networks for speech detection. In Proceedings of the 2004 Eighth International Conference on Spoken Language Processing, Jeju Island, Korea, 4–8 October 2004; pp. 1077–1080. [Google Scholar]
- Lauer, F.; Suen, C.Y.; Bloch, G. A trainable feature extractor for handwritten digit recognition. Pattern Recognit. 2007, 40, 1816–1824. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Zhang, X.; Hao, Y. A Method Combining CNN and ELM for Feature Extraction and Classification of SAR Image. J. Sens. 2019, 2019, 1–9. [Google Scholar] [CrossRef]
- Niu, X.-X.; Suen, C.Y. A novel hybrid CNN-SVM classifier for recognizing handwritten digits. Pattern Recognit. 2012, 45, 1318–1325. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 2012 Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Maji, S.; Malik, J. Fast and Accurate Digit Classification; Technical Report No. UCB/EECS-2009-159; Electrical Engineering and Computer Sciences Department, University of California at Berkeley: Berkeley, CA, USA, 2009; pp. 1–11. Available online: http://www2.eecs.berkeley.edu/Pubs/TechRpts/2009/EECS-2009-159.pdf (accessed on 20 October 2020).
- Kusetogullari, H.; Yavariabdi, A.; Cheddad, A.; Grahn, H.; Hall, J. ARDIS: A Swedish historical handwritten digit dataset. Neural Comput. Appl. 2019, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Ali, S.; Shaukat, Z.; Azeem, M.; Sakhawat, Z.; Mahmood, T.; ur Rehman, K. An efficient and improved scheme for handwritten digit recognition based on convolutional neural network. SN Appl. Sci. 2019, 1, 1125. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Gan, Y.; Vong, C.-M.; Chen, C. Homo-ELM: Fully homomorphic extreme learning machine. Int. J. Mach. Learn. Cybern. 2020, 11, 1–10. [Google Scholar] [CrossRef]
- Zhao, H.-h.; Liu, H. Multiple classifiers fusion and CNN feature extraction for handwritten digits recognition. Granul. Comput. 2020, 5, 411–418. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factors | Shallow Neural Network (SNN) | Deep Neural Network (DNN) |
|---|---|---|
| Feature Engineering | 1. Individual feature extraction process is required. Various features cited in the literature are histogram oriented gradients, speeded up robust features, and local binary patterns. | 1. Replace the hand-crafted features and directly work on the entire input. Thus, more practical for complex datasets. |
| Data Size Dependency | 2. Needs a lesser quantity of data. | 2. Needs vast volumes of data. |
| Size of hidden layers | 3. Single hidden layer is required to fully connect the network. | 3. Multiple hidden layers which may be fully connected. |
| Requirements | 4. Give more importance to the quality of features and their extraction process. | 4. Automatically detects the significant features of an object, e.g., an image, handwritten character or a face. |
| 5. More dependent on human expertise. | 5. Less human involvement. |
| Layers | Parameters (CNN) | Parameters (CNN) |
|---|---|---|
| Input | 28 28 1 | 28281 |
| CONV_1 | Filters: 3318 | Filters: 3318 |
| Activation: ReLU | Activation: ReLU | |
| Stride: 2 | Stride: 2 | |
| POOL_1 | Process: Downsampling | Process: Downsampling |
| Size: 22 | Size: 22 | |
| Stride: 2 | Stride: 2 | |
| CONV_2 | Filters: 33816 | Filters: 33816 |
| Activation: ReLU | Activation: ReLU | |
| Stride: 2 | Stride: 2 | |
| POOL_2 | Process: Downsampling | Process: Downsampling |
| Size: 22 | Size: 22 | |
| Stride: 2 | Stride: 2 | |
| CONV_3 | Filters: 331632 | Filters: 331632 |
| Activation: ReLU | Activation: ReLU | |
| Stride: 1 | Stride: 1 | |
| FC-1 | Filters: 1 166 | Filters: 1 166 |
| Stride: 1 | Stride: 1 | |
| Softmax ELM | Classification Process | ‒ |
| ‒ | Classification Process | |
| Output | Predicted Class | Predicted Class |
| Numerals | Predicted Class | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | Accuracy (%) | ||
| Actual Class | 0 | 483 | 100 | |||||||||
| 1 | 472 | 1 | 99.78 | |||||||||
| 2 | 483 | 100 | ||||||||||
| 3 | 1 | 429 | 1 | 99.53 | ||||||||
| 4 | 463 | 3 | 99.35 | |||||||||
| 5 | 1 | 429 | 2 | 99.30 | ||||||||
| 6 | 410 | 100 | ||||||||||
| 7 | 1 | 411 | 2 | 99.27 | ||||||||
| 8 | 3 | 1 | 426 | 99.06 | ||||||||
| 9 | 2 | 1 | 453 | 99.33 | ||||||||
| Ref. | Approach | Database | Size of Sample | Testing Time (s) | Classification Accuracy (%) |
|---|---|---|---|---|---|
| [18] | ELM | MNIST | Small | ‒ | 98.4 |
| [39] | H-ELM FCM-CNN-H-ELM | MNIST | ‒ | 20.43 16.79 | 99.1 98.7 |
| [40] | ELM | MNIST | Large | ‒ | 97.7 |
| [41] | CKELM | MNIST | Small | ‒ | 96.8 |
| [44] | CNN-ELM | MSTAR | Small | ‒ | 100 |
| [49] | CNN | MNIST | Large | 58 | 99.2 |
| [50] | Homo-ELM | MNIST NIST19 | Small | ‒ | 97.0 98.3 |
| [51] | Multiple fusion CNN | MNIST | ‒ | ‒ | 98.0 |
| This Work | CNN-ELM-DL4J | USPS | Large | 26.52 | 99.7 |
| This Work | CNN-ELM-DL4J | MNIST | Large | 24.23 | 99.8 |
| This Work | CNN-ELM-DL4J | Self-build | Small | 11.27 | 99.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, S.; Li, J.; Pei, Y.; Aslam, M.S.; Shaukat, Z.; Azeem, M. An Effective and Improved CNN-ELM Classifier for Handwritten Digits Recognition and Classification. Symmetry 2020, 12, 1742. https://doi.org/10.3390/sym12101742
Ali S, Li J, Pei Y, Aslam MS, Shaukat Z, Azeem M. An Effective and Improved CNN-ELM Classifier for Handwritten Digits Recognition and Classification. Symmetry. 2020; 12(10):1742. https://doi.org/10.3390/sym12101742
Chicago/Turabian StyleAli, Saqib, Jianqiang Li, Yan Pei, Muhammad Saqlain Aslam, Zeeshan Shaukat, and Muhammad Azeem. 2020. "An Effective and Improved CNN-ELM Classifier for Handwritten Digits Recognition and Classification" Symmetry 12, no. 10: 1742. https://doi.org/10.3390/sym12101742
APA StyleAli, S., Li, J., Pei, Y., Aslam, M. S., Shaukat, Z., & Azeem, M. (2020). An Effective and Improved CNN-ELM Classifier for Handwritten Digits Recognition and Classification. Symmetry, 12(10), 1742. https://doi.org/10.3390/sym12101742