DSM: Delayed Signature Matching in Deep Packet Inspection



Abstract
:1. Introduction
2. Related Work
2.1. DPI in General
2.2. DPI with Multiple Stages
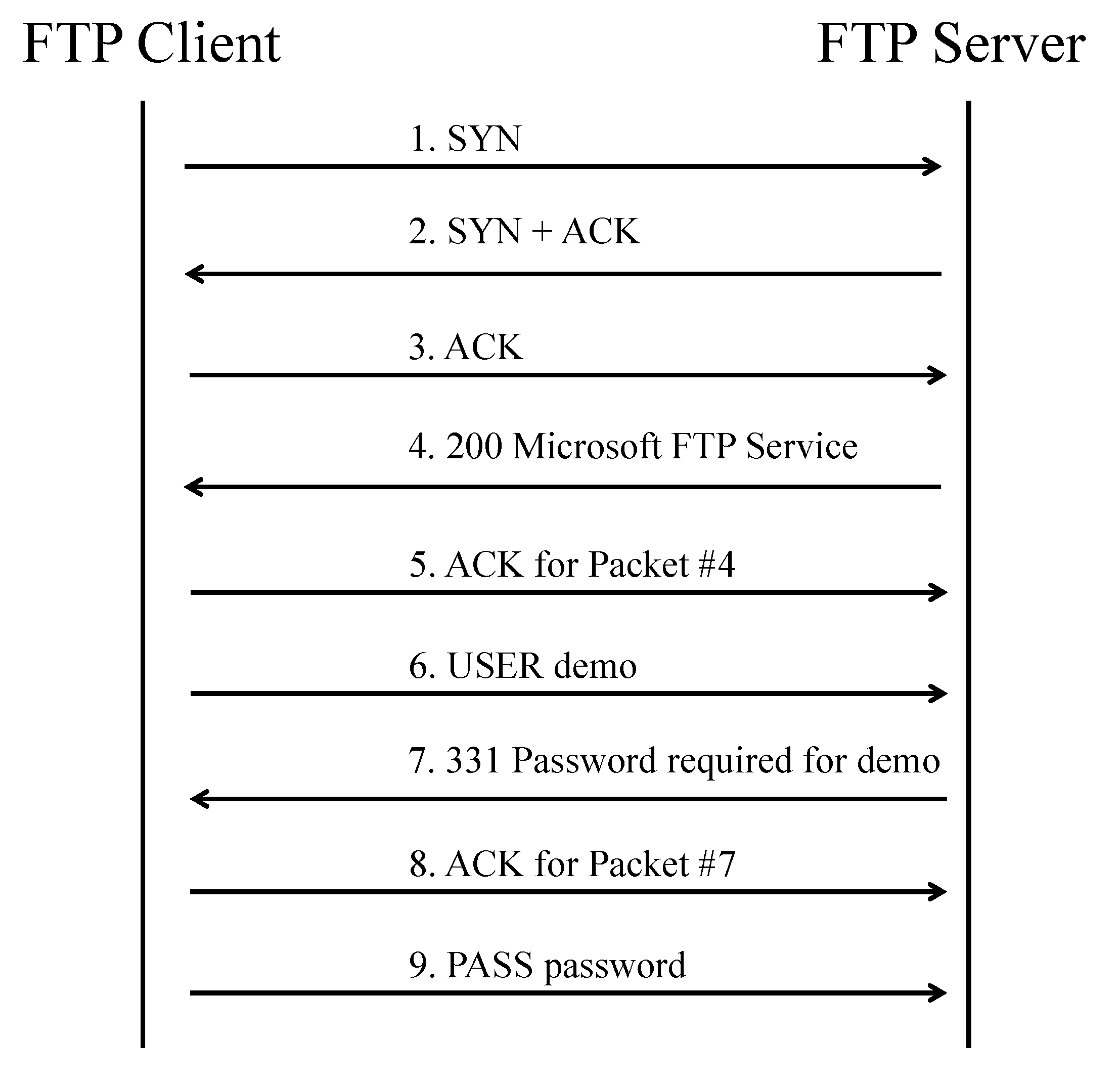
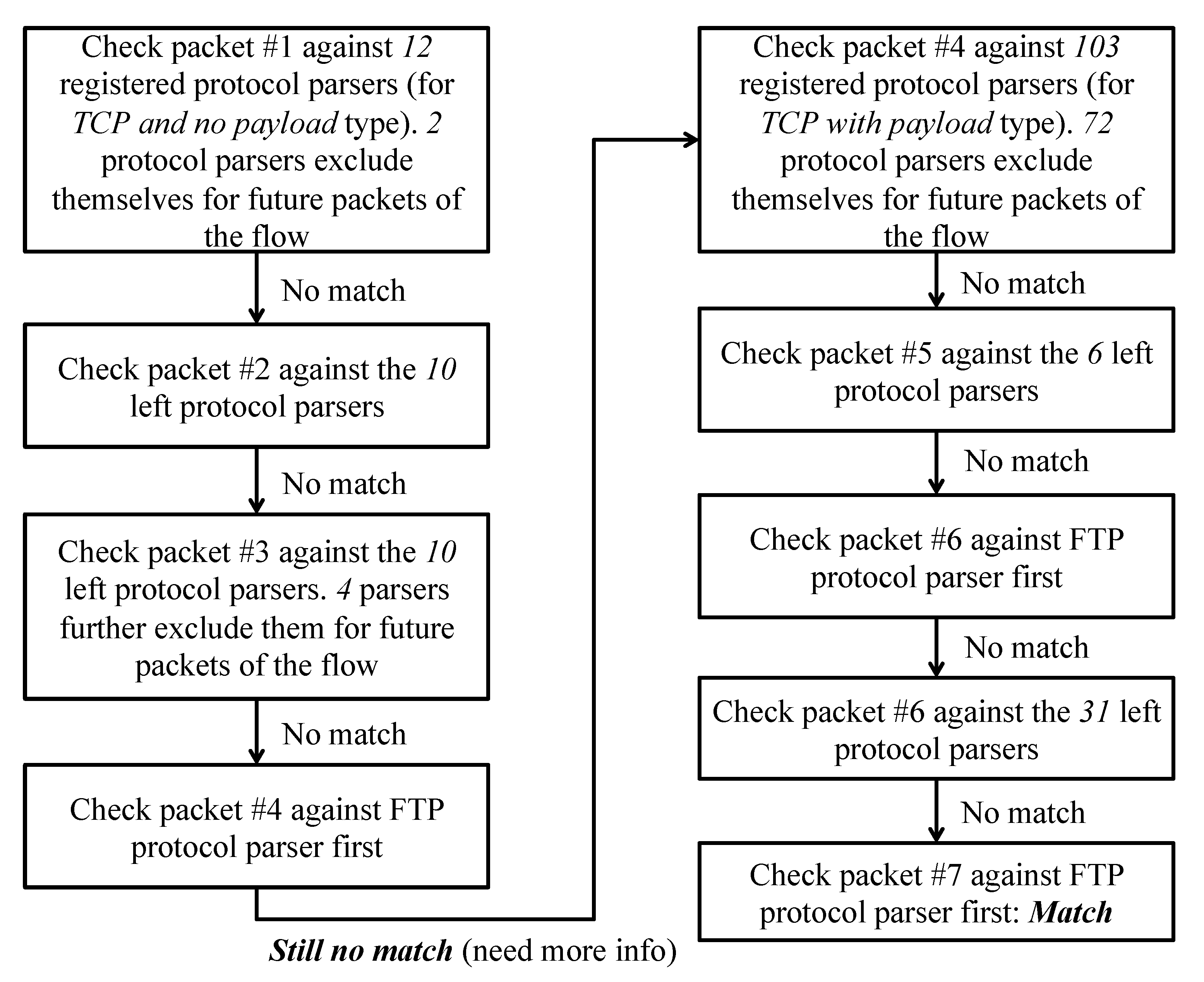
3. Motivating Example
4. Delayed Signature Matching (DSM)
4.1. DSM Processing Algorithm
| Algorithm 1 The DSM Processing |
| Input: a packet, the packet’s flow information , all DSM rules . |
|
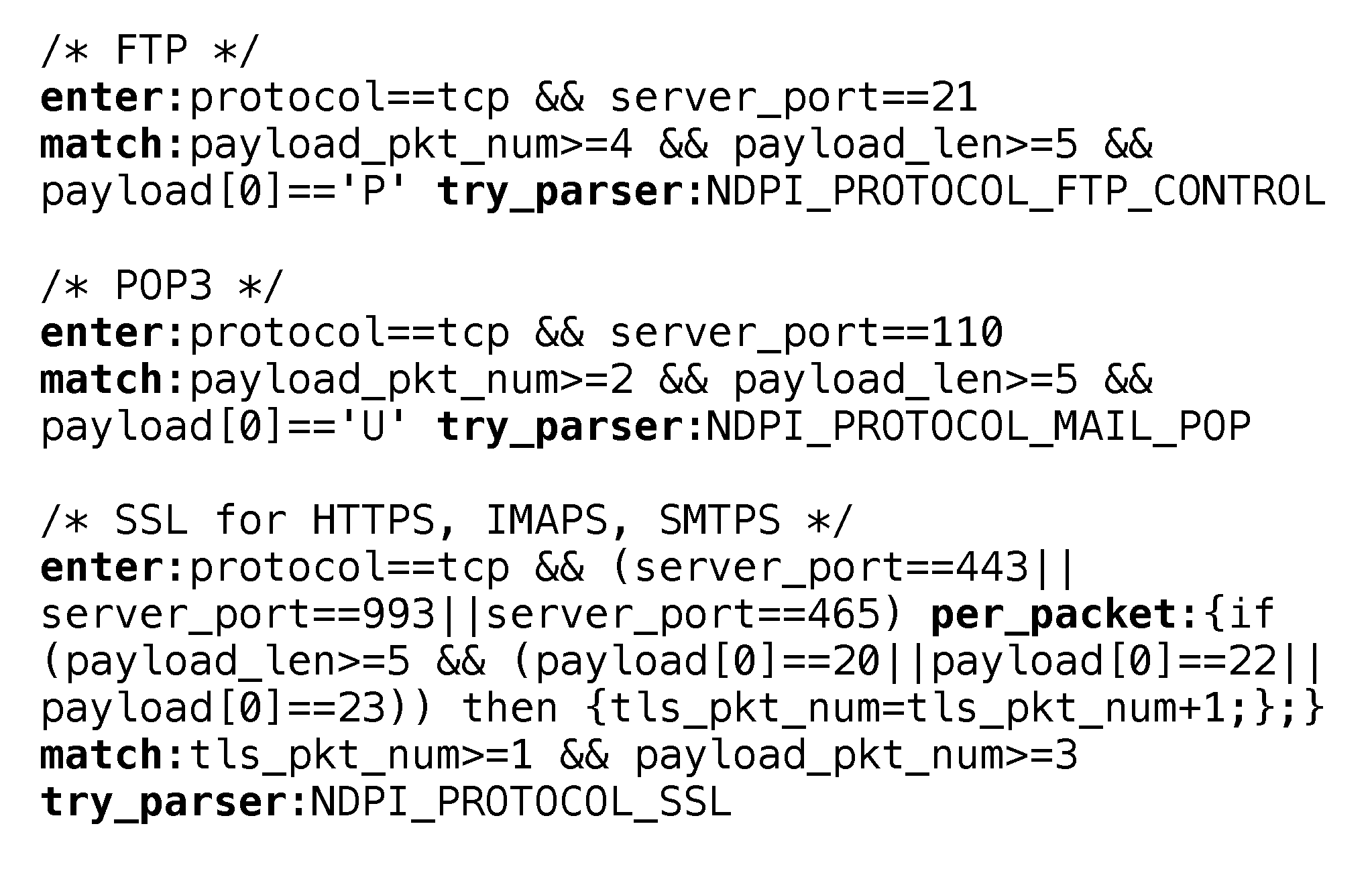
4.2. DSM Rule Creation
- protocol, the protocol of the packet. For example, it could be used to check whether protocol==tcp.
- server_port, the TCP or UDP port of the server side (the side that accepts the connection).
- pkt_num, stands for the number of total packets that have been received in the flow.
- payload_pkt_num represents the number of packets that have payload have been received in the flow.
- payload represents the (application layer) payload of the packet. With the operator “[]”, byte at any index could be accessed.
- payload_len represents the length of payload.
4.3. DSM Rule Evaluation
4.4. Discussion
5. Analysis
5.1. The Correctness of the DSM Method
5.2. Performance Analysis
6. Evaluation
6.1. Implementation of DSM
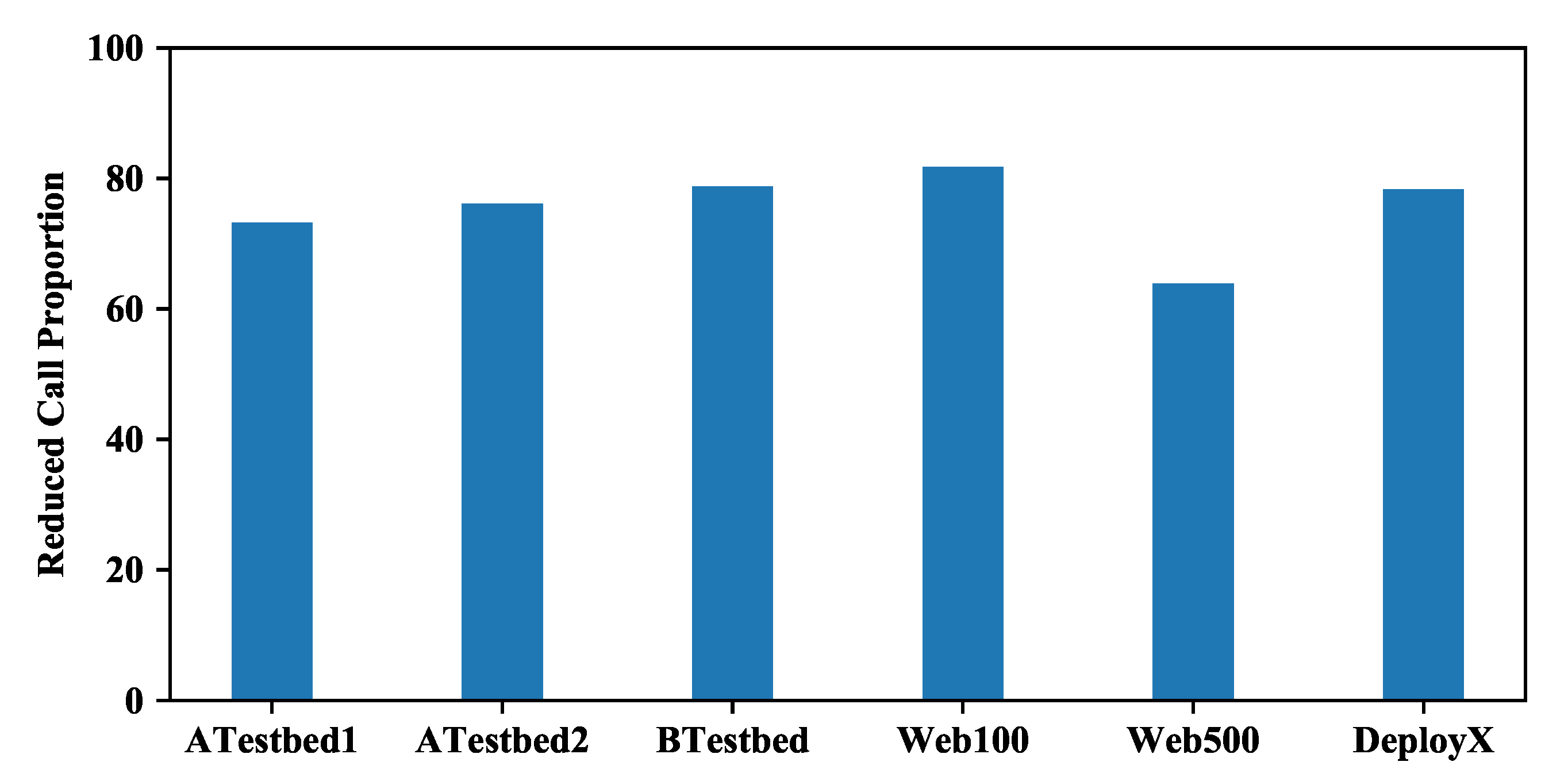
6.2. Experiment Results
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Porter, T. The Perils of Deep Packet Inspection. Available online: https://www.symantec.com/connect/articles/perils-deep-packet-inspection (accessed on 23 September 2020).
- Dainotti, A.; Pescape, A.; Claffy, K.C. Issues and future directions in traffic classification. IEEE Netw. 2012, 26, 35–40. [Google Scholar] [CrossRef] [Green Version]
- Bujlow, T.; Carela-Español, V.; Barlet-Ros, P. Independent comparison of popular DPI tools for traffic classification. Comput. Netw. 2015, 76, 75–89. [Google Scholar] [CrossRef] [Green Version]
- Cisco. Network Based Application Recognition (NBAR). Available online: https://www.cisco.com/c/en/us/products/ios-nx-os-software/network-based-application-recognition-nbar/index.html (accessed on 23 September 2020).
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapé, A. Mobile Encrypted Traffic Classification Using Deep Learning: Experimental Evaluation, Lessons Learned, and Challenges. IEEE Trans. Netw. Serv. Manag. 2019, 16, 445–458. [Google Scholar] [CrossRef]
- Zeng, Y.; Guo, S. Deep Packet Inspection with Delayed Signature Matching in Network Auditing. In Proceedings of the International Conference on Information and Communications Security (ICICS), Lille, France, 29–31 October 2018; pp. 75–91. [Google Scholar]
- Paxson, V. Bro: A system for detecting network intruders in real-time. In Proceedings of the 7th Conf. USENIX Security Symp., San Antonio, TX, USA, 26–29 January 1998. [Google Scholar]
- Cisco. Snort—Network Intrusion Detection & Prevention System. Available online: https://www.snort.org/ (accessed on 23 September 2020).
- Qosmos. Qosmos DPI Engine. Available online: https://www.qosmos.com/products/deep-packet-inspection-engine/ (accessed on 23 September 2020).
- Ipoque GmbH. DPI Engine—R&S PACE 2. Available online: https://ipoque.com/products/dpi-engine-rsrpace-2 (accessed on 23 September 2020).
- Deri, L.; Martinelli, M.; Bujlow, T.; Cardigliano, A. nDPI: Open-source high-speed deep packet inspection. In Proceedings of the 10th Int. Wireless Commun. and Mobile Comput. Conf. (IWCMC), Nicosia, Cyprus, 4–8 August 2014; pp. 617–622. [Google Scholar]
- Finsterbusch, M.; Richter, C.; Rocha, E.; Muller, J.; Hanssgen, K. A Survey of Payload-Based Traffic Classification Approaches. IEEE Commun. Surv. Tuts. 2014, 16, 1135–1156. [Google Scholar] [CrossRef]
- Kumar, S.; Dharmapurikar, S.; Yu, F.; Crowley, P.; Turner, J. Algorithms to Accelerate Multiple Regular Expressions Matching for Deep Packet Inspection. In Proceedings of the ACM SIGCOMM, Pisa, Italy, 11–15 September 2006; pp. 339–350. [Google Scholar]
- Bremler-Barr, A.; David, S.T.; Harchol, Y.; Hay, D. Leveraging traffic repetitions for high-speed deep packet inspection. In Proceedings of the IEEE INFOCOM, Kowloon, Hong Kong, 26 April–1 May 2015; pp. 2578–2586. [Google Scholar]
- Intel. Hyperscan. Available online: https://www.hyperscan.io/ (accessed on 23 September 2020).
- Wang, X.; Hong, Y.; Chang, H.; Park, K.; Langdale, G.; Hu, J.; Zhu, H. Hyperscan: A Fast Multi-pattern Regex Matcher for Modern CPUs. In Proceedings of the 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI), Boston, MA, USA, 26–28 February 2019; pp. 631–648. [Google Scholar]
- Doroud, H.; Aceto, G.; de Donato, W.; Jarchlo, E.A.; Lopez, A.M.; Guerrero, C.D.; Pescape, A. Speeding-Up DPI Traffic Classification with Chaining. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, UAE, 9–13 December 2018; pp. 1–6. [Google Scholar]
- ntop. nDPI—Open Source Deep Packet Inspection Software Toolkit. Available online: https://github.com/ntop/nDPI (accessed on 23 September 2020).
- Callado, A.; Kamienski, C.; Szabo, G.; Gero, B.P.; Kelner, J.; Fernandes, S.; Sadok, D. A Survey on Internet Traffic Identification. IEEE Commun. Surv. Tuts. 2009, 11, 37–52. [Google Scholar] [CrossRef]
- Nguyen, T.T.T.; Armitage, G. A survey of techniques for internet traffic classification using machine learning. IEEE Commun. Surv. Tuts. 2008, 10, 56–76. [Google Scholar] [CrossRef]
- Karagiannis, T.; Papagiannaki, K.; Faloutsos, M. BLINC: Multilevel Traffic Classification in the Dark. In Proceedings of the ACM SIGCOMM, Portland, OR, USA, August–3 September 2005; pp. 229–240. [Google Scholar]
- Zhang, J.; Chen, X.; Xiang, Y.; Zhou, W.; Wu, J. Robust Network Traffic Classification. IEEE/ACM Trans. Netw. 2015, 23, 1257–1270. [Google Scholar] [CrossRef]
- Taylor, V.F.; Spolaor, R.; Conti, M.; Martinovic, I. Robust Smartphone App Identification via Encrypted Network Traffic Analysis. IEEE Trans. Inf. Forensics Secur. 2018, 13, 63–78. [Google Scholar] [CrossRef] [Green Version]
- Cao, J.; Wang, D.; Qu, Z.; Sun, H.; Li, B.; Chen, C.L. An improved network traffic classification model based on a support vector machine. Symmetry 2020, 12, 301. [Google Scholar] [CrossRef] [Green Version]
- Moore, A.W.; Papagiannaki, K. Toward the Accurate Identification of Network Applications. In Proceedings of the Passive and Active Network Measure (PAM), Boston, MA, USA, 31 March–1 April 2005; pp. 41–54. [Google Scholar]
- Sommer, E.; Strait, M. L7-Filter. Available online: http://l7-filter.sourceforge.net (accessed on 23 September 2020).
- Sommer, R.; Amann, J.; Hall, S. Spicy: A unified deep packet inspection framework for safely dissecting all your data. In Proceedings of the Annual Computer Security Applications Conference (ACSAC), Los Angeles, CA, USA, 5–9 December 2016; pp. 558–569. [Google Scholar] [CrossRef]
- Dyer, K.P.; Coull, S.E.; Ristenpart, T.; Shrimpton, T. Protocol misidentification made easy with format-transforming encryption. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security (CCS), Berlin, Germany, 4–8 November 2013; pp. 61–72. [Google Scholar]
- Backurs, A.; Indyk, P. Which Regular Expression Patterns Are Hard to Match? In Proceedings of the IEEE 57th Annual Symposium on Foundations of Computer Science (FOCS), New Brunswick, NJ, USA, 9–11 October 2016; pp. 457–466. [Google Scholar]
- Dharmapurikar, S.; Krishnamurthy, P.; Sproull, T.S.; Lockwood, J.W. Deep packet inspection using parallel bloom filters. IEEE Micro 2004, 24, 52–61. [Google Scholar] [CrossRef]
- Antonello, R.; Fernandes, S.F.L.; Sadok, D.F.H.; Kelner, J.; Szabó, G. Design and optimizations for efficient regular expression matching in DPI systems. Comput. Commun. 2015, 61, 103–120. [Google Scholar] [CrossRef]
- Durumeric, Z.; Ma, Z.; Springall, D.; Barnes, R.; Sullivan, N.; Bursztein, E.; Bailey, M.; Halderman, J.A.; Paxson, V. The Security Impact of HTTPS Interception. In Proceedings of the 24th Annual Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 26 February–1 March 2017. [Google Scholar]
- Sherry, J.; Lan, C.; Popa, R.A.; Ratnasamy, S. BlindBox: Deep Packet Inspection over Encrypted Traffic. In Proceedings of the ACM SIGCOMM, London, UK, 17–21 August 2015; pp. 213–226. [Google Scholar]
- Yuan, X.; Wang, X.; Lin, J.; Wang, C. Privacy-preserving deep packet inspection in outsourced middleboxes. In Proceedings of the IEEE INFOCOM, San Francisco, CA, USA, 10–14 April 2016; pp. 1–9. [Google Scholar]
- Poddar, R.; Lan, C.; Popa, R.A.; Ratnasamy, S. SafeBricks: Shielding Network Functions in the Cloud. In Proceedings of the 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI), Renton, WA, USA, 9–11 April 2018; pp. 201–216. [Google Scholar]
- De La Torre Parra, G.; Rad, P.; Choo, K.K.R. Implementation of deep packet inspection in smart grids and industrial Internet of Things: Challenges and opportunities. J. Netw. Comput. Appl. 2019, 135, 32–46. [Google Scholar] [CrossRef]
- Wang, Z.; Zhu, S.; Cao, Y.; Qian, Z.; Song, C.; Krishnamurthy, S.V.; Chan, K.S.; Braun, T.D. SymTCP: Eluding Stateful Deep Packet Inspection with Automated Discrepancy Discovery. In Proceedings of the 27th Annual Network & Distributed System Security Symposium (NDSS), San Diego, CA, USA, 23–26 February 2020. [Google Scholar] [CrossRef]
- Keralapura, R.; Nucci, A.; Chuah, C. Self-Learning Peer-to-Peer Traffic Classifier. In Proceedings of the 18th International Conference on Distributed and Computer and Communication Networks (ICCCN), Francisco, CA, USA, 3–6 August 2009; pp. 1–8. [Google Scholar]
- Bober, A.; Konieczny, J. Introduction to Layer 7-Filter. Available online: https://mum.mikrotik.com//presentations/PL10/l7_interprojekt.pdf (accessed on 23 September 2020).
- Myers, J.G.; Rose, M.T. Post Office Protocol—Version 3. RFC 1939. 1996. Available online: https://tools.ietf.org/html/rfc1939 (accessed on 4 December 2020).
- Dierks, T.; Rescorla, E. The Transport Layer Security (TLS) Protocol Version 1.2. RFC 5246. 2008. Available online: https://tools.ietf.org/html/rfc5246 (accessed on 4 December 2020).
- Eastlake, D., 3rd. Transport Layer Security (TLS) Extensions: Extension Definitions. RFC 6066. 2011. Available online: https://tools.ietf.org/html/rfc6066 (accessed on 4 December 2020).
- Levine, J.R. Flex and Bison—Unix Text Processing Tools; O’Reilly: Springfield, MO, USA, 2009. [Google Scholar]
- Wang, L.; Dyer, K.P.; Akella, A.; Ristenpart, T.; Shrimpton, T. Seeing through Network-Protocol Obfuscation. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security (CCS), Denver, CO, USA, 12–16 October 2015; pp. 57–69. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Size (MB) | Time (Hour) | Num. of Flows | Num. of Pkts | Traffic Desc. |
|---|---|---|---|---|---|
| ATestbed1 | 79.6 | 23.9 | 30,735 | 422,966 | upstream |
| ATestbed2 | 304.6 | 103.4 | 110,174 | 1,599,281 | upstream |
| BTestbed | 326.4 | 93.2 | 24,970 | 1,383,572 | upstream |
| Web100 | 135.2 | 0.6 | 3701 | 222,924 | both |
| Web500 | 685.3 | 3.1 | 37,473 | 1,035,565 | both |
| Deployx | 518.6 | 11.9 | 143,314 | 3,000,000 | upstream |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, Y.; Guo, S.; Wu, T.; Zheng, Q. DSM: Delayed Signature Matching in Deep Packet Inspection. Symmetry 2020, 12, 2011. https://doi.org/10.3390/sym12122011
Zeng Y, Guo S, Wu T, Zheng Q. DSM: Delayed Signature Matching in Deep Packet Inspection. Symmetry. 2020; 12(12):2011. https://doi.org/10.3390/sym12122011
Chicago/Turabian StyleZeng, Yingpei, Shanqing Guo, Ting Wu, and Qiuhua Zheng. 2020. "DSM: Delayed Signature Matching in Deep Packet Inspection" Symmetry 12, no. 12: 2011. https://doi.org/10.3390/sym12122011
APA StyleZeng, Y., Guo, S., Wu, T., & Zheng, Q. (2020). DSM: Delayed Signature Matching in Deep Packet Inspection. Symmetry, 12(12), 2011. https://doi.org/10.3390/sym12122011