An Improved Network Traffic Classification Model Based on a Support Vector Machine



Abstract
:
1. Introduction
- (1)
- In the process of feature reduction, in order to select the optimal feature subset which can represent the distribution of original traffic data, a Filter-Wrapper hybrid feature selection model is proposed.
- (2)
- In order to balance the empirical risk and generalization ability of support vector machine (SVM) traffic classification model, improve its classification and generalization ability, and improved the grid search parameter optimization algorithm is proposed. The algorithm can dynamically adjust the second search area, reduce the density of grid generation, improve the search efficiency of the algorithm, and prevent the over-fitting while optimizing the parameters.
- (3)
- We compare the proposed model with the traditional SVM, and the representative supervised machine learning algorithm. It shows that traffic classification performance can be significantly improved by the proposed model by using very few training samples.
2. Related Works
2.1. Method Based on Port Numbers
2.2. Method Based on Deep Packet Inspection
2.3. Method Based on Protocol Analysis
2.4. Method Based on Machine Learning Techniques
3. Materials and Methods
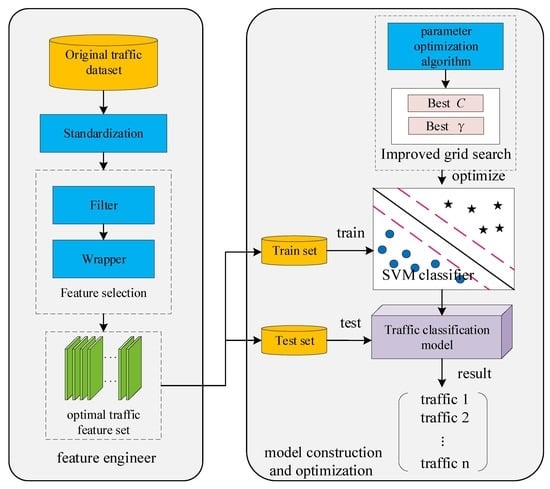
3.1. Model Framework
3.2. The Filter-Wrapper Feature Selection Algorithm
3.2.1. Filter-Wrapper Feature Selection Model Framework
3.2.2. Filter-Wrapper Feature Selection Algorithm Framework
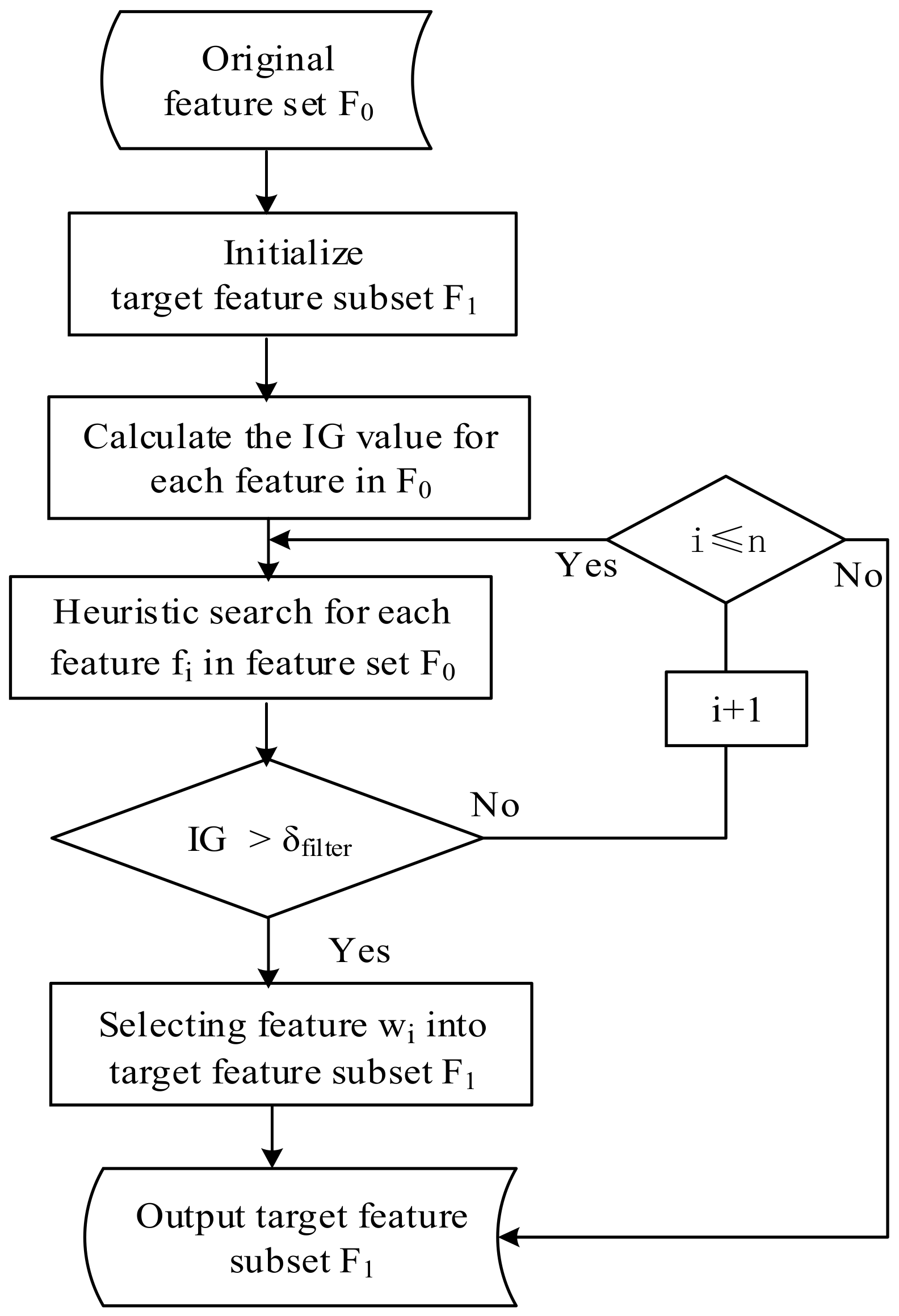
3.2.3. Filter Feature Selection Algorithm Evaluation Strategy
3.2.4. Wrapper Feature Selection Algorithm Search Strategy
| Algorithm 1: Heuristic Sequence Forward Search Strategy |
| Input: initial feature set |
| Output: target feature set |
| 1. ; |
| 2. Select features to add into the initial feature set ; |
| 3. For do |
| 4. The classification accuracy of computing data set on ; |
| 5. Select features from the remaining features and add them into to generate a new feature subset ; |
| 6. The classification accuracy of computing data set on ; |
| 7. if, then; |
| 8. else, no change; |
| 9. End if |
| 10. End For |
3.3. Parameters Optimization Based on Improved Grid Search Algorithm
3.3.1. Basic Principle of Traditional Grid Search Algorithm
3.3.2. Improved Grid Search Algorithm Framework
| Algorithm 2: Improved Grid Optimization Parameter Algorithm (IGS) |
| Input:, , , , , ; |
| Output:, , ; |
| 1. , ; |
| 2. ; |
| 3. The initial optimization result , , is obtained by searching in the initial parameter space; |
| 4. , ; |
| 5. If , then |
| 6. Second-search of optimal contour region based on evaluation results; |
| 7. The second optimization results , , are calculated and obtained; |
| 8. While do |
| 9. For, , do |
| 10. , ; |
| 11. Calculate and update the second-optimization results , , ; |
| 12. if , break |
| 13. , ; |
| 14. End For |
| 15. End While |
| 16. End if |
| 17. , , ; |
3.3.3. IGS Evaluation Strategy
4. Experimental Performance Evaluation
4.1. Datasets
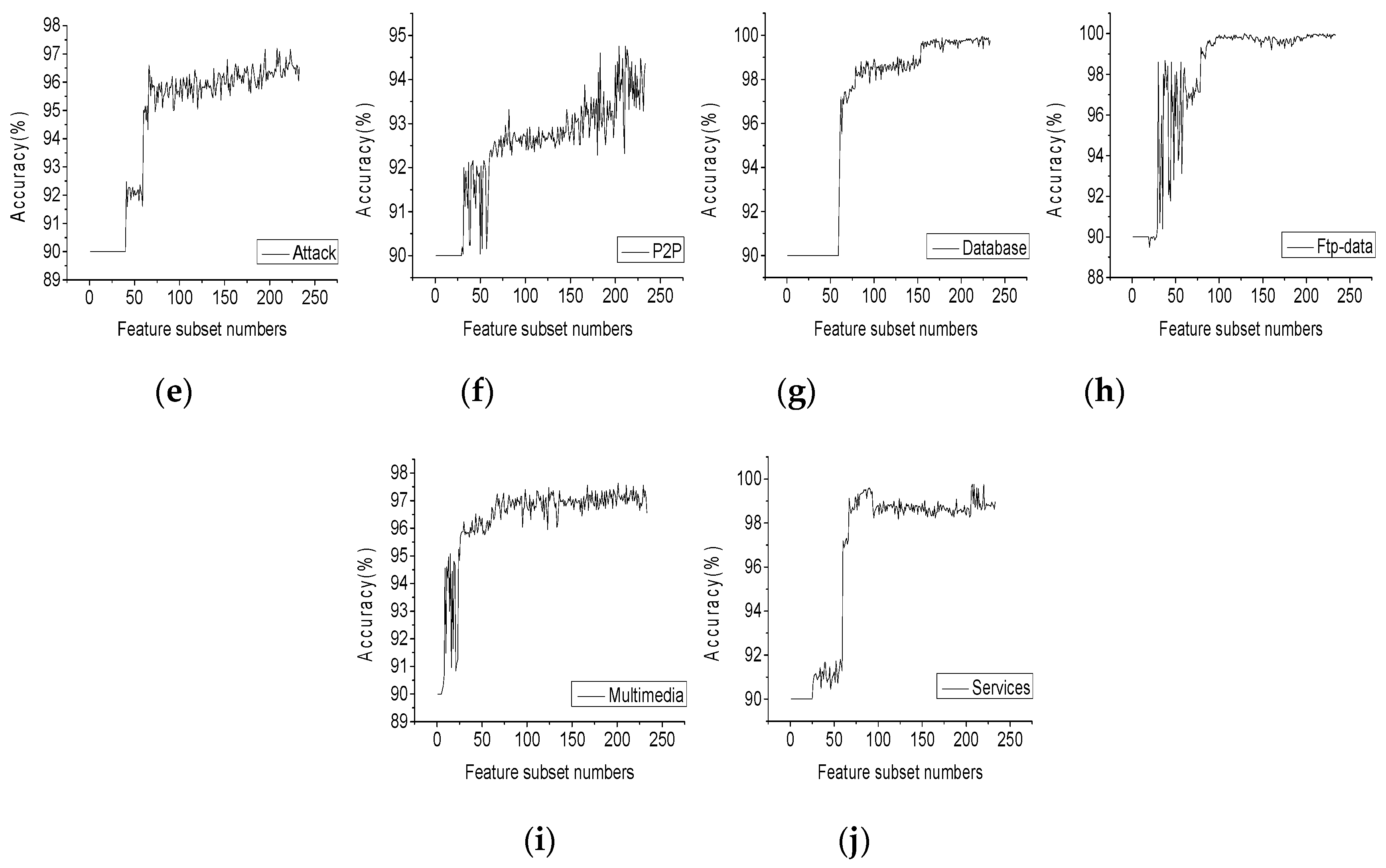
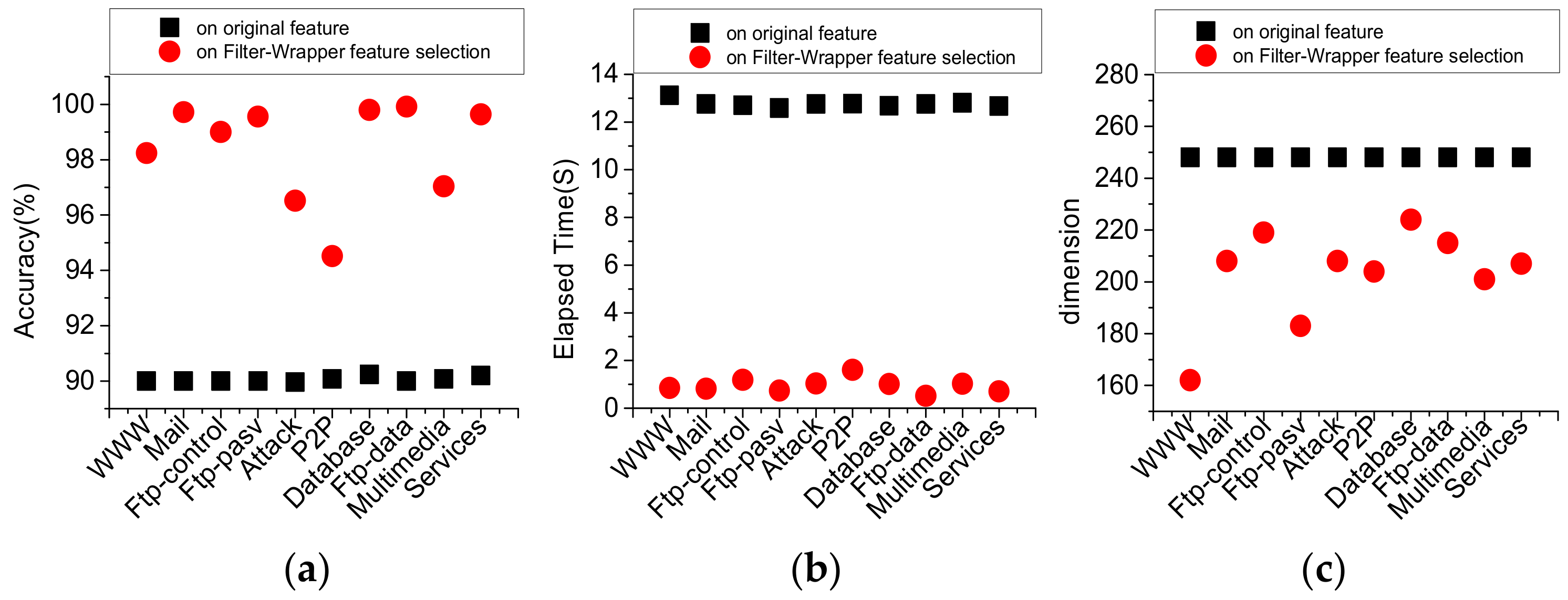
4.2. Performance Analysis of Filter-Wrapper Feature Selection
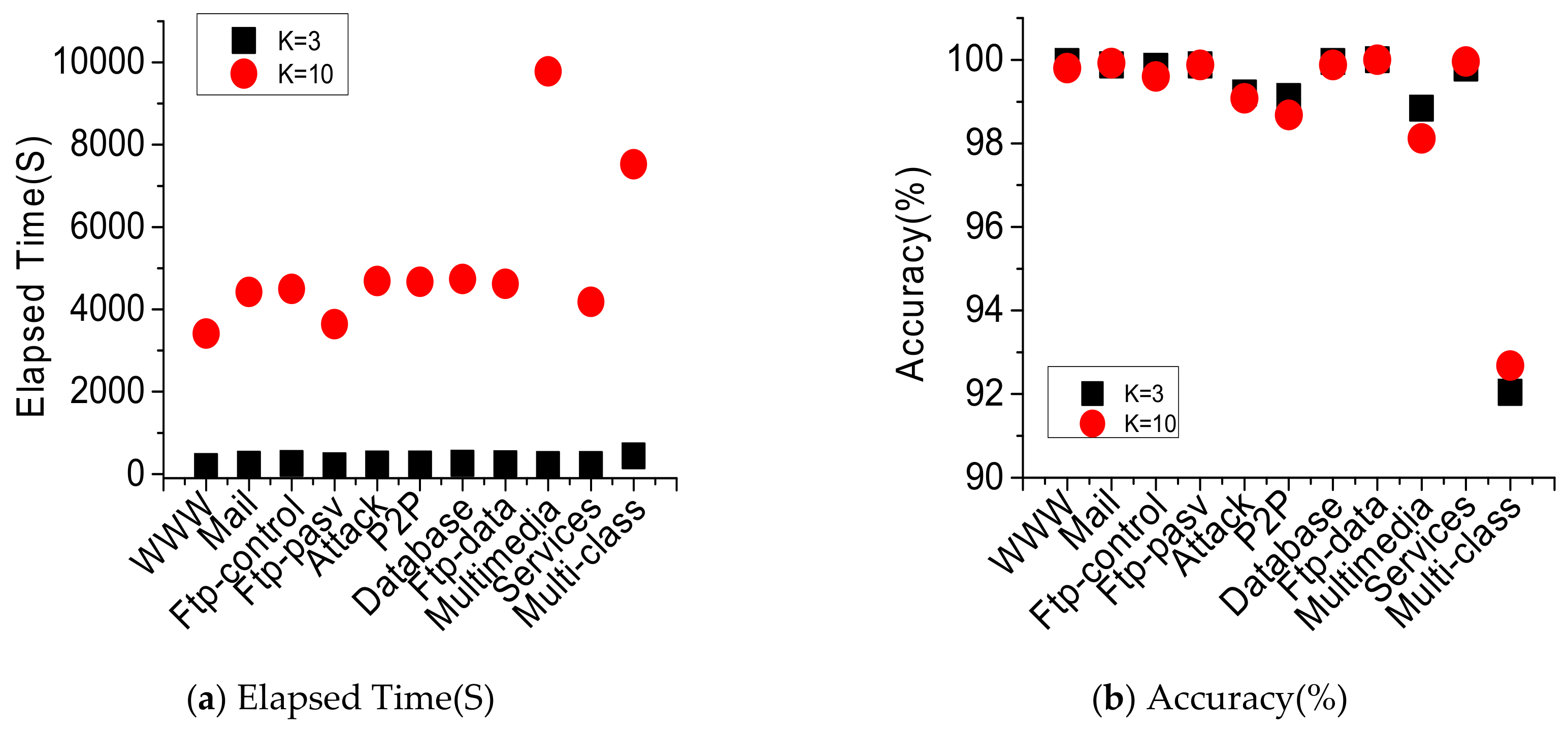
4.3. Performance Analysis of Parameter Optimization for Improved Grid Algorithm
4.3.1. Initialization Parameter Setting
4.3.2. Initial Grid Parameter Optimization
4.3.3. Second-Grid Parameter Optimization
4.4. Performance Comparison
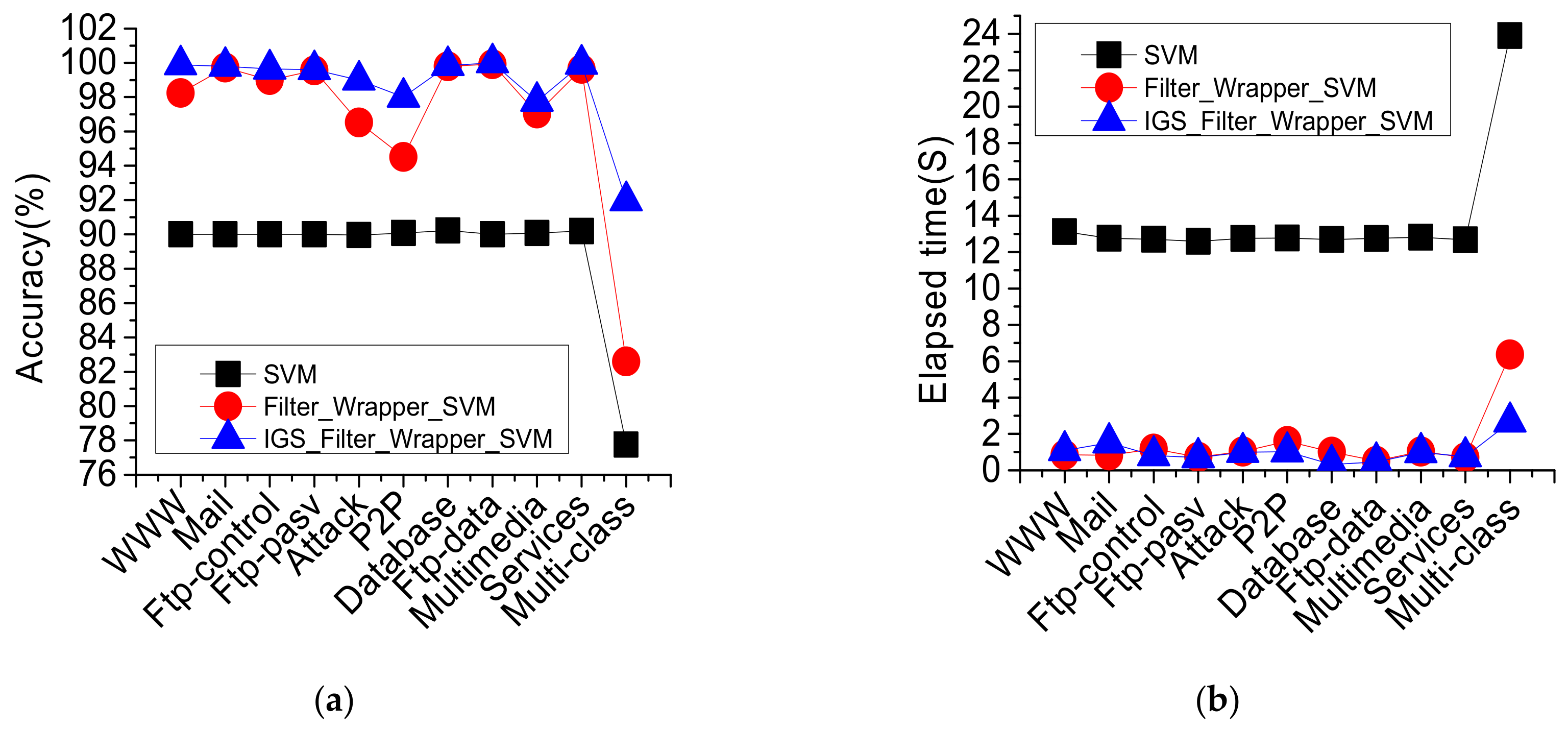
4.4.1. Comparison and Analysis of Each Stage of the IGS Algorithm
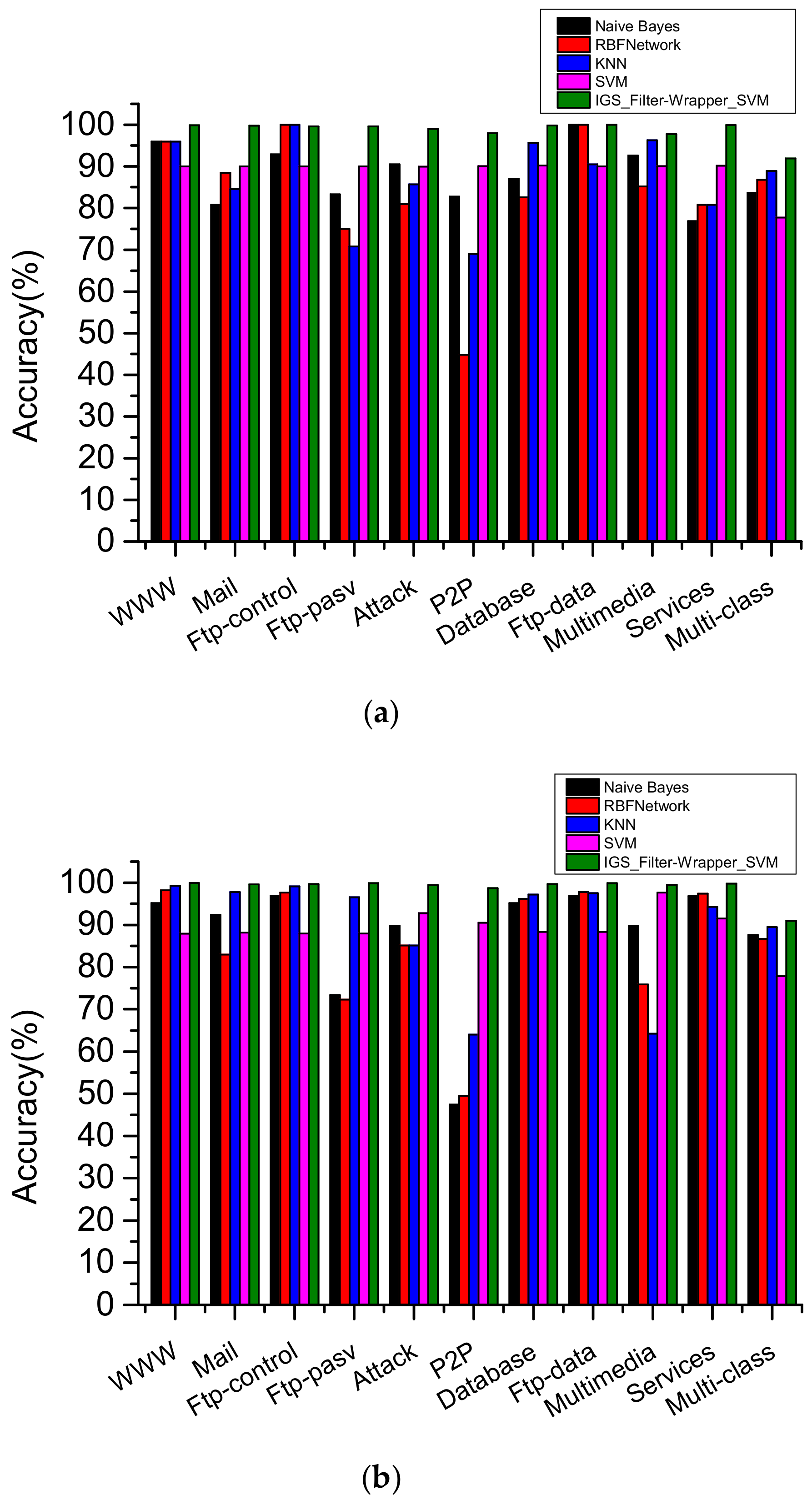
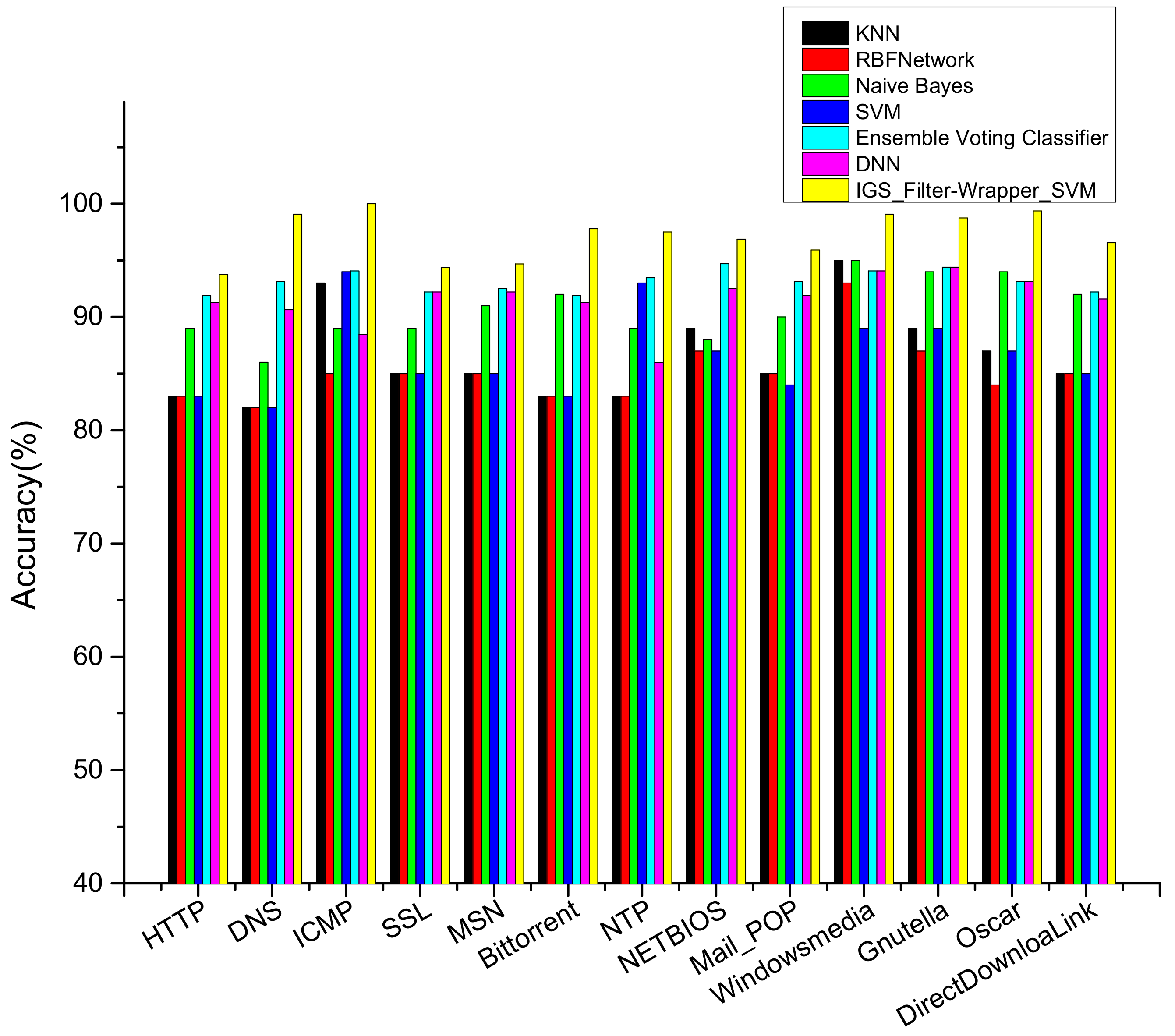
4.4.2. Comparison and Analysis of IGS and Other Algorithms
4.4.3. Comparison and Analysis of IGS on CAIDA Datasets
4.4.4. Comparison of IGS and Other Related Approaches
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Max, B.; Mritunjay, K. Identifying P2P traffic: A survey. Peer Peer Netw. Appl. 2017, 10, 1182–1203. [Google Scholar]
- Yinxiang, H.; Yun, L.; Baohua, Q. Internet traffic classification based on Min-Max Ensemble Feature Selection. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016. [Google Scholar]
- Hongtao, S.; Gang, L.; Hai, W. A novel traffic identification approach based on multifractal analysis and combined neural network. Ann. Telecommun. 2014, 69, 155–169. [Google Scholar]
- Neeraj, N.; Shikha, A.; Sanjay, S. Recent Advancement in Machine Learning Based Internet Traffic Classification. J. Procs. 2015, 60, 784–791. [Google Scholar]
- Yu, W.; Yang, X.; Wang, Z.; Shunzheng, Z. Generating regular expression signatures for network traffic classification in trusted network management. J. Netw. Comput. Appl. 2012, 35, 992–1000. [Google Scholar]
- Alok, T.; Ruben, T.; Marios, I.; Ram, K.; Antonio, N. Towards self adaptive network traffic classification. Comput. Commun. 2015, 56, 35–46. [Google Scholar]
- Hongtao, S.; Hongping, L.; Dan, Z.; Chaqiu, C.; Wei, W. Efficient and robust feature extraction and selection for traffic classification. Comput. Netw. 2017, 119, 1–16. [Google Scholar]
- Neminath, H.; Mayank, S. $BitCoding$: Network Traffic Classification through Encoded Bit Level Signatures. IEEE/ACM Trans. Netw. 2018, 26, 2334–2346. [Google Scholar]
- Jun, Z.; Chao, C.; Yang, X.; Wanlei, Z.; Athanasios, V.V. An Effective Network Traffic Classification Method with Unknown Flow Detection. IEEE Trans. Netw. Serv. Manage. 2013, 10, 133–147. [Google Scholar]
- Iliofotou, M.; Pappu, P.; Faloutsos, M. Network Traffic Analysis Using Traffic Dispersion Graphs (TDGs): Techniques and Hardware Implementation; Technical Report; University of California: Riverside, CA, USA, 2007. [Google Scholar]
- Bonfiglio, D.; Mellia, M.; Meo, M.; Rossi, D. Detailed analysis of skype traffic. IEEE Trans. Multimedia 2008, 11, 117–127. [Google Scholar] [CrossRef] [Green Version]
- Margaret, G.; Darshan, B.; Michel, C.; Josiah, D. Identifying infected users via network traffic. Comput. Secur. 2019, 80, 306–316. [Google Scholar]
- Zhihong, R.; Weina, N.; Xiaosong, Z.; Hongwei, L. Tor anonymous traffic identification based on gravitational clustering. Peer Peer Netw. Appl. 2018, 11, 592–601. [Google Scholar]
- Songyin, L.; Jing, H.; Shengnan, H.; Tiecheng, S. Improved EM method for internet traffic classification. In Proceedings of the 2016 8th International Conference on Knowledge and Smart Technology (KST), Chiangmai, Thailand, 3–6 February 2016; pp. 13–17. [Google Scholar]
- Dainotti, A.; Gargiulo, F.; Kuncheva, L.I. Identification of traffic flows hiding behind TCP port 80. In Proceedings of the 2010 IEEE International Conference on Communications, Cape Town, South Africa, 23–27 May 2010; pp. 1–6. [Google Scholar]
- Aceto, G.; Ciuonzo, D.; Montieri, A. Multi-classification approaches for classifying mobile app traffic. J. Netw. Comput. Appl. 2018, 103, 131–145. [Google Scholar] [CrossRef]
- Aceto, G.; Ciuonzo, D.; Montieri, A. Mobile encrypted traffic classification using deep learning. In Proceedings of the 2018 Network Traffic Measurement and Analysis Conference (TMA), Vienna, Austria, 26–29 June 2018; pp. 1–8. [Google Scholar]
- Wang, P.; Chen, X.; Ye, F.; Sun, Z. A survey of techniques for mobile service encrypted traffic classification using deep learning. IEEE Access 2019, 7, 54024–54033. [Google Scholar] [CrossRef]
- Vijayanand, R.; Devaraj, D.; Kannapiran, B. Intrusion detection system for wireless mesh network using multiple support vector machine classifiers with genetic-algorithm-based feature selection. Comput. Secur. 2018, 77, 304–314. [Google Scholar] [CrossRef]
- Alice, E.; Francesco, G.; Luca, S. Support Vector Machines for TCP traffic classification. Comput. Netw. 2009, 53, 2476–2490. [Google Scholar]
- Yuan, R.; Li, Z.; Guan, X.; Xu, L. An SVM-based machine learning method for accurate internet traffic classification. Inf. Syst. Front. 2010, 12, 149–156. [Google Scholar] [CrossRef]
- Sicker, D.C.; Ohm, P.; Grunwald, D. Legal issues surrounding monitoring during network research. In Proceedings of the 7th ACM SIGCOMM Conference On Internet Measurement, San Diego, CA, USA, 24–26 October 2007; pp. 141–148. [Google Scholar] [CrossRef]
- Scott, D.; Stuart, R. NP-Completeness of Searches for Smallest Possible Feature Sets; AAAI Press: Palo Alto, CA, USA, 1994; pp. 37–39. [Google Scholar]
- Selvi, S.; Manimegalai, D. Task Scheduling Using Two-Phase Variable Neighborhood Search Algorithm on Heterogeneous Computing and Grid Environments. Arab. J. Sci. Eng. 2015, 40, 817–844. [Google Scholar] [CrossRef]
- Adriana, M.C. Tuning model parameters through a Genetic Algorithm approach. In Proceedings of the 2016 IEEE 12th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 8–10 September 2016; pp. 135–140. [Google Scholar]
- Di, H.; Yunlv, H. An Improved Tabu Search Algorithm Based on Grid Search Used in the Antenna Parameters Optimization. Math. Probl. Eng. 2015. [Google Scholar] [CrossRef]
- Yudong, Z.; Zhangjing, Y.; Huimin, L.; Xingxing, Z.; Preetha, P.; Qingming, L.; Shuihua, W. Facial Emotion Recognition Based on Biorthogonal Wavelet Entropy, Fuzzy Support Vector Machine, and Stratified Cross Validation. IEEE Access 2015, 4, 8375–8385. [Google Scholar]
- Lei, M.; Manchun, L.; Yu, G.; Tan, C.; Xiaoxue, M.; Lean, Q. A Novel Wrapper Approach for Feature Selection in Object-Based Image Classification Using Polygon-Based Cross-Validation. IEEE Geosci. Remote. Sens. Lett. 2017, 14, 409–413. [Google Scholar]
- Moore, A.; Zuev, D. Discriminators for Use in Flow-Based Classification; Intel Research: Cambridge, UK, 2005. [Google Scholar]
- Mashael, A.; Kevin, B.; Ian, G. Enhancing Tor’s performance using real-time traffic classification. In Proceedings of the 2012 ACM conference on Computer and communications security, Raleigh, CA, USA, 16–18 October 2012; pp. 73–84. [Google Scholar]
- Chihchung, C.; Chihjen, L. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar]
- The Cooperative Association for Internet Data Analysis (CAIDA). Available online: http://www.caida.org (accessed on 1 September 2012).
- Sena, G.; Pablo, B. Statistical traffic classification by boosting support vector machines. In Proceedings of the 7th Latin American Networking Conference, New York, NY, USA, 4–5 October 2012. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Traffic Class | Representative Application | Sample of Flows | Traffic Class | Representative Application | Sample Flows |
|---|---|---|---|---|---|
| WWW | http, https | 2999 | P2P | Kazaa, BitTorrent, Gnutella | 2391 |
| pop2/3,smtp, imap | 2999 | Database | Postgres, sqlnet, Oracle, ingres | 2943 | |
| FTP-control | FTP | 2990 | Ftp-data | ftp | 2997 |
| FTP-pasv | FTP | 2989 | Multi- Media | Voice, video | 576 |
| Attack | Worm, virus | 1973 | Service | X11,dns, Ident, ntp | 2220 |
| Feature Number | Feature Description | Feature Number | Feature Description |
|---|---|---|---|
| 40 | dsack_pkts_sent_b a | 78 | urgent_data_bytes_b a |
| 53 | zwnd_probe_pkts_a b | 92 | zero_win_adv_b a |
| 54 | zwnd_probe_pkts_b a | 102 | missed_data_b a |
| 55 | zwnd_probe_pkts_b a | 103 | truncated_data_a b |
| 56 | zwnd_probe_bytes_b a | 104 | truncated_data_b a |
| 75 | urgent_data_pkts_a b | 105 | truncated_packets_a b |
| 76 | urgent_data_pkts_b a | 106 | truncated_packets_b a |
| 77 | urgent_data_bytes_a b |
| Traffic Class | The Number of Optimal Feature Combinations | Accuracy (%) |
|---|---|---|
| WWW | 162 | 98.8 |
| 208 | 99.96 | |
| FTP-control | 219 | 99.44 |
| FTPp-pasv | 183 | 99.8 |
| Attack | 208 | 97.2 |
| P2P | 204 | 94.76 |
| Database | 224 | 99.96 |
| FTP-data | 215 | 99.98 |
| Multimedia | 201 | 97.64 |
| Services | 207 | 99.76 |
| Traffic Class | The Number of Optimal Feature Combinations | Accuracy (%) | ||
|---|---|---|---|---|
| WWW | 162 | 11.3137 | 0.0625 | 99.96 |
| 208 | 0.5 | 0.0220971 | 99.88 | |
| Ftp-control | 219 | 32 | 0.00276214 | 99.84 |
| Ftp-pasv | 183 | 11.3137 | 0.0220971 | 99.88 |
| Attack | 208 | 90.5097 | 0.0220971 | 99.20 |
| P2P | 204 | 724.077 | 0.0625 | 99.12 |
| Database | 224 | 4 | 0.0220971 | 99.96 |
| Ftp-data | 215 | 1.41421 | 0.0220971 | 100.00 |
| Multimedia | 201 | 724.077 | 0.0078125 | 98.84 |
| Services | 207 | 4 | 0.5 | 99.80 |
| Multi-class | 219 | 11.3137 | 0.0220971 | 92.04 |
| Traffic Class | Traffic Class | ||||
|---|---|---|---|---|---|
| WWW | 1.41421 | 0.176777 | Database | 2 | 0.0110485 |
| 1 | 0.125 | Ftp-data | 1 | 0.03125 | |
| Ftp-control | 1.41421 | 0.0220971 | Multimedia | 22.6274 | 0.015625 |
| Ftp-pasv | 5.65685 | 0.0625 | Services | 4 | 0.0883883 |
| Attack | 8 | 0.03125 | Multi-class | 5.65685 | 0.03125 |
| P2P | 32 | 0.015625 |
| Traffic Class | Sample Number | Traffic Class | Sample Number |
|---|---|---|---|
| Http | 33667 | NETBIOS | 58 |
| DNS | 22814 | Mail_POP | 64 |
| ICMP | 1318 | Windows media | 46 |
| SSL | 2671 | Gnutella | 108 |
| MSN | 190 | Oscar | 126 |
| Bittorrent | 61 | DirectDownloadLink | 45 |
| NTP | 81 |
| Algorithm | Feature Selection | Parameters Optimization | Classification Accuracy |
|---|---|---|---|
| IGS_filter-wrapper_SVM | Filter-Wrapper | IGS | more than 99.34% |
| Ensemble learning [15] | Identification Engineer | no | more than 99% |
| Ensemble learning [16] | Burst Threshold | no | more than 80% |
| Deep learning [17] | No | Back-Propagation | more than 80% |
| SVM [21] | Sequential forward | Grid-Search | 97.17% |
| SVM [33] | No | Grid-Search | more than 95% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, J.; Wang, D.; Qu, Z.; Sun, H.; Li, B.; Chen, C.-L. An Improved Network Traffic Classification Model Based on a Support Vector Machine. Symmetry 2020, 12, 301. https://doi.org/10.3390/sym12020301
Cao J, Wang D, Qu Z, Sun H, Li B, Chen C-L. An Improved Network Traffic Classification Model Based on a Support Vector Machine. Symmetry. 2020; 12(2):301. https://doi.org/10.3390/sym12020301
Chicago/Turabian StyleCao, Jie, Da Wang, Zhaoyang Qu, Hongyu Sun, Bin Li, and Chin-Ling Chen. 2020. "An Improved Network Traffic Classification Model Based on a Support Vector Machine" Symmetry 12, no. 2: 301. https://doi.org/10.3390/sym12020301
APA StyleCao, J., Wang, D., Qu, Z., Sun, H., Li, B., & Chen, C.-L. (2020). An Improved Network Traffic Classification Model Based on a Support Vector Machine. Symmetry, 12(2), 301. https://doi.org/10.3390/sym12020301