Natural Language Processing Model for Automatic Analysis of Cybersecurity-Related Documents


Abstract
1. Introduction
1.1. Our Contribution
1.2. Related Work
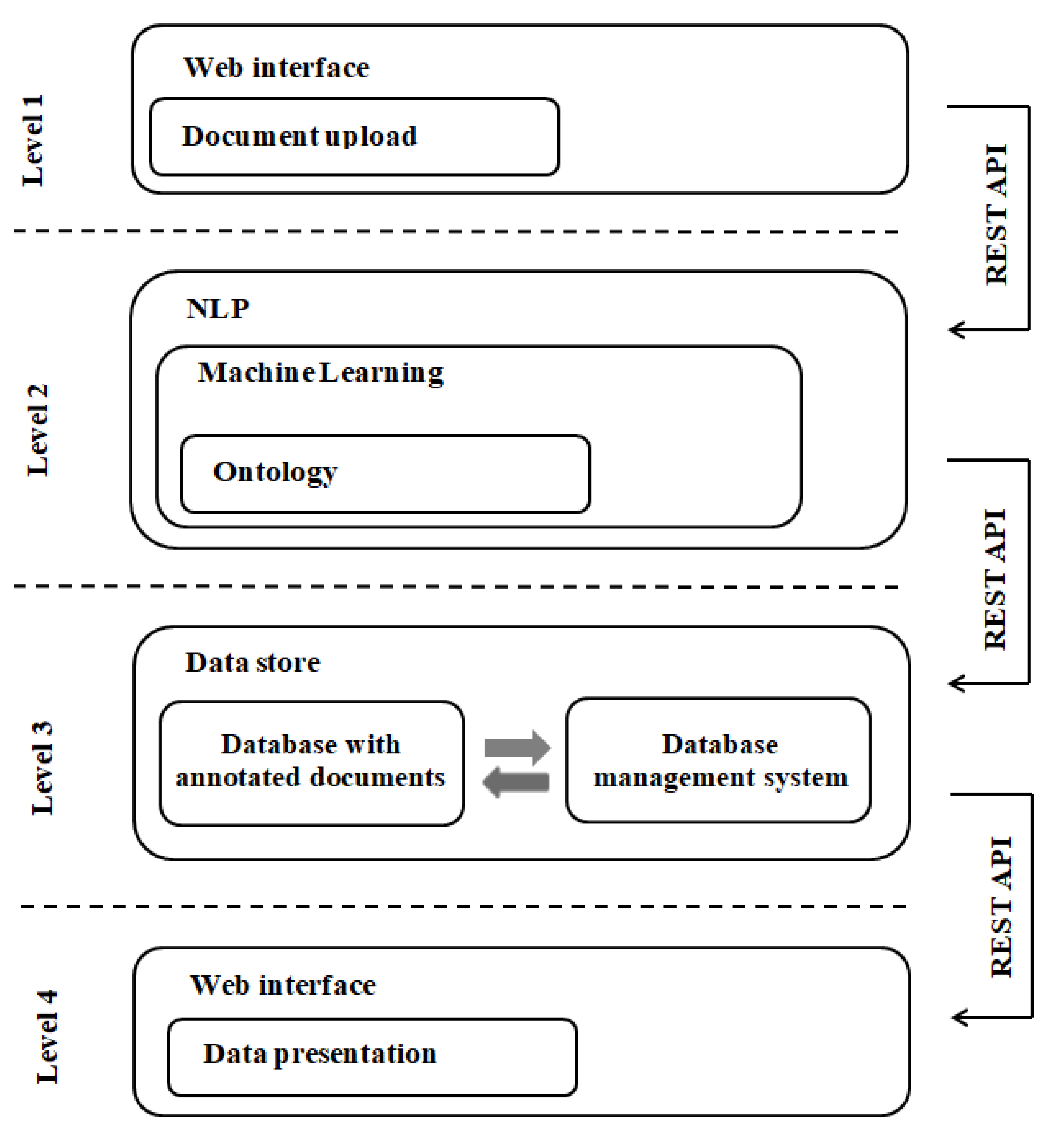
2. The Architecture of Cybersecurity Analyzer
3. The Development of the NLP Model Based on ML for the Cybersecurity Field
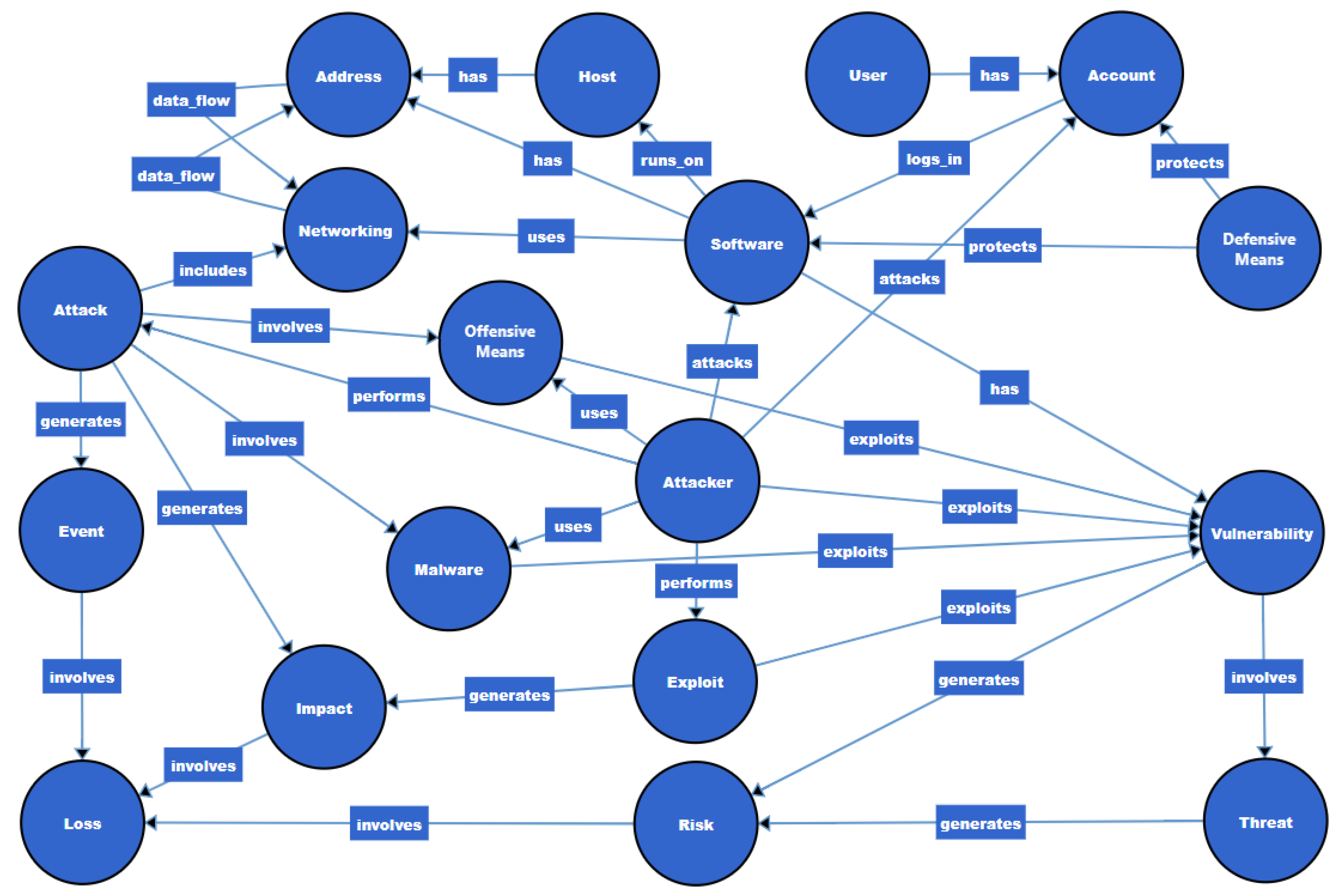
3.1. Developing a Domain Ontology
3.2. Implementing the Ontology Using IBM Watson
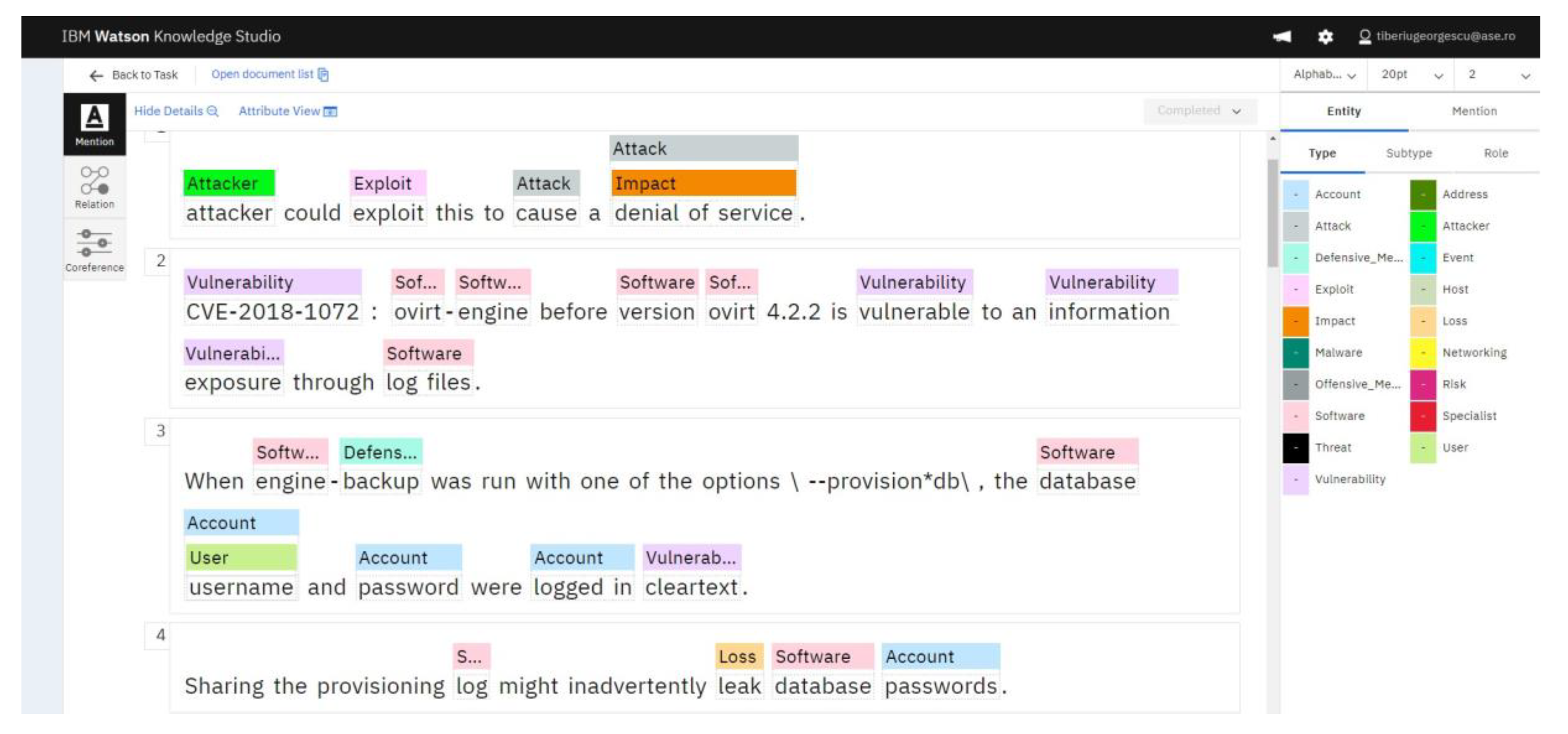
3.3. The Development Process of the NER Model
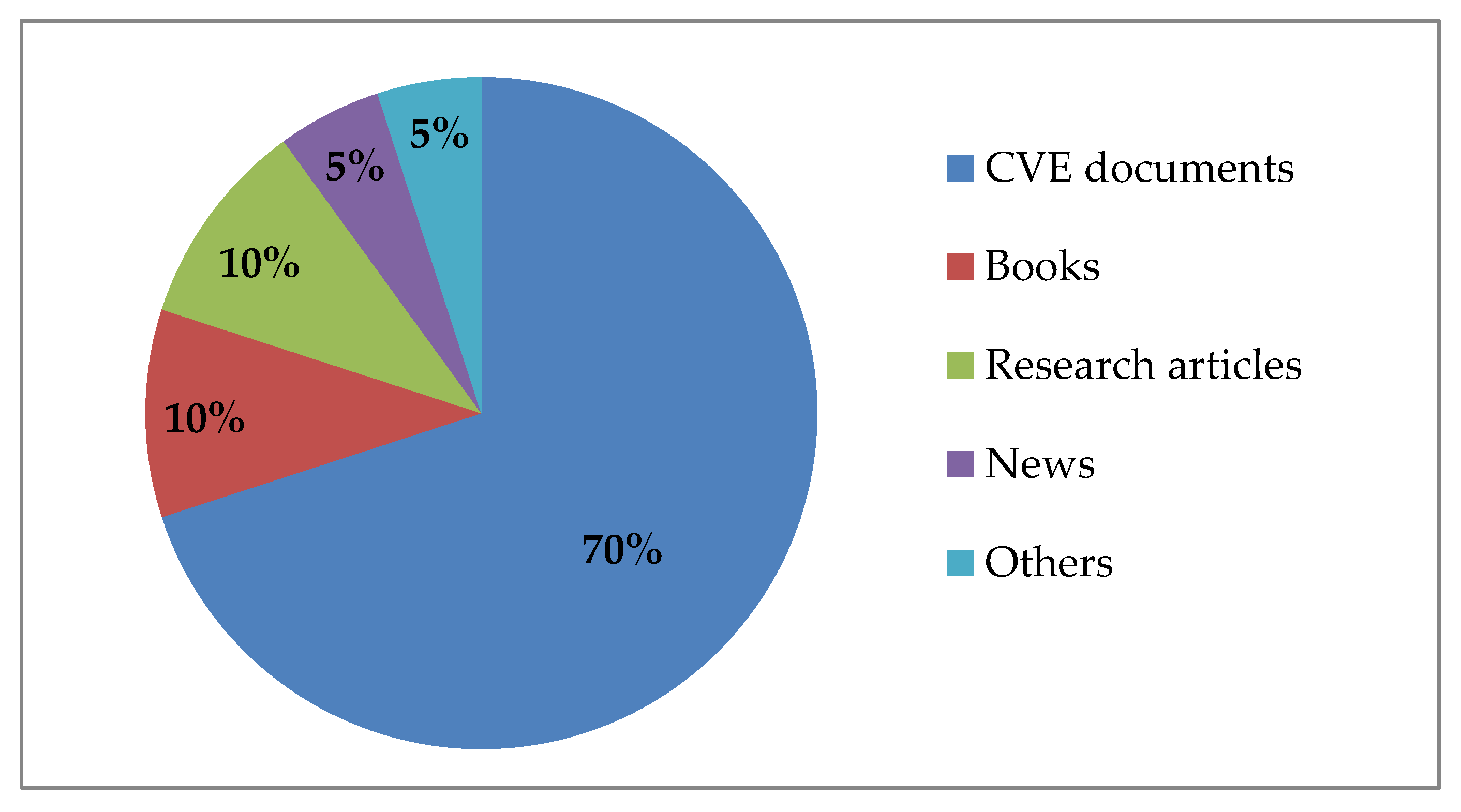
3.4. The Training Process
- Pre-annotation of documents using the rule-based model (based on the ontology): The rule-based model identifies predefined elements, such as instances or relations. Subsequently, since the human annotation process is time-consuming, we used the rule-based model to automatize and speed up the training process of the ML model. The advantage of this approach is the reduced time required for annotation. On the other hand, the annotators need to be extra careful. If the machine has annotation flaws and the mistakes are not corrected by the human annotators, the flaws become even more difficult to correct in the subsequent process;
- Correction of the annotation made by the rule-based model: Very often, the entities automatically annotated by the rule-based model are incomplete and sometimes even wrong, therefore human intervention is required;
- Quality examination of the annotation process: For this purpose periodic tests of the ML-based model’s performances are implemented, comparing the evolution of indicators over time;
- Integration of the training sets into the model: Once the training sets are considered to be appropriately annotated, they are approved and integrated within the model, being marked as ground truth.
4. Model Performances
4.1. Methodology and Metrics Used
- Training sets: represent documents labeled by humans. Starting from these annotations, the model learns to properly recognize entities, relations and classes;
- Test sets: represent documents used to test the model after it has been trained. The performances are evaluated based on the differences between the annotations made by the model and those made by human;
- Blind sets: represent documents that have not been previously viewed by the humans involved in the annotation process [31].
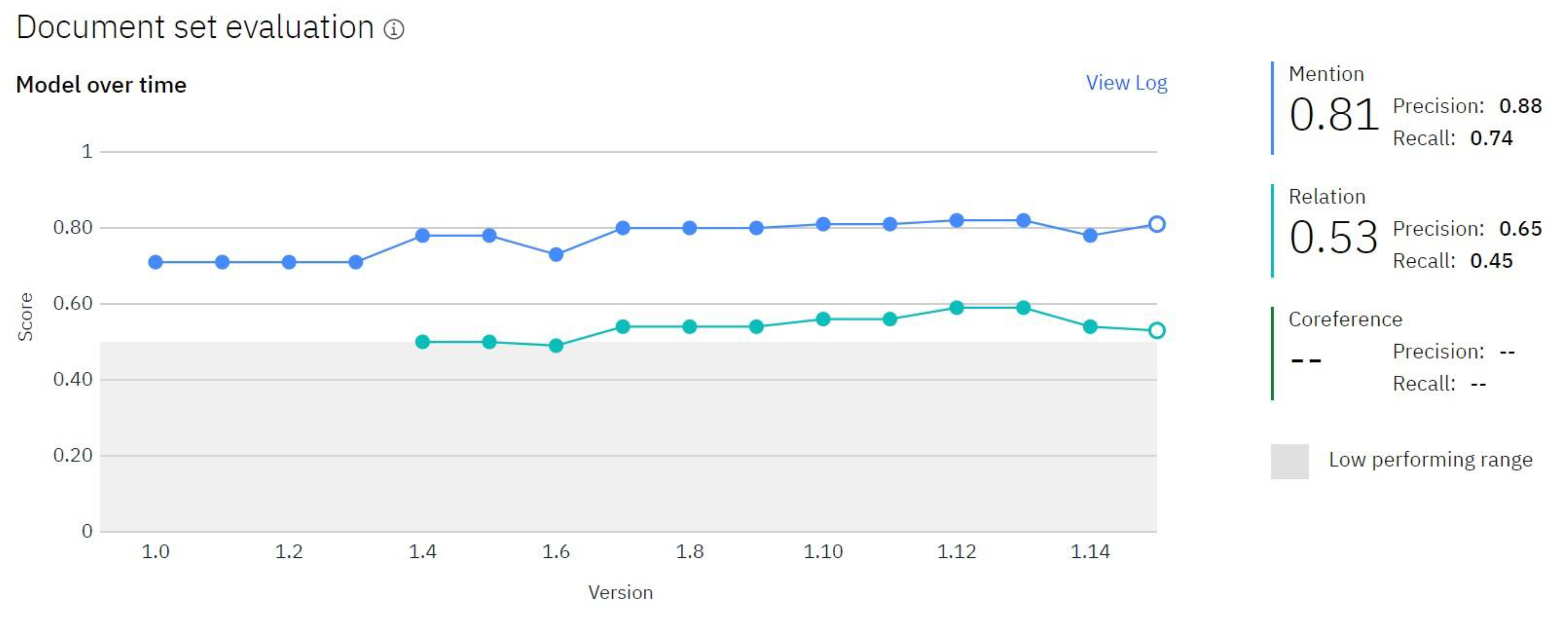
4.2. The Values of Performance Indicators Obtained by Our Model
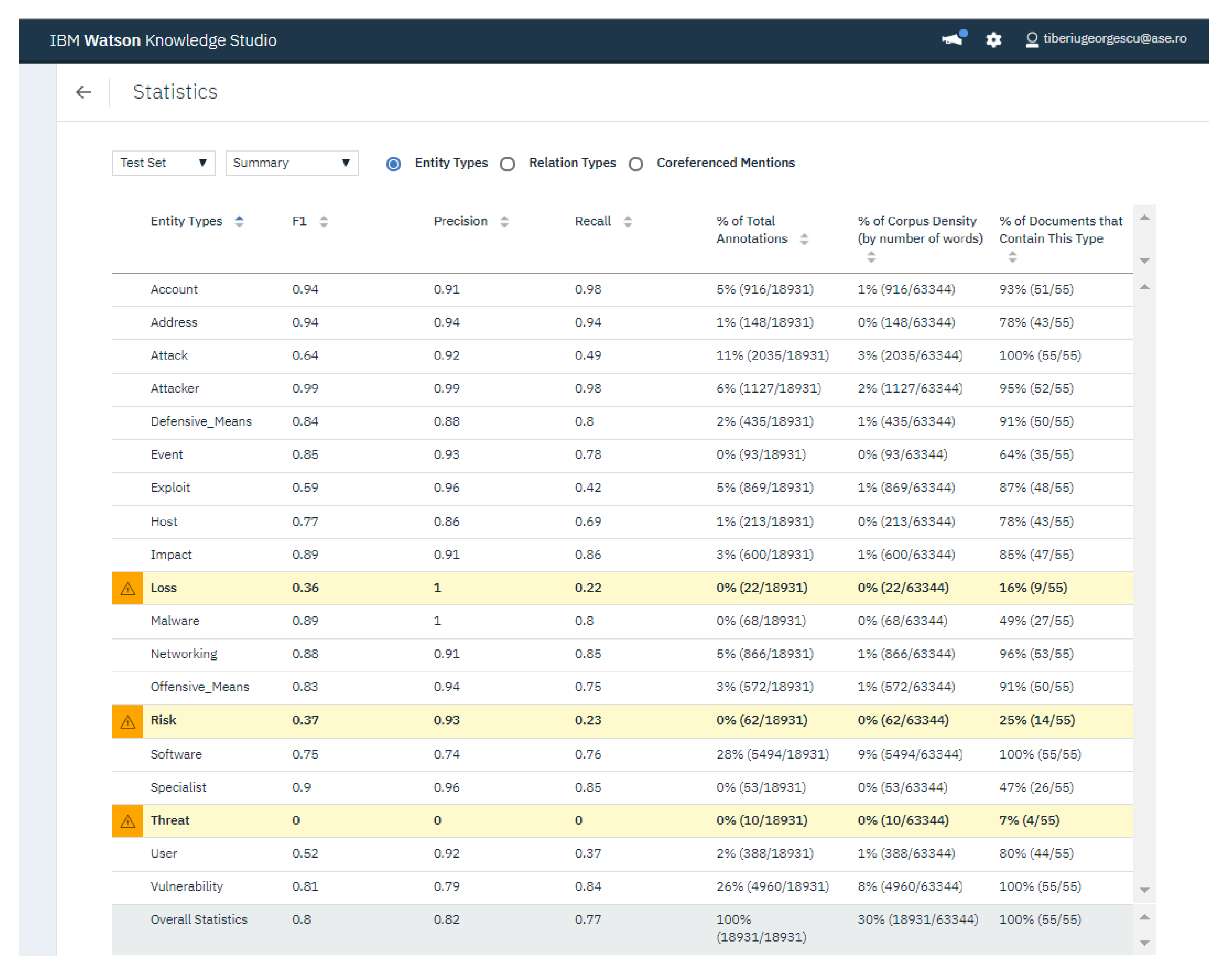
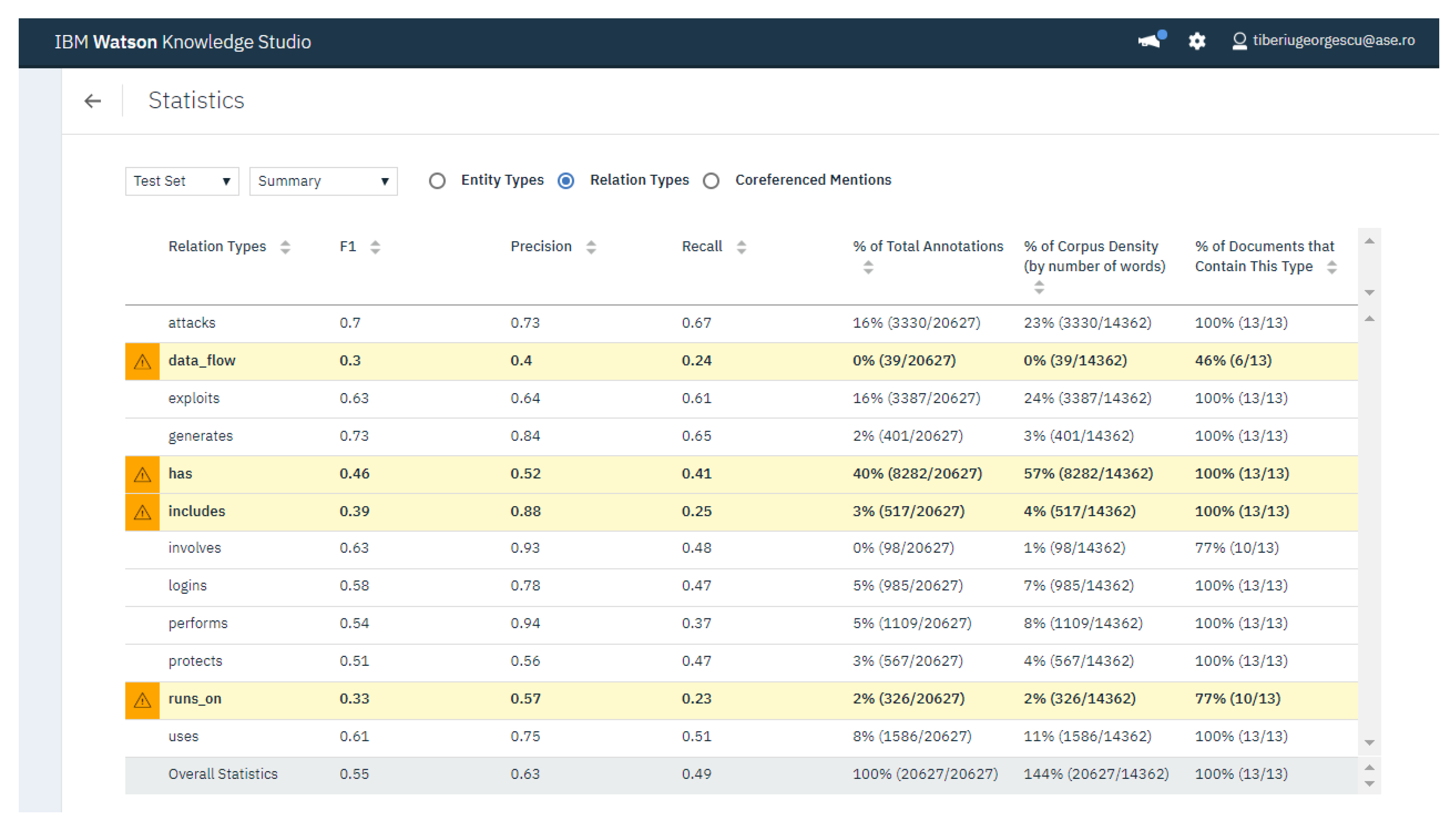
4.3. Analysis of F1 Score, Precision and Recall Indicators for NER
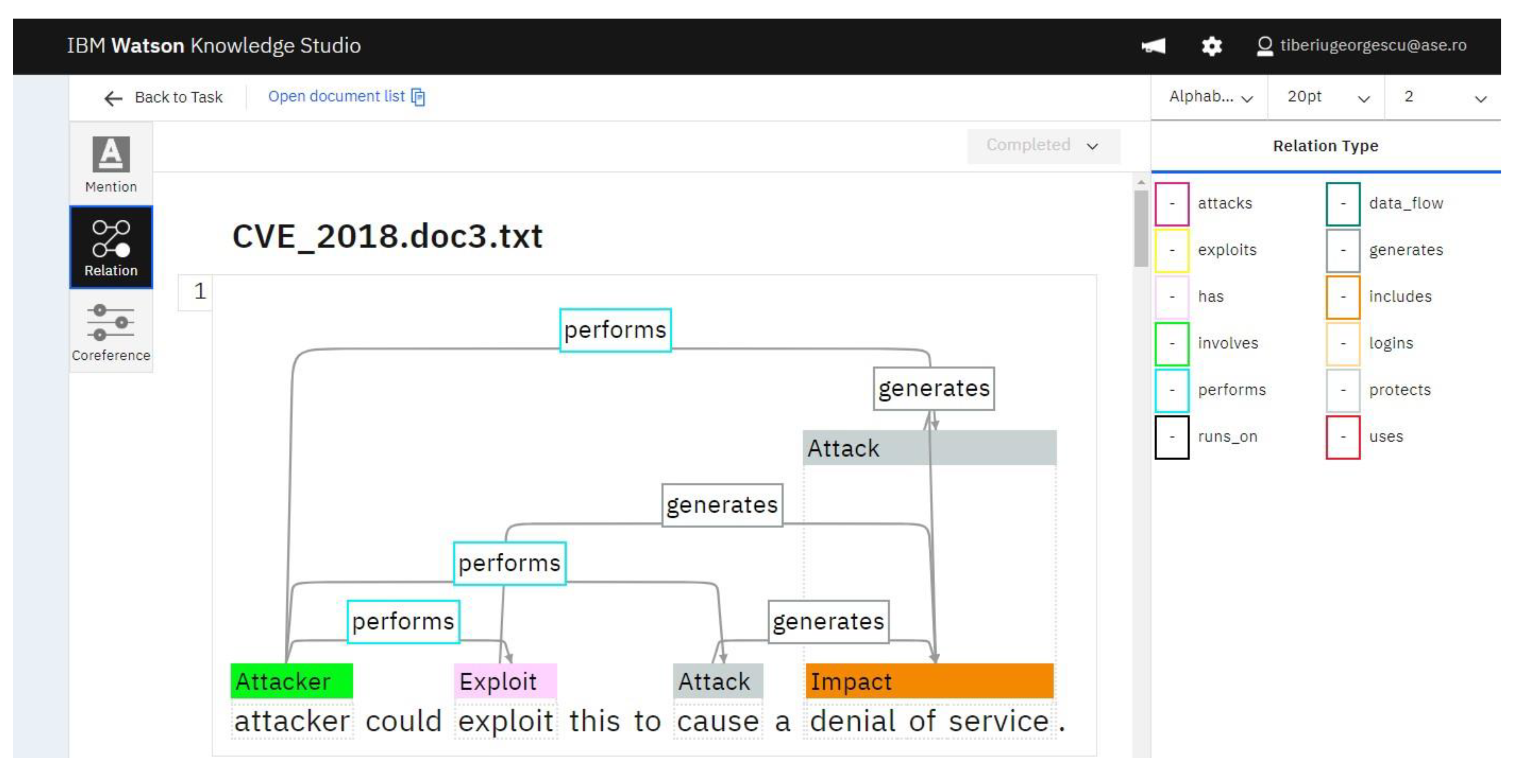
4.4. Analysis of F1 Score, Precision and Recall for Relation Extraction
4.5. The Comparison of Our Results with Other Similar Models
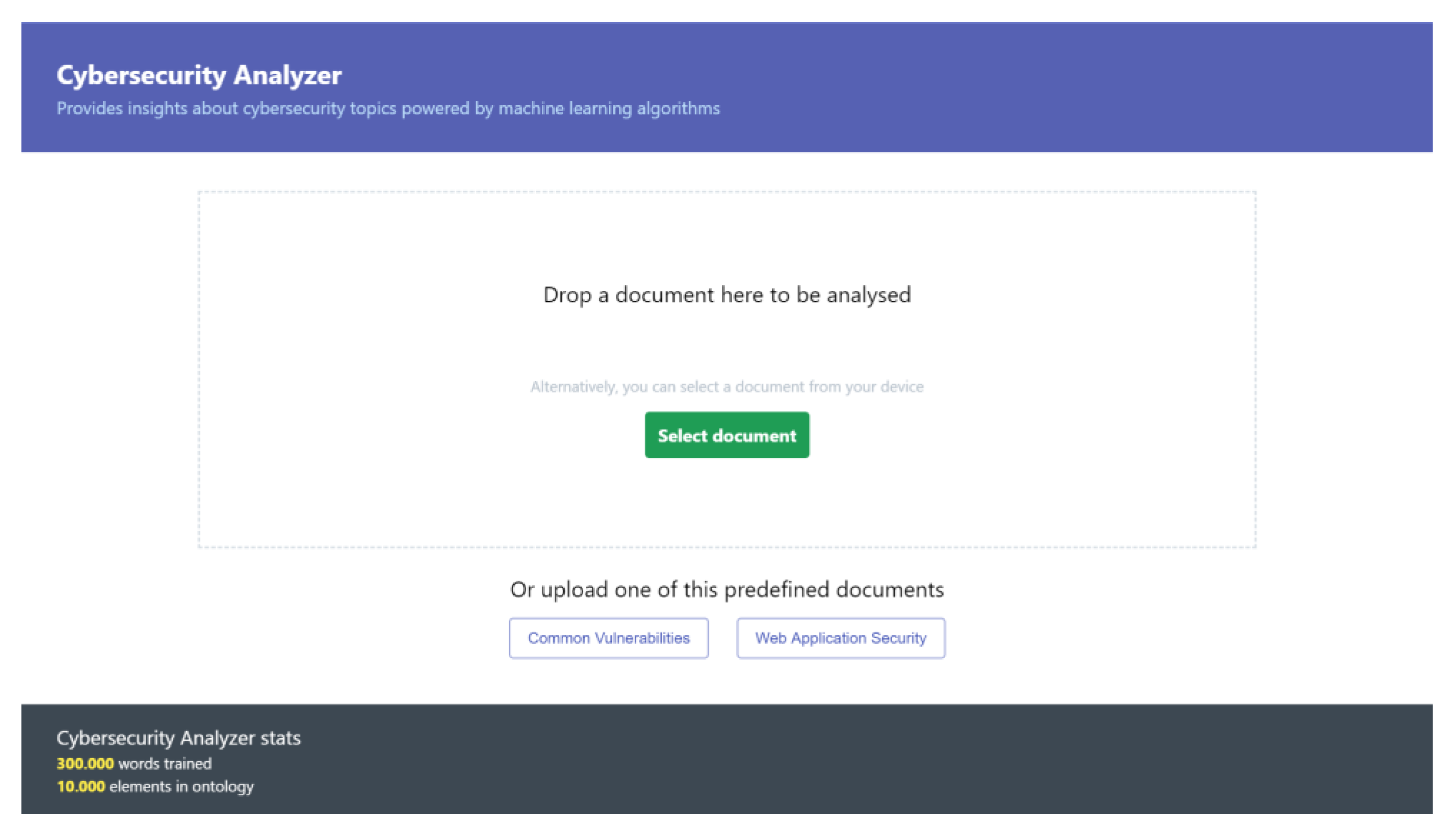
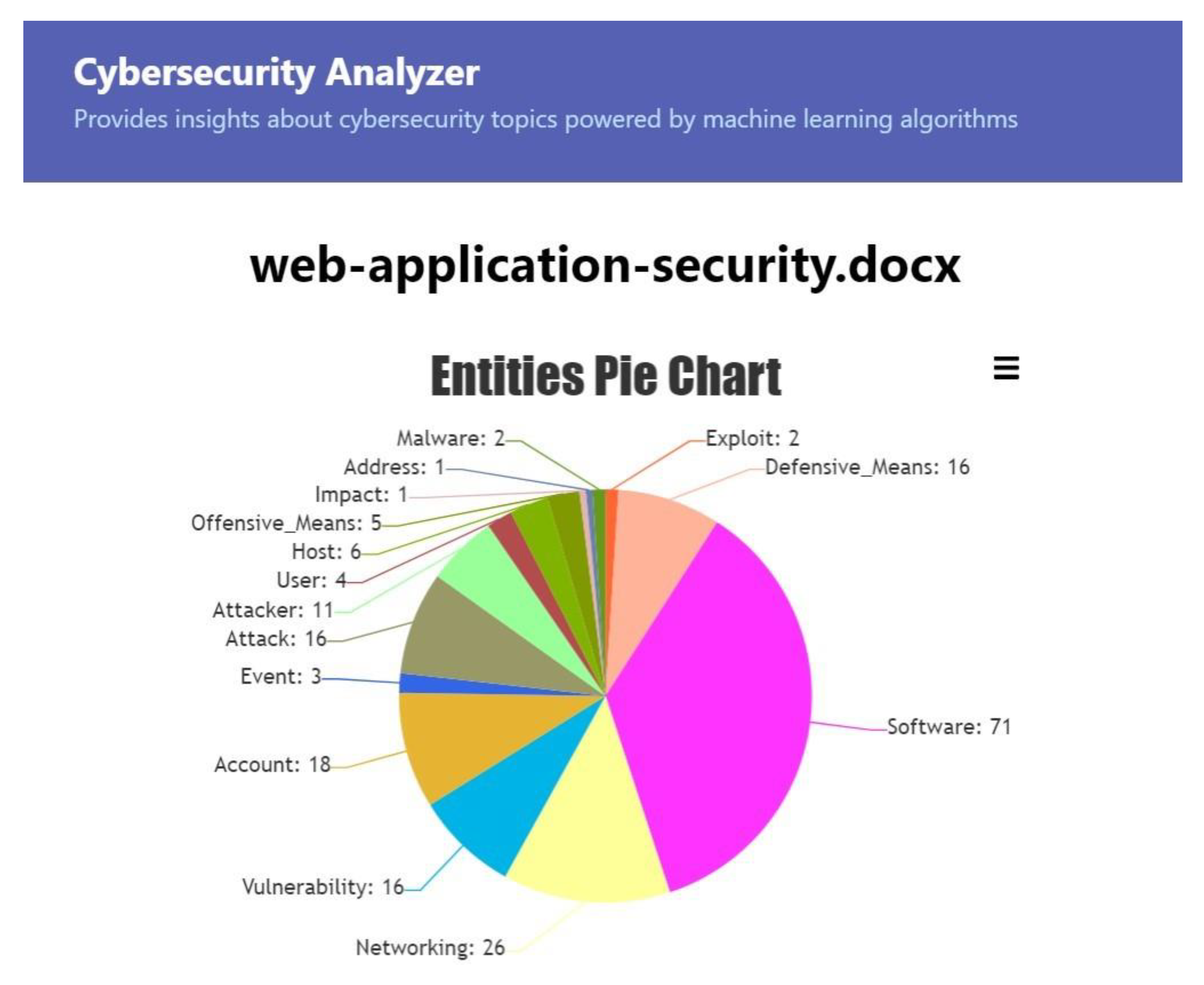
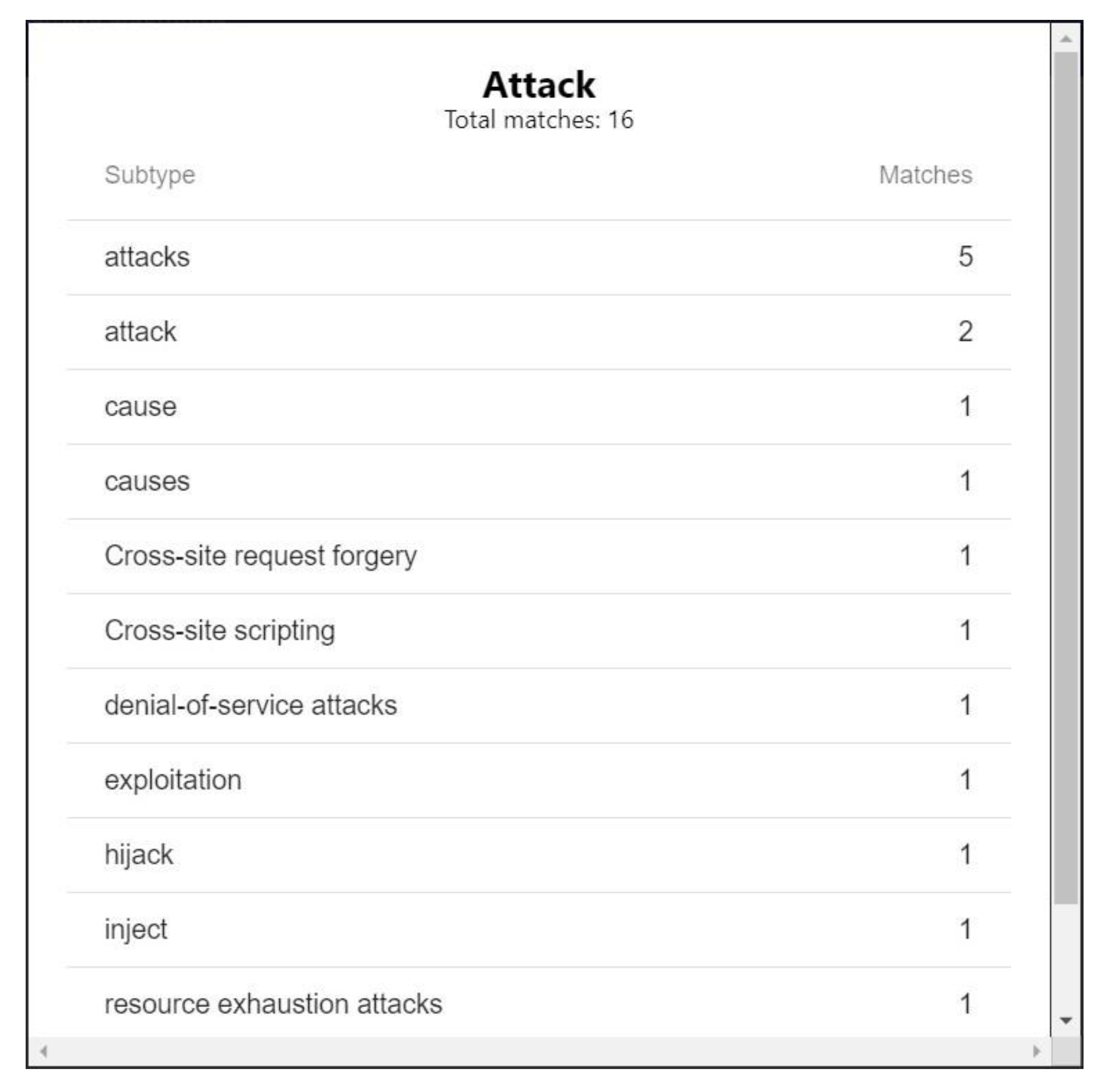
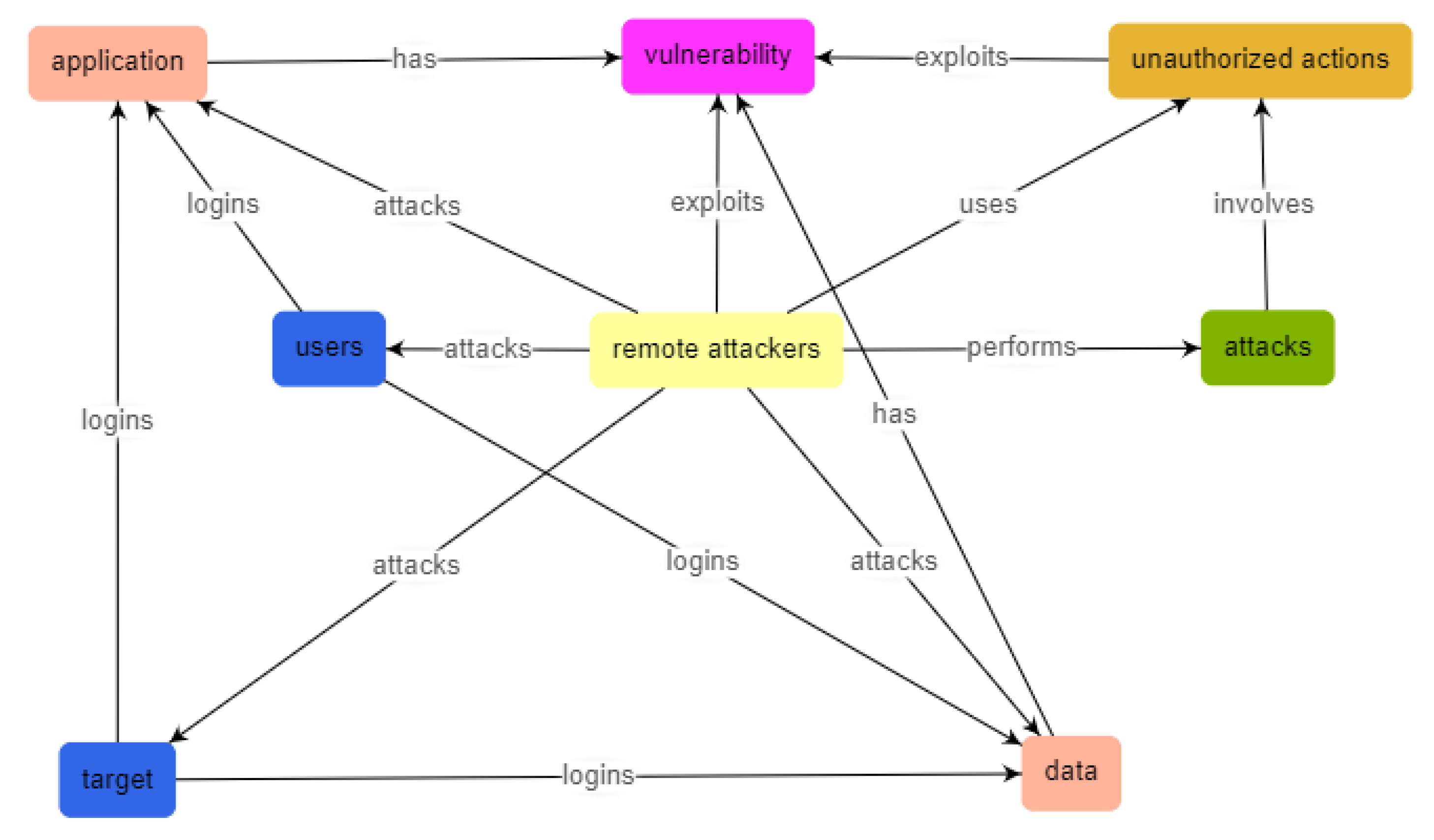
5. Using Cybersecurity Analyzer
- Presentation of the entities and classes relevant to the cybersecurity field for documents uploaded by users;
- Presentation of the relations between the identified entities (Figure 13).
6. Conclusions and Future Work
Supplementary Materials
Funding
Acknowledgments
Conflicts of Interest
References
- Georgescu, T.M. Machine learning based system for semantic indexing documents related to cybersecurity. Econ. Inform. 2019, 19. [Google Scholar] [CrossRef]
- Cockburn, I.M.; Henderson, R.; Stern, S. The impact of artificial intelligence on innovation. In The Economics of Artificial Intelligence: An Agenda, National Bureau of Economic Research; University of Chicago Press: Chicago, IL, USA, 2019; Volume w24449. [Google Scholar]
- Iannacone, M.; Bohn, S.; Nakamura, G.; Gerth, J.; Huffer, K.; Bridges, R.; Goodall, J. Developing an ontology for cyber security knowledge graphs. In Proceedings of the 10th Annual Cyber and Information Security Research Conference, Oak Ridge, TN, USA, 7–9 April 2015; p. 12. [Google Scholar]
- Scarpato, N.; Cilia, N.D.; Romano, M. Reachability Matrix Ontology: A Cybersecurity Ontology. Appl. Artif. Intell. 2019, 33, 643–655. [Google Scholar] [CrossRef]
- Narayanan, S.N.; Ganesan, A.; Joshi, K.; Oates, T.; Joshi, A.; Finin, T. Early Detection of Cybersecurity Threats Using Collaborative Cognition. In Proceedings of the 4th International Conference on Collaboration and Internet Computing (CIC), Philadelphia, PA, USA, 18–20 October 2018; pp. 354–363. [Google Scholar]
- Georgescu, T.M.; Smeureanu, I. Using Ontologies in Cybersecurity Field. Inform. Econ. 2017, 21. Available online: http://revistaie.ase.ro/ (accessed on 16 November 2019). [CrossRef]
- Mozzaquatro, B.A.; Agostinho, C.; Goncalves, D.; Martins, J.; Jardim-Goncalves, R. An ontology-based cybersecurity framework for the internet of things. Sensors 2018, 18, 3053. [Google Scholar] [CrossRef] [PubMed]
- Georgescu, T.M.; Iancu, B.; Zurini, M. Named-Entity-Recognition-Based Automated System for Diagnosing Cybersecurity Situations in IoT Networks. Sensors 2019, 19, 3380. [Google Scholar] [CrossRef] [PubMed]
- Jia, Y.; Qi, Y.; Shang, H.; Jiang, R.; Li, A. A practical approach to constructing a knowledge graph for cybersecurity. Engineering 2018, 4, 53–60. [Google Scholar] [CrossRef]
- Radi, A.N.; Rabeeh, A.; Bawakid, F.M.; Farrukh, S.; Ullah, Z.; Daud, A.; Aslam, M.A.; Alowibdi, J.S.; Saeed-Ul, H. Web Observatory Insights: Past, Present, and Future. Int. J. Semant. Web Inf. Syst. 2019, 15, 52–68. [Google Scholar]
- Bakker de Boer, M.H.; Bakker, B.J.; Boertjes, E.; Wilmer, M.; Raaijmakers, S.; van der Kleij, R. Text Mining in Cybersecurity: Exploring Threats and Opportunities. Multimodal Technol. Interact. 2019, 3, 62. [Google Scholar] [CrossRef]
- Bridges, R.A.; Jones, C.L.; Iannacone, M.D.; Testa, K.M.; Goodall, J.R. Automatic labeling for entity extraction. arXiv 2013, arXiv:1308.4941. Available online: https://arxiv.org/abs/1308.4941 (accessed on 8 February 2020).
- National Vulnerability Database. Available online: https://nvd.nist.gov/ (accessed on 11 October 2019).
- McNeil, N.; Bridges, R.A.; Iannacone, M.D.; Czejdo, B.; Perez, N.; Goodall, J.R. Pattern accurate computationally efficient bootstrapping for timely discovery of cyber-security concepts. In Proceedings of the 12th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 4–7 December 2013; pp. 60–65. [Google Scholar]
- Bridges, R.A.; Huffer, K.M.; Jones, C.L.; Iannacone, M.D.; Goodall, J.R. Cybersecurity Automated Information Extraction Techniques: Drawbacks of Current Methods, and Enhanced Extractors. In Proceedings of the 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 437–442. [Google Scholar]
- Gasmi, H.; Laval, J.; Bouras, A. Information Extraction of Cybersecurity Concepts: An LSTM Approach. Appl. Sci. 2019, 9, 3945. [Google Scholar] [CrossRef]
- Soman, K.P.; Alazab, M. A Comprehensive Tutorial and Survey of Applications of Deep Learning for Cyber Security. 2020. Available online: https://www.techrxiv.org/articles/A_Comprehensive_Tutorial_and_Survey_of_Applications_of_Deep_Learning_for_Cyber_Security/11473377/1 (accessed on 5 February 2020).
- Joshi, A.; Lal, R.; Finin, T.; Joshi, A. Extracting cybersecurity related linked data from text. In Proceedings of the IEEE Seventh International Conference on Semantic Computing, Irvine, CA, USA, 16–18 September 2013; pp. 252–259. [Google Scholar]
- Fritzner, J.E.H. Automated Information Extraction in Natural Language. Master’s Thesis, Norwegian University of Science and Tehnology, Trondheim, Norway, 2017. [Google Scholar]
- NeCamp, T.; Sattigeri, P.; Wei, D.; Ray, E.; Drissi, Y.; Poddar, A.; Mahajan, D.; Bowden, S.; Han, B.A.; Mojsilovic, A.; et al. Data Science For Social Good; University of Chicago: Chicago, IL, USA, 2017; Available online: https://dssg.uchicago.edu/wp-content/uploads/2017/09/necamp.pdf (accessed on 12 November 2019).
- Tonin, L. Digitala Vetenskapliga Arkivet. 2017. Available online: http://www.diva-portal.org/smash/get/diva2:1087619/FULLTEXT01.pdf (accessed on 14 November 2019).
- PatriotFest. 2019. Available online: https://www.patriotfest.ro/ (accessed on 19 October 2019).
- IBM (International Business Machines). IBM Cloud. 2019. Available online: https://console.bluemix.net/catalog/services/knowledge-studio (accessed on 11 October 2019).
- International Business Machines Corporation. IBM Cloud. 2019. Available online: https://cloud.ibm.com/ (accessed on 8 October 2019).
- IBM (International Business Machines). IBM Cloud. 2019. Available online: https://console.bluemix.net/docs/services/discovery/index.html#about (accessed on 11 October 2019).
- Stanford University School of Medicine Stanford Center for Biomedical Informatics Research. Protégé. 2018. Available online: https://protege.stanford.edu/ (accessed on 16 November 2019).
- Postman, H.Q. Postman. 2019. Available online: https://www.getpostman.com/ (accessed on 17 November 2019).
- Ferrucci, D.; Brown, E.; Chu-Carroll, J.; Fan, J.; Gondek, D.; Kalyanpur, A.A.; Lally, A.; Murdock, J.W.; Nyberg, E.; Prager, J.; et al. The AI Magazine 110. 2010. Available online: http://www.aaai.org/Magazine/Watson/watson.php (accessed on 20 September 2019).
- Kapoor, S.; Zhou, B.; Kantor, A. IBM Developer. 2017. Available online: https://developer.ibm.com/tv/deep-dive-watson-neural-networks/ (accessed on 19 October 2019).
- MITRE Corporation. Common Vulnerabilities and Exposures. 2019. Available online: https://cve.mitre.org/ (accessed on 11 October 2019).
- IBM (International Business Machines). IBM Cloud. 2019. Available online: https://cloud.ibm.com/docs/services/knowledge-studio?topic=knowledge-studio-evaluate-ml (accessed on 11 October 2019).
- CoNLL. Shared Task Evaluation. 2018. Available online: https://universaldependencies.org/conll18/evaluation.html (accessed on 14 December 2019).
- The Stanford Natural Language Processing Group. 2018. Available online: https://nlp.stanford.edu/software/CRF-NER.shtml (accessed on 19 October 2019).
- Georgescu, T.M. Modelarea Bazată pe Volume Mari de Date. Securitate Cibernetică în Contextul Big Data (Eng. “Modelling Based on Large Volumes of Data. Cybersecurity in the Context of Big Data”). Ph.D. Thesis, The Bucharest University of Economic Studies, Bucharest, Romania, 2019. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. of Types of Relations | Names of Relations | No. of Relations | Parent Class | Child Class |
|---|---|---|---|---|
| 1 | attacks | 1 | Attacker | Account |
| 2 | Attacker | Software | ||
| 2 | data flow | 3 | Address | Networking |
| 4 | Networking | Address | ||
| 3 | exploits | 5 | Attacker | Vulnerability |
| 6 | Exploit | Vulnerability | ||
| 7 | Malware | Vulnerability | ||
| 8 | Offensive Means | Vulnerability | ||
| 4 | generates | 9 | Attack | Event |
| 10 | Attack | Impact | ||
| 11 | Exploit | Impact | ||
| 12 | Threat | Risk | ||
| 13 | Vulnerability | Risk | ||
| 5 | has | 14 | Host | Address |
| 15 | Software | Address | ||
| 16 | Software | Vulnerability | ||
| 6 | includes | 17 | Attack | Networking |
| 7 | involves | 18 | Attack | Malware |
| 19 | Attack | Offensive Means | ||
| 20 | Event | Loss | ||
| 21 | Impact | Loss | ||
| 22 | Risk | Loss | ||
| 23 | Vulnerability | Threat | ||
| 8 | logs in | 24 | Account | Software |
| 9 | performs | 25 | Attacker | Attack |
| 26 | Attacker | Exploit | ||
| 10 | protects | 27 | Defensive Means | Account |
| 28 | Defensive Means | Software | ||
| 11 | runs on | 29 | Software | Host |
| 12 | uses | 30 | Attacker | Malware |
| 31 | Attacker | Offensive Means | ||
| 32 | Software | Networking | ||
| 33 | User | Account |
| Relation Type | Parent Entity | Parent Class | Child Entity | Child Class |
|---|---|---|---|---|
| performs | Attacker | Attacker | Exploit | Exploit |
| performs | Attacker | Attacker | cause | Attack |
| performs | Attacker | Attacker | denial of service | Attack |
| generates | Exploit | Exploit | denial of service | Impact |
| generates | cause | Attack | denial of service | Impact |
| generates | denial of service | Attack | denial of service | Impact |
| Project | F1 Score for NER | Number of Classes | F1 Score for Relation Extraction | Number of Relations |
|---|---|---|---|---|
| Cybersecurity Analyzer | 0.81 | 18 | 0.58 | 33 |
| [18] | 0.8 | 10 | N/A | N/A |
| [8] | 0.68 | 17 | 0.46 | 30 |
| [19] | 0.67 | 4 | 0.55 | 2 |
| [20] | 0.49 | 5 | 0.19 | N/A |
| [21] | 0.73 | 5 | N/A | N/A |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Georgescu, T.-M. Natural Language Processing Model for Automatic Analysis of Cybersecurity-Related Documents. Symmetry 2020, 12, 354. https://doi.org/10.3390/sym12030354
Georgescu T-M. Natural Language Processing Model for Automatic Analysis of Cybersecurity-Related Documents. Symmetry. 2020; 12(3):354. https://doi.org/10.3390/sym12030354
Chicago/Turabian StyleGeorgescu, Tiberiu-Marian. 2020. "Natural Language Processing Model for Automatic Analysis of Cybersecurity-Related Documents" Symmetry 12, no. 3: 354. https://doi.org/10.3390/sym12030354
APA StyleGeorgescu, T.-M. (2020). Natural Language Processing Model for Automatic Analysis of Cybersecurity-Related Documents. Symmetry, 12(3), 354. https://doi.org/10.3390/sym12030354