Research on Information Fusion for Machine Potential Fault Operation and Maintenance


Abstract
:1. Introduction
2. Related Work
3. Information Fusion Based on D–S Evidence
3.1. D–S Evidence Theory
3.2. Lack of D–S Evidence Theory
3.3. Improved Evidence Theory
3.3.1. Weight of Evidence Reliability Based on Entropy
3.3.2. Weight of Evidence Consistency Based on Evidence Correlation Matrix
3.3.3. Reference Evidence Generation
3.3.4. Comprehensive Evidence Fusion Rule
4. Experiments
4.1. Reliability Weight Calculation
4.2. Consistency Weight Calculation
4.3. Reference Evidence Calculation
4.4. Comprehensive Evidence Fusion Generation
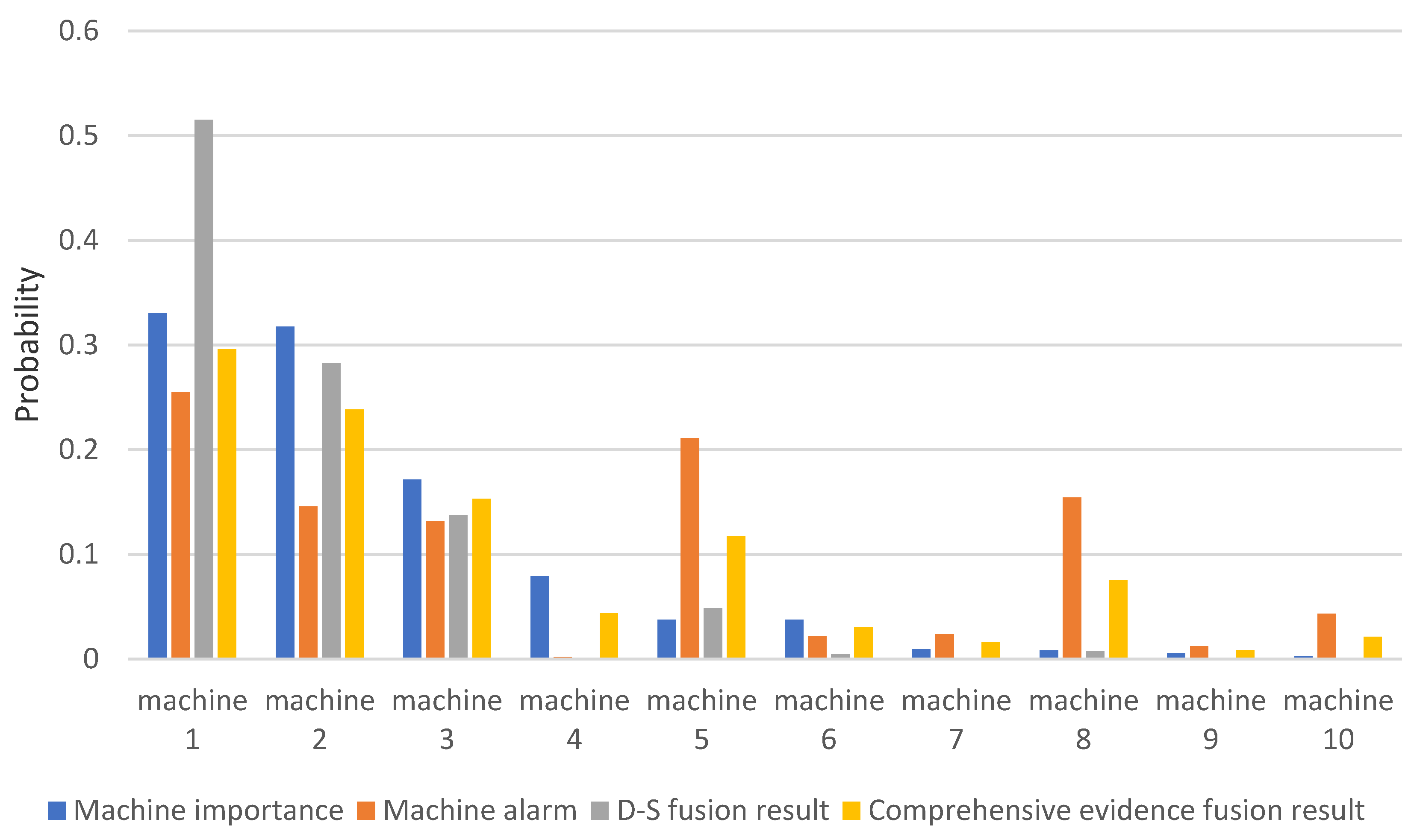
4.5. Results Analysis
5. Application and Verification
5.1. Problem Description
5.2. Establish Problem Identification Framework
5.3. Suspected Failure Probability Of Machines
5.4. Comparative Analysis
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mandroli, S.S.; Shrivastava, A.K.; Ding, Y. A survey of inspection strategy and sensor distribution studies in discrete-part manufacturing processes. IIE Trans. 2006, 38, 309–328. [Google Scholar] [CrossRef]
- Sun, S.; Lin, H.; Ma, J.; Li, X. Multi-sensor distributed fusion estimation with applications in networked systems: A review paper. Inf. Fusion 2017, 38, 122–134. [Google Scholar] [CrossRef]
- Kletti, J. (Ed.) Manufacturing Execution System-MES; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach; Pearson Education Limited: London, UK, 2016. [Google Scholar]
- Chen, M.; Mao, S.; Liu, Y. Big data: A survey. Mob. Netw. Appl. 2014, 19, 171–209. [Google Scholar] [CrossRef]
- Russom, P. Big data analytics. TDWI Best Practices Report Fourth Quarter 2011, 19, 1–34. [Google Scholar]
- Ackson, S.; Brownie, J. AI-based decision support tool for strategic decision making in the factory of the future. Comput. Integr. Manuf. Syst. 1992, 5, 83–90. [Google Scholar] [CrossRef]
- Kusiak, A.; Ahn, J. Intelligent scheduling of automated machining systems. Comput. Integr. Manuf. Syst. 1992, 5, 3–14. [Google Scholar] [CrossRef]
- Daǧli, C.H. Knowledge-based systems for cutting stock problems. Eur. Ournal Oper. Res. 1990, 44, 160–166. [Google Scholar] [CrossRef]
- Confalonieri, M.; Barni, A.; Valente, A.; Cinus, M.; Pedrazzoli, P. An AI based decision support system for preventive maintenance and production optimization in energy intensive manufacturing plants. In Proceedings of the 2015 IEEE International Conference on Engineering, Technology and Innovation/International Technology Management Conference (ICE/ITMC), Belfast, UK, 22–24 June 2015; pp. 1–8. [Google Scholar]
- Tang, Y.; Zhou, D.; Xu, S.; He, Z. A Weighted Belief Entropy-Based Uncertainty Measure for Multi-Sensor Data Fusion. Sensors 2017, 17, 928. [Google Scholar] [CrossRef] [Green Version]
- Box, G.E.; Tiao, G.C. Bayesian Inference in Statistical Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Takagi, H.; Hayashi, I. NN-driven fuzzy reasoning. Int. Ournal Approx. Reason. 1991, 5, 191–212. [Google Scholar] [CrossRef] [Green Version]
- Mizumoto, M.; Zimmermann, H. Comparison of fuzzy reasoning methods. Fuzzy Sets Syst. 1982, 8, 253–283. [Google Scholar] [CrossRef]
- Dempster, A.P. Upper and lower probabilities induced by a multivalued mapping. In Classic Works of the Dempster-Shafer Theory of Belief Functions; Springer: Berlin/Heidelberg, Germany, 2008; pp. 57–72. [Google Scholar]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976. [Google Scholar]
- Barnett, A. Computational methods for a mathematical theory of evidence. In Classic Works of the Dempster-Shafer Theory of Belief Functions; Springer: Berlin/Heidelberg, Germany, 2008; pp. 197–216. [Google Scholar]
- Carpenter, G.A.; Martens, S.; Ogas, O. Self-organizing information fusion and hierarchical knowledge discovery: a new framework using ARTMAP neural networks. Neural Netw. 2005, 18, 287–295. [Google Scholar] [CrossRef] [Green Version]
- Yuan, T.; Kuo, W. Spatial defect pattern recognition on semiconductor wafers using model-based clustering and Bayesian inference. Eur. Ournal Oper. Res. 2008, 190, 228–240. [Google Scholar] [CrossRef]
- Zheng, Y.; Qin, S.; Wang, F. PLS-based similarity analysis for mode identification in multimode manufacturing processes. Ifac-Pap. 2015, 48, 777–782. [Google Scholar] [CrossRef]
- Khakifirooz, M.; Chien, C.F.; Chen, Y. Bayesian inference for mining semiconductor manufacturing big data for yield enhancement and smart production to empower industry 4.0. Appl. Soft Comput. 2018, 68, 990–999. [Google Scholar] [CrossRef]
- Kozan, E.; Köksoy, O. A bayesian parameter estimation approach to response surface optimization in quality engineering. Sak. Üniversitesi Fen Bilimleri Enstitüsü Derg. 2019, 23, 767–774. [Google Scholar] [CrossRef]
- Aminzadeh, M.; Kurfess, T.R. Online quality inspection using Bayesian classification in powder-bed additive manufacturing from high-resolution visual camera images. Ournal Intell. Manuf. 2019, 30, 2505–2523. [Google Scholar] [CrossRef]
- Ji, W.; Li, Y.; AbouRizk, S.M. Integrated data-driven approach for analyzing pipe welding operator-quality performance. Autom. Constr. 2019, 106, 102814. [Google Scholar] [CrossRef]
- Lin, L.; Lin, C.L. The use of grey-fuzzy logic for the optimization of the manufacturing process. Ournal Mater. Process. Technol. 2005, 160, 9–14. [Google Scholar] [CrossRef]
- Scarpelli, H.; Gomide, F. Fuzzy reasoning and fuzzy Petri nets in manufacturing systems modeling. Ournal Intell. Fuzzy Syst. 1993, 1, 225–241. [Google Scholar] [CrossRef]
- Liu, N.M.; Horng, T.; Chiang, K.T. The method of grey-fuzzy logic for optimizing multi-response problems during the manufacturing process: a case study of the light guide plate printing process. Int. Ournal Adv. Manuf. Technol. 2009, 41, 200–210. [Google Scholar] [CrossRef]
- Zhou, X.; Peng, T. Application of multi-sensor fuzzy information fusion algorithm in industrial safety monitoring system. Saf. Sci. 2020, 122, 104531. [Google Scholar] [CrossRef]
- Seiti, H.; Hafezalkotob, A.; Martinez, L. R-sets, Comprehensive Fuzzy Sets Risk Modeling for Risk-based Information Fusion and Decision-making. IEEE Trans. Fuzzy Syst. 2019. [Google Scholar] [CrossRef]
- Yuqin, J.; Peixia, W.; Yue, L. Study of manufacturing system based on neural network multi-sensor data fusion and its application. In Proceedings of the IEEE International Conference on Robotics, Intelligent Systems and Signal Processing, Changsha, China, 8–13 October 2003; Volume 2, pp. 1022–1026. [Google Scholar]
- Goebel, K.; Badami, V.; Perera, A. Diagnostic information fusion for manufacturing processes. In Proceedings of the Second International Conference on Information Fusion, Sunnyvale, CA, USA; 1999; Volume 99, pp. 331–336. [Google Scholar]
- Chen, S.L.; Jen, Y.W. Data fusion neural network for tool condition monitoring in CNC milling machining. Int. J. Mach. Tools Manuf. 2000, 40, 381–400. [Google Scholar] [CrossRef]
- Li, Y.; Xiao, Z.; Zhen, X.; Cao, X. Attentional information fusion networks for cross-scene power line detection. Ieee Geosci. Remote Sens. Lett. 2019, 16, 1635–1639. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Z.; Ma, L.; Alsaadi, F.E. A partial-nodes-based information fusion approach to state estimation for discrete-time delayed stochastic complex networks. Inf. Fusion 2019, 49, 240–248. [Google Scholar] [CrossRef]
- Jian, X.; Li, W.; Guo, X.; Wang, R. Fault diagnosis of motor bearings based on a one-dimensional fusion neural network. Sensors 2019, 19, 122. [Google Scholar] [CrossRef] [Green Version]
- Yuan, K.; Xiao, F.; Fei, L.; Kang, B.; Deng, Y. Modeling Sensor Reliability in Fault Diagnosis Based on Evidence Theory. Sensors 2016, 16, 113. [Google Scholar] [CrossRef] [Green Version]
- Gong, Y.; Su, X.; Qian, H.; Yang, N. Research on fault diagnosis methods for the reactor coolant system of nuclear power plant based on DS evidence theory. Ann. Nucl. Energy 2018, 112, 395–399. [Google Scholar] [CrossRef]
- Qingdong, D.; Lingyu, X.; Hai, Z. DS evidence theory applied to fault diagnosis of generator based on embedded sensors. In Proceedings of the Third International Conference on Information Fusion, Paris, France, 10–13 July 2000; Volume 1. [Google Scholar]
- Ghorabaee, M.K.; Zavadskas, E.K.; Amiri, M.; Antucheviciene, J. A New Method of Assessment Based On Fuzzy Ranking and Aggregated Weights (Afraw) For Mcdm Problems Under Type-2 Fuzzy Environment. Econ. Comput. Econ. Cybern. Stud. Res. 2017, 50, 39–68. [Google Scholar]
- Wang, H.; Lin, D.; Qiu, J.; Ao, L.; Du, Z.; He, B. Research on multiobjective group decision-making in condition-based maintenance for transmission and transformation equipment based on DS evidence theory. IEEE Trans. Smart Grid 2015, 6, 1035–1045. [Google Scholar] [CrossRef]
- Zhang, Z. Data Fusion Optimization Analysis of Wireless Sensor Networks Based on oint DS Evidence Theory and Matrix Analysis. In Proceedings of the2019 4th International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Hohhot, China, 24–26 October 2019; pp. 689–6894. [Google Scholar]
- Shi, J.; Luo, L.; Fan, C. Research on Fusion Method of Fault Diagnosis Based on DBN and Correlation Model for Optimized DS Evidence Theory. In Proceedings of the 2019 Prognostics and System Health Management Conference (PHM-Paris), Paris, France, 2–5 May 2019; pp. 356–361. [Google Scholar]
- Jiang, S.; Lian, M.; Lu, C.; Ruan, S.; Wang, Z.; Chen, B. SVM-DS fusion based soft fault detection and diagnosis in solar water heaters. Energy Explor. Exploit. 2019, 37, 1125–1146. [Google Scholar] [CrossRef]
- Tang, X.; Gu, X.; Wang, J.; He, Q.; Zhang, F.; Lu, J. A Bearing Fault Diagnosis Method Based On Feature Selection Feedback Network and Improved DS Evidence Fusion. IEEE Access. 2020. [Google Scholar] [CrossRef]
- Su, X.; Mahadevan, S.; Xu, P.; Deng, Y. Handling of dependence in Dempster–Shafer theory. Int. Ournal Intell. Syst. 2015, 30, 441–467. [Google Scholar] [CrossRef]
- Zadeh, L.A. Review of A Mathematical Theory of Evidence. Ai Mag. 1984, 5, 235–247. [Google Scholar]
- Wehrl, A. General properties of entropy. Rev. Mod. Phys. 1978, 50, 221. [Google Scholar] [CrossRef]
- Gray, R.M. Entropy and Information Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Sun, Z.H.; Liu, R.; Ming, X. A Fault Diagnosis and Maintenance Decision System for Production Line Based on Human-machine Multi-Information Fusion. In Proceedings of the 2018 Artificial Intelligence and Cloud Computing Conference, Tokyo, Japan, 21–23 December 2018; pp. 151–156. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Fusion Methods | Advantage | Disadvantage | Main Application Scenarios |
|---|---|---|---|
| Bayesian inferences | Simple calculation rules and fast calculation speed. | This method should be based on the accurate prior probability. | |
| fuzzy reasoning | Information processing is closer to people’s thinking with strong explanatory ability. | There are a lot of subjective factors in design of reasoning rule and the standards are not unified. | |
| Neural network | High data utilization and high accuracy. | Poor interpretability and high computational complexity. | |
| D–S evidence | Suitable for the fusion of multi-source information with strong explanatory ability and flexible fusion mode. | The serious conflict between evidences is hard to resolve. |
| Witness 1 | Witness 2 | Fusion Result | |
|---|---|---|---|
| A | 0.99 | 0.00 | 0.00 |
| B | 0.01 | 0.01 | 1.00 |
| C | 0.00 | 0.99 | 0.00 |
| Witness 1 | Witness 2 | |
|---|---|---|
| A | 0.60 | 0.60 |
| B | 0.40 | 0.20 |
| C | 0.00 | 0.20 |
| Witness 1 | Witness 2 | Witness 3 | Witness 4 | D–S Fusion Result | |
|---|---|---|---|---|---|
| A | 0.90 | 0.95 | 0.95 | 0.00 | 0.00 |
| B | 0.09 | 0.04 | 0.03 | 0.03 | 0.63 |
| C | 0.01 | 0.01 | 0.02 | 0.97 | 0.37 |
| 0.1553 | 0.0971 | 0.1008 | 0.0585 |
| 0.2076 | 0.2547 | 0.2517 | 0.2860 |
| 0.2734 | 0.2538 | 0.4723 | 0.005 |
| Reference Evidence | |||
|---|---|---|---|
| 0.6680 | 0.0450 | 0.2870 | |
| 0.9362 | 0.0490 | 0.0148 | |
| 0.9381 | 0.0469 | 0.0150 |
| Evidence Fusion Result | |||
|---|---|---|---|
| 0.0000 | 0.6255 | 0.3745 | |
| 0.6680 | 0.0450 | 0.2870 | |
| 0.9362 | 0.0490 | 0.0148 | |
| 0.9381 | 0.0469 | 0.0150 |
| Order | Probability | Order | Probability |
|---|---|---|---|
| 0.3309 | 0.0376 | ||
| 0.3176 | 0.0092 | ||
| 0.1713 | 0.0083 | ||
| 0.0793 | 0.0054 | ||
| 0.0376 | 0.0027 |
| Order | Probability | Order | Probability |
|---|---|---|---|
| 0.2547 | 0.0217 | ||
| 0.1456 | 0.0235 | ||
| 0.1315 | 0.1543 | ||
| 0.0021 | 0.0122 | ||
| 0.2111 | 0.0433 |
| Order | Probability | Order | Probability |
|---|---|---|---|
| 0.2958 | 0.0303 | ||
| 0.2385 | 0.0158 | ||
| 0.1530 | 0.0755 | ||
| 0.0438 | 0.0085 | ||
| 0.1175 | 0.0214 |
| Order | Probability | Order | Probability |
|---|---|---|---|
| 0.5149 | 0.005 | ||
| 0.2826 | 0.001 | ||
| 0.1377 | 0.008 | ||
| 0.0010 | 0.000 | ||
| 0.0486 | 0.000 |
| Order | Comprehensive Evidence Fusion | Result From [49] | Normalization Result Form [49] |
|---|---|---|---|
| 0.3349 | 0.2890 | 0.3349 | |
| 0.2413 | 0.2083 | 0.2413 | |
| 0.1488 | 0.1285 | 0.1488 | |
| 0.0332 | 0.0286 | 0.0332 | |
| 0.1100 | 0.0950 | 0.1100 | |
| 0.0250 | 0.0216 | 0.0250 | |
| 0.0135 | 0.0116 | 0.0135 | |
| 0.0674 | 0.0582 | 0.0674 | |
| 0.0072 | 0.0062 | 0.0072 | |
| 0.0187 | 0.0162 | 0.0187 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, W.; Wan, Y.; Zuo, T.-Y.; Sha, X.-M. Research on Information Fusion for Machine Potential Fault Operation and Maintenance. Symmetry 2020, 12, 375. https://doi.org/10.3390/sym12030375
Xu W, Wan Y, Zuo T-Y, Sha X-M. Research on Information Fusion for Machine Potential Fault Operation and Maintenance. Symmetry. 2020; 12(3):375. https://doi.org/10.3390/sym12030375
Chicago/Turabian StyleXu, Wei, Yi Wan, Tian-Yu Zuo, and Xin-Mei Sha. 2020. "Research on Information Fusion for Machine Potential Fault Operation and Maintenance" Symmetry 12, no. 3: 375. https://doi.org/10.3390/sym12030375