Generative Adversarial Network-Based Super-Resolution Considering Quantitative and Perceptual Quality


Abstract
1. Introduction
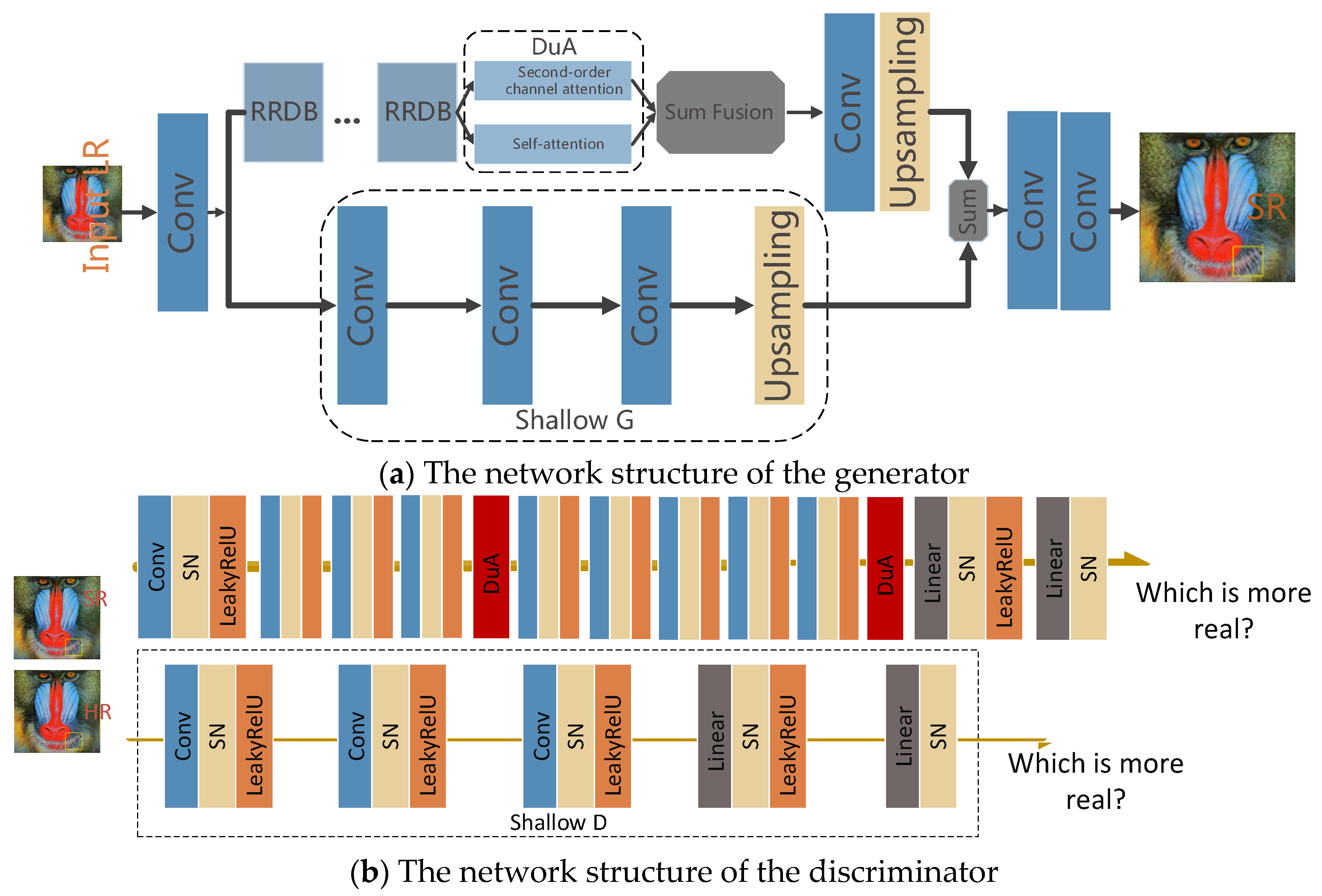
- To make full use of the original low-resolution images, we should not only narrow the gap between SR and HR at high-levels but also narrow the gap between low-levels. A shallow generator and a shallow discriminator are added to obtain a closer picture of the original real image.
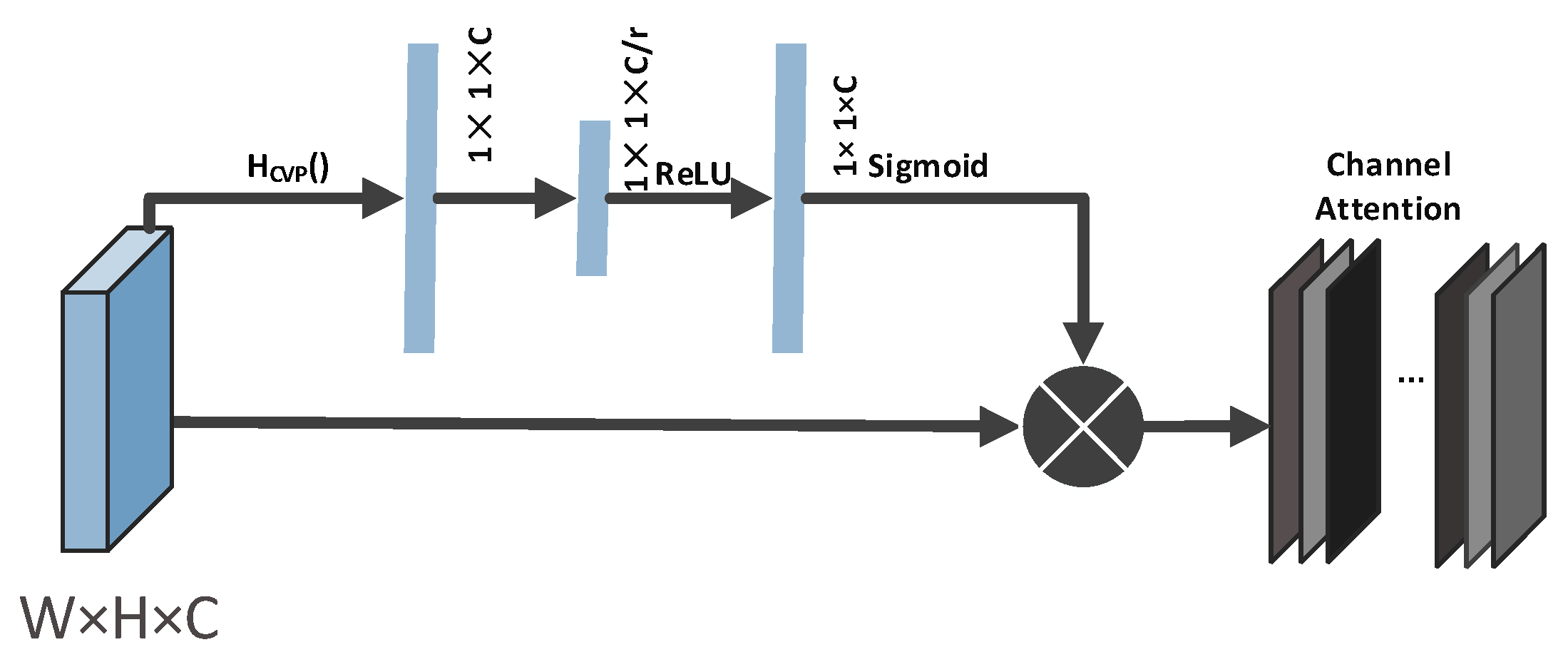
- Considering the dependencies between feature maps, we introduce a second-order channel attention mechanism and self-attention mechanism on the generator and the discriminator, so that the network focuses on more informative parts and improves the network’s expressive ability and discriminative ability, which more accurately restrain pictures generated by the generation network.
- For perceptual loss, we introduce covariance normalization in the feature extraction layer so that the perceptual loss can improve the perceptual quality of SR pictures from higher-order statistical features for more discriminative representations.
- We improve the perceptual quality of the image while considering the distortion of the image, making the generated SR image more suitable for human visual perception.
2. Related Work
2.1. Network Structure
2.2. Loss Function
2.3. Attention Mechanism
3. Methods
3.1. Generator
3.2. Discriminator
3.3. Perceptual Loss
3.4. Attention Mechanism
3.4.1. Channel Attention Mechanism
3.4.2. Self-Attention
4. Experience
4.1. Data
4.2. Evaluation Methods
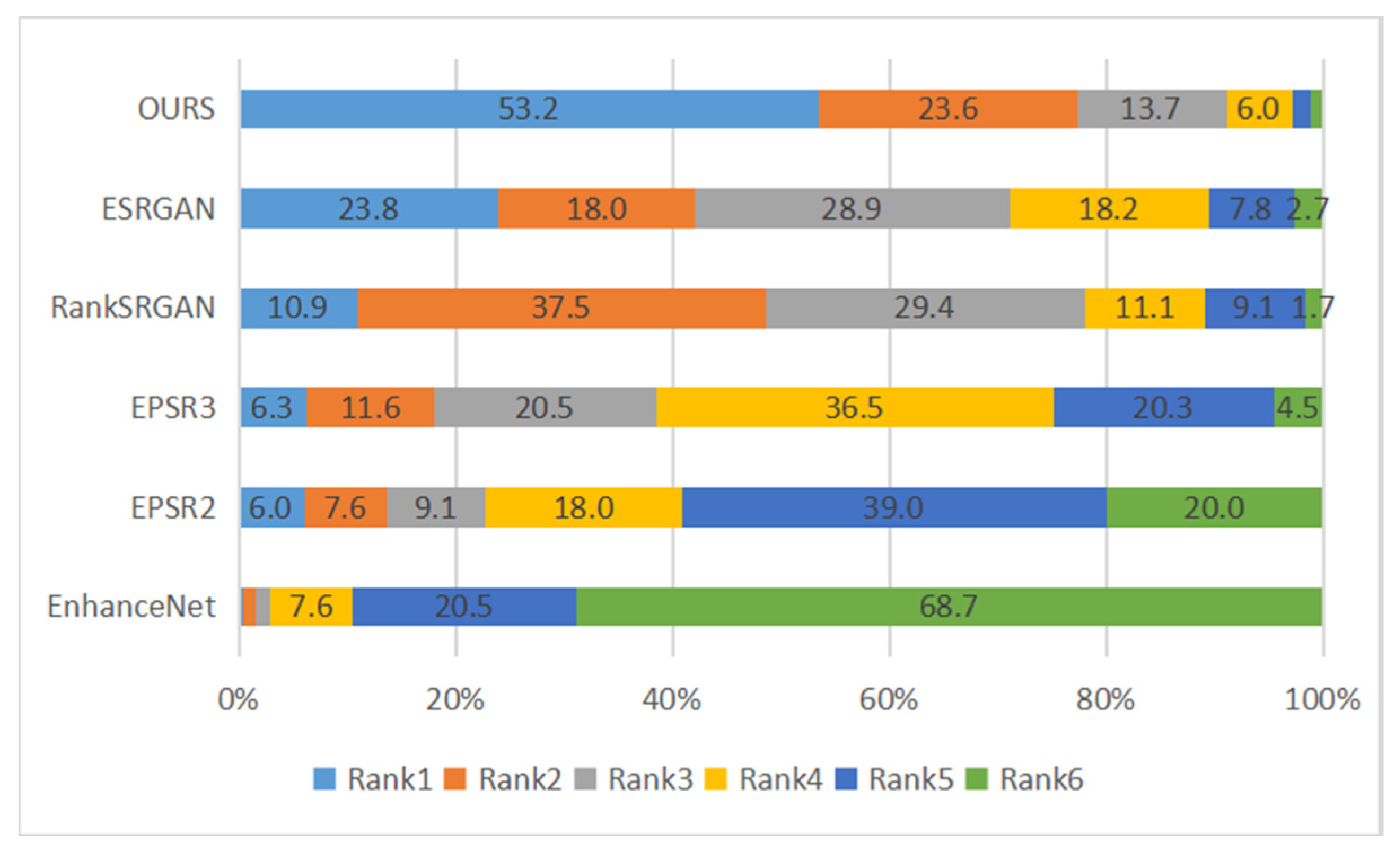
4.3. Experimental Results
4.4. Ablation Eeperiences
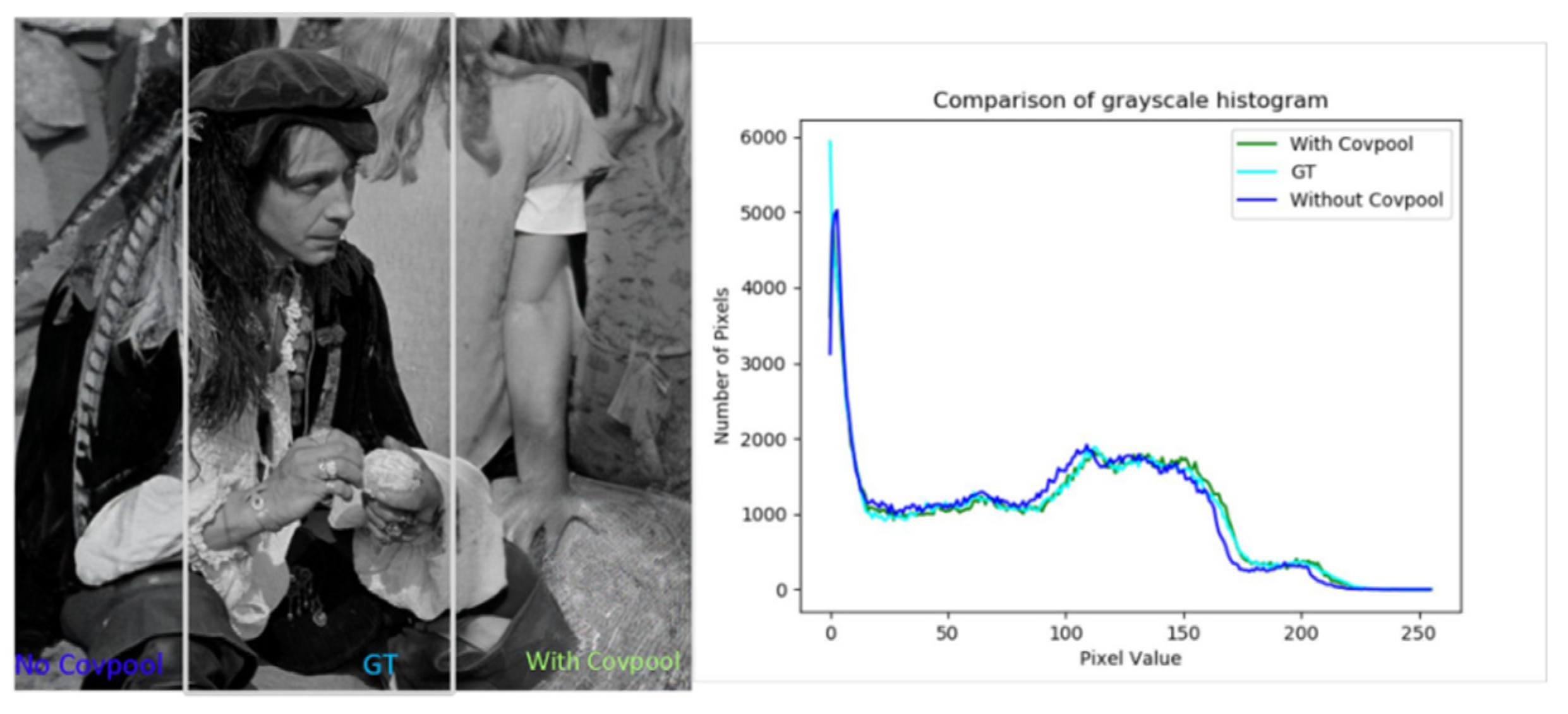
4.4.1. Covariance Normalization (COVNORM)
4.4.2. DUA Only in THE Generator
4.4.3. DUA in G and D
4.4.4. Shallow G
4.4.5. Shallow D
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Lai, W.; Huang, J.; Ahuja, N.; Yang, M. Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks. IEEE Trans. 2019, 41, 2599–2613. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-Recursive Convolutional Network for Image Super-Resolution. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image Super-Resolution Using Dense Skip Connections. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4809–4817. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. MemNet: A Persistent Memory Network for Image Restoration. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4549–4557. [Google Scholar]
- Chao, D.; Chen, C.L.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 184–199. [Google Scholar]
- Kim, J.; Lee, J. Deep Residual Network with Enhanced Upscaling Module for Super-Resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 913–9138. [Google Scholar]
- Choi, J.H.; Kim, J.H.; Cheon, M.; Lee, J.S. Deep learning-based image super-resolution considering quantitative and perceptual quality. arXiv 2018, arXiv:1809.04789. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Shi, W. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar]
- Luo, X.; Chen, R.; Xie, Y.; Qu, Y.; Li, C. Bi-GANs-ST for Perceptual Image Super-Resolution. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2019; pp. 20–34. [Google Scholar]
- Mechrez, R.; Talmi, I.; Shama, F.; Zelnik-Manor, L. Learning to Maintain Natural Image Statistics. arXiv 2018, arXiv:1803.04626. [Google Scholar]
- Wang, X.; Yu, K.; Dong, C.; Loy, C.C. Recovering Realistic Texture in Image Super-Resolution by Deep Spatial Feature Transform. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 606–615. [Google Scholar]
- Vasu, S.; Madam, N.T.; Rajagopalan, A.N. Analyzing Perception-Distortion Tradeoff Using Enhanced Perceptual Super-Resolution Network. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2019; pp. 114–131. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Change Loy, C. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2019; pp. 63–79. [Google Scholar]
- Zhang, W.; Liu, Y.; Dong, C.; Qiao, Y. RankSRGAN: Generative Adversarial Networks with Ranker for Image Super-Resolution. In Proceedings of the IEEE International Conference on Computer Vision; IEEE: Piscataway, NJ, USA, 2019; pp. 3096–3105. [Google Scholar]
- Blau, Y.; Michaeli, T. The Perception-Distortion Tradeoff. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6228–6237. [Google Scholar]
- Michelini, P.N.; Zhu, D.; Liu, H. Multi–scale Recursive and Perception–Distortion Controllable Image Super–Resolution. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2019; pp. 3–19. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Super-Resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Pan, J.; Liu, S.; Sun, D.; Zhang, J.; Liu, Y.; Ren, J.; Yang, M.H. Learning Dual Convolutional Neural Networks for Low-Level Vision. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3070–3079. [Google Scholar]
- Pan, J.; Liu, Y.; Dong, J.; Zhang, J.; Ren, J.; Tang, J.; Yang, M.H. Physics-Based Generative Adversarial Models for Image Restoration and Beyond. arXiv 2018, arXiv:1808.00605v1. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2018; pp. 294–310. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.; Zhang, L. Second-Order Attention Network for Single Image Super-Resolution. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 11057–11066. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar]
- Mechrez, R.; Talmi, I.; Zelnik-Manor, L. The Contextual Loss for Image Transformation with Non-Aligned Data. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2018; pp. 768–783. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Vu, T.; Luu, T.M.; Yoo, C.D. Perception-Enhanced Image Super-Resolution via Relativistic Generative Adversarial Networks. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2019; pp. 98–113. [Google Scholar]
- Li, P.; Xie, J.; Wang, Q.; Zuo, W. Is Second-Order Information Helpful for Large-Scale Visual Recognition? In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2089–2097. [Google Scholar]
- Li, P.; Xie, J.; Wang, Q.; Gao, Z. Towards Faster Training of Global Covariance Pooling Networks by Iterative Matrix Square Root Normalization. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 947–955. [Google Scholar]
- Blau, Y.; Mechrez, R.; Timofte, R.; Michaeli, T.; Zelnik-Manor, L. The 2018 PIRM Challenge on Perceptual Image Super-Resolution. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2018; pp. 334–355. [Google Scholar]
- Wang, D.; Wang, L. On OCT Image Classification via Deep Learning. IEEE Photonics J. 2019, 11, 1–14. [Google Scholar] [CrossRef]
- Cheng, S.; Wang, L.; Du, A. Histopathological Image Retrieval Based on Asymmetric Residual Hash and DNA Coding. IEEE Access 2019, 7, 101388–101400. [Google Scholar] [CrossRef]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar]
- Wang, Y.; Wang, L.; Wang, H.; Li, P. End-to-End Image Super-Resolution via Deep and Shallow Convolutional Networks. IEEE Access 2019, 7, 31959–31970. [Google Scholar] [CrossRef]
- Soh, J.W.; Park, G.Y.; Jo, J.; Cho, N.I. Natural and Realistic Single Image Super-Resolution with Explicit Natural Manifold Discrimination. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 8114–8123. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral Normalization for Generative Adversarial Networks. arXiv 2018, arXiv:1802.05957v1. [Google Scholar]
- Zhang, H.; Goodfellow, I. Self-Attention Generative Adversarial Networks. arXiv 2018, arXiv:1805.08318v2. [Google Scholar]
- Liu, D.; Wen, B.; Fan, Y.; Loy, C.C.; Huang, T.S. Non-local recurrent network for image Restoration. In Neural Information Processing Systems (NIPS); MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “Completely Blind” Image Quality Analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-Reference Image Quality Assessment in the Spatial Domain. IEEE Trans. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Gondal, M.W.; Schölkopf, B.; Hirsch, M. The Unreasonable Effectiveness of Texture Transfer for Single Image Super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 80–97. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Sajjadi, M.S.M.; Schölkopf, B.; Hirsch, M. EnhanceNet: Single Image Super-Resolution through Automated Texture Synthesis. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4501–4510. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PI/RMSE | Set5 | Set14 | BSDS100 | PIRM_val |
|---|---|---|---|---|
| EnhanceNet | 2.926/10.088 | 3.018/18.068 | 2.908/17.515 | 2.688/15.985 |
| SRGAN | 3.355/9.313 | 2.882/17.432 | 2.531/17.138 | -- |
| EUSR | 4.904/7.596 | 3.094/15.834 | 2.683/15.049 | 2.353/12.579 |
| EPSR2 | 4.112/7.446 | 3.025/15.626 | 2.746/14.569 | 2.388/12.409 |
| EPSR3 | 3.257/8.930 | 2.698/17.074 | 2.199/16.782 | 2.069/15.359 |
| CX | 3.295/9.583 | 2.759/17.441 | 2.250/18.781 | 2.131/15.248 |
| RankSRGAN | 3.083/8.702 | 2.615/17.143 | 2.131/16.500 | 2.021/14.993 |
| ESRGAN | 3.320/8.219 | 2.926/18.161 | 2.337/17.093 | 2.299/15.569 |
| ours | 3.176/7.883 | 2.813/16.728 | 2.326/16.375 | 2.211/14.115 |
| PSNR/SSIM | SET5 | SET14 | BSDS100 | PIRM_val |
|---|---|---|---|---|
| EnhanceNet | 28.573/0.81 | 24.967/0.651 | 24.368/0.614 | 25.069/0.646 |
| SRGAN | 29.426/0.836 | 25.186/0.665 | 24.569/0.625 | -- |
| EUSR | 31.045/0.863 | 26.416/0.705 | 25.651/0.669 | 27.265/0.728 |
| EPSR2 | 31.240/0.865 | 26.552/0.709 | 25.896/0.667 | 27.350/0.728 |
| EPSR3 | 29.586/0.841 | 25.452/0.681 | 24.726/0.636 | 25.459/0.666 |
| CX | 29.116/0.832 | 25.148/0.671 | 24.039/0.629 | 25.410/0.675 |
| RankSRGAN | 29.796/0.839 | 26.484/0.703 | 25.505/0.649 | 25.622/0.659 |
| ESRGAN | 30.318/0.871 | 26.406/0.722 | 24.479/0.677 | 25.577/0.696 |
| ours | 30.586/0.862 | 27.024/0.742 | 25.896/0.693 | 26.224/0.712 |
| LPIPS | SET5 | SET14 | BSDS100 | PIRM_val |
|---|---|---|---|---|
| EnhanceNet | 0.102 | 0.168 | 0.209 | 0.167 |
| SRGAN | 0.084 | 0.154 | 0.189 | -- |
| EUSR | 0.081 | 0.155 | 0.194 | 0.146 |
| EPSR2 | 0.078 | 0.161 | 0.198 | 0.143 |
| EPSR3 | 0.089 | 0.163 | 0.200 | 0.187 |
| CX | 0.081 | 0.152 | 0.190 | 0.145 |
| RankSRGAN | 0.072 | 0.143 | 0.176 | 0.139 |
| ESRGAN | 0.067 | 0.151 | 0.166 | 0.132 |
| ours | 0.066 | 0.134 | 0.163 | 0.126 |
| BSDS100 | ESRGAN | CovNorm | DUA in G | DUA in G and D | Shallow G | Shallow G and D |
|---|---|---|---|---|---|---|
| PSNR/SSIM | 25.402/0.683 | 25.943/0.703 | 26.147/0.708 | 26.176/0.711 | 26.184/0.711 | 26.224/0.712 |
| PI/RMSE | 2.184/15.484 | 2.147/14.566 | 2.078/14.211 | 2.086/14.110 | 2.103/14.099 | 2.116/14.023 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Wang, L.; Cheng, S.; Ao, N. Generative Adversarial Network-Based Super-Resolution Considering Quantitative and Perceptual Quality. Symmetry 2020, 12, 449. https://doi.org/10.3390/sym12030449
Li C, Wang L, Cheng S, Ao N. Generative Adversarial Network-Based Super-Resolution Considering Quantitative and Perceptual Quality. Symmetry. 2020; 12(3):449. https://doi.org/10.3390/sym12030449
Chicago/Turabian StyleLi, Can, Liejun Wang, Shuli Cheng, and Naixiang Ao. 2020. "Generative Adversarial Network-Based Super-Resolution Considering Quantitative and Perceptual Quality" Symmetry 12, no. 3: 449. https://doi.org/10.3390/sym12030449
APA StyleLi, C., Wang, L., Cheng, S., & Ao, N. (2020). Generative Adversarial Network-Based Super-Resolution Considering Quantitative and Perceptual Quality. Symmetry, 12(3), 449. https://doi.org/10.3390/sym12030449