Transmission Line Obstacle Detection Based on Structural Constraint and Feature Fusion


Abstract
:1. Introduction
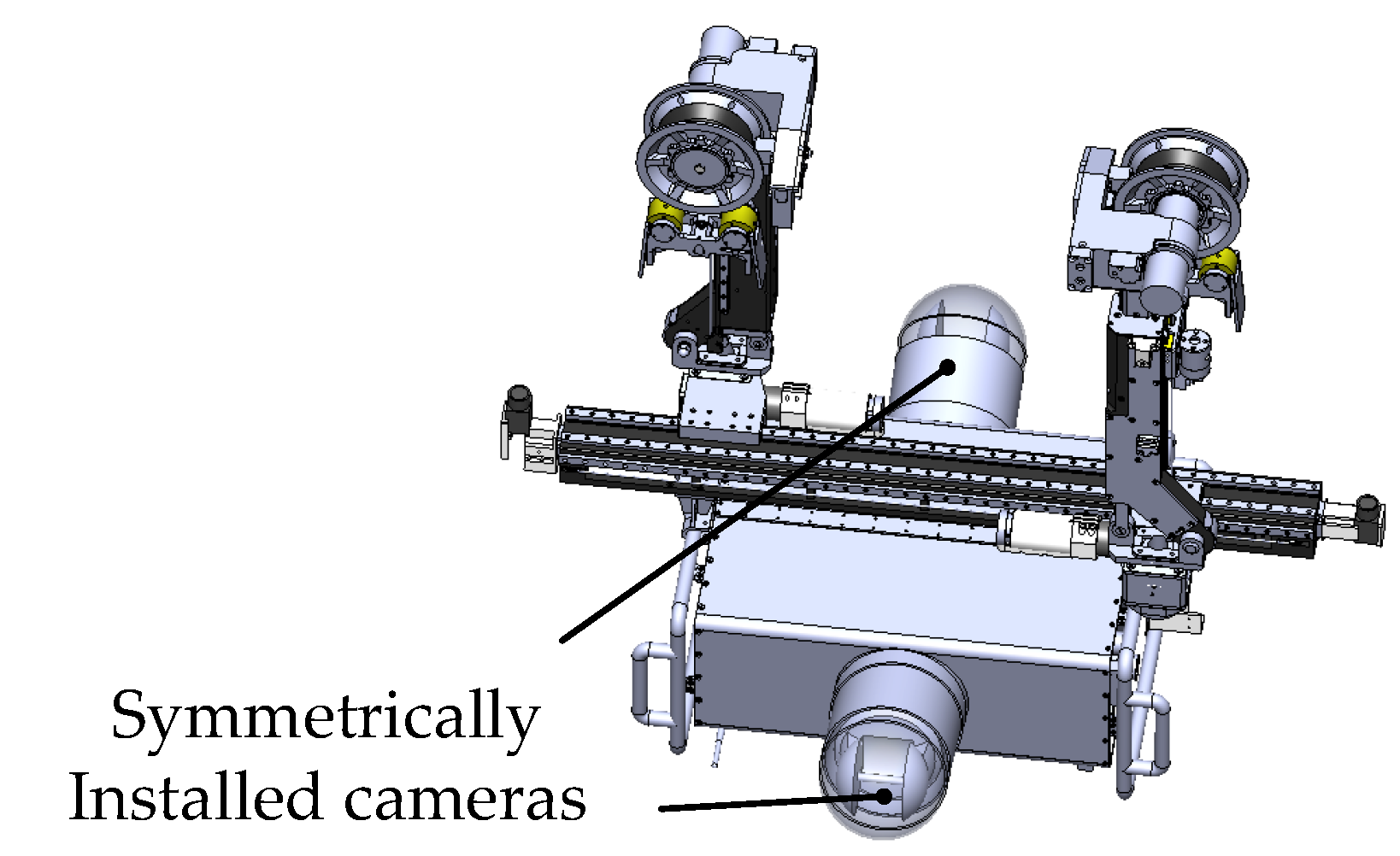
2. Visual Obstacle Detection Method
2.1. Region Proposal of Obstacles
2.1.1. Ground Wire Detection
2.1.2. Obstacle Region Proposal based on Structural Constraints
2.2. Obstacle Recognition
2.2.1. Feature Extraction
2.2.2. Fusion of Local and Global Features
2.2.3. Support Vector Machine Classification and Particle Swarm Optimization
2.2.4. Obstacle Classification based on PSO-SVM
3. Experiment Results and Analysis
3.1. Database
3.2. Obstacle Recogition
3.2.1. Influence of ORB Feature Dimension k on Obstacle Recognition
3.2.2. Influence of Feature Fusion Parameters on Obstacle Recognition
3.2.3. Comparison with Other Methods
3.3. Comprehensive Evaluation of Obstacle Detection
3.3.1. Parameter Settings
3.3.2. Visual Effect Analysis
3.3.3. Quantitative Analysis
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pouliot, N.; Montambault, S. Field-oriented developments for LineScout Technology and its deployment on large water crossing transmission lines. J. Field Robot. 2012, 29, 25–46. [Google Scholar] [CrossRef]
- Debenest, P.; Guarnieri, M. Expliner—From prototype towards a practical robot for inspection of high-voltage lines. In Proceedings of the 1st International Conference on Applied Robotics for the Power Industry, Montreal, QC, Canada, 5–7 October 2010; pp. 1–6. [Google Scholar]
- Wang, H.G.; Jiang, Y.; Liu, A.; Fang, L.; Ling, L. Research of power transmission line maintenance robots in SIACAS. In Proceedings of the 1st International Conference on Applied Robotics for the Power Industry, Montreal, QC, Canada, 5–7 October 2010; pp. 1–7. [Google Scholar]
- Wang, W.; Wu, G.P.; Bai, Y.C.; Xiao, H. Hand-eye-vision based control for an inspection robot’s autonomous line grasping. J. Cent. South Univ. 2014, 21, 2216–2227. [Google Scholar] [CrossRef]
- Song, Y.F.; Wang, H.G.; Zhang, J.W. A vision-based broken strand detection method for a power-line maintenance robot. IEEE Trans. Power Deliv. 2014, 29, 2154–2161. [Google Scholar] [CrossRef]
- Ye, X.; Wu, G.P.; Huang, L.; Fan, F.; Zhang, Y. Image Enhancement for Inspection of Cable Images Based on Retinex Theory and Fuzzy Enhancement Method in Wavelet Domain. Symmetry 2018, 10, 570. [Google Scholar] [CrossRef] [Green Version]
- Ye, X.; Wu, G.P.; Fei, F.; Peng, X.Y.; Wang, K. Overhead ground wire detection by fusion global and local features and supervised learning method for a cable inspection robot. Sens. Rev. 2018, 38, 376–386. [Google Scholar] [CrossRef] [Green Version]
- Cheng, Z.W.; Xiao, H.; Wu, G.P. Electromagnetic sensor navigation system of robot for high-voltage transmission line inspection. Transducer Microsyst. Technol. 2006, 39, 33–35. [Google Scholar]
- Cao, H.; Wu, G.P.; Zheng, T.; Yan, Y. Obstacle detection and locating method of an autonomous inspection robot on high voltage transmission line. Eng. J. Wuhan Univ. 2012, 45, 229–234. [Google Scholar]
- Pouliot, N.; Richard, P.; Montambault, S. LineScout power line robot: Characterization of a UTM-30LX LIDAR system for obstacle detection. IEEE/RSJ Int. Conf. Intell. Robot. Syst. 2012, 4327–4334. [Google Scholar]
- Richard, P.L.; Pouliot, N.; Montambault, S. Introduction of a LIDAR-based obstacle detection system on the LineScout power line robot. J. Endourol. 2014, 28, 330–334. [Google Scholar]
- Li, Q.M.; Zhang, Y.C.; Li, J.C. Visual navigation for power transmission line inspection robot. Comput. Eng. Appl. 2007, 43, 221–224+248. [Google Scholar]
- Zhang, Y.C.; Liang, Z.Z.; Fu, S.Y.; Tan, M.; Wu, G.P. Structure-constrained Obstacle Recognition for Transmission line Inspection Robot. ROBOT 2007, 1, 1–6. [Google Scholar]
- Hu, C.S.; Wu, G.P.; Cao, H.; Jiang, G.W. Research of Obstacle Recognition Based on Vision for High Voltage Transmission Line Inspection Robot. Chin. J. Sens. Actuators 2008, 21, 2092–2096. [Google Scholar]
- Tan, L.; Wang, Y.N.; Sheng, C.S. Vision based obstacle detection and recognition algorithm for transmission line deicing robot. Chin. J. Sci. Instrum. 2011, 32, 2564–2571. [Google Scholar]
- Li, Z.H.; Wang, H.G.; Wang, Y.C. Path planning for power transmission line inspection robot based on visual obstacle detection. IEEE Int. Conf. Robot. Biomim. 2013, 158–163. [Google Scholar]
- Miu, S.Y.; Sun, W.; Zhang, H.X. Intelligent Visual Method Based on complex Moments for Obstacle Recognition of High Voltage Transmission Line Deicer Robot. ROBOT 2010, 3, 425–431. [Google Scholar] [CrossRef]
- Cao, W.M.; Wang, Y.N.; Ying, F.; Wu, X.R.; Miu, S.Y. Research on obstacle recognition based on vision for deicing robot on high voltage transmission line. Chin. J. Sci. Instrum. 2011, 9, 2049–2056. [Google Scholar]
- Cao, W.M.; Wang, Y.N.; Wen, Y.M. Research on Obstacle Recognition Based on Wavelet Moments and SVM for Deicing Robot on High Voltage Transmission Line. J. Hunan Univ. (Nat. Sci.) 2012, 9, 33–38. [Google Scholar]
- Tang, H.W.; Sun, W.; Zhang, W.Y.; Miu, S.Y.; Yang, Y. Wavelet Neural Network Method Based on Particle Swarm Optimization for Obstacle Recognition of Power Line Deicing Robot. J. Mech. Eng. 2017, 53, 55–63. [Google Scholar] [CrossRef]
- Sheng, C.S. The Research on Obstacle Recognition Method for High Voltage Transmission Line De-Icing Robot. Master’s Thesis, Hunan University, Hunan, China, 25 April 2011. [Google Scholar]
- Wang, Y.P. Research and Application on Svm-Based Obstacle Recognition for High-Voltage Power Line Inspection Robot. Master’s Thesis, ChongQing University, Chong Qing, China, 2015. [Google Scholar]
- Cheng, L.; Wu, G.P. Obstacles detection and depth estimation from monocular vision for inspection robot of high voltage transmission line. Clust. Comput. 2019, 22, 2611–2627. [Google Scholar] [CrossRef]
- Li, A. Research of Detection and Recognition of Obstacles on Transmission Lines. Master’s Thesis, Hunan University, Hunan, China, 20 April 2016. [Google Scholar]
- Akinlar, C.; Topal, C. EDLines: A real-time line segment detector with a false detection control. Pattern Recognit. Lett. 2011, 32, 1633–1642. [Google Scholar] [CrossRef]
- Zitnick, C.L.; Dollár, P. Edge Boxes: Locating Object Proposals from Edges. In Lecture Notes in Computer Science, Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 391–405. [Google Scholar]
- Topal, C.; Akinlar, C. Edge Drawing: A combined real-time edge and segment detector. J. Vis. Commun. Image Represent. 2012, 23, 862–872. [Google Scholar] [CrossRef]
- Žunić, J.; Hirota Rosin, K.P.L. A Hu moment invariant as a shape circularity measure. Pattern Recognit. 2010, 43, 47–57. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E.; Yuan, Q.Q.; Masters, B.R. Digital Image Processing, 3rd ed.; Electronic Industry Press: Beijing, China, 2017; pp. 331–333. [Google Scholar]
- Zhao, L.J.; Tang, P.; Huo, L.Z.; Zheng, K. A review of visual word packet model in image scene classification. J. Image Graph. 2014, 19, 333–343. [Google Scholar]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef] [Green Version]
- Zhenhui, L.; Hongguang, W.; Yuechao, W. Line-grasping control for a power transmission line inspection robot. J. Jilin Univ. (Eng. Technol. Ed.) 2015, 45, 1519–1526. [Google Scholar]
- Yuan, L.; Chen, F.; Zhou, L.; Hu, D. Improve scene classification by using feature and kernel combination. Neurocomputing 2015, 17, 213–220. [Google Scholar] [CrossRef]
- Premebida, C.; Ludwig, O.; Nunes, U. LIDAR and vision-based pedestrian detection system. J. Field Robot. 2009, 26, 696–711. [Google Scholar] [CrossRef]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: a local SVM approach. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR), Cambridge, UK, 26 August 2004; Volume 3, pp. 32–36. [Google Scholar]
- Shi, Y.; Eberhart, R. A Modified Particle Swarm Optimizer. In Proceedings of the IEEE ICEC Conference, Anchorage, AK, USA, 4–9 May 1998; pp. 69–73. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 389–396. [Google Scholar] [CrossRef]
- Hu, X.; Eberhart, R.C.; Shi, Y. Swarm Intelligence for Permutation Optimization: Case Study of n-Queens Problem. In Proceedings of the IEEE Swarm Intelligence Symposium, Indianapolis, IN, USA, 26 April 2003; pp. 243–246. [Google Scholar]
- Blum, C.X. Swarm Intelligence in Optimization. In Swarm Intelligence; Springer: Berlin/Heidelberg, Germany, 2008; pp. 43–45. [Google Scholar]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A Database and Web-Based Tool for Image Annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Mandel, J.S.; Bond, J.H.; Bradley, M.; Snover, D.C.; Church, T.R.; Williams, S.; Watt, G.; Schuman, L.M.; Ederer, F.; Gilbertsen, F. Sensitivity, specificity, and positive predictivity of the Hemoccult test in screening for colorectal cancers: The University of Minnesota’s Colon Cancer Control Study. Gastroenterology 1989, 97, 597–600. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Total | Obstacle Group | Damper | Suspension Clamp |
|---|---|---|---|---|
| Number | 1000 | 653 | 1810 | 525 |
| Type | Obstacle Group | Damper | Suspension Clamp | Background |
|---|---|---|---|---|
| Number | 1300 | 2000 | 1500 | 3000 |
| Parameter | Value |
|---|---|
| Particle swarm size n | 30 |
| Maximum number of iterations G | 50 |
| Inertial factor [wmin,wmax] | [0.4,0.9] |
| Methods | Detection Accuracy (%) | |||
|---|---|---|---|---|
| Damper | Obstacle Group | Suspension Clamp | Background | |
| Wavelet moment + SVM | 75.3 | 72.4 | 70.0 | 85.7 |
| Joint invariant moment + Wavelet neural network | 80.5 | 78.2 | 75.3 | 84.1 |
| Wavelet moment + Wavelet neural network | 78.2 | 79.3 | 76.0 | 85.0 |
| Proposed method | 86.2 | 83.6 | 83.1 | 85.3 |
| CNN | 80.3 | 75.2 | 76.4 | 82.4 |
| Type | Name | Value |
|---|---|---|
| Region Proposal | Overlap rate α | 0.65 |
| Overlap rate thr β | 0.75 | |
| Threshold thr | 0.5,0.7 | |
| Feature fusion | Clustering center dimension k | 50 |
| Fusion parameter γ | 0.4 |
| Database | A1 (Short Distance) | A2 (Long Distance) | ||
|---|---|---|---|---|
| Threshold | thr=0.5 | thr=0.7 | thr=0.5 | thr=0.7 |
| Obstacle group | 80.2% | 75.1% | 90.5% | 83.6% |
| damper | 74.3% | 72.3% | 96.4% | 89.4% |
| Suspension clamp | 76.8% | 70.8% | 92.6% | 87.5% |
| Stage | Line Extraction | Bounding Box Extraction | Obstacle Recognition | Total |
|---|---|---|---|---|
| Time (ms) | 5.5 | 100 | 15.2 | 120.7 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, X.; Wang, D.; Zhang, D.; Hu, X. Transmission Line Obstacle Detection Based on Structural Constraint and Feature Fusion. Symmetry 2020, 12, 452. https://doi.org/10.3390/sym12030452
Ye X, Wang D, Zhang D, Hu X. Transmission Line Obstacle Detection Based on Structural Constraint and Feature Fusion. Symmetry. 2020; 12(3):452. https://doi.org/10.3390/sym12030452
Chicago/Turabian StyleYe, Xuhui, Dong Wang, Daode Zhang, and Xinyu Hu. 2020. "Transmission Line Obstacle Detection Based on Structural Constraint and Feature Fusion" Symmetry 12, no. 3: 452. https://doi.org/10.3390/sym12030452