Metric Factorization with Item Cooccurrence for Recommendation

Abstract
:1. Introduction
2. Related Works
2.1. Matrix Factorization
2.2. Item Embedding
3. Metric Factorization with Item Cooccurrence (MFIC) Model
3.1. Factorized Metric Learning (FML )Model
3.2. Word Embedding
3.3. MFIC Model
3.4. Evaluation for Rating Prediction
3.5. Evaluation for Ranking Prediction
3.6. Optimization and Prediction
4. Experimental Evaluation
4.1. Preparation for the Rating Prediction Experiments and Presentation of the Experimental Result
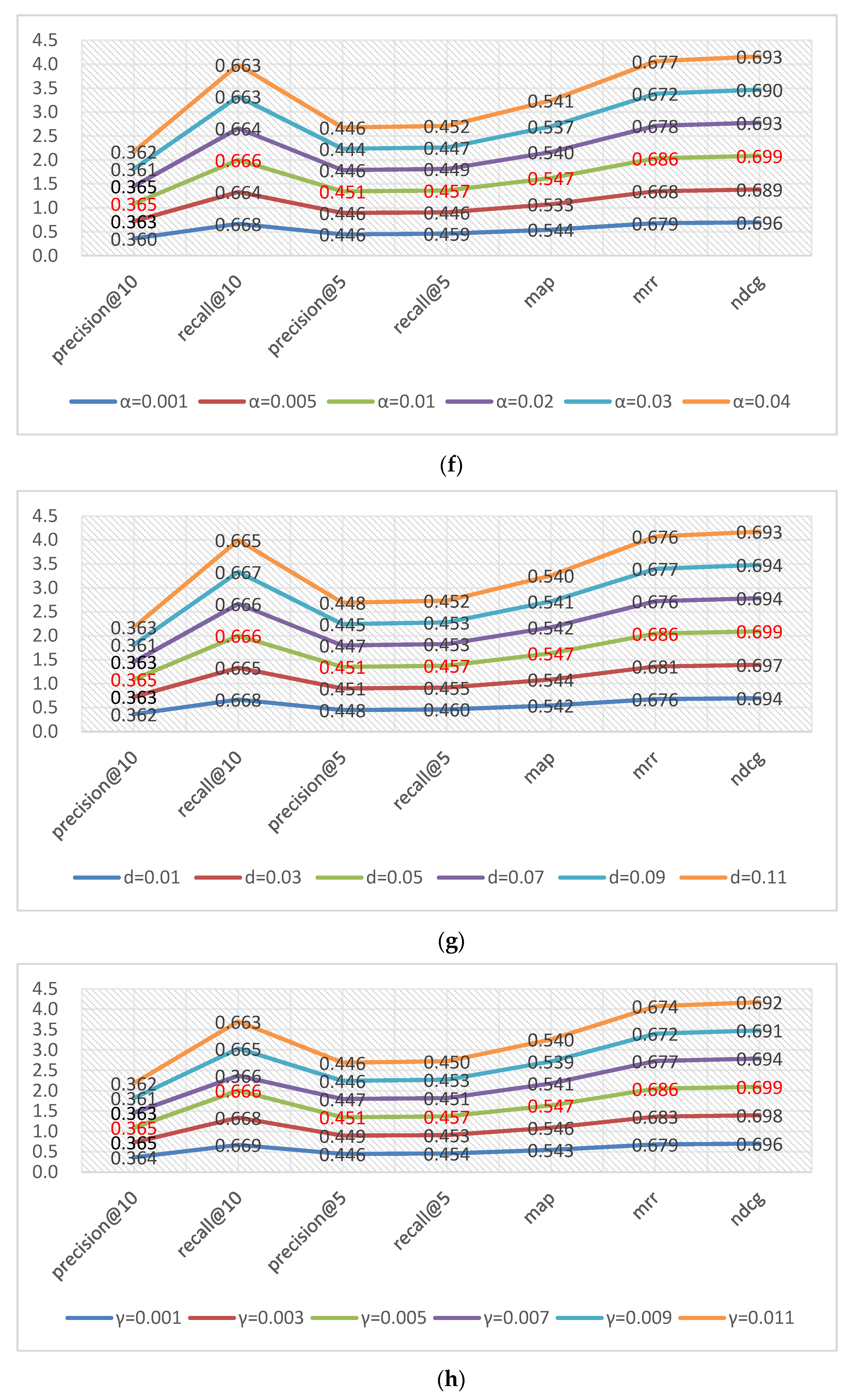
4.2. Item Ranking Experiment Preparation and Experimental Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- He, C.; Zhang, Q.; Tang, Y.; Liu, S.; Liu, H. Network Embedding Using Semi-Supervised Kernel Nonnegative Matrix Factorization. IEEE Access 2019, 7, 92732–92744. [Google Scholar] [CrossRef]
- Resnick, P.; Iacovou, N.; Suchak, M.; Bergstrom, P.; Riedl, J. GroupLens: An Open Architecture for Collaborative Filtering of Netnews. In Proceedings of the 1994 ACM conference on Computer Supported Cooperative Work, Chapel Hill, NC, USA, 22–26 October 1994; pp. 175–186. [Google Scholar]
- Su, X.; Khoshgoftaar, T.M. A Survey of Collaborative Filtering Techniques. In Advances in Artificial Intelligence; Hindawi LimitedAdam House: London, UK, 2009; Volume 2009, pp. 1–19. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.-S. Neural Collaborative Filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Yue, S.; Larson, M.; Hanjalic, A. Collaborative Filtering beyond the User-Item Matrix: A Survey of the State of the Art and Future Challenges. ACM Comput. Surv. (CSUR) 2014, 47, 1–45. [Google Scholar]
- Ram, P.; Gray, A.G. Maximum inner-product search using cone trees. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; p. 931. [Google Scholar]
- Tversky, A.; Gati, I. Similarity, separability, and the triangle inequality. Psychol. Rev. 1982, 89, 123–154. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Koren, Y.; Volinsky, C. Collaborative Filtering for Implicit Feedback Datasets. In ICDM; IEEE Computer Society: Washington, DC, USA, 2008; pp. 263–272. [Google Scholar]
- Tay, Y.; Tuan, L.A.; Hui, S.C. Latent Relational Metric Learning via Memory-based Attention for Collaborative Ranking. In Proceedings of the Web Conference (WWW 2018), Lyon, France, 23–27 April 2018; pp. 729–739. [Google Scholar]
- Weinberger, K.Q.; Saul, L.K. Distance Metric Learning for Large Margin Nearest Neighbor Classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar]
- Hong, R.; Hu, Z.; Liu, L.; Wang, M.; Yan, S.; Tian, Q. Understanding Blooming Human Groups in Social Networks. IEEE Trans. Multimed. 2015, 17, 1980–1988. [Google Scholar] [CrossRef]
- Steck, H. Training and testing of recommender systems on data missing not at random. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–28 July 2010; pp. 713–722. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Salakhutdinov, R. Probabilistic matrix factorization. In Proceedings of the 20th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 1257–1264. [Google Scholar]
- Salakhutdinov, R.; Mnih, A. Bayesian probabilistic matrix factorization using markov chain monte carlo. ICML 08. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 880–887. [Google Scholar]
- Yin, Y.; Chen, L.; Xu, Y.; Wan, J. Location-Aware Service Recommendation With Enhanced Probabilistic Matrix Factorization. IEEE Access 2018, 6, 62815–62825. [Google Scholar] [CrossRef]
- Rubens, N.; Kaplan, D.; Sugiyama, M. Active learning in recommender systems. In Proceedings of the 19th International Conference on User Modeling, Adaption, Girona, Spain, 11–15 July 2011; pp. 414–417. [Google Scholar]
- Koren and Yehuda. Collaborative filtering with temporal dynamics. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 447–456.
- Volkovs, M.; Yu, G.W. Effective Latent Models for Binary Feedback in Recommender Systems. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 313–322. [Google Scholar]
- Levy, O.; Goldberg, Y. Neural Word Embedding as Implicit Matrix Factorization. In Proceedings of the 28th Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2177–2185. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. NIPS’13. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Guardiasebaoun, E.; Guigue, V.; Gallinari, P. Latent Trajectory Modeling: A Light and Efficient Way to Introduce Time in Recommender Systems. In Proceedings of the 9th ACM Conference on Recommender Systems, Vienna, Austria, 16–20 September 2015; pp. 281–284. [Google Scholar]
- Liang, D.; Altosaar, J.; Charlin, L.; Blei, D.M. Factorization Meets the Item Embedding: Regularizing Matrix Factorization with Item Co-occurrence. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 59–66. [Google Scholar]
- Tran, T.; Lee, K.; Liao, Y.; Lee, D. Regularizing Matrix Factorization with User and Item Embeddings for Recommendation. In Proceedings of the 27th ACM International Conference on Information and Knowledge Managemen, Torino, Italy, 22–26 October 2018; pp. 687–696. [Google Scholar]
- He, X.; Zhang, H.; Kan, M.Y.; Chua, T.S. Fast Matrix Factorization for Online Recommendation with Implicit Feedback. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 549–558. [Google Scholar]
- Barkan, O.; Koenigstein, N. ITEM2VEC: Neural item embedding for collaborative filtering. In Proceedings of the 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Vietri sul Mare, Salerno, Italy, 13–16 September 2016; pp. 1–6. [Google Scholar]
- Shuai, Z.; Yao, L.; Yi, T.; Xu, X.; Zhu, L. Metric Factorization: Recommendation beyond Matrix Factorization. Comput. Sci. 2018, 6, 1–11. [Google Scholar]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar]
- Bayer, I.; He, X.; Kanagal, B.; Rendle, S. A generic coordinate descent framework for learning from implicit feedback. In Proceedings of the 26th International Conference on World Wide Web, Perth Australia, 3–7 April 2017; pp. 1341–1350. [Google Scholar]
- Liang, D.; Charlin, L.; Mcinerney, J.; Blei, D.M. Modeling User Exposure in Recommendation. WWW 16. In Proceedings of the 25th International Conference on World Wide Web, Montréal, QC, Canada, 11–15 May 2016; pp. 951–961. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. Arch. 2014, 15, 1929–1958. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. Arch. 2011, 12, 257–269. [Google Scholar]
- Tran, D.Q.V.; Tuan-Anh, N.P.; Gao, C. Attention-based Group Recommendation. Assoc. Comput. Mach. 2018, 1, 1–15. [Google Scholar]
- Hsieh, C.-K.; Yang, L.; Cui, Y.; Lin, T.-Y.; Belongie, S.; Estrin, D. Collaborative Metric Learning. In Proceedings of the 26th International Conference on World Wide Web (WWW ’17), Perth, Australia, 3–7 April 2017; pp. 193–201. [Google Scholar]
- Li, P.; Wang, Z.; Ren, Z.; Bing, L.; Lam, W. Neural rating regression with abstractive tips generation for recommendation, SIGIR’17. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 345–354. [Google Scholar]
- Dziugaite, G.K.; Roy, D.M. Neural Network Matrix Factorization. Comput. Sci. 2015, 11, 1–7. [Google Scholar]
- Wu, Y.; Dubois, C.; Zheng, A.X.; Ester, M. Collaborative Denoising Auto-Encoders for Top-N Recommender Systems, WSDM’16. In Proceedings of the Ninth ACM International Conference on Web Search and Data Mining, San Francisco, CA, USA, 22–25 February 2016; pp. 153–162. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Number of Users | Number of Items | Total Rating | Range of Rating | Sparsity |
|---|---|---|---|---|---|
| Movielens-100K | 943 | 1682 | 100,000 | 0–5 | 6.30% |
| Movielens-1M | 6040 | 3952 | 1,000,209 | 0–5 | 4.19% |
| Model | Movielens-1M | Movielens-100K | ||
|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | |
| BPMF | 0.678 | 0.867 | 0.725 | 0.927 |
| NRR | 0.691 | 0.875 | 0.717 | 0.909 |
| NNMF | 0.669 | 0.843 | 0.709 | 0.903 |
| FML | 0.658 | 0.844 | 0.706 | 0.900 |
| MFIC | 0.653 | 0.834 | 0.688 | 0.883 |
| Ours vs. best | 0.005 | 0.010 | 0.008 | 0.017 |
| Datasets | Number of Users | Number of Items | Total Rating | Range of Rating | Sparsity |
|---|---|---|---|---|---|
| FilmTrust | 1508 | 2071 | 35,497 | 0–5 | 1.13% |
| EachMovie | 29520 | 1648 | 1,048,575 | 0–1 | 2.15% |
| FilmTrust | |||||||
|---|---|---|---|---|---|---|---|
| Model | MAP | MRR | NDCG | Recall@5 | Precision@5 | Recall@10 | Precision@10 |
| NeuMF | 0.483 | 0.609 | 0.646 | 0.393 | 0.413 | 0.626 | 0.350 |
| CDAE | 0.523 | 0.654 | 0.678 | 0.441 | 0.436 | 0.647 | 0.353 |
| WRMF | 0.516 | 0.648 | 0.663 | 0.427 | 0.433 | 0.632 | 0.351 |
| FML | 0.543 | 0.681 | 0.696 | 0.452 | 0.450 | 0.668 | 0.364 |
| MFIC | 0.548 | 0.685 | 0.701 | 0.458 | 0.456 | 0.674 | 0.367 |
| Ours vs. best | 0.005 | 0.004 | 0.005 | 0.006 | 0.005 | 0.006 | 0.003 |
| EachMovie | |||||||
| Model | MAP | MRR | NDCG | Recall@5 | Precision@5 | Recall@10 | Precision@10 |
| NeuMF | 0.414 | 0.656 | 0.657 | 0.335 | 0.378 | 0.475 | 0.302 |
| CDAE | 0.432 | 0.678 | 0.673 | 0.356 | 0.394 | 0.497 | 0.311 |
| WRMF | 0.433 | 0.679 | 0.670 | 0.355 | 0.397 | 0.494 | 0.314 |
| FML | 0.466 | 0.708 | 0.694 | 0.392 | 0.419 | 0.533 | 0.325 |
| MFIC | 0.487 | 0.728 | 0.713 | 0.399 | 0.446 | 0.539 | 0.349 |
| Ours vs. best | 0.021 | 0.020 | 0.019 | 0.007 | 0.027 | 0.006 | 0.024 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, H.; Wang, L.; Qin, J. Metric Factorization with Item Cooccurrence for Recommendation. Symmetry 2020, 12, 512. https://doi.org/10.3390/sym12040512
Dai H, Wang L, Qin J. Metric Factorization with Item Cooccurrence for Recommendation. Symmetry. 2020; 12(4):512. https://doi.org/10.3390/sym12040512
Chicago/Turabian StyleDai, Honglin, Liejun Wang, and Jiwei Qin. 2020. "Metric Factorization with Item Cooccurrence for Recommendation" Symmetry 12, no. 4: 512. https://doi.org/10.3390/sym12040512
APA StyleDai, H., Wang, L., & Qin, J. (2020). Metric Factorization with Item Cooccurrence for Recommendation. Symmetry, 12(4), 512. https://doi.org/10.3390/sym12040512