Abstract
With the flourishing of big data and the 5G era, the amount of data to be transmitted in the communication process is increasing, and end-to-end communication in traditional social networks has been unable to meet the current communication needs. Therefore, in order to improve the success rate of data forwarding, social networks propose that the sender of the message should reasonably choose the next hop node. However, existing routing and forwarding algorithms do not take into account nodes that are live in different scenarios, and the applicable next hop node metrics are also different. These algorithms only consider the forwarding preferences of the nodes during working hours and do not consider the forwarding preferences of the nodes during non-working hours. We propose a routing algorithm based on fuzzy decision theory, which aims at a more accurate decision on selecting the next hop. A routing and forwarding algorithm based on fuzzy decision is proposed in this paper. This algorithm symmetrical divides scenes in opportunistic social networks into working time and non-working time according to real human activity. In addition, metrics are designed symmetrically for these two scenarios. Simulation results demonstrate that, in the best case, the proposed scheme presents an average delivery ratio of 0.95 and reduces the average end-to-end delay and average overhead compared with the epidemic routing algorithm, the EIMSTalgorithm, the ICMT algorithm, and the FCNSalgorithm.
1. Introduction
In recent years, due to the rapid development of 5G networks and big data [1], each of us has mobile communication devices, such as smartphones and iPads with Bluetooth, WiFi, etc. These communication devices carried by people have become an integral part of people’s daily lives [2]. In this case, we can consider these mobile devices carried or used by people as nodes in opportunistic social networks. Because of the significant sociality of human activities, the movement of nodes conforms to the rules of human social activities, and the strength of the social connection between nodes can often indicate the level of the possibility of an connection opportunity. Consequently, the practicality and effectiveness of opportunistic social network routing protocols can be improved by analyzing the social attributes [3] of nodes.
Therefore, combining the opportunistic network [4] with the mobile social network [5,6] to form the opportunistic social network [7,8] has both the social characteristics of the social network and the data forwarding characteristics of the opportunistic network, which is a form of the social network’s transition to offline materialization. The opportunistic social network adopts a “storage-carry-forward” [9,10] routing model and proposes that data forwarding can be achieved through the “opportunity exchange” [11,12,13] method. This communication relies on the movement of nodes and efficient forwarding algorithms, so that some nodes have the opportunity to act as relay nodes. In other words, the source node needs to find a suitable relay node to send the message to the destination node [14], and this relay node has a great chance to communicate with the source node or the destination node. The message is transmitted and shared in a network that lacks a stable end-to-end connection through this method. It can be seen that in order to improve the efficiency of routing forwarding and reduce the delay, selecting the appropriate relay node is the key to the routing and forwarding algorithm.
Recently proposed data forwarding algorithms [15,16,17] focus on analyzing social characteristics, including interests, work place, time, social relationships, similarity, etc. Obviously, each social factor may play a different role in the successful data transmission process. In order to select a more suitable relay node, different social attributes need to be selected in different scenarios as a measure of relay node selection. However, the existing algorithms in opportunistic social networks only consider the selection of the best next hop node in a single scenario and do not fully consider the social characteristics of human mobility. The above situation has led to problems such as reducing data forwarding efficiency and greatly increasing the network load, transmission delay, and node energy consumption. In order to solve this problem, it is necessary to find an effective method for selecting the best next hop node under the environment of big data and 5G. There are many excellent strategies for selecting the next hop node in the existing algorithms. Since opportunistic social networks are closely related to social life, another problem arises. This problem is how to integrate human mobility characteristics into complex routing algorithms and propose effective solutions for selecting next hop nodes. Because there are many reasons that cause human movement [18,19], the behavior of a node has a large number of attributes. Selecting one or more representative attributes as the basis for selecting the next hop node is a solution to existing routing algorithms. Therefore, it is reasonable for different algorithms to choose different attributes in different application scenarios. In real social scenarios, humans move for different reasons at different periods of time. How does one choose the attributes that are suitable for the scenario on the premise of considering the actual motion situation? Finally, choosing the best next hop node according to different attributes is a problem to be solved.
To solve these urgent issues, an effective transmission strategy based on a fuzzy control system [20,21] is proposed in this work, which is known as a fuzzy control routing-forwarding algorithm. We comprehensively considered the possible behavior patterns of nodes. As shown in Figure 1, Tom’s life is regular. He takes a bus from 7:30 to 8:30, works between 8:30 and 17:00, takes a break from 17:00 to 19:00, and comes back home at the end of the day. Different social characteristics are exhibited at different time periods. Consequently, we innovatively divided the background of the routing algorithm into working time and non-working time. In working times, this paper takes advantage of the Degree of Intimacy (DI) and Separating Time (ST) as the metrics. In non-working time, this paper uses the Sensitivity of Interest (IS) and the Sensitivity of Age (AS) as the metrics. Through reasonable weight adjustments and fuzzy decision-supporting system, the optimum next hop is obtained in this paper. In a nutshell, this algorithm is a novel routing-forwarding method, which completely considers the real-life scenarios. The contributions of this paper are listed as follows:

Figure 1.
Real-life scenarios.
- By comprehensively analyzing the characteristics of nodes in the opportunistic social network, the idea of dividing daily scenarios into working time and non-working time is established.
- According to the features of the two scenarios, this article proposes four unique features to assess the sociality of nodes. In working time, our paper utilizes two social factors, which are the Degree of Intimacy (DI) and Separating Time (ST). In non-working time, we exploit two social factors, which are the Sensitivity of Interest (IS) and the Sensitivity of Age (AS).
- To evaluate the impact of each social characteristic on the transmission process in the opportunistic social network synthetically, we make use of the idea of a fuzzy decision-supporting system with the analytic hierarchy process and with selecting optimal next hop nodes.
- Taking advantage of the simulation tool ONE, we acquired the results of the experiment, which demonstrated the significance of the MSFC algorithm to enhance the ability of routing-forwarding and to reduce the overhead ratio.
The rest of this paper is structured as follows. In Section 2, we describe and analyze the related works. The model of this algorithm is proposed and analyzed in Section 3, In Section 4, the complexity analysis of the system model is provided. The simulation results are presented in Section 5. The last section concludes the paper.
2. Related Work
In recent years, research on routing algorithms has become a hot issue in opportunistic social networks. In order to adapt the proposed algorithm to different application scenarios, researchers have tried different algorithms and methods to improve the delivery ratio and reduce the overhead. In the opportunistic social network, routing algorithms can be roughly divided into two categories: the socially-ignorant routing algorithm and the social-based routing algorithm. We will introduce the two categories of routing algorithms related to our work in detail.
2.1. The Proposed Socially-Ignorant Routing Algorithm
In existing socially-ignorant routing algorithms, transmission strategies are proposed to improve the forwarding success rate of the opportunistic network. The epidemic algorithm [22] is a flooding routing algorithm that takes the source node as the pathogen and other nodes in the network as vulnerable populations. Its disadvantage is that the demand for network resources is too large. The spray and wait algorithm [23] is divided into two phases: spray and wait. In the spray phase, the source node injects a fixed number of message copies into the network and then enters the wait phase. If the message copy is not delivered to the target node, the node carrying the message completes the message delivery by direct delivery [24].
To improve the delivery ratio and reduce the end-to-end delay and the network overhead, some complex mathematical methods have been applied in opportunistic transmission models, such as decision tree, Markov chains, probability prediction, etc. Sharma et al. [25] proposed a machine leaning-based protocol for improving the effective of opportunistic routings. This algorithm makes use of the method of decision tree and neural networks to predict the successful ratio of packet deliveries. J.Wu [26] proposed a message cache management and data transmission algorithm, which designed a node recognition method for assessment probability and reconstructed the cache space. This work improved the forwarding rate while causing a small routing overhead, but this was not for our scenario.
2.2. The Proposed Social-Based Routing Algorithm
Existing social-based routing algorithms make full use of social contact patterns to design efficient data forwarding strategies for opportunistic social network. ETNS [27] was proposed, which is an effective transmission strategy based on node socialization to divide nodes in the network into several different communities. By considering nodes’ global trust, the author can judge the behavior of nodes in the communities and establish a community reduction strategy to decrease the number of inefficient nodes. PIS [18] integrates three social features, namely physical proximity, user interests, and the social relationship, of users’ daily routines into a unified distance function, so as to select optimal relay nodes for data forwarding. FCNS [28] makes use of mobile and social similarities to predict the transmission preference of nodes. GSI [29] fully exploits the geographical information, social features, and user interests to enhance transmission performance. FSF [30] assesses the friendship strength among the pair of nodes, then it determines the individual selfishness of the relay node.
In addition, many mathematical methods exist such as graph theory, fuzzy inference logic, information entropy. J.Wu [31] proposed an Efficient Data Packet Iteration and Transmission (EDPIT) algorithm, which selects data packets via iteration. This article made full use of information entropy to solve an actual question. FPRDM [32] uses an intelligent fuzzy decision-making system to reduce the average end-to-end delay. Although these papers all have made corresponding contributions to the opportunistic social networks, there is still room for improvement.
Different from the previously stated data forwarding strategies in opportunistic social networks, our work fully considers the applicable attributes of working time and non-working time, respectively, assigns corresponding weights to each attribute through a large number of experiments, and makes decisions using a fuzzy control system. Our proposed algorithm can choose more optimum next hop nodes and reduce the average end-to-end delay.
3. Model Design
In the opportunistic social network, the most traditional routing algorithms only consider a single scenario. When we analyzed the routing-forwarding algorithm to select the next hop node, we comprehensively considered the possible behavior patterns of nodes, and the innovative proposal divided the background of the routing algorithm into working time and non-working time according to the actual situation of human movement. In working time, people obtain certain regular things, which are fixed to be performed in each time period. For example, as shown in Figure 1, people generally take the bus at 8 o’clock, go to work at 9 o’clock, eat at 12 o’clock, etc. However, working time is totally different from non-working time, when the problem becomes a probability for people’s travel. People can freely choose the travel time and travel destination according to their own interests, preferences, etc. The nodes in this article are communication devices that people carry, such as mobile phones, iPods, and Bluetooth devices. Since these devices are used by human beings, it can be considered that these nodes have human attributes. The proposed model in this paper comprehensively considers the scenarios and situations in which nodes can communicate and divides people’s communication into working time and non-working time, respectively. In working times, we take advantage of the DI and ST as the metrics for selecting the optimum next hop node. In non-working time, the IS and the AS as the metrics are used by this paper for selecting the optimum next hop node. These metrics for two scenes are selected by combining actual scenarios and analyzing a large amount of data. In non-working hours, we chose sensitivity of interest and sensitivity of age as measurement indicators. We found that people prefer to do something that they are interested in and there is a significant difference in the proportion of people of different ages who like things and make friends. In working time, we chose the degree of intimacy and separating time as metrics. We found that people’s lives are more regular during working hours. The ability to communicate frequently proves that the two are either at work or good friends, and if their separating time is short, they must be friends. In the following content, the mathematical meaning of the four indicators will be explained in detail.
3.1. Working Time
In working time, the degree of intimacy and the separating time together as measures of this period are used by this paper. The degree of intimacy is an expression of trust between nodes. Its strength is related to the number of connections established between nodes. The more connections are established, the higher the degree of intimacy between nodes. The separating time indicates the time difference between the two nodes’ encounters. The shorter the separating time, the closer the relationship between nodes. It is worth noting that the successful selection of the global optimal next hop node requires a common consideration of intimacy and separating time in the network.
3.1.1. Degree of Intimacy
The degree of intimacy between nodes can be roughly divided into two types: one is a direct communication node pair, and the other is an indirect communication node pair. The number of encounters of nodes i and j of direct communication at time t is expressed as . The number of times that nodes i and k of indirect communication meet at time t is expressed as . The number of times k and j meet at time t is expressed as . The above situation is equivalent to i and j exchanging message. Through the above analysis, the intimacy function of nodes i and j at time t can be computed by the following formula, where is a constant integer and the threshold of the number of node encounters:
The first part of the above formula indicates the direct encounter strength of the node. If the direct encounter times between nodes i and j are larger than , then the strength of the two nodes is equal to one, which proves that the relationship between the two nodes is more intimate. The second part of the above formula represents the indirect encounter strength of the node. The more common friends they have, the closer they will be. is defined as a collection of encountering nodes. is the weight proven by a large number of experiments, indicating the impact of direct encounter strength and indirect encounter strength on the calculation of the degree of intimacy.
3.1.2. Separating Time
The separating time indicates that the nodes move in the network, and the two nodes enter each other’s communication area. That is to say, the two nodes can establish a connection and start communication. When the distance between two nodes is greater than the radius of the communication area, the communication between the two nodes is considered to be broken, and then, they meet again. In this paper, the separating time of two nodes is defined as the time interval between two identical nodes encountering one another. A shorter separating time means a more intimate relationship between the two nodes.
where is recorded the moment of the next meeting event and is recorded the moment of this meeting event.
3.2. Non-Working Time
In non-working hours, the nodes in the opportunistic social network are considered to be mobile devices carried by people in this paper. Therefore, these mobile devices carried by people reflect the characteristics of human beings. Because of the same interests and similar ages, people will be more likely to communicate. Consequently, to judge the next hop node, we have taken full advantage of the metrics, which are the sensitivity of interest and the sensitivity of age. Compared with the node attributes used in the traditional routing algorithm, the attributes used by this algorithm can effectively avoid the inaccuracy of the result caused by the incomplete access of the node message.
3.2.1. Sensitivity of Interest
In non-working hours, people’s travel is more casual and unconstrained, so one of the reasons for people to travel may be interests. Therefore, the two nodes with the same interest are more likely to meet the two nodes with different interests. As we can see, interests lead to the motion of nodes. However, it is impossible that the movement of a node depends entirely on interests, so the probability that a node moves due to interests is called the sensitivity of interest in this paper. When people use mobile devices, our interests can be easily obtained and analyzed from our related operations. The node’s sensitivity of interest is an M*1 probability vector , where represents the transpose of a matrix. indicates the probability that node i will move because of the interest. Indeed, is used to compare the sensitivity of nodes to different interests. Hence, without loss of generality, we technically define for , and can be considered as a discrete probabilistic distribution. The weight of interest j occupying node i is defined as:
Node i’s sensitivity to all interests is defined as:
When selecting the next hop node, the interest sensitivity of all neighbor nodes around the source node i is calculated in turn, and the difference of interest sensitivity between the node i and the neighbor node j is compared. Select one or more nodes with the smallest difference as the next hop node to improve the message forwarding success rate. The difference is defined as:
3.2.2. Sensitivity of Age
The sensitivity of age is indicated as a similar trajectory and travel time due to age. For example, the young like to play in the afternoon. However, older people may like to go to the park in the morning or go to a square dance at night. Based on this theory, our paper draws a comprehensive consideration of age, time, and communication area, all of which affect the movement trajectory of nodes. Consequently, the sensitivity of age can be computed by the following formula:
where is defined as a constant, and the age of node i is expressed as . The closer the age, the greater the possibility of communication. The time interval between two nodes is described as . In , r represents the set of locations representing the communication area in the opportunistic social network; if , ; if not, .
3.3. Making Complete Use of the Fuzzy Decision Support System
The fuzzy decision-making system is a new adaptive technology based on fuzzy inference and mathematics, which has emerged as a decision support system in recent years. This system is expected to be used to provide more accurate decisions for route selection and data transmission in 5G networks and big data. Because the relationships between nodes and their social attributes are ambiguous and uncertain, we use fuzzy control decision-making methods to calculate the forwarding preferences of nodes. The fuzzy decision system consists of three components, including the fuzzifier, fuzzy inference, and defuzzifier. In the following sections, the specific implementation of each part of the fuzzy decision support system is described in detail.
3.3.1. The Fuzzifier
In the domain U, the fuzzy subset is essentially a function of . Consequently, the primary task of dealing with a fuzzy situation in practice is to determine membership functions . There are three main methods for determining the membership function: the fuzzy statistical method, the tripartite method, and the Delphi method. The tripartite method is an experimental method that uses the idea of random intervals to study fuzziness, which is consistent with the analysis of specific application scenarios in this paper. Therefore, the tripartite method is used to determine the membership function.
In working time, the factor set is , where respectively represent the DI and the ST. The judgment set is , where respectively represent low, medium, and high. In non-working hours, the factor set is , where respectively represent IS and AS; the evaluation set is , where respectively mean three different levels of membership subsets (low, medium, and high). Obviously, we can define the same membership function to calculate the degree of membership between nodes in the above two scenarios.
A common function is defined as a parent function for fuzzification of working time and non-working time. We define a generic function as:
In this general function, t is set as the label to identify whether the node is in working time or non-working time. When t is equal to one, nodes i and j live in the working time, Otherwise, when t is equal to zero, nodes i and j live in the non-working time. In the above formula, W can be adjusted according to the experiment. Finally, the weight of the working time is , and the weight of the non-working time is . After standardizing , the input value of the fuzzy system is obtained.
According to the tripartite method and the attribute setting in this article, we define , and is a random vector and U, V the boundary values of membership function and satisfying the condition of . However, have the ability to determine the mapping relationship:
On the basis of the theory of , the equation could be expanded as:
As demonstrated in Figure 2A–C, when the Common Function changes over time, low, medium and high membership functions present different curves and the codomain is always between 0 and 1. According to the actual application scenarios and a large number of literature references, obeying the normal distribution is set, and , .
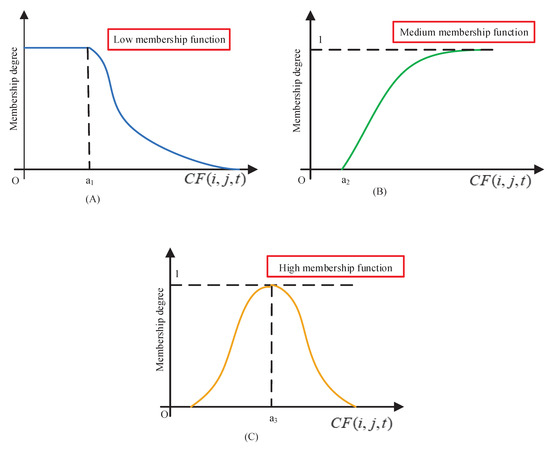
Figure 2.
Three different grades of membership functions’ quantization vectors. Figures (A–C) show when the Common Function changes over time, low, medium and high membership functions present different curves and the codomain is always between 0 and 1.
In the above formula, is described as , which is the standard normal distribution function. In this fuzzification process, according to the membership function set by artificial experience and data training, the situation divides the opportunistic social network into working time and non-working time and assigns three different membership functions to each case. Both critical and metric parameters can be adjusted to optimal values through multiple data trainings and parameter adjustments.
3.3.2. The Model of Fuzzy Inference
As shown in Figure 3, based on the actual situation, the fuzzy rules of working time and non-working time are designed by using “IF-THEN” rules. When t is equal to one, node pairs live in the working time, Otherwise, when t is equal to zero, node pairs live in the non-working time. According to the fuzzy rules we designed and the degree of membership of the node pairs, the nodes during working hours and non-working hours are divided into three states, which are active state, normal state, and lazy state. The establishment of fuzzy rules is described in detail by the following. The fuzzy rules in working hours are described as:
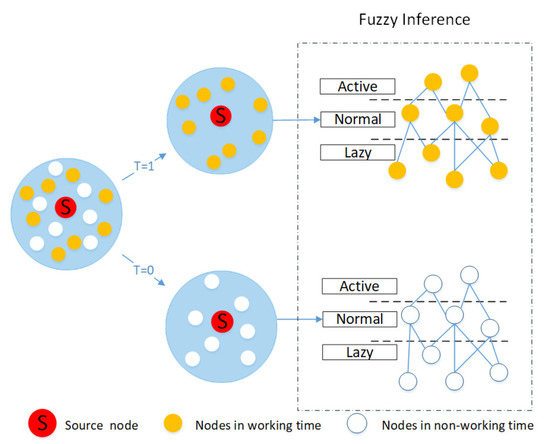
Figure 3.
Fuzzy rule.
- If the membership degree is high and the communication frequencies of nodes i and j are considered to be at a high level, then the nodes i and j are defined to be in the active state.
- If the membership degree is medium and the communication frequencies of nodes i and j are considered to be at a medium level, then nodes i and j are defined to be in the normal state.
- If the membership degree is low and the communication frequencies of nodes i and j are considered to be low, then nodes i and j are defined to be in the lazy state.
The fuzzy rules in non-working hours are described as:
- If the membership degree is high and the communication frequencies of nodes i and j are considered to be at a high level, then the nodes i and j are defined to be in the active state.
- If the membership degree is medium and the communication frequencies of nodes i and j are considered to be at a medium level, then nodes i and j are defined to be in the normal state.
- If the membership degree is low and the communication frequencies of nodes i and j are considered to be low, then nodes i and j are defined to be in the lazy state.
where i is a source node and j is the collective name of the neighbor node.
For the above rules, the article is described in the form of “IF A THEN B” as follows:
- If =, then it is considered to be in the active state.
- If =, then it is considered to be in the normal state.
- If =, then it is considered to be in the lazy state.
where indicates that the node pairs are in the non-working time, while indicates that the node pair are in the non-working time.
3.3.3. The Components of the Defuzzifier
Regardless of whether the node pair is in the working time or non-working time, the source node i and the neighboring node can calculate the corresponding membership degree through the membership function, so it can be inferred that each node needs to maintain a fuzzy vector . One interesting thing we find about the node i and its neighbor nodes is that their vector expression of the membership degree can be expressed as:
From the perspective of the entire network, the vector has become a matrix, the scale of which is .
Each row of the matrix indicates that node i and n nodes in the network calculate the membership degree, and three fuzzy sets of high level, medium level. and low level corresponding to node i and each node are respectively obtained. There is a total of n rows and n columns. The diagonal line indicates the degree of membership of node i and itself, which is set to zero.
The element with the highest degree of membership is selected from each row of the matrix as the output value by the principle of maximum membership, which can be represented as:
The above formula can also be expressed as:
In order to reduce node energy consumption and release storage space, we obtain a vector after compression matrix transposition according to the maximum value selected in each row, such as:
For the node with a high degree of membership in the vector, we think that the node pairs have high activity. Obviously, the node can be selected as the next hop node. For instance, when a node forwards a message, it will select the node with the highest similarity with itself as the next hop node in the network. In this way, the forwarding success rate is the highest.
In order to reduce the network load and improve the forwarding efficiency, the degree of membership of the node that belongs to node j in low and medium activity can be defined as zero. For example, in the vector, when and n, the membership of the node pair is high, so the next hop node set is [].
4. Complexity Analysis
In a nutshell, an effective fuzzy control routing-forwarding algorithm is proposed in this paper. We comprehensively considered the possible behavior patterns of nodes and innovatively divided the background of the routing algorithm into working time and non-working time in the opportunistic social network. At the same time, in order to enhance the understanding and readability of our whole algorithm, the detailed steps of the MSFC algorithm are listed as follows:
Step 1: Firstly, we should judge whether the source node i is in working time or non-working time. Secondly, we should determine whether the neighbor node j of source node iis in working time or non-working time. Finally, the neighbor nodes are divided into two sets: and .
Step 2: This article defines a common function, which includes a label t. When t is equal to one, nodes i and j live in the working time. Otherwise, when t is equal to zero, nodes i and j live in the non-working time. When nodes i and j live in the working time, calculate the degree of intimacy and separating time; when the nodes i and j live in the non-working time, calculate the node sensitivity of interest and the sensitivity of age.
Step 3: According to the fuzzy decision control system, each node evaluates the membership degree of CFwith other nodes, determines the level of the transmission preference, and stores it in an matrix, which is known as .
Step 4: The dimension of is reduced to a vector, and the node with a high degree of membership is selected. That is to say, this node is considered to be in the active state, and the active node is selected as the optimum next hop node.
Algorithm 1 and Figure 4 are proposed to make the MSFC algorithm more rigorous and intuitive. Specifically, in the process of determining the membership degree, each node pair has a commotion function corresponding to three different levels (low, medium, high) that contain n membership degrees values, which presents a time complexity of . Ultimately, the time complexity of the process of finding the optimum next hop node is . As a consequence, the overall time complexity of the fuzzy control routing-forwarding algorithm can be computed as .
| Algorithm 1: Multi-scenario routing algorithm based on fuzzy control theory. |
| Input: all nodes in the opportunistic social network; |
Output: the optimal next hop nodes;
|
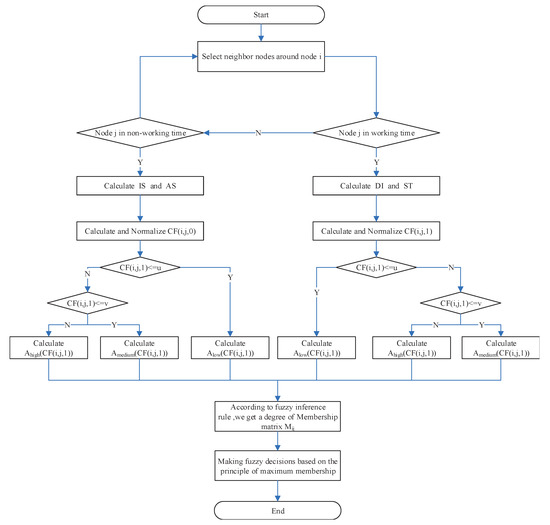
Figure 4.
The process of selecting the best next hop node.
5. Simulations
The simulations adopted the Opportunistic Network Environment (ONE) to evaluate the experimental performance of the routing algorithm proposed in this article. To be specific, it was compared with four other algorithms, three of which were the latest routing algorithms, one of which was a traditional algorithm in opportunistic social networks: EIMST(effective information transmission based on socialization nodes) [33], ICMT (Information Cache Management and data Transmission algorithm) [26], FCNS(fuzzy routing-forwarding algorithm) [28], and epidemic [22]. EIMST attempts to achieve an effective information transmission based on socialization nodes. ICMT makes use of memory management and node collaboration to achieve an effective data transmission. However, FCNS is a fuzzy routing-forwarding algorithm exploiting comprehensive node similarity in opportunistic social network.
5.1. Simulation Parameters
After analyzing the suitable scenario of the algorithm, the parameters were set as follows: The communication area was 2500 m × 3600 m, and the simulation time was 12 h. Five-hundred nodes were involved, and all nodes were distributed in the area at random. The maximum transmission area of each node was 20 m, and the nodes’ speed was defined as 1–25 m/s. The initial energy for every node was 100 J, and every node always consumed 0.25 J during the process of storage, carry, and forward. The cache space of every node was set to 10, 15, 20, 25, 30, 35, and 40 Mb, and the initial value was 10 Mb. In order to enhance the readability of the above simulation information, the detailed information is shown in Table 1. In our experiment, the effective data transmission algorithm depended on social relationship attributes having the best performance when during the working time and during the non-working time, .

Table 1.
The experimental setting of the simulation environment.
5.2. Evaluation Metrics
Our routing algorithm was compared with the above routings algorithm to assess its performance in the same simulation environment. In addition, this study mainly focused on the following metrics [33]:
- Delivery ratio: This measurement metric refers to the probability of choosing a suitable node as the next hop node, which is expressed as:where is the number of received messages by surrounding neighbor nodes and is the number of forwarded messages by nodes.
- Average end-to-end delay: This parameter comprehensively evaluates the delay caused by routing selections, relay nodes’ waiting delay, and transmission delay. The average end-to-end delay can be described as:where is the total delay of message forwarding from source nodes to destinations and N is the number of nodes that successfully acquired the message in the communication area.
- Overhead on average: This parameter represents the network overhead for successfully passing messages between a pair of nodes, which could be formalized as:where is the total time of data transmission and represents the total time of successful message forwarding between nodes.
- Energy surplus: this parameter records the energy surplus of the node during transmission.
5.3. Simulation Result Analysis
The Influence of the Moving Model on the MSFC Algorithm
This section mainly discusses and analyzes the performance of the MSFC algorithm in different mobile models. The simulation employed different mobile models to demonstrate the performance of the MSFC algorithm. We respectively selected the mobile models of Random Walk (RW), Random Way Point (RWP), and Shortest Path Map-Based Movement (SPMBM) to evaluate the message transmission efficiency. The delivery ratio of the MSFC algorithm in different mobile models is depicted in Figure 5. The MSFC algorithm worked best when using SPMBM as a mobile model. When the simulation time reached 12 h, the delivery ratio of MSFC could reach 95%. However, for the other two models, when the simulation time was 12 h, the delivery ratio of RWP was 0.9, and the delivery ratio of RW was 0.84.
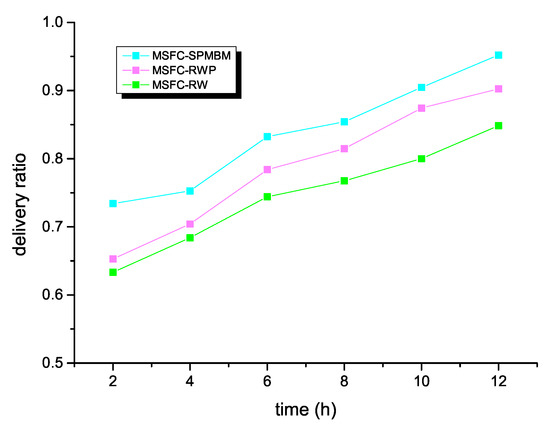
Figure 5.
Delivery ratio and time for MSFC in different models. Random Walk (RW), Random Way Point (RWP), and Shortest Path Map-Based Movement (SPMBM)
Next, Figure 6 shows the average end-to-end delay of the MSFC algorithm in different models. As can be seen from the result, the MSFC algorithm had the lowest average end-to-end delay, when this algorithm selected SPMBM as the mobile model. Consequently, when the simulation time reached 12 h, the average end-to-end delay of the MSFC algorithm was 35. However, for the other two models, when the simulation time was 12 h, the average end-to-end delay of RWP was 66, and the average end-to-end delay of RW was 46.
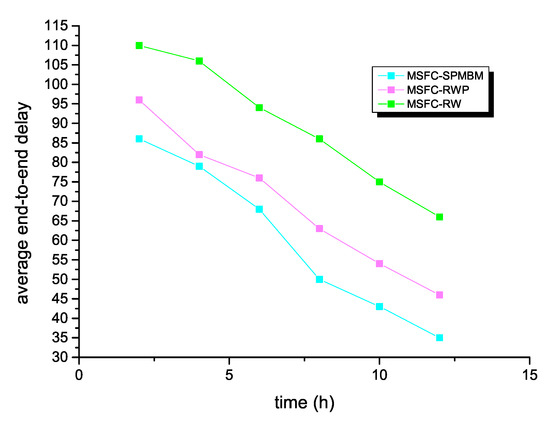
Figure 6.
Average end-to-end delay and time for MSFC in different models.
Next, the average overhead of the MSFC algorithm is demonstrated in Figure 7 in different mobile models. With the increasing of simulation time, the average overhead decreased at the same time. Moreover, when the mobile model of the MSFC algorithm was SPMBM, the average overhead of the network was the lowest.
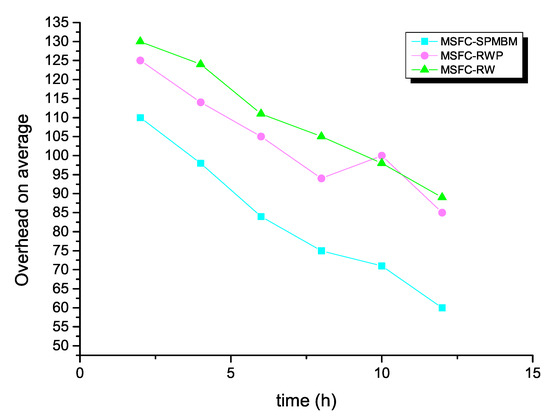
Figure 7.
Average overhead and time for MSFC in different models.
The impact of the simulation time and mobile model on the energy consumption is exhibited in Figure 8. Regardless of the simulation time, the MSFC algorithm had the lowest energy consumption when the mobile model was SPMBM.
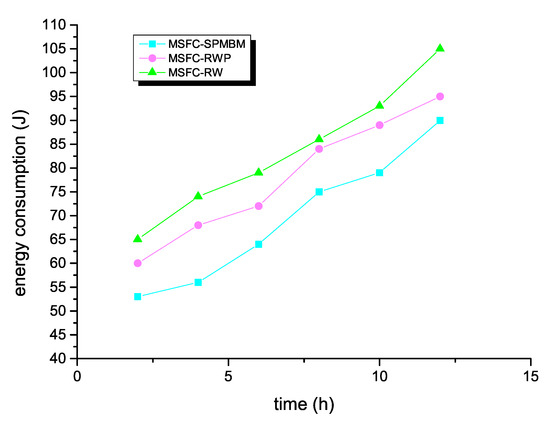
Figure 8.
Energy consumption and time for MSFC in different models.
5.4. Analysis of the Experimental Result
This section mainly performs a comparison and analysis between the five different algorithms. People’s demand for data forwarding is increasing under the environment of big data and 5G. It is crucial to improve the delivery ratio to choose the appropriate relay node in opportunistic social networks. However, in process with a large amount of data forwarding, the node’s cache space will also affect the node’s delivery ratio. Consequently, in this experiment, we rationally set the cache space as a variable to study the forwarding performance of each algorithm. All in all, the nodes had a larger cache space, and all algorithms had a higher delivery ratio. This was because nodes could handle more complex computing tasks and stored more information in opportunistic social networks.
Firstly, as Figure 9 shows, the delivery ratio of the EIMST algorithm was always lower than the ICMT and FCNS algorithms. This was because the EIMST algorithm did not establish a good cache management strategy and only considered the cooperation of nodes in the process of message forwarding. Consequently, no matter how the node’s cache space changed, the average delivery ratio of EIMST was maintained at about 0.8. The delivery ratio of the traditional routing algorithm epidemic was generally lower than several other algorithms. This was because the epidemic routing algorithm did not select the appropriate next hop node. It sent the message of the source node to all nodes that had met the node like spreading a virus. Therefore, a large number of message copies were stored in the node, occupying the node’s limited cache space and consuming a large amount of node resources. The ICMT and FCNS algorithms used data management and fuzzy control theory to make more accurate judgments during data forwarding. However, these algorithms still forwarded information to some unrelated nodes, occupying network resources and bandwidth. Compared with the other four algorithms, the MSFC algorithm had a transfer efficiency of 0.95 when the cache was 40 M. The main reason was that the MSFC algorithm comprehensively analyzed and divided the real human social scene into working hours and non-working hours. Additionally, the two scenarios had their own metrics. In the process of data packet forwarding, first select the one that is in the same state as the others. The nodes were then selected from the candidate node set as a node with a high state, making the selected node greatly suitable as the next hop node.
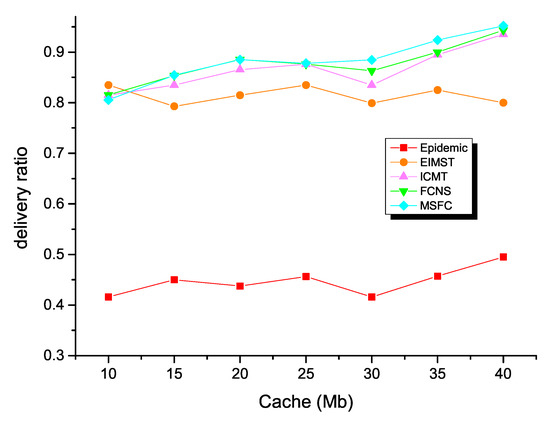
Figure 9.
Delivery ratio with various cache spaces.
Secondly, the next figure exhibits the comparison results between the five different algorithms in terms of average end-to-end delay. As shown in Figure 10, the average end-to-end delay of every algorithm increased as the nodes’ cache increased. To be specific, epidemic’s maximum delay could reach 530 because the algorithm generated a large number of message copies in opportunistic social networks, and this method dramatically increased routing and message forwarding delays. The EMIST algorithm and the ICMT algorithm had lower delays than the epidemic algorithm, because both algorithms effectively controlled the number of message copies. In addition, the EIMST algorithm implemented community division and information management, while the ICMT algorithm effectively utilized the cooperation mechanism between nodes to utilize the cache space of the nodes reasonably in order to reduce the delay in the message forwarding process. The average end-to-end delay of the FCNS algorithm was also significantly lower than the traditional algorithm, because the algorithm took advantage of the similarity of nodes to make message forwarding decisions, and the forwarding preference played a crucial role in the message forwarding process. The average end-to-end delay of the MSFC algorithm was the lowest among different node caches compared to several other algorithms, which further showed that the fuzzy control theory of the MSFC algorithm was better than the FCNS algorithm. The average transmission delay of the MSFC algorithm was stably maintained at about 35, because the algorithm took into account the fuzzy data forwarding relationship between nodes through different indicators of working status.
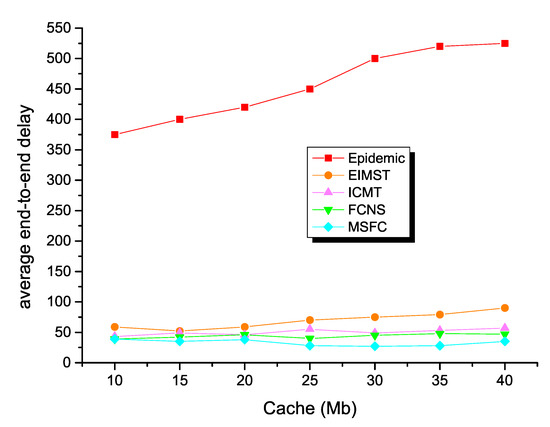
Figure 10.
Average end-to-end delay with various cache spaces.
Thirdly, the comparison results between the five different algorithms in the field of average overhead are demonstrated in Figure 11. The energy surplus of each routing algorithm decreased as the node’s cache space increased. Specifically, the epidemic algorithm had the least remaining energy, because the redundant message copy group of the algorithm in the opportunistic social network consumed much time and many resources in the network. This method sharply consumed energy in the network. The remaining energy of The EMIST algorithm and ICMT algorithm was higher than the epidemic algorithm, because both algorithms effectively controlled the number of message copies. In addition, the EIMST algorithm implemented community division and information management, while the ICMT algorithm effectively used the cooperation mechanism between nodes to use the node’s cache space rationally and control the forwarding time to achieve the purpose of reducing network energy consumption. The energy consumption of the FCNS algorithm was also significantly lower than the traditional algorithm. This was because the algorithm used the similarity of the nodes to make message forwarding decisions. The higher the similarity, the higher the success rate of forwarding of the nodes, so the less network energy was consumed. The energy consumption of the MSFC algorithm was the lowest in the cache space of different nodes compared to several other algorithms, which further showed that the next hop node selection strategy of the MSFC algorithm was better than the FCNS algorithm, and in all comparisons. In the algorithm, the relay nodes that successfully forwarded the message from the source node to the destination node were also the least.
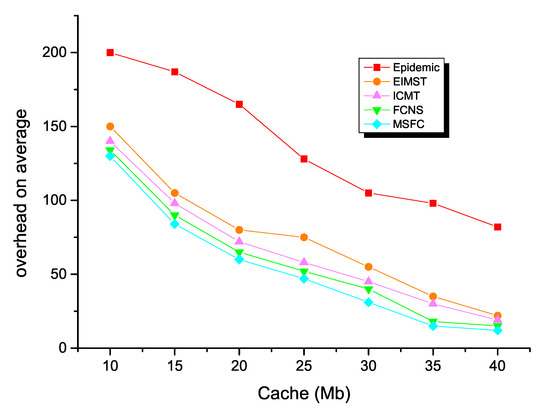
Figure 11.
Average overhead with various cache spaces.
Finally, Figure 12 shows the comparison of the remaining energy of the five different algorithms. The energy surplus of each routing algorithm decreased as the node’s cache space increased. More specifically, the energy surplus of the epidemic algorithm was the least, because the redundant message copy group of the algorithm in the opportunistic social network consumed much time and many resources in the network. This method drastically consumed energy in the network. The energy surplus of the EMIST algorithm and the ICMT algorithm was higher than the epidemic algorithm, because both algorithms effectively controlled the number of message copies. In addition, the EIMST algorithm implemented community division and information management, while the ICMT algorithm effectively exploited the cooperation mechanism between nodes to use the node’s cache space reasonably and control the forwarding time to achieve the purpose of reducing network energy consumption. The energy consumption of the FCNS algorithm was also significantly lower than the traditional algorithm, because it used the similarity of the nodes to make message forwarding decisions. The higher the similarity of the nodes, the less network energy was consumed. The energy consumption of the MSFC algorithm was the lowest in the cache space of different nodes compared to several other algorithms, which further showed that the next hop node selection strategy of the MSFC algorithm was better than the FCNS algorithm. In all compared algorithms, the relay nodes that successfully forwarded the message from the source node to the destination node were also the least.
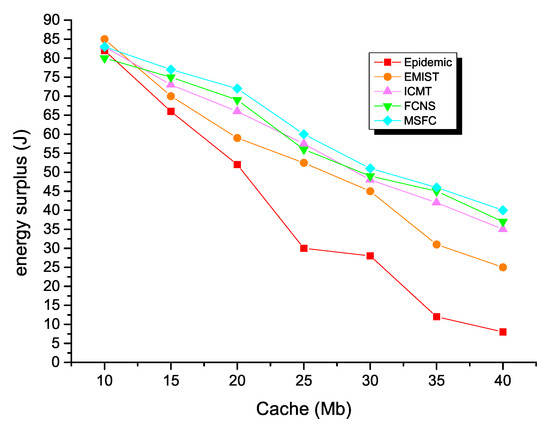
Figure 12.
Energy surplus with various cache spaces.
In a nutshell, the experimental results showed that the MSFC algorithm effectively reduced network delay, overhead, and energy consumption and increased the message delivery success ratio compared with a typical algorithm and several recently proposed routing algorithms. The average delivery ratio of the MSFC algorithm was 0.95. This algorithm reduced the average end-to-end delay and average overhead compared with the epidemic routing algorithm, the EIMST algorithm, the ICMT algorithm, and the FCNS algorithm
6. Conclusions
An effective transmission strategy based on a fuzzy control system was proposed in this work, which was called a fuzzy control routing-forwarding algorithm. This algorithm comprehensively considered nodes’ characteristics. Consequently, during the working time, the metrics were the Degree of Intimacy (DI) and Separating Time (ST). During the non-working time, the metrics were the Sensitivity of Interest (IS) and the Sensitivity of Age (AS). Unlike other routing algorithms based on a single scenario, this algorithm synthetically considered the scenarios of working time and non-working time. When selecting a suitable next hop node from the surrounding neighbors, this algorithm exploited fuzzy control decision-making methods to calculate the forwarding preferences of nodes. Supposing that the computing capacity and cache spaces of mobile devices in opportunistic social networks will be further enhanced, the MSFC algorithm can be applied to the transmission environment of 5G and big data networks. In future work, we will further improve the performance of the algorithm, enhance its portability, make it suitable for multiple scenarios, and further improve its transmission efficiency.
Author Contributions
Y.Y. (Yao Yu), J.Y., Z.C., and J.W. conceived of the idea of the paper. Y.Y. (Yao Yu), Y.Y. (Yeqing Yan), J.Y., Z.C., and J.W. designed and performed the experiments; Y.Y. (Yao Yu) and Y.Y. (Yeqing Yan) analyzed the data; Z.C. contributed reagents/materials/analysis tools; Y.Y. (Yao Yu) wrote and revised the paper. All authors read and agreed to the published version of the manuscript.
Funding
This work is partially supported by National Natural Science Foundation of China (Grant Nos. 61462079, 61562086, 61562078, 61862060) and the Science and Technology Support Project of Ministry of National Science and Technology of China (Grant No. 2015BAH02F01).
Conflicts of Interest
The authors declare that they have no competing interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ONE | Opportunistic Networking Environment |
| FCNS | Fuzzy Routing-Forwarding Algorithm Exploiting Comprehensive Node Similarity |
| MSFC | Multi-Scenario Routing Algorithm Based on Fuzzy Control Theory |
| DI | Degree of Intimacy |
| ST | Separating Times |
| IS | Sensitivity of Interest |
| AS | Sensitivity of Age |
| EIMST | Effective Information Transmission Based on Socialization Nodes |
| ICMT | Information Cache Management and Data Transmission Algorithm |
| FPRDM | An Adaptive Control Scheme Based on Intelligent Fuzzy Decision-Making System |
References
- Lucas-Estañ, M.C.; Gozalvez, J. Mode Selection for 5G Heterogeneous and Opportunistic Networks. IEEE Access 2019, 7, 113511–113524. [Google Scholar] [CrossRef]
- Yan, Y.; Chen, Z.; Wu, J.; Wang, L. An effective data transmission algorithm based on social relationships in opportunistic mobile social networks. Algorithms 2018, 11, 125. [Google Scholar] [CrossRef]
- Wu, J.; Chen, Z. Human Activity Optimal Cooperation Objects Selection Routing Scheme in Opportunistic Networks Communication. Wirel. Pers. Commun. 2017, 95, 3357–3375. [Google Scholar] [CrossRef]
- Amah, T.E.; Kamat, M.; Bakar, K.A.; Moreira, W.; Oliveira, A., Jr.; Batista, M.A. Preparing opportunistic networks for smart cities: Collecting sensed data with minimal knowledge. J. Parallel Distr. Comput. 2020, 135, 21–55. [Google Scholar] [CrossRef]
- Wu, D.; Liu, B.; Yang, Q.; Wang, R. Social-aware cooperative caching mechanism in mobile social networks. J. Netw. Comput. Appl. 2020, 149, 102457. [Google Scholar] [CrossRef]
- Wu, J.; Tian, X.; Tan, Y. Hospital evaluation mechanism based on mobile health for IoT system in social networks. Comput. Biol. Med. 2019, 109, 138–147. [Google Scholar] [CrossRef]
- Wu, J.; Chen, Z.; Zhao, M. Weight distribution and community reconstitution based on communities communications in social opportunistic networks. Peer-to-Peer Netw. Appl. 2019, 12, 158–166. [Google Scholar] [CrossRef]
- Luo, J.; Hu, J.; Wu, D.; Li, R. Opportunistic Routing Algorithm for Relay Node Selection in Wireless Sensor Networks. IEEE Trans. Ind. Inform. 2015, 11, 112–121. [Google Scholar] [CrossRef]
- Li, J.; Jia, X.; Lv, X.; Han, Z.; Liu, J.; Hao, J. Opportunistic routing with data fusion for multi-source wireless sensor networks. Wirel. Netw. 2019, 25, 3103–3113. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Y.; Zhang, J.; Ye, H.; Tan, Z. Cooperative Store-Carry-Forward Scheme for Intermittently Connected Vehicular Networks. IEEE Trans. Veh. Technol. 2017, 66, 777–784. [Google Scholar] [CrossRef]
- Luo, J.; Wu, J.; Wu, Y. Advanced Data Delivery Strategy Base on Multi-Perceived Community with IoT in Social Complex Networks. Complexity 2020, 2020, 15. [Google Scholar] [CrossRef]
- Wu, J.; Chen, Z.; Zhao, M. Community recombination and duplication node traverse algorithm in opportunistic social networks. Peer-to-Peer Netw. Appl. 2020, 1–8. [Google Scholar] [CrossRef]
- Socievole, A.; Caputo, A.; De Rango, F.; Fazio, P. Routing in Mobile Opportunistic Social Networks with Selfish Nodes. Wirel. Commun. Mob. Comput. 2019. [Google Scholar] [CrossRef]
- Wu, J.; Yu, G.; Guan, P. Interest characteristic probability predicted method in social opportunistic networks. IEEE Access 2019, 7, 59002–59012. [Google Scholar] [CrossRef]
- Lenando, H.; Alrfaay, M. EpSoc: Social-Based Epidemic-Based Routing Protocol in Opportunistic Mobile Social Network. Mob. Inf. Syst. 2018. [Google Scholar] [CrossRef]
- Zhou, H.; Leung, V.C.; Zhu, C.; Xu, S.; Fan, J. Predicting Temporal Social Contact Patterns for Data Forwarding in Opportunistic Mobile Networks. IEEE Trans. Veh. Technol. 2017, 66, 10372–10383. [Google Scholar] [CrossRef]
- Wang, R.; Wang, X.; Hao, F.; Zhang, L.; Liu, S.; Wang, L.; Lin, Y. Social identity–aware opportunistic routing in mobile social networks. Trans. Emerg. Telecommun. Technol. 2018, 29, e3297. [Google Scholar] [CrossRef]
- Xia, F.; Liu, L.; Jedari, B.; Das, S.K. PIS: A Multi-dimensional Routing Protocol for Socially-aware Networking. IEEE Trans. Mob. Comput. 2016, 15, 2825–2836. [Google Scholar] [CrossRef]
- Wang, S.; Wang, X.; Cheng, X.; Huang, J.; Bie, R.; Zhao, F. Fundamental analysis on data dissemination in mobile opportunistic networks with Lévy mobility. IEEE Trans. Veh. Technol. 2016, 66, 4173–4187. [Google Scholar] [CrossRef]
- Dutu, L.; Mauris, G.; Bolon, P. A Fast and Accurate Rule-Base Generation Method for Mamdani Fuzzy Systems. IEEE Trans. Fuzzy Syst. 2018, 26, 715–733. [Google Scholar] [CrossRef]
- Li, A.; Zhao, Z. An Improved Model of Variable Fuzzy Sets with Normal Membership Function for Crane Safety Evaluation. Math. Probl. Eng. 2017, 2017, 3190631. [Google Scholar] [CrossRef]
- Chitra, M.; Siva Sathya, S. Selective epidemic broadcast algorithm to suppress broadcast storm in vehicular ad hoc networks. Egy. Inf. J. 2017, 19, 1–9. [Google Scholar] [CrossRef]
- Sisodiya, S.; Sharma, P.; Tiwari, S.K. A new modifified spray and wait routing algorithm for heterogeneous delay tolerant network. In Proceedings of the 2017 International Conference on International Conference on I-Smac, Coimbatore, India, 10–11 February 2017; pp. 843–848. [Google Scholar]
- Kim, J.B.; Lee, I.H. Non-Orthogonal Multiple Access in Coordinated Direct and Relay Transmission. IEEE Commun. Lett. 2015, 19, 2037–2040. [Google Scholar] [CrossRef]
- Sharma, D.K.; Dhurandher, S.K.; Woungang, I.; Mohananey, A.; Rodrigues, J.J. A machine learning-based protocol for effificient routing in opportunistic networks. IEEE Syst. J. 2018, 12, 2207–2213. [Google Scholar] [CrossRef]
- Wu, J.; Chen, Z.; Zhao, M. Information cache management and data transmission algorithm in opportunistic social networks. Wirel. Netw. 2019, 25, 2977–2988. [Google Scholar] [CrossRef]
- Yan, Y.; Chen, Z.; Wu, J.; Wang, L.; Liu, K.; Wu, Y. Effective data transmission strategy based on node socialization in opportunistic social networks. IEEE Access 2019, 7, 22144–22160. [Google Scholar] [CrossRef]
- Liu, K.; Chen, Z.; Wu, J.; Wang, L. FCNS: A fuzzy routing-forwarding algorithm exploiting comprehensive node similarity in opportunistic social networks. Symmetry 2018, 10, 338. [Google Scholar] [CrossRef]
- Yang, Y.; Zhao, H.; Ma, J.; Han, X. Social-aware data dissemination in opportunistic mobile social networks. Int. J. Modern Phys. C 2017, 28, 1750115. [Google Scholar] [CrossRef]
- Souza, C.; Mota, E.; Galvao, L.; Manzoni, P.; Cano, J.C.; Calafate, C.T. Fsf: Friendship and selfishness forwarding for delay tolerant networks. In Proceedings of the 2016 IEEE Symposium on Computers and Communication (ISCC), Messina, Italy, 27–30 June 2016; pp. 1200–1207. [Google Scholar]
- Wu, J.; Chen, Z.; Zhao, M. An efficient data packet iteration and transmission algorithm in opportunistic social networks. J. Ambient Intell. Humanized Comput. 2019. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhang, L.; Shi, H.; Hwang, K.-S.; Shi, X.; Luo, S. An Adaptive Routing-Forwarding Control Scheme Based on an Intelligent Fuzzy Decision-Making System for Opportunistic Social Networks. Symmetry 2019, 11, 1095. [Google Scholar] [CrossRef]
- Wu, J.; Chen, Z.; Zhao, M. SECM: Status Estimation and Cache Management algorithm in opportunistic networks. J. Supercomput. 2019, 75, 2629–2647. [Google Scholar] [CrossRef]












© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).