Using the Least Squares Support Vector Regression to Forecast Movie Sales with Data from Twitter and Movie Databases


Abstract
:1. Introduction
2. The Developed Movie Sales Forecasting Architecture
2.1. The Least Square Support Vector Regression
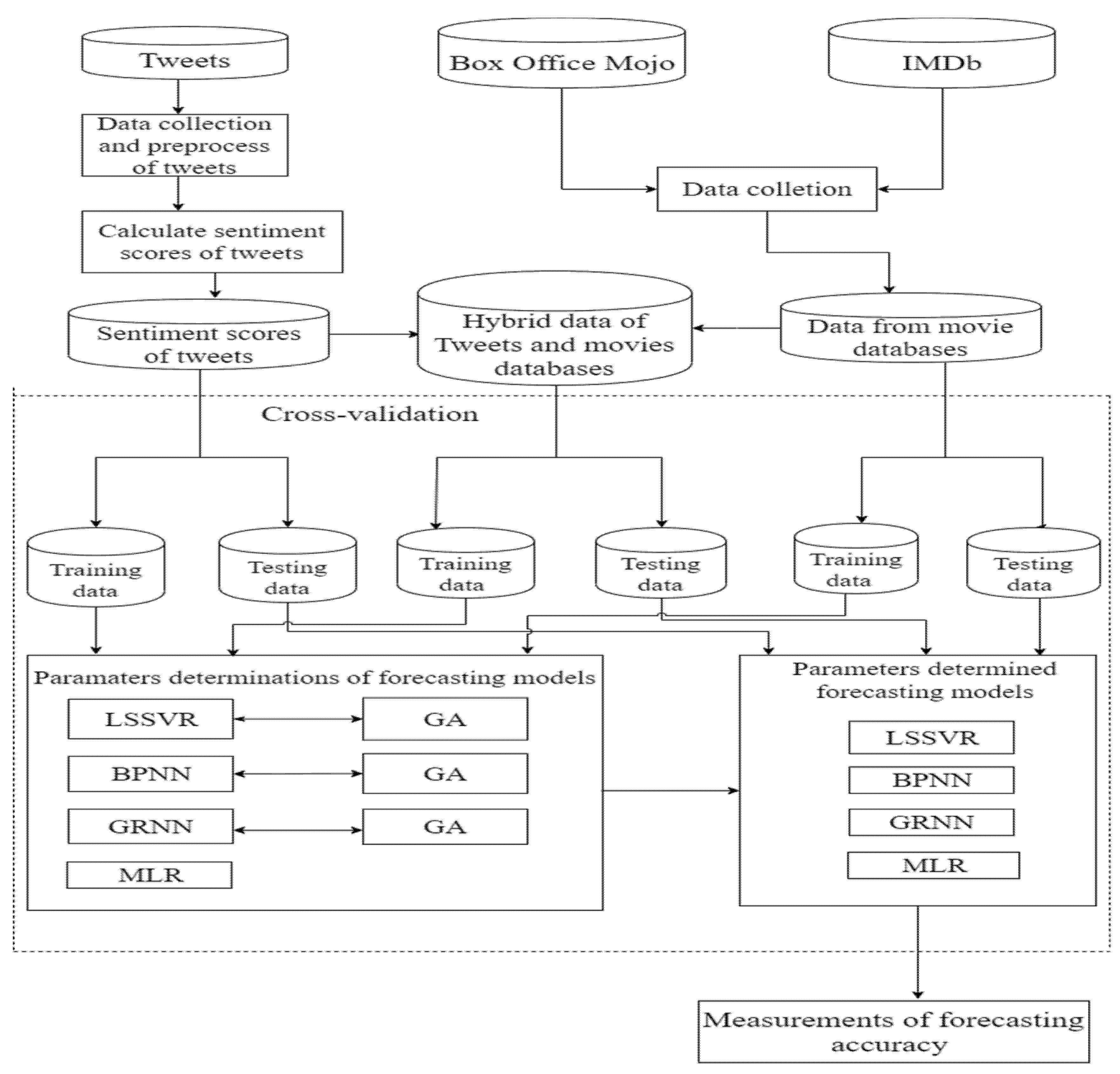
2.2. The Proposed Architecture for Forecasting Movie Sales
3. Numerical Results
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pai, P.-F.; Liu, C.-H. Predicting vehicle sales by sentiment analysis of Twitter data and stock market values. IEEE Access 2018, 6, 57655–57662. [Google Scholar] [CrossRef]
- Kang, G.J.; Ewing-Nelson, S.R.; Mackey, L.; Schlitt, J.T.; Marathe, A.; Abbas, K.M.; Swarup, S. Semantic network analysis of vaccine sentiment in online social media. Vaccine 2017, 35, 3621–3638. [Google Scholar] [CrossRef] [PubMed]
- Giatsoglou, M.; Vozalis, M.G.; Diamantaras, K.; Vakali, A.; Sarigiannidis, G.; Chatzisavvas, K.C. Sentiment analysis leveraging emotions and word embeddings. Expert Syst. Appl. 2017, 69, 214–224. [Google Scholar] [CrossRef]
- Xu, J.; Xu, B.; Wang, P.; Zheng, S.; Tian, G.; Zhao, J. Self-taught convolutional neural networks for short text clustering. Neural Netw. 2017, 88, 22–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tran, T.; Kavuluru, R. Predicting mental conditions based on “history of present illness” in psychiatric notes with deep neural networks. J. Biomed. Inform. 2017, 75, S138–S148. [Google Scholar] [CrossRef]
- Oliveira, N.; Cortez, P.; Areal, N. The impact of microblogging data for stock market prediction: Using Twitter to predict returns, volatility, trading volume and survey sentiment indices. Expert Syst. Appl. 2017, 73, 125–144. [Google Scholar] [CrossRef] [Green Version]
- Leitch, D.; Sherif, M. Twitter mood, CEO succession announcements and stock returns. J. Comput. Sci-Neth. 2017, 21, 1–10. [Google Scholar] [CrossRef]
- Li, Q.; Jin, Z.; Wang, C.; Zeng, D.D. Mining opinion summarizations using convolutional neural networks in Chinese microblogging systems. Knowl-Based. Syst. 2016, 107, 289–300. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Gelbukh, A. Aspect extraction for opinion mining with a deep convolutional neural network. Knowl-Based. Syst. 2016, 108, 42–49. [Google Scholar] [CrossRef]
- Corea, F. Can twitter proxy the investors’ sentiment? The case for the technology sector. Big Data Research 2016, 4, 70–74. [Google Scholar] [CrossRef]
- Huberty, M. Can we vote with our tweet? On the perennial difficulty of election forecasting with social media. Int. J. Forecast. 2015, 31, 992–1007. [Google Scholar] [CrossRef]
- Li, N.; Wu, D.D. Using text mining and sentiment analysis for online forums hotspot detection and forecast. Decis. Support Syst. 2010, 48, 354–368. [Google Scholar] [CrossRef]
- Ru, Y.; Li, B.; Liu, J.; Chai, J. An effective daily box office prediction model based on deep neural networks. Cogn. Syst. Res. 2018, 52, 182–191. [Google Scholar] [CrossRef]
- Baek, H.; Oh, S.; Yang, H.-D.; Ahn, J. Electronic word-of-mouth, box office revenue and social media. Electron. Commer. R. A. 2017, 22, 13–23. [Google Scholar] [CrossRef]
- Lee, J.H.; Jung, S.H.; Park, J. The role of entropy of review text sentiments on online WOM and movie box office sales. Electron. Commer. R. A. 2017, 22, 42–52. [Google Scholar] [CrossRef]
- Ding, C.; Cheng, H.K.; Duan, Y.; Jin, Y. The power of the “like” button: The impact of social media on box office. Decis. Support Syst. 2017, 94, 77–84. [Google Scholar] [CrossRef]
- Hur, M.; Kang, P.; Cho, S. Box-office forecasting based on sentiments of movie reviews and Independent subspace method. Inform. Sci. 2016, 372, 608–624. [Google Scholar] [CrossRef]
- Kim, T.; Hong, J.; Kang, P. Box office forecasting using machine learning algorithms based on SNS data. Int. J. Forecast. 2015, 31, 364–390. [Google Scholar] [CrossRef]
- Gopinath, S.; Chintagunta, P.K.; Venkataraman, S. Blogs, advertising, and local-market movie box office performance. Manag. Sci. 2013, 59, 2635–2654. [Google Scholar] [CrossRef]
- Rui, H.; Liu, Y.; Whinston, A. Whose and what chatter matters? The effect of tweets on movie sales. Decis. Support Syst. 2013, 55, 863–870. [Google Scholar] [CrossRef] [Green Version]
- Karniouchina, E.V. Impact of star and movie buzz on motion picture distribution and box office revenue. Int. J. Res. Mark. 2011, 28, 62–74. [Google Scholar] [CrossRef]
- Chakravarty, A.; Liu, Y.; Mazumdar, T. The differential effects of online word-of-mouth and critics’ reviews on pre-release movie evaluation. J. Interact. Mark. 2010, 24, 185–197. [Google Scholar] [CrossRef]
- Mishne, G.; Glance, N.S. Predicting movie sales from blogger sentiment. In Proceedings of the AAAI Spring Symposium: Computational Approaches to Analyzing Weblogs, Stanford, CA, USA, 27–29 March 2006; pp. 155–158. [Google Scholar]
- Liu, Y. Word of mouth for movies: Its dynamics and impact on box office revenue. J. Mark. 2006, 70, 74–89. [Google Scholar] [CrossRef]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Pai, P.-F.; Hong, L.-C.; Lin, K.-P. Using internet search trends and historical trading data for predicting stock markets by the least squares support vector regression model. Comput. Intel. Neuros. 2018, 2018, 6305246. [Google Scholar] [CrossRef] [Green Version]
- Mukherjee, S.; Osuna, E.; Girosi, F. Nonlinear prediction of chaotic time series using support vector machines. In Proceedings of the Neural Networks for Signal Processing VII, Amelia Island, FL, USA, 24–26 September 1997; pp. 511–520. [Google Scholar]
- Müller, K.-R.; Smola, A.J.; Rätsch, G.; Schölkopf, B.; Kohlmorgen, J.; Vapnik, V. Predicting time series with support vector machines. In Proceedings of the International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019; pp. 999–1004. [Google Scholar]
- Vapnik, V.; Golowich, S.E.; Smola, A.J. Support vector method for function approximation, regression estimation and signal processing. In Proceedings of the Advances Neural Information Processing System, Denver, CO, USA, 2‒6 December 1997; pp. 281–287. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. MLear 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Fletcher, R. Practical Methods of Optimization; Wiley: Hoboken, NJ, USA, 1987; pp. 80–94. [Google Scholar]
- Karush, W. Minima of Functions of Several Variables with Inequalities As Side Conditions. Master’s Thesis, University of Chicago, Chicago, IL, USA, 1939. [Google Scholar]
- Kuhn, H.W.; Tucker, A.W. Nonlinear programming. In Proceedings of the 2nd Berkeley Symposium on Mathematical Statistics and Probabilities, Berkeley, CA, USA, 31 July–12 August 1951; pp. 481–492. [Google Scholar]
- Mercer, J. Functions of Positive and Negative Type and Their Connection with the Theory of Integral Equations. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 1909, 209, 415–446. [Google Scholar]
- Thelwall, M.; Buckley, K.; Paltoglou, G.; Cai, D.; Kappas, A. Sentiment strength detection in short informal text. JASIS 2010, 61, 2544–2558. [Google Scholar] [CrossRef] [Green Version]
- Thelwall, M.; Buckley, K.; Paltoglou, G. Sentiment strength detection for the social web. JASIS 2012, 63, 163–173. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Specht, D.F. A general regression neural network. IEEE Trans. Neural Netw. 1991, 2, 568–576. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Holland, J. Adaptation in Natural and Arti_cial Systems: An Introductory Analysis with Applications to Biology, Control, and Artifcial Intelligence; University of Michigan Press: Ann Arbor, MI, USA, 1975; pp. 439–444. [Google Scholar]
- Arias, M.; Arratia, A.; Xuriguera, R. Forecasting with Twitter data. ACM Trans. Intell. Syst. 2013, 5, 1–24. [Google Scholar] [CrossRef]
- Maqsood, H.; Mehmood, I.; Maqsood, M.; Yasir, M.; Afzal, S.; Aadil, F.; Selim, M.M.; Muhammad, K. A local and global event sentiment based efficient stock exchange forecasting using deep learning. Int. J. Inf. Manag. 2020, 50, 432–451. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types of Variables | Data Descriptions | Number of Variables | Data Sources |
|---|---|---|---|
| Independent variables | Sentiment scores of tweets | 10 | |
| Distributors | 1 | Box Office Mojo | |
| Genres | 1 | Box Office Mojo | |
| MPAA ratings | 1 | Box Office Mojo | |
| Runtime | 1 | IMDB | |
| Budgets | 1 | IMDB | |
| The dependent variable | Worldwide box office | 1 | Box Office Mojo |
| Data Sources | Forecasting Accuracy Measurements | Forecasting Models | |||
|---|---|---|---|---|---|
| LSSVR | BPNN | GRNN | MLR | ||
| Movie databases | RMSE | 33.84 | 308.86 | 260.86 | 266.87 |
| MAPE(%) | 2.46 | 36.98 | 28.97 | 30.89 | |
| Tweets | RMSE | 63.75 | 342.28 | 436.24 | 374.65 |
| MAPE(%) | 6.18 | 40.51 | 49.83 | 40.12 | |
| Hybrid data | RMSE | 4.72 | 316.98 | 327.29 | 331.41 |
| MAPE(%) | 0.53 | 36.49 | 39.31 | 35.72 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.-T.; Pai, P.-F. Using the Least Squares Support Vector Regression to Forecast Movie Sales with Data from Twitter and Movie Databases. Symmetry 2020, 12, 625. https://doi.org/10.3390/sym12040625
Huang Y-T, Pai P-F. Using the Least Squares Support Vector Regression to Forecast Movie Sales with Data from Twitter and Movie Databases. Symmetry. 2020; 12(4):625. https://doi.org/10.3390/sym12040625
Chicago/Turabian StyleHuang, Yi-Ting, and Ping-Feng Pai. 2020. "Using the Least Squares Support Vector Regression to Forecast Movie Sales with Data from Twitter and Movie Databases" Symmetry 12, no. 4: 625. https://doi.org/10.3390/sym12040625