Pancreatic Cancer Early Detection Using Twin Support Vector Machine Based on Kernel


Abstract
1. Introduction
2. Materials and Methods
2.1. Kernel Method
2.1.1. Linear Kernel
2.1.2. Polynomial Kernel
2.1.3. Radial Basis Function (RBF) Kernel
2.2. Twin Support Vector Machine (TWSVM)
2.3. k-Fold Cross Validation
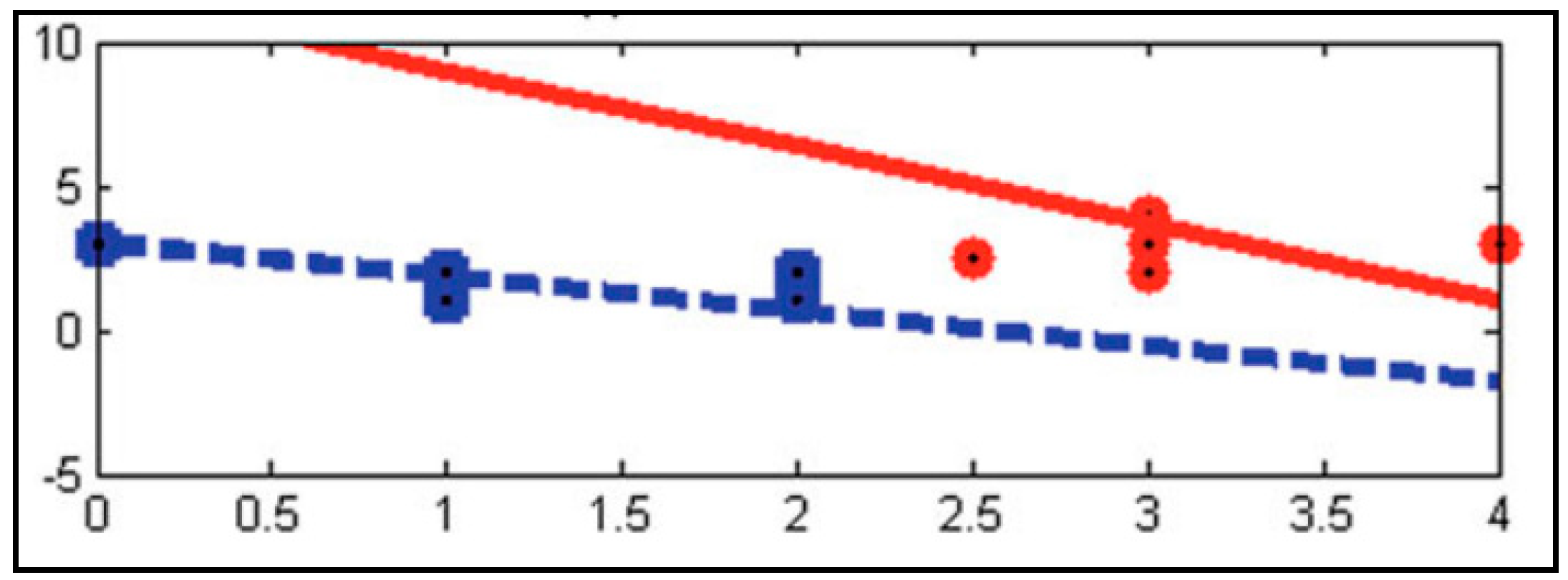
2.4. Proposed Method
3. Results and Discussions
3.1. Data
3.2. Confusion Matrix
- TP = Many cases of pancreatic cancer are predicted to be correct
- TN = Many cases of not pancreatic cancer are predicted to be correct
- FP = Many cases of not pancreatic cancer are predicted to be wrong (predicted as pancreatic cancer)
- FN = Many pancreatic cancer cases are predicted to be wrong (predicted as not pancreatic cancer)
3.3. Evaluation Parameters
3.4. Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cancer. Available online: https://www.who.int/cancer/en/ (accessed on 19 January 2020).
- Worldwide Cancer Statistics. Available online: https://www.cancerresearchuk.org/health-professional/cancer-statistics/worldwide-cancer (accessed on 25 January 2020).
- McGuigan, A.; Kelly, P.; Turkington, R.C.; Jones, C.; Coleman, H.G.; MacCain, R.S. Pancreatic cancer: A review of clinical diagnosis, epidemiology, treatment and outcomes. World J. Gastroenterol. 2018, 24, 4846–4861. [Google Scholar] [CrossRef] [PubMed]
- Global Cancer Observatory 2018. Available online: http://gco.iarc.fr/ (accessed on 23 December 2019).
- Rahib, L.; Smith, B.D.; Aizenberg, R.; Rosenzweig, A.B.; Fleshman, J.M.; Matrisian, L.M. Projecting cancer incidence and deaths to 2030: The unexpected burden of thyroid, liver, and pancreas cancers in the United States. Cancer Res. 2014, 74, 2913–2921. [Google Scholar] [CrossRef] [PubMed]
- Kim, V.M.; Ahuja, N. Early Detection of Pancreatic Cancer. Chin. J. Cancer Res. 2015, 27, 321–331. [Google Scholar] [PubMed]
- Badger, S.A.; Brant, J.L.; Jones, C.; McClements, J.; Loughrey, M.B.; Taylor, M.A.; Diamond, T.; McKie, L.D. The role of surgery for pancreatic cancer: A 12-year review of patient outcome. Ulster Med. J. 2010, 79, 70–75. [Google Scholar] [PubMed]
- Octaviani, T.L.; Rustam, Z. Random Forest for Breast Cancer Prediction. In Proceedings of the 4th International Symposium on Current Progress in Mathematics and Sciences (ISCPMS2018), Depok, Indonesia, 30–31 October 2018. [Google Scholar]
- Rustam, Z.; Putri, R.A. Comparison between stochastic support vector machine (stochastic SVM) and Fuzzy Kernel Robust C-Means (FKRCM) in breast cancer classification. In Proceedings of the 4th International Symposium on Current Progress in Mathematics and Sciences (ISCPMS2018), Depok, Indonesia, 30–31 October 2018. [Google Scholar]
- Rustam, Z.; Hartini, S. Classification of Breast Cancer using Fast Fuzzy Clustering based on Kernel. In Proceedings of the 9th Annual Basic Science International Conference 2019 (BaSIC 2019), Malang, Indonesia, 20–21 March 2019. [Google Scholar]
- Fijri, A.L.; Rustam, Z. Comparison between Fuzzy Kernel C-Means and Sparse Learning Fuzzy C-Means for Breast Cancer Clustering. In Proceedings of the ICAITI 2018—1st International Conference on Applied Information Technology and Innovation: Toward A New Paradigm for the Design of Assistive Technology in Smart Home Care, Padang, Indonesia, 4–5 September 2018. [Google Scholar]
- Rustam, Z.; Hapsari, V.A.W.; Solihin, M.R. Optimal cervical cancer classification using Gauss-Newton representation based algorithm. In Proceedings of the 4th International Symposium on Current Progress in Mathematics and Sciences (ISCPMS2018), Depok, Indonesia, 30–31 October 2018. [Google Scholar]
- Zahras, D.; Rustam, Z. Cervical Cancer Risk Classification Based on Deep Convolutional Neural Network. In Proceedings of the ICAITI 2018—1st International Conference on Applied Information Technology and Innovation: Toward A New Paradigm for the Design of Assistive Technology in Smart Home Care, Padang, Indonesia, 4–5 September 2018. [Google Scholar]
- Arfiani, A.; Rustam, Z. Ovarian cancer data classification using bagging and random forest. In Proceedings of the 4th International Symposium on Current Progress in Mathematics and Sciences (ISCPMS2018), Depok, Indonesia, 30–31 October 2018. [Google Scholar]
- Octaviani, T.L.; Rustam, Z.; Siswantining, T. Ovarian Cancer Classification using Bayesian Logistic Regression. In Proceedings of the 9th Annual Basic Science International Conference 2019 (BaSIC 2019), Malang, Indonesia, 20–21 March 2019. [Google Scholar]
- Salmi, N.; Rustam, Z. Naïve Bayes Classifier Models for Predicting the Colon Cancer. In Proceedings of the 9th Annual Basic Science International Conference 2019 (BaSIC 2019), Malang, Indonesia, 20–21 March 2019. [Google Scholar]
- Huljanah, M.; Rustam, Z.; Utama, S.; Siswantining, T. Feature Selection using Random Forest Classifier for Predicting Prostate Cancer. In Proceedings of the 9th Annual Basic Science International Conference 2019 (BaSIC 2019), Malang, Indonesia, 20–21 March 2019. [Google Scholar]
- Rustam, Z.; Kharis, S.A.A. Comparison of Support Vector Machine Recursive Feature Elimination and Kernel Function as feature selection using Support Vector Machine for lung cancer classification. In Proceedings of the Basic and Applied Sciences Interdisciplinary Conference, Depok, Indonesia, 18–19 August 2017. [Google Scholar]
- Qiu, Y.; Jiang, H.; Shimada, K.; Hiraoka, N.; Maeshiro, K.; Ching, W.K.; Aoki-Kinoshita, K.; Furuta, K. Towards Prediction of Pancreatic Cancer Using SVM Study Model. J. Clin. Oncol. Res. 2014, 2, 1031. [Google Scholar]
- Jayadeva; Khemchandani, R.; Chandra, S. Twin Support Vector Machines for Pattern Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 905–910. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Wei, X.; Zhou, Y. Twin support vector machines: A survey. Neurocomputing 2018, 300, 34–43. [Google Scholar] [CrossRef]
- Shawe-Taylor, J.; Cristianini, N. Kernel Methods for Pattern Analysis; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Suo, H.; Li, M.; Lu, P.; Yan, Y. Using SVM as Back-End Classifier for Language Identification. EURASIP J. Audio Speech Music Process. 2008, 1, 674859. [Google Scholar] [CrossRef][Green Version]
- Chidambaram, S.; Srinivasagan, K.G. Performance evaluation of support vector machine classification approaches in data mining. Clust. Comput. 2018, 22, S189–S196. [Google Scholar]
- Raju, K.S.; Murty, M.R.; Rao, M.V.; Satapathy, S.C. Support Vector Machine with K-fold Cross Validation Model for Software Fault Prediction. Int. J. Pure Appl. Math. 2018, 118, 321–334. [Google Scholar]


{kind=link}
| No | CA (U/mL) | Hemoglobin (g/dL) | Leukocytes (sel/uL) | Hematocrit (%) | Platelets (sel/uL) | Diagnosis |
|---|---|---|---|---|---|---|
| 1 | 5.73 | 12.1 | 10,200 | 36.7 | 143,000 | N |
| 2 | 8.05 | 11.8 | 11,300 | 35.9 | 222,000 | N |
| 3 | 86.21 | 10.1 | 12,800 | 34.1 | 346,000 | Y |
| 4 | 87.13 | 12 | 11,700 | 36.7 | 612,000 | Y |
| Predict | |||
|---|---|---|---|
| Pancreatic Cancer (Y) | Not Pancreatic Cancer (N) | ||
| Actual | Pancreatic Cancer (Y) | True Positive (TP) | False Negative (FN) |
| Not Pancreatic Cancer (N) | False Positive (FP) | True Negative (TN) | |
| Parameter | Formula | Explanation |
|---|---|---|
| Accuracy | Comparison between the number of cases of pancreatic cancer and not pancreatic cancer that identified correctly with the total number of all cases | |
| Sensitivity | Proportion of pancreatic cancer cases identified correctly | |
| Specificity | Proportion of not pancreatic cancer cases identified correctly |
| Classification Model | Accuracy (%) | Sensitivity (%) | Specificity (%) | Running Time (seconds) |
|---|---|---|---|---|
| TWSVM with Linear Kernel | 92% | 86% | 95% | 1.2811 |
| TWSVM with Polynomial Kernel with | 80% | 75% | 83% | 1.2040 |
| TWSVM with RBF Kernel with | 98% | 97% | 100% | 1.3408 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sadewo, W.; Rustam, Z.; Hamidah, H.; Chusmarsyah, A.R. Pancreatic Cancer Early Detection Using Twin Support Vector Machine Based on Kernel. Symmetry 2020, 12, 667. https://doi.org/10.3390/sym12040667
Sadewo W, Rustam Z, Hamidah H, Chusmarsyah AR. Pancreatic Cancer Early Detection Using Twin Support Vector Machine Based on Kernel. Symmetry. 2020; 12(4):667. https://doi.org/10.3390/sym12040667
Chicago/Turabian StyleSadewo, Wismaji, Zuherman Rustam, Hamidah Hamidah, and Alifah Roudhoh Chusmarsyah. 2020. "Pancreatic Cancer Early Detection Using Twin Support Vector Machine Based on Kernel" Symmetry 12, no. 4: 667. https://doi.org/10.3390/sym12040667
APA StyleSadewo, W., Rustam, Z., Hamidah, H., & Chusmarsyah, A. R. (2020). Pancreatic Cancer Early Detection Using Twin Support Vector Machine Based on Kernel. Symmetry, 12(4), 667. https://doi.org/10.3390/sym12040667