1. Introduction
Tesseract [
1,
2] is a popular open-source Optical Character Recognition (OCR) engine, developed initially by Hewlett Packard and later sponsored by Google. The original model has been improved since, now reaching version 4.1 (stable) at the time of writing. Among the significant changes is the inclusion of a Long-Short Term Memory (LSTM) OCR module, as stated in the manual [
3].
Despite the various enhancements, Tesseract’s performance can be greatly influenced by specific features of the input images. This paper investigates if input image augmentation, using generated convolution kernels, is feasible. The current work revolves around Tesseract 4.0′s inability to recognize texts from samples which present certain noise patterns, as shown in [
4]. The idea of encountering similar behavior in realistic pictures of text, taken with handheld devices, is introduced and discussed by evaluating the performance of the OCR engine using a public dataset.
The main contribution of this study consists of an implementation that relies on generating convolution kernels in an unsupervised manner, with the purpose of preprocessing the samples in order to maximize Tesseract 4.0′s performance. Multiple metrics, such as Character Error Rate (CER), Word Error Rate (WER) and F1 Score are used to evaluate the performance of the proposed method on a large (10,000 images) test set. The project proved to achieve comparatively better performances than other external image preprocessors for OCR engines, regardless of the chosen metric. e.g., the current solution achieves a +0.48 absolute accuracy improvement at the character level, compared to +0.25 or +0.22, as presented in other papers—see
Section 2.3 for additional information.
The paper is structured as follows: below, a discussion about different papers which tackle similar problems and the motivation of the current work, while
Section 2 illustrates the proposed strategies, techniques and implementation.
Section 3 covers performance-wise aspects. The paper ends with
Section 4, which discusses conclusions and future work.
1.1. Previous Work
Harraj et al. [
5] propose a four-step algorithm to improve Tesseract 3.02′s accuracy. The article focuses on using image processing methods to preprocess the input such that the OCR engine receives a clearer data to analyze. The technique involves brightness and contrast management, greyscale conversion, an unsharp masking [
6] approach and Otsu’s binarization method [
7]. The authors prove that preprocessing can improve the detection accuracy from 77.17% to 83.97% on a challenging input.
Koistinen et al. [
8] support the idea that Tesseract’s performance can be increased through image preprocessing (e.g., Linear Normalization, Wolf’s binarization method [
9] and Contrast Limited Adaptive Histogram Equalization [
10]). Five different combinations of algorithms generate new samples, based on the original image, that are forwarded to Tesseract. An hOCR-formatted [
11] output is created and later checked by a morphological analyzer, according to each word’s confidence. The implementation is built around Tesseract 3.04 and authors state a 27.48% improvement versus ABBYY FineReader 7 or 8 and 9.16% versus ABBYY FineReader 11. Precision and recall are evaluated between 0.69 and 0.71.
A different implementation is described by Reul et al. [
12], which targets datasets consisting of early printed books. The cross-fold training and voting mechanism are key elements in the proposed method. By training the same OCR engine (OCRopus) on different subsets, the authors obtain architecturally-similar models but with different characteristics. Voting occurs by taking into account the confidence of OCRopus for each character. A maximum of 50% relative reduction of CER is illustrated through the results of the experiment and, on average, a 0.02 absolute decrease in CER.
OCR error can be further decreased by automatically selecting favorable preprocessing algorithms [
13]. The authors claim that in the context of unknown distortions applied to the input image, the preprocessing methods will not offer the guarantee of improving the quality of the recognition process. Therefore, a 15 layer convolutional neural network is proposed and used to pick the most suitable preprocessing step (e.g., binarization, noise reduction, sharpening) for the given case. Two OCR engines are employed: Tesseract 2.0 and NNOCR, the latter including a modern LSTM architecture. The evaluation consists of recording normalized character-level accuracy for three sets of images, each containing 1000 samples. Results indicate an increase in accuracy from 0.38 to 0.63 for Tesseract 2.0 and from 0.93 to 0.96 for NNOCR.
Background elimination is another problem addressed in the context of OCR optimization [
14]. As certain documents might include background artifacts, these can lead to the occurrence of errors. The proposed solution revolves around image preprocessing by altering contrast with respect to brightness and chromaticity. Background and foreground pixels are linked through an equation whose coefficients (brightness and color distortion) are computed using error minimization on a training set. Image enhancement techniques are also applied in order to suppress the background region. The method was evaluated using Tesseract and compared to ABBYY FineReader and HANWANG OCR. The following results are presented for Tesseract: the original set of samples achieves a precision of 0.907 and 0.901 recall rate, while the preprocessed set leads to a precision of 0.929 and a recall of 0.928.
Thompson et al. propose in [
15] a strategy centered around spellchecking biased towards medical terms and rule-based error correction. As stated, the work is highly focused on enhancing OCR performance on the British Medical Journal (BMJ) archive. The rule-based method targets character-level correction of false positives such as punctuation marks recognized in the middle of certain words. Spellchecking is performed with the assistance of Hunspell, configured to favor decade-specific word frequency lists with respect to the publication date of the targeted document. Dictionary augmentation is also performed. Evaluation reveals an up to 16% decrease in WER on poor quality texts; on average, the WER is decreased from 0.169 to 0.09.
An alternative approach to improving OCR accuracy is presented by de Jager et al. [
16]. Even though their work relies on Google Cloud Vision for text recognition within the context of a more particular use case, a similar problem is addressed. Accuracy improvement is accomplished through various techniques such as identifying and pairing field names and corresponding values. Additionally, approximate string matching (ASM) [
17] is employed when comparing the OCR’s output with the ground truth. The described method is based on the Levenshtein distance, permitting string matching with respect to a fixed numeric threshold. As a result, the F1 score is increased from 60.18% to 80.61% with the assistance of index pairing and, finally, to 90.06% when ASM is applied. Furthermore, the authors discuss the choice of an optimal OCR engine for the experiment. A comparison between Tesseract and Google Cloud Vision is also included: the dataset composed of 19 images revealed a 71.76% accuracy for the former and 89.03% accuracy for the latter.
A similar postprocessing OCR optimization is discussed by Priambada et al. [
18]. The Levenshtein distance is used as a metric for successfully matching Tesseract’s readings with information stored in a database. The prototype targets a real-time analysis scenario, with 300–600 ms processing time, and boosts precision, recall and F1 score from 17% to 60%.
In [
19], Brisinello et al. propose a method of improving Tesseract 4.0′s accuracy on recognizing text from images that originate from Set-Top Boxes (STBs). Four preprocessing actions are included: image resizing, sharpening, blurring and foreground-background separation through k-means clustering. Combinations of the first three preprocessing actions are said to boost the accuracy of Tesseract 4.0 from 70.2% to 92.9%.
Finally, the authors of the Brno Mobile OCR dataset, the same used in this article, propose two state-of-the-art baseline models of neural networks for text recognition with the intention of assessing the difficulty of the dataset [
20]. The former relies on Gated Recurrent Unit (GRU) layers and achieves 0.33% CER and 1.93% WER, while the latter is described as a fully convolutional network and produces a 0.50% CER and a 2.79% WER on the ‘easy’ version of the dataset. The paper concludes that the dataset is considered challenging.
1.2. Problem Motivation
Many preprocessing solutions resort to image-specific alterations (e.g., binarization, noise reduction, sharpening, contrast management), applied according to predetermined conditions, which evaluate different characteristics. A question arises whether these changes are more beneficial if performed with respect to specific features or shapes (i.e., characters and symbols) and not globally. The majority of projects that perform image preprocessing with the purpose of enhancing OCR seem biased towards applying common filters, which neither adapt to the preferences of a certain engine nor provide sufficient granularity or flexibility in their alterations (see Table 5 for more details).
Moreover, determining conditions and thresholds for image enhancement by relying on principles related to human vision might not yield optimal results. OCR engines are nowadays mostly implemented using neural networks, which might favor inputs that seem unnatural, the same way they manifest undesired behavior when presented with specially crafted inputs [
21]. Performing substantial feature-level changes would require a more powerful image processing action than the ones previously enumerated.
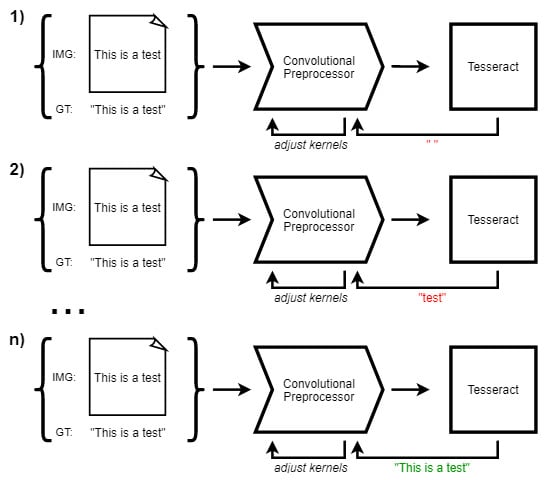
The following problem is also addressed: certain images prove to be challenging for Tesseract 4.0, as the results are unexpectedly inaccurate and large segments of text are apparently omitted. As presented in [
4], small amounts of salt-and-pepper noise can diminish the performance of Tesseract 4.0, to a point where text from ideal samples is not identified at all or causes segmentation errors. Nevertheless, the ’hidden text’ is correctly perceived by the human eye with little to no effort. The approach involves genetic algorithm based fuzzing, therefore the noise signature is sample-specific and the behavior cannot be deterministically reproduced. The existence of different, more natural image perturbations (e.g., color contrasts, lightning effects, blurring, etc.), which produce similar behavior, while being less noticeable, is plausible.
The objective of this article is to implement and prove the effectiveness of convolution-based preprocessing in order to perform flexible and informed feature-level decisions and alterations. Additionally, the resulted convolutional filters will highly optimize the images so that they conform to Tesseract 4.0′s preferences, without necessarily relying on aesthetical validation or external guidance (e.g., page segmentation method, language, etc.).
Current investigation proves that realistic, yet low-quality photographs of texts represent difficult inputs for Tesseract 4.0. An example is illustrated in
Figure 1.
Considering the aforementioned aspects, the following hypothesis arises: Tesseract 4.0′s weakness does not rely within the character classifier itself and it is more likely to be caused by the layout detection and analysis procedure. This is supported by
Figure 2, which shows a tendency of Tesseract towards greater precision when improvements are applied, while the recall is lower and remains almost constant. In this work, precision (1), recall (2) and F1 score (3) are defined as follows, where LCS stands for the Longest Common Subsequence [
22]:
A good true positives to false positives ratio is suggested, therefore characters are correctly classified by their features; however, the larger number of false negatives might imply that some characters are not detected or recognized at all.
Similar behavior can be caused by samples that contain specific artifacts or distortions. Moreover, the presence of unfavorable lighting and color contrasts can produce incorrect binarization and lead to an early corruption of the sample, before even reaching the segmentation step or the classifier.
2. Samples Preprocessing Using Generated Convolution Kernels
The challenge at hand can be formulated as an optimization problem, where the algorithm needs to discover the best convolution kernels, which maximize Tesseract’s accuracy over a set of training samples. Each set of kernels is viewed as a state, composed of real values from the interval [−4; 4]—limits which were empirically chosen. Since the environment imposes no constraints regarding the transition from one state to another and the intermediate states do not directly contribute to the final result, the proposed method includes only 2 states: initial and final. The task resembles the multi-armed bandit problem with a continuous search space.
The current implementation employs multiple modules in kernel optimization; for the sake of simplicity, the architecture of the current implementation is presented in
Figure 3.
A given image runs through the convolutional preprocessor and the result is passed to Tesseract 4.0. The output is compared to the ground truth and a score is determined; this score evaluates the quality of the current kernels and instructs the reinforcement learning model. Once new kernels are generated, based on previous ’compressed’ versions, they are ’decompressed’, in order to fit the convolutional preprocessor and the cycle repeats. The training methodology is further described using the pseudo-code from Algorithm 1.
| Algorithm 1. Training phase and kernels generation with feedback from Tesseract 4.0. |
| 1 | /* |
| 2 | input:inputs[i]—array of RGB images |
| 3 | output:next_state—compressed set of kernels |
| 4 | */ |
| 5 | |
| 6 | fort = 1 to MAX_EPOCHS do |
| 7 | ifrand(0, 1) < random_limit then |
| 8 | action = pick_random_action() |
| 9 | random_limit *= 0.994 |
| 10 | else |
| 11 | action = kernel_optimizer.suggest_action().clip(-4, 4) |
| 12 | |
| 13 | next_state = current_state + action |
| 14 | convolution_preprocessor.set_kernels(decompress(next_state)) |
| 15 | |
| 16 | score = 0 |
| 17 | fori = 1 to N do |
| 18 | preprocessed_inputs[i] = convolution_processor.apply_convolutions(inputs[i]) |
| 19 | score += levenshtein(run_tesseract(preprocessed_inputs[i]), expected_texts[i]) |
| 20 | |
| 21 | ifscore > best_score then |
| 22 | kernel_optimizer.save_current_state() |
| 23 | |
| 24 | replay_buffer.add(current_state, action, next_state, score) |
| 25 | |
| 26 | ifrandom_limit < 0.1 then |
| 27 | kernel_optimizer.train(replay_buffer) |
Below, the concept implemented in each module is further discussed.
Convolutional Preprocessor: This module applies a set of given convolution kernels to the input image. It resembles a basic convolutional neural network as it comprises 5 convolution layers separated by ReLU activation functions for nonlinearity purposes. Architecture is presented in
Figure 4.
A padding is applied in order to preserve the original size of the sample. The input images are represented as 3 channels (RGB) signals and compressed to a 1 channel (grayscale) model using 1 × 1 convolutions for each channel. The purposes of this filter are manifold:
The concept of symmetry is employed in the following 4 one-channel kernels with respect to the middle horizontal line, vertical line, first and second diagonal.
A first benefit brought by symmetrical kernels addresses the problem of a large search space: 4 filters of size 3 × 3 × 1 (width × height × num_channels) imply working with 24 variables instead of 36, thus reducing the number by 33.(3)%.
The second advantage is represented by the “mirroring” constraint, which prevents the over-optimization of kernels. Since the symmetrical kernels will target variations of low-level well-defined features (e.g., lines at different angles) there is a smaller chance of overfitting.
The choice of using 4 kernels is made to properly capture the 4 essential features within the 3 × 3 space. Separating the convolutional layers with ReLU activators has the purpose of creating a preprocessing model more suitable for non-linear inputs, such as images that contain edges and fast transitions between colors. This becomes useful in removing regions which are not of interest (i.e., non-positive colors in the image) while also guiding the preprocessor into working with and outputting values compatible with the grayscale color interval.
Finally, the convolutional model relies only on basic components and avoids downsampling and working with higher-level features for performance and generalization reasons.
Score Module: The current component implements the score function which guides the reinforcement learning algorithm. The metric is defined as the Levenshtein distance between the output of Tesseract and the ground truth; in the implementation, the score is represented as the negative value in order to perform reward maximization, as expressed in Equation (4). A value of 0 indicates an optimal result as it implies the OCR engine correctly identified every character in all the given N images.
Reinforcement Learning Kernels Optimizer: The module handles the generation of kernels, which attempt to maximize the score, in an unsupervised (actor-critic) manner. It uses states and actions to represent the current configuration of the convolution kernels. Since the search space is large (27 variables in continuous search space), the following constraints were added:
It works using a ’compressed’ version of the kernels, in order to enforce the symmetry constraints.
A modified implementation of the Twin Delayed Deep Deterministic Policy Gradient (TD3), as presented by Fujimoto et al. [
24] is employed.
Maintaining convergence is a daunting task, given the large number of hyperparameters and the large search space. Several issues occurred, ranging from plain divergence, getting stuck in local optimum caused by the amounts of noise, to catastrophic forgetting, which is highly influenced by the experience replay window. Values for such parameters must follow certain rules and constraints; however, the efficiency of the final model can only be evaluated empirically, after it performed a number of optimizations. This approach, while it delivers notable results, is both time and resource consuming.
The algorithm relies on a fixed initial state, based on the identity kernel. It starts with a high probability of generating randomized kernel configurations, which are added to the initial state. This approach, when compared to generating kernels from scratch, brings multiple advantages: it permits fine control regarding how much the image will be altered post-convolution since it applies ’masks’ to the identity kernels, while also attaining better results within fewer epochs. The probability of randomly generating kernels decreases linearly after each epoch; during this time, the neural network is continuously trained through experience replay.
As the probability lowers, the actor is queried more often for recommended actions. An action also contains a small amount of uniformly distributed noise (0.5%–5%), in order to perform exploration around the suggested kernel configuration.
Kernels (De)Compression: This method ensures that generated kernels are symmetrical to one of the reference lines (horizontal, vertical, first and second diagonal). As an example, states reached by the reinforcement learning algorithm are expanded into kernels by duplicating values and are then written in the convolutional preprocessor for further usage. Likewise, current kernels are ’compressed’ by this module into states by removing duplicates and being fed to the kernel optimizer. This directly employs working with a smaller number of variables and prevents overfitting, up to a point. Observations reveal that non-symmetric kernels produce better scores on the training set but do not generalize well.
2.1. Approaching the Overfitting Issue
As stated in [
25], reinforcement learning algorithms are environment-dependent and have difficulty in adapting to new test cases. Their task is to optimize solutions for a single specific problem. The same set of samples is used both as a ’training set’ and ’testing set’, therefore heavily encouraging overfitting behavior, since the model specializes in solving only the problem described by the given inputs. The model’s performance in the context of fresh input data is never considered, as its purpose is to learn to optimally handle only the particular situation described in the training set. Therefore, when transitioning to a new set of inputs (i.e., a new environment), the overfitted model will not necessarily produce the expected outputs.
In the current scenario, the algorithm is required to produce kernels that generalize well over a larger set of images. This is addressed by limiting the number of training epochs and the number of convolution layers. Additionally, the convolutional preprocessor does not use any sort of downsampling techniques, thus ensuring the fact that the kernels will only handle generic, low-level features. The symmetry produced by mirroring values inside the kernels also ensures greater compatibility with a larger, more diverse set of samples, as it reduces the overall number of variables. The intuition behind the concept relies within the fact that a convolution filter captures more information, and starts particularizing a feature once it grows in size. This ensures better accuracy at the cost of genericity. As an example, a kernel with the same size as the input sample acts as a fully-connected dense layer; this resembles a good approximator, but the resulted multivariable function will perform correctly only on the samples that it was trained on, because of memorization. By using a smaller number of variables in the convolutional model, this situation can be partially prevented.
2.2. Evaluation
The model was trained on a set of 30 images from Brno Mobile OCR Dataset [
11], with no external information about the dataset. The performance of this implementation was validated with a testing set which consists of 10,000 successive images from the same dataset using 3 relevant metrics.
Due to a dataset constraint, a white padding was added around the images to ensure they are of the same size—these new images are used in the presented work for both training and evaluation. Postprocessing artifacts might appear because of this padding, which can lead to an increase in the edit distance when comparing to the ground truth.
The results are presented in
Figure 5a–c, each illustrating a different metric—Character Error Rate (CER), Word Error Rate (WER), Longest Common Subsequence Error (LCSE)—used for comparison between Tesseract’s output and the ground truth. CER and WER rely on the Levenshtein distance applied to either characters or encoded words; LCSE, on the other hand, will compare the lengths of the resulted texts using Formula (5).
Dashed lines represent linear regressions performed by minimizing the least-squares error, for the sake of clarity.
The existence of outliers suggests that two sets of points cannot be perfectly grouped into clusters; this implies that the current solution is not effective for every sample. Numerical results, including precision and recall, are available in
Table 1.
Further evaluation investigates the performance of the implementation from a qualitative point of view. Samples which generate a minimal number of errors during the OCR process are desired. Since the Levenshtein distance does not strictly enforce this condition (e.g., a one character improvement in all the samples might be equivalent to a 100 characters improvement in one sample), it is important to properly validate the efficiency of the preprocessing step. A histogram for each metric was computed with the purpose of observing how the distributions are affected.
Figure 6a (CER),
Figure 6b (WER) and
Figure 6c (LCSE) successfully illustrate the comparison between the preprocessed and original samples in the testing set, with respect to each metric.
A quick observation reveals 2 spikes in the distributions related to the CER and WER produced by the original samples (
Figure 6a,b). These suggest that the most frequent error affects the recognition of all characters (CER = 1) or words (WER = 1), thus manifesting at the block/segment level.
The preprocessing method, on the other hand, is observed to shift the peak of each distribution towards the minimal error rate and highly improve the recognition process.
A visual comparison between the original and the preprocessed images is available in
Table 2. The result of the character recognition process is also included. An interesting observation is that the adapted samples, while ensuring improved OCR, are not necessarily easier to read by the human eye, as there is nothing to guide the algorithm in that direction.
Table 3 presents the concrete values used for each filter in the convolutional preprocessor. The first layer performs a basic grayscale conversion with emphasis on the green and blue channels while reducing the weight of the red nuances—which are mostly encountered in the background. The next layers have the role of adapting the received data by performing convolutions. The final layer will additionally attempt to scale the values to a valid interval; clipping values to 0–255 is still required.
The kernels work in synergy towards the final result; as there are no interval constraints in between the layers, the model has additional freedom for data manipulation. This implies that intermediate samples might not necessarily resemble valid images, as the pixels’ values might be outside the grayscale interval. For the sake of presenting visual examples of what each preprocessing stage does, the following samples are rescaled to the valid interval after each convolution; this is only for demonstration purposes—the preprocessor will still use the non-scaled values. The results can be observed in
Table 4.
Observations revealed that the preprocessor’s behavior is influenced by white padding added to the images; samples that contain white padding are treated differently than those which do not. Tesseract-compatible results are achieved in both cases, nonetheless. The training procedure, however, was made using only padded images for the ease of implementation (in order to satisfy dataset constraints). e.g., the sample illustrated in
Table 4 does not contain any white padding, yet the preprocessed sample is compatible with Tesseract’s OCR preferences.
The preprocessor works by attempting to discover a compromise between a good contrast and the accuracy of each character’s shape, while also attempting to fix Tesseract’s segmentation problem. Once certain parts of the text are recognized, the problem of optimizing for contrast or for ‘readability’ arises as the information found in the image is many times insufficient for doing both. This is mostly specific to the OCR-engine and to the sample (e.g., colors, amount of text, distortions, etc.); in many situations, samples with good contrast and damaged characters are preferred (see
Table 2). However, if the image permits, the shapes of the characters are also corrected up to a point and, additionally, certain amounts of noise (up to the size of a character fragment) are removed, as shown in
Table 4.
2.3. Discussion
The current algorithm relies on randomness to a certain degree. Informed decisions are made by the reinforcement learning model but noise is still applied in order to perform additional exploration. Given this fact, the consistency of the results cannot be guaranteed and neither their optimality.
Moreover, there exists a compromise between score and generalization. A better score usually requires a larger training period; however, this also prompts the algorithm to start over-optimizing the kernels and manifest a tendency to overfit. The ’simplicity’ of the convolutional processor might prevent this up to a point, although empirically it was discovered that the network still favors samples from the training set.
Regarding the chosen optimization metric, the Levenshtein distance offers good granularity and relevance, thus making a good candidate for a score function. However, in certain scenarios it might favor undesired results; as an example, during the training phase, the algorithm might focus on producing more noisy samples which resolve to ’random characters’, instead of having fewer samples which are correctly identified. This behavior is attenuated, as the model converges to more optimal solutions.
The solution proves powerful enough to correct various image defects up to the size of incomplete characters, as shown in
Table 4.
From a methodological point of view, a comparison is made between the presented solution and similar projects which discuss the subject of image preprocessing for enhancing OCR results. Therefore,
Table 5 illustrates the advantages and disadvantages identified for each method.
A comparison to similar projects is performed using relative metrics, i.e., comparing the performance of the raw OCR engine and then the performance of the complete implementation (see
Table 6). This way, external factors such as performances of different OCR engines and differences of difficulty between datasets are minimized. Both absolute and relative changes are determined for each implementation, using the available results as either one or the other is referenced in similar projects. The relative change indicates, as a percentage, the performance increase after OCR enhancement. This number, however, is biased towards smaller starting values, and can yield misleading results in certain cases: e.g., a performance increase from 0.01 (1%) to 0.02 (2%) has a relative change of 100%, yet this does not apply for 0.98 (98%) to 0.99 (99%). Therefore, this metric is to be compared with the absolute change for a better understanding of the results.
A non-relative comparison can be made in the context of considering the same dataset but for different OCR engines. In this case, the current solution (CER = 0.384, WER = 0.593) performs worse than the state-of-the-art baseline GRU network (CER = 0.0033, WER = 0.0193), presented in [
20].
The improvement can most likely be justified by the following facts: (1) this approach ensures numerically oriented optimizations by taking into account uncanny image characteristics which might seem odd to the human eye, but can offer good insight to the OCR engine; (2) the chosen preprocessing method offers enough flexibility to accommodate the transformations required for the text to be properly interpreted.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



















