Forecasting of Coalbed Methane Daily Production Based on T-LSTM Neural Networks



Abstract
:1. Introduction
2. Related Work
3. Data and Methods
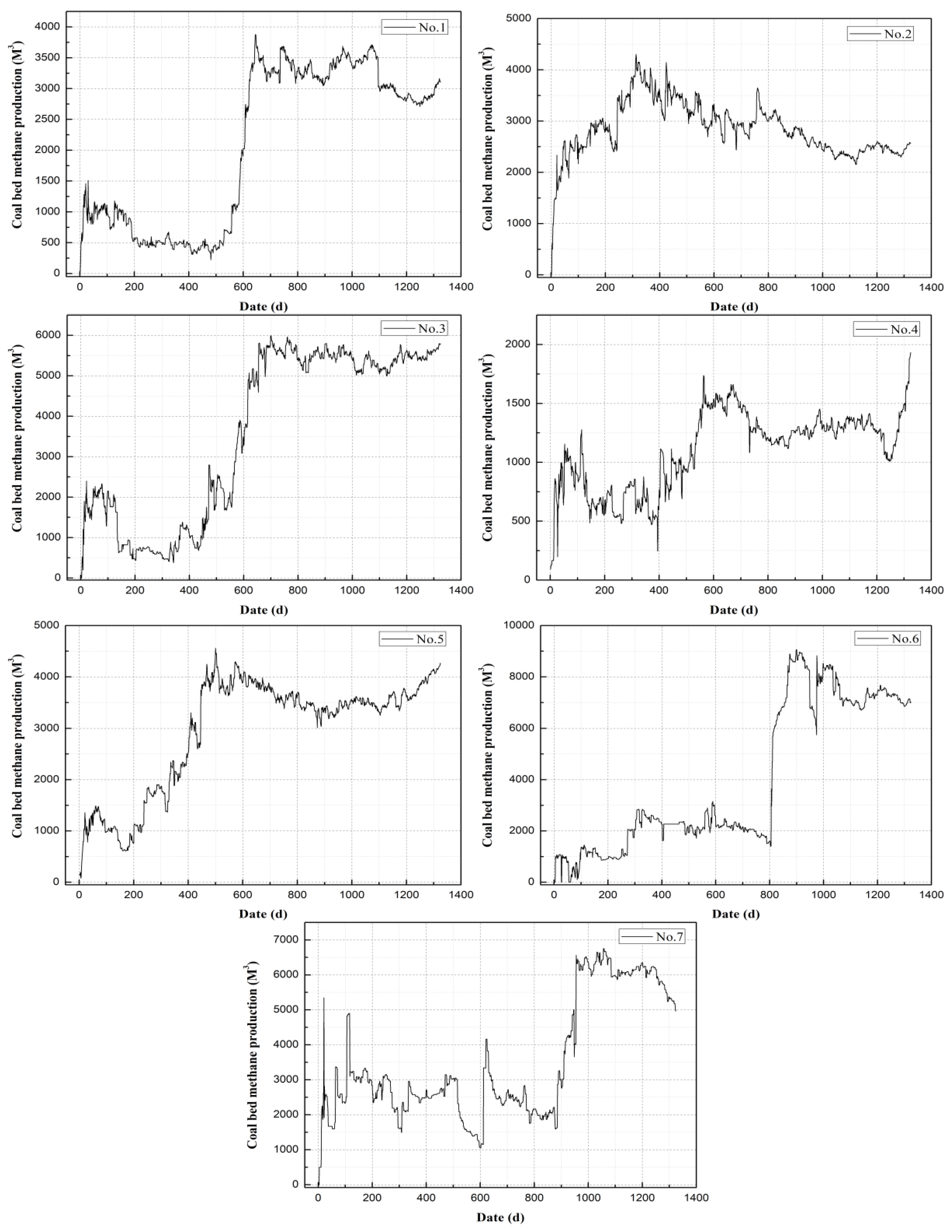
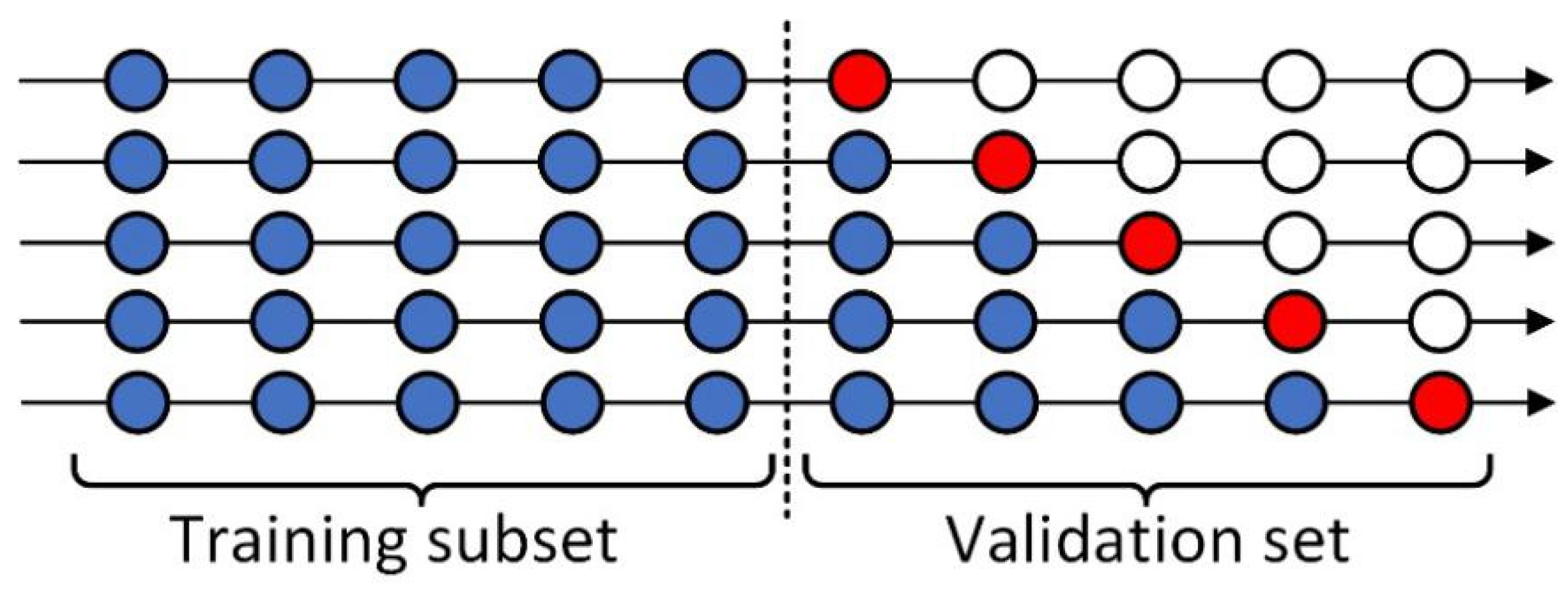
3.1. Data Description
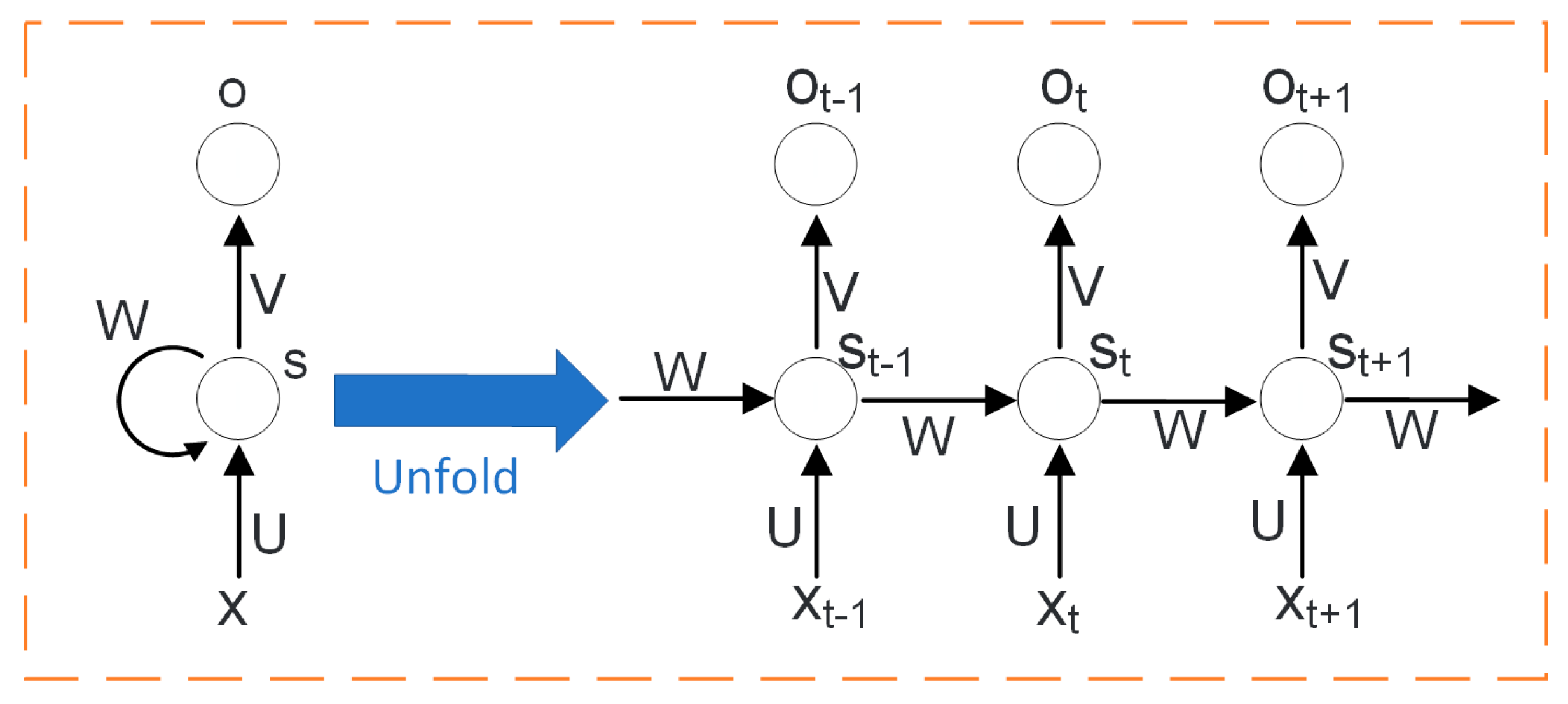
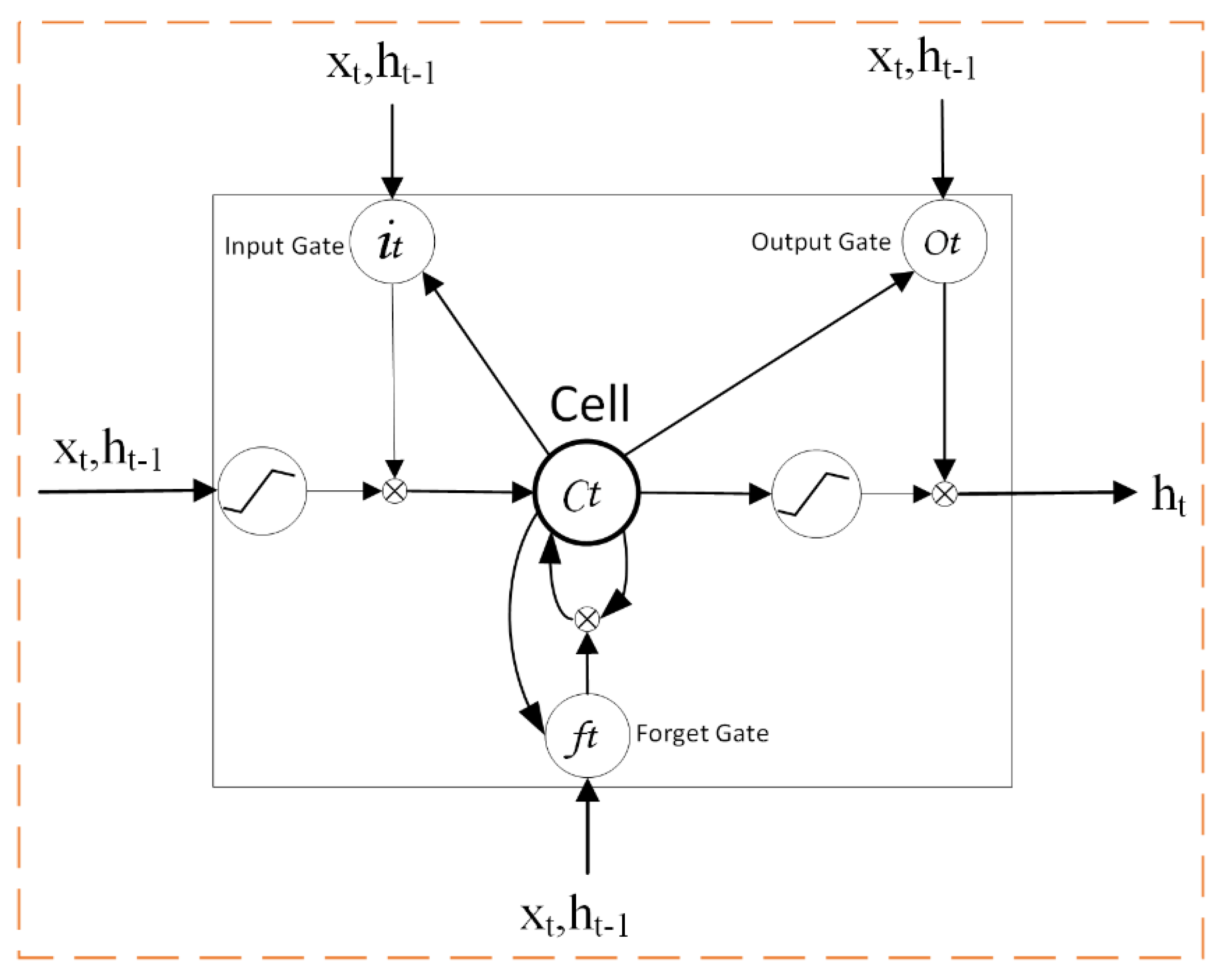
3.2. LSTM Neural Network
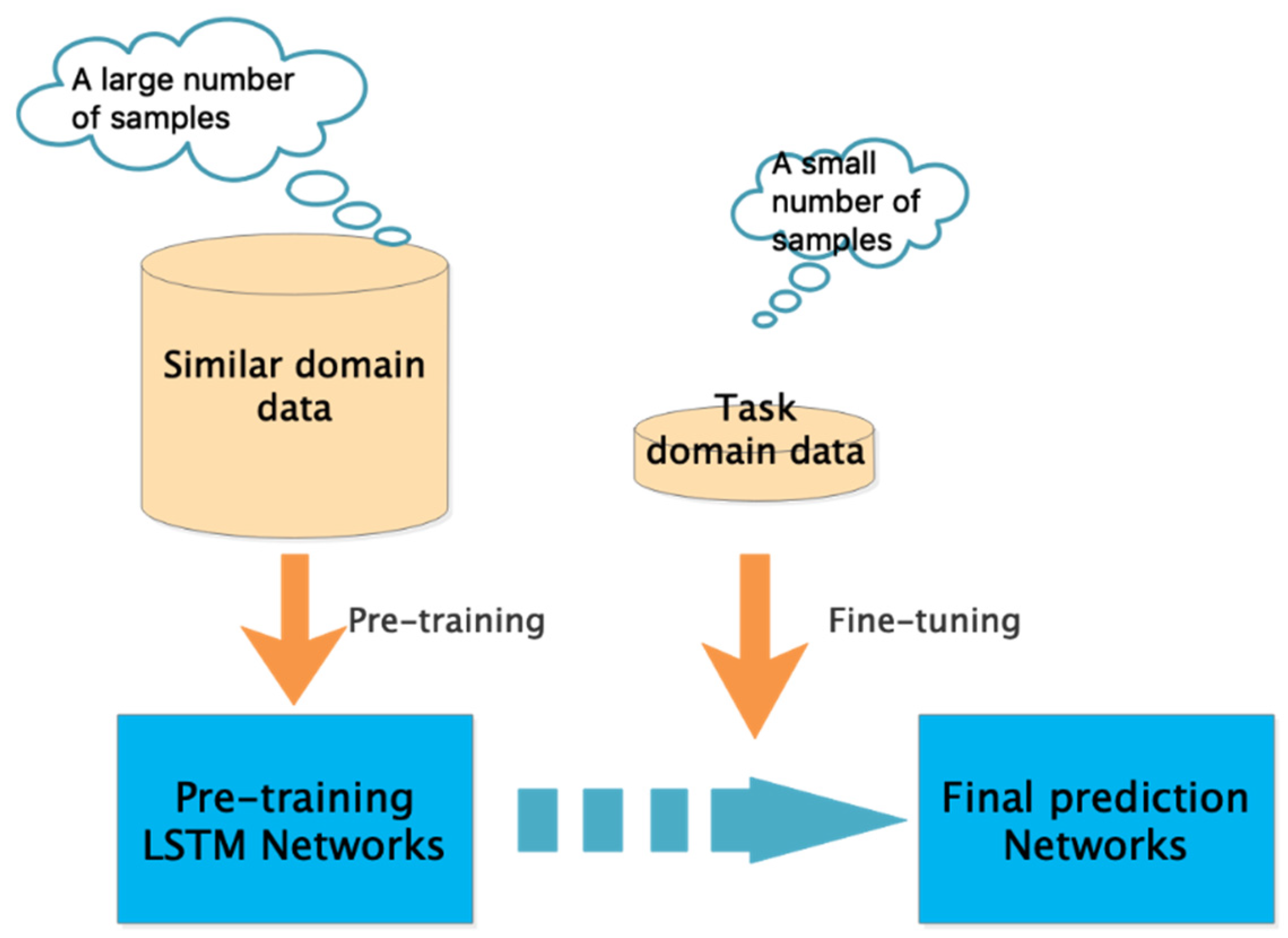
3.3. T-LSTM Model
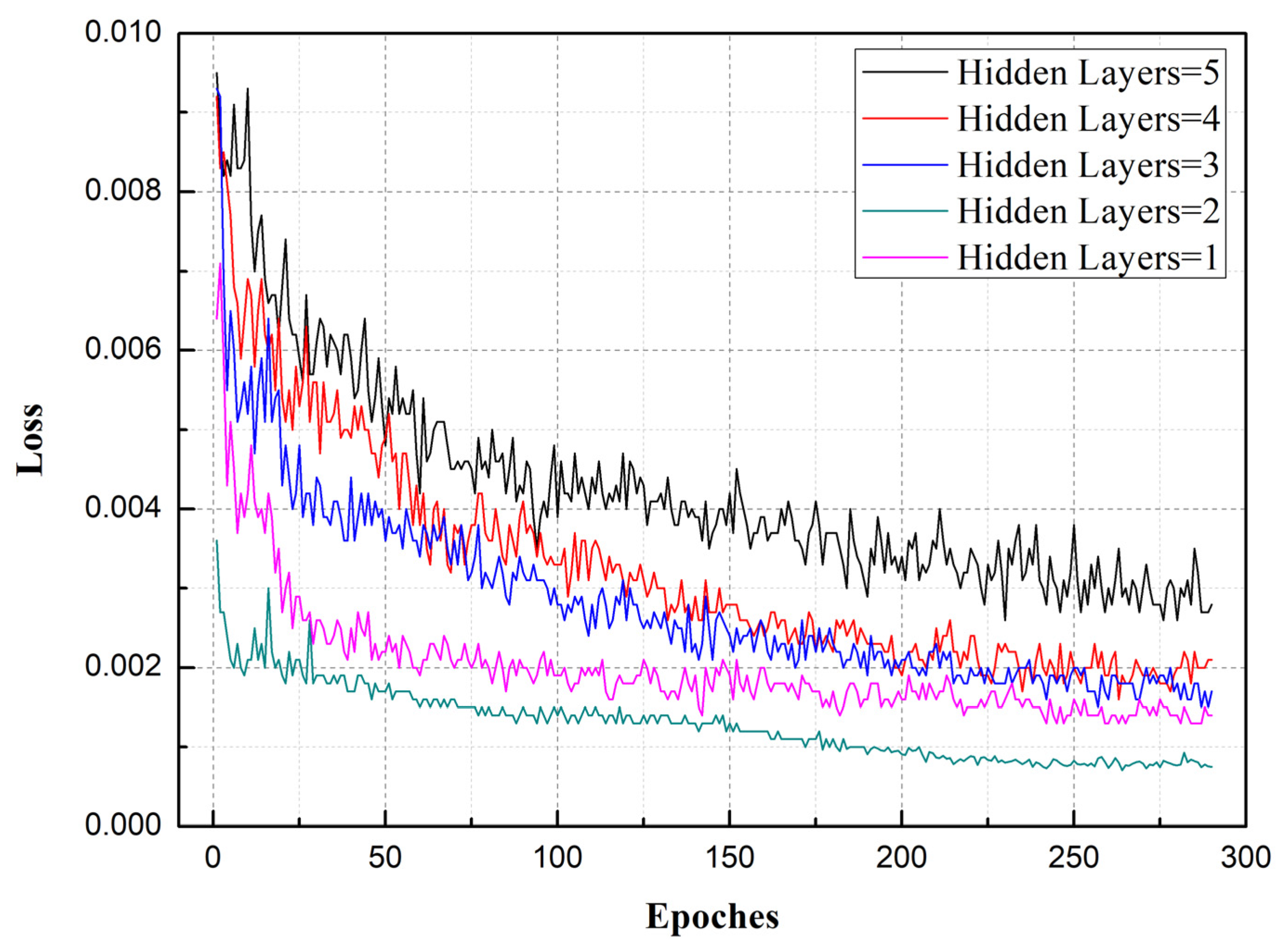
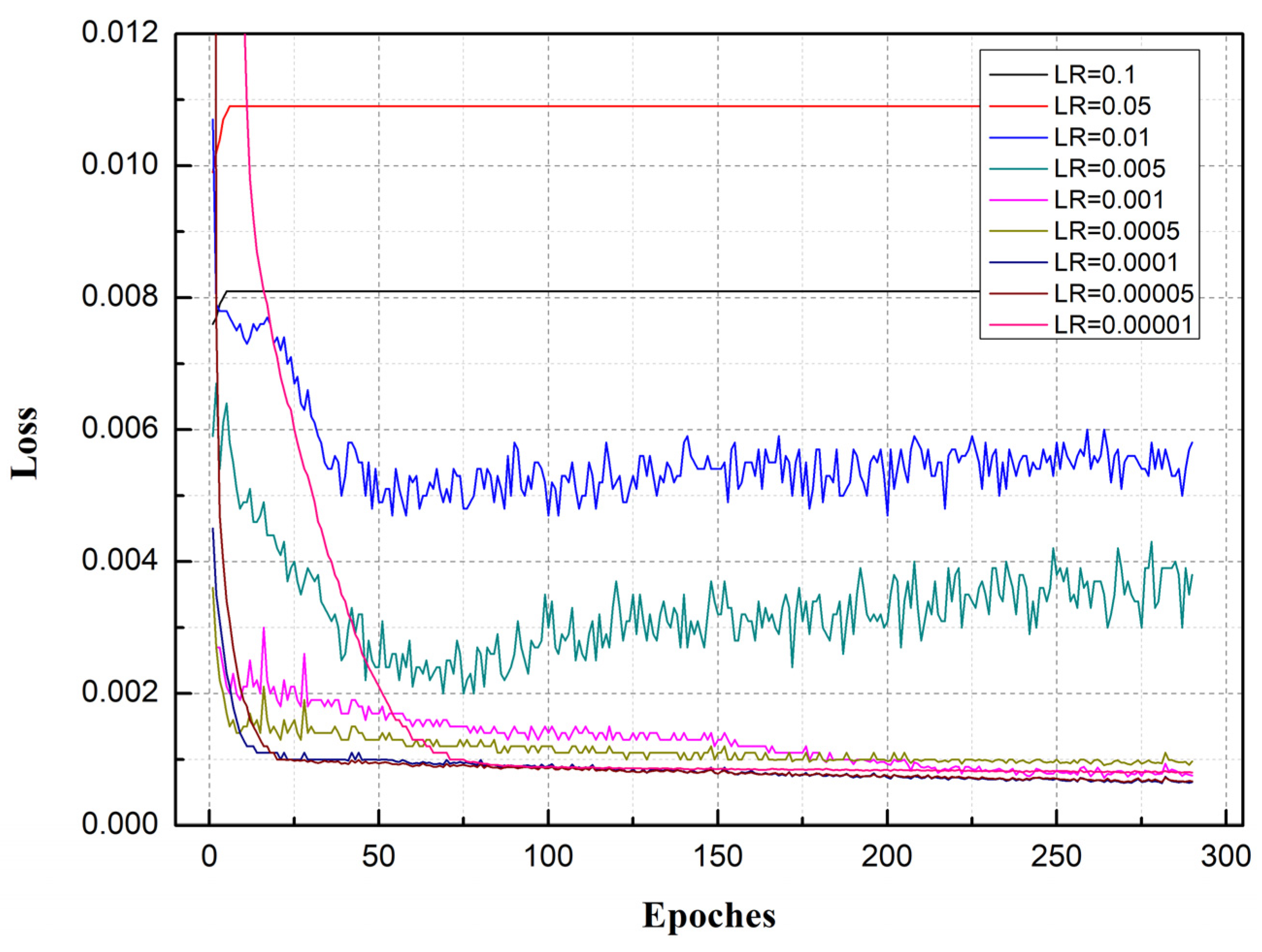
4. T-LSTM Network Training and Parameter Optimization
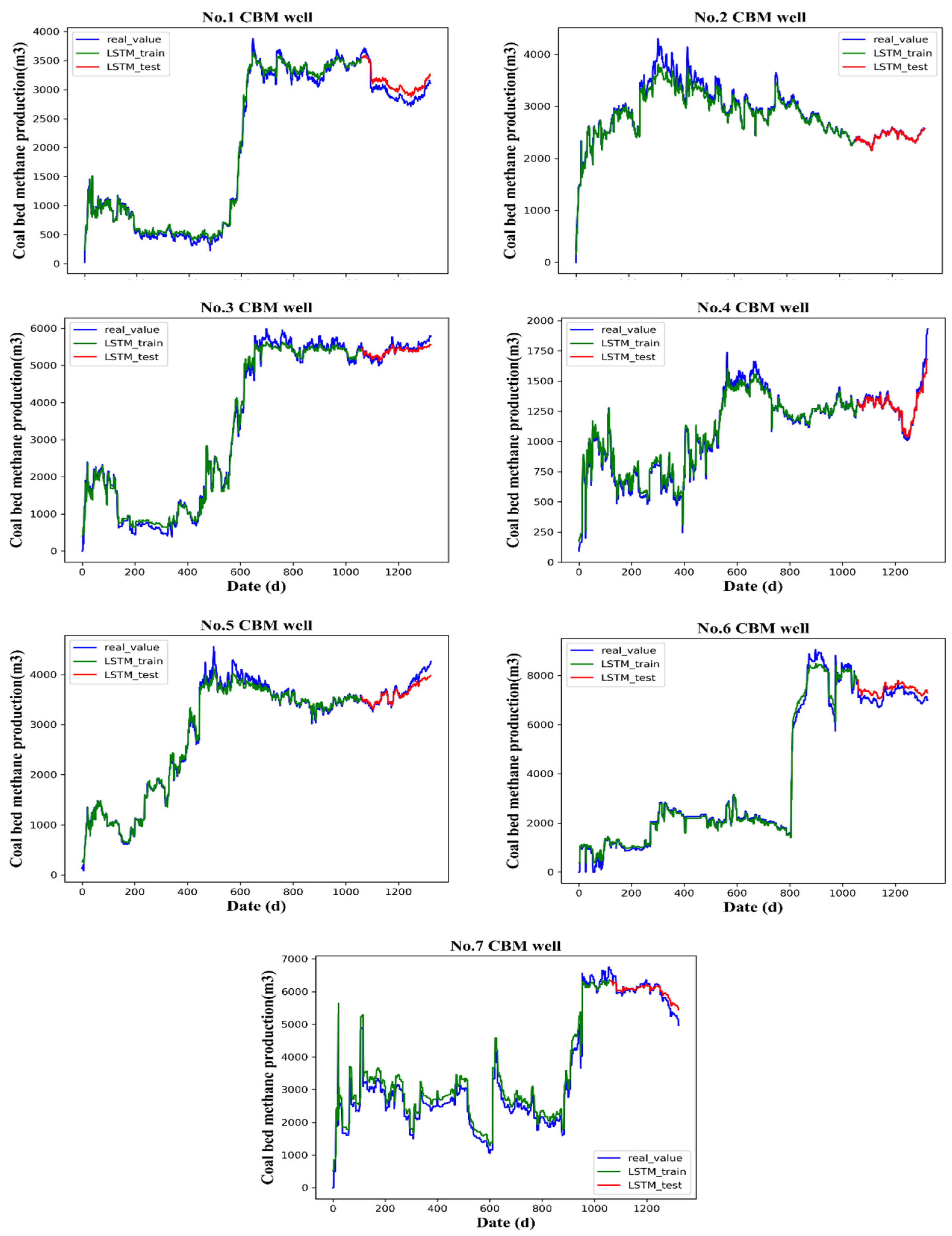
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yun, M.G.; Rim, M.W.; Han, C.N. A model for pseudo-steady and non-equilibrium sorption in coalbed methane reservoir simulation and its application. J. Nat. Gas Sci. Eng. 2018, 54, 342–348. [Google Scholar] [CrossRef]
- Xu, H. Research on Particle Swarm Optimization Algorithm Improvement and Its Application in the CBM Production Forecast; China University of Mining and Technology: Jiangsu, China, 2013. [Google Scholar]
- Wang, S.Q. Gas Time Series Prediction and Anomaly Detection Based on Deep Learning; China University of Mining and Technology: Jiangsu, China, 2018. [Google Scholar]
- Ping, X.; Xiaochun, L.; Zhiming, F.; Bing, B. Application of Quantification Theory to predict Coal Methane Content. Disaster Adv. 2012, 5, 1609–1614. [Google Scholar]
- Clarkson, C. Production data analysis of unconventional gas wells: Review of theory and best practices. Int. J. Coal Geol. 2013, 109, 101–146. [Google Scholar] [CrossRef]
- Li, H.; Li, Z.; Zhang, H.; Hu, J.T. Study of Coalbed Methane Production Forecast at Different Stages by Using Weibull Model. J. Oil Gas Technol. 2013, 35, 100–103. [Google Scholar]
- Xu, B.X.; Li, X.F.; Hu, X.H.; Hu, S.M. Type curves for production prediction of coalbed methane wells. J. China Univ. Min. Technol. 2011, 40, 743–747. [Google Scholar]
- Jang, H.; Kim, Y.; Park, J.; Lee, J. Prediction of production performance by comprehensive methodology for hydraulically fractured well in coalbed methane reservoirs. Int. J. Oil Gas Coal Technol. 2019, 20, 143–168. [Google Scholar] [CrossRef]
- Chen, X.J.; Li, P.F.; Li, P.; Hui, P.; Guo, Y.H. Application of Multiple Stepwise Regression Analysis in Prediction of Coal Seam Gas Content (in Chinese). Coal Eng. 2019, 51, 106–111. [Google Scholar]
- Li, D.; Cheng, S.; Wang, Z. The Prediction on Coal Field’s CBM (Coalbed Methane) Resource (in Chinese). Shanxi Sci. Technol. 2015, 1, 54–56. [Google Scholar]
- Cipolla, C.L.; Lolon, E.P.; Erdle, J.C.; Rubin, B. Reservoir Modeling in Shale-Gas Reservoirs. SPE Reserv. Eval. Eng. 2010, 13, 638–653. [Google Scholar] [CrossRef]
- Zhao, Y.-L.; Zhao, L.; Wang, Z.-M.; Yang, H. Numerical simulation of multi-seam coalbed methane production using a gray lattice Boltzmann method. J. Pet. Sci. Eng. 2019, 175, 587–594. [Google Scholar] [CrossRef]
- Zhou, F. History matching and production prediction of a horizontal coalbed methane well. J. Pet. Sci. Eng. 2012, 96, 22–36. [Google Scholar] [CrossRef]
- Lü, Y.; Tang, D.; Xu, H.; Tao, S. Productivity matching and quantitative prediction of coalbed methane wells based on BP neural network. Sci. China Ser. E Technol. Sci. 2011, 54, 1281–1286. [Google Scholar] [CrossRef]
- King, G. Material-Balance Techniques for Coal-Seam and Devonian Shale Gas Reservoirs with Limited Water Influx. SPE Reserv. Eng. 1993, 8, 67–72. [Google Scholar] [CrossRef]
- Shi, J.; Chang, Y.; Wu, S.; Xiong, X.; Liu, C.; Feng, K. Development of material balance equations for coalbed methane reservoirs considering dewatering process, gas solubility, pore compressibility and matrix shrinkage. Int. J. Coal Geol. 2018, 195, 200–216. [Google Scholar] [CrossRef]
- Sun, Z.; Shi, J.; Zhang, T.; Wu, K.; Miao, Y.; Feng, D.; Sun, F.; Han, S.; Wang, S.; Hou, C.; et al. The modified gas-water two phase version flowing material balance equation for low permeability CBM reservoirs. J. Pet. Sci. Eng. 2018, 165, 726–735. [Google Scholar] [CrossRef]
- Liu, Z.; Yang, X.; Zhang, J. Logging Predicting for Coalbed Gas Content in Eastern Block of Ordos Basin. Geol. Sci. Technol. Inf. 2014, 33, 95–99. [Google Scholar]
- Xu, H.; Tang, D.Z.; Liu, D.M.; Tang, S.H.; Yang, F.; Chen, X.Z.; He, W.; Deng, C.M. Study on coalbed methane well productivity by using artificial neural network (in Chinese). China Coal 2012, 38, 9–13. [Google Scholar]
- Lv, Y.M.; Tang, D.Z.; Li, Z.P.; Shao, X.J.; Hu, H. Fitting and predicting models for coalbed methane wells dynamic productivity (in Chinese). J. China Coal Soc. 2011, 36, 1481–1485. [Google Scholar]
- Ma, X.; Zhang, C.; Chen, X.F. A Method Combined Principal Component Analysis and BP Artifical Neural Network for Coalbed Methane (CBM) Wells to Predict Productivity (in Chinese). Sci. Technol. Ind. 2013, 13, 97–100. [Google Scholar]
- Xia, H.; Qin, Y.; Zhang, L.; Cao, Y.; Xu, J. Forecasting of coalbed methane (CBM) productivity based on rough set and least squares support vector machine. In Proceedings of the 2017 25th International Conference on Geoinformatics, Buffalo, NY, USA, 2–4 August 2017; pp. 1–6. [Google Scholar]
- Li, C.S.; Tan, M.X.; Zhang, K.J. Research on Single Well Production Prediction Based on Improved BP Neural Networks (in Chinese). Sci. Technol. Eng. 2011, 11, 7766–7769. [Google Scholar]
- Yang, Y.G.; Qin, Y. Study and application on random dynamic model of the coalbed methane output forecasting (in Chinese). J. China Coal Soc. 2001, 2, 122–125. [Google Scholar]
- Bai, Y.; Zeng, B.; Li, C.; Zhang, J. An ensemble long short-term memory neural network for hourly PM2.5 concentration forecasting. Chemosphere 2019, 222, 286–294. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Peng, L.; Yao, X.; Cui, S.; Hu, Y.; You, C.; Chi, T. Long short-term memory neural network for air pollutant concentration predictions: Method development and evaluation. Environ. Pollut. 2017, 231, 997–1004. [Google Scholar] [CrossRef] [PubMed]
- Wen, C.; Liu, S.; Yao, X.; Peng, L.; Li, X.; Hu, Y.; Chi, T. A novel spatiotemporal convolutional long short-term neural network for air pollution prediction. Sci. Total. Environ. 2019, 654, 1091–1099. [Google Scholar] [CrossRef]
- Zhao, J.; Deng, F.; Cai, Y.; Chen, J. Long short-term memory - Fully connected (LSTM-FC) neural network for PM2.5 concentration prediction. Chemosphere 2019, 220, 486–492. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.Y.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef] [Green Version]
- Tian, Y.; Zhang, K.; Li, J.; Lin, X.; Yang, B. LSTM-based traffic flow prediction with missing data. Neurocomputing 2018, 318, 297–305. [Google Scholar] [CrossRef]
- Li, Y.; Cao, H. Prediction for Tourism Flow based on LSTM Neural Network. Procedia Comput. Sci. 2018, 129, 277–283. [Google Scholar] [CrossRef]
- Ma, X.; Tao, Z.; Wang, Y.; Yu, H.; Wang, Y. Long short-term memory neural network for traffic speed prediction using remote microwave sensor data. Transp. Res. Part C Emerg. Technol. 2015, 54, 187–197. [Google Scholar] [CrossRef]
- Fischer, T.; Krauss, C. Deep learning with long short-term memory networks for financial market predictions. Eur. J. Oper. Res. 2018, 270, 654–669. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.Y.; Won, C.H. Forecasting the volatility of stock price index: A hybrid model integrating LSTM with multiple GARCH-type models. Expert Syst. Appl. 2018, 103, 25–37. [Google Scholar] [CrossRef]
- Peng, L.; Liu, S.; Liu, R.; Wang, L. Effective long short-term memory with differential evolution algorithm for electricity price prediction. Energy 2018, 162, 1301–1314. [Google Scholar] [CrossRef]
- Fang, Z.Q.; Wang, X.H.; Xia, T. Electricity Sales Forecasting Based on Long-short Term Memory Networks. Electr. Power Eng. Technol. 2018, 37, 78–83. (In Chinese) [Google Scholar]
- Sagheer, A.; Kotb, M. Time series forecasting of petroleum production using deep LSTM recurrent networks. Neurocomputing 2019, 323, 203–213. [Google Scholar] [CrossRef]
- Chen, Z.; Mauricio, A.; Li, W.; Gryllias, K. A deep learning method for bearing fault diagnosis based on Cyclic Spectral Coherence and Convolutional Neural Networks. Mech. Syst. Signal Process. 2020, 140, 1–16. [Google Scholar] [CrossRef]
- Chemali, E.; Kollmeyer, P.; Preindl, M.; Ahmed, R.; Emadi, A.; Kollmeyer, P. Long Short-Term Memory Networks for Accurate State-of-Charge Estimation of Li-ion Batteries. IEEE Trans. Ind. Electron. 2017, 65, 6730–6739. [Google Scholar] [CrossRef]
- Cortez, B.; Carrera, B.; Kim, Y.-J.; Jung, J.-Y. An architecture for emergency event prediction using LSTM recurrent neural networks. Expert Syst. Appl. 2018, 97, 315–324. [Google Scholar] [CrossRef]
- Kumar, J.; Goomer, R.; Singh, A.K. Long Short Term Memory Recurrent Neural Network (LSTM-RNN) Based Workload Forecasting Model For Cloud Datacenters. Procedia Comput. Sci. 2018, 125, 676–682. [Google Scholar] [CrossRef]
- Li, C.; Wang, Z.; Rao, M.; Belkin, D.; Song, W.; Jiang, H.; Yan, P.; Li, Y.; Lin, P.; Hu, M.; et al. Long short-term memory networks in memristor crossbar arrays. Nat. Mach. Intell. 2019, 1, 49–57. [Google Scholar] [CrossRef]
- Petersen, N.C.; Rodrigues, F.; Pereira, F.C. Multi-output bus travel time prediction with convolutional LSTM neural network. Expert Syst. Appl. 2019, 120, 426–435. [Google Scholar] [CrossRef] [Green Version]
- Gao, W.; Farahani, M.R.; Aslam, A.; Hosamani, S. Distance learning techniques for ontology similarity measuring and ontology mapping. Clust. Comput. 2017, 20, 959–968. [Google Scholar] [CrossRef]
- Xiong, Z.; Wu, Y.; Ye, C.; Zhang, X.; Xu, F. Color image chaos encryption algorithm combining CRC and nine palace map. Multimedia Tools Appl. 2019, 78, 31035–31055. [Google Scholar] [CrossRef]
- Cordero, A.; Jaiswal, J.P.; Torregrosa, J.R. Stability analysis of fourth-order iterative method for finding multiple roots of non-linear equations. Appl. Math. Nonlinear Sci. 2019, 4, 43–56. [Google Scholar] [CrossRef] [Green Version]
- Voit, M.; Meyer-Ortmanns, H. Predicting the separation of time scales in a heteroclinic network. Appl. Math. Nonlinear Sci. 2019, 4, 279–288. [Google Scholar] [CrossRef] [Green Version]
- Bergmeir, C.; Benítez, J.M. On the use of cross-validation for time series predictor evaluation. Inf. Sci. 2012, 191, 192–213. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
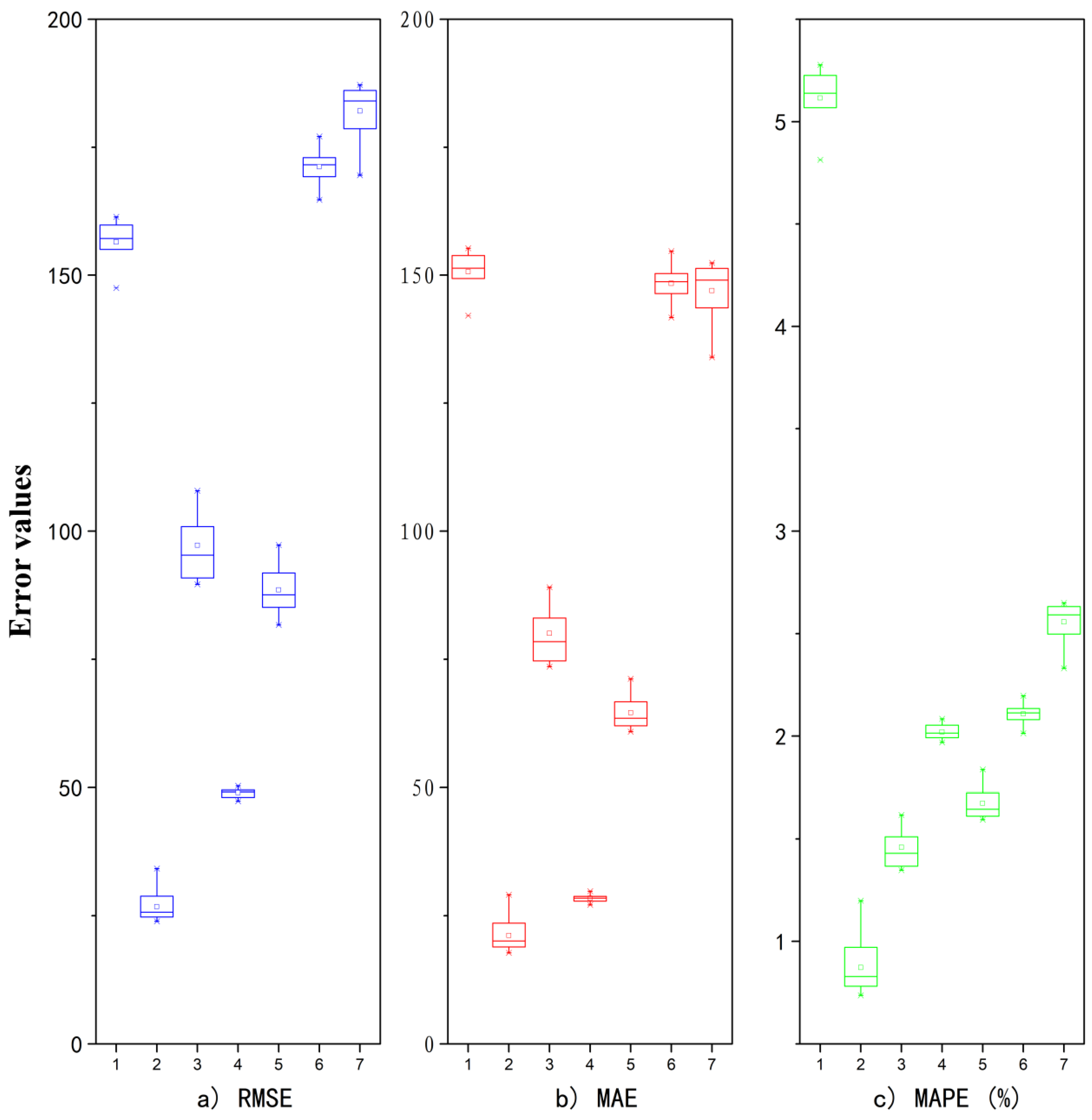
| Well | RMSE (m3) | MAE (m3) | MAPE (%) |
|---|---|---|---|
| 1 | 155.04 | 149.34 | 5.07 |
| 2 | 25.79 | 20.17 | 0.83 |
| 3 | 90.86 | 74.68 | 1.37 |
| 4 | 47.33 | 27.14 | 1.97 |
| 5 | 89.02 | 64.55 | 1.67 |
| 6 | 174.53 | 151.75 | 2.16 |
| 7 | 184.06 | 148.71 | 2.59 |
| Prediction Model | Average Relative Error (%) |
|---|---|
| BP neural networks [2] | 6.04 |
| SVR [2] | 4.28 |
| HPSO-SVR [2] | 2.44 |
| IPSO-SVM [2] | 2.44 |
| HPSO-SVM [2] | 2.20 |
| Type curves [7] | 16 |
| Decline curves [8] | 5 |
| Multiple stepwise regression [9] | 13.6 |
| Multiple regression [13] | 7.87 |
| BP neural networks [13] | 2.25 |
| BP neural networks [15] | 1.35 |
| BP neural networks [16] | 4.61 |
| LS-SVM [18] | 7.91 |
| T-LSTM | 2.20 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Rui, X.; Fan, Y.; Yu, T.; Ju, Y. Forecasting of Coalbed Methane Daily Production Based on T-LSTM Neural Networks. Symmetry 2020, 12, 861. https://doi.org/10.3390/sym12050861
Xu X, Rui X, Fan Y, Yu T, Ju Y. Forecasting of Coalbed Methane Daily Production Based on T-LSTM Neural Networks. Symmetry. 2020; 12(5):861. https://doi.org/10.3390/sym12050861
Chicago/Turabian StyleXu, Xijie, Xiaoping Rui, Yonglei Fan, Tian Yu, and Yiwen Ju. 2020. "Forecasting of Coalbed Methane Daily Production Based on T-LSTM Neural Networks" Symmetry 12, no. 5: 861. https://doi.org/10.3390/sym12050861
APA StyleXu, X., Rui, X., Fan, Y., Yu, T., & Ju, Y. (2020). Forecasting of Coalbed Methane Daily Production Based on T-LSTM Neural Networks. Symmetry, 12(5), 861. https://doi.org/10.3390/sym12050861