Multi-View Pose Generator Based on Deep Learning for Monocular 3D Human Pose Estimation



Abstract
:1. Introduction
- We introduce an end-to-end network to implement a multi-view 3D pose estimation framework with single-view 2D pose as input;
- We establish a strong MvPG to predict the 2D poses of multiple views from the 2D poses in a single view;
- We present a simple and effective multi-view 2D pose datasets generation method.
- We propose a novel loss function for constraining both joint points and bone length.
2. Related Work
2.1. Multi-View 3D Pose Estimation
2.2. Single-View 3D Pose Estimation
2.3. GCNs for 3D Pose Estimation
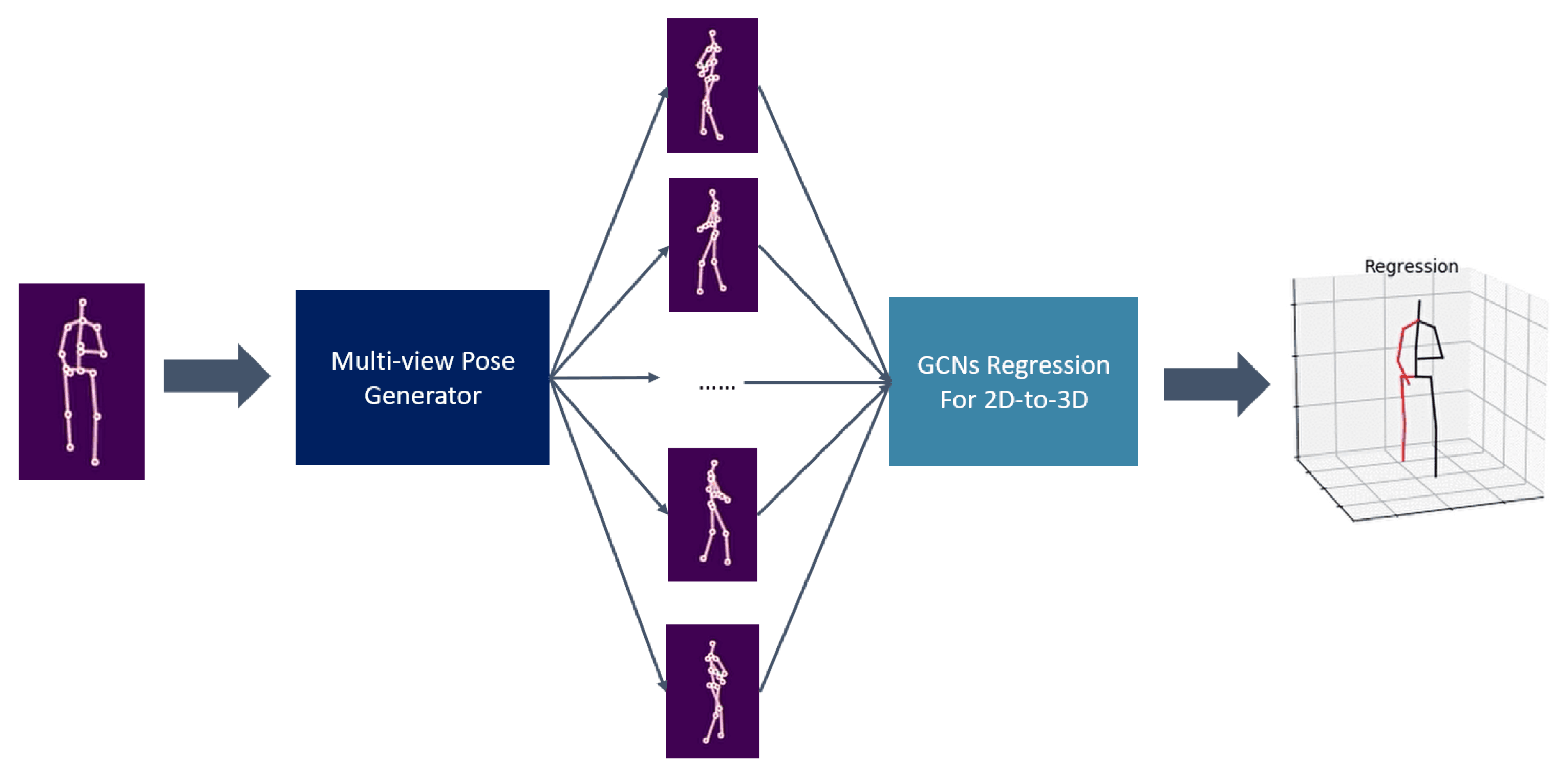
3. Framework
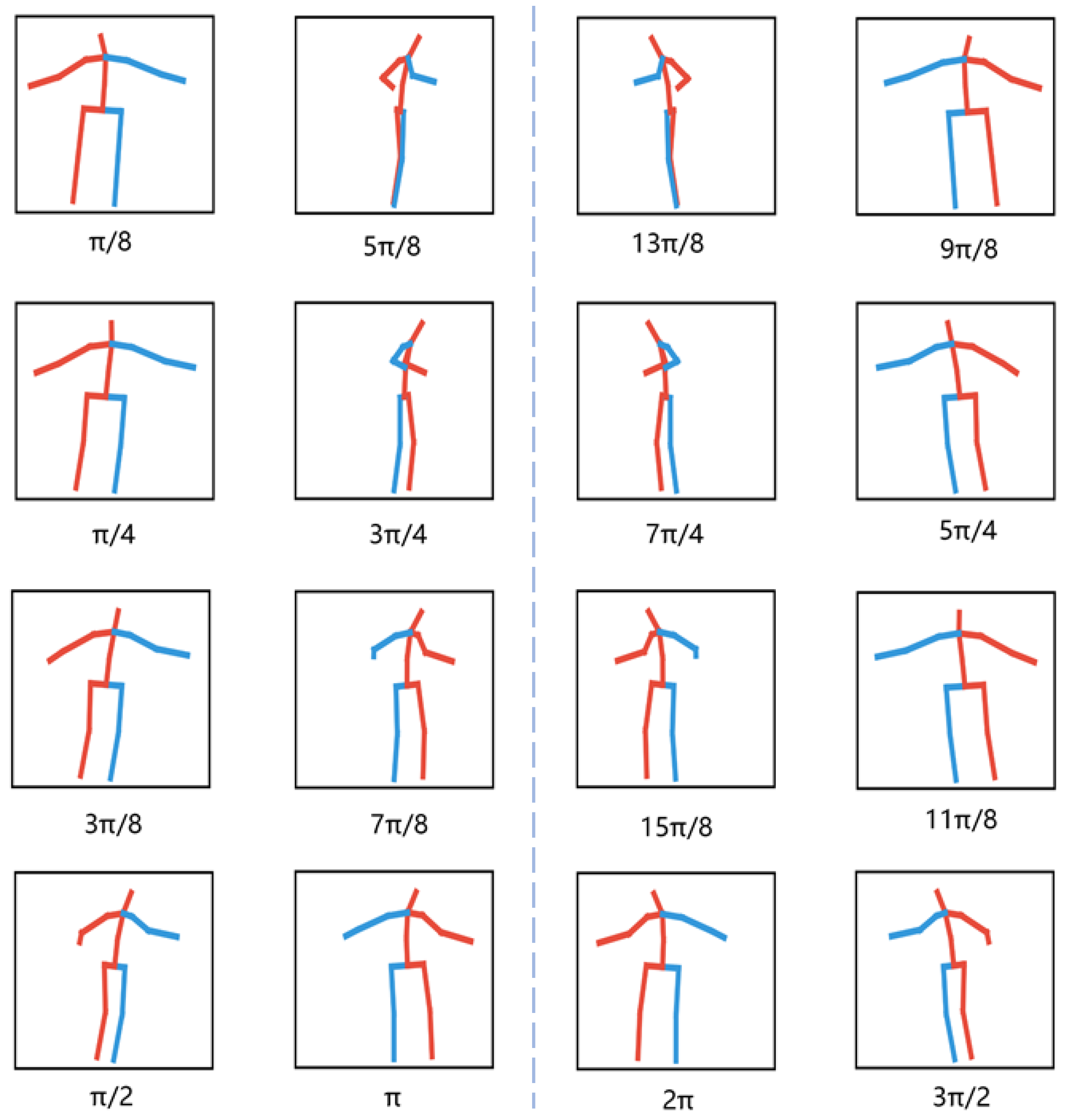
3.1. Multi-View Pose Generator
3.2. 2D Pose Data Augmentation
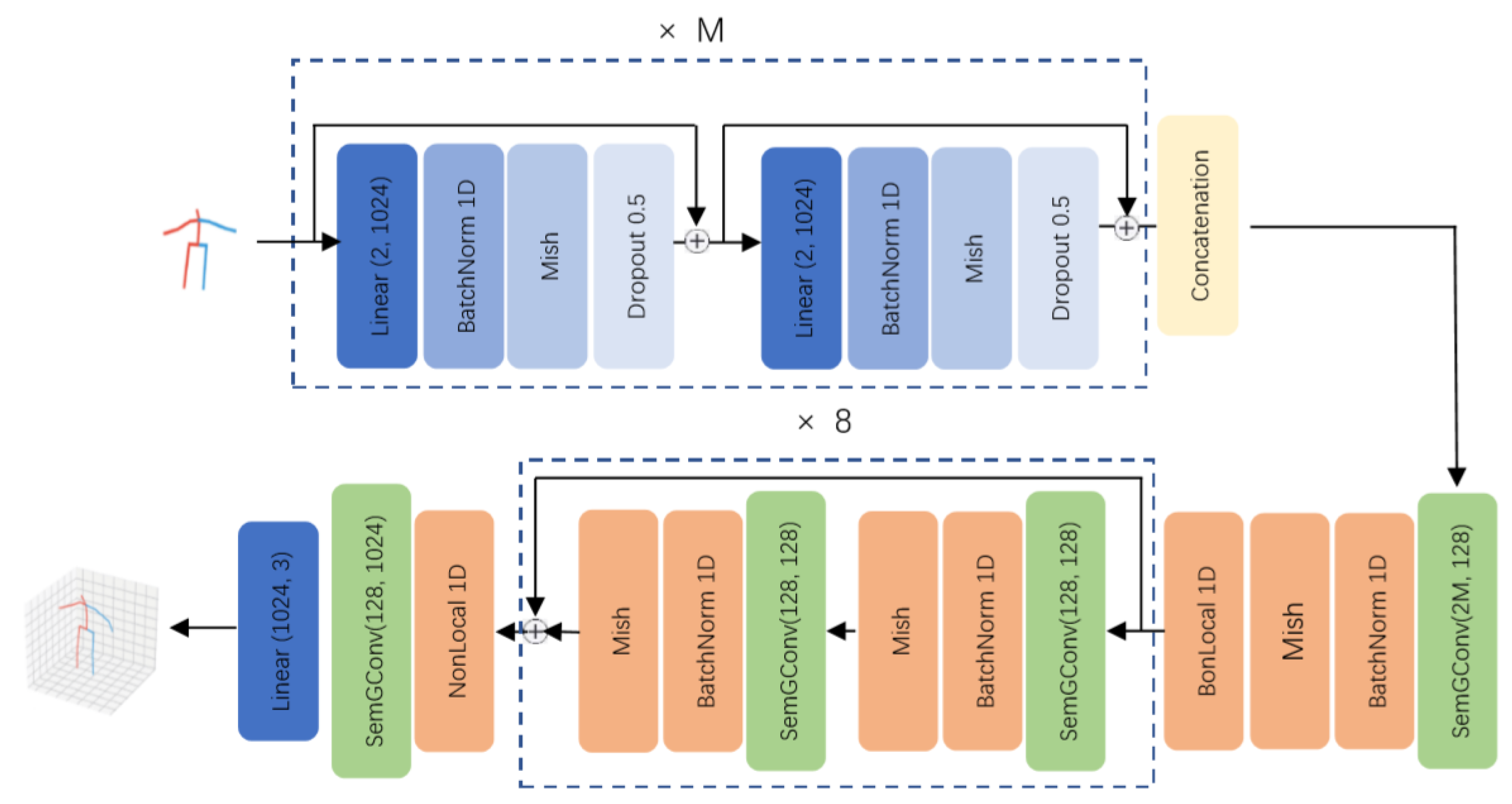
3.3. 2D to 3D Pose Regression Network
3.3.1. Network Design
3.3.2. Loss Function
4. Experiments
4.1. Setting
4.2. Ablation Study
4.2.1. Performance Analysis of the Number of Views Generated by MvPG
4.2.2. Impact of MvPG on 3D Pose Estimation Network
4.3. Comparison with the State of the Art
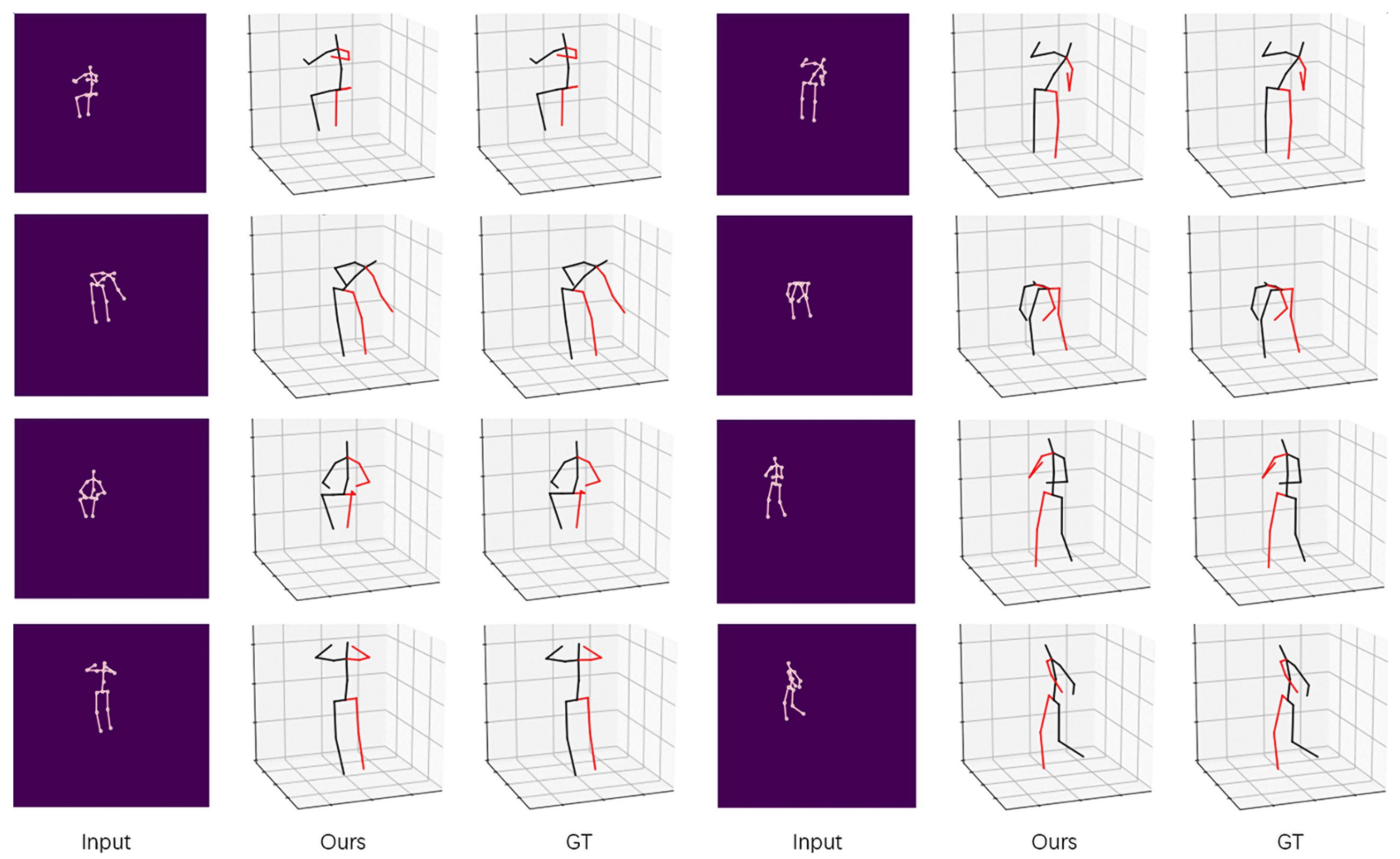
4.4. Qualitative Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, D.; He, L.; Tu, Z.; Han, F.; Zhang, S.; Yang, B. Learning motion representation for real-time spatio-temporal action localization. Pattern Recognit. 2020, 103, 107312. [Google Scholar] [CrossRef]
- Buys, K.; Cagniart, C.; Baksheev, A.; Laet, T.D.; Schutter, J.D.; Pantofaru, C. An adaptable system for RGB-D based human body detection and pose estimation. J. Vis. Commun. Image Represent. 2014, 25, 39–52. [Google Scholar] [CrossRef]
- Ancillao, A. Stereophotogrammetry in Functional Evaluation: History and Modern Protocols; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Procházka, A.; Vyšata, O.; Vališ, M.; Ťupa, O.; Schätz, M.; Mařík, V. Bayesian classification and analysis of gait disorders using image and depth sensors of Microsoft Kinect. Digit. Signal Process. 2015, 47, 169–177. [Google Scholar] [CrossRef]
- Clark, R.A.; Bower, K.J.; Mentiplay, B.F.; Paterson, K.; Pua, Y.H. Concurrent validity of the Microsoft Kinect for assessment of spatiotemporal gait variables. J. Biomech. 2013, 46, 2722–2725. [Google Scholar] [CrossRef] [PubMed]
- Sohn, K.; Lee, H.; Yan, X. Learning Structured Output Representation using Deep Conditional Generative Models. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Dutchess County, NY, USA, 2015; pp. 3483–3491. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Dutchess County, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- Yang, W.; Ouyang, W.; Wang, X.; Ren, J.; Li, H.; Wang, X. 3D Human Pose Estimation in the Wild by Adversarial Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5255–5264. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J.J. A Simple Yet Effective Baseline for 3d Human Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2640–2649. [Google Scholar]
- Wang, K.; Lin, L.; Jiang, C.; Qian, C.; Wei, P. 3D Human Pose Machines with Self-supervised Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1069–1082. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kocabas, M.; Karagoz, S.; Akbas, E. Self-Supervised Learning of 3D Human Pose Using Multi-View Geometry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1077–1086. [Google Scholar]
- Fang, H.; Xu, Y.; Wang, W.; Liu, X.; Zhu, S.C. Learning Knowledge-guided Pose Grammar Machine for 3D Human Pose Estimation. arXiv 2017, arXiv:1710.06513. [Google Scholar]
- Zhou, X.; Huang, Q.; Sun, X.; Xue, X.; Wei, Y. Towards 3D Human Pose Estimation in the Wild: A Weakly-Supervised Approach. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 398–407. [Google Scholar]
- Zhao, L.; Peng, X.; Tian, Y.; Kapadia, M.; Metaxas, D.N. Semantic Graph Convolutional Networks for 3D Human Pose Regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3425–3435. [Google Scholar]
- Rhodin, H.; Spörri, J.; Katircioglu, I.; Constantin, V.; Meyer, F.; Müller, E.; Salzmann, M.; Fua, P. Learning Monocular 3D Human Pose Estimation From Multi-View Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8437–8446. [Google Scholar]
- Qiu, H.; Wang, C.; Wang, J.; Wang, N.; Zeng, W. Cross View Fusion for 3D Human Pose Estimation. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 915–922. [Google Scholar]
- Dong, J.; Jiang, W.; Huang, Q.; Bao, H.; Zhou, X. Fast and Robust Multi-Person 3D Pose Estimation from Multiple Views. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7792–7801. [Google Scholar]
- Iskakov, K.; Burkov, E.; Lempitsky, V.; Malkov, Y. Learnable Triangulation of Human Pose. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 7718–7727. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Huang, F.; Zeng, A.; Liu, M.; Lai, Q.; Xu, Q. DeepFuse: An IMU-Aware Network for Real-Time 3D Human Pose Estimation from Multi-View Image. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 429–438. [Google Scholar]
- Ci, H.; Wang, C.; Ma, X.; Wang, Y. Optimizing Network Structure for 3D Human Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 2262–2271. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Derpanis, K.G.; Daniilidis, K. Harvesting multiple views for marker-less 3d human pose annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6988–6997. [Google Scholar]
- Trumble, M.; Gilbert, A.; Malleson, C.; Hilton, A.; Collomosse, J. Total Capture: 3D Human Pose Estimation Fusing Video and Inertial Sensors. BMVC 2017, 2, 3. [Google Scholar]
- Tome, D.; Toso, M.; Agapito, L.; Russell, C. Rethinking pose in 3d: Multi-stage refinement and recovery for markerless motion capture. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 474–483. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Pham, H.H.; Salmane, H.; Khoudour, L.; Crouzil, A.; Velastin, S.A.; Zegers, P. A unified deep framework for joint 3d pose estimation and action recognition from a single rgb camera. Sensors 2020, 20, 1825. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, J.; Lee, G.H. Trajectory Space Factorization for Deep Video-Based 3D Human Pose Estimation. arXiv 2019, arXiv:1908.08289. [Google Scholar]
- Cheng, Y.; Yang, B.; Wang, B.; Yan, W.; Tan, R.T. Occlusion-Aware Networks for 3D Human Pose Estimation in Video. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 723–732. [Google Scholar]
- Zhang, D.; Zou, L.; Zhou, X.; He, F. Integrating feature selection and feature extraction methods with deep learning to predict clinical outcome of breast cancer. IEEE Access 2018, 6, 28936–28944. [Google Scholar] [CrossRef]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, 16–20 June 2019; pp. 3595–3603. [Google Scholar]
- Cai, Y.; Ge, L.; Liu, J.; Cai, J.; Cham, T.J.; Yuan, J.; Thalmann, N.M. Exploiting spatial-temporal relationships for 3d pose estimation via graph convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 2272–2281. [Google Scholar]
- Zhang, Y.; An, L.; Yu, T.; Li, X.; Li, K.; Liu, Y. 4D Association Graph for Realtime Multi-person Motion Capture Using Multiple Video Cameras. arXiv 2020, arXiv:2002.12625. [Google Scholar]
- Liu, J.; Guang, Y.; Rojas, J. GAST-Net: Graph Attention Spatio-temporal Convolutional Networks for 3D Human Pose Estimation in Video. arXiv 2020, arXiv:2003.14179. [Google Scholar]
- Wang, L.; Chen, Y.; Guo, Z.; Qian, K.; Lin, M.; Li, H.; Ren, J.S. Generalizing Monocular 3D Human Pose Estimation in the Wild. arXiv 2019, arXiv:1904.05512. [Google Scholar]
- Misra, D. Mish: A Self Regularized Non-Monotonic Neural Activation Function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Liu, Q.; Furber, S. Noisy Softplus: A Biology Inspired Activation Function. In International Conference on Neural Information Processing; Springer: Cham, Switzerland, 2016; Volume 9950, pp. 405–412. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Sun, X.; Shang, J.; Liang, S.; Wei, Y. Compositional Human Pose Regression. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2602–2611. [Google Scholar]
- Fang, H.; Xu, Y.; Wang, W.; Liu, X.; Zhu, S.C. Learning Pose Grammar to Encode Human Body Configuration for 3D Pose Estimation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Basic Version (SemGCN [15]) | MvPG-4 | MvPG-8 | MvPG-16 | MPJPE (mm) |
|---|---|---|---|---|
| √ | 40.8 | |||
| √ | √ | 36.9 | ||
| √ | √ | 39.0 | ||
| √ | √ | 35.8 |
| Method | MPJPE (mm) |
|---|---|
| FCN [10] | 44.4 |
| SemGCN [15] | 42.1 |
| MvPG-16 + FCN [10] | 41.8 |
| MvPG-16 + SemGCN [15] | 39.9 |
| Method | Dire. | Disc. | Eat | Greet | Phone | Photo | Pose | Purch. | Sit | SitD. | Smoke | Wait | WalkD. | Walk | WalkT. | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Martinez et al. [10] | 51.8 | 56.2 | 58.1 | 59.0 | 69.5 | 78.4 | 55.2 | 58.1 | 74.0 | 94.6 | 62.3 | 59.1 | 65.1 | 49.5 | 52.4 | 62.9 |
| Sun et al. [40] | 52.8 | 54.8 | 54.2 | 54.3 | 61.8 | 53.1 | 53.6 | 71.7 | 86.7 | 61.5 | 67.2 | 53.4 | 47.1 | 61.6 | 53.4 | 59.1 |
| Fang et al. [41] | 50.1 | 54.3 | 57.0 | 57.1 | 66.6 | 73.3 | 53.4 | 55.7 | 72.8 | 88.6 | 60.3 | 57.7 | 62.7 | 47.5 | 50.6 | 60.4 |
| Yang et al. [8] | 51.5 | 58.9 | 50.4 | 57.0 | 62.1 | 65.4 | 49.8 | 52.7 | 69.2 | 85.2 | 57.4 | 58.4 | 43.6 | 60.1 | 47.7 | 58.6 |
| Zhao et al. [15] | 47.3 | 60.7 | 51.4 | 60.5 | 61.1 | 49.9 | 47.3 | 68.1 | 86.2 | 55.0 | 67.8 | 61.0 | 42.1 | 60.6 | 45.3 | 57.6 |
| Ci et al. [22] | 46.8 | 52.3 | 44.7 | 50.4 | 52.9 | 68.9 | 49.6 | 46.4 | 60.2 | 78.9 | 51.2 | 50.0 | 54.8 | 40.4 | 43.3 | 52.7 |
| Martinez et al. [10] (GT) | 37.7 | 44.4 | 40.3 | 42.1 | 48.2 | 54.9 | 44.4 | 42.1 | 54.6 | 58.0 | 45.1 | 46.4 | 47.6 | 36.4 | 40.4 | 45.5 |
| Zhao et al. [15] (GT) | 37.8 | 49.4 | 37.6 | 40.9 | 45.1 | 41.4 | 40.1 | 48.3 | 50.1 | 42.2 | 53.5 | 44.3 | 40.5 | 47.3 | 39.0 | 43.8 |
| Wang et al. [35] (GT) | 32.1 | 39.2 | 33.4 | 36.4 | 38.9 | 45.9 | 38.4 | 31.7 | 42.5 | 48.1 | 37.8 | 37.9 | 38.7 | 30.6 | 32.6 | 37.6 |
| Ci et al. [22] (GT) | 36.3 | 38.8 | 29.7 | 37.8 | 34.6 | 42.5 | 39.8 | 32.5 | 36.2 | 39.5 | 34.4 | 38.4 | 38.2 | 31.3 | 34.2 | 36.3 |
| Ours (GT) | 37.1 | 42.9 | 35.7 | 37.3 | 39.4 | 47.6 | 40.3 | 37.1 | 48.1 | 51.7 | 38.8 | 39.0 | 40.5 | 29.7 | 33.6 | 39.9 |
| Ours (GT/non-local) | 30.9 | 39.2 | 31.1 | 33.7 | 36.2 | 45.1 | 35.7 | 30.1 | 40.4 | 48.1 | 35.1 | 35.2 | 37.4 | 27.9 | 30.2 | 35.8 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, J.; Wang, M.; Zhao, X.; Zhang, D. Multi-View Pose Generator Based on Deep Learning for Monocular 3D Human Pose Estimation. Symmetry 2020, 12, 1116. https://doi.org/10.3390/sym12071116
Sun J, Wang M, Zhao X, Zhang D. Multi-View Pose Generator Based on Deep Learning for Monocular 3D Human Pose Estimation. Symmetry. 2020; 12(7):1116. https://doi.org/10.3390/sym12071116
Chicago/Turabian StyleSun, Jun, Mantao Wang, Xin Zhao, and Dejun Zhang. 2020. "Multi-View Pose Generator Based on Deep Learning for Monocular 3D Human Pose Estimation" Symmetry 12, no. 7: 1116. https://doi.org/10.3390/sym12071116
APA StyleSun, J., Wang, M., Zhao, X., & Zhang, D. (2020). Multi-View Pose Generator Based on Deep Learning for Monocular 3D Human Pose Estimation. Symmetry, 12(7), 1116. https://doi.org/10.3390/sym12071116