1. Introduction
Exascale systems will be available in a few years. These systems can be achieved by enhancing hardware ability as well as parallelism in the application by integrating different programming models using dual- and tri-programming models. Exascale systems can achieve 1018 floating-point operations per second with thousands or millions of threads, which will involve several difficulties including runtime errors.
Parallel programs built by using programming models have been targeted by different testing tools. In particular, high-level programming models targeting Graphics Processing Unit (GPU) need more effort. Because of the integration between different programming models, errors will be more frequent and unpredictable and therefore need testing techniques to detect them. As a result, building a testing tool targeting parallel programs is not an easy task, especially when these parallel programs are built using integrated programming models. In addition, there is a shortage of testing tools targeting parallel systems, which use dual-programming models.
Previously, we proposed an architecture for a parallel testing tool targeting programs built with heterogeneous architecture, including the dual-programming models Message Passing Interface (MPI) + OpenACC, and covering different errors [
1,
2,
3]. In addition, we proposed a static testing approach that targets OpenACC-related programs [
4]. We then improved that to create a hybrid testing tool that targets OpenACC-related programs by integrating static and dynamic approaches; we named it ACC_TEST [
5,
6].
Parallelism and performance can be enhanced by integrating several programming models along with the ability to work in heterogeneous platforms. Using hybrid programming models helps move towards Exascale, which needs programming models for supporting massively parallel systems. The programming models can be classified into three levels: single-level programming model: MPI [
7]; dual-level programming model: MPI + OpenMP [
8]; and tri-level programming model: MPI + OpenMP + CUDA [
9].
In this paper, the dual-programming model MPI + OpenACC has been chosen, as combining MPI and OpenACC enhances parallelism and performance and reduces programming efforts. OpenACC can be compiled to work in different hardware architecture as well as multiple device types, and MPI will be used for exchanging data between different nodes. The dual-programming model combines the advantages of both programming models, including programmability and portability from OpenACC and high performance, scalability, and portability from MPI [
10].
We chose this combination because OpenACC has allowed non-computer science specialists to parallelize their programs, which can possibly lead to errors when OpenACC directives and clauses are misused. OpenACC uses high-level directives without considering much detail, which is one of its main features. In addition, OpenACC has the ability to work on any GPU platform, which gives it high portability. We believe that this combination needs to be considered for testing because there is a high possibility of runtime errors occurring when programmers use MPI + OpenACC. Some researchers claim that MPI + CUDA [
9], a hybrid programming model, can be applicable on heterogeneous cluster systems. However, this combination only works on NVIDIA GPU devices and CUDA is considered a low-level programming model that needs various details. In addition, the combination of MPI + OpenMP [
8] targets homogenous architecture through shared memory, which does not serve the purpose of using the GPU in accelerating the user codes.
The first part of the chosen combination is Message-Passing Interface (MPI), the first version of which was released in 1994 [
11]. MPI supports parallelism in C, C++, and Fortran by using message passing to establish standard efficient, portable, and flexible message passing programs. MPI has the ability to be integrated with other programming models, including shared memory-related programming models like OpenMP and GPU-related programming models like OpenACC. In addition, MPI has two types of communication, including point-to-point and collective, which can be blocking or non-blocking. Finally, MPI has released the latest version MPI 4.0, which has the ability to better support hybrid-programming models [
11].
The second part is OpenACC, which has been released to support parallelism and accelerate C, C++, and Fortran codes for heterogeneous CPU/GPU systems by using high-level directives. OpenACC has three directive types, including compute, data management, and synchronization directives. In November 2019, the latest OpenACC version 3.0 [
12] was released to include many features to support parallelism, including portability, flexibility, compatibility, and less programming effort and time.
In this paper, the ACC_TEST has been improved upon to have the ability to test programs built using MPI + OpenACC dual-programming models and detect related errors. Our solution aimed at covering a wide range of errors that occur in the dual-programming models MPI + OpenACC with less overhead and better system execution time. Finally, our testing tool works in parallel by detecting runtime errors with testing threads created based on application threads numbers.
This paper is structured as follows:
Section 2 provides a related work, including testing tools classified by the testing techniques that were used. We explain our techniques for testing the programs based on dual-programming models in
Section 3. We discuss our implementation, testing, and evaluation of ACC_TEST in
Section 4 and show some results from our experiments. The conclusion and future scope will be discussed in
Section 5.
3. Our Techniques for Testing Dual-Programming Models Related Programs
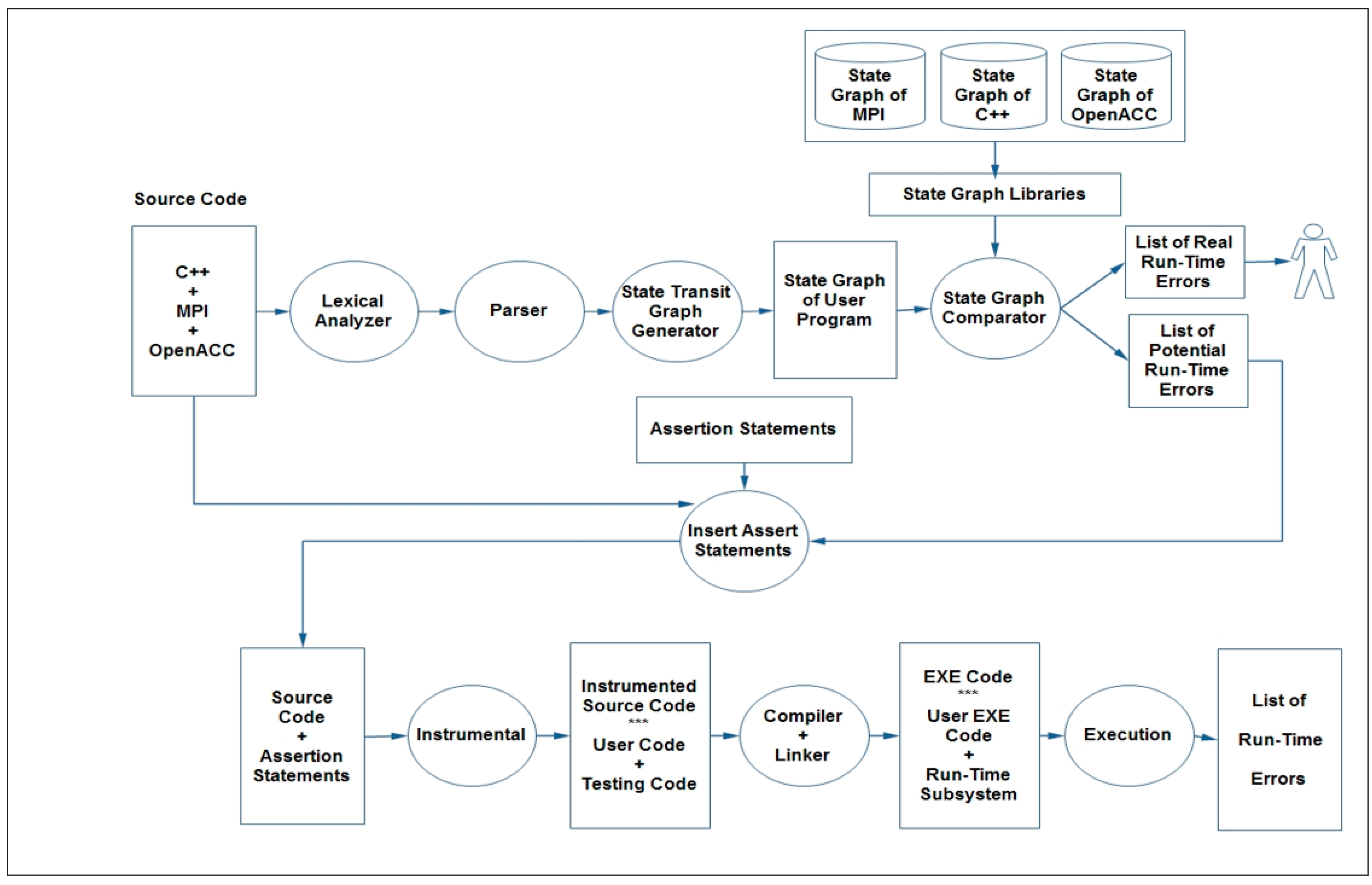
We designed ACC_TEST for detecting errors in parallel programs created by using the integrated model MPI + OpenACC. Our solution integrates the static and dynamic analysis for checking the actual and potential errors with lower overheads and covering a wide range of errors. In our solution, we use the static analysis for discovering as many errors as possible as well as annotate any potential errors for further dynamic testing. This method helps us reduce any unnecessary code instrumentation and minimize the dynamic testing to cover only the code parts that need to be tested during runtime. The dynamic analysis will be used to check and detect any errors that cannot be detected during our static analysis and to detect thread interactions during runtime for any possible errors like race condition and deadlock. An overview of our solution is shown in
Figure 1.
ACC_TEST classifies the targeted source code into several parts for ensuring efficient error detection so that only the parts that needed to be investigated will be covered. This classification includes OpenACC data and compute regions, MPI point-to-point and collective communications, as well as non-parallel code parts. ACC_TEST detects errors based on the OpenACC error classification published in [
4] that classified OpenACC errors into OpenACC data managements errors, race condition, deadlock, and livelock. In addition, MPI errors are detected by ACC_TEST based on [
46] that classified MPI errors into deadlock, data race, mismatches, resource handling, and memory errors.
OpenACC data clause detection is built based on the assumption that the OpenACC data clause can be used inefficiently, which makes it error-prone and the errors cannot be detected by a compiler. As a result, ACC_TEST investigates all OpenACC data clauses in the source code using our static approach to ensure their correctness, including their syntax and semantics. There are two main types of OpenACC data clauses, structured and unstructured data clauses, which need to be checked differently based on their nature. Algorithm 1 was built to check the structure data clauses in both data and compute regions because of their similar behavior and role. This algorithm used our static approach to examine any variable related to OpenACC data clause directives and determine their locations in three places in the targeted source code, including data region, before and after this region. In case of any error detected by our static approach, an error message will be written to the error list resulting from ACC_TEST.
| Algorithm 1: Structured Data Clause Check Algorithm |
|---|
| | START |
| 1: | RECEIVED ACC_DClauseVar, ACC_DClauseType |
| 2: | SEARCH for ACC_DClauseVar Location in the source code |
| 3: | STORE ACC_DClauseVar, ACC_DClauseType, ACC_DClauseVarLineNo, ACC_DClauseVarFileName, ACC_DClauseVarLocation IN ACC_DClauseVarList |
| 4: | WHILE ACC_DClauseVar in ACC_DClauseVarList |
| 5: | CASE ACC_DClauseVarLocation: |
| 6: | In_ ACCDataRegion: |
| 7: | IF ACC_DClauseVar founded |
| 8: | IF ACC_DClauseVar part of equation |
| 9: | IF ACC_DClauseVar is define && ACC_DClauseType = copyin |
| 10: | ERROR REPORTED |
| 11: | ELSE IF ACC_DClauseVar is reused && ACC_DClauseType = copyout |
| 12: | ERROR REPORTED |
| 13: | ELSE IF ACC_DClauseVar is reused && ACC_DClauseType = copyin && the ACC_DefineVar not in copy clause or copyin clause |
| 14: | ERROR REPORTED |
| 15: | ELSE IF ACC_DClauseVar is define && ACC_DClauseVar is reused && (ACC_DClauseType = copyin or ACC_DClauseType = copyout) |
| 16: | ERROR REPORTED |
| 17: | END IF |
| 18: | ELSE IF ACC_DClauseVar is CALLED by function |
| 19: | IF ACC_DClauseVar is CALLED by value |
| 20: | ERROR REPORTED |
| 21: | ELSE IF ACC_DClauseType = copyout |
| 22: | ERROR REPORTED |
| 23: | END IF |
| 24: | END IF |
| 25: | ELSE |
| 26: | ERROR REPORTED |
| 27: | END IF |
| 28: | Before_ ACCDataRegion: |
| 29: | IF ACC_DClauseVar founded |
| 30: | IF ACC_DClauseVar initialized |
| 31: | PASS |
| 32: | ELSE IF ACC_DClauseVar used as define && (ACC_DClauseType = create or ACC_DClauseType = copyout) |
| 33: | ERROR REPORTED |
| 34: | ELSE |
| 35: | ERROR REPORTED |
| 36: | END IF |
| 37: | ELSE |
| 38: | ERROR REPORTED |
| 39: | END IF |
| 40: | After_ ACCDataRegion: |
| 41: | IF ACC_DClauseVar founded |
| 42: | IF ACC_DClauseType = create or ACC_DClauseType = copyin |
| 43: | ERROR REPORTED |
| 44: | ELSE |
| 45: | PASS |
| 46: | END IF |
| 47: | ELSE |
| 48: | ERROR REPORTED |
| 49: | ENDIF |
| 50: | END CASE |
| 51: | END WHILE |
| | END |
In terms of the OpenACC unstructured data clause, Algorithm 2 is responsible for detecting any error related to the unstructured data clause as well as detecting the data movements between the enter and exit region. In addition, some behaviors that are not considered an error, but could cause memory-related problems, will be detected by our static approach when variables are moved to the GPU without being used or a temporary GPU variable is created and not deleted at the exit region.
| Algorithm 2: Unstructured Data Clause Check Algorithm |
|---|
| | START |
| 1: | RECEIVE ACC_DClauseVar, ACC_DClauseType |
| 2: | SEARCH for ACC_DClauseVar Locations in the source code |
| 3: | STORE ACC_DClauseVar, ACC_DClauseType, ACC_DClauseVarLineNo, ACC_DClauseVarFileName, ACC_DClauseVarLocation IN ACC_DClauseVarList |
| 5: | WHILE ACC_DClauseVar in ACC_DClauseVarList |
| 6: | IF (ACC_DClauseType = copyin or ACC_DClauseType = create) && (ACC_DClauseVar not founded at exit data region directive) |
| 7: | ERROR REPORTED |
| 8: | ELSE IF (ACC_DClauseType = copyout or ACC_DClauseType = delete) && (ACC_DClauseVar not founded at enter data region directive) |
| 9: | ERROR REPORTED |
| 10: | END IF |
| 11: | CASE ACC_DClauseVarlocation: |
| 12: | In_ ACCDataRegion: |
| 13: | IF ACC_DClauseVar founded |
| 14: | IF ACC_DClauseVar part of equation |
| 15: | IF ACC_DClauseVar is define |
| 16: | IF ACC_DClauseType = delete |
| 17: | ERROR REPORTED |
| 18: | ELSE IF (ACC_DClauseType = create or ACC_DClauseType = copyin) && ACC_DClauseVar not founded in copyout at exit |
| 19: | ERROR REPORTED |
| 20: | END IF |
| 21: | ELSE IF ACC_DClauseVar is reused |
| 22: | IF ACC_DClauseType = copyout |
| 23: | ERROR REPORTED |
| 24: | ELSE IF ACC_DClauseType = create or ACC_DClauseType = copyin |
| 25: | IF ACC_Definedvar not in copyout at exit |
| 26: | ERROR REPORTED |
| 27: | ELSE IF ACC_DClauseVar not in delete at exit |
| 28: | ERROR REPORTED |
| 29: | END IF |
| 30: | END IF |
| 31: | ELSE IF ACC_DClauseVar is define and reused |
| 32: | IF ACC_DClauseType = delete |
| 33: | ERROR REPORTED |
| 34: | ELSE IF ACC_DClauseType = copyout && ACC_DClauseVar not at enter region |
| 35: | ERROR REPORTED |
| 36: | ELSE IF (ACC_DClauseType = copyin or ACC_DClauseType = create) && ACC_DClauseVar is not in copyout at exit region |
| 37: | ERROR REPORTED |
| 38: | END IF |
| 39: | END IF |
| 40: | ELSE IF ACC_DClauseVar is CALLED by function |
| 41: | IF ACC_DClauseVar is CALLED by value |
| 42: | ERROR REPORTED |
| 43: | ELSE IF ACC_DClauseVar is CALLED by reference |
| 44: | IF (ACC_DClauseType = copyin or ACC_DClauseType = create) && ACC_DClauseVar not in delete at exit |
| 45: | ERROR REPORTED |
| 46: | ELSE IF ACC_DClauseType = copyout |
| 47: | ERROR REPORTED |
| 48: | END IF |
| 49: | END IF |
| 50: | END IF |
| 51: | ELSE |
| 52: | ERROR REPORTED |
| 53: | END IF |
| 54: | Before_ ACCDataRegion: |
| 55: | IF ACC_DClauseVar founded |
| 56: | IF ACC_DClauseVar initialized |
| 57: | PASS |
| 58: | ELSE IF ACC_DClauseVar used in the equation as define |
| 59: | IF ACC_DClauseType = create |
| 60: | ERROR REPORTED |
| 61: | ELSE IF (ACC_DClauseType = copyout or ACC_DClauseType = delete) && ACC_DClauseVar not in copyin or create at enter |
| 62: | ERROR REPORTED |
| 63: | END IF |
| 64: | ELSE |
| 65: | ERROR REPORTED |
| 66: | END IF |
| 67: | ELSE |
| 68: | ERROR REPORTED |
| 69: | END IF |
| 70: | After_ ACCDataRegion: |
| 71: | IF ACC_DClauseVar founded |
| 72: | IF ACC_DClauseType = delete |
| 73: | ERROR REPORTED |
| 74: | ELSE IF (ACC_DClauseType = copyin or ACC_DClauseType = create) && ACC_DClauseVar not in copyout at exit |
| 75: | ERROR REPORTED |
| 76: | END IF |
| 77: | ELSE IF ACC_DClauseVar not founded |
| 78: | IF ACC_DClauseType = copyout |
| 79: | ERROR REPORTED |
| 80: | ELSE IF (ACC_DClauseType = copyin or ACC_DClauseType = create) && ACC_DClauseVar not in delete at exit |
| 81: | ERROR REPORTED |
| 82: | ELSE IF ACC_DClauseVar in delete and copyout at exit |
| 83: | ERROR REPORTED |
| 84: | END IF |
| 85: | END IF |
| 86: | END CASE |
| 87: | END WHILE |
| | END |
ACC_TEST dynamic approach uses the information resulting from our static testing to determine the place of the present data clause in the source code and its variable list. Then, our dynamic instrumentation uses the API function (acc_is_present), which indicates if the variable is present on the device to test the present clause. In addition, an if-statement will be inserted to test the result of the OpenACC API function and issue error message, indicating the error type and place to the programmer. The following code in
Figure 2 is an example of our insertion statements before being instrumented, where the var_name, var_size, and var_type will be determined by our static testing and inserted with the comment character, followed by the word “ASSERT” to be distinguished by our instrumenter.
ACC_TEST identifies a variable to receive the value from the API function (acc_is_present), which takes the variable name, size, and type as shown in the previous code. This OpenACC API function tests if the data are present on the GPU. In C and C++, the function returns nonzero value if the data are present and zero if not present. If (acc_is_present) returns a nonzero value, this shows that the targeted variable is present in the current GPU, which can then complete the program. Our instrumenter will remove any comment character followed by our inserted label “ASSERT” to keep the insert test code to be compiled, when the user code and the inserted test code move to the instrumenter phase.
In terms of detecting OpenACC race condition, there are several situations that cause race condition in OpenACC, including host and device synchronization, loop parallelization, shared data read-and-write, asynchronous directives, reduction clause, and independent clause races. Our instrumentation mechanism will use the static approach annotation to insert codes into the targeted source code for collecting information during runtime. In the code given in
Figure 3, our insertion mechanism will insert data structure for collecting actual information during runtime and use them for several test cases in our dynamic testing phase after the instrumentation phase.
For detecting data dependency in OpenACC compute region loops, Algorithm 3 shows the process of detecting loop race condition, finding any dependency, and the possibility of having race condition within each loop threads.
| Algorithm 3: Race Detection: Data Dependency Check Algorithm |
|---|
| | START |
| 1: | SEARCH Loops inside ACCComputeRegion |
| 2: | STORE ACC_LoopID, ACC_LoopLineNo, ACC_LoopIterationVar, ACC_LoopStartValue, ACC_LoopEndValue, ACC_LoopComputeRegion,ACC_LoopIndependant |
| 3: | SEARCH Equation in loop |
| 4: | STORE ACC_EquationID, ACC_EquationComputeRegion, ACC_EquationLoopID, ACC_EquationArrayVarName, ACC_EquationArrayVarStatus, ACC_EquationArrayVarIndex, ACC_ EquationArrayVarType, ACC_EquationArrayVarPlace |
| 5: | IF (ACC_EquationArrayVarName_1 = ACC_EquationArrayVarName_2) && (ACC_EquationComputeRegion_1 = ACC_EquationComputeRegion_2) |
| 6: | IF ACC_EquationArrayVarType = Array |
| 7: | IF (ACC_EquationArrayVarIndex_1 != ACC_EquationArrayVarIndex_2) && (ACC_EquationArrayVarPlace_1 != ACC_EquationArrayVarPlace_2) |
| 8: | ERROR REPORTED |
| 9: | ELSE IF Equation In ACC_IndependentClause |
| 10: | ERROR REPORTED |
| 11: | END IF |
| 12: | END IF |
| 13: | END IF |
| 14 | END |
For ensuring there are worked parallel codes, we detect the threads generated in OpenACC, including gangs and vectors. Our static testing phase generates tested gangs and vectors for each compute region for further comparison with the actual number of gang and vectors generated by the original source code. By using this compassion, the user code performance could be enhanced, because users assume that some compute regions work in parallel when they actually work sequentially. For each thread, some information will be collected during runtime, as shown in the following inserted test code in
Figure 4, which will be used in our dynamic testing phase after instrumentation. These inserted statements will be added to each OpenACC compute region.
All thread information in each OpenACC compute region from the inserted test code in
Figure 5 will be used to test actual parallelism for each OpenACC compute region and detect any differences between the tested and actual parallelism indicating the compute region, which is not parallelized.
In the case of read-write race condition, Algorithm 4 will be used by ACC_TEST static approach to detect different types of related race conditions.
| Algorithm 4: Race Detection: Read-Write Check Algorithm |
|---|
| | START |
| 1: | SEARCH Equation in ACCComputeRegion |
| 2: | STORE ACC_EquationID, ACC_EquationComputeRegion, ACC_EquationLoopID, ACC_EquationArrayVarName, ACC_EquationArrayVarStatus,ACC_EquationArrayVarIndex, ACC_EquationArrayVarType |
| 3: | IF (ACC_EquationID_1 = ACC_EquationID_2) && (ACC_EquationArrayVarName_1 = ACC_EquationArrayVarName_2) |
| 4: | IF (ACC_EquationArrayVarIndex_1 != ACC_EquationArrayVarIndex_2) |
| 5: | IF ACC_EquationArrayVarStatus_1 = Read && ACC_EquationArrayVarStatus_2 = Write |
| 6: | ERROR REPORTED |
| 7: | ELSE IF ACC_EquationArrayVarStatus_1 = Write && ACC_EquationArrayVarStatus_2 = Read |
| 8: | ERROR REPORTED |
| 9: | ELSE IF ACC_EquationArrayVarStatus_1 = Write && ACC_EquationArrayVarStatus_2 = Write |
| 10: | ERROR REPORTED |
| 11: | END IF |
| 12: | END IF |
| 13: | END IF |
| | END |
In our dynamic phase, for the case of data race detection for writing and reading to memory and at compiling time, if the addresses cannot be determined or the addresses potentially have conflicts, ACC_TEST static approach will insert codes to be investigated during the dynamic phase. In our dynamic approach, each memory access statement that is marked by our static analysis will be monitored, and their information will be recorded to detect any data race. The information will include variable, thread id, operation (R/W), and memory addresses.
To detect race condition that results from reading and writing to or from the same address in the Host or Device, our dynamic tester will instrument the inserted test statements in the user code to register each address space in Host and Device and then check if there is any writing to the same address at the same time. In this case, the dynamic tester will execute user code and inserted code to discover if there is any reading or writing to the same address. If so, an error message is shown to the user, indicating the race condition along with the reason. The inserted test code is shown in
Figure 6, which will use the data structure to store actual information during runtime for each thread, as explained earlier. These test codes will investigate the device addressed in the same compute region as well as across different compute regions.
In terms of detecting OpenACC deadlock, ACC_TEST will use the static analysis to partially detect deadlock by annotating the code parts that need further investigation during runtime. The dynamic part of ACC_TEST will use the instrumentations annotated for testing the threads arrival at the end of each OpenACC compute region. This approach was used because we assumed that each OpenACC parallel compute region could have deadlock. At the end of each OpenACC compute region, our dynamic phase will check the number of threads included in the region and compare them by the number of threads at the end of the OpenACC region. Because of the implicit barrier on OpenACC, which hides information from the developers, our approach will make sure any unexpected behavior is investigated and reported to the developers along with related information. ACC_TEST dynamic approach will also be used to detect deadlock caused by GPU livelock as well as livelock that can occur in the Host and Device interaction.
In the case of deadlock detection, the source code execution will be continuously working, causing the execution to hang without knowing the problem. Therefore, our dynamic tester will add an asynchronous directive for each compute region that has potential deadlock and number these asynchronous directives with the same number as the compute region. However, if our static tester does not detect any potential deadlock in the compute regions, our dynamic tester will not add the asynchronous directives. Our static tester will be responsible for marking each compute region that has potential deadlock and providing our dynamic tester with the appropriate information needed to proceed with the dynamic testing. Our insertion mechanism will insert test codes for testing the threads’ arrival at the end of each OpenACC compute region as well as for testing the threads’ arrival at the end of all regions. As shown in
Figure 7, at the end of all compute regions, our tester will insert a timer and test the arrival of all threads at the end of each OpenACC compute region. If all threads arrived at the end of all OpenACC compute regions, it indicates that the source code is deadlock-free, but if the timer has ended and not all threads arrived at the end of all regions, it indicates deadlock.
During runtime and after executing the inserted test code, ACC_TEST will investigate the OpenACC compute region that caused the deadlock and provided the developers error message, which indicates the error type and its related compute region. The timer takes into consideration the sending, receiving, and execution time. This can detect the CPU deadlock that resulted from the GPU livelock. Our static phase will also analyze the source code to detect any potential livelock in the GPU from the user source code and without execution. Using the hybrid testing technique will ensure the user code correctness and detect any potential deadlock.
In terms of MPI error detection, our static approach starts by checking each MPI communication, whether it is point-to-point, collectives, blocking, or non-blocking. This process will determine the MPI calls’ locations on the source code, rank, and communication type. In addition, our static approach has the ability to retrieve all attributes related to the MPI sending and receiving calls, including data, counter, data type, source, destination, tag, and MPI communicator as well as other information related to each type of MPI calls. Algorithm 5 shows the process of storing all related MPI calls and checking MPI data type and size mismatching as well as the MPI send/receive pair for detecting any differences between the numbers of sends and receives. This pairing will also examine the message tag to detect any unmatched message pairing. This process will avoid any potential race condition and deadlocks.
| Algorithm 5: MPI Communication Detection |
|---|
| | START |
| 1: | SEARCH mpi_send calls in user code |
| 2: | STORE mpi_send_comm_type, mpi_send_no, mpi_send_line_no, mpi_send_data, mpi_send_count, mpi_send_data_type, mpi_send_dest, mpi_send_tag,mpi_send_comm, mpi_send_rank, mpi_send_match, recver_line_no, mpi_isend_request |
| 3: | SEARCH mpi_recv calls in user code |
| 4: | STORE mpi_recv_comm_type, mpi_recv_no, mpi_recv_line_no, mpi_recv_data, mpi_recv_count, mpi_recv_data_type, mpi_recv_source, mpi_recv_tag,mpi_recv_comm, mpi_recv_status, mpi_recv_rank, mpi_recv_match, mpi_recv_potential, mpi_irecv_request |
| 5: | SEARCH mpi_sendrecv calls in user code |
| 6: | STORE mpi_sendrecv_no, mpi_sendrecv_line_no, mpi_sendrecv_send_data, mpi_sendrecv_send_count, mpi_sendrecv_send_data_type, mpi_sendrecv_dest,mpi_sendrecv_send_tag, mpi_sendrecv_recv_data mpi_sendrecv_recv_count, mpi_sendrecv_recv_type, mpi_sendrecv_source,mpi_sendrecv_recv_tag, mpi_sendrecv_comm, mpi_sendrecv_status |
| 7: | SEARCH mpi_collective_comm calls in user code |
| 8: | STORE mpi_collective_no, mpi_collective_line_no, mpi_collective_data, mpi_collective_count, mpi_collective_data_type, mpi_collective_root, mpi_collective_comm, mpi_collective_rank |
| 9: | CHECK No of mpi_send_call with No of mpi_recv_call |
| 10: | IF No. of mpi_send_call > mpi_recv_call |
| 11: | ERROR REPORTED |
| 12: | ELSE IF mpi_send_call < mpi_recv_call |
| 13: | ERROR REPORTED |
| 14: | END IF |
| 15: | FOR each send and recv pair |
| 16: | CHECK details of each send and recv pair |
| 17: | IF there is a difference between data types for the same pair |
| 18: | ERROR REPORTED |
| 19: | ELSE IF there is a difference between data size for the same pair |
| 20: | ERROR REPORTED |
| 21: | ELSE IF there is a send without recv |
| 22: | ERROR REPORTED |
| 23: | ELSE IF there is a recv without send |
| 24: | ERROR REPORTED |
| 25: | ELSE IF mpi_recv_source = “MPI_ANY_SOURCE” |
| 26: | ANNOTATION FOR FURTHER DYNAMIC PHASE |
| 27: | ELSE IF mpi_recv_tag = “MPI_ANY_TAG” |
| 28: | ANNOTATION FOR FURTHER ACC_TEST DYNAMIC PHASE |
| 29: | END IF |
| 30: | IF mpi_send_rank_1 = mpi_send_dest_2 && mpi_send_rank_2 = mpi_send_dest_1 |
| 31: | ANNOTATION FOR FURTHER ACC_TEST DYNAMIC PHASE |
| 32: | ELSE IF recver_line_no_1 < mpi_send_line_no_2 && recver_line_no_2 < mpi_send_line_no_1 |
| 33: | ERROR REPORTED |
| 34: | ELSE IF recver_line_no_1 > mpi_send_line_no_2 && recver_line_no_2 > mpi_send_line_no_1 |
| 35: | ERROR REPORTED |
| 36: | ELSE IF mpi_send_rank_1 = mpi_send_rank_2 && mpi_send_dest_1 > mpi_send_dest_2 && mpi_send_tag_1 = mpi_send_tag_2 |
| 37: | ERROR REPORTED |
| 38: | END FOR |
| | END |
In addition, in the case of the MPI sending calls more than receiving calls, this will be reported as there will be messages sent without being received, which can cause potential errors. On the other hand, if the MPI is receiving calls more than sending calls, it will also cause potential errors, including deadlock and race condition, as there will be processes waiting for receiving messages forever. In addition, some cases of deadlock will be detected when there is any MPI_Recv call without sender, and potential deadlock will be detected when using the wild card receive. In the case of having MPI_Send without receive, it will cause lake of resource errors. In addition, when there is a data exchange between two different processes where the same process sends and receives, it can cause potential deadlock, which needs further detection during ACC_TEST dynamic phase. Finally, the receive/receive deadlock will be detected by the static phase, but the send/send deadlock needs further investigation during the dynamic phase.
ACC_TEST dynamic phase is responsible for detecting deadlocks and race conditions by using the annotation from the static phase and using the insertion mechanism for executing testing during runtime. Connections that have potential errors will be investigated during our dynamic phase, which enhances the testing time and system performance by only testing the required parts of the code and minimizing overheads. In terms of detecting deadlock in point-to-point blocking communication, the following code in
Figure 8 shows the inserted codes that test MPI_Send and MPI_Recv calls.
For detecting race condition, ACC_TEST will compare all received calls’ actual information with our static phase information to detect any potential race conditions, as displayed in
Figure 9, where some values will be inserted and compared with the result from actual values. Similarly, to test the MPI_sendrecv, ACC_TEST will split this connection into MPI_Send and MPI_Recv and test them individually, as shown in
Figure 10.
In the case of collective communication, MPI_Bcast be will examined during runtime to detect any deadlock by inserting some testing codes as displayed in
Figure 11 for testing the data exchange between different MPI broadcasts. The annotation has been used for replacing each MPI blocking broadcast (MPI_Bcast) with MPI non-blocking broadcast (MPI_Ibcast) for avoiding any runtime blocking behavior and testing the arrival of all broadcasts calls and to compare actual information with the tested broadcast calls.
In terms of the used instrumentation method, we add the testing codes to the source code, because by adding the testing code to the user code, the testing will be distributed, increasing the reliability of our testing tool and avoiding the single point of failure, which happens when using the second method of having centralized control and call function for testing. In our case, reliability is more important than a smaller size. In addition, the testing code will be used in the testing house. In the operation phase, the user has the choice to use the uninstrumented source code, which will allow the compiler to ignore the test code, and the code size will not affect the operational user code. In addition, by using the chosen method, we will enhance performance by having distributed testing codes rather than centralized control.
ACC_TEST collected some historical information during the dynamic and static phases and stored it in a log file for use in debugging and tracking changes in user code. The runtime errors detected by our dynamic phase will be stored in a report separate from the report for the static analysis detection. After the execution of our testing for MPI and OpenACC-related programs, ACC_TEST will create a historical log file including several useful types of information to be used in debugging. This file will include the following information related to MPI + OpenACC programs:
- (1)
Summary of OpenACC regions: total number of compute, structured, and unstructured data regions, as well as the starting and ending points for each region;
- (2)
Compute region variables information;
- (3)
Loops information;
- (4)
Equations information;
- (5)
Equation data race analytics information;
- (6)
Equations read/write race condition analytics information;
- (7)
Thread information gang/vector;
- (8)
MPI-blocking communication information, including information about MPI_Send, MPI_Recv, and MPI_Sendrecv;
- (9)
MPI non-blocking communication information, which has information about MPI_Isend and MPI_Irecv;
- (10)
MPI collective communication information;
- (11)
MPI rank information.
Finally, our testing tool will produce several files reporting errors detected in our static and dynamic phases. In summary, our testing tool outputs will be:
- (1)
Inserted source code, including user codes and uninstrumented test codes;
- (2)
Static errors report, including information of errors detected during our static phase;
- (3)
Dynamic errors report, including information related to errors detected during our dynamic phase;
- (4)
Historical log file, including information from our static analysis;
- (5)
Historical log file for our dynamic analysis.
ACC_TEST has the ability to detect MPI + OpenACC hybrid-based programs and to detect OpenACC-based programs and MPI-based programs individually.
4. Discussion and Evaluation
Our tool has been implemented and tested for verifying and validating the ACC_TEST. Several experiments have been conducted, covering several scenarios and test suites for testing our proposed solution and ensuring ACC_TEST’s capability to detect different types of errors in MPI, OpenACC, and MPI + OpenACC dual-programming models. Because of the lack of the dual-programming models MPI + OpenACC benchmarks, we created our own hybrid programming models’ test suites for evaluating our testing techniques as well as the error coverage. We built several test cases for testing our proposed techniques and our testing tool, as shown in
Table 1. Because of the lack of MPI + OpenACC benchmarks, we created our own hybrid programming models test suites for evaluating our testing techniques as well as the error coverage. These test suites include both OpenACC and MPI directives for building parallel programs using the dual-programming models MPI + OpenACC. We built these test suites for evaluating our hybrid-testing tool and examining its ability to cover the runtime errors that we targeted and to measure different overheads, including size, compilation, and execution overheads.
Table 2 shows our hybrid testing tool’s ability to detect errors, which occur in MPI + OpenACC dual-programming models. We collected all errors that can be identified by our OpenACC and MPI testers and examine them on our hybrid testing tool for the dual-programming model. We found that our integrated tool could detect all errors targeted.
In the following,
Figure 12 displays the number of detected errors detected by our tool, including the number of errors detected by our static and dynamic approaches.
In terms of size overheads, we used Equation (1) for measuring the size overhead, as shown in
Figure 13. We noted that the size overheads range between 79% and 135%, based on the nature of the source code and its behavior. However, these size overheads will not affect the user code because all the inserted statements will be considered by the compiler as a comment, as they all start with the comment character. These inserted statements will affect the user source code only on the testing house and when these codes pass our instrumenter. We believe that these size overheads are needed because of the nature of runtime errors, which cannot be detected during our static phase analysis and need to be tested during runtime:
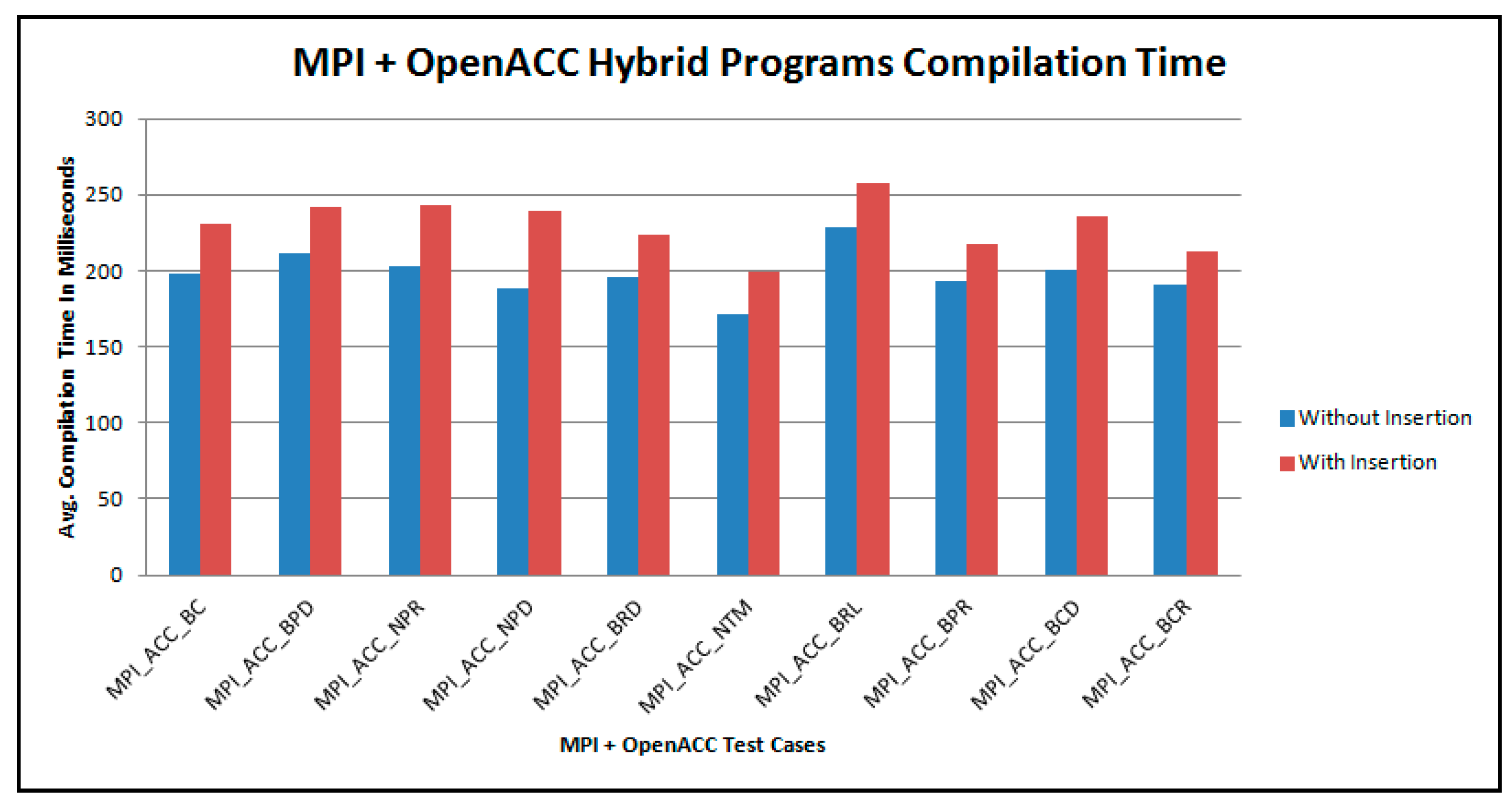
In terms of compilation and execution times, we measure our test cases and compare the compilation and execution times before and after our insertion process.
Figure 14 shows the average compilation time in milliseconds, which is 198 milliseconds before insertion and 230 milliseconds after insertion.
In terms of the execution time, there are differences in the execution time based on the number of processes. The average time before insertion ranges between 230 milliseconds in the 4 processes and 1578 milliseconds in the 128 processes. After the insertion, the execution time ranges between 241 and 1765 milliseconds for the 4 and 128 processes, respectively.
Compilation Time (CT) or Execution Time (ET) overheads will be calculated using the following Equation (2):
Figure 15 shows the compilation time overhead resulting from ACC_TEST. The compilation overheads range from 12% to 27%, which is considered acceptable and can vary based on the used compiler and system behavior. In terms of measuring the overheads and their relation to the number of MPI processes,
Figure 16 shows the execution time overhead for MPI + OpenACC-related test cases.
We successfully minimized the execution overheads to be under 18%; the execution overheads range between 1% and below 18% based on the system behavior, the machine status, and the number of processes.
Finally,
Figure 17 shows the execution time for testing programs built using MPI + OpenACC dual-programming models, for which the average testing time is 115 milliseconds.
In comparison to the MPI testing techniques published in [
47], our testing tool minimizes the size overhead for testing MPI-related programs because we avoid adding unnecessary messaging (communications) to test the connection between senders and receivers to detect deadlock. Another main advantage of ACC_TEST is that we used distributed testing techniques, unlike some other tools [
48,
49], which used a centralized manager for detecting MPI-related errors, causing a single point of failure and single point of attack.
OpenACC has been used for building ACC_TEST, which makes it portable and hardware architecture-independent. It therefore works with any type of GPU accelerator, hardware, platform, and operating system. In addition, ACC_TEST is easy to maintain and requires less effort because of the high maintainability of OpenACC. Our insertion techniques help increase the reliability of ACC_TEST because this technique avoids centralized control and single-point-of-failure problems as well as increase performance by distributing our testing tasks and avoiding centralized controlled testing. ACC_TEST also helps produce more high-quality systems without errors.
In
Table 3, we summarize the comparative study conducted in our research. Because there is no published work or existing testing tool that detects OpenACC errors or the dual-programming model MPI + OpenACC, we chose the closest work to compare with our techniques in different attribute.
ACC_TEST has the capability to cover different types of errors in OpenACC, MPI, and dual-programming models. In addition, ACC_TEST used hybrid-testing techniques for covering a wide range of errors while minimizing overheads. ACC_TEST is built based on a distributed mechanism, which avoids single point of failures. Additionally, the dual-programming models MPI + OpenACC have been supported by ACC_TEST for the first time in the research field. ACC_TEST is scalable and adaptable and can run on any platform.

 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}