A Comprehensive Study of HBase Storage Architecture—A Systematic Literature Review



Abstract
:1. Introduction
1.1. Apache HBase
1.2. Apache HBase Data Model
- (1)
- Table: HBase tables are column-oriented, i.e., data are stored in column format.
- (2)
- Row Key: It is the most crucial component of the HBase table. It is used for searching and retrieving data. It increases the speed of the searches.
- (3)
- Column Families: The entire columns related to each other are combined and called column families, as shown in Figure 1.
- (4)
- Column Qualifiers: Each column in the HBase table is known as the Column Qualifier.
- (5)
- Cell: A cell is made up of row key, column family, and column qualifier. Actual data are stored in a cell. There are many versions of the cell.
- (6)
- Time Stamp: A Time Stamp is made up of date and time. Whenever data are stored, they have a unique date and time. The timestamp is stored with the actual data, making it easy to search for a particular version of the data.
1.3. Contributions
- We have provided a systematic literature review (SLR) that shows which studies are directly associated with particular datasets.
- We have indicated the main research areas in HBase storage architecture and that there is still a need for improvements.
- The present study’s taxonomy will lead to a comprehensive analysis of the more active storage framework areas.
2. Materials and Methods
2.1. Search Criteria
2.1.1. Search String
2.1.2. Search Sources
2.2. Selection Strategy
3. Results
- RQ1: What are the primary datasets used by the research?
- RQ2: What are the primary factors for selecting HBase storage architecture in various domains?
3.1. Internet of Things (IoT)
3.2. GeoScience
3.3. Healthcare
3.4. Electrical Power
3.5. Documents
3.6. Marketing
3.7. Different Datasets
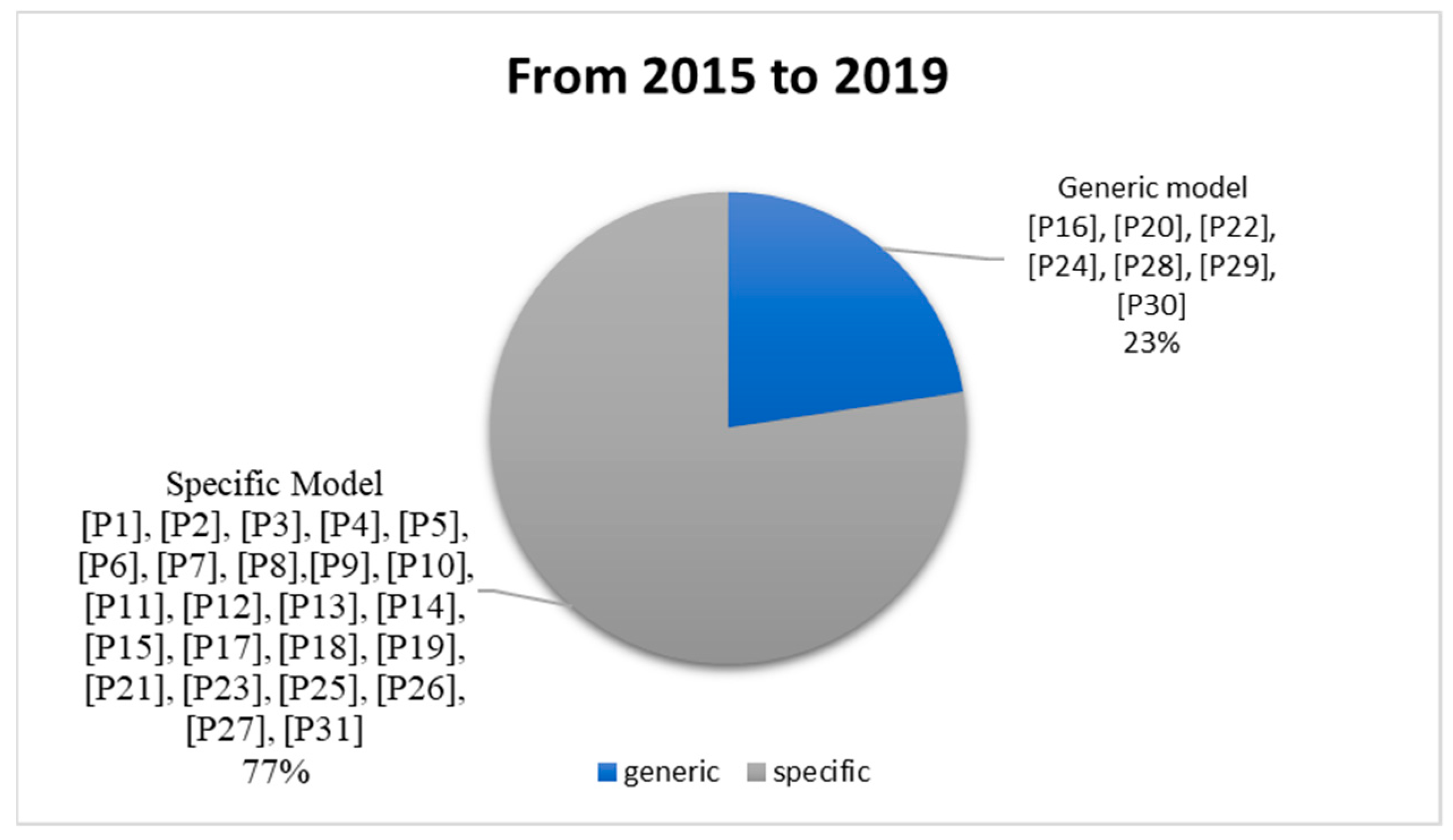
- RQ3: Are the proposed approaches application/data-specific or generic?
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Coughlin, T. 2019. Available online: https://www.seagate.com/in/en/our-story/data-age-2025/ (accessed on 13 February 2020).
- Morris, T. 2019. Available online: https://www.business2community.com/big-data/19-data-and-analytics-predictions-through-2025-02178668 (accessed on 21 March 2020).
- Zheng, K.; Fu, Y. Research on vector spatial data storage schema based on Hadoop platform. Int. J. Database Theory Appl. 2013, 6, 85–94. [Google Scholar] [CrossRef]
- Um, J.H.; Lee, S.; Kim, T.H.; Jeong, C.H.; Song, S.K.; Jung, H. Distributed RDF store for efficient searching billions of triples based on Hadoop. J. Supercomput. 2016, 72, 1825–1840. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, G.; Hu, X.; Wu, X. A distributed cache for hadoop distributed file system in real-time cloud services. In Proceedings of the 2012 ACM/IEEE 13th International Conference on Grid Computing, Beijing, China, 20–23 September 2012; pp. 12–21. [Google Scholar]
- Li, M.; Zhu, Z.; Chen, G. A scalable and high-efficiency discovery service using a new storage. In Proceedings of the 2013 IEEE 37th Annual Computer Software and Applications Conference, Kyoto, Japan, 22–26 July 2013; pp. 754–759. [Google Scholar]
- Kim, M.; Choi, J.; Yoon, J. Development of the big data management system on national virtual power plant. In Proceedings of the 2015 10th International Conference on P2P, Parallel, Grid, Cloud and Internet Computing (3PGCIC), Krakow, Poland, 4–6 November 2015; pp. 100–107. [Google Scholar]
- Rathore, M.M.; Son, H.; Ahmad, A.; Paul, A.; Jeon, G. Real-time big data stream processing using GPU with spark over hadoop ecosystem. Int. J. Parallel Program. 2018, 46, 630–646. [Google Scholar] [CrossRef]
- Smith, K. 2018. Available online: https://www.brandwatch.com/blog/facebook-statistics/ (accessed on 20 December 2019).
- George, L. HBase: The Definitive Guide: Random Access to Your Planet-Size Data; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2011. [Google Scholar]
- Huang, X.; Wang, L.; Yan, J.; Deng, Z.; Wang, S.; Ma, Y. Towards Building a Distributed Data Management Architecture to Integrate Multi-Sources Remote Sensing Big Data. In Proceedings of the 2018 IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Exeter, UK, 28–30 June 2018; pp. 83–90. [Google Scholar]
- Taylor, R.C. An overview of the Hadoop/MapReduce/HBase framework and its current applications in bioinformatics. BMC Bioinform. 2010, 11, S1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sinha, S. HBase Tutorial: HBase Introduction and FaceBook Case Study. 2018. Available online: https://www.edureka.co/blog/hbase-tutorial (accessed on 28 September 2020).
- Okoli, C.; Schabram, K. A Guide to Conducting a Systematic Literature Review of Information Systems Research. 5 May 2010. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1954824 (accessed on 10 November 2020).
- Zheng, Y.; Liu, C. HBase based storage system for the internet of things. In Proceedings of the 2016 4th International Conference on Machinery, Materials and Computing Technology, Hangzhou, China, 23–24 January 2016; pp. 484–487. [Google Scholar]
- Li, X.; Li, Z.; Ma, X.; Liu, C. A novel HBase data storage in wireless sensor networks. Eurasip J. Wirel. Commun. Netw. 2017, 2017, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Zhu, Y.; Wang, C.; Chen, Y.; Huang, T.; Shi, W.; Mao, Y. A versatile event-driven data model in hbase database for multi-source data of power grid. In Proceedings of the 2016 IEEE International Conference on Smart Cloud (SmartCloud), New York, NY, USA, 18–20 November 2016. [Google Scholar]
- Chen, Z.; Chen, S.; Feng, X. A design of distributed storage and processing system for internet of vehicles. In Proceedings of the 2016 8th International Conference on Wireless Communications & Signal Processing (WCSP), Yangzhou, China, 13–15 October 2016; pp. 1–5. [Google Scholar]
- Liu, B.; Huang, R.; Huang, T.; Yan, Y. MSDB: A massive sensor data processing middleware for HBase. In Proceedings of the 2017 IEEE Second International Conference on Data Science in Cyberspace (DSC), Shenzhen, China, 26–29 June 2017; pp. 450–456. [Google Scholar]
- Jing, W.; Tian, D. An improved distributed storage and query for remote sensing data. Procedia Comput. Sci. 2018, 129, 238–247. [Google Scholar]
- Gao, F.; Yue, P.; Wu, Z.; Zhang, M. Geospatial data storage based on HBase and MapReduce. In Proceedings of the 2017 6th International Conference on Agro-Geoinformatics, Fairfax, VA, USA, 7–10 August 2017; pp. 1–4. [Google Scholar]
- Wang, K.; Liu, G.; Zhai, M.; Wang, Z.; Zhou, C. Building an efficient storage model of spatial-temporal information based on HBase. J. Spat. Sci. 2019, 64, 301–317. [Google Scholar] [CrossRef]
- Wang, Y.; Li, C.; Li, M.; Liu, Z. HBase storage schemas for massive spatial vector data. Clust. Comput. 2017, 20, 3657–3666. [Google Scholar] [CrossRef]
- Qian, L.; Yu, J.; Zhu, G.; Pang, H.; Mei, F.; Lu, W.; Mei, Z. Research and Implementation of Geography Information Query System Based on HBase. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Dalian, China, 2019; Volume 384, p. 012168. [Google Scholar]
- Qin, J.; Ma, L.; Niu, J. Massive AIS Data Management Based on HBase and Spark. In Proceedings of the 2018 3rd Asia-Pacific Conference on Intelligent Robot Systems (ACIRS), Singapore, 21–23 July 2018; pp. 112–117. [Google Scholar]
- Nitnaware, C.; Khan, A. A multi-dimensional data storage model for location based application on Hbase. In Proceedings of the 2015 International Conference on Innovations in Information, Embedded and Communication Systems (ICIIECS), Coimbatore, India, 19–20 March 2015; pp. 1–5. [Google Scholar]
- Zhang, L.; Li, Q.; Li, Y.; Cai, Y. A Distributed Storage Model for Healthcare Big Data Designed on HBase. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 4101–4105. [Google Scholar]
- Gui, H.; Zheng, R.; Ma, C.; Fan, H.; Xu, L. An architecture for healthcare big data management and analysis. In International Conference on Health Information Science; Springer: Cham, Switzerland, 2016; pp. 154–160. [Google Scholar]
- Lei, R.A.O.; Fan-de, Y.A.N.G.; Xin-ming, L.I.; Dong, L.I.U. A Storage Model of Equipment Data Based on HBase. Appl. Mech. Mater. 2014, 713–715, 2418–2422. [Google Scholar]
- Jin, J.; Song, A.; Gong, H.; Xue, Y.; Du, M.; Dong, F.; Luo, J. Distributed storage system for electric power data based on hbase. Big Data Min. Anal. 2018, 1, 324–334. [Google Scholar]
- Daki, H.; El Hannani, A.; Ouahmane, H. HBase-based storage system for electrical consumption forecasting in a Moroccan engineering school. In Proceedings of the 2018 4th International Conference on Optimization and Applications (ICOA), Mohammedia, Morocco, 26–27 April 2018; pp. 1–6. [Google Scholar]
- Yan, Z.J.; Sun, P.; Liu, X.M. An HBase-based platform for massive power data storage in power system. In Advanced Materials Research; Trans Tech Publications Ltd.: Stafa-Zurich, Switzerland, 2015; Volume 1070, pp. 739–744. [Google Scholar]
- Zhengjun, P.; Lianfen, Z. Application and research of massive big data storage system based on HBase. In Proceedings of the 2018 IEEE 3rd International Conference on Cloud Computing and Big Data Analysis (ICCCBDA), Chengdu, China, 20–22 April 2018; pp. 219–223. [Google Scholar]
- Wen, S. Efficient DNA Sequences Storage Scheme based on HBase. In Proceedings of the 2018 International Conference on Mechanical, Electronic, Control and Automation Engineering (MECAE 2018), Qingdao, China, 30–31 March 2018; pp. 686–689. [Google Scholar]
- Zhuang, H.; Lu, K.; Li, C.; Sun, M.; Chen, H.; Zhou, X. Design of a more scalable database system. In Proceedings of the 2015 15th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, Shenzhen, China, 4–7 May 2015; pp. 1213–1216. [Google Scholar]
- Hong, S.; Cho, M.; Shin, S.; Um, J.H.; Seon, C.N.; Song, S.K. Optimizing hbase table scheme for marketing strategy suggestion. In Proceedings of the 2016 8th International Conference on Knowledge and Smart Technology (KST), Chiangmai, Thailand, 3–6 February 2016; pp. 313–316. [Google Scholar]
- Saloustros, G.; Magoutis, K. Rethinking HBase: Design and implementation of an elastic key-value store over log-structured local volumes. In Proceedings of the 2015 14th International Symposium on Parallel and Distributed Computing, Limassol, Cyprus, 29 June–2 July 2015; pp. 225–234. [Google Scholar]
- Zhu, L.; Li, Y. Distributed storage and analysis of massive urban road traffic flow data based on Hadoop. In Proceedings of the 2015 12th Web Information System and Application Conference (WISA), Jinan, China, 11–13 September 2015; pp. 75–78. [Google Scholar]
- Van Le, H.; Takasu, A. G-hbase: A high performance geographical database based on hbase. IEICE Trans. Inf. Syst. 2018, 101, 1053–1065. [Google Scholar]
- Kuo, C.T.; Hon, W.K. Practical index framework for efficient time-travel phrase queries on versioned documents. In Proceedings of the 2016 Data Compression Conference (DCC), Snowbird, UT, USA, 30 March–1 April 2016; pp. 556–565. [Google Scholar]
- Cao, C.; Wang, W.; Zhang, Y.; Ma, X. Leveraging column family to improve multi-dimensional query performance in HBase. In Proceedings of the 2017 IEEE 10th International Conference on Cloud Computing (CLOUD), Honolulu, CA, USA, 25–30 June 2017; pp. 106–113. [Google Scholar]
- Wu, H.; Zhu, Y.; Wang, C.; Hou, J.; Li, M.; Xue, Q.; Mao, K. A performance-improved and storage-efficient secondary index for big data processing. In Proceedings of the 2017 IEEE International Conference on Smart Cloud (SmartCloud), New York, NY, USA, 3–5 November 2017; pp. 161–167. [Google Scholar]
- Chi, Y.; Yang, Y.; Xu, P.; Li, G.; Li, S. Design and implementation of monitoring data storage and processing scheme based on distributed computing. In Proceedings of the 2018 IEEE 3rd International Conference on Big Data Analysis (ICBDA), Shanghai, China, 9–12 March 2018; pp. 206–211. [Google Scholar]
- Xu, Y.; Zou, Q.; Feng, X. Efficient and Timely Querying of Massive Trajectory Data in Internet of Vehicles. In Proceedings of the 2016 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Chengdu, China, 15–18 December 2016; pp. 293–298. [Google Scholar]
- Habeeb, R.A.A.; Nasaruddin, F.; Gani, A.; Hashem, I.A.T.; Ahmed, E.; Imran, M. Real-time big data processing for anomaly detection: A survey. Int. J. Inf. Manag. 2019, 45, 289–307. [Google Scholar] [CrossRef] [Green Version]
- Neilson, A.; Daniel, B.; Tjandra, S. Systematic review of the literature on big data in the transportation domain: Concepts and applications. Big Data Res. 2019, 17, 35–44. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Research Questions | Objectives |
|---|---|---|
| RQ1 | What are the primary datasets and storage techniques used by the researchers? | The aim is to investigate the primary focus of the researcher in datasets and storage techniques. |
| RQ2 | What are the primary factors of selecting HBase storage architecture in various domains? | The aim is to investigate the domain that is working on HBase storage architecture. |
| RQ3 | Are the proposed approaches application/data-specific or generic? | The aim is to identify whether the proposed techniques are data-specific or generic. |
| Resources | Hyperlinks |
|---|---|
| IEEEXplore | https://ieeexplore.ieee.org/ |
| ACM | https://dl.acm.org/ |
| ScienceDirect | https://www.sciencedirect.com/ |
| Inclusion Rules | Exclusion Rules | |
|---|---|---|
| 1 | Those papers that address one research question at least. | Papers do not answer even a single defined research question. |
| 2 | Those papers have the ultimate goal of HBase storage architecture, data model, and storage techniques and do not concentrate on other HBase issues. | Papers do not use HBase for storage architecture; they only discuss the working of HBase architecture. |
| 3 | Those papers that are published in journals or conferences. | Papers are not published at conferences or in journals. |
| 4 | Papers do not have full text. | |
| 5 | Short articles and discussions. |
| Stages | Applied Inclusion and Exclusion Rules |
|---|---|
| Stage 1 | Performed the defined research query on the selected sources. |
| Stage 2 | Downloaded all the papers by just going through abstract, title, keywords, and those related to the research question. |
| Stage 3 | Applied the inclusion and exclusion defined rules. |
| Stage 4 | Deeply studied all the contents and finalized for systematic literature review (SLR). |
| Source | Stage 1 | Stage 2 | Stage 3 | Stage 4 |
|---|---|---|---|---|
| ScienceDirect | 690 | 89 | 20 | 13 |
| IEEEXplore | 380 | 120 | 60 | 15 |
| ACM | 108 | 60 | 15 | 03 |
| Total | 1178 | 269 | 95 | 31 |
| No. | Dataset | Storage Technique |
|---|---|---|
| [P1] [11] | Remote sensing data | A distributed storage model for heterogeneous remote sensing data. Data were stored as a NetCDF (Network Common Data Form) file. |
| [P2] [15] | Wireless sensor data (IoT) | A two-layer distributed storage structure was designed: (1) distributed database to store metadata; (2) MySQL to store sensor data. |
| [P3] [16] | Wireless sensor data | Designed a real-time storage model: stored massive data quickly. |
| [P4] [17] | Power grid | A versatile event-driven data model for power grid multi-source data. |
| [P5] [18] | Internet of Vehicles (IoV) | A distributed storage and processing system on HBase. |
| [P6] [19] | Sensor data | Designed a data processing middleware for storing sensor data. |
| [P7] [20] | Remote sensor image data | The storage model of remote sensing image data was designed. |
| [P8] [21] | Geospatial data | Designed the HBase table to store Geospatial dataUsed the MapReduce to improve input/output (I/O) efficiency for geospatial data. |
| [P9] [22] | Geographic data/spatial-temporal | An efficient organization and storage proposed by adopting the strong expansibility for spatial-temporal information. |
| [P10] [23] | Spatial vector | Designed two models: (1) HBase storage schema with Z curve as row key; (2) HBase storage schema with geometry objects identifiers as the row key. |
| [P11] [24] | Sea wind and satellite image | Geographical information query system based on HBase storage model. |
| [P12] [25] | Spatial-temporal | Proposed an Automatic Identification System based on HBase and Spark (AISHS). |
| [P13] [26] | Location-based data | Proposed a multi-dimensional data storage model Index structure using quadtree over HBase. |
| [P14] [27] | Healthcare data | Designed a multi-table structure and three kinds of index tables. |
| [P15] [28] | Healthcare data | Designed an architecture for healthcare big data management and analysis. For personal health problem detection and vital real-time sign monitoring, a prototype system was constructed. |
| [P16] [29] | Equipment dataset | The data model of the equipment database was designed based on HBase. Equipment data’s reading and writing processes were established. |
| [P17] [30] | Electricity power data | A distributed storage system on HBase for electric power data. |
| [P18] [31] | Electric consumption data | Storage model for electric power to manage Morocco school electricity consumption. |
| [P19] [32] | Sample data and alarm dataset in a power system | Designed a data storage structure for power data. |
| [P20] [33] | E-Commerce | Designed a non-primary key table; through this primary table query, the row key table is generated. |
| [P21] [34] | DNA | DNA sequence storage schemes based on HBase were designed. |
| [P22] [35] | E-Commerce | Devised a new distributed data storage framework for e-commerce data. |
| [P23] [36] | Marketing strategy | Designed a unique table schema on HBase to store business data. |
| [P24] [37] | Online data | Redesigned the HBase Architecture, used the thinner layer of a log-structured B+ tree to store actual data instead of HDFS. |
| [P25] [38] | Urban traffic data (Time-series) | Designed a distributed storage model for urban road traffic data. |
| [P26] [39] | Geography | Designed high-performance geographical database. |
| [P27] [40] | Document data | Designed an index framework to store versioned documents and processed them efficiently. |
| [P28] [41] | Bixi Data (Time-series dataset collected by the sensor) | Designed a Column Family Indexed Data Model. |
| [P29] [42] | Power grid | A secondary index on the event-driven storage model. |
| [P30] [43] | Traffic data (Time-series) | A scheme for monitoring data storage and processing; used the HBase to store timing monitoring data. Enhanced the field method to improve storage efficiency. |
| [P31] [44] | IoV | A row key structure design to store IoV data. |
| No. | Storage Efficient | Scalable | Novel Technique | Indexing/Row Key | Improved Reading/Writing | Main Features | Experimental | Implementation |
|---|---|---|---|---|---|---|---|---|
| [P1] | ✔ | ✔ | ✔ | Elastic based secondary | ✔ | Managed heterogeneous remote sensing data. | ✔ | ✔ |
| [P2] | ✔ | ✔ | ✔ | Implement row key in lexicographic order | ✔ | Solved the issue of hotspot data scatter and high concurrent transactions. | Not mentioned (NM) | ✔ |
| [P3] | ✔ | ✔ | ✖ | ✖ | Quickly stored massive sensor data. | ✔ | ✔ | |
| [P4] | ✔ | ✔ | ✔ | Event type and event time as the row key | ✔ | Novel virtual column family improved the join operation. | ✔ | ✔ |
| [P5] | ✔ | ✔ | ✔ | Single row key, complexed row key | ✔ | Overcame the single point of failure. Reliable data storage. Met the real-time computing requirements. | ✔ | ✔ |
| [P6] | ✔ | ✔ | ✔ | ✖ | ✔ | Redesigned the HBase table, solved the problem of the hotspot. | ✔ | ✔ |
| [P7] | ✔ | ✔ | ✔ | Grid index and the Hibert curve | ✔ | Stored imaged data. Effectively improved the data writing and query speed, and showed good scalability. | ✖ | ✔ |
| [P25] | ✔ | ✔ | ✖ | ✔ | ✔ | Stored the traffic data. | ✔ | ✔ |
| [P30] | ✔ | ✔ | ✔ | Hash prefix with a timestamp | ✔ | Improved the HBase table for time series data. | ✖ | ✔ |
| [P31] | ✔ | ✔ | ✖ | ✔ | ✔ | Improved query performance of time series data. | ✔ | ✔ |
| No. | Storage Efficient | Scalable | Novel Technique | Indexing/Row Key | Improved Reading/Writing | Main Features | Experimental | Implementation |
|---|---|---|---|---|---|---|---|---|
| [P8] | ✔ | ✔ | ✔ | Geo Hash | ✔ | Improved I/O efficiency. | ✔ | ✔ |
| [P9] | ✔ | ✔ | ✔ | ✔ | ✔ | Improved query processing time. | ✔ | ✖ |
| [P10] | ✔ | ✔ | ✔ | Z curve or Geometry object identifier | ✔ | Improved query performance. | ✔ | ✖ |
| [P11] | ✔ | ✔ | ✔ | ✔ | ✔ | Improved write operation, and a log layer was used instead of HDFS. | ✔ | ✔ |
| [P12] | ✔ | ✔ | ✔ | Combination of B-order value and keyword | ✔ | Improved query efficiency and reduced the time consumption of spatial queries. | ✔ | ✔ |
| [P13] | ✔ | ✔ | ✔ | Index structure using quadtree over HBase | ✔ | Multi-dimensional data storage. Thousands of location updates per second | ✖ | ✔ |
| [P26] | ✔ | ✖ | ✔ | Geohash | ✔ | Decreased the spatial query time. | ✔ | ✔ |
| No. | Storage Efficient | Scalable | Novel Technique | Indexing/Row Key | Improved Reading/Writing | Main Features | Experimental | Implementation |
|---|---|---|---|---|---|---|---|---|
| [P14] | ✔ | ✔ | ✔ | Personal Identification Number (PIN) | Improved reading/writing by three index table | Multi-tables structure, simple or complex row key. | ✔ | ✔ |
| [P15] | ✔ | ✔ | ✔ | ✔ | NM | Detected potential health problems. | ✔ | ✔ |
| [P16] | ✔ | ✔ | ✔ | Equipment code is used as the row key | ✔ | Improved the reading/writing operation. Organized the equipment data into three dimensions. Supported fast retrieval of massive data. | NM | ✔ |
| No. | Storage Efficient | Scalable | Novel Technique | Indexing/Row Key | Improved Reading/Writing | Main Features | Experimental | Implementation |
|---|---|---|---|---|---|---|---|---|
| [P17] | ✔ | ✔ | ✔ | Combination of region key, name, id, and timestamp | ✔ | Improved writing operation | ✔ | ✔ |
| [P18] | ✔ | ✔ | ✔ | Combination of column and timestamp value | Decrease the cost of the expense of electrical consumption | School electric data storage | ✔ | ✔ |
| [P19] | ✔ | ✔ | ✔ | Sequential key | ✖ | Stored the massive power data quickly | ✖ | ✔ |
| [P28] | ✔ | ✔ | ✔ | ✔ | ✔ | Improved the multi-dimension query time | ✔ | ✔ |
| [P29] | ✔ | ✔ | ✔ | Event time used as the row key | ✔ | Improved the reading operation | ✔ | ✔ |
| No. | Storage Efficient | Scalable | Novel Technique | Indexing/Row Key | Improved Reading/Writing | Main Features | Experimental | Implementation |
|---|---|---|---|---|---|---|---|---|
| Document Domain | ||||||||
| [P27] | ✖ | ✔ | ✔ | ✔ | Indexing technique on versioned document | ✔ | ✔ | |
| Marketing Domain | ||||||||
| [P20] | ✔ | ✔ | ✔ | ✔ | ✔ | Improved the data processing by adding the index table in each region | ✖ | ✔ |
| [P22] | ✔ | ✔ | ✔ | ✖ | ✔ | Solved the issue of hotspot data. Improved storage balance. | ✔ | ✔ |
| [P23] | ✔ | ✔ | ✔ | ✔ | ✔ | An optimized table schema for suggesting marking strategy operations. | ✖ | ✔ |
| Different Domain | ||||||||
| [P21] | ✔ | ✔ | ✔ | DNA classification code used as the row key | ✔ | Solved the issue of hotspot data. | ✖ | ✔ |
| [P24] | ✔ | ✔ | ✔ | ✔ | ✔ | Changed the layered architecture of HBase. | ✔ | ✔ |
| Years | Worked | Domain |
|---|---|---|
| (2015 to 2019) | [P1–P7], [P25], [P30], [P31] | Sensor |
| [P8–P13], [P26] | Geospatial | |
| [P14–P16] | Healthcare | |
| [P17–P19], P28], [P29] | Electric power | |
| [P21], [P24] | Different datasets | |
| [P27] | Documents | |
| [P20], [P22], [P23] | Marketing |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassan, M.U.; Yaqoob, I.; Zulfiqar, S.; Hameed, I.A. A Comprehensive Study of HBase Storage Architecture—A Systematic Literature Review. Symmetry 2021, 13, 109. https://doi.org/10.3390/sym13010109
Hassan MU, Yaqoob I, Zulfiqar S, Hameed IA. A Comprehensive Study of HBase Storage Architecture—A Systematic Literature Review. Symmetry. 2021; 13(1):109. https://doi.org/10.3390/sym13010109
Chicago/Turabian StyleHassan, Muhammad Umair, Irfan Yaqoob, Sidra Zulfiqar, and Ibrahim A. Hameed. 2021. "A Comprehensive Study of HBase Storage Architecture—A Systematic Literature Review" Symmetry 13, no. 1: 109. https://doi.org/10.3390/sym13010109