Relation Representation Learning via Signed Graph Mutual Information Maximization for Trust Prediction


Abstract
:1. Introduction
- We propose a novel relation representation learning model via maximizing mutual information between the signed graph and entity relation representation, which is preferable and suitable for trust networks modeling.
- We first introduce translation principle to signed graph to explore abundant feature and semantic information of edges on the signed graph.
- We develop a trust prediction algorithm that takes the learned relation representation vector to complete the trust prediction tasks.
- Experiments with four real-world datasets show that SGMIM can obtain efficient accuracy.
2. Related Work
2.1. Approaches Based on Social Network Analysis
2.2. Approaches Based on GNNs
2.3. Approaches Based on Signed Graph
3. Preliminaries
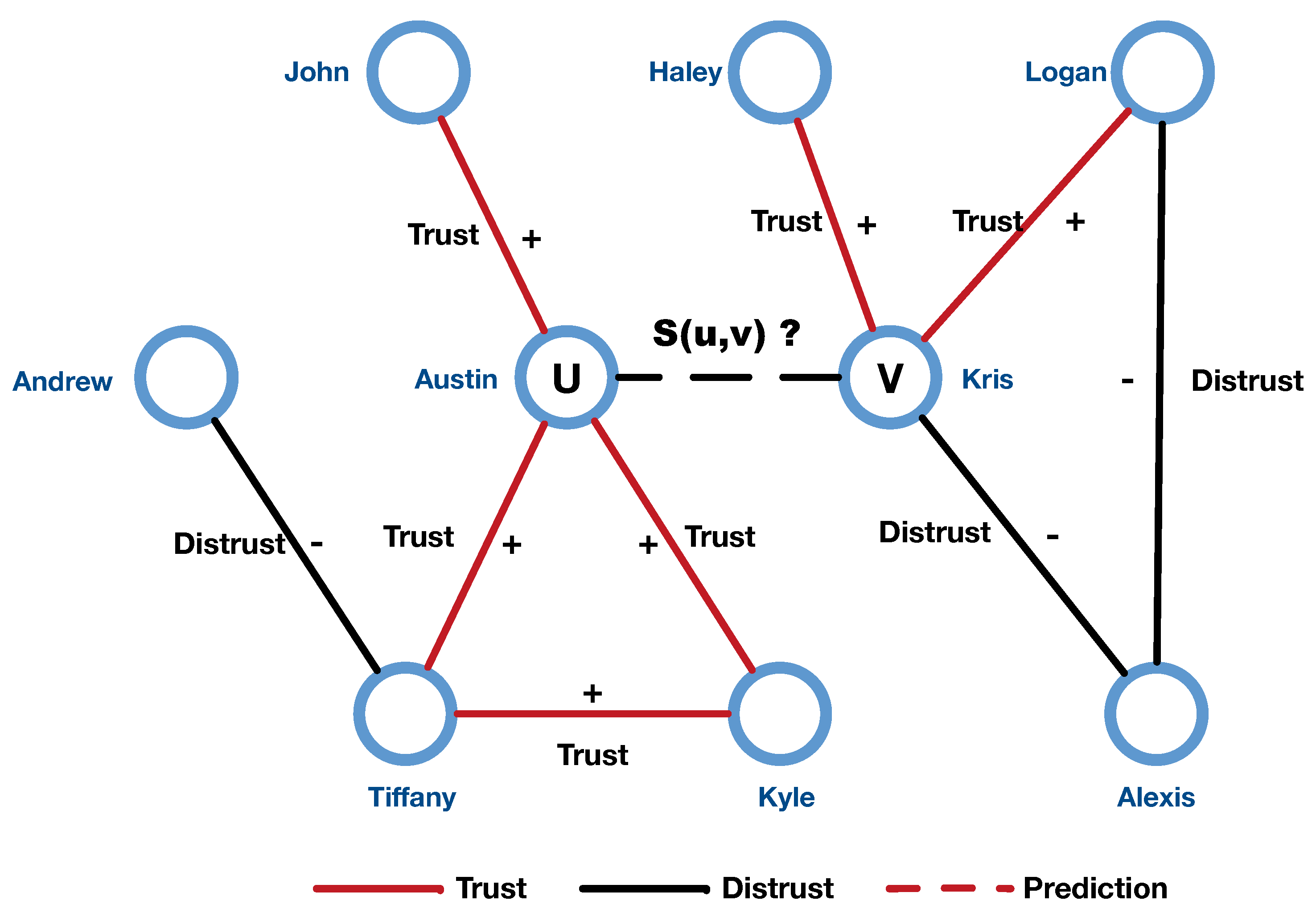
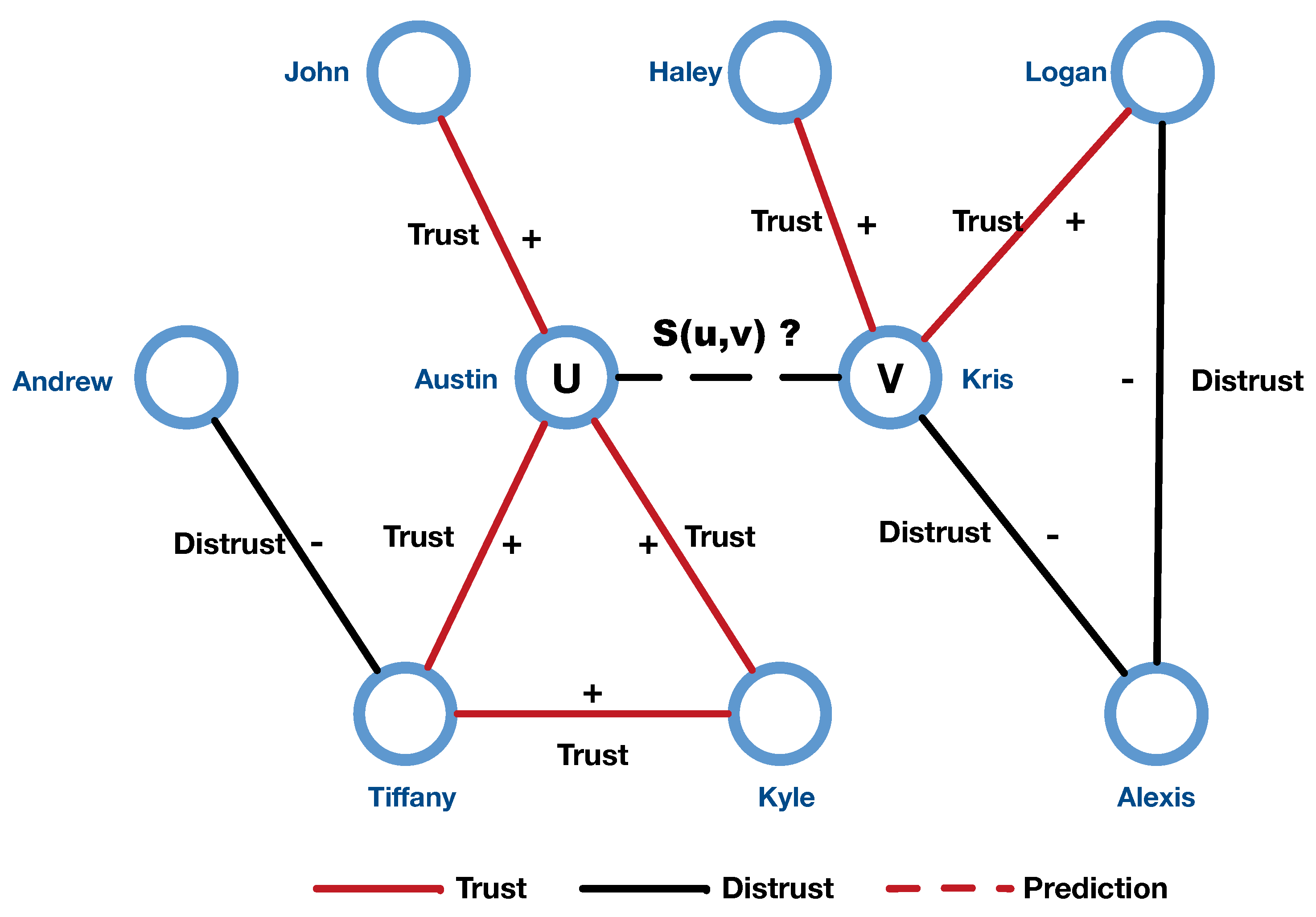
3.1. Problem Formulation
3.2. Mutual Information
4. Proposed Method
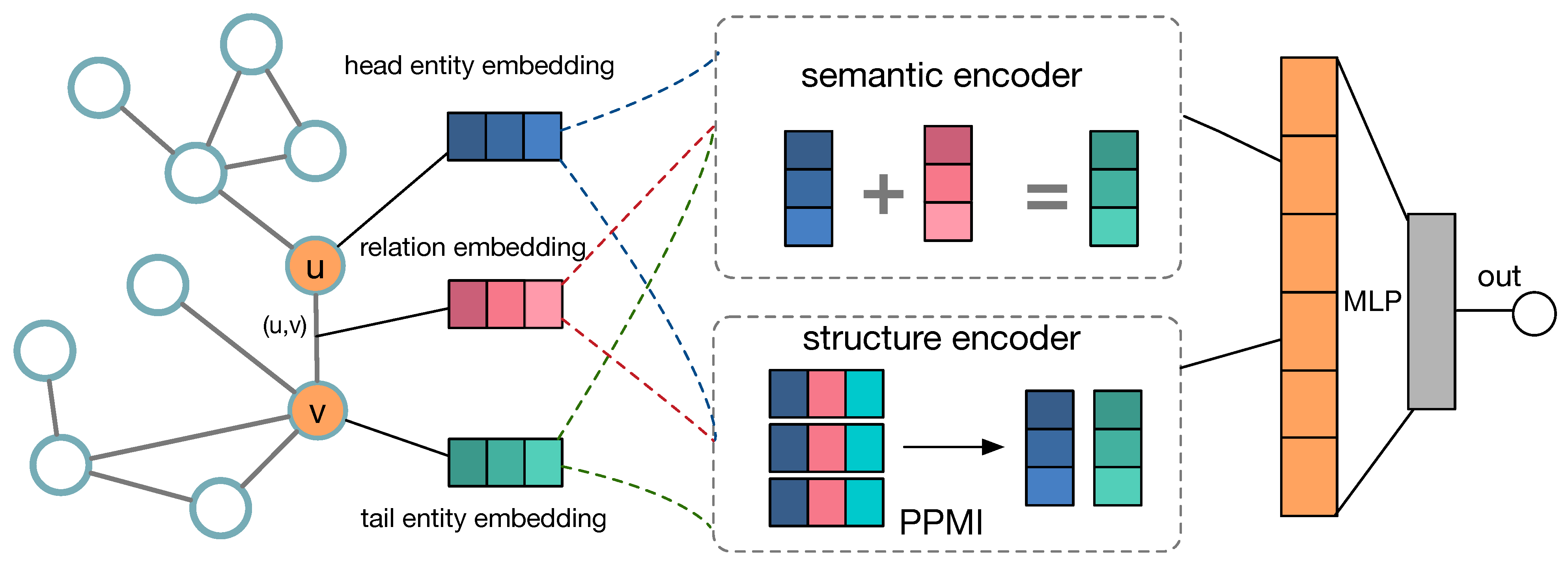
4.1. Framework
4.2. Encoding Semantic Relation
4.3. Learning Structure Information
4.4. Model Training
| Algorithm 1Traning process of SGMIM model |
| Require:G: ; A: adjacency matrix; S: sign set of edges; k: dimension of node embedding vector; m: dimension of edge embedding vector; : hyper-parameter; epoches: iterate number. |
| Ensure:U: head entity representation; V: tail entity representation; R: relation representation. |
| 1: Initialization U, V, R |
| 2: Calculate PPMI Z |
| 3: for iter in range(epoches) |
| 4: Sample positive triple (u, r, v) |
| 5: Generate embedding U, R, V |
| 6: Sample negative triple (u’, r, v’) |
| 7: Generate embedding U’, R, V’ |
| 8: |
| 9: score = Discriminator(, ) |
| 10: Loss1 = BCEWithLogicLoss(score, S) |
| 11: Loss2 = CrossEntropyLoss(, Z) |
| 12: Loss = Loss1+(1−Loss2 |
| 13: Update U, R, V |
| 14: Loss Backforward |
| 15: end for |
5. Experiments
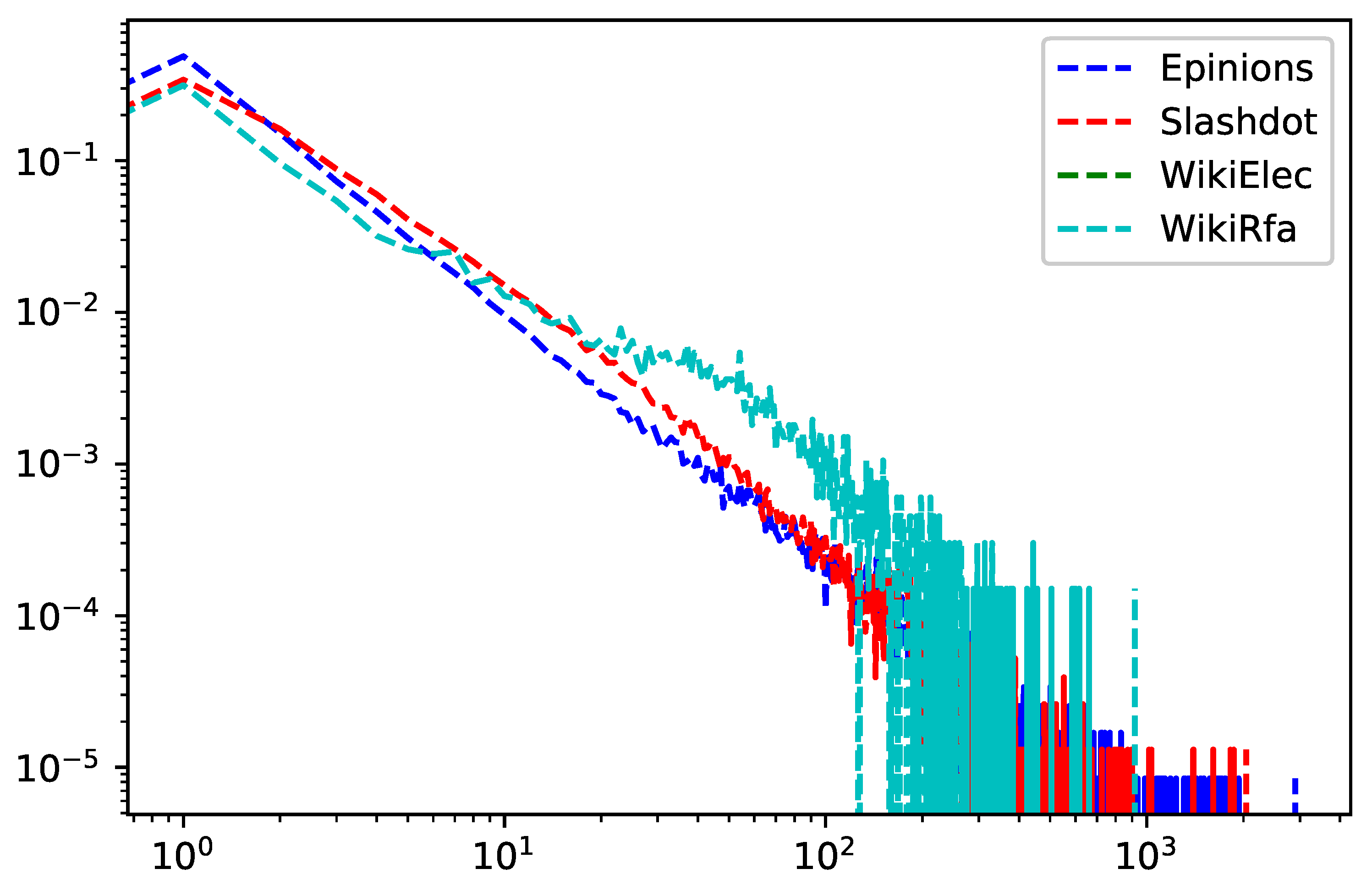
5.1. Datasets
5.2. Baselines
5.3. Evaluation Metric
5.4. Experimental Results
5.5. Parameter Sensitivity
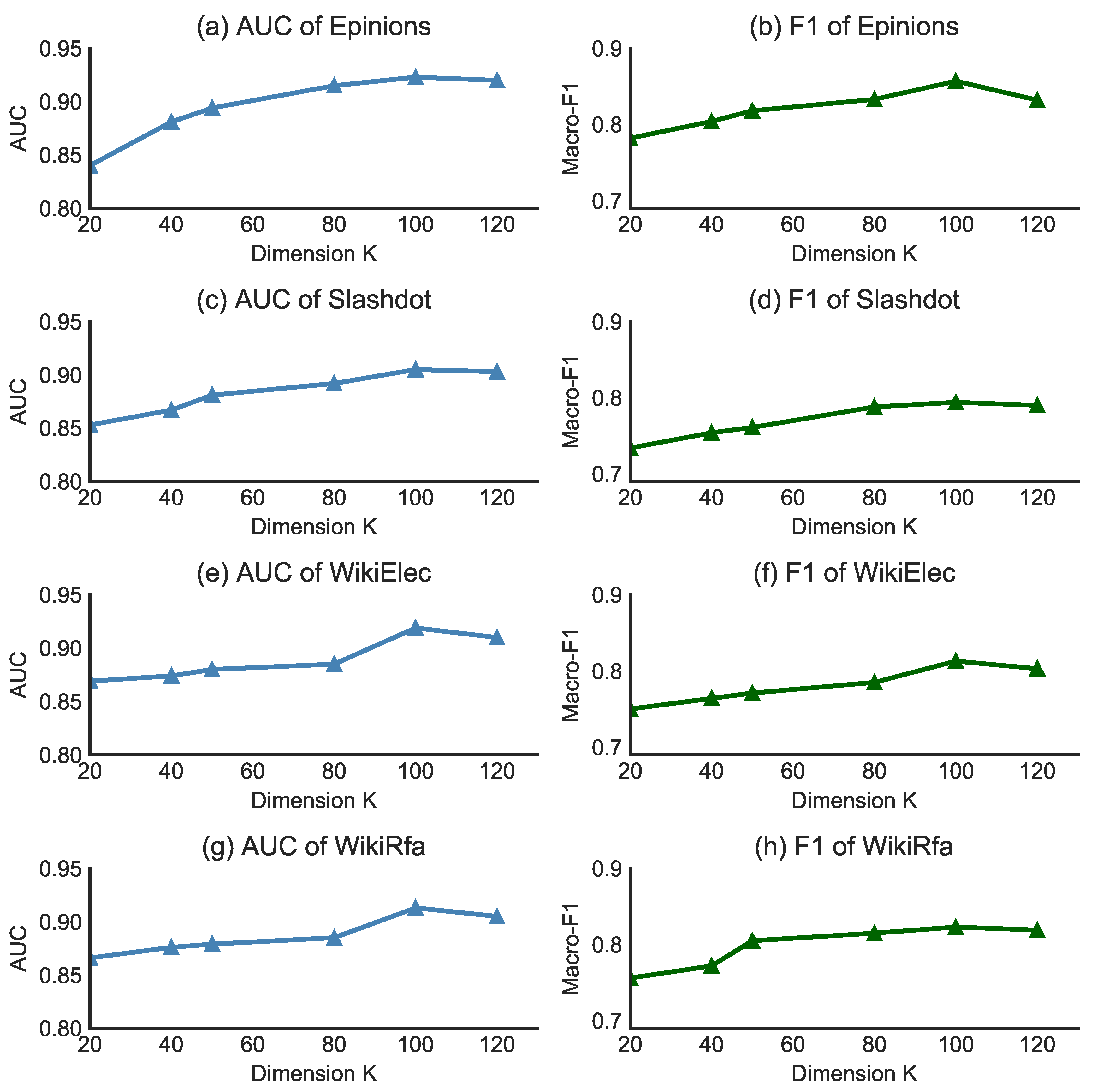
5.5.1. Dimension
5.5.2. Hyper-Parameters
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kipf, T.N.; Welling, M. Variational Graph Auto-Encoders. arXiv 2016, arXiv:1611.07308. [Google Scholar]
- Liben-Nowell, D.; Kleinberg, J. The link-prediction problem for social networks. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1019–1031. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Chen, Y. Link prediction based on graph neural networks. In Advances in Neural Information Processing Systems; 2018; pp. 5171–5181. Available online: https://papers.nips.cc/paper/2018/file/53f0d7c537d99b3824f0f99d62ea2428-Paper.pdf (accessed on 11 January 2021).
- Qu, M.; Bengio, Y.; Tang, J. GMNN: Graph Markov Neural Networks. arXiv 2019, arXiv:1905.06214. [Google Scholar]
- Wu, J.; He, J.; Xu, J. DEMO-Net: Degree-specific Graph Neural Networks for Node and Graph Classification. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 406–415. [Google Scholar]
- Zhang, Y.; Pal, S.; Coates, M.; Ustebay, D. Bayesian Graph Convolutional Neural Networks for Semi-Supervised Classification. Proc. AAAI Conf. Artif. Intell. 2019, 33, 5829–5836. [Google Scholar] [CrossRef]
- Bjerrum, E.J.; Threlfall, R. Molecular Generation with Recurrent Neural Networks (RNNs). arXiv 2017, arXiv:1705.04612. [Google Scholar]
- Bresson, X.; Laurent, T. A Two-Step Graph Convolutional Decoder for Molecule Generation. arXiv 2019, arXiv:1906.03412. [Google Scholar]
- Chen, C.; Ye, W.; Zuo, Y.; Zheng, C.; Ong, S.P. Graph Networks as a Universal Machine Learning Framework for Molecules and Crystals. Chem. Mater. 2019, 31, 3564–3572. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Cui, P.; Wang, J.; Pei, J.; Yang, S. Community Preserving Network Embedding. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Cao, S.; Wei, L.; Xu, Q. GraRep: Learning Graph Representations with Global Structural Information. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015. [Google Scholar]
- Tang, J.; Chang, Y.; Aggarwal, C.; Liu, H. A Survey of Signed Network Mining in Social Media. ACM Comput. Surv. 2016, 49, 42. [Google Scholar] [CrossRef]
- Tang, J.; Hu, X.; Liu, H. Is distrust the negation of trust? The value of distrust in social media. In Proceedings of the 25th ACM Conference on Hypertext and Social Media, Santiago, Chile, 1–4 September 2014; pp. 148–157. [Google Scholar]
- Somu, N.; Raman, M.R.G.; Kalpana, V.; Kirthivasan, K.; Sriram, V.S.S. An improved robust heteroscedastic probabilistic neural network based trust prediction approach for cloud service selection. Neural Netw. 2018, 108, 339–354. [Google Scholar] [CrossRef]
- Leskovec, J.; Huttenlocher, D.; Kleinberg, J. Predicting positive and negative links in online social networks. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 641–650. [Google Scholar]
- Victor, P.; Cornelis, C.; Cock, M.D.; Teredesai, A.M. Trust- and Distrust-Based Recommendations for Controversial Reviews. IEEE Intell. Syst. 2011, 26, 48–55. [Google Scholar] [CrossRef] [Green Version]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Representation Learning on Graphs: Methods and Applications. IEEE Data (Base) Eng. Bull. 2017, 40, 52–74. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. ICLR (Poster). arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Hamilton, W.L.; Ying, Z.; Leskovec, J. Inductive Representation Learning on Large Graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 1024–1034. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R. Gated Graph Sequence Neural Networks. arXiv 2015, arXiv:1511.05493. [Google Scholar]
- Wang, S.; Tang, J.; Aggarwal, C.C.; Chang, Y.; Liu, H. Signed network embedding in social media. In Proceedings of the 17th SIAM International Conference on Data Mining, Houston, TX, USA, 27–29 April 2017; pp. 327–335. [Google Scholar]
- Yuan, S.; Wu, X.; Xiang, Y. SNE: Signed Network Embedding. In Proceedings of the Pacific-asia Conference on Knowledge Discovery & Data Mining, Jeju, Korea, 23–26 May 2017; pp. 183–195. [Google Scholar]
- Wang, S.; Aggarwal, C.; Tang, J.; Liu, H. Attributed Signed Network Embedding. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 137–146. [Google Scholar]
- Cheng, K.; Li, J.; Liu, H. Unsupervised Feature Selection in Signed Social Networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 777–786. [Google Scholar]
- Kamvar, S.D.; Schlosser, M.T.; Garcia-Molina, H. The Eigentrust algorithm for reputation management in P2P networks. In Proceedings of the International Conference on World Wide Web, Budapest, Hungary, 20–24 May 2003; pp. 640–651. [Google Scholar]
- Josang, A. A logic for uncertain probabilities. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2001, 9, 279–311. [Google Scholar] [CrossRef]
- Golbeck, J.A. Computing and Applying Trust in Web-Based Social Networks; University of Maryland at College Park: College Park, MD, USA, 2005. [Google Scholar]
- Novák, V.; Perfilieva, I.; Močkoř, J. Mathematical Principles of Fuzzy Logic; Kluwer Academic: Dordrecht, The Netherlands, 1999; pp. 1–5. [Google Scholar]
- Hao, F.; Min, G.; Lin, M.; Luo, C.; Yang, L.T. MobiFuzzyTrust: An Efficient Fuzzy Trust Inference Mechanism in Mobile Social Networks. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 2944–2955. [Google Scholar] [CrossRef]
- Kant, V.; Bharadwaj, K.K. Fuzzy Computational Models of Trust and Distrust for Enhanced Recommendations. Int. J. Intell. Syst. 2013, 28, 332–365. [Google Scholar] [CrossRef]
- Rasmusson, L.; Jansson, S. Simulated social control for secure Internet commerce. In Proceedings of the 1996 Workshop on New Security Paradigms, Lake Arrowhead, CA, USA, 17–20 September 1996; pp. 18–25. [Google Scholar]
- Massa, P.; Avesani, P. Controversial Users Demand Local Trust Metrics: An Experimental Study on Epinions.com Community. In Proceedings of the AAAI-05, Pittsburgh, PA, USA, 9–13 July 2005; pp. 121–126. [Google Scholar]
- Kim, Y.A.; Song, H.S. Strategies for predicting local trust based on trust propagation in social networks. Knowl. Based Syst. 2011, 24, 1360–1371. [Google Scholar] [CrossRef]
- Tang, J.; Gao, H.; Hu, X.; Liu, H. Exploiting homophily effect for trust prediction. In Proceedings of the ACM International Conference on Web Search and Data Mining, Rome, Italy, 4–8 February 2013; pp. 53–62. [Google Scholar]
- Yao, Y.; Tong, H.; Lu, J.; Lu, J.; Lu, J. MATRI: A multi-aspect and transitive trust inference model. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1467–1476. [Google Scholar]
- Belkin, M.; Niyogi, P. Laplacian eigenmaps and spectral techniques for embedding and clustering. Adv. Neural Inf. Process. Syst. 2001, 14, 585–591. [Google Scholar]
- Tang, L.; Liu, H. Leveraging social media networks for classification. Data Min. Knowl. Discov. 2011, 23, 447–478. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear Dimensionality Reduction by Locally Linear Embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saul, L.K.; Roweis, S.T. An introduction to locally linear embedding. J. Mach. Learn. Res. 2008, 7. Available online: http://www.cs.columbia.edu/~jebara/6772/papers/lleintro.pdf (accessed on 11 January 2021).
- Yang, Q.; Chen, M.; Tang, X. Directed graph embedding. In IJCAI; 2009; pp. 2707–2712. Available online: https://www.aaai.org/Papers/IJCAI/2007/IJCAI07-435.pdf (accessed on 11 January 2021).
- Perozzi, B.; Al-Rfou, R.; Skiena, S. DeepWalk: Online learning of social representations. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–17 August 2014; pp. 701–710. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable Feature Learning for Networks. In Proceedings of the ACM Sigkdd International Conference on Knowledge Discovery & Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. LINE: Large-scale Information Network Embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How Powerful are Graph Neural Networks. arXiv 2018, arXiv:1810.00826. [Google Scholar]
- You, J.; Liu, B.; Ying, R.; Pande, V.; Leskovec, J. Graph convolutional policy network for goal-directed molecular graph generation. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 31, pp. 6412–6422. [Google Scholar]
- Sun, F.Y.; Hoffman, J.; Verma, V.; Tang, J. InfoGraph: Unsupervised and Semi-supervised Graph-Level Representation Learning via Mutual Information Maximization. arXiv 2020, arXiv:1908.01000. [Google Scholar]
- Guha, R.; Kumar, R.; Raghavan, P.; Tomkins, A. Propagation of trust and distrust. In Proceedings of the International Conference on World Wide Web, New York, NY, USA, 17–20 May 2004; pp. 403–412. [Google Scholar]
- Mishra, A.; Bhattacharya, A. Finding the bias and prestige of nodes in networks based on trust scores. In Proceedings of the 20th International Conference on World Wide Web (WWW 2011), Hyderabad, India, 28 March–1 April 2011. [Google Scholar]
- Zolfaghar, K.; Aghaie, A. Mining trust and distrust relationships in social Web applications. In Proceedings of the 2010 IEEE 6th International Conference on Intelligent Computer Communication and Processing (ICCP10), Cluj-Napoca, Romania, 26–28 August 2010; pp. 73–80. [Google Scholar] [CrossRef]
- Velikovi, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep Graph Infomax. In Proceedings of the 2018 International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Peng, Z.; Huang, W.; Luo, M.; Zheng, Q.; Rong, Y.; Xu, T.; Huang, J. Graph Representation Learning via Graphical Mutual Information Maximization. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020. [Google Scholar]
- Belghazi, I.; Rajeswar, S.; Baratin, A.; Hjelm, R.D.; Courville, A. MINE: Mutual Information Neural Estimation. ArXiv 2018, arXiv:1801.04062. [Google Scholar]
- Donsker, M.D.; Varadhan, S.S. Asymptotic evaluation of certain markov process expectations for large time. IV. Commun. Pure Appl. Math. 1983, 36, 183–212. [Google Scholar] [CrossRef]
- Gutmann, M.U.; Hyvärinen, A. Noise-Contrastive Estimation of Unnormalized Statistical Models, with Applications to Natural Image Statistics. J. Mach. Learn. Res. 2012, 13, 307–361. [Google Scholar]
- Logeswaran, L.; Lee, H. An efficient framework for learning sentence representations. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April 30–3 May 2018. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv 2018, arXiv:1808.06670. [Google Scholar]
- Zhou, K.; Wang, H.; Zhao, W.; Zhu, Y.; Wang, S.; Zhang, F.; Wang, Z.; Wen, J.R. S3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Galway, Ireland, 19–23 October 2020. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Durán, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-Relational Data. In Proceedings of the 26th International Conference on Neural Information Processing Systems (NIPS’13), Lake Tahoe, NV, USA, 5–8 December 2013; Curran Associates Inc.: Red Hook, NY, USA, 2013; Volume 2, pp. 2787–2795. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence (AAAI’15), Austin, TX, USA, 25–30 January 2015; pp. 2181–2187. [Google Scholar]
- Sun, Z.; Deng, Z.H.; Nie, J.Y.; Tang, J. RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space. arxiv 2019, arXiv:1902.10197. [Google Scholar]
- Bullinaria, J.A.; Levy, J.P. Extracting semantic representations from word co-occurrence statistics: A computational study. Behav. Res. Methods 2007, 39, 510–526. [Google Scholar] [CrossRef] [Green Version]
- Kunegis, J.; Schmidt, S.; Lommatzsch, A.; Lerner, J.; Albayrak, S. Spectral Analysis of Signed Graphs for Clustering, Prediction and Visualization. In Proceedings of the Siam International Conference on Data Mining, Columbus, OH, USA, 29 April–1 May 2010. [Google Scholar]
- Leskovec, J. Signed Networks in Social Media. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 10–15 April 2010. [Google Scholar]
- Song, W.; Wang, S.; Yang, B.; Lu, Y.; Zhao, X.; Liu, X. Learning Node and Edge Embeddings for Signed Networks. Neurocomputing 2018, 319, 42–54. [Google Scholar] [CrossRef]
- Demiar, J.; Schuurmans, D. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| G | signed trust network |
| V | set of vertexes |
| set of positive edges | |
| set of negative edges | |
| out degree of node | |
| in degree of node | |
| dimensions of node representation | |
| dimensions of relation representation | |
| n | size of vertex |
| Statistics | Epinions | Slashdot | WikiElec | WikiRfa |
|---|---|---|---|---|
| nodes num | 131,828 | 82,140 | 7194 | 10,885 |
| edges num | 841,372 | 549,202 | 114,040 | 137,966 |
| positive num | 717,690 | 425,083 | 90,890 | 109,269 |
| negative num | 123,682 | 124,119 | 23,150 | 28,697 |
| average sparsity | 22.4 | 14.7 | 25.5 | 31.3 |
| Dataset | Epinions | Slashdot | WikiElec | WikiRfa | |||||
|---|---|---|---|---|---|---|---|---|---|
| Dimension | Algorithm | F1 | AUC | F1 | AUC | F1 | AUC | F1 | AUC |
| SC | 0.729 | 0.801 | 0.687 | 0.761 | 0.708 | 0.724 | 0.719 | 0.783 | |
| SNE | 0.748 | 0.854 | 0.712 | 0.830 | 0.734 | 0.827 | 0.740 | 0.852 | |
| K = 20 | SiNE | 0.756 | 0.879 | 0.726 | 0.849 | 0.749 | 0.845 | 0.754 | 0.866 |
| nSNE | 0.739 | 0.847 | 0.720 | 0.827 | 0.743 | 0.869 | 0.731 | 0.830 | |
| SGMIM | 0.780 | 0.872 | 0.734 | 0.853 | 0.750 | 0.863 | 0.756 | 0.857 | |
| SC | 0.754 | 0.813 | 0.694 | 0.787 | 0.702 | 0.815 | 0.713 | 0.781 | |
| SNE | 0.785 | 0.856 | 0.739 | 0.859 | 0.724 | 0.841 | 0.760 | 0.843 | |
| K = 50 | SiNE | 0.790 | 0.883 | 0.742 | 0.822 | 0.731 | 0.866 | 0.754 | 0.853 |
| nSNE | 0.809 | 0.802 | 0.737 | 0.748 | 0.757 | 0.870 | 0.741 | 0.862 | |
| SGMIM | 0.818 | 0.896 | 0.761 | 0.871 | 0.763 | 0.887 | 0.772 | 0.886 | |
| SC | 0.764 | 0.789 | 0.705 | 0.773 | 0.697 | 0.822 | 0.704 | 0.813 | |
| SNE | 0.783 | 0.863 | 0.748 | 0.859 | 0.738 | 0.840 | 0.780 | 0.846 | |
| K = 80 | SiNE | 0.787 | 0.891 | 0.763 | 0.886 | 0.745 | 0.868 | 0.795 | 0.881 |
| nSNE | 0.812 | 0.882 | 0.766 | 0.842 | 0.726 | 0.865 | 0.782 | 0.858 | |
| SGMIM | 0.833 | 0.901 | 0.778 | 0.892 | 0.781 | 0.899 | 0.805 | 0.902 | |
| SC | 0.769 | 0.789 | 0.711 | 0.764 | 0.720 | 0.812 | 0.713 | 0.813 | |
| SNE | 0.803 | 0.873 | 0.759 | 0.859 | 0.767 | 0.880 | 0.781 | 0.882 | |
| K = 100 | SiNE | 0.816 | 0.901 | 0.776 | 0.892 | 0.805 | 0.908 | 0.809 | 0.894 |
| nSNE | 0.832 | 0.912 | 0.750 | 0.841 | 0.782 | 0.879 | 0.773 | 0.886 | |
| SGMIM | 0.857 | 0.921 | 0.794 | 0.905 | 0.814 | 0.919 | 0.814 | 0.914 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jing, Y.; Wang, H.; Shao, K.; Huo, X. Relation Representation Learning via Signed Graph Mutual Information Maximization for Trust Prediction. Symmetry 2021, 13, 115. https://doi.org/10.3390/sym13010115
Jing Y, Wang H, Shao K, Huo X. Relation Representation Learning via Signed Graph Mutual Information Maximization for Trust Prediction. Symmetry. 2021; 13(1):115. https://doi.org/10.3390/sym13010115
Chicago/Turabian StyleJing, Yongjun, Hao Wang, Kun Shao, and Xing Huo. 2021. "Relation Representation Learning via Signed Graph Mutual Information Maximization for Trust Prediction" Symmetry 13, no. 1: 115. https://doi.org/10.3390/sym13010115
APA StyleJing, Y., Wang, H., Shao, K., & Huo, X. (2021). Relation Representation Learning via Signed Graph Mutual Information Maximization for Trust Prediction. Symmetry, 13(1), 115. https://doi.org/10.3390/sym13010115