1. Introduction
Blind deblurring, or blind deconvolution, has received considerable attention in the field of image processing and computer vision. The most typical example is the motion blur caused by a mobile phone shaking when taking pictures. In addition, the movement of the target object, bad weather, poor focus, insufficient light, etc., are all causes of image degradation. The blur kernel is assumed to be space-invariant. The blurred image
obtained is expressed as the convolution of the kernel
and the clear image
. The kernel is also referred to the point spread function (PSF) [
1], which leads to image degradation. The blurring process can be modeled as follows [
2]:
where “*” stands for the convolution operator;
and
represent clear images and blurred versions, respectively;
denotes the kernel representing degradation induced in the spatial domain; and
stands for the inevitable noise.
In blind deblurring, only the blurred version
is known; thus, we have to calculate the kernel
and the clear image
through the obtained blurred image
, simultaneously. Obviously, this problem is highly ill-posed. In theory, infinite solution pairs
and
correspond to
. The delta kernel and blurred images are the most typical solutions. To alleviate this inherently ill-posed problem, image priors and appropriate regularization are employed [
3]. Various statistical priors are incorporated into the associated variational model to tackle this challenging inverse problem. The statistical priors about images mainly include image gradient sparse priors [
4,
5,
6], L0 regularized priors [
7,
8,
9], low-rank priors [
10,
11], dark channel priors [
9], deep discrimination priors [
12], extreme channel priors [
13], and patch-based priors [
14,
15]. Moreover, many specially designed priors [
16,
17] are exploited. The maximum a posterior (MAP) framework [
18] is used by most of the above algorithms. The solution space is constrained, and the possibility of the algorithm producing trivial solutions is reduced. Most of the priors mentioned above are about image gradient priors. The information about the image itself needs to be better utilized. Therefore, it makes sense to establish a prior that is more relevant to the image domain.
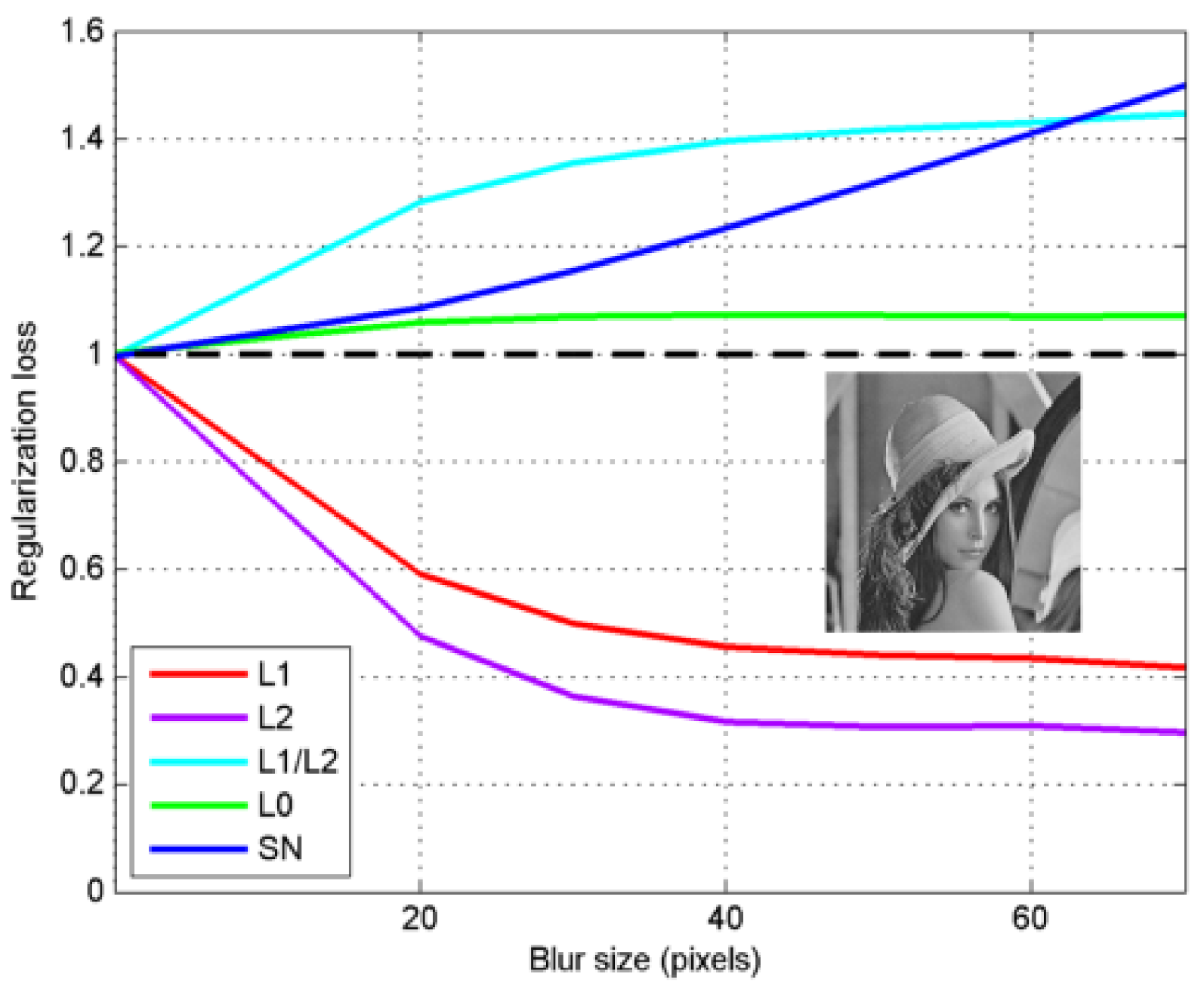
This paper proposes a prior that is directly related to the image, that is, spectral norm regularization (SN). Its form is
, where
is the spectral norm of the image. SN and other regularizations will be compared in detail in
Section 3. As shown in
Figure 1, the SN value is positively correlated with the degree of image degradation. Based on this discovery, a blind deblurring algorithm using SN is proposed.
The core contributions are as follows:
- (1)
This paper proposes a prior, named spectral norm regularization (SN). Different from existing image gradient priors, SN is a prior about the image domain. The SN value becomes larger when the image becomes blurred. As a result, SN can easily distinguish between degraded and clear images.
- (2)
This paper proposed a novel algorithm to utilize the property of SN, named BDA-SN. BDA-SN can use not only the information brought by the image gradient domain but also the information brought by the image domain. Therefore, BDA-SN can better deal with blind deblurring.
- (3)
Extensive experiments demonstrate that BDA-SN can achieve good performances on actual and simulated images. Qualitative and quantitative evaluations indicate that BDA-SN is superior to other state-of-the-art methods.
2. Related Work
In the past ten years, deblurring algorithms for single images have made great progress. There are two main methods. One is through statistical priors of natural images, and the other is via deep learning.
Scholars developed various statistical priors on image distribution in order to efficiently calculate the kernel. After investigating the variational Bayesian inference, Fergus et al. [
4] introduced a mixture of Gaussian models to fit the gradient distribution. To better fit the gradient of the heavy-tailed distribution, a piecewise function was adopted by Shan et al. [
6]. Levin et al. [
5] found that the maximum a posterior (MAP) method often produces trivial solutions and introduced an effective maximum margin strategy. Krishnan et al. [
19] exploited the L1/L2 function to restrict the sparsity of the gradient. Xu and Jia [
7] found a more sparse prior; that is, the generalized L0 regularization prior, which not only improves the restoration quality but also speeds up algorithm efficiency. For text images, Pan et al. [
9] investigated the sparsity of image pixel intensity. Jin [
20] designed a blind deblurring strategy with high accuracy and robustness to noise. Bai et al. [
21] exploited the re-weighted total variation of the graph (RGTV) prior that derives the blur kernel efficiently. L0 regularization is widely used in image restoration and has achieved excellent results. Li et al. [
12] utilized L0 regularization to constrain the blur kernel. In this paper, the L0 regularization prior is also adopted in the proposed blind deblurring model.
In the MAP framework, the estimation of the kernel benefits from sharp edges. Therefore, algorithms that use explicit edge extraction [
22,
23] have received widespread attention. Using a gradient threshold to retrieve strong edges is the main edge extraction method at present. The explicit edge extraction method has obvious defects; In other words, some images have no obvious edges to retrieve [
24]. This method not only leads to over-sharpening of the image but also to the amplification of noise.
The gradient prior and the intensity prior are mainly applied to a single pixel or adjacent pixels, ignoring the relationship in a larger range. In order to better reflect the relationship within the image, many patch-based algorithms have been exploited. Inspired by the statistical priors of natural images, Sun et al. [
25] adopted two priors based on patch edges. Ren et al. [
10] developed a blind deblurring method combining self-similar characteristics of image patches with low-rank prior. By combining low ranking constraint and salient edge selection, Dong et al. [
11] developed an algorithm that can protect edges while removing blur. Hsieh et al. [
26] proposed a strongly imposed zero patch minimum constraint for blind image deblurring. These patch-based methods require a patch search, so more running time is required. Tang et al. [
15] used sparse representation with external patch priors for image deblurring. Pan et al. [
9] analyzed the changes in the dark channel after the image was blurred and introduced a blind deblurring algorithm via a dark channel prior, which achieves good performance in different scenes. Yan et al. [
13] combined a bright channel with a dark channel and utilized the extreme channel for image restoration. Although Pan et al. [
9] and Yan et al. [
13] have achieved good results, they obviously encountered certain limitations. Sometimes, the image did not have obvious dark pixels and bright pixels and the blur kernel could not be effectively estimated. Inspired by the dark channel prior, Wen and Ying [
27] proposed sparse regularization using the local minimum pixel, which improves the speed of the algorithm. At the same time, Chen et al. [
16] proposed the local maximum gradient prior (LMG) for blind deblurring, and LMG has reached satisfactory performance in a variety of scenes. Xu et al. [
24] simplified LMG and derived the patch maximum gradient prior (PMG), which lowered the cost of calculation. Algorithms based on image priors are difficult to use to restore images of specific scenes [
28]. Therefore, some algorithms for special scenes have been exploited, such as text [
9], saturated [
29], and face images [
29]. However, these specific algorithms often lack generalization and have poor restoration effects on other special scene images.
Table 1 summarizes the strengths and weaknesses of BDA-SN and previous methods.
In recent years, deep neural networks have developed rapidly, and data-driven methods have made great progress. Nah and Hyun [
30] adopted a convolutional neural network (CNN) with multiple scales, which does not need to make any assumptions about the kernel and recovers images with an end-and-end method. Su et al. [
31] used a deep learning method to deblur the video with trained CNN. Kupyn et al. [
32] exploited an end-and-end learning approach, which utilizes conditional generative adversarial networks (GAN) to remove motion blur. Zhao et al. [
33] developed an improved deep multi-patch hierarchical network that has a powerful and complex representation for dynamic scene deblurring. Almansour et al. [
34] investigated the impact of a super-resolution reconstruction technique using deep leaning on abdominal magnetic resonance imaging. Li et al. [
35] developed a single-image high-fidelity blind deblurring method that embedded a CNN prior before MAP. Although these data-driven ways reached excellent results, the effects severely depend on the similarity of the test dataset and the training dataset. Therefore, the generalization of data-driven strategies is poor, and the computational cost is huge.
Having reviewed the progress of image restoration of the last decade in this section, the rest of this work is as follows. In
Section 3, this paper introduces a blind deblurring algorithm using spectral norm regularization (BDA-SN) in detail. In
Section 4, this paper presents some experimental results for performance evaluation, which are compared with the latest methods.
Section 5 provides an analysis and discussion about the effectiveness of BDA-SN.
Section 6 gives a summary of this paper.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}