1. Introduction
With the development of autonomous ship technology, the safety of the autonomous navigation of ships is particularly important. An accurate ship maneuvering model has a high practical value for providing accurate motion predictions or designing a control system. When the ship performs tasks that require high maneuverability, such as obstacle avoidance or navigation in narrow waters, the ship dynamics model is used to foresee the behavior or trajectory of the ship in the future, and judge whether the current control strategy is safe or the planned path meets the dynamic constraints. Then, the model takes the correct actions to avoid collisions.
The fluid dynamic effect and the complicated geometry of the hull surface cause a nonlinear or asymmetrical behavior, since establishing an accurate dynamic model is always a difficult problem in practical applications for ships. Currently, modeling of the ship maneuvering motion is mainly divided into parametric modeling based on a priori model and nonparametric modeling based on data. Both modeling methods have their own advantages and disadvantages.
In parametric modeling, many models have been proposed to approximate the ship dynamics. In particular, the quadratic Norrbin model [
1] and cubic Abkowitz [
2] model are widely used in surface ships. Methods such as the least square [
3], extended Kalman filter (EKF) [
4], and least squares support vector regression (LSSVR) [
5,
6] have been used to identify the hydrodynamic coefficients in the model. However, due to the correlation between the terms in the model, the parameter cancellation effect [
7] makes some hydrodynamic coefficients very unstable. The optimal truncated singular value decomposition (T-SVD) [
8] and optimal truncated least squares support vector regression (T-LSSVR) [
9,
10,
11] are proposed to reduce the uncertainty of the estimated parameters. However, this problem is not yet completely solved. At the same time, since only a limited number of polynomials are used to approximate the model, the model’s accuracy is not yet ideal, especially in the surge velocity. The ‘true’ model structure of a ship is never known. The goal of building a model is to obtain accurate predictions, and to not necessarily obtain the correct model structure.
Nonparametric modeling requires almost no previous information of the model structure of the ship, which can also obtain accurate predictions. Machine learning techniques provide an effective way for the modeling of ships [
12]. Methods such as support vector regression (SVR), locally weighted learning (LWL), and Gaussian process regression (GPR) have been used in modeling of the ship maneuvering motion. Generalized ellipsoidal basis function fuzzy neural networks [
13] are used to model the movement of a large tanker. However, the structure of the neural network is more difficult to determine. The
-support vector regression (
-SVR) [
14] is proposed to establish the maneuvering motion model and is validated by KVLCC2 ship experimental data. Moreover, it is based on structural risk minimization to overcome the shortcomings of neural networks that are easy to overfit. However, the parameters are difficult to adjust. A novel nonparametric identification modeling method based on locally weighted learning (LWL) [
15] is used for ship dynamics modeling. It can provide higher modeling accuracy, but has the disadvantage of high computational complexity and long computational time. Kernel ridge regression (KRR) [
16,
17,
18] trains the models with several random tests, while KRR requires the performance of a grid search for hyperparameter optimization. Gaussian process regression (GPR) can automatically optimize hyperparameters by maximizing the marginal likelihood function, and it can also overcome overfitting. It is widely used in the dynamic modeling of robotic arms [
19] and racing cars [
20]. Recently, it has also been introduced in the dynamic modeling of ships. Multi-output Gaussian processes are proposed to model a container ship [
21]. A noisy input Gaussian process is proposed for ship dynamics modeling using simulated ship motion data with artificial noise [
22].
In general, nonparametric modeling with the kernel function avoids the shortcomings of parametric modeling that require a knowledge of the model structure. The nonparametric model can obtain ship motion prediction with higher accuracy than the parametric model. Insufficient information can affect the generalization ability of the model. Both the parametric model and nonparametric model require a large sample of data to cover the state space, in order to ensure the generalization of the model. However, it is difficult to use nonparametric kernel methods for regression when the data sample is too large.
In this paper, a nonparametric model based on sparse Gaussian process regression with similarity was used for the dynamic modeling of a ship without assumptions in the mathematical model of the ship. It solves the problem, wherein the kernel method is difficult to apply to big data, using similarity to sparse large sample datasets. The experimental data of KVLCC2 ship are used to verify the validity of the proposed method. In the case of sensor signal loss, the identified model continues to provide accurate ship acceleration, speed, and trajectory information in the future. Moreover, the multi-step prediction model is used to provide accurate ship speed and position information in the future, and it provides important support for the autonomous navigation of ships.
The rest of the paper is organized as follows:
Section 2 presents the ship parametric model and nonparametric model, and reviews the Gaussian Process regression algorithm.
Section 3 describes the large sample sparse Gaussian process regression algorithm based on similarity. In
Section 4, identification modeling and a systematic evaluation are conducted based on real data from KVLCC2 model tests. Finally,
Section 5 presents the conclusions and suggestions for future work.
3. Large Sample Sparse Gaussian Process Regression Algorithm Based on Similarity
Nonparametric modeling based on kernel methods, such as the Gaussian process is mainly suitable for interpolation prediction. When there are sample points near point that are required to be predicted, the prediction at will be more accurate. In order to learn a ‘good’ model, the training dataset requires the state space to be covered as much as possible.
Ship motion data are usually in the hundreds of thousands. Accurate modeling requires as many samples as possible to provide rich data incentives. However, when all of the sample points are used for regression prediction, it will cause the inverse matrix to be uncalculated. The easiest way to reduce the calculation of the inverse matrix is to select only a small part of the large sample data for modeling. The randomly selected data from a large sample will make the sample spatial distribution uneven. In addition, there may be no sample points in a local area that are close to point that require to be predicted, resulting in inaccurate predictions.
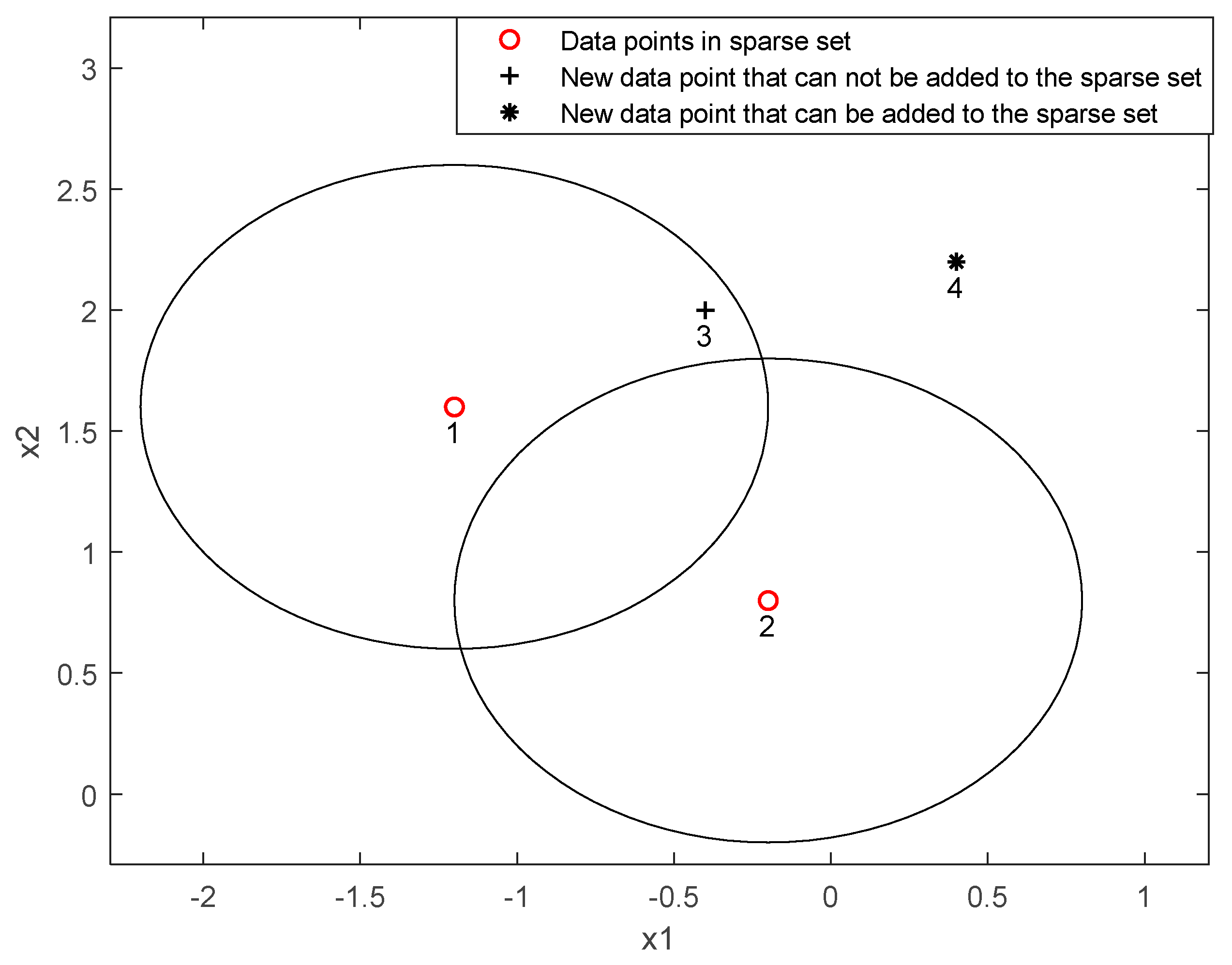
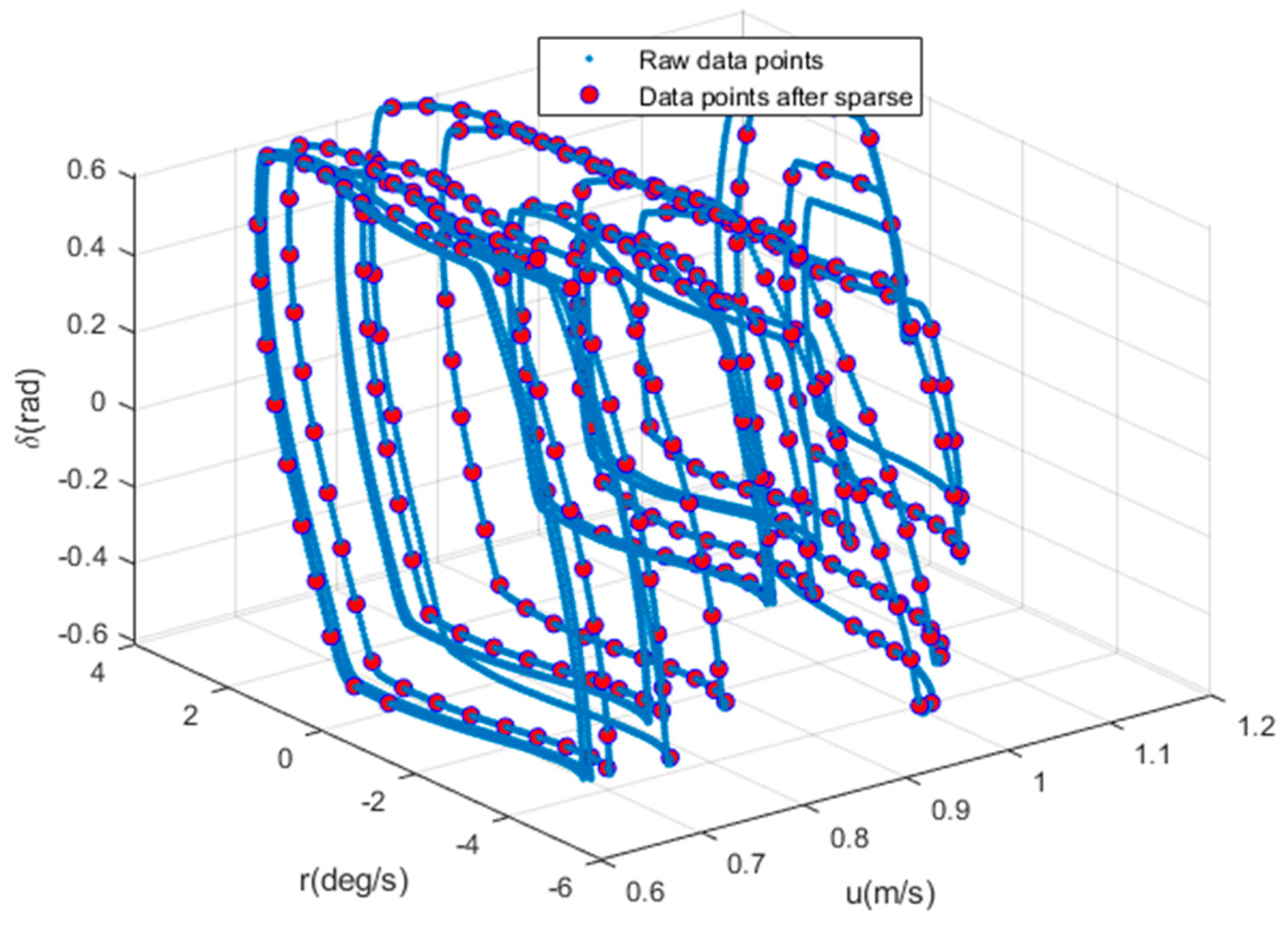
A sparse algorithm based on similarity is proposed to the sparse large sample data. Points with less similarity are equivalent to containing new incentives and are added to the sparse set. Points with greater similarity are regarded as information redundancy and are not added to the sparse set. A sparse set with a small uniform distribution in the shape space is obtained, which replaces the overall sample for regression prediction.
Taking a two-dimensional input system as an example, the similarity between
and
can be defined as
The closer and are, the greater the similarity, and the similarity is 1 when they are completely similar. Moreover, and represent the weight coefficient of each dimension. Here, the larger the setting, the larger the interval between the data points selected for this dimension. Furthermore, it can usually be set to the amplitude of each dimension to balance the data points of each dimension.
Figure 3 shows the principle of updating sparse data based on similarity. The new data point 3 has a high similarity to the existing points in the sparse set. It is regarded as data redundancy and is not added to the sparse set. Point 4 is farther from the sparse set and is regarded as new information that is added to the sparse set.
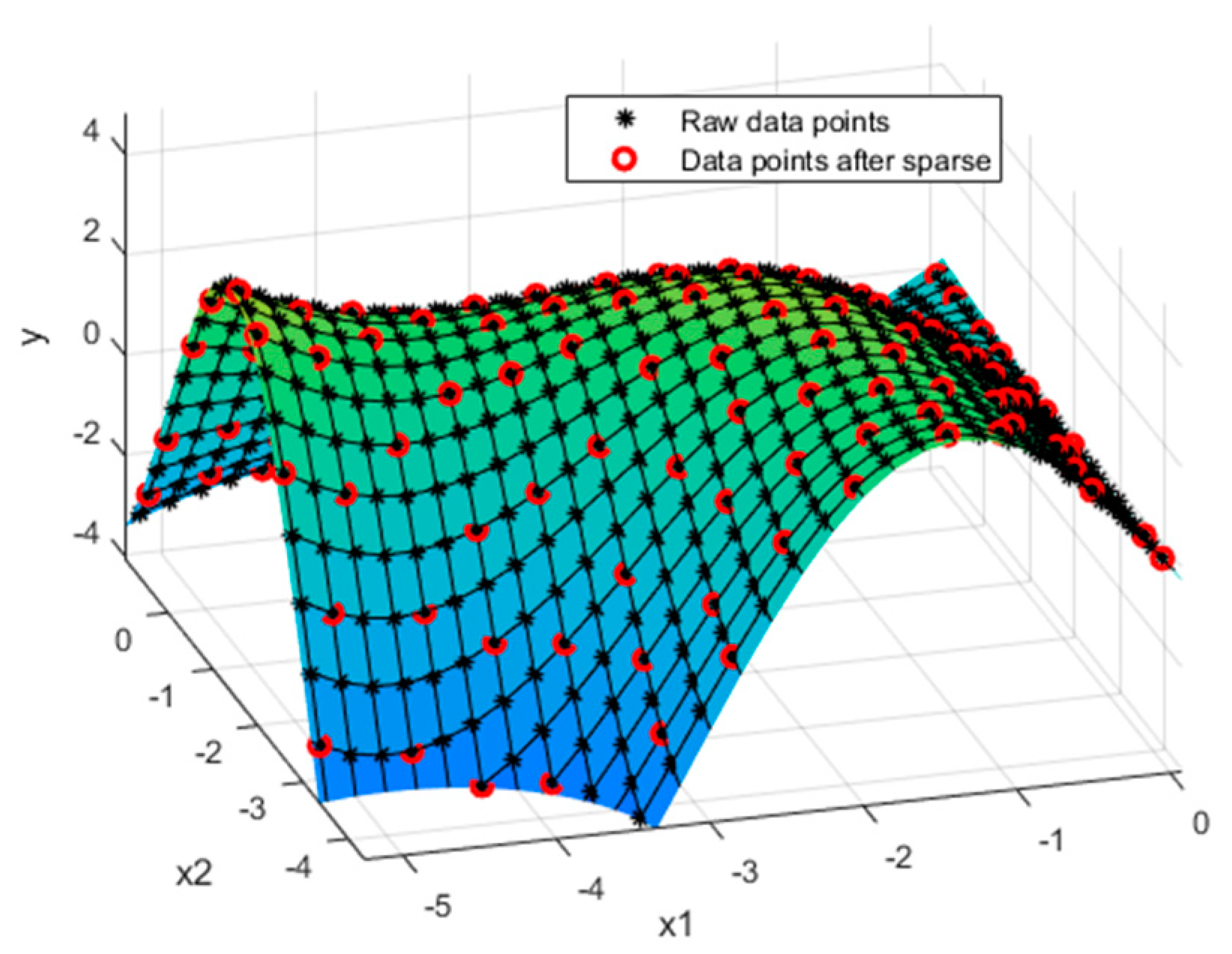
Taking two-dimensional surface reconstruction as an example, the data points are generated by the function in Equation (12). Both dimensions are sampled at 0.2 intervals for a total of 3721 sample points. The flowchart of learning based on the sparse Gaussian process is detailed in
Table 1.
Figure 4 shows the distribution of data after sparseness, and the sparse data points are evenly distributed throughout the space.
Table 2 shows the influence of sparse data amount on model prediction accuracy and speed. It can be found that only 350 data points can be selected to achieve a similar prediction accuracy to 3721 samples. In addition, the training time is shortened from 54 to 0.6 s and the accuracy is satisfied. At the same time, it greatly saves training time.
5. Conclusions and Future Work
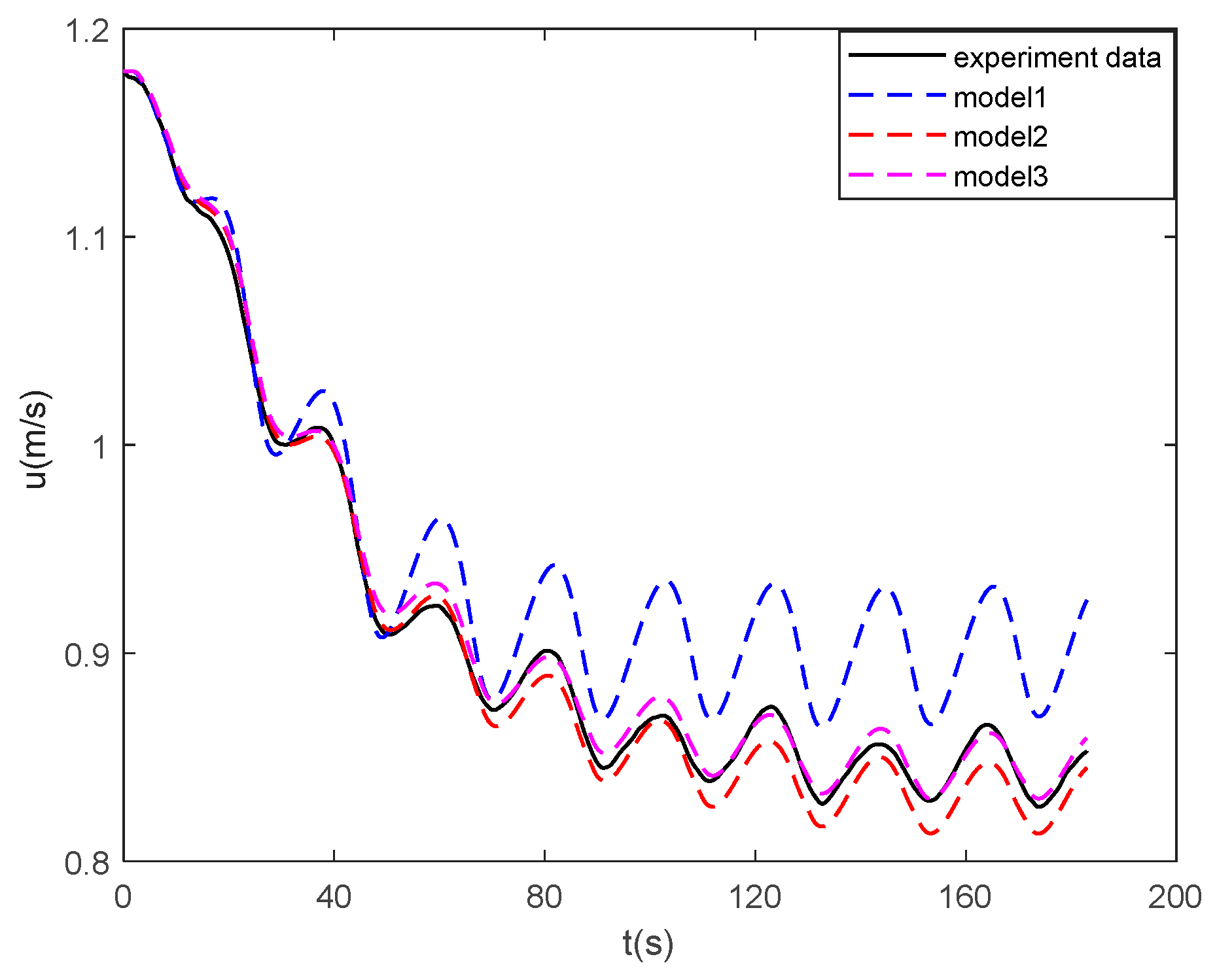
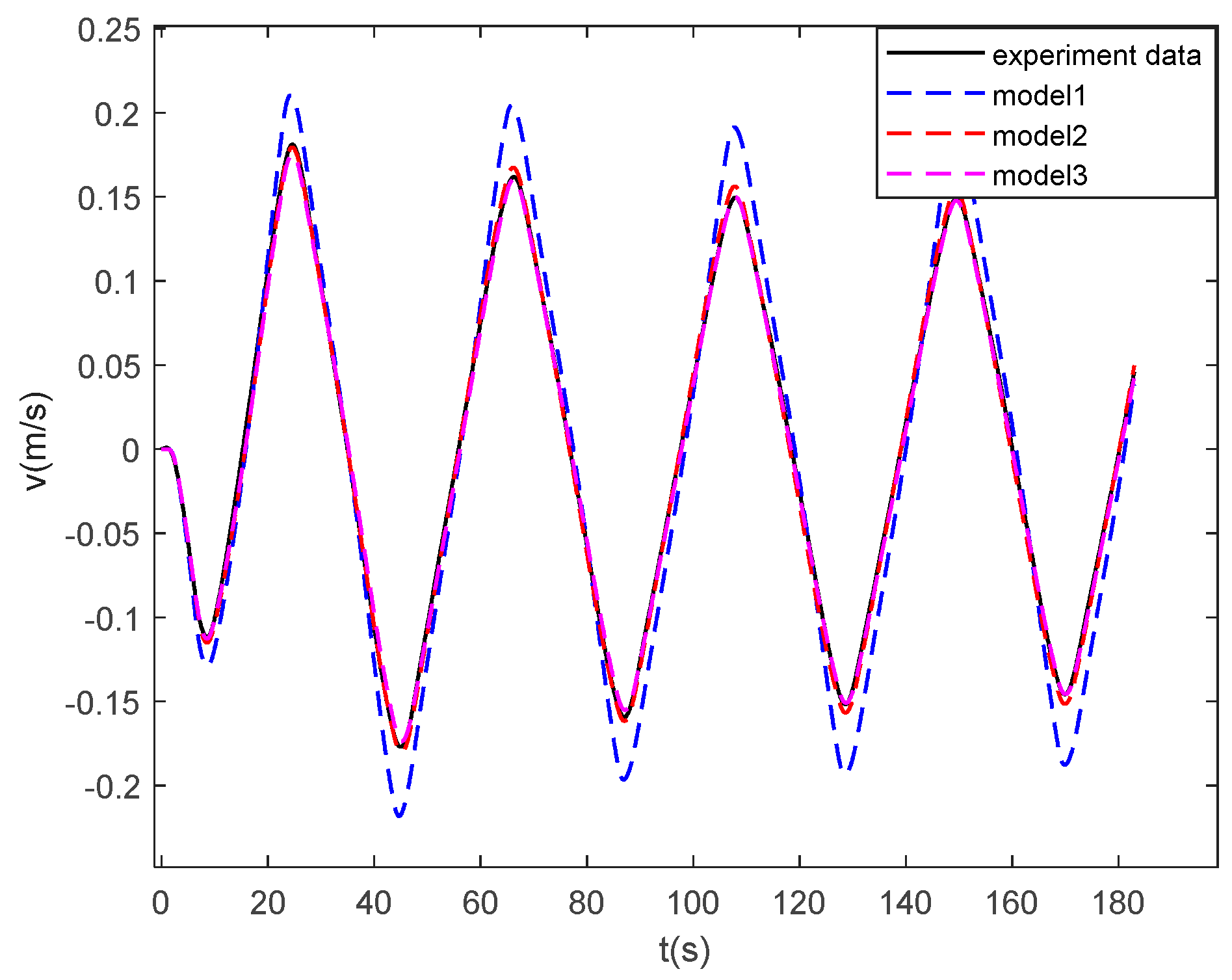
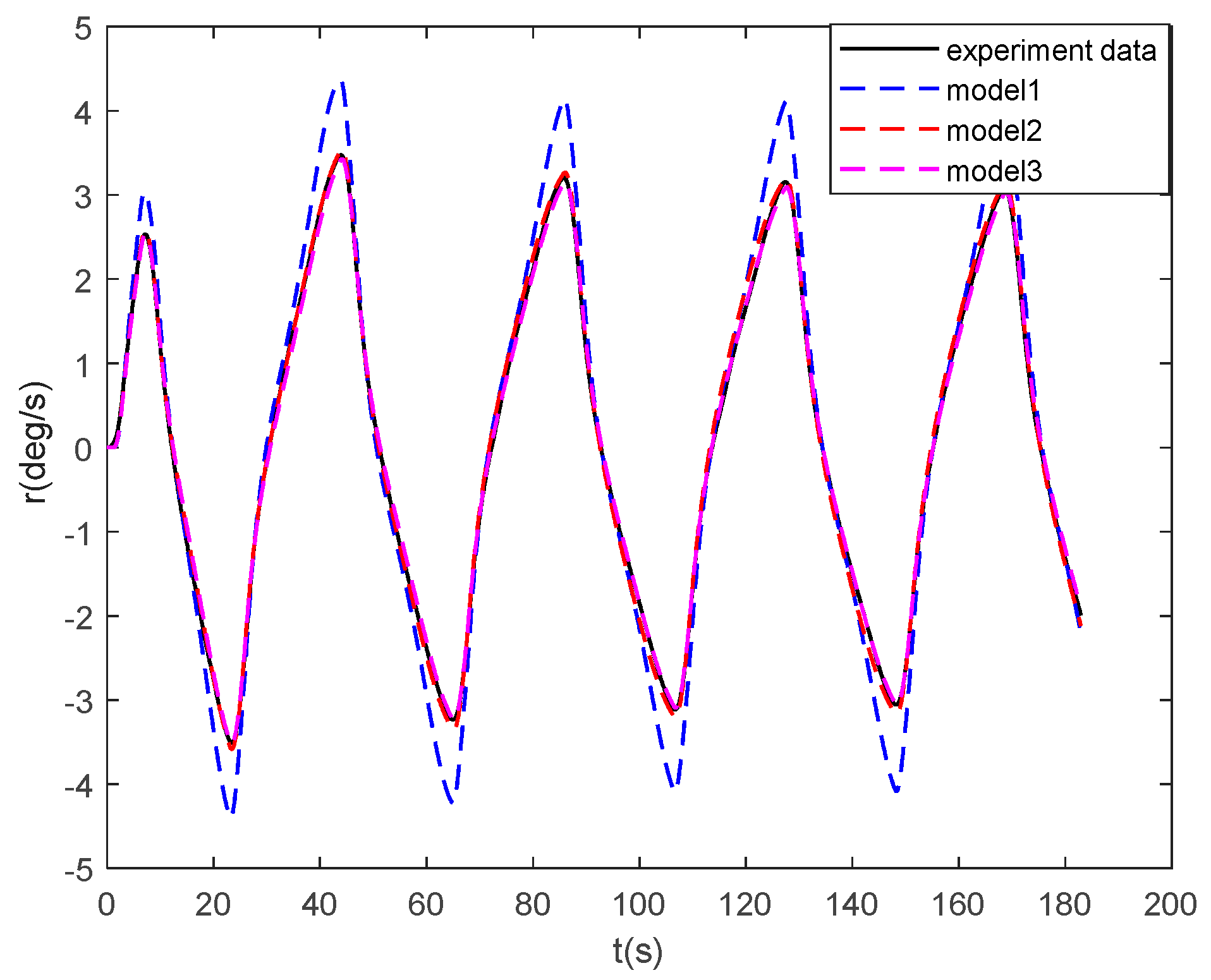
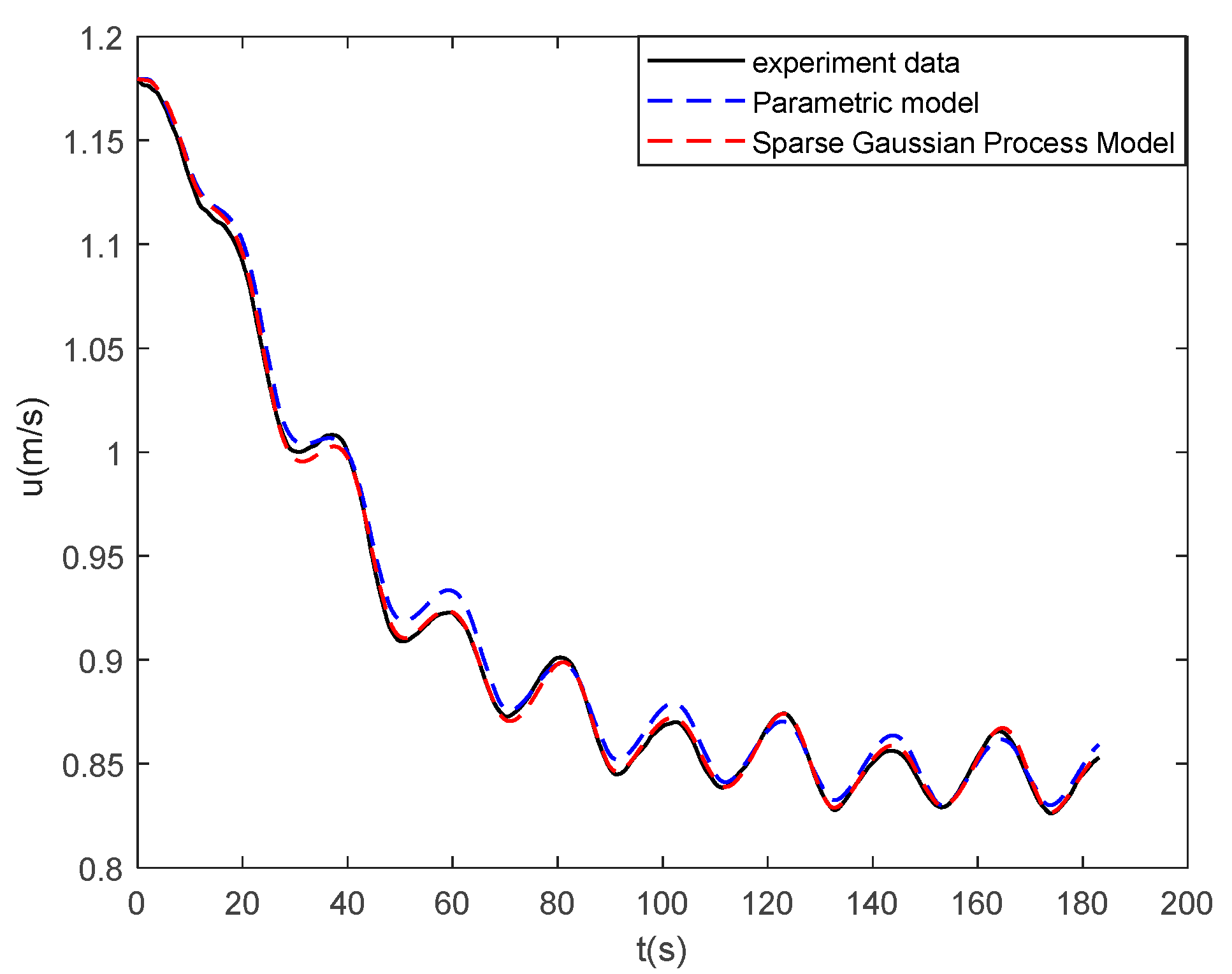
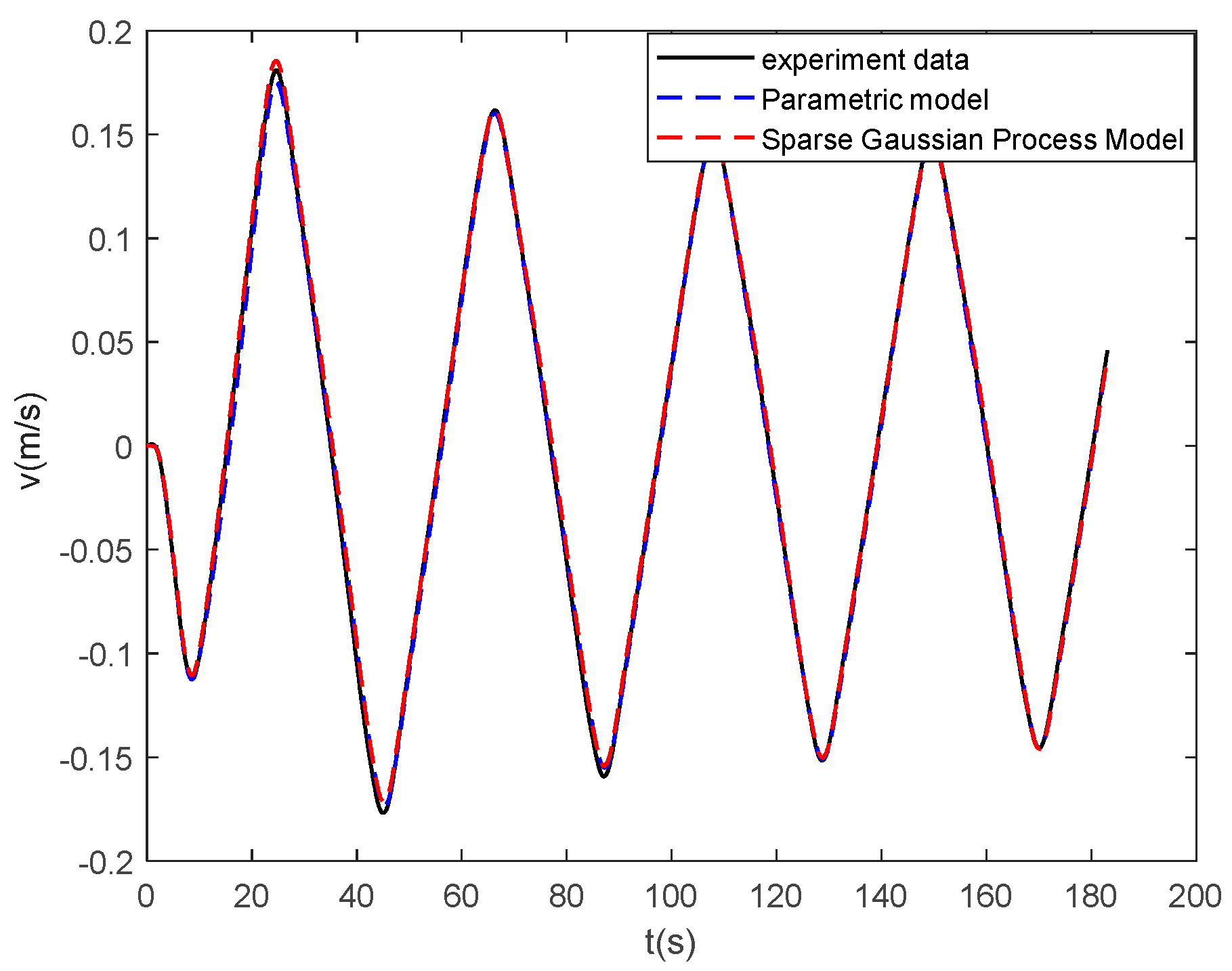
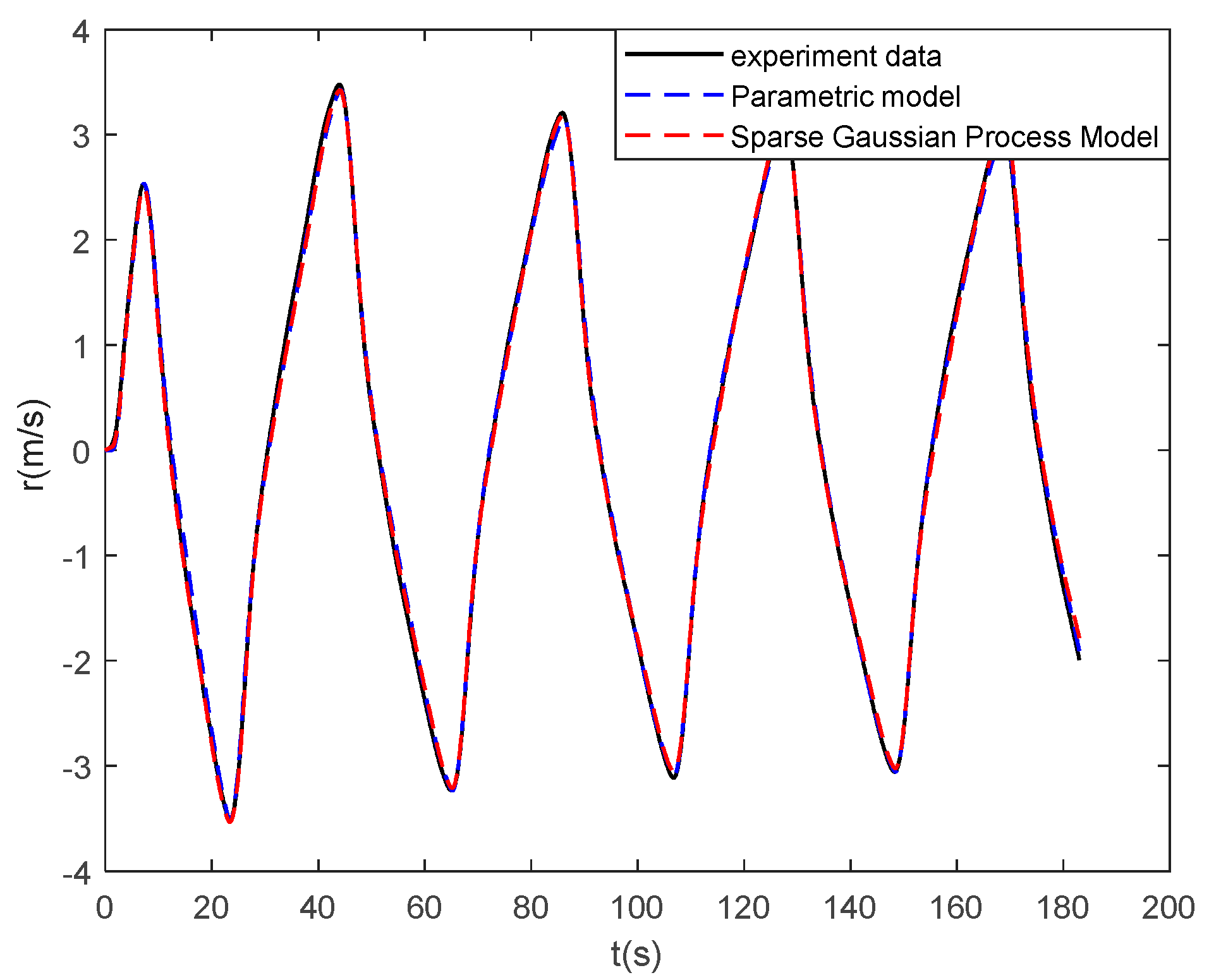
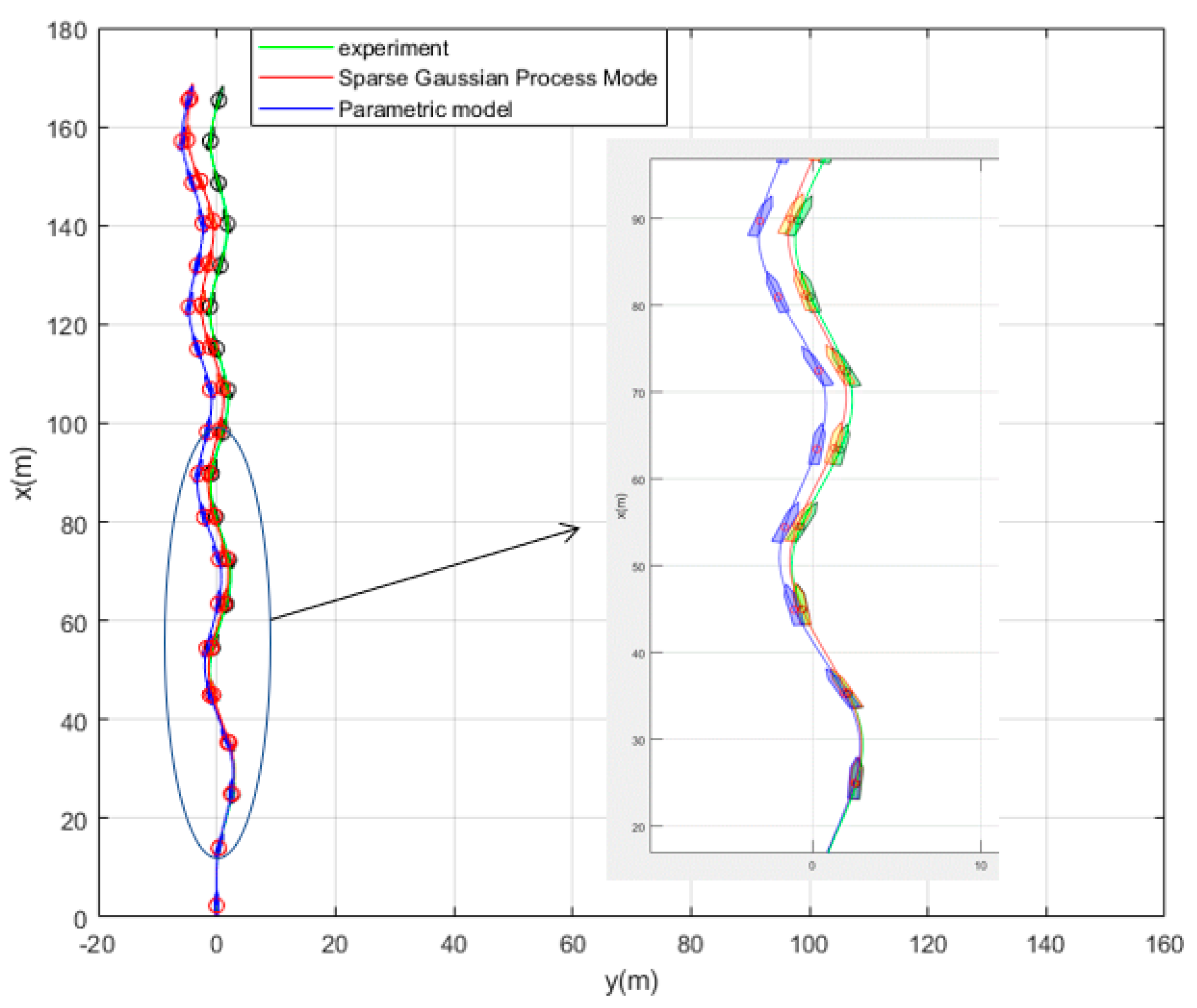
In this work, a data-driven nonparametric model based on sparse Gaussian process regression with similarity was used for the dynamic modeling of a ship. The experimental data of KVLCC2 are used to verify the validity of the proposed method. The case study shows that the sparse Gaussian process regression with similarity can be applied to the learning of large sample data and to obtain ship motion prediction with higher accuracy than the parameterized model. In the case of sensor signal loss, the model can continue to provide accurate ship state information in the future, and the maximum error of 100 s trajectory prediction is 0.59 m. High-precision prediction can help controllers make safe decisions on path planning and obstacle avoidance.
The advantages of the proposed model based on sparse Gaussian process regression with similarity for ship dynamics modeling can be summarized as follows: First, unlike parameter identification, the model based on Gaussian process regression is not required to know the previous model structure of the ship dynamics. It obtains a more accurate motion prediction than the parametric model. Second, the similarity-based sparse method solves the defect, wherein the kernel method is difficult to apply to large sample data learning. It only uses very little data to replace the large sample information. Therefore, the model can be more generalized. Finally, the Gaussian process is the same as LSSVR and KRR in mean prediction. The hyperparameters learned by the Gaussian process can be used in the two aforementioned methods. In addition, the proposed sparse algorithm can be applied to the two aforementioned algorithms.
However, the proposed method still requires further research. Since the information contained in the dataset determines the essential performance of the model, it is difficult to further improve the model performance without increasing the training data. For parametric and nonparametric identification, the training data should cover the ship motion state space as much as possible. Moreover, further research is required to understand how the least experimentation can be used to cover the state space.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}