1. Introduction
Transition matrices such as the ones summarizing a Markov chain contain a certain amount of information, but this amount is not so straightforward to quantify. When the transition matrix is estimated from an observed dataset, we generally consider the contingency table associated with the transition matrix, and we evaluate the quantity of information it contains using a measure of association. There exist many different measures of association, some being derived from the chi-square statistic (e.g., Cramer’s V), some being defined as the proportion of reduction in error (e.g., Theil’s u, Goodman & Kruskal
&
), and others being based on the concept of similarity and dissimilarity (e.g., Goodman and Kruskal
, Kendall’s
, Somers’s
d) [
1,
2]. All these measures have in common that they take as a reference situation the perfect independence between rows and columns of the contingency table, then they quantify the strength of association as a function of the distance between the reference situation and the contingency table of interest.
The concept of a measure of association is particularly relevant in the social sciences, because the vast majority of variables used for analysis are categorical in nature, often without a precise ordering of the modalities. The number of modalities of a variable can sometimes be very large, for example in the case of an exhaustive classification of all the types of diplomas that can be obtained. Moreover, the number of potential explanatory factors for a phenomenon can also be very large, because social phenomena are often closely linked to one another (family, school and professional trajectories, for example). Measures of association are therefore extremely useful for comparing different factors with each other and ranking them according to their explanatory power.
Numerous measures of association have been defined to take into account the characteristics of the different variables studied. Many of these measures are highly specialized. For example, the Pearson correlation coefficient is intended to measure a linear relationship between two continuous variables, to the exclusion of other forms of relationship. The notion of predictive power described in this article follows the same logic in that it is intended to best express the row-to-column relationship that may exist within a specific object, a transition matrix. On the other hand, other measures of a more general nature have also been proposed. Recently, one can note the concept of Maximum Information Coefficient (MIC, [
3]). It should be noted, however, that too much generality of a coefficient can also make it unsuitable for certain uses. For example, because the MIC is symmetric, it does not apply to transition matrices associated with one-way Markov chains running from the past to the future. Similarly, if one wants to be able to distinguish between several types of relationships (linear, exponential, parabolic, etc.), it is necessary to use tools that allow one to distinguish a particular form of relationship.
If we concentrate on the transition matrix of a Markov chain, the rows and columns are not interchangeable. According to the standard notation, the rows represent the past observation and the columns represent the current observation. Therefore, a measure of the quantity of information must be asymmetrical with the columns depending on the rows. Among the previously cited association measures, some of them such as Theil’s u are in line with this requirement, but they measure the degree of dependence between rows and columns rather than the quantity of information provided by the matrix to predict the column variable.
The following example highlights the difference between both concepts. Let
and
be two transition matrices associated with first-order Markov chains:
Both transition matrices represent a situation of perfect independence between the rows and columns in the sense that the information provided by a specific row cannot help to better predict the corresponding column, and vice versa. Consequently, all the measures mentioned above take a value of zero meaning perfect independence. From another point of view, if the goal is to predict the most likely column, then provides more information than , since whatever the row, the first column occurs 60% of the time, while the probability of occurrence of all columns is identical in . Consequently, if you need to guess the most likely column, you would prefer to have instead of . This example simply demonstrates that traditional measures of association do not take into account all the information contained in a transition matrix. Put differently, the concept of association measures the degree of difference between the rows of the matrix. On the contrary the concept of predictive power that we introduce in this article considers in addition the degree of difference between the columns. While it is sufficient for all rows to be equal for the association to be zero, zero predictive power additionally requires that the columns be equal (or equivalently that all row distributions be equal to the uniform distribution).
The distinction between a measure of association and a measure of predictive power proves important when working with Markovian models. If we consider a high-order Markov chain and we want to approximate it through a Mixture Transition Distribution (MTD) model [
4], then it is useful to evaluate the role and importance of each lag in the overall model. This is very important, because by its construction, the MTD model will be all the better as the contribution of each lag on the present is similar. This is also the starting point for the traditional estimation algorithm of the MTD model [
5,
6]. If matrices
and
above represent the direct relationship between lag 1 and the present, and lag 2 and the present, respectively, then using an association measure such as Theil’s
u would just indicate that both lags are absolutely non-informative on the present situation, when in fact
gives a clear indication of the most likely current situation. Therefore, evaluating the two matrices through a measure of the predictive power rather than an association measure is clearly better.
Of course, one could argue that if the transition matrix of a Markov chain has all rows equal, then it corresponds to a zero-order model, which is an independence model. This is true, but once again, even independence models can be more or less informative regarding the variable of interest. For instance, if we assume that a condition can have three causes and our model points with a 60% probability to one of them, we are in a better position to determine the best treatment than if all three causes are equally likely.
The concept of predictive power was first introduced by the author in a now out of print book about Markov chains written in French [
7], but until then the concept had not been really developed and it had never been published in English. In this article, we define which properties are required for a statistic to be a measure of the predictive power of a transition matrix rather than a measure of association, then we define such a statistic, we provide two alternatives, and we illustrate the behaviour of these measures through practical examples.
2. Properties of a Measure of the Predictive Power
Traditional measures of association evaluate the distance between an empirical matrix and a matrix with perfect independence between rows and columns. The more different the rows of the matrix, the higher the association. On the other hand, the predictive power of a matrix measures the degree of certainty about the column. As can be deduced from the example of
Section 1, when the association is null, the predictive power can be non-null, but when the predictive power is null, the association is null too. Formally, we define the following desired qualities for a measure of the predictive power:
The predictive power takes values between zero and one.
The predictive power reaches its minimal value of zero only when all rows of the transition matrix are uniform distributions.
The predictive power reaches its maximal value of one only when whatever the row of the matrix, there is always a probability of one to be in one of the columns (not necessarily the same column for each row).
The predictive power increases weakly monotonously with the certainty of the columns.
The first point is required for the sake of clarity and simplicity of use of the measure. Indeed, it would be perfectly possible to consider, for example, a measure ranging from −1 to +1, but then it would be difficult to understand what a negative rather than a positive value could mean. The second and third requirements ensure that when the measure takes its minimum, then it is not possible to transform the matrix (by exchanging some elements of the underlying contingency table) into another one with even less predictive power, and vice versa regarding the maximum value. Finally, the fourth requirement ensures that all possible situations represented by a transition matrix can be ordered in a non-decreasing manner, hence ensuring their comparability.
Different concepts are available to fulfill all of these requirements and to build a suitable measure. We present three possibilities in the next section.
5. Conclusions
Association and predictive power are two close but different concepts measuring two different aspects of a transition matrix or of a contingency table. The main difference is that with the concept of association, all situations of independence correspond to the value of zero, when the predictive power differentiate further between independence situations that provide no information on the most likely column of the transition matrix or contingency table, and situations that provide some kind of information about the columns. In that sense, predictive power extends the concept of association for situations in which it is important to differentiate between the columns.
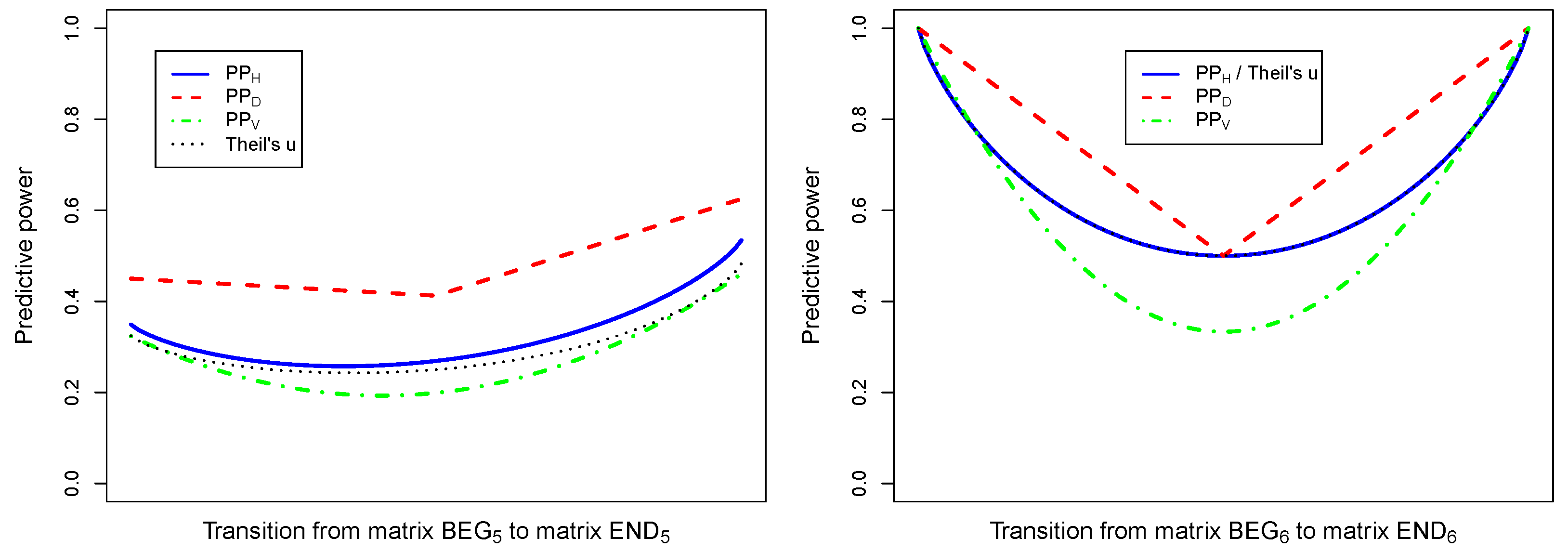
By nature, the concept of predictive power is not symmetric. This is illustrated by the discussion of the comparison between predictive power and Theil’s
u, as well as by the various numerical examples provided in
Section 4. However, predictive power coefficients are useful for detecting and quantifying situations in which symmetry reduces the complexity of a problem into a simpler problem. Therefore, predictive power should not be viewed as a symmetric concept per se, but as a tool for detecting symmetry.
A specific situation in which the predictive power proves useful is for the initialization of the estimation algorithm of the MTD model [
5]. Let a discrete random variable take two different values, and suppose that we want to model a second-order Markov chain. Suppose that empirically the links between lags 1 and 2 and the present, as computed from a dataset, are summarized by the matrices
and
used in
Section 4. If
is the direct relationship between lag 1 and the present, and
is the direct relationship between lag 2 and the present, then using Theil’s
u (as suggested in [
5]) would not let us to determine which matrix should be given more importance as starting value. Moreover, we could also wrongly conclude that since both matrices present a null association, then the Markovian process is of order zero and there is no interest in using a second-order model. On the other hand, using a measure of the predictive power such as
, we would conclude that lag 1 does not explain the present situation (
= 0), on the contrary of lag 2 (
= 1), so lag 2 should be given more weight than lag 1 in the initialization of the estimation process. We could also be certain that a second-order model is of interest.
In this article, we presented a concept derived from that of association, but allowing better distinguishing the respective importance of each column of a matrix. We believe that by allowing going beyond what is measured by the association concept alone, this new tool will allow to distinguish more finely between close situations, as it may be necessary when using the MTD model to approximate high order Markov chains. Now that measures of the predictive power of transition matrices have been defined, a next step could be to validate them. For this, a simulation approach could be considered by building theoretical causal models that could be used to generate artificial data in which the degree of dependence between the past and the present is fixed. Then, different measures of predictive power could be calculated and compared to verify that their values are closely correlated with the theoretical degree of causality.





{kind=link}
{kind=link}